写一次跑16颗芯片:看FlagTree如何终结AI算子的重复造轮
2026 年 4 月 21 日,第五届中国国际软件发展大会(CSISD 2026)在北京国家会议中心召开。大会以"人工智能与软件变革"为主题,中国科学院院士梅宏作主旨报告,开放原子开源基金会理事长谢少锋、华为云 CEO 周跃峰等先后做主题演讲。
在当天下午的高峰论坛上,北京智源人工智能研究院研究员郑杨发表了题为《多元 AI 芯片统一编译器 FlagTree 与公共编译中间表示层 FLIR》的主题报告,并正式发布了面向多种芯片架构、统一编译器的最重要一层:公共编译中间表示层FLIR,让多种芯片后端共享编译优化。通过FLIR的支持,芯片厂商适配FlagTree统一编译器可以更轻松,基于FlagTree的算子可以更容易获取优化性能。
一、问题:同一个算子,为什么要写十几遍?
AI 芯片产业正处于多架构并存阶段,华为昇腾、寒武纪、昆仑芯、摩尔线程、沐曦、天数智芯、海光、燧原、曦望芯科、安谋科技、清微智能、NVIDIA等,十余种架构各有各的编译器工具链、编程模型和中间表示(IR)。一个算子开发者要让自己的 kernel 跑在不同芯片上,就得为每家芯片重复开发和维护,工程成本随芯片种类线性增长。
Triton 试图解决这个问题。它通过 Python DSL 和基于 blocked program 的自动 tiling,降低了 GPU 算子开发门槛。然而,原生 Triton 编译器的多后端支持是分叉式的——各芯片厂商基于不同版本的 Triton 做 fork,fork 之间无法共享编译优化,事实上在 Triton 生态内部又制造了另一层碎片化。
能不能在一个统一的编译器仓库里支持所有芯片,并且让编译优化跨芯片共享?
答案是肯定的,FlagTree 和 FLIR 要解决的就是这个问题。
二、解法全景:FlagOS 的三层分工
FlagTree 和 FLIR 是 FlagOS 2.0 多元 AI 芯片统一开源系统软件栈的编译层组件。理解它们的定位,需要先看 FlagOS 的整体架构:
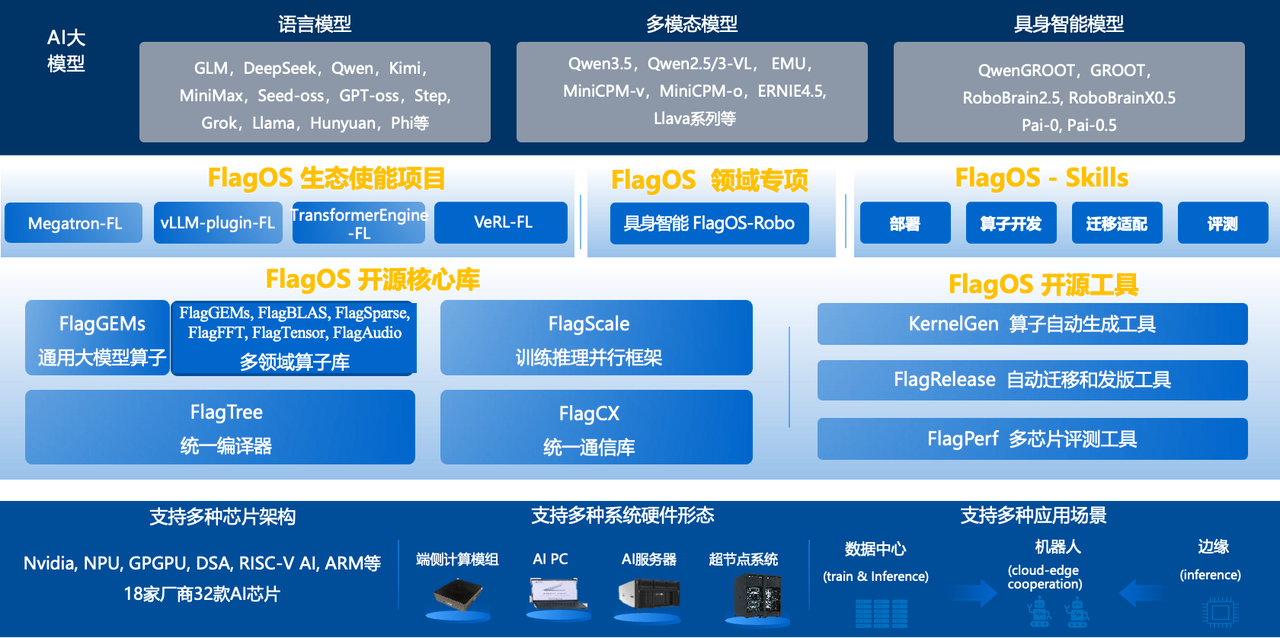
图1 、FlagOS:面向多种 AI 芯片的系统软件栈
-
算子库层(FlagGems 等):基于 Triton 语言编写的多领域算子库,FlagGems 已实现 497 个算子,覆盖大语言模型和多模态模型的主要计算需求。此外还有 FlagBLAS、FlagSparse、FlagFFT、FlagTensor、FlagAudio 等专项库。上游对接 PyTorch、TensorFlow、PaddlePaddle、MindSpore 等框架及 vLLM、SGLang 等推理服务
-
编译器层(FlagTree + FLIR):FlagTree 是统一编译器,将 Triton 语言编写的算子编译到不同芯片上;FLIR 是 FlagTree 内部的公共中间表示层,在各芯片后端之间共享编译优化
-
硬件后端层:16 家芯片/IP 厂商的编译器和运行时
简单说:FlagGems 让算子只写一次,FlagTree 让这份代码编译到多颗芯片,FLIR 让编译优化不重复做。
三、FlagTree:16 家芯片,一个仓库
FlagTree fork 自 triton-lang/triton,把 16 家芯片厂商的 Triton 后端聚合在同一个仓库中,统一编程接口和编译路径,每季度发布一个版本。当前已支持 180+ 算子在 10+ AI 芯片上的编译运行,各后端均配有独立的 CI/CD 保障代码质量。围绕编译器内核,FlagTree 向三个方向扩展能力:
-
FLIR:公共编译中间表示层,让编译优化跨芯片共享
-
TLE:三层语法接口扩展,让开发者获得超越原生 Triton 的编程能力和性能
-
Hint:非侵入式编译指导,让开发者在不破坏可移植性的前提下引导硬件级优化
编译管线中,Triton DSL 及其扩展经由 Triton IR 向下降级。对 NVIDIA/AMD 等 GPGPU 架构,走 TritonGPU IR → LLVM IR 的原生路径;对昇腾 NPU、安谋科技 AIPU、清微智能可重构处理器等非 GPGPU 架构,走 FLIR → Hardware-Specific IR 路径。
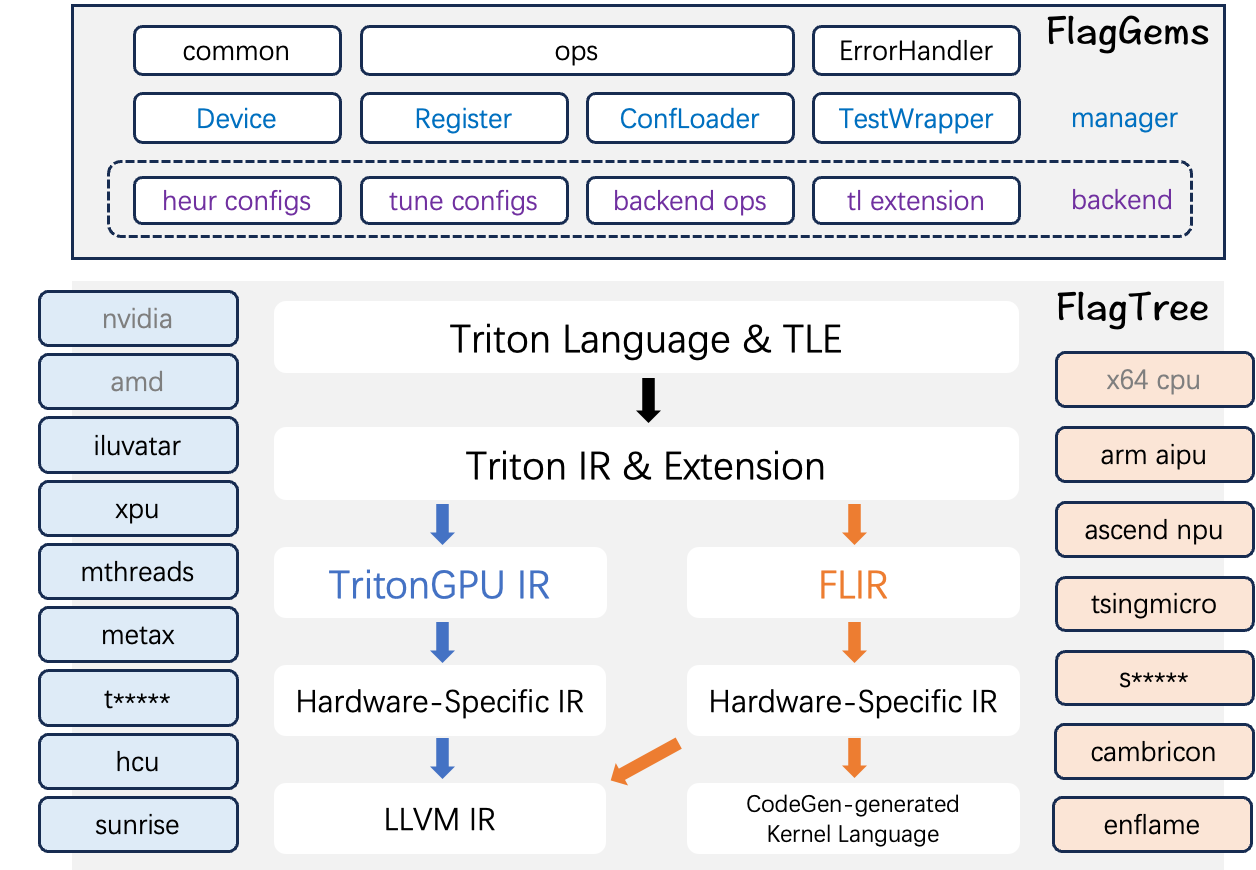
图2 、FlagTree生态矩阵:单仓库聚合 16 家芯片后端,统一编程接口与路径
每个芯片后端的接入由四个组件构成:
-
后端调度(
backend/compiler.py):将公共 Pass、FLIR Pass 和后端专有 Pass 按序编排成编译降级管线 -
后端专有 Pass:处理强依赖硬件架构的降级逻辑
-
运行时接入(
backend/driver.py):对接芯片底层框架,管理设备内存、Stream 调度与任务下发 -
后端 IR 构造接口(
backend_ir.cc):将底层硬件操作通过 Python API 暴露给上层
四、FLIR:公共编译中间表示层
4.1 为什么需要 FLIR
在 FLIR 之前,FlagTree 虽然把 16 家芯片放进了同一个仓库,但各后端独立实现从 Triton IR 到硬件 IR 的降级逻辑,编译优化 Pass 在后端之间大量重复——每新增一家芯片,降级逻辑要从头写;一个后端改进了访存优化,其他后端也用不上。而FLIR(FlagTree IR)在 Triton IR 与各芯片硬件 IR 之间插入了一层公共中间表示。引入 FLIR 后:
-
新芯片接入更快——只需实现从 FLIR 到自身硬件 IR 的降级,不必从 Triton IR 全程重写
-
优化多芯共享——FLIR 层面的 Pass 所有接入后端都能用
-
多家芯片厂商可以在 FLIR 层面联合贡献代码
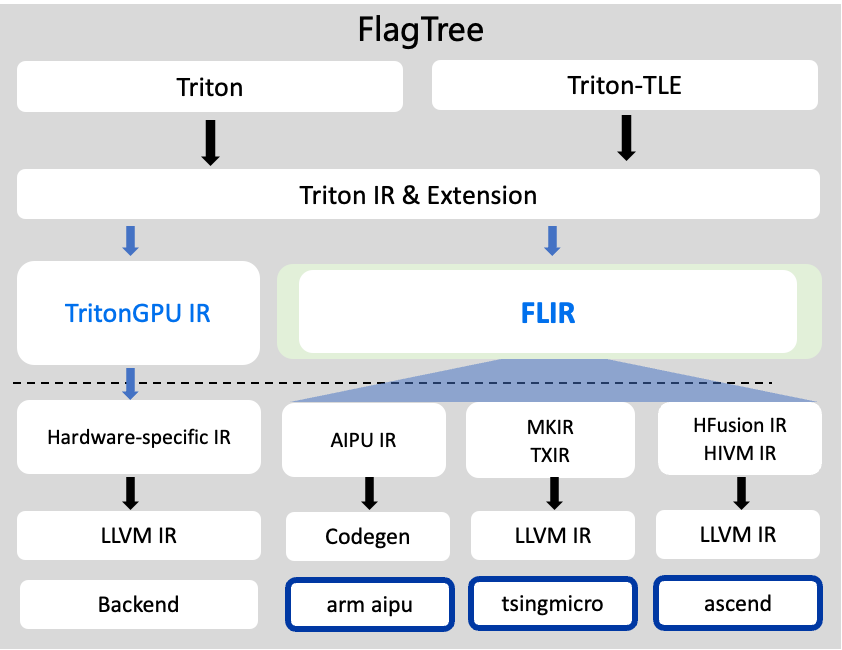 图3、FlagTree 编译降级全景:Triton IR 经 FLIR 公共中间层分发至多芯片后端
图3、FlagTree 编译降级全景:Triton IR 经 FLIR 公共中间层分发至多芯片后端
4.2 FLIR 做了什么
FLIR 将 Triton IR 的指针式访存和 tensor 级计算,降级为基于 memref 和 linalg dialect 的线性代数表示。以一个最简单的向量加法 kernel 示例,来说明Triton IR 中的访存和计算:
// Triton IR: 指针式访存 + tensor 级计算 tt.func @kernel(%arg0: !tt.ptr<f32>, %arg1: !tt.ptr<f32>) { %pid = tt.get_program_id x : i32 %range = tt.make_range {start=0, end=1024} : tensor<1024xi32> %off = arith.addi %pid_splat, %range : tensor<1024xi32> %ptr0 = tt.addptr %arg0_splat, %off // 指针计算 %x = tt.load %ptr0, %mask // 带 mask 的指针式 load %ptr1 = tt.addptr %arg1_splat, %off %y = tt.load %ptr1, %mask %z = arith.addf %x, %y : tensor<1024xf32> // tensor 级加法 tt.store %out_ptr, %z, %mask }FLIR 降级后变为:
// FLIR: memref 式访存 + linalg 线性代数计算 func.func @kernel(%arg0: memref<*xf32>, %arg1: memref<*xf32>, %num_programs: i32, %pid: i32) { // 指针分析 → 结构化 memref %src0 = memref.reinterpret_cast %arg0 to offset: [%pid_offset], sizes: [1024], strides: [1] %src1 = memref.reinterpret_cast %arg1 to offset: [%pid_offset], sizes: [1024], strides: [1] // memref.copy 取代 tt.load memref.copy %src0, %buf0 memref.copy %src1, %buf1 %x = bufferization.to_tensor %buf0 %y = bufferization.to_tensor %buf1 // linalg.generic 取代 arith.addf (tensor) %z = linalg.generic { indexing_maps = [...], iterator_types = ["parallel"] } ins(%x, %y) outs(%out) { ^bb0(%a: f32, %b: f32, %c: f32): %sum = arith.addf %a, %b : f32 linalg.yield %sum } bufferization.materialize_in_destination %z in writable %dst }降级后的变化:
-
函数签名从
tt.func(tt.ptr)变为func.func(memref, num_programs, pid)——后端不再需要处理 Triton 特有的指针语义 -
指针计算(
tt.addptr+tt.make_range+arith.muli)被分析为memref.reinterpret_cast的 offset/size/stride 参数——这是 FLIR 指针分析(PtrAnalysis)做的事 -
tensor 级的
arith.addf变为linalg.generic——标准 MLIR 的线性代数表示,方便各后端接入
4.3 降级的三个层面
FLIR 的降级工作按优先级分为三层:
结构化访存(优化重点,复用度最高):将 Triton 的指针式 load/store 降级为 memref 式的结构化访存。流程包括基址/偏移/步长提取、线性与结构化分析、轴连续性标记、交错访存连续化、策略选择(水平拼接/垂直堆叠/跨边界处理)。
非结构化访存(收敛至有限路径):对无法结构化表示的访存(间接索引、scatter/gather),提供三种降级策略:
-
部分向量化(
tensor.extract_slice/tensor.insert_slice) -
完全标量化(
tensor.extract/tensor.insert) -
linalg 路径(
linalg.generic+affine.load)
张量计算(分类后端特化):将 tensor 级 arith 转为 linalg,为不同后端提供多套方案。这里的难点在于多输出规约(Multi-payloads Reduction) 的初值选择--用首元素做初值,可能因 padding引入错误值;让编译器静态推导初值,则算法复杂且通用性差。
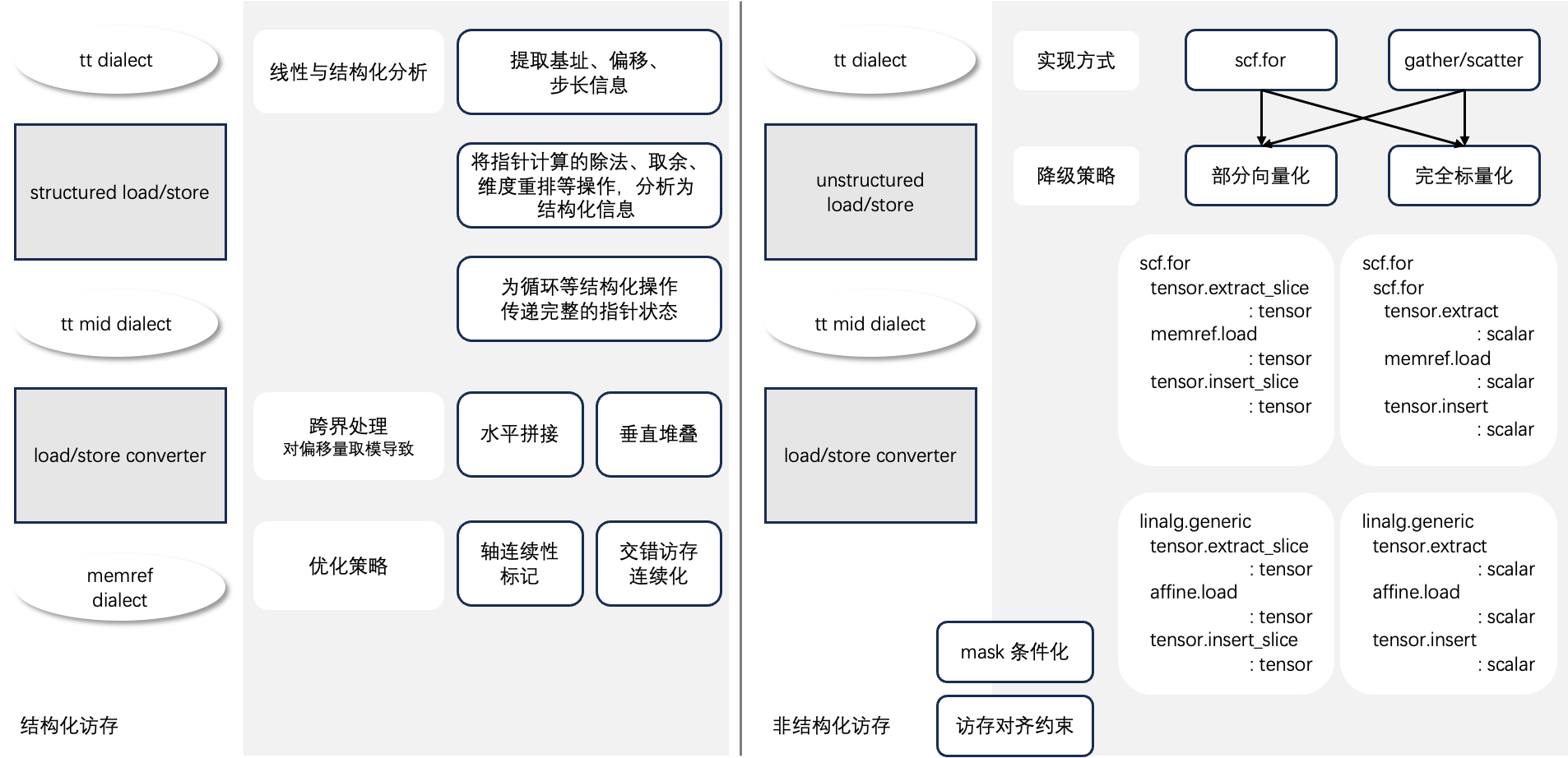
图4、FLIR 访存降级双路径对照解析
4.4 跨后端复用
FLIR 当前已接入昇腾、安谋科技 AIPU、清微智能三个后端。Pass 的复用情况反映了 FLIR 的实际价值:
三个后端共享的 Pass:TritonToStructured(结构化访存分析与转换)和 TritonToUnstructured(非结构化访存降级),这两个是工作量最大的 Pass,一次实现三家受益。其中昇腾使用 Incubated 版本,包含更精细的指针分析和标注注入。
AIPU 和清微共享的 Pass:StructuredToMemref、TritonArithToLinalg、TritonPtrToMemref、UnstructuredToMemref——从 FLIR 到 memref/linalg 的转换逻辑。
昇腾专有:DiscreteMaskAccessConversion、TritonToAnnotation、TritonToHIVM/HFusion/LLVM——华为 NPU 的硬件语义适配。
清微智能专有:UnstructuredToMK、TritonPtrToAddress——可重构处理器的特有降级。
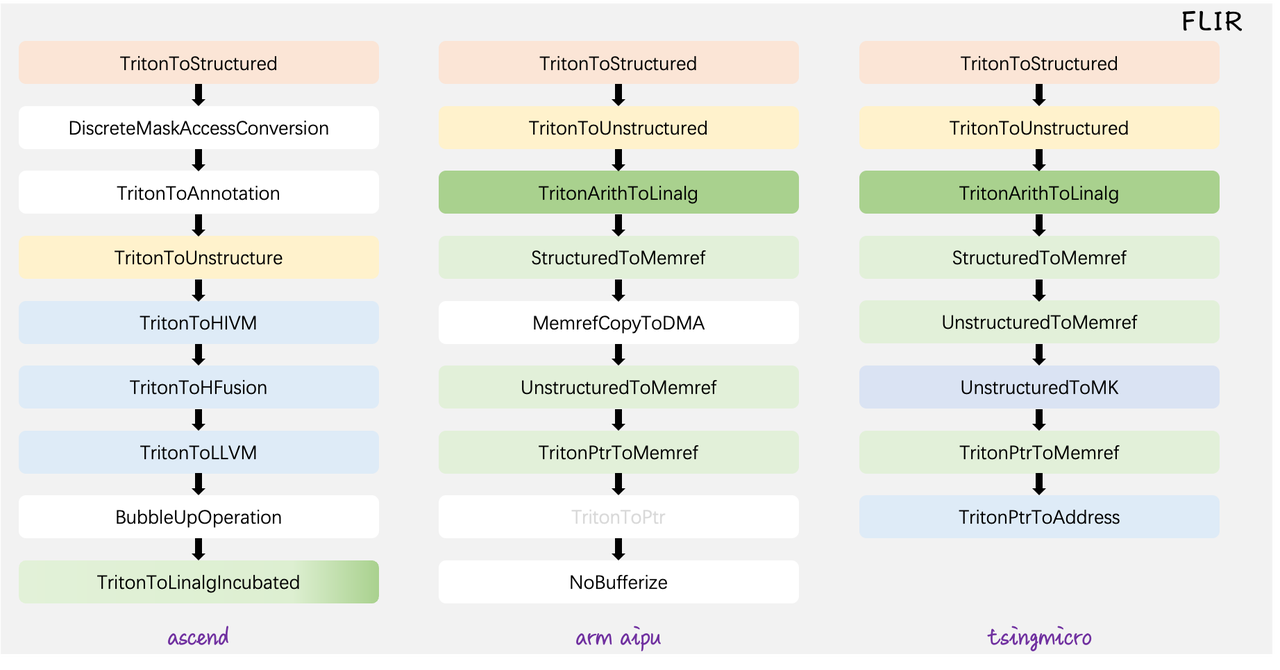
图5、FLIR 跨后端 Pass 复用:三条编译管线的共享与特化
以昇腾后端为例,FLIR 在编译管线中的实际编排如下(摘自 FlagTree 昇腾后端的 compiler.py):
def ttir_to_linalg(mod, metadata, opt): pm = ir.pass_manager(mod.context) # FLIR 共享 Pass ascend.passes.ttir.add_triton_to_structure_incubated(pm, ...) ascend.passes.ttir.add_discrete_mask_access_conversion(pm, ...) ascend.passes.ttir.add_triton_to_annotation(pm) ascend.passes.ttir.add_triton_to_unstructure_incubated(pm, ...) # 昇腾专有 Pass ascend.passes.ttir.add_triton_to_hivm(pm) ascend.passes.ttir.add_triton_to_hfusion(pm) ascend.passes.ttir.add_triton_to_llvm(pm) ascend.passes.ttir.add_bubble_up_operation(pm) # 再次调用结构化分析 + linalg 降级 ascend.passes.ttir.add_triton_to_structure_incubated(pm, ...) ascend.passes.ttir.add_triton_to_linalg_incubated(pm, ...) pm.run(mod)可以看到,FLIR 的共享 Pass(triton_to_structure_incubated、discrete_mask_access_conversion、triton_to_unstructure_incubated)和昇腾的专有 Pass(triton_to_hivm、triton_to_hfusion)交替编排在同一条管线中。新增一个后端时,共享 Pass 直接复用,只需实现专有部分。
五、FLIR 对 TLE 的编译支撑
TLE(Triton Language Extension)是 FlagTree 对 Triton 的语言扩展,[导读]Triton-TLE 新语言赋能 MoE 算子优化,在 FlagOS 2.0 中关村论坛发布时已经推出。
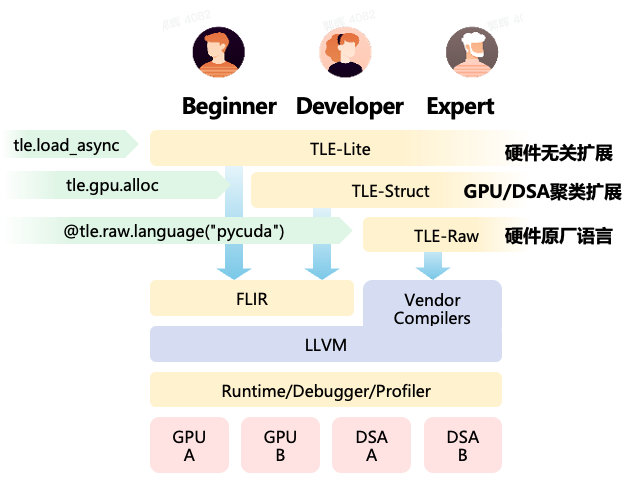
图6、TLE三层扩展能力
TLE 提供三个层次的扩展能力:TLE-Lite(硬件无关扩展,如 tle.load_async)、TLE-Struct(GPU/DSA 聚类扩展,如 tle.gpu.alloc)、TLE-Raw(硬件原厂语言嵌入),让开发者在保持 Tile 编程易用性的同时显著增强对芯片架构的感知能力。这次报告重点不是 TLE 语言本身,而是 FLIR 如何支撑 TLE 在多架构芯片上的编译降级。
5.1 降级路径
TLE 代码经 AST 解析后生成 TLE IR,其中 tle.dsa 系列原语先降级为 dsa.core → dsa.semantic 表示,再经由 FLIR 的 TleToLinalg Pass 转换为 memref/hivm 表示。具体规则包括:
-
二元算术算子(如
tle.dsa.add):注册转换规则,降级为 HIVM 方言的向量算子 -
数据搬运(
tle.dsa.copy):根据存储层级选择不同降级路径——全局内存(GM)与片上统一缓冲区(UB)之间降级为memref::CopyOp,GM 到 L1 缓冲区降级为hivm::ND2NZOp -
迭代器扩展:在原有
tl.range基础上新增tle.dsa.pipeline(流水迭代器)和tle.dsa.parallel(并行迭代器),其中tle.dsa.parallel会被标记为hivm.parallel_loop,指导 pipe 同步分析,标记循环迭代间无数据依赖,消除非必要同步
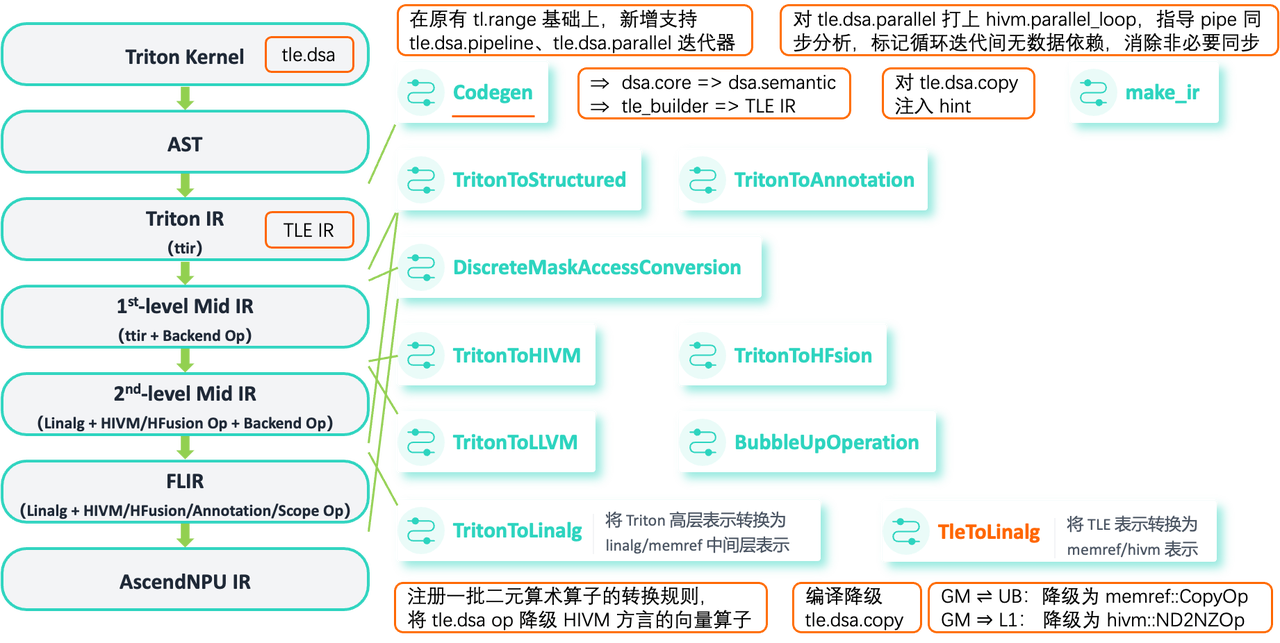 图7、支持语言扩展TLE编译降级案例
图7、支持语言扩展TLE编译降级案例
5.2 性能验证
FlagTree 与华为、清微智能合作,分别选取 GPU、DSA、可重构计算三大架构进行 TLE 支持和验证。目前 TLE 共支持 31 种原语,FLIR 支撑其中华为昇腾 15 个和清微智能 3 个 tle.dsa 原语的编译降级。实测性能数据:
|
算子 |
芯片 |
性能提升 |
|---|---|---|
|
SparseMLA |
昇腾 |
相比 Triton 实现提升 82 倍,达到原生 Ascend C 性能的 1.24 倍 |
|
RMSNorm+RoPE |
昇腾 |
相比 Triton 实现提升 2.37 倍,与原生 Ascend C 持平 |
|
CausalConv1D Fwd |
昇腾 |
相比 Triton 实现提升 63 倍 |
|
CausalConv1D Update |
昇腾 |
相比 Triton 实现提升 6 倍 |
|
MoeAlignBlockSize |
英伟达 |
相比 Triton 实现提升 25%~200%,最高达 CUDA 实现的 4 倍 |
|
TopK |
英伟达 |
相比 Triton 实现提升 1.6 倍 |
|
SparseMLA |
英伟达 |
相比 Triton 实现提升 27% |
|
GEMM |
清微 |
相比 Triton 实现提升 1.5 倍 |
昇腾上的性能提升尤为显著——SparseMLA 提升 82 倍、CausalConv1D Fwd 提升 63 倍——这些数字反映的不是 TLE 有多快,而是原生 Triton 在非 GPGPU 架构上对片上存储层级的访存模式表达不足,TLE + FLIR 的编译降级弥补了这一缺陷。
六、生态互通:华为、清微智能等与FlagOS的联合共建
FLIR 的工程价值不仅在于技术架构,更在于它提供了多方联合贡献的公共层。FLIR 采用了开源共建模式,由FlagOS开源社区牵头,华为、清微智能、安谋科技、中科加禾、先进编译实验室等联合参与贡献。
各方的协作体现在 FLIR 的 Pass 复用结构中:
公共层共享:TritonToStructured(结构化访存分析与转换)和 TritonToUnstructured(非结构化访存降级)由 FLIR 公共层提供,华为昇腾、安谋科技 AIPU、清微智能三个后端共享复用。这两个 Pass 是工作量最大的编译降级组件,一次实现三家受益。
华为昇腾深度参与:昇腾后端贡献了 DiscreteMaskAccessConversion(离散 mask 的数据流转换)、TritonToAnnotation(语义标注)、TritonToHIVM(核间同步降级)、TritonToHFusion(Cube Core 算子生成)等多个专有 Pass,同时使用 FLIR 公共层的 Incubated 版本(包含更精细的指针分析和标注注入)。在 TLE 支撑方面,昇腾后端已实现 15 个 tle.dsa 原语的编译降级。
清微智能可重构处理器接入:清微智能贡献了 UnstructuredToMK 和 TritonPtrToAddress 等面向可重构处理器的专有 Pass,同时复用 FLIR 公共层的结构化与非结构化访存分析。在 TLE 支撑方面已实现 3 个原语的编译降级,GEMM 算子性能达到原生实现的 1.5 倍。
安谋科技 AIPU 共建:安谋科技 AIPU 后端与清微智能共享 StructuredToMemref、TritonArithToLinalg、TritonPtrToMemref、UnstructuredToMemref 等从 FLIR 到 memref/linalg 的转换逻辑,并贡献了 MemrefCopyToDMA(DMA 降级)和 NoBufferize 等专有 Pass。
这种"公共层共享 + 专有 Pass 各建"的模式,使得新芯片接入 FLIR 时只需实现硬件专有的最后一段降级,公共层的编译优化直接复用。一家优化了结构化访存分析,所有接入后端受益。
七、Roadmap与开源共建
最后给感兴趣的开发者一起分享下FlagTree 和 FLIR 的当前进展与下一步目标:
|
维度 |
已达成 |
下一步 |
|---|---|---|
|
后端覆盖 |
3 款芯片/IP 后端(昇腾、安谋科技 AIPU、清微智能) |
覆盖更多架构类型,接入更多芯片后端 |
|
编译完备度 |
70+ Triton 原语降级,100+ 大模型算子精确度校验 |
200+ 算子校验,覆盖全部 Triton 原语 |
|
复用率 |
结构化/非结构化访存与 linalg 降级跨后端复用 |
Pass 微粒化拆分,形成可复用标准组件 |
|
TLE 支撑 |
昇腾和清微智能共 18 个 tle.dsa 原语编译降级 |
随 TLE 语言扩展持续增加原语支撑 |
FLIR 的长期目标是成为多元 AI 芯片编译生态的公共基础设施——不属于任何一家芯片厂商,而是由FlagOS开源社区成员共同维护的公共中间层。一家贡献了结构化访存优化,所有接入后端受益;一家接入了新架构类型,其他后端的开发者也能参考其实现路径。
我们欢迎更多芯片厂商、编译器团队、高校实验室和广大开发者一起参与 FlagTree 和 FLIR 的共建:
-
芯片厂商:接入 FLIR 后端,复用公共层 Pass,降低 Triton 生态适配成本
-
编译器开发者:贡献 FLIR 公共 Pass(结构化访存、张量计算降级等),优化一次惠及多芯片
-
算子开发者:基于 Triton + TLE 编写算子,通过 FlagTree 编译到 10+ 芯片,不再为每家芯片维护独立实现
开源仓库:
-
FlagOS 官网:https://flagos.io
-
FlagTree(统一编译器):https://github.com/flagos-ai/FlagTree
-
FLIR(公共编译中间表示层):https://github.com/flagos-ai/flir
-
FlagGems(通用算子库):https://github.com/flagos-ai/FlagGems

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)