AI会做题,但不会干活?问题出在这里
AI会做题,但不会干活?问题出在这里
你有没有发现一个奇怪的现象,AI 能告诉你 Kubernetes 的架构细节,能解释 SQL 的发展历史,甚至能回答非洲燕子和欧洲燕子的飞行速度有什么区别。
但你让它帮你生成一份符合公司规范的财务报告,它就开始瞎编了。
这不是 AI 不够聪明,而是它缺了一样东西,程序性知识。
会背书不等于会干活
大语言模型就像一个博学的学霸,你问它任何知识点都能答上来。但真让它按照公司的 47 步流程生成一份合规的财务报告,它就傻眼了。
这时候只有两个选择。
要么你每次都把 47 个步骤一步步输入给它,累死你。要么就让它自己猜,然后你收到一份完全不符合规范的报告,还得重新来过。
这就是为什么很多人觉得 AI 看起来很强,实际用起来却不靠谱。不是它不行,是它根本不知道你们公司的工作流程是怎么运转的。
技能文件就是用来解决这个问题的。
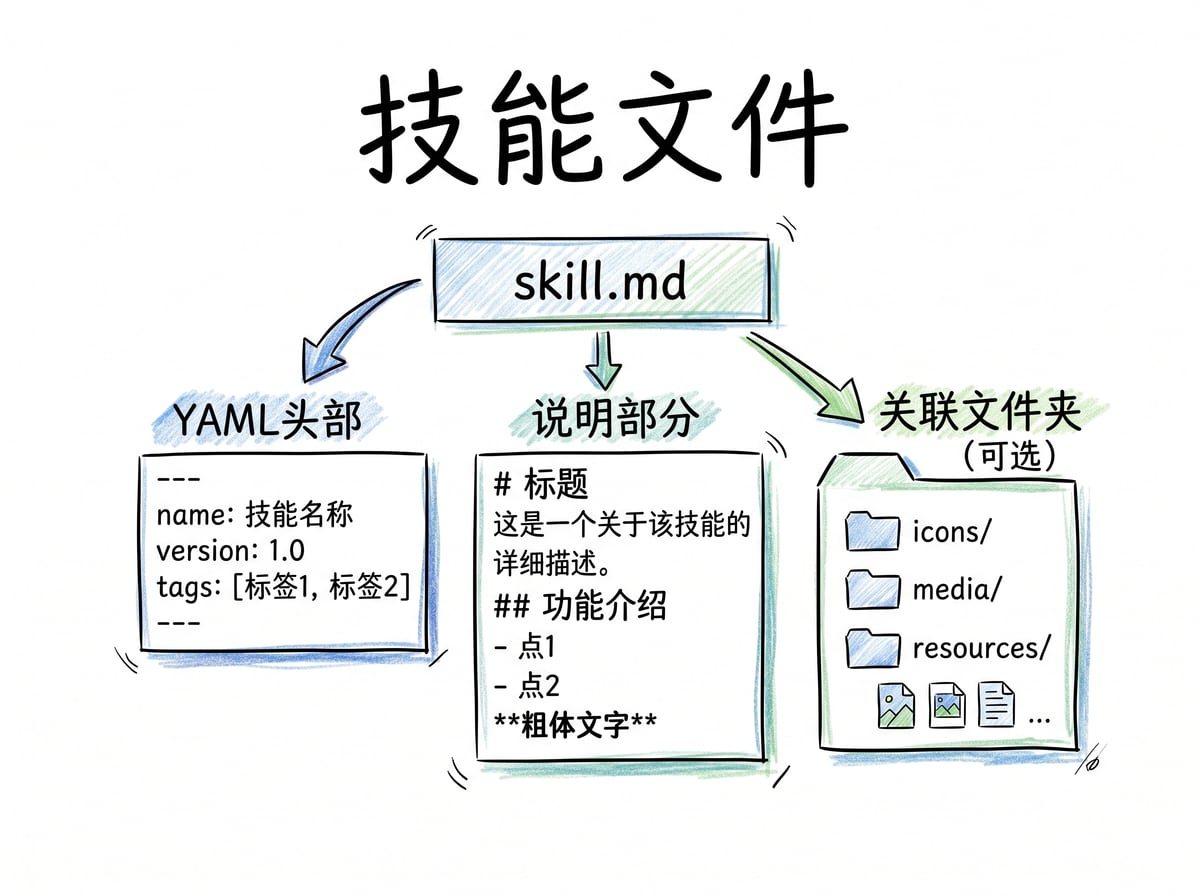
一个文件就能教会 AI 干活
技能的格式简单到让人意外,就是一个 skill.md 文件放在一个文件夹里。
文件最上面是一段 YAML 格式的头部信息,里面必须包含两个东西,名称和描述。
名称就是给这个技能起个名字,比如 PDF 生成器。描述更重要,它告诉 AI 什么时候该用这个技能,比如“当用户要求提取 PDF 时使用此技能”。
这个描述就是触发条件,AI 会根据这个判断要不要调用这个技能。
头部信息下面就是具体的操作说明,一步步的工作流程、规则、输入输出的例子,所有 AI 需要知道的东西都写在这里,用的就是普通的 Markdown 格式。
文件夹里还可以放三个可选目录。scripts 目录放可执行的代码,JavaScript、Python 或者 bash 脚本都行。references 目录放额外的参考文档,AI 需要的时候会去读。assets 目录放静态资源,比如模板文件和数据文件。
就这么简单,一个技能文件就做好了。
100 个技能怎么不把 AI 撑爆
问题来了,如果一个 AI 代理装了 100 个技能,启动的时候把所有技能都加载进去,上下文窗口不就爆了吗?
技能系统用了一个聪明的办法,叫渐进式披露,分三层加载。
第一层是启动时只加载元数据,也就是每个技能的名称和描述。100 个技能也就几百个 Token,根本不会占满上下文窗口。这相当于给 AI 一个技能目录。
第二层是当 AI 遇到一个任务,发现某个技能的描述跟这个任务匹配上了,它才会把这个技能的完整说明读进来。这时候 AI 才知道具体该怎么做。
第三层是那些可选的文件夹,脚本、参考文档、资源文件,只有在真正需要的时候才会加载。
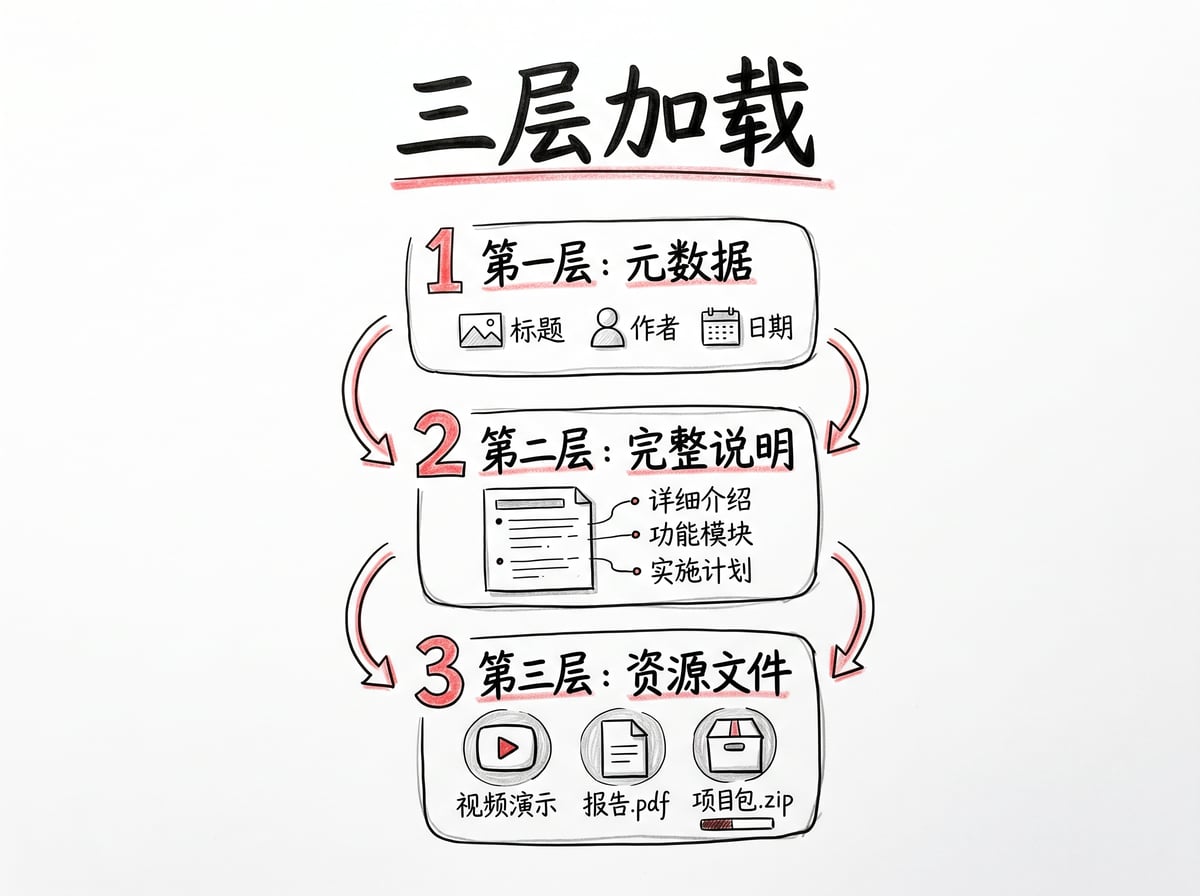
整个过程就像是 AI 先看了一眼目录,知道自己能做什么。遇到任务了再翻到对应的章节,看详细步骤。需要用到工具了再去拿工具。
这样既不会浪费资源,又能随时调用需要的技能。
技能和其他知识有什么不同
给 AI 提供知识的方式有好几种,技能只是其中一种,它们各管各的事。
MCP,也就是模型上下文协议,它给 AI 提供的是工具访问能力。AI 可以通过 MCP 调用外部 API,跟各种服务交互。但 MCP 只告诉 AI 能做什么,不告诉它什么时候做、怎么做。
RAG,检索增强生成,它处理的是事实性知识。需要查资料的时候,RAG 会从知识库里把相关内容拉出来。但 RAG 只是参考资料,它不会教 AI 怎么完成一个任务。
微调是把知识直接烧进模型的权重里,这是永久性的改变。但微调成本高,而且模型一更新,微调就得重新来。
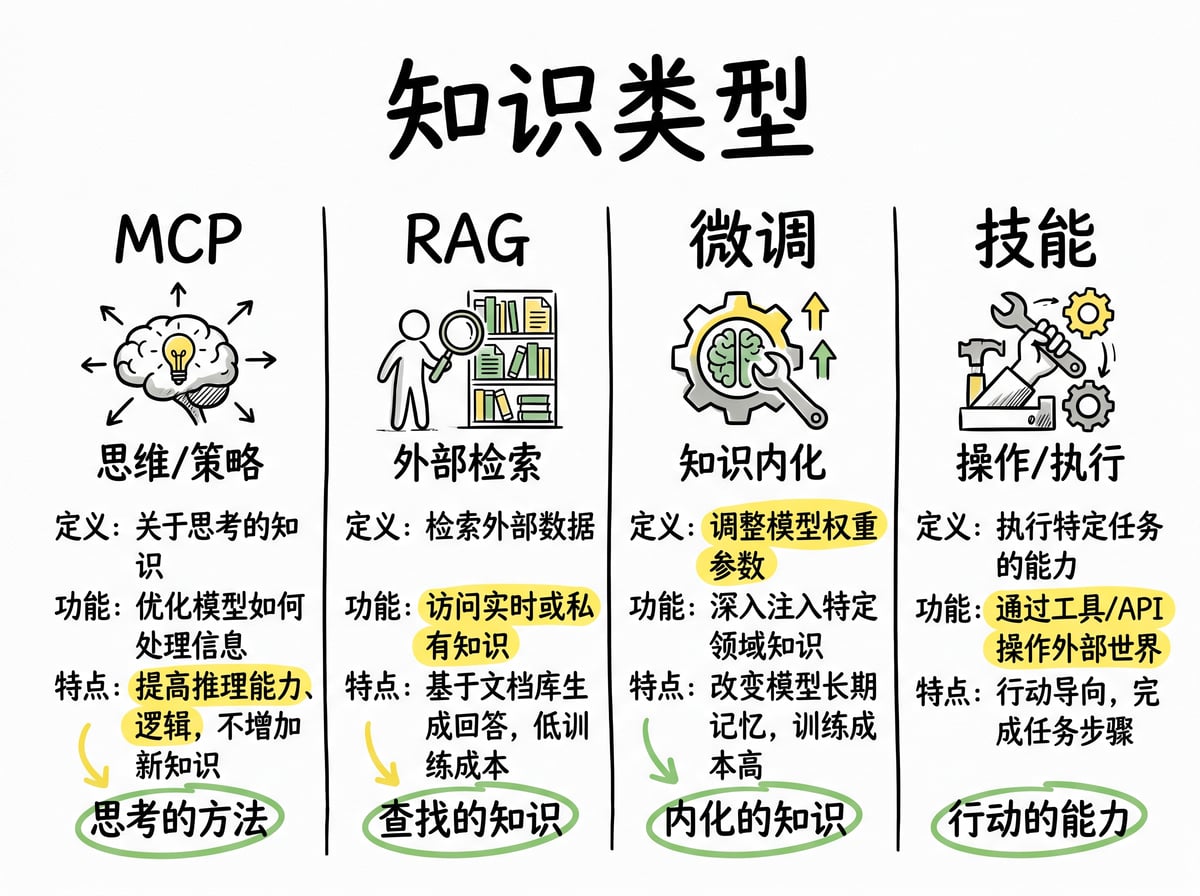
技能处理的是程序性知识,也就是怎么做事、按什么顺序做、需要什么判断。而且因为技能就是文件,可以版本控制,随时更新,在不同平台之间迁移也很方便。
实际使用中,技能经常会跟其他形式的知识配合。比如 MCP 提供调用外部功能的能力,技能提供什么时候调用、怎么调用的判断。
这就像人的三种记忆
认知科学里有个说法,人类有三种不同的记忆。
语义记忆是事实,比如罗马是意大利的首都。
情景记忆是经历,比如我去年夏天去了罗马,确实去了,那地方真不错。
程序记忆是技能,比如怎么在罗马街头骑小摩托还能活着回来讲这个故事,我也做到了,差点没命。
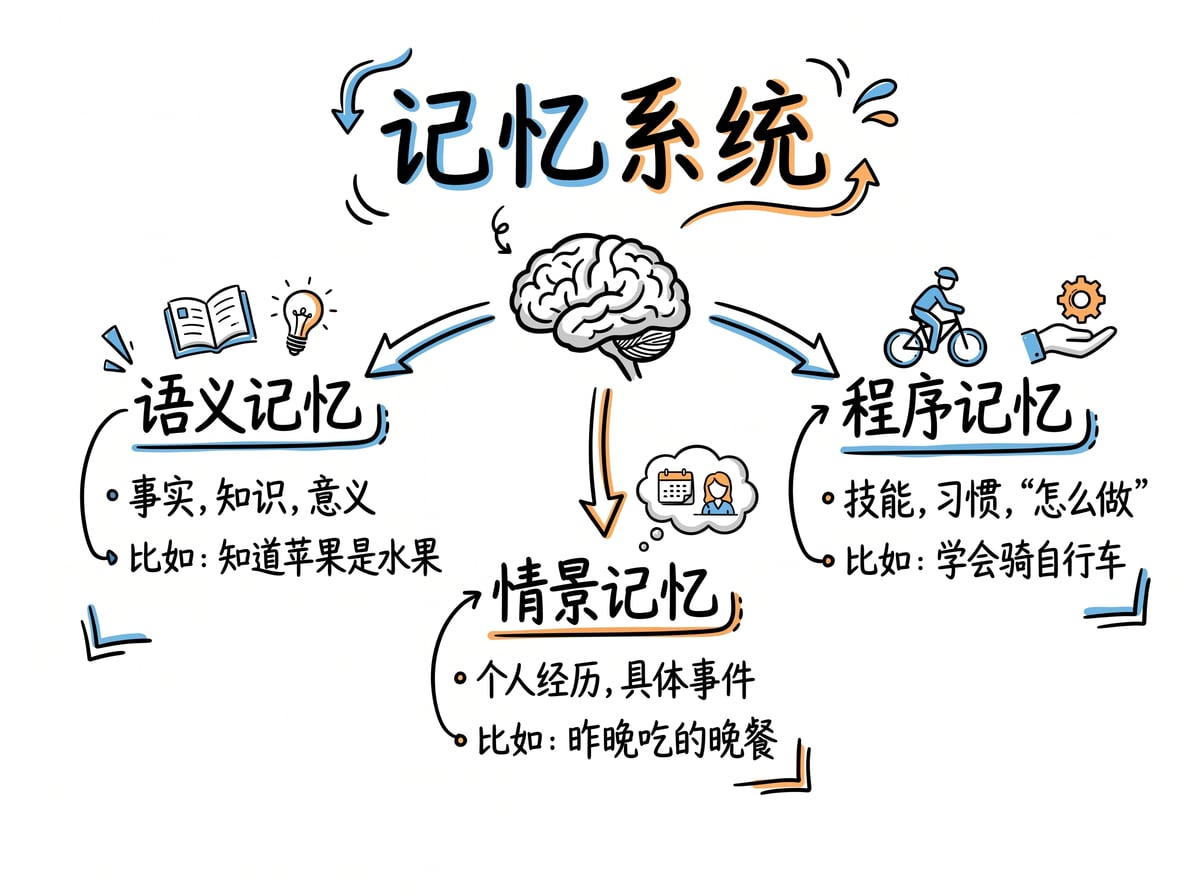
AI 代理的架构也开始往这个方向发展了。
语义记忆对应的是 RAG 和知识库,负责事实查询。
情景记忆对应的是对话日志和交互历史,记录 AI 跟用户的互动。
程序记忆对应的就是技能文件,教 AI 怎么做事。
这种对应关系不是巧合,而是 AI 系统在模仿人类认知的结构。
但有一件事必须提醒你
技能文件可以包含可执行脚本,这些脚本能访问文件系统、环境变量、API 密钥。这让技能很强大,但也带来了风险。
当 AI 运行这些脚本的时候,通常是在你的本地机器上执行命令。审计发现,公开的技能文件里经常藏着各种坏东西,提示注入、工具投毒、隐藏的恶意软件,开源生态系统里常见的那些问题,技能文件里一个都不少。
所以安装技能的时候,要像对待任何软件依赖一样谨慎。先看看它到底做了什么,确认没问题再在本地机器上用。
别因为一个技能文件把自己的系统搞崩了。
一个开放的标准
skill.md 这个格式是开放标准,发布在 agentskills.io 上,用的是 Apache 2.0 许可证。
Claude Code、OpenAI Codex 和很多其他 AI 平台都采用了这个标准。这意味着你为一个平台写的技能,可以直接在其他支持这个标准的平台上用。
不用担心被某个平台锁死,技能文件是通用的。
所以现在的情况是,AI 已经知道非洲燕子和欧洲燕子的飞行速度了,现在它还能学会你定义的任何可重复任务。
从会背书到会干活,就差一个技能文件。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)