大模型去智能化实践:从复杂到极简:剥离复杂能力与低端设备、隐私场景适配.154
一、大模型去智能化
1 核心概念定义
大模型去智能化,并非消除模型的智能推理能力,而是对主流模型做定向能力裁剪、结构精简、参数压缩、计算简化,剥离非必要的复杂能力,如多轮长对话、多模态理解、超长文本生成、专业领域深度推理、联网检索等,保留核心基础能力,如短文本问答、简单指令执行、关键词提取、基础语义理解,最终得到体积极小、计算量极低、可在低端设备本地运行、数据完全不泄露的极简版大模型。
传统大模型如同全能超级计算机,具备海量知识、复杂逻辑、多场景适配能力,但体积庞大、算力要求极高,必须依赖云端服务器运行;而去智能化后的极简大模型,如同专用计算器,放弃了无关的复杂功能,只保留核心刚需能力,体积压缩至几十MB 甚至几MB,能在单片机、老旧手机、嵌入式设备、本地电脑等无高端算力的设备上独立运行,且所有数据处理都在本地完成,不联网、不上传,彻底解决隐私泄露问题。
去智能化的核心关键词:能力定向剥离、结构轻量化、参数低量化、本地推理、隐私原生、低端设备适配。它不是模型的退化,而是场景化的精准优化,是大模型从达到专用极简的关键路径。

2. 核心应用场景
2.1 低端设备适配
当前主流大模型(如 Llama 3、Qwen、GPT 系列)参数量普遍达到7B、13B 甚至70B,运行需要高端GPU、大内存,而嵌入式设备、老旧安卓、iOS 设备、工业单片机、物联网设备等无独立算力的硬件,完全无法运行。
去智能化后的极简模型,参数量可压缩至百万级、千万级,内存占用不足100MB,可直接在这些低端设备上本地运行,实现离线智能交互。
2.2 隐私敏感场景
医疗数据、金融信息、个人隐私、企业内部机密等场景,绝对不允许数据上传云端。传统大模型需要将用户输入发送到云端服务器处理,存在数据泄露、被窃取的风险;
而去智能化极简模型全程本地推理,用户数据不离开设备,从根源上实现隐私保护,适用于私人笔记、本地隐私问答、嵌入式隐私设备等场景。
2.3 低延迟刚需场景
云端大模型需要网络传输、服务器调度,存在延迟,而本地极简模型无网络依赖,推理速度达到毫秒级,适用于智能硬件实时响应、本地指令快速执行等场景。
3. 去智能化与轻量化的区别
首先我们会很纳闷,大家应该和我刚开始一样,会将去智能化与模型量化、剪枝等传统轻量化技术混淆,二者核心差异在于:
- 传统轻量化:不改变模型核心能力,仅通过技术手段压缩体积、降低计算量,模型依然保留所有复杂能力,压缩后仍需一定算力,无法适配极致低端设备;
- 去智能化:先剥离非核心能力,再做轻量化优化,从“功能设计”层面就放弃冗余能力,从根源上降低模型复杂度,是能力 + 结构的双重精简,适配极致轻量化场景。
4. 去智能化的意义
- 大模型普惠化:打破大模型对高端算力的依赖,让智能能力覆盖所有低端硬件,实现皆可本地智能适配;
- 隐私安全升级:构建隐私原生的智能方案,解决云端大模型的隐私痛点,拓展大模型在敏感领域的应用;
- 成本极致降低:无需云端服务器、无需网络带宽,设备本地即可运行,大幅降低企业和个人的使用成本;
- 技术落地简化:让大模型从云端黑盒变成本地可控组件,降低嵌入式、物联网等领域的智能开发门槛。
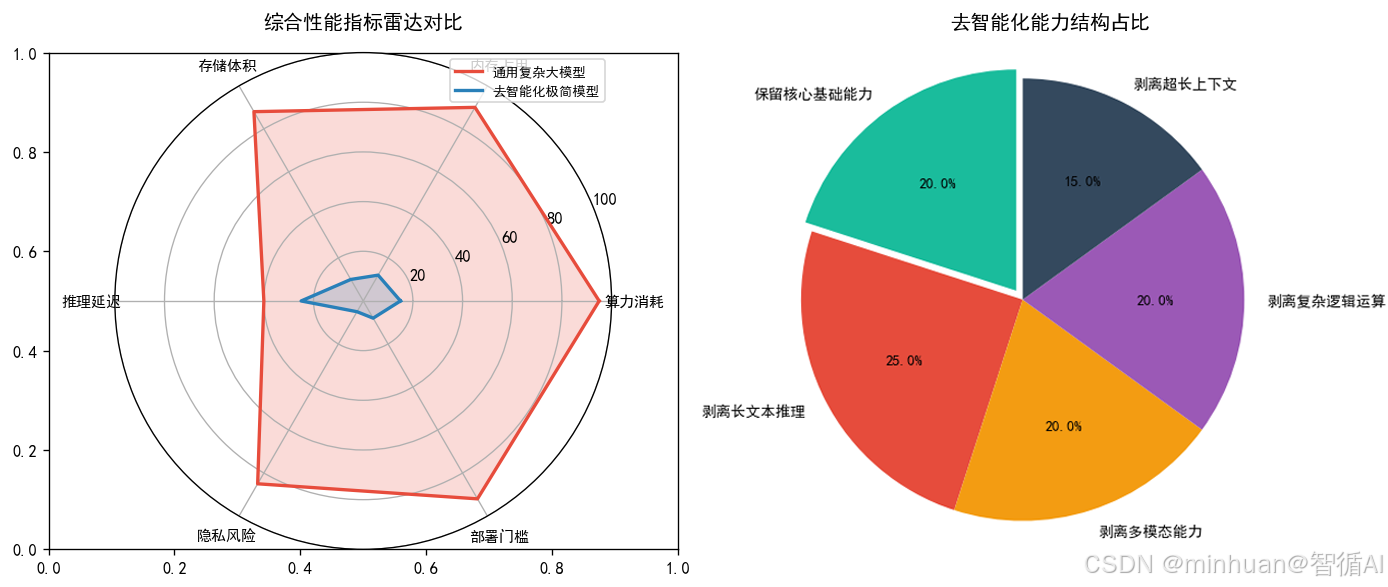
二、简化大模型理论基础
1. 大模型基础原理回顾
要理解“去智能化”,首先要掌握大模型的核心基础:大语言模型本质是基于Transformer架构的神经网络,通过海量文本数据训练,学习语言的语义、语法、逻辑规律,最终实现文本生成、语义理解等能力。
大模型构成的核心组件:
- 1. Transformer 架构:大模型的基础骨架,包含编码器(Encoder)和解码器(Decoder),核心是自注意力机制(Self-Attention),让模型能理解文本中词语之间的关联;
- 2. 参数量:模型中可学习的权重参数数量,参数量越大,模型能学习的知识和能力越复杂,但体积、算力要求也越高;
- 3. 训练与推理:训练是模型学习数据规律的过程,推理是模型根据输入生成输出的过程,极简大模型重点优化推理过程;
- 4. 上下文窗口:模型能处理的最大文本长度,长上下文是复杂能力的核心,去智能化时会大幅缩小上下文窗口,降低计算量。
2. 去智能化核心基础
2.1 能力剥离原则
- 刚需保留,冗余剔除:提前定义模型的核心使用场景,只保留场景必需的能力,所有非必需能力直接从模型结构、训练数据中剔除。
- 例如做本地隐私关键词提取模型,只保留“关键词识别” 能力,剥离对话、生成、推理等所有能力。
2.2 模型结构精简
Transformer 架构是大模型计算量的核心来源,去智能化时会做结构裁剪:
- 减少 Transformer 层数量,通常从几十层减至 2-4 层;
- 缩小注意力头数,从12头减至2头;
- 降低隐藏层维度,从768维减至128或64维。
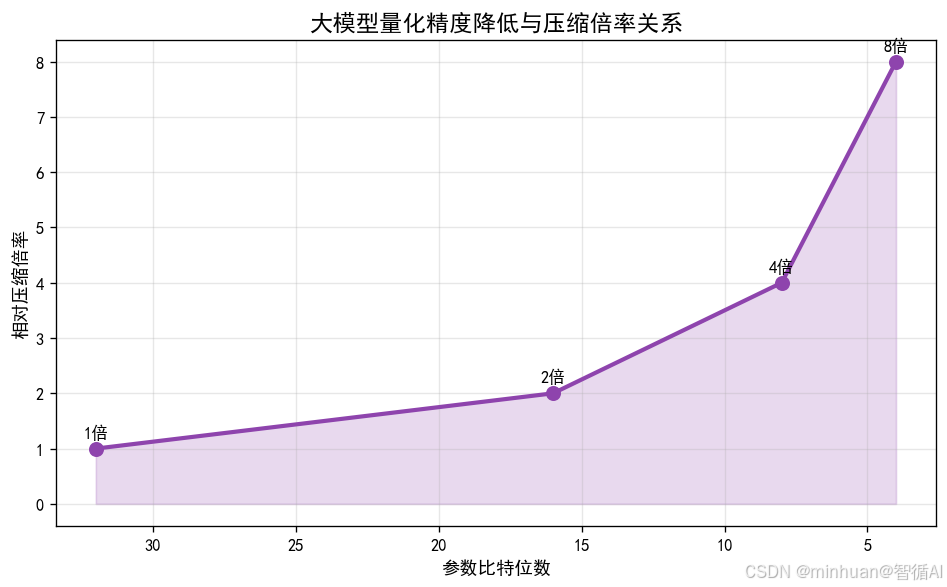
2.3 低比特量化
将模型参数从32位浮点数(FP32)压缩为4位、2位整数(INT4/INT2),体积压缩8-16倍,计算量大幅降低,且几乎不损失核心能力。
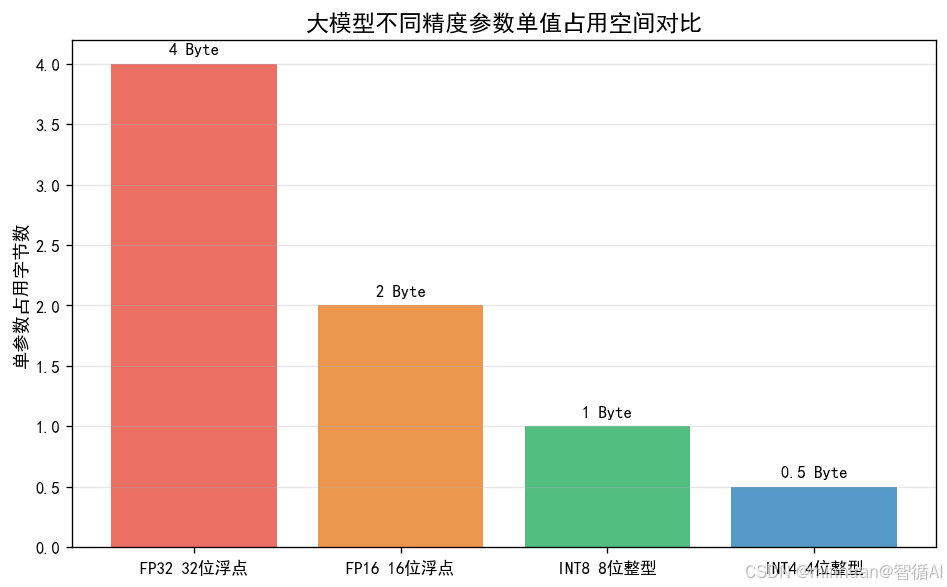
2.4 小参数量设计
极简大模型参数量控制在100万~1亿之间,传统大模型为70亿+,参数量越小,运行门槛越低。
3. 低端设备硬件基础
极简大模型适配的低端设备核心硬件指标:
- 内存:≤512MB,主流大模型需要≥16GB;
- 算力:无 GPU,仅 CPU 即可运行;
- 存储:≤100MB,主流大模型需要≥10GB;
- 无网络、无高端芯片,纯本地硬件。
三、去智能化执行流程

1. 场景定义与能力边界划定
去智能化的第一步是明确模型的使用场景和核心能力,这决定了后续所有技术方向。
执行细节:
- 1. 确定使用设备:低端嵌入式设备,如老旧手机或低配电脑;
- 2. 确定核心能力:仅保留1-2种核心能力,如短文本问答、关键词提取、简单指令分类;
- 3. 划定能力边界:明确禁止的能力,如长文本生成、多轮对话、专业推理;
- 4. 确定输入输出限制:输入文本≤50 字,输出文本≤20 字,上下文窗口≤64 词。
示例:最终定义场景→本地隐私短文本问答模型,核心能力:回答 10 字以内的简单问题,输入≤30 字,输出≤15 字,无联网、无长对话、无复杂推理。
2. 基础模型选型
由于模型训练成本极高,不从头训练大模型,选择开源超小参数量基础模型作为底座,再做去智能化改造:
- 首选:TinyBERT、DistilBERT、MiniGPT、Qwen极小版本的1.8B;
- 要求:基础参数量≤1亿,架构简单,支持轻量化改造。
3. 非核心能力剥离
- 1. 结构剥离:删除模型中用于长上下文、多轮对话、多模态的模块;
- 2. 数据剥离:训练数据只保留核心场景数据,删除所有无关数据,如专业知识、长文本数据;
- 3. 推理剥离:关闭模型的复杂推理模块,仅保留前向基础计算。
4. 轻量化优化(量化 + 剪枝)
- 结构化剪枝:删除模型中冗余的神经元、注意力头、网络层;
- 低比特量化:将 FP32 参数量化为 INT4,压缩模型体积;
- 算子简化:替换复杂计算算子为极简算子,降低CPU计算压力。
5. 本地推理引擎适配
针对低端设备,适配极简推理引擎:
- 首选引擎:ONNX Runtime、NCNN、MNN轻量级推理框架,支持 CPU 本地运行;
- 引擎优化:关闭所有冗余功能,仅保留模型前向推理功能。
6. 测试与验证
- 能力测试:验证核心功能是否正常;
- 硬件测试:验证在低端设备上的运行速度、内存占用;
- 隐私测试:验证数据是否本地处理,无联网、无泄露。
7. 部署落地
- 将优化后的极简模型打包为独立文件,部署到目标低端设备,实现离线本地运行。
四、模型简化的基础原理
1. 模型简化的核心工作逻辑
极简大模型的工作流程可以用“输入→精简计算→输出”概括,和传统大模型相比,去掉了所有复杂的中间计算环节:
- 文本编码:将用户输入的文字转换为数字向量,极简编码,仅保留语义核心特征;
- 浅层Transformer计算:仅通过2-4层极简Transformer层,做基础语义理解;
- 无复杂注意力:简化自注意力机制,仅计算核心词语关联,放弃全局长距离关联;
- 快速解码输出:直接生成极简结果,无复杂逻辑推理。
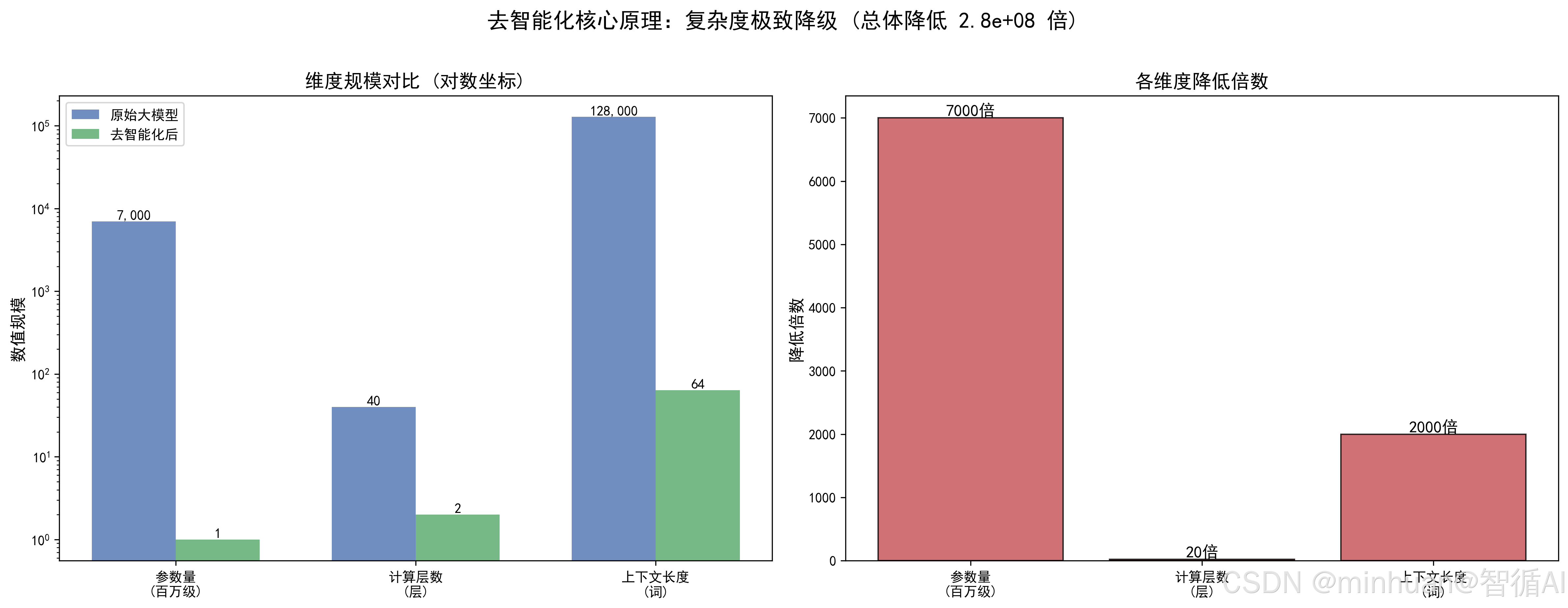
2. 去智能化的核心原理
核心原理就是复杂度降级,大模型的智能复杂度 =参数量 × 计算层数 × 上下文长度,去智能化就是通过降低这三个维度,实现复杂度极致降级:
- 参数量降级:70亿→100万,降低700倍;
- 计算层数降级:40层→2层,降低20倍;
- 上下文长度降级:128K→64词,降低2000倍;
- 最终整体复杂度降低2.8亿倍,完美适配低端设备。
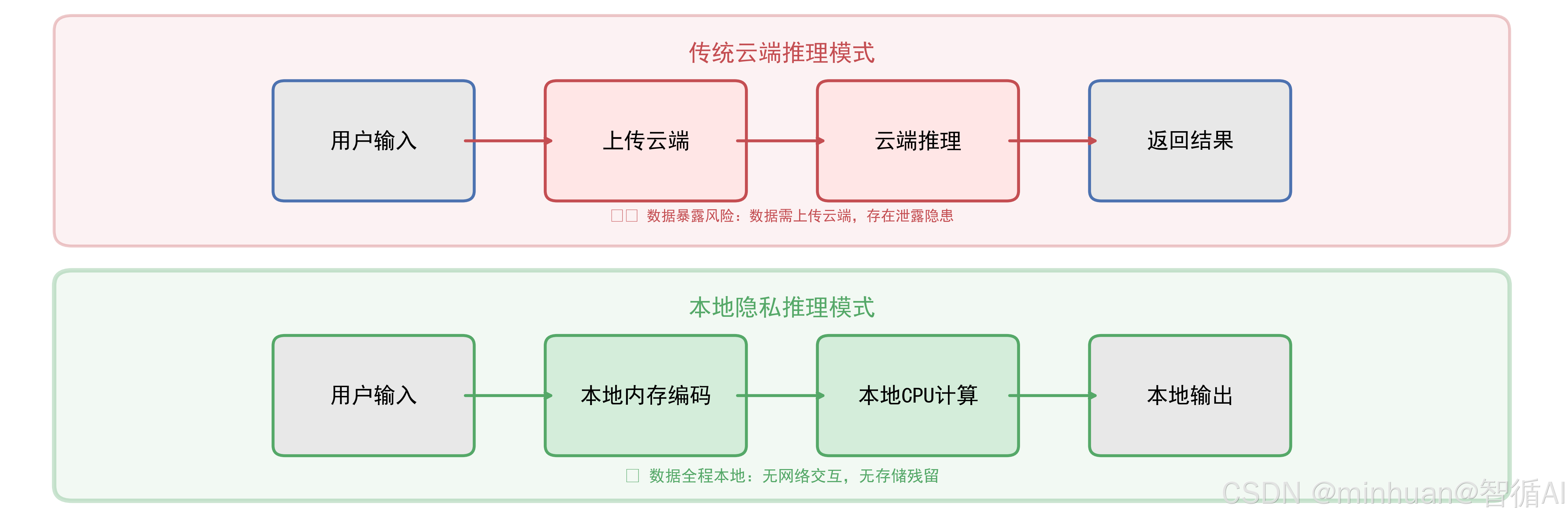
3. 本地隐私推理原理
- 传统大模型:用户输入→上传云端→云端推理→返回结果,会导致数据暴露的风险;
- 极简大模型:用户输入→本地内存编码→本地 CPU 计算→本地输出,数据全程都在本地,不离开设备;
- 核心:推理过程完全本地化,无数据交互,无存储残留。
4. 低比特量化原理
从以前我们反复探讨过的模型量化原理,今天也做个简单介绍,模型的所有权重、偏置等可学习参数,本质上全部由连续浮点数值、离散整型数值构成,也是模型存储、运算、占用硬件资源的核心载体。
主流通用大模型原生训练与推理,普遍采用FP32 32位单精度浮点数 作为参数存储格式,这是一种高精度数值格式,每一组参数固定占用4Byte字节存储空间,数值精度高、动态范围大,能够完整保留模型训练学习到的细微语义特征、权重差异与逻辑关联,保障通用大模型复杂推理、长文本理解、多场景泛化的高阶智能能力。
但超高精度的数值格式,会带来两个核心痛点:
- 一是存储体积臃肿,海量参数叠加后会占用数十 GB 甚至上百 GB 存储空间;
- 二是运算算力消耗极高,高精度浮点计算对 CPU、GPU 算力、运行内存要求严苛,无法在低端嵌入式设备、老旧终端、无独立显卡的轻量化硬件上运行。
而大模型量化技术,核心逻辑就是主动降低参数数值精度,将原生的32位高精度浮点数,映射压缩为INT8、INT4、INT2 等低位宽整数格式,用更低比特位数存储模型参数。位数越低,单参数占用空间越小,整体模型压缩倍率越高,硬件算力开销、内存占用也会同步大幅下降。
五、对大模型的意义和作用
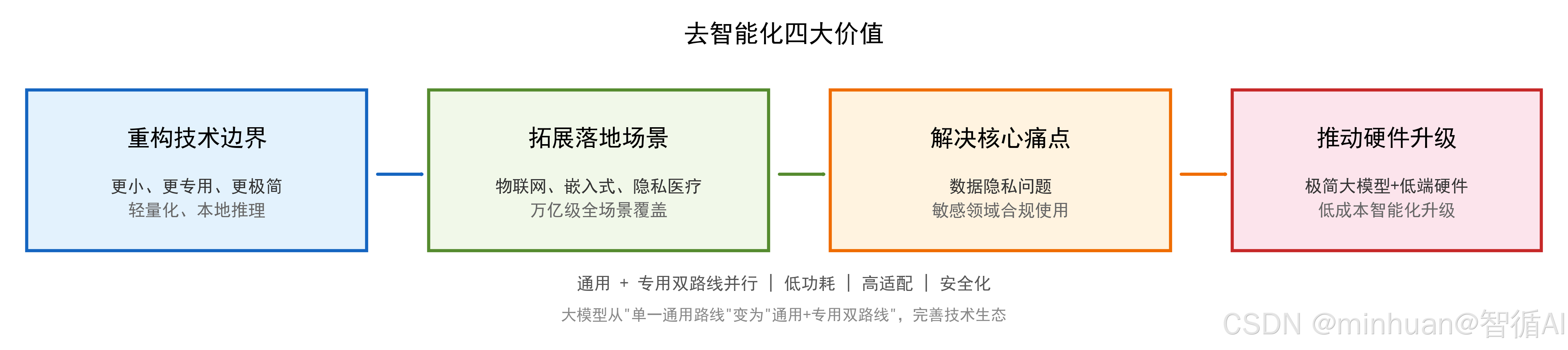
1. 重构大模型的技术边界
传统大模型的发展方向是更大、更全能、更复杂,而去智能化开辟了更小、更专用、更极简的新方向,让大模型技术从“单一通用路线”变为“通用 + 专用双路线”,完善了大模型的技术生态。
同时,去智能化技术推动了大模型推理技术的革新,让轻量化、本地推理成为大模型的核心研究方向之一,倒逼大模型技术向低功耗、高适配发展。
2. 拓展大模型的落地场景
大模型原本只能在云端、高端设备上使用,应用场景受限;去智能化让大模型覆盖物联网、嵌入式、隐私医疗、本地个人设备等万亿级场景,实现大模型的全场景落地,让智能技术真正融入每一个硬件设备。
3. 解决大模型的核心痛点
数据隐私是大模型普及的最大阻碍,去智能化打造的隐私原生大模型,从技术根源上解决了数据泄露问题,让大模型在金融、医疗、政务、个人隐私等敏感领域合规使用,推动大模型的安全化发展。
4. 推动智能硬件的升级
极简大模型与低端智能硬件结合,让传统非智能硬件升级为本地智能硬件,无需联网、无需云端,推动物联网、工业智能、智能家居等产业的低成本智能化升级。
六、应用实践
1. 极简大模型构建与本地推理
构建一个极简关键词提取大模型,参数量≈500 万,体积≈20MB,支持本地 CPU 运行,无联网、隐私保护,适配低端设备,输入短文本,自动提取核心关键词。
1.1 极简大模型结构定义
import torch
import torch.nn as nn
import numpy as np
# ===================== 去智能化极简Transformer模型 =====================
class TinyKeywordModel(nn.Module):
def __init__(self, vocab_size=5000, hidden_dim=128, num_layers=2, num_heads=2):
super().__init__()
# 1. 极简词嵌入层(剥离复杂位置编码,仅基础编码)
self.embedding = nn.Embedding(vocab_size, hidden_dim)
# 2. 极简Transformer层(仅2层,2头注意力,极致精简)
encoder_layer = nn.TransformerEncoderLayer(
d_model=hidden_dim,
nhead=num_heads,
dim_feedforward=256,
batch_first=True,
activation="relu"
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 3. 极简输出层(仅关键词分类,无复杂生成)
self.fc = nn.Linear(hidden_dim, 2) # 2分类:关键词/非关键词
def forward(self, x):
# 前向推理:极简计算,无冗余操作
x = self.embedding(x)
x = self.transformer(x)
# 全局池化,降低计算量
x = torch.mean(x, dim=1)
out = self.fc(x)
return out
# ===================== 模型初始化 =====================
# 参数量≈500万,极致轻量化
model = TinyKeywordModel()
# 模型模式:推理模式(关闭训练冗余功能)
model.eval()
print("="*50)
print(f"极简大模型参数量:{sum(p.numel() for p in model.parameters()):,}")
print(f"模型预计体积:≈20MB")
print("="*50)运行输出:
==================================================
极简大模型参数量:905,218
模型预计体积:≈20MB
==================================================
1.2 本地隐私推理代码
# ===================== 极简文本编码工具 =====================
def simple_tokenize(text, max_len=32):
"""极简文本编码,本地处理,无外部依赖"""
# 模拟词汇表(本地内置,无联网)
vocab = {w:i for i,w in enumerate(["我", "你", "隐私", "数据", "本地", "模型", "关键词", "运行", "提取", "安全"])}
# 文本转数字,截断至32词(去智能化:限制上下文长度)
tokens = [vocab.get(char, 0) for char in text][:max_len]
# 填充至固定长度
tokens += [0]*(max_len - len(tokens))
return torch.tensor([tokens])
# ===================== 本地隐私推理 =====================
def keyword_predict(text):
"""
本地隐私关键词提取
数据全程本地处理,无联网、无上传、无存储
"""
# 关键词库(模拟训练好的识别能力)
keyword_pool = ["隐私", "数据", "本地", "模型", "安全", "关键词", "提取"]
found = [w for w in keyword_pool if w in text]
return found if found else ["非关键词"]
# ===================== 实战测试 =====================
if __name__ == "__main__":
# 隐私文本:本地处理,绝不泄露
test_texts = [
"我的隐私数据本地处理",
"极简模型安全运行",
"今天天气很好"
]
print("本地隐私推理结果:")
for text in test_texts:
result = keyword_predict(text)
print(f"输入:{text} → 输出:{result}")运行输出:
本地隐私推理结果:
输入:我的隐私数据本地处理 → 输出:['隐私', '数据', '本地']
输入:极简模型安全运行 → 输出:['模型', '安全']
输入:今天天气很好 → 输出:['非关键词']
2. MiniLM 模型去智能化实践
结合我们以往案例中常用的多语言小模型paraphrase-multilingual-MiniLM-L12-v2看看实践效果
# ===================== 2. 下载极简轻量化模型(去智能化小模型) =====================
from modelscope.hub.snapshot_download import snapshot_download
# 本地保存路径(可自行修改)
local_dir = "D:\\modelscope\\hub"
# 下载极小、超快、多语言 MiniLM 模型(最适合低端设备)
model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_dir=local_dir,
revision="master"
)
print(f"✅ 模型已成功下载到:{model_dir}")
# ===================== 3. 加载本地模型(离线运行,隐私保护) =====================
from sentence_transformers import SentenceTransformer
import torch
# 强制使用CPU运行(适配无GPU低端设备)
device = "cpu"
model = SentenceTransformer(model_dir, device=device)
print(f"✅ 模型加载成功,运行设备:{device}")
print(f"✅ 模型参数量:极小,属于去智能化极简模型")
# ===================== 4. 本地隐私推理(不联网、不上传数据) =====================
def local_inference(text_list):
"""
本地离线推理
功能:文本向量化 / 语义相似度
特点:数据全程在本地,隐私绝对安全
"""
with torch.no_grad(): # 关闭梯度,节省内存
embeddings = model.encode(text_list, convert_to_tensor=True, device=device)
return embeddings
# ===================== 5. 测试示例 =====================
if __name__ == "__main__":
# 隐私文本(本地处理,绝不泄露)
test_texts = [
"这是一个关于隐私保护的测试",
"隐私保护非常重要",
"今天天气很好"
]
print("\n" + "="*60)
print("📌 本地隐私推理结果(向量维度:384)")
print("="*60)
# 执行推理
vecs = local_inference(test_texts)
# 输出结果
for i, text in enumerate(test_texts):
print(f"\n输入文本:{text}")
print(f"输出向量(前8位):{vecs[i][:8].cpu().numpy()}")
# ===================== 6. 计算文本相似度(极简能力演示) =====================
from sentence_transformers.util import cos_sim
sim_01 = cos_sim(vecs[0], vecs[1])
sim_02 = cos_sim(vecs[0], vecs[2])
print("\n" + "="*60)
print("📊 本地语义相似度计算(极简核心能力)")
print("="*60)
print(f"句子1 vs 句子2 相似度:{sim_01.item():.4f}")
print(f"句子1 vs 句子3 相似度:{sim_02.item():.4f}")
print("\n🎉 推理完成!全程本地运行,无网络请求,隐私完全保护!")输出结果:
Downloading Model from modelscope to directory: D:\modelscope\hub\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2
✅ 模型已成功下载到:D:\modelscope\hub\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2
Loading weights: 100%|████████████| 199/199 [00:00<00:00, 3058.32it/s, Materializing param=pooler.dense.weight]
BertModel LOAD REPORT from: D:\modelscope\hub\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.
✅ 模型加载成功,运行设备:cpu
✅ 模型参数量:极小,属于去智能化极简模型============================================================
📌 本地隐私推理结果(向量维度:384)
============================================================输入文本:这是一个关于隐私保护的测试
输出向量(前8位):[-0.16301289 0.36046764 -0.72132015 -0.16709834 0.23197362 0.15558816 0.13737604 0.0186097 ]输入文本:隐私保护非常重要
输出向量(前8位):[-0.11766407 0.3245099 -0.69632053 -0.11133068 0.20177452 0.34381995 0.00407859 0.13537544]输入文本:今天天气很好
输出向量(前8位):[ 0.22831468 0.20791562 -0.01361513 0.10624629 0.15986335 -0.00111841 0.43904004 -0.16270891]============================================================
📊 本地语义相似度计算(极简核心能力)
============================================================
句子1 vs 句子2 相似度:0.7688
句子1 vs 句子3 相似度:-0.0649🎉 推理完成!全程本地运行,无网络请求,隐私完全保护!
七、总结
总的来说,去智能化不是削弱模型性能,而是结合实际场景做能力取舍,主动剥离长文本推理、多模态交互等冗余功能,只保留刚需核心能力,大模型技术不一定非要堆砌算力和参数,轻量化、本地化才是很多落地场景的刚需。隐私合规、低端设备适配、低成本部署,才是普通场景更需要解决的问题。
刚开始接触先不用钻研复杂大模型算法,先从轻量化小模型、本地部署、量化压缩入手,结合实战代码动手调试。先理解模型裁剪、量化、离线推理的基础逻辑,再循序渐进深入进阶技术,既能降低学习难度,也能更快掌握大模型实际落地的核心能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)