Memoria-智能影记创新实训博客(二):相册语义搜索功能接口实现与界面展示
Memoria-智能影记创新实训博客(二):相册语义搜索功能接口实现与界面展示
博客主题:主线功能的实现
功能时间跨度:2026.03.30 - 2026.04.10(第5-6周)
进度总结:在图片打标的基础上,我进一步完成任务书主线功能中的语义搜索功能,成功实现了图片的分类整理与自由搜索两大基础任务,为后续的生成任务打下基础。
1. 目标
与上一篇博客一样,我们首先强调,所有的功能都不会把用户相册的原始图片上传至云端大模型,所有算法的实现,都完美保护了用户的图片隐私。
语义搜索的目标,是让用户在相册页直接用自然语言找图,不仅能通过“在济南”“去年3月”这类时间地点进行搜索,还能通过“花”“人物”这种短语标签进行搜索,还能通过“春节团聚吃饺子的照片”“去年在杭州的夜景”“红色上衣的人像”这种复合查询进行搜索,还能通过“春天的气息”“努力的经历”这种抽象查询进行搜索,还能通过“单人照,不要合影”这种排除类查询进行搜索。 简而言之,这套功能需要解决三件事:
- 借助本地规则和LLM把自然语言查询解析成系统可执行的搜索计划(这是该功能的核心)。
- 遵循计划,在时间、地点、标签和各类语义向量之间组合检索。
- 按序展示结果,同时,当严格条件结果太少时,自动放宽约束,尽量返回相关结果而不是空结果。
2. 前期工作
语义搜索建立在前面的图片打标能力之上,相关实现可参考上一篇博客:Memoria-智能影记创新实训博客(一):图片打标、废片剔除功能接口实现与界面展示。
搜索阶段依赖图片 embedding、aiTags 和地理信息。 其中最关键的是两层基础能力:
- 图片侧:每张图已经有
aiTags和 embedding,可用于粗标签过滤和向量相似度计算。 - 查询侧:查询会被解析成时间范围、地点、粗标签、正向语义、召回语义和负向语义。
图片侧已经在打标功能中实现,本功能主要集中在查询侧。
3. 查询解析
语义搜索的核心,不是把一句中文硬拆成几个标签,而是借助 LLM 把用户意图翻译成一份可执行的搜索计划。当前代码里,真正承担主解析任务的是 DeepSeek;短查询直达负责处理极短、极稳的输入;本地规则更多是无 API 时的备选方案,以及 LLM 缺字段时的兜底补全。
3.1 短查询直达
如果输入是 1 到 4 个汉字,且不包含时间、地点、否定词等结构化线索,系统会优先尝试短查询直达。它会把查询和一组粗标签种子做相似度比较,只要相似度不低于 0.18,就直接生成搜索计划,不再调用大模型。
static const double _shortRouteCoarseSimilarityThreshold = 0.18;
例如:
海边-> 命中beach_water宠物-> 命中pets_animals夜景-> 更可能走后面的通用解析,因为它已经带有场景语义,通常需要补语义短句
这条路线的目的只有一个:让最短、最稳定的查询直接返回,不把一次简单搜索变成一轮大模型解析。
3.2 本地规则解析
本地规则是离线保底,当没有配置 LLM_API_KEY,或者 LLM 返回缺字段、解析失败时,系统才更多依赖这条路线。它主要负责三件事:
- 提取时间:把“去年”“本月”“今天”“2024年5月”转成时间范围。
- 提取地点:优先在照片库已存在的地理文本里匹配,再补常见城市白名单。
- 提取粗标签和语义:用别名相似度把查询映射到粗标签,再生成正向语义。
粗标签不是看到关键词就收,而是要过一个词面相似度门槛:
if (score >= 0.34) {
results.add(...)
}
比如“去年杭州夜景”这类查询,就算没有大模型,本地规则也能先抽出:
- 时间:去年
- 地点:杭州
- 粗标签候选:
city_street、sky_sunset - 正向语义:
a photo of a city street at night一类英文短句
但它的能力边界也很明显:它更擅长识别时间、地点和少量高频主题,遇到“春节团聚吃饺子的照片”“有春天氛围的校园日常”这种复合意图时,仍然需要 LLM 来做更完整的语义展开。
3.3 DeepSeek 结构化解析
如果配置了 LLM_API_KEY,系统会调用 LLMService.completeText(...),默认模型是 deepseek-ai/DeepSeek-V3.2。这一步是整条语义搜索链路里最关键的解析环节。它的任务不是直接返回图片,而是先理解用户真正想找什么,再把这句话翻译成一份 JSON 搜索计划。
给 LLM 的系统提示词是:
你是“相册语义搜索解析器”。你的唯一任务是把用户的相册搜索语句转成结构化 JSON。你输出的不是解释,不是建议,而是“搜索计划”。只输出一个 JSON 对象,不要输出 Markdown,不要输出代码块,不要输出任何额外文本。
给 LLM 的用户提示词模板是:
请把用户的相册搜索语句解析成 JSON。
你需要输出以下字段:
{
"query_type": "metadata | attribute | concrete | abstract | collection",
"time_ranges": [{"start_time_ms": 0, "end_time_ms": 0, "reason": ""}],
"locations": [{"text": "", "type": "province | city | district"}],
"coarse_tags": [{"id": "", "label_zh": "", "label_en": "", "confidence": 0.0}],
"tag_strictness": "strict | prefer | optional",
"positive_semantics": [{"text": "", "weight": 0.0}],
"recall_semantics": [{"text": "", "weight": 0.0}],
"negative_semantics": [{"text": "", "weight": 0.0}],
"estimated_result_count": {"min": 0, "max": 0, "confidence": 0.0},
"notes": ""
}
字段要求:
1. query_type 必须解释查询本质:
- metadata:纯时间/地点过滤
- attribute:颜色、穿着、局部视觉属性
- concrete:具体主体或具体场景
- abstract:抽象情绪、氛围、季节感
- collection:一整类照片集合,不是单一对象
2. time_ranges:用于时间过滤,可以有多个时间段,无法确定时可为 null
3. locations:只保留真实地理位置名称,不要把“海边、草地、夜景、花海、公园”放进去
4. coarse_tags:只能从给定粗标签列表中选择,不能自造
5. tag_strictness:
- strict:必须命中这些粗标签
- prefer:优先使用,结果少时可放宽
- optional:仅作辅助,不阻塞召回
6. positive_semantics:用于最终精排,必须是适合搜图的英文短句
7. recall_semantics:用于结果不足时宽召回,也必须是适合搜图的英文短句
8. negative_semantics:表示不想要的内容;如果用户没明确要截图/文档/代码,默认加入这类负向语义
9. estimated_result_count:估计合理结果规模,输出 min / max / confidence
10. metadata 查询必须返回空 coarse_tags / positive_semantics / recall_semantics / negative_semantics
11. 只输出 JSON,不要解释
粗标签列表:
${jsonEncode(coarseCatalog)}
用户查询:
$rawQuery
这份 JSON 里,每个字段都有明确分工,而这些字段组合起来,恰好对应后面的搜索执行步骤:
query_type:决定这次搜索更像“筛选”,还是“找具体内容”,也决定默认标签严格度。time_ranges:直接约束拍摄时间。locations:直接匹配照片的省、市、区、地点名等逆地理文本。coarse_tags:用来缩小候选集,不直接决定最终排序。tag_strictness:决定粗标签是强过滤、弱过滤,还是仅辅助。positive_semantics:精排主语义,直接决定“像不像”。recall_semantics:严格结果不够时的宽召回语义。negative_semantics:用户不想要的方向,用于惩罚而不是一票否决。estimated_result_count:不是展示给用户看,而是告诉系统“结果太少时要不要继续放宽”。
3.4 三条路线怎么配合
这三条路线不是互斥关系,但在有 API 的正常使用场景里,DeepSeek 是主路线,短查询直达是加速通道,本地规则只是兜底。
例 1:去年杭州的夜景
- LLM 会先把它理解成“时间 + 地点 + 具体场景”的组合查询
query_type更接近concretetime_ranges会落到“去年”locations会落到“杭州”positive_semantics不会只停留在“night view”这种单词层面,而会展开成更适合搜图的短句,比如“a photo of a city street at night”或“a night cityscape photo”recall_semantics还会补上更宽一点的同主题表达,避免只搜到一小撮极像的夜景图
例 2:春节团聚吃饺子的照片,不要截图
- 这类查询真正有价值的地方,不是抽出“春节”和“饺子”两个词,而是理解它是一个带节日、人物关系、餐桌场景和排除条件的复合查询
- LLM 会把它组织成多条
positive_semantics,例如“family reunion dinner”“people eating dumplings together” - 同时生成
negative_semantics,明确削弱截图、文档、代码界面这类非相册照片结果 estimated_result_count还会告诉系统,这更像一个结果量不小的集合查询,后面在放宽搜索时就不会过早收缩
例 3:有春天气息的校园日常
- 这类查询最能体现 LLM 的价值,因为它不是一个明确物体,而是“场景 + 氛围 + 主题集合”
query_type更可能被解析成abstract或collectioncoarse_tags不会被限制得太窄,避免只剩一个“校园”标签positive_semantics会更聚焦“campus daily life in spring”“warm outdoor student moments”这类图像语义recall_semantics会扩展到更宽的校园、人物、户外、春天氛围相关表达,提升召回
所以,查询解析的重点不是“规则抽词”,而是利用 LLM 把一句自然语言拆成可执行的搜索结构,并顺手把用户没说全、但和搜图强相关的语义一起补齐。本地规则仍然存在,但本质上更像是没有配置 API 时的备选方案。
4. 搜索执行
解析完成后,系统拿到的已经不是一句话,而是一份搜索计划。后面的执行顺序很固定:先过滤,再缩圈,再打分,再分层返回。
4.1 先按时间和地点过滤
第一层先跑 metadata 过滤。时间命中 time_ranges,地点命中照片已有的 province / city / district / locationName / formattedAddress。
如果这次查询本身就是 metadata,或者没有任何正向、负向语义,系统就到这里为止,直接返回过滤结果,不再做向量匹配。也就是说,“2024 年杭州照片”这种查询,本质上是筛选,不是语义排序。
4.2 再按粗标签缩小候选集
有粗标签时,系统会继续看 tag_strictness:
strict:必须命中这些粗标签。prefer:先按粗标签过滤;如果候选空了,主链路允许回退到原候选集。optional:粗标签只是辅助,主链路不强制过滤。
这一步的作用,是把“人物、海边、美食、城市街景”这类大方向先圈出来,减少后面向量精排的噪声。
4.3 最后用正向语义和负向语义打分
真正决定排序的是向量打分。每张候选图都会和 positive_semantics、negative_semantics 分别计算相似度。
static const double _positiveSemanticParticipationThreshold = 0.20;
static const double _exactPositiveThreshold = 0.24;
static const double _relatedSemanticThreshold = 0.14;
static const double _rescueSemanticThreshold = 0.10;
static const double _negativePenaltyAlpha = 0.6;
static const double _minimumFinalScore = 0.03;
这里有两个正向分数:
semanticScore:所有正向语义按权重加权后的总分,用来判断“方向是否相关”。qualifiedPositiveScore:只统计相似度不低于0.20的正向语义,再做加权平均,用来判断“是否足够像”。
最终分数是:
finalScore = qualifiedPositiveScore - 0.6 * negativeScore
它的含义很直接:
- 正向语义决定主方向。
- 负向语义只负责削弱,不直接把结果踢掉。
- 即使方向相关,最终分数仍然必须不低于
0.03,低质量尾部结果不会进列表。
4.4 结果为什么会分成 Exact 和 Related
系统不会把所有命中的图混成一个列表,而是先在数据层分成两档:
exact:qualifiedPositiveScore >= 0.24,且finalScore >= 0.03related:semanticScore >= 0.14,且finalScore >= 0.03
这两个阈值对应的是两种不同的问题:
0.24回答“这张图是不是已经很像用户真正想找的内容”。0.14回答“它至少是不是同一方向的相关图”。
举个例子,搜索“春节团聚吃饺子的照片”时:
- 饺子、餐桌、家人都比较明确的图,更容易进
exact - 只有聚餐氛围、但看不清饺子的图,可能进
related
界面层最终会把两类结果合并展示;如果没有 exact、只有 related,再提示用户“未找到您所需的图片,只找到一些相关图片”。
5. 自动放宽与召回
语义搜索不是一次算完就结束。当前代码里,如果结果数量不够,会自动进入回退搜索。
是否需要放宽,不是固定看“有没有结果”,而是结合查询自己预估的结果规模判断。如果总结果数低于期望下限,就继续扩大搜索。
当前回退分三层:
-
放宽时间 / 地点约束
如果“时间 + 地点”一起过滤后没有结果,会优先保留时间或地点中更合理的一边。 -
放宽粗标签约束
如果当前是prefer或optional,会逐步弱化粗标签限制。 -
使用
recall_semantics做召回
这一步把语义门槛降到0.10,专门找“方向相关”的图片。
semanticThreshold: _rescueSemanticThreshold,
也就是说,系统并不是一上来就把搜索放得很宽,而是先严格、再逐层放宽,最大程度满足用户体验。
6. 搜索页设置
语义搜索的入口就在相册页顶部搜索框:
搜索结果页不是简单平铺,而是做了三层处理:
- 结果分层:搜索服务内部区分
exactPhotos和relatedPhotos - 排序方式:按分数或按时间排序
- 标签二次筛选:从结果图的
aiTags中提取高频标签,作为筛选 chip
final tags = _tagBrowserService.browsableTagsForPhoto(photo);
界面层会把 exact 和 related 合并成一个结果流;如果没有精确结果、只有相关结果,会额外给出提示。
这意味着语义搜索不是“查完就结束”,而是允许用户在搜索结果内部继续按标签缩小范围,形成一层轻量交互闭环。
7. 参数选择
短查询粗类相似度阈值 0.18:让“海边、宠物、花”这种极短查询直接走快速路线,提高用户体验。本地粗标签抽取阈值 0.34:保证别名匹配必须足够接近,避免把粗标签抽得太散。正向语义参与阈值 0.20:只让真正起作用的正向语义进入精确分计算。Exact 阈值 0.24:保证精确结果足够像。Related 阈值 0.14:让相关结果保留更宽的召回。Recall 阈值 0.10:在严格结果不足时,给回退搜索更大的召回空间。负向惩罚系数 0.6:负向语义用于削弱,而不是直接抹掉正向结果。最低最终分 0.03:避免低质量尾部结果混进列表。
8. 界面展示
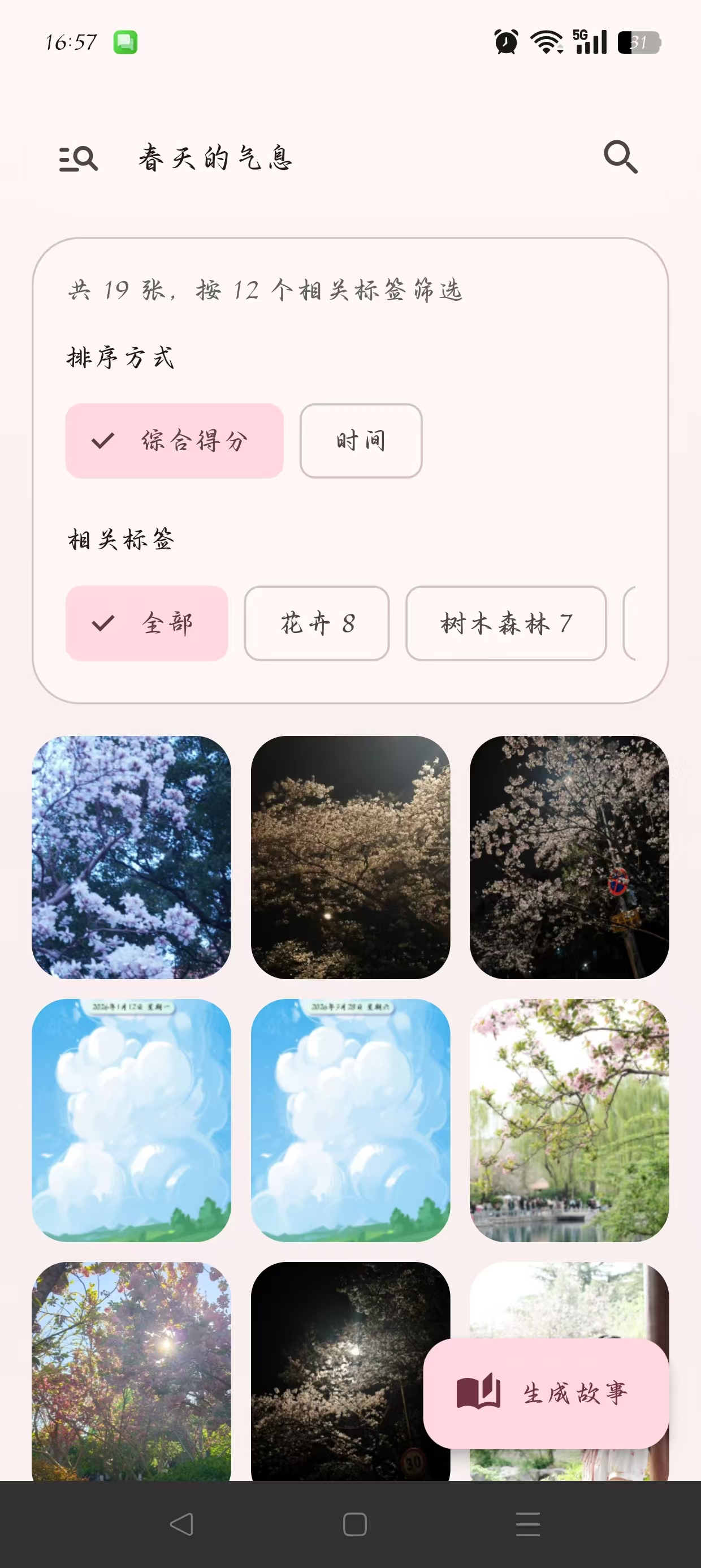
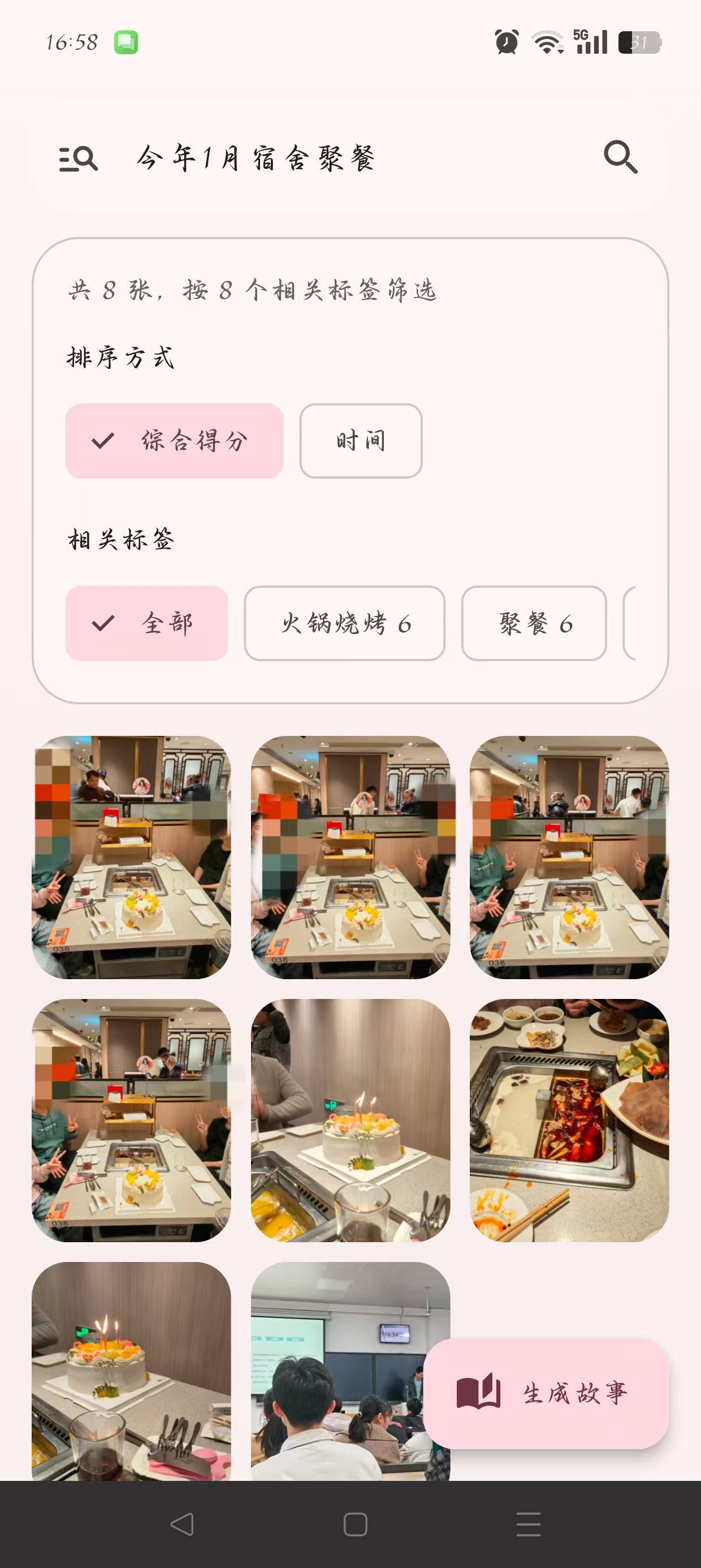
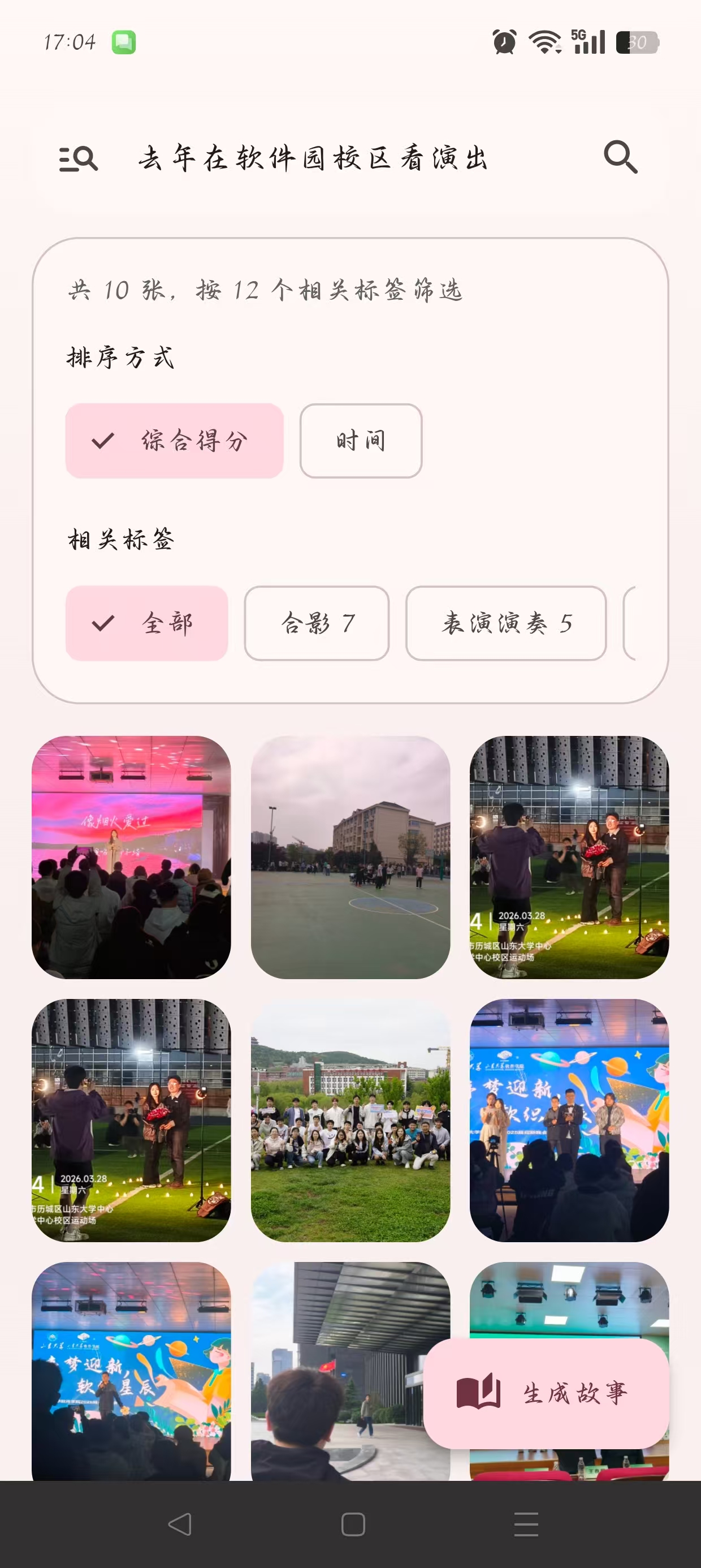
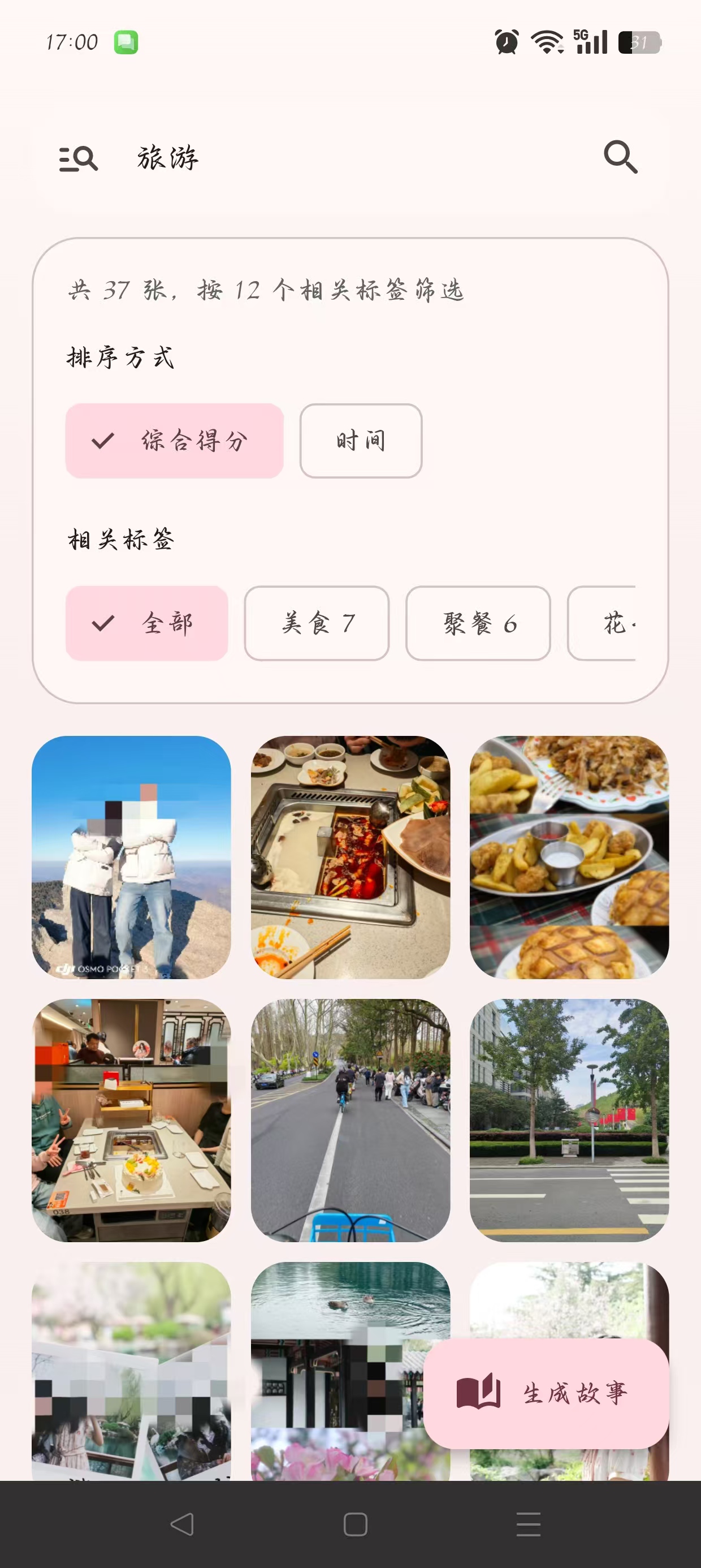
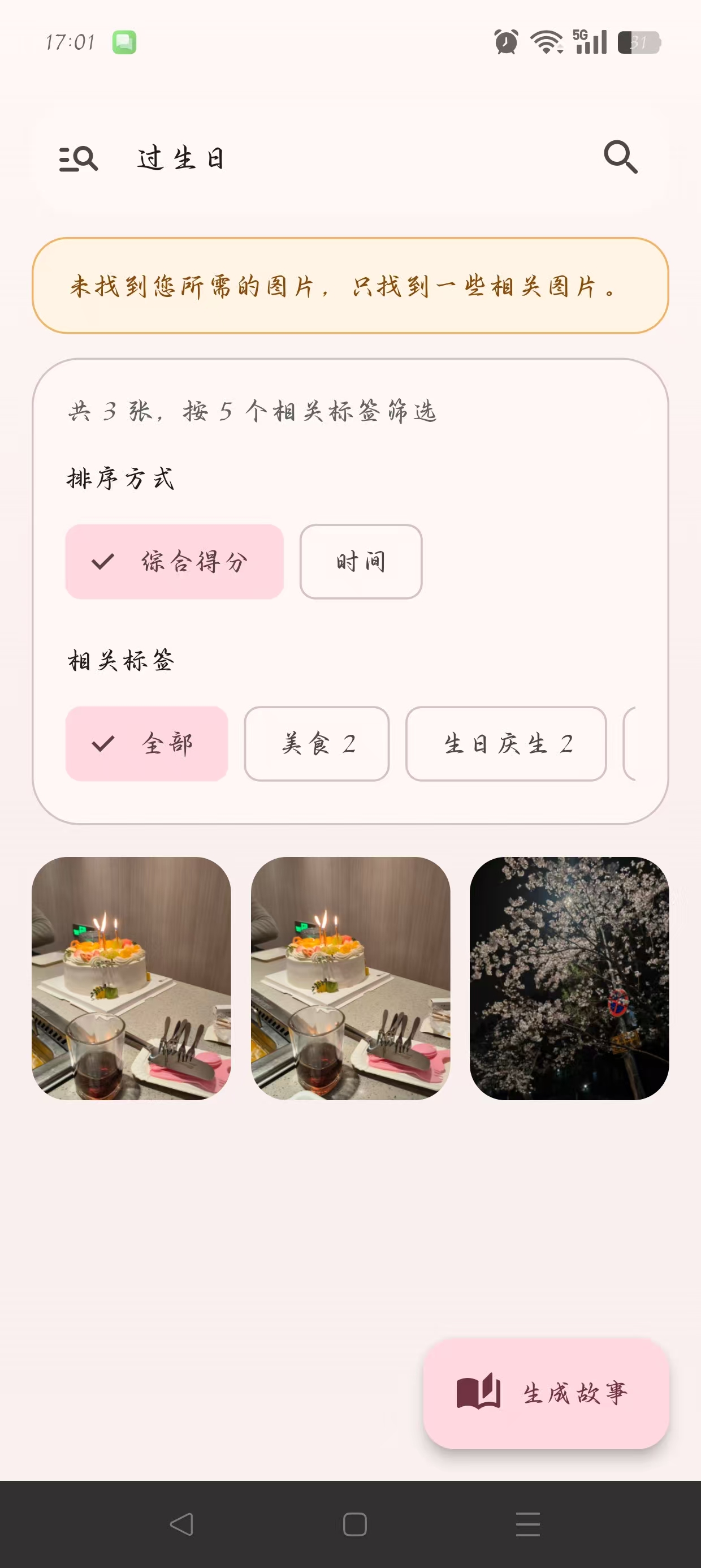
9. 总结
这套语义搜索的核心,不是让大模型直接帮我们找图,而是把自然语言先解析成一份结构化搜索计划,再让时间、地点、标签和向量语义共同执行。
从实现上看,它有三个明显特点:
- 查询解析不是单一路径,而是“短查询直达 + 本地规则 + DeepSeek 结构化解析”的组合。
- 搜索结果不是单阈值裁剪,而是
exact / related / recall三层递进。 - 展示侧不是只展示结果,而是基于综合分数排序,同时支持
aiTags和时间进行二次筛选,形成可交互的搜索结果页。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)