【鲁莽尝试】初次尝试微调qwen3_tts
记录本地调试qwen3_tts过程
1、创建qwen3_tts虚拟环境
conda create -n qwen3_tts python=3.11 -y
conda activate qwen3_tts
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124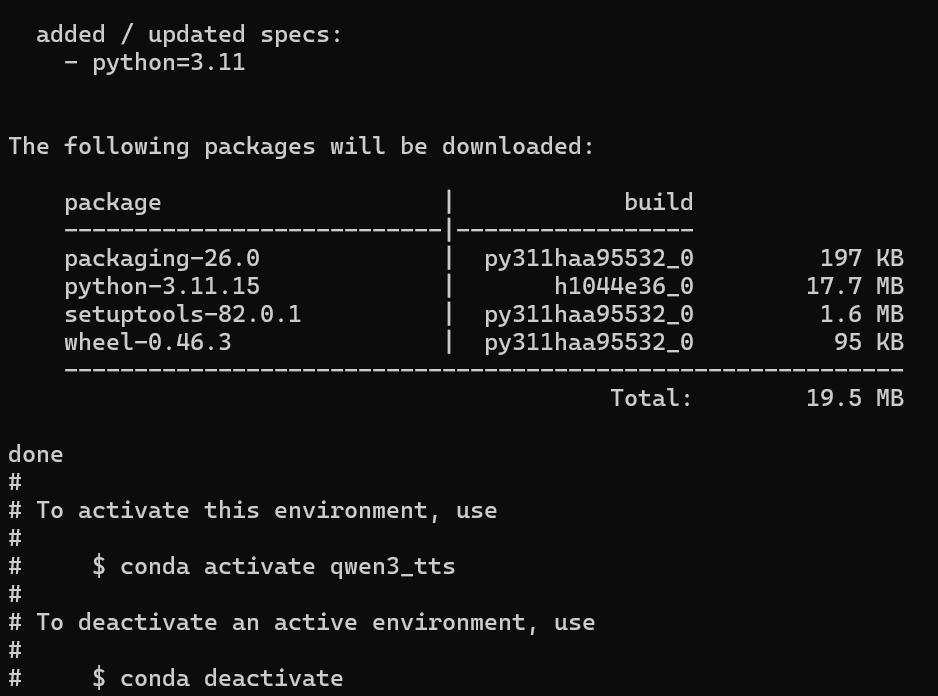
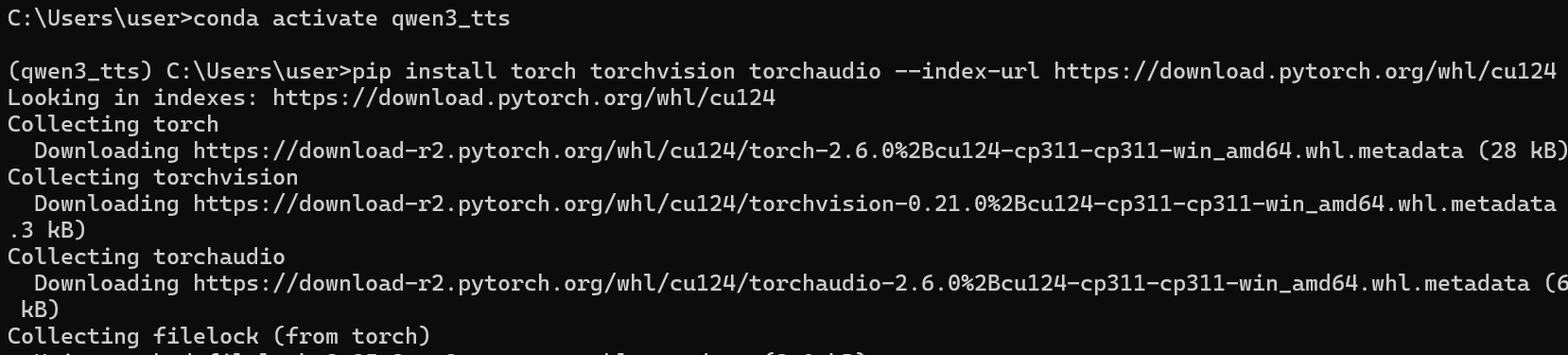
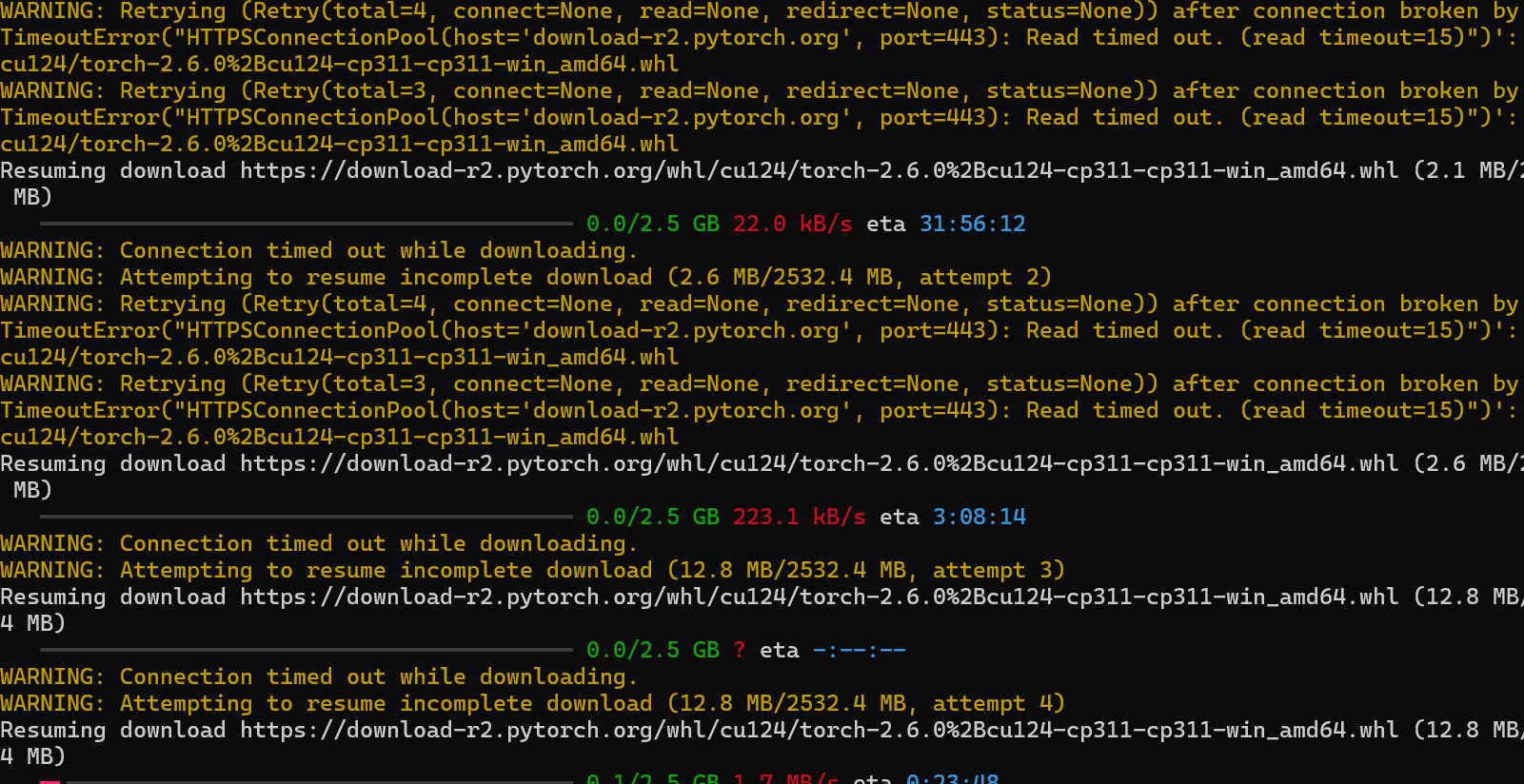
这里安装pytorch出现了超时问题

这里尝试安装了几次,都是速度有点慢
可以更换国内下载地址,也可以更换cuda版本,也可以尝试延长超时时间
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 --timeout 600这里时间久一点,安装内容也多一点
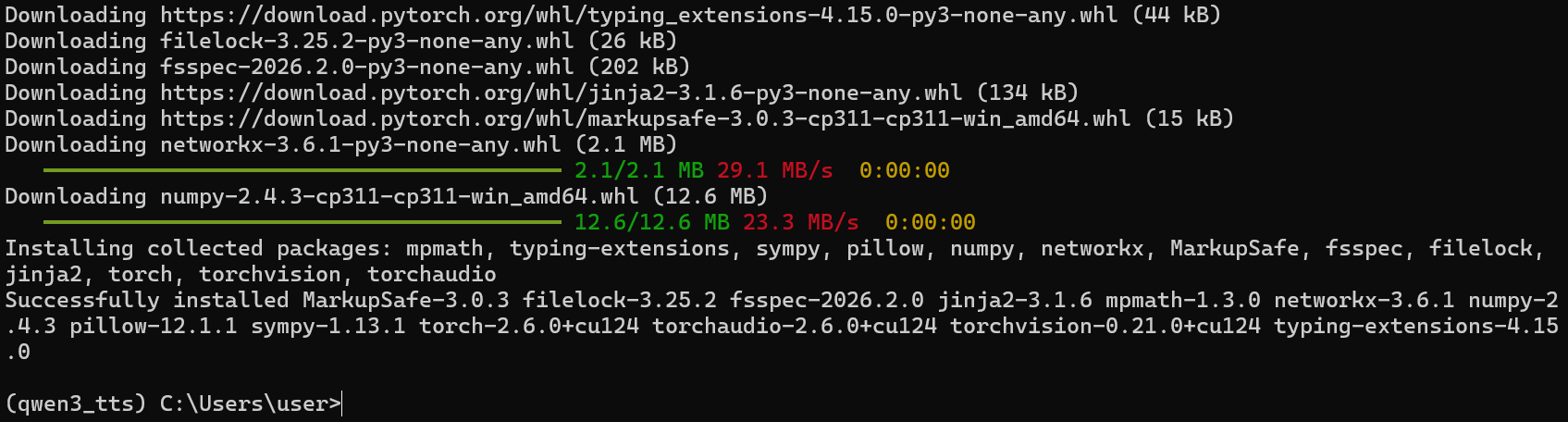
安装完毕之后,检验是否可用:
python -c "import torch; print(f'PyTorch: {torch.__version__}'); print(f'CUDA available: {torch.cuda.is_available()}'); print(f'GPU: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else None}')"
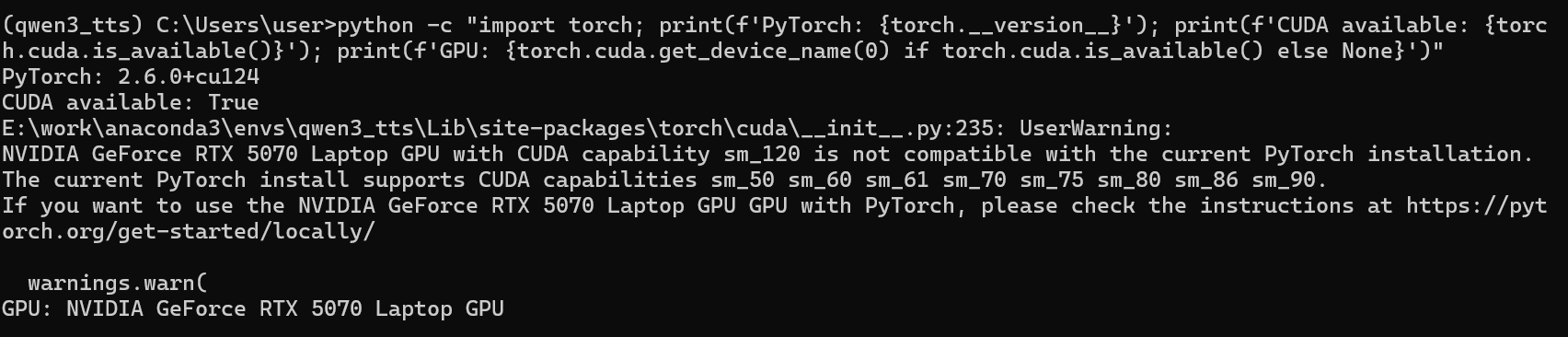
这个警告很关键——RTX 5070 的 compute capability 是 sm_120(Blackwell),但 PyTorch 2.6 最高只支持到 sm_90。
这意味着 GPU 能识别,但无法真正在上面跑计算,会自动降级到 CPU,速度反而更慢。
重新安装nightly 版本(更新最快)
pip install torch torchvision torchaudio --pre --index-url https://download.pytorch.org/whl/nightly/cu124 --timeout 1200
但是这里报错了,因为torchaudio还没有nightly版本
 然后做了一个尝试,根据前辈的经验,安装了指定版本的torch(之前别的电脑也装过,版本不一致可能会有各种问题。。。)
然后做了一个尝试,根据前辈的经验,安装了指定版本的torch(之前别的电脑也装过,版本不一致可能会有各种问题。。。)
解决yolov11在RTX5070显卡安装pytorch报错
运行安装指令
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128 --timeout 600验证
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128 --timeout 600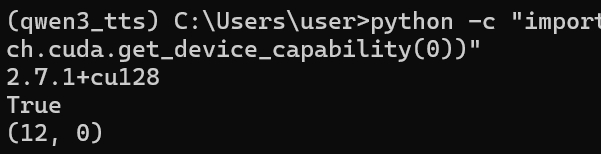
这里应该是安装成功了,再看后面有没有问题
2、模型下载
这里涉及到了国内外网络环境差别的问题,一般使用HuggingFace (不过国外网络更快),国内使用ModelScope更快一点
先安装ModelScope
pip install --upgrade modelscope
然后 切换一下目录
cd Qwen3-TTS/finetuning使用ModelScope下载模型
分别运行安装指令
modelscope download --model Qwen/Qwen3-TTS-Tokenizer-12Hz --local_dir ./Qwen3-TTS-Tokenizer-12Hz
这部分安装还没遇到问题,
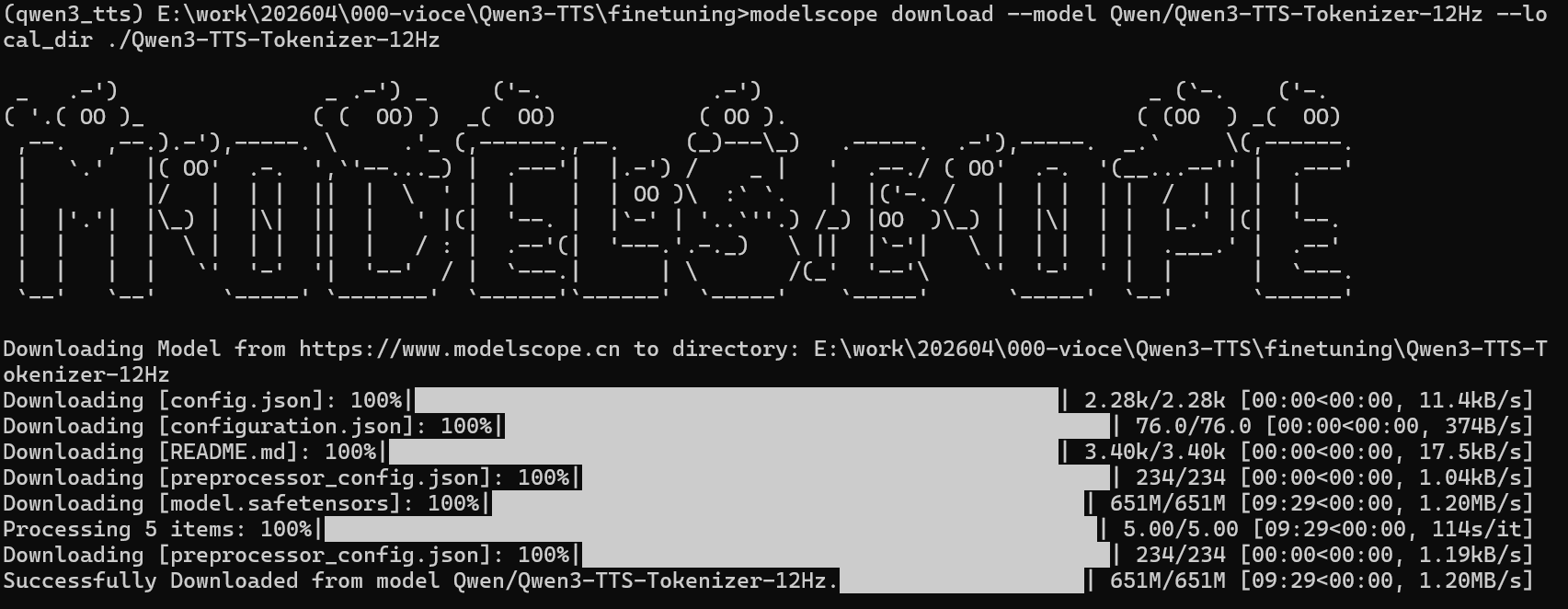
检验完整性通过
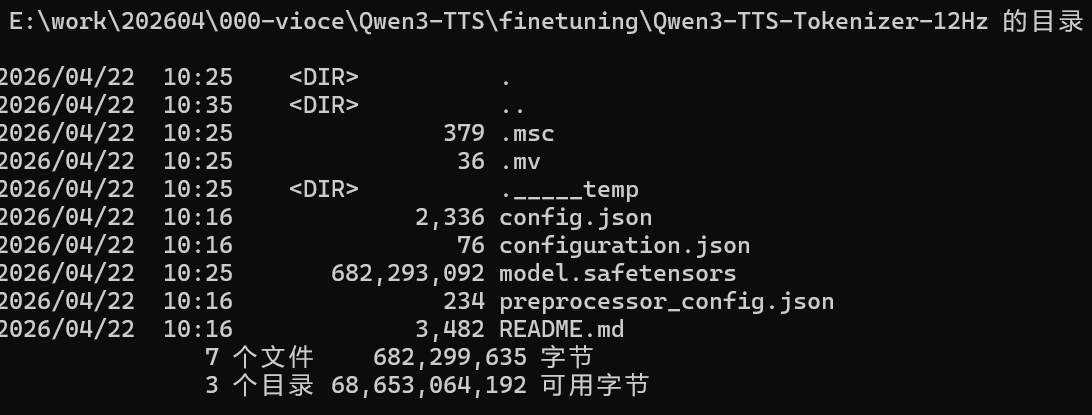
接下来安装模型文件
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir ./Qwen3-TTS-12Hz-1.7B-Base这里下载模型可能会很慢,有可能下载不完整
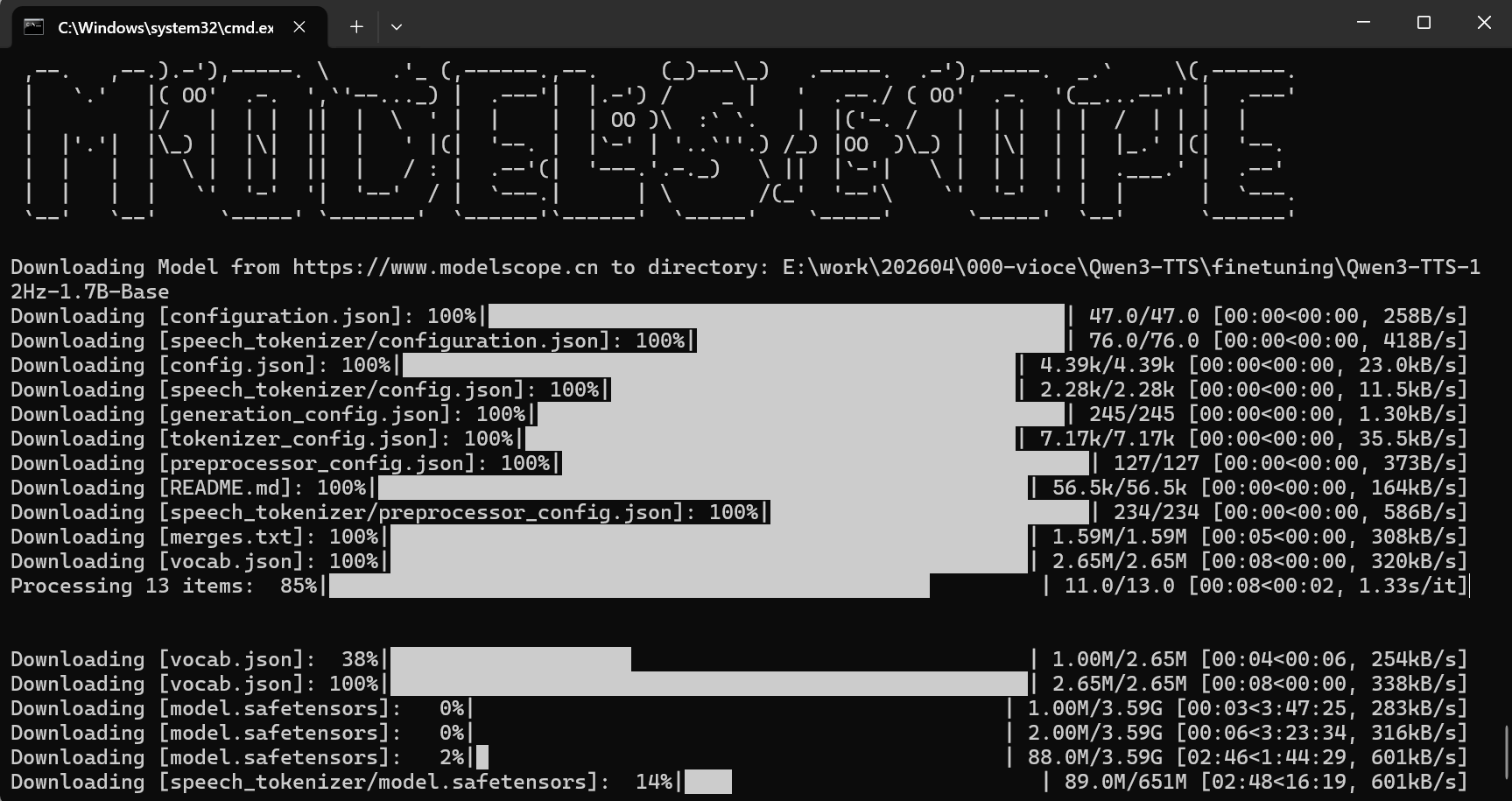
最后安装结果是这样

检查模型内容
# 检查目录内容
dir E:\work\202604\000-vioce\Qwen3-TTS\finetuning\Qwen3-TTS-12Hz-1.7B-Base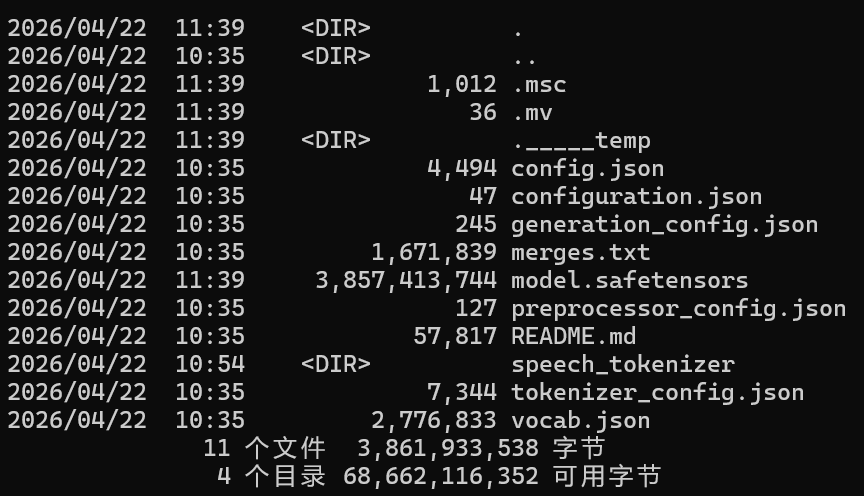
这里显示基本说明模型文件完整
3、准备训练数据
准备16kHz的wav格式录音文件,和录音文件对应的文本内容,还有一个参考音频(也可以和录音文件一致)
这里编写了脚本来处理32kHz的长录音
#!/usr/bin/env python3
"""
Qwen3-TTS 数据准备脚本
功能:
1. ffmpeg 将音频转成 16kHz 单声道
2. 按句子拆分音频(VAD 静音检测)
3. 匹配对应文本,生成 train_raw.jsonl
"""
import subprocess
import json
import os
import re
import sys
# ==================== 配置 ====================
#根据实际路径更改路径配置
AUDIO_INPUT = r"XXX\test-data\ye.wav"
TEXT_PATH = r"XXX\test-data\ybf.txt"
OUTPUT_DIR = r"XXX\test-data\segments"
OUTPUT_JSONL = r"XXX\finetuning\train_raw.jsonl"
REF_AUDIO = r"XXX\test-data\ye_16k.wav"
# ==================== ====================
def run_cmd(cmd, desc=""):
print(f"[CMD] {desc}")
result = subprocess.run(cmd, capture_output=True, text=True, shell=False)
if result.returncode != 0:
print(f" ERROR: {result.stderr[-300:]}")
sys.exit(1)
return result
def get_duration(path):
result = subprocess.run(
["ffprobe", "-v", "quiet", "-print_format", "json", "-show_format", path],
capture_output=True, text=True
)
import json as _json
d = _json.loads(result.stdout)
return float(d["format"]["duration"])
def step1_convert_to_16k():
print("\n===== Step 1: Convert to 16kHz =====")
if os.path.exists(REF_AUDIO):
print(f" {REF_AUDIO} already exists, skipping conversion")
return
os.makedirs(os.path.dirname(REF_AUDIO), exist_ok=True)
cmd = [
"ffmpeg", "-y",
"-i", AUDIO_INPUT,
"-ar", "16000", "-ac", "1",
REF_AUDIO
]
run_cmd(cmd, "ffmpeg convert to 16kHz mono")
print(f" -> {REF_AUDIO}")
def step2_split_by_sentence():
print("\n===== Step 2: Split audio by sentence (VAD) =====")
os.makedirs(OUTPUT_DIR, exist_ok=True)
# 读取文本
with open(TEXT_PATH, "r", encoding="utf-8") as f:
raw = f.read()
# 提取正文段落,合并为纯文本
lines = [l.strip() for l in raw.split("\n") if len(l.strip()) > 5]
full_text = "".join(lines)
# 按句子分割(中文句号、逗号、感叹号、问号等)
# 按中文字符和标点切分
sentences = re.split(r"(?<=[。!?;\n])", full_text)
sentences = [s.strip() for s in sentences if len(s.strip()) >= 5]
print(f" 文本句子数: {len(sentences)}")
total_dur = get_duration(REF_AUDIO)
chars_per_sec = len(full_text) / total_dur
print(f" 总时长: {total_dur:.1f}s, 字符/s: {chars_per_sec:.1f}")
# 按字符数估算每句对应的时间范围
seg_durs = []
seg_texts = []
for sent in sentences:
est_dur = len(sent) / chars_per_sec
seg_durs.append(est_dur)
seg_texts.append(sent)
# 累积时间生成音频片段
seg_files = []
cur_time = 0.0
for i, (sent, dur) in enumerate(zip(seg_texts, seg_durs)):
out_wav = os.path.join(OUTPUT_DIR, f"seg_{i:03d}.wav")
cmd = [
"ffmpeg", "-y",
"-i", REF_AUDIO,
"-ss", str(cur_time),
"-t", str(dur + 0.5), # 加 0.5s 缓冲避免截断
"-ar", "16000", "-ac", "1",
out_wav
]
r = subprocess.run(cmd, capture_output=True, text=True)
if r.returncode != 0:
print(f" WARN seg {i}: ffmpeg failed, skipping")
continue
seg_files.append(out_wav)
cur_time += dur
print(f" 音频片段数: {len(seg_files)}")
return seg_files, seg_texts[:len(seg_files)]
def step3_write_jsonl(seg_files, seg_texts):
print("\n===== Step 3: Write train_raw.jsonl =====")
os.makedirs(os.path.dirname(OUTPUT_JSONL), exist_ok=True)
with open(OUTPUT_JSONL, "w", encoding="utf-8") as f:
for wav_path, text in zip(seg_files, seg_texts):
# Windows 路径转正斜杠
wav_path_fw = wav_path.replace("\\", "/")
ref_fw = REF_AUDIO.replace("\\", "/")
obj = {
"audio": wav_path_fw,
"text": text,
"ref_audio": ref_fw
}
f.write(json.dumps(obj, ensure_ascii=False) + "\n")
print(f" -> {OUTPUT_JSONL}")
print(f" Total samples: {len(seg_files)}")
# Show first 3
print("\n First 3 samples:")
for i, (wav, text) in enumerate(zip(seg_files[:3], seg_texts[:3])):
print(f" [{i}] {os.path.basename(wav)}: {text[:40]}...")
def main():
print("=" * 50)
print("Qwen3-TTS Data Preparation Script")
print("=" * 50)
print(f" Audio input : {AUDIO_INPUT}")
print(f" Text input : {TEXT_PATH}")
print(f" Output dir : {OUTPUT_DIR}")
print(f" Output JSONL: {OUTPUT_JSONL}")
print(f" Ref audio : {REF_AUDIO}")
step1_convert_to_16k()
seg_files, seg_texts = step2_split_by_sentence()
step3_write_jsonl(seg_files, seg_texts)
print("\n[DONE] train_raw.jsonl is ready!")
if __name__ == "__main__":
main()
运行之后,在对应路径下生成了分段的语音和对应位置上的文件
安装qwen3_tts模块
pip install -U qwen-tts这一步时间会久一点,看着安装的内容也比较多
可能也和网速有关系,安装一段时间才会成功

4、数据预处理
这里的作用是为为原始jsonl数据加入audio_codes
或者说:把音频文件转成模型能认识的 "数字密码"(audio_codes)
模型训练的是"文本 + audio_codes → 语音" 的映射关系。直接训练音频太大了,转成 token 序列之后:
体积小(42条样本的 audio_codes 只有 518KB)
训练速度快
模型只学 audio_tokens 和 text_tokens 之间的对应关系
在上一步操作中将生成的train_raw.jsonl放在了finetuning目录下,然后运行prepare_data.py进行数据预处理
这个脚本是 Qwen 官方提供的,路径在:Qwen3-TTS/finetuning/prepare_data.py
运行成功后,生成train_with_codes.jsonl
准备在下一步操作中使用
5、SFT微调
这一步操作是,用准备好的 train_with_codes.jsonl 数据,去微调 Qwen3-TTS-12Hz-1.7B-Base 模型,让模型学会"说"这个说话人的声音。
这一步有一个硬件问题,当前设备是8G的独显,对应脚本中的batch_size=32,这里肯定要改小,避免CUDA OOM
更新的一个新的微调脚本进行优化
# coding=utf-8
"""
Qwen3-TTS SFT 微调脚本 - 8GB 显存优化版
基于官方 sft_12hz.py,修改以下内容:
1. 移除 flash_attention_2(Windows 不支持,显存足够不用)
2. 启用 gradient_checkpointing 节省显存
3. 使用 device_map="auto" 智能分配显存
4. 优化 batch_size 和 gradient_accumulation_steps
5. 默认 batch_size=2(42条样本够用)
"""
import argparse
import json
import os
import shutil
import gc
import torch
from accelerate import Accelerator
from dataset import TTSDataset
from qwen_tts.inference.qwen3_tts_model import Qwen3TTSModel
from safetensors.torch import save_file
from torch.optim import AdamW
from torch.utils.data import DataLoader
from transformers import AutoConfig
target_speaker_embedding = None
def train():
global target_speaker_embedding
parser = argparse.ArgumentParser()
parser.add_argument("--init_model_path", type=str, default="Qwen/Qwen3-TTS-12Hz-1.7B-Base")
parser.add_argument("--output_model_path", type=str, default="output")
parser.add_argument("--train_jsonl", type=str, required=True)
parser.add_argument("--batch_size", type=int, default=2) # 8GB 显存用 2
parser.add_argument("--lr", type=float, default=2e-6) # 官方建议 2e-6 ~ 2e-5
parser.add_argument("--num_epochs", type=int, default=10)
parser.add_argument("--speaker_name", type=str, default="speaker_test")
parser.add_argument("--gradient_accumulation_steps", type=int, default=4)
parser.add_argument("--use_gradient_checkpointing", action="store_true", default=True)
args = parser.parse_args()
print("=" * 50)
print("Qwen3-TTS SFT Fine-tuning (8GB VRAM Optimized)")
print("=" * 50)
print(f" Model: {args.init_model_path}")
print(f" Output: {args.output_model_path}")
print(f" Data: {args.train_jsonl}")
print(f" Batch size: {args.batch_size}")
print(f" Grad accum: {args.gradient_accumulation_steps}")
print(f" Learning rate: {args.lr}")
print(f" Epochs: {args.num_epochs}")
print(f" Speaker: {args.speaker_name}")
print(f" Grad checkpoint: {args.use_gradient_checkpointing}")
print("=" * 50)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision="bf16",
log_with="tensorboard",
device_placement=True,
)
MODEL_PATH = args.init_model_path
# ============================================================
# 显存优化1: 不使用 flash_attention_2(Windows 不支持)
# 显存优化2: device_map="auto" 让 accelerate 智能分配
# ============================================================
qwen3tts = Qwen3TTSModel.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="eager", # 不依赖 flash-attn,兼容性好
)
# ============================================================
# 显存优化3: 启用 gradient checkpointing(用计算换显存)
# ============================================================
if args.use_gradient_checkpointing and hasattr(qwen3tts.model, 'enable_gradient_checkpointing'):
qwen3tts.model.enable_gradient_checkpointing()
print("[Memory] Gradient checkpointing enabled")
config = AutoConfig.from_pretrained(MODEL_PATH)
train_data = open(args.train_jsonl, encoding="utf-8").readlines()
train_data = [json.loads(line) for line in train_data]
dataset = TTSDataset(train_data, qwen3tts.processor, config)
train_dataloader = DataLoader(
dataset,
batch_size=args.batch_size,
shuffle=True,
collate_fn=dataset.collate_fn,
)
optimizer = AdamW(qwen3tts.model.parameters(), lr=args.lr, weight_decay=0.01)
model, optimizer, train_dataloader = accelerator.prepare(
qwen3tts.model, optimizer, train_dataloader
)
num_epochs = args.num_epochs
model.train()
# 打印 GPU 显存状态
if torch.cuda.is_available():
mem_allocated = torch.cuda.memory_allocated() / 1024**3
mem_reserved = torch.cuda.memory_reserved() / 1024**3
print(f"[GPU] Currently using: {mem_allocated:.2f} GB / {mem_reserved:.2f} GB reserved")
print("\n===== Training Start =====")
for epoch in range(num_epochs):
epoch_loss = 0.0
num_steps = 0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(model):
input_ids = batch['input_ids']
codec_ids = batch['codec_ids']
ref_mels = batch['ref_mels']
text_embedding_mask = batch['text_embedding_mask']
codec_embedding_mask = batch['codec_embedding_mask']
attention_mask = batch['attention_mask']
codec_0_labels = batch['codec_0_labels']
codec_mask = batch['codec_mask']
# 提取说话人 embedding(detach 避免优化它)
speaker_embedding = model.speaker_encoder(
ref_mels.to(model.device).to(model.dtype)
).detach()
if target_speaker_embedding is None:
target_speaker_embedding = speaker_embedding
print(f"[Speaker] Reference embedding captured, shape: {speaker_embedding.shape}")
input_text_ids = input_ids[:, :, 0]
input_codec_ids = input_ids[:, :, 1]
input_text_embedding = model.talker.model.text_embedding(input_text_ids) * text_embedding_mask
input_codec_embedding = model.talker.model.codec_embedding(input_codec_ids) * codec_embedding_mask
input_codec_embedding[:, 6, :] = speaker_embedding
input_embeddings = input_text_embedding + input_codec_embedding
for i in range(1, 16):
codec_i_embedding = model.talker.code_predictor.get_input_embeddings()[i - 1](codec_ids[:, :, i])
codec_i_embedding = codec_i_embedding * codec_mask.unsqueeze(-1)
input_embeddings = input_embeddings + codec_i_embedding
outputs = model.talker(
inputs_embeds=input_embeddings[:, :-1, :],
attention_mask=attention_mask[:, :-1],
labels=codec_0_labels[:, 1:],
output_hidden_states=True,
)
hidden_states = outputs.hidden_states[0][-1]
talker_hidden_states = hidden_states[codec_mask[:, :-1]]
talker_codec_ids = codec_ids[codec_mask]
sub_talker_logits, sub_talker_loss = model.talker.forward_sub_talker_finetune(
talker_codec_ids, talker_hidden_states
)
loss = outputs.loss + 0.3 * sub_talker_loss
epoch_loss += loss.item()
num_steps += 1
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
optimizer.zero_grad()
if step % 5 == 0 or step == len(train_dataloader) - 1:
avg_loss = epoch_loss / max(num_steps, 1)
lr_now = optimizer.param_groups[0]['lr']
print(f"Epoch {epoch}/{num_epochs-1} | Step {step}/{len(train_dataloader)-1} "
f"| Loss: {loss.item():.4f} | AvgLoss: {avg_loss:.4f} | LR: {lr_now:.2e}")
gc.collect()
avg_epoch_loss = epoch_loss / max(num_steps, 1)
print(f"\n>>> Epoch {epoch} finished. Avg Loss: {avg_epoch_loss:.4f}\n")
# ============================================================
# 保存 checkpoint
# ============================================================
if accelerator.is_main_process:
output_dir = os.path.join(args.output_model_path, f"checkpoint-epoch-{epoch}")
shutil.copytree(MODEL_PATH, output_dir, dirs_exist_ok=True)
# 更新 config
input_config_file = os.path.join(MODEL_PATH, "config.json")
output_config_file = os.path.join(output_dir, "config.json")
with open(input_config_file, 'r', encoding='utf-8') as f:
config_dict = json.load(f)
config_dict["tts_model_type"] = "custom_voice"
talker_config = config_dict.get("talker_config", {})
talker_config["spk_id"] = {args.speaker_name: 3000}
talker_config["spk_is_dialect"] = {args.speaker_name: False}
config_dict["talker_config"] = talker_config
with open(output_config_file, 'w', encoding='utf-8') as f:
json.dump(config_dict, f, indent=2, ensure_ascii=False)
# 保存模型权重
unwrapped_model = accelerator.unwrap_model(model)
state_dict = {k: v.detach().to("cpu") for k, v in unwrapped_model.state_dict().items()}
# 删除 speaker_encoder(替换为新的)
keys_to_drop = [k for k in state_dict.keys() if k.startswith("speaker_encoder")]
for k in keys_to_drop:
del state_dict[k]
# 用训练好的 speaker embedding 替换 ID=3000 的向量
weight = state_dict['talker.model.codec_embedding.weight']
state_dict['talker.model.codec_embedding.weight'][3000] = (
target_speaker_embedding[0].detach().to(weight.device).to(weight.dtype)
)
save_path = os.path.join(output_dir, "model.safetensors")
save_file(state_dict, save_path)
print(f"[Save] Checkpoint saved to: {output_dir}")
# 显示显存占用
if torch.cuda.is_available():
mem_allocated = torch.cuda.memory_allocated() / 1024**3
print(f"[GPU] Memory after epoch {epoch}: {mem_allocated:.2f} GB")
print("\n===== Training Done =====")
if __name__ == "__main__":
train()
运行之后开始训练
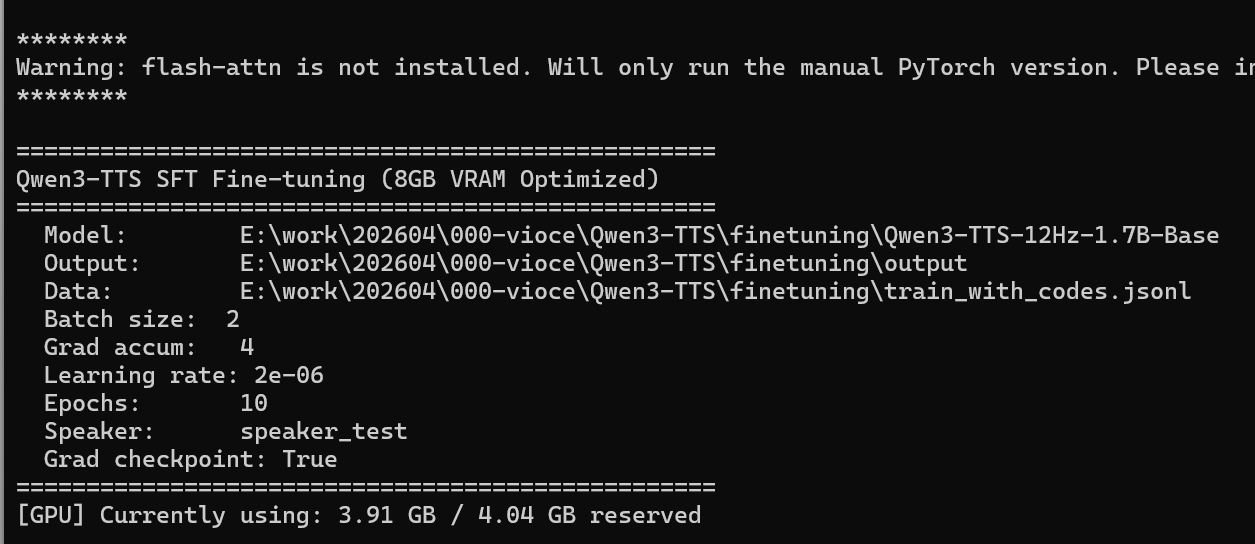
但是出现了问题
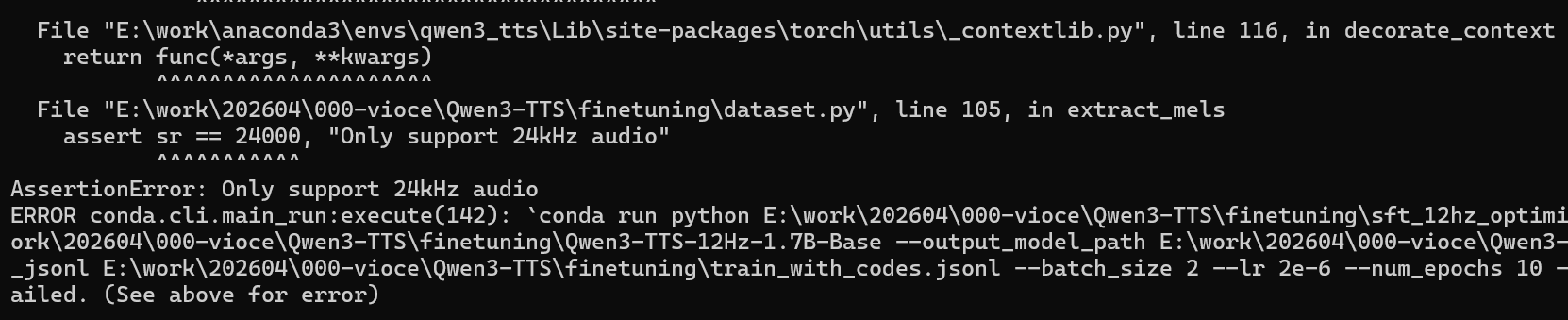
这里的报错是需要识别24kHz的音频文件,这里需要再适配一下
这里把
-
ye.wav→ye_24k.wav(转成 24kHz) - 重新拆分成 42 个 24kHz 音频片段(
segments24k/) - 生成
train_raw_24k.jsonl
这三步合并为同一个脚本处理
#!/usr/bin/env python3
"""
将 16kHz 音频重新转为 24kHz,并重新拆分,生成 train_raw_24k.jsonl
"""
import subprocess
import json
import os
import re
import math
# ===== 配置 =====
AUDIO_INPUT = r"E:\work\202604\000-vioce\Qwen3-TTS\test-data\ye.wav"
TEXT_PATH = r"E:\work\202604\000-vioce\Qwen3-TTS\test-data\ybf.txt"
REF_24K = r"E:\work\202604\000-vioce\Qwen3-TTS\test-data\ye_24k.wav"
SEG24K_DIR = r"E:\work\202604\000-vioce\Qwen3-TTS\test-data\segments24k"
OUTPUT_JSONL = r"XXXXXX\finetuning\train_raw_24k.jsonl"
NUM_SEGMENTS = 42 # 和之前保持一致
# ================
def get_duration(path):
result = subprocess.run(
["ffprobe", "-v", "quiet", "-print_format", "json", "-show_format", path],
capture_output=True, text=True
)
d = json.loads(result.stdout)
return float(d["format"]["duration"])
def step1_convert_24k():
print("\n===== Step 1: Convert ye.wav -> ye_24k.wav (24kHz) =====")
if os.path.exists(REF_24K):
print(f" {REF_24K} already exists, skipping")
return
cmd = [
"ffmpeg", "-y",
"-i", AUDIO_INPUT,
"-ar", "24000", "-ac", "1",
REF_24K
]
r = subprocess.run(cmd, capture_output=True, text=True)
if r.returncode != 0:
print(f" ERROR: {r.stderr[-300:]}")
return False
print(f" -> {REF_24K}")
return True
def step2_resplit_segments():
print("\n===== Step 2: Re-split into 24kHz segments =====")
os.makedirs(SEG24K_DIR, exist_ok=True)
duration = get_duration(REF_24K)
dur_per_seg = duration / NUM_SEGMENTS
print(f" Total duration: {duration:.1f}s, splitting into {NUM_SEGMENTS} segments @ {dur_per_seg:.1f}s each")
# 读取文本
with open(TEXT_PATH, "r", encoding="utf-8") as f:
raw = f.read()
lines = [l.strip() for l in raw.split("\n") if len(l.strip()) > 5]
full_text = "".join(lines)
chars = [c for c in full_text if "\u4e00" <= c <= "\u9fff" or c in ",。!?;:""'''…—"]
char_text = "".join(chars)
chars_per_sec = len(char_text) / duration
print(f" Effective Chinese chars: {len(char_text)}, rate: {chars_per_sec:.1f} chars/s")
chars_per_seg = math.ceil(len(char_text) / NUM_SEGMENTS)
seg_files = []
seg_texts = []
cur_time = 0.0
for i in range(NUM_SEGMENTS):
start = i * dur_per_seg
out_wav = os.path.join(SEG24K_DIR, f"seg_{i:03d}.wav")
cmd = [
"ffmpeg", "-y",
"-i", REF_24K,
"-ss", str(start),
"-t", str(dur_per_seg + 0.5),
"-ar", "24000", "-ac", "1",
out_wav
]
r = subprocess.run(cmd, capture_output=True, text=True)
if r.returncode != 0:
print(f" WARN seg {i}: ffmpeg failed")
continue
sc = i * chars_per_seg
ec = min((i + 1) * chars_per_seg, len(char_text))
seg_text = char_text[sc:ec]
if len(seg_text) < 5:
continue
seg_files.append(out_wav)
seg_texts.append(seg_text)
cur_time += dur_per_seg
print(f" Segments created: {len(seg_files)}")
return seg_files, seg_texts
def step3_write_jsonl(seg_files, seg_texts):
print("\n===== Step 3: Write train_raw_24k.jsonl =====")
os.makedirs(os.path.dirname(OUTPUT_JSONL), exist_ok=True)
ref_fw = REF_24K.replace("\\", "/")
with open(OUTPUT_JSONL, "w", encoding="utf-8") as f:
for wav_path, text in zip(seg_files, seg_texts):
wav_fw = wav_path.replace("\\", "/")
obj = {
"audio": wav_fw,
"text": text,
"ref_audio": ref_fw
}
f.write(json.dumps(obj, ensure_ascii=False) + "\n")
print(f" -> {OUTPUT_JSONL}")
print(f" Total: {len(seg_files)} samples")
# Show first 3
print("\n First 3 samples:")
for i, (wav, text) in enumerate(zip(seg_files[:3], seg_texts[:3])):
print(f" [{i}] {os.path.basename(wav)}: {text[:30]}...")
def main():
print("=" * 50)
print("Audio 16kHz -> 24kHz Resplit Script")
print("=" * 50)
ok = step1_convert_24k()
if not ok:
print("Conversion failed, abort.")
return
seg_files, seg_texts = step2_resplit_segments()
step3_write_jsonl(seg_files, seg_texts)
print("\n[DONE] Now run prepare_data.py with train_raw_24k.jsonl")
if __name__ == "__main__":
main()
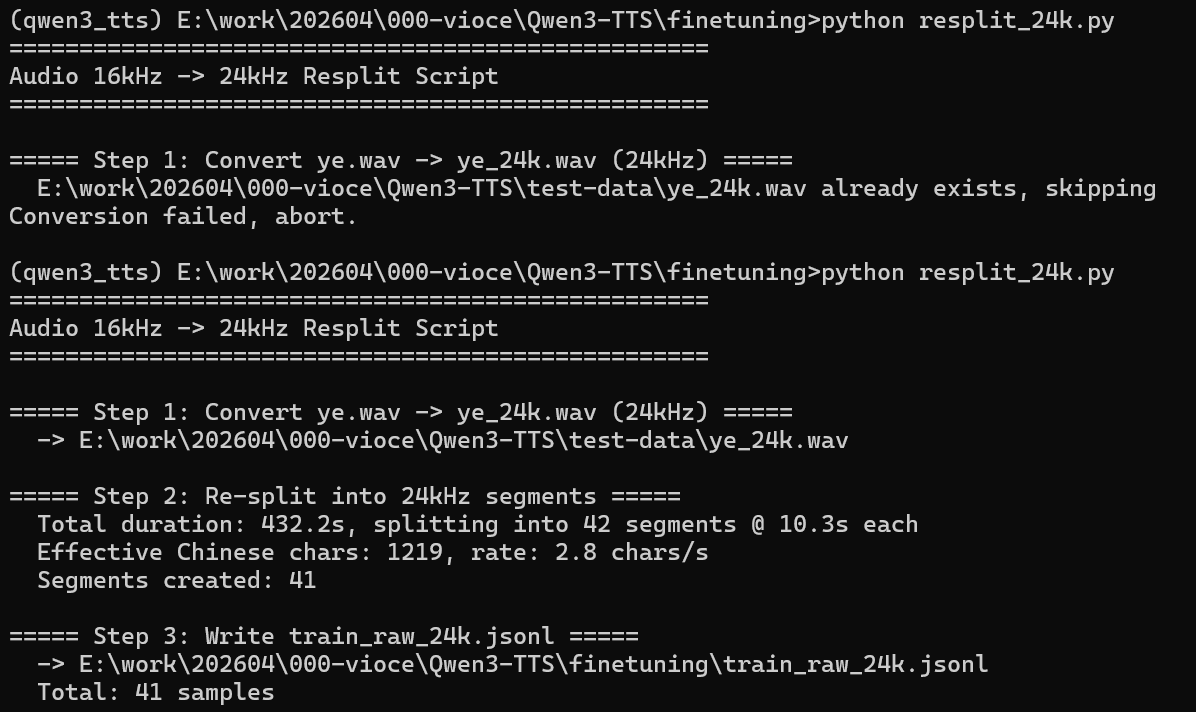
6、未完待续·
当前设备的安装记录只能到此为止了。因为后续的数据预处理部分cuda会OOM,属于显存不够。在更换了0.6模型,调低batch_size之后,也是没办法。还是经验不足,这个尝试也有点鲁莽。
(使用cpu也是可以跑的,但是时间会更长,而且可能问题更多)
好消息是另一个12G显存的4070显卡理论上是可以跑的,可以把这次的经验用在新的环境中,这次也是打下一些基础吧

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)