Java开发者AI转型第七课!AI失忆症克星!ChatMemory对话历史管理与上下文实战
大家好,我是直奔標杆,欢迎各位Java同仁来到《Spring AI 零基础到实战》专栏的第七课,咱们继续并肩前行,一步步搞定Spring AI实战技能,共同实现AI转型!
在上一节《Java开发者AI转型第六课!Spring AI 灵魂架构 Advisor 切面拦截与自定义实战》中,咱们一起吃透了现代Spring AI的核心——Advisor(顾问/切面拦截器)。掌握了这个高阶技能,咱们终于能直面AI应用开发中最头疼的难题:大模型的“7秒钟失忆症”,今天就带大家彻底解决它!
相信很多同仁在实际开发中都遇到过这样的问题,用代码调用大模型聊天时:
你问:“我叫张三,今年 6 岁。”
AI 答:“你好,张三小朋友。”
你紧接着问:“我几岁了?”
AI 答:“抱歉,我不知道你的年龄。”
是不是很困惑?网页版的Deepseek/ChatGPT能轻松记住上下文,为啥咱们通过API调用的大模型就成了“失忆症患者”?还有更实际的问题:如果同时有100个用户使用你的AI客服,怎么确保张三的聊天记忆不串到李四那里?服务器重启后,之前的聊天记录还能找回来吗?
这节课,咱们就借助上一节学到的Advisor机制,结合Spring AI强大的ChatMemory组件,手把手教大家给大模型装上“长久记忆”,同时实现多租户隔离和数据库持久化,直接适配生产环境,干货拉满,建议收藏跟着实操!
本节学习目标(共勉)
-
认知破局:搞懂大语言模型(LLM)的无状态(Stateless)本质,避开初学者常见误区;
-
自动化记忆:掌握MessageWindowChatMemory与MessageChatMemoryAdvisor的用法,实现零代码侵入的上下文自动拼接;
-
多租户隔离:巧用ChatMemory.CONVERSATION_ID,实现多用户会话的物理隔离,避免记忆串线;
-
记忆持久化:告别内存丢失问题,实战JdbcChatMemoryRepository,将对话记录永久存入MySQL数据库,适配生产级需求。
多租户记忆检索与装配引擎(核心原理拆解)
在动手写代码之前,咱们先通过一张逻辑图,搞清楚多用户场景下,Spring AI底层的记忆切面是如何工作的:
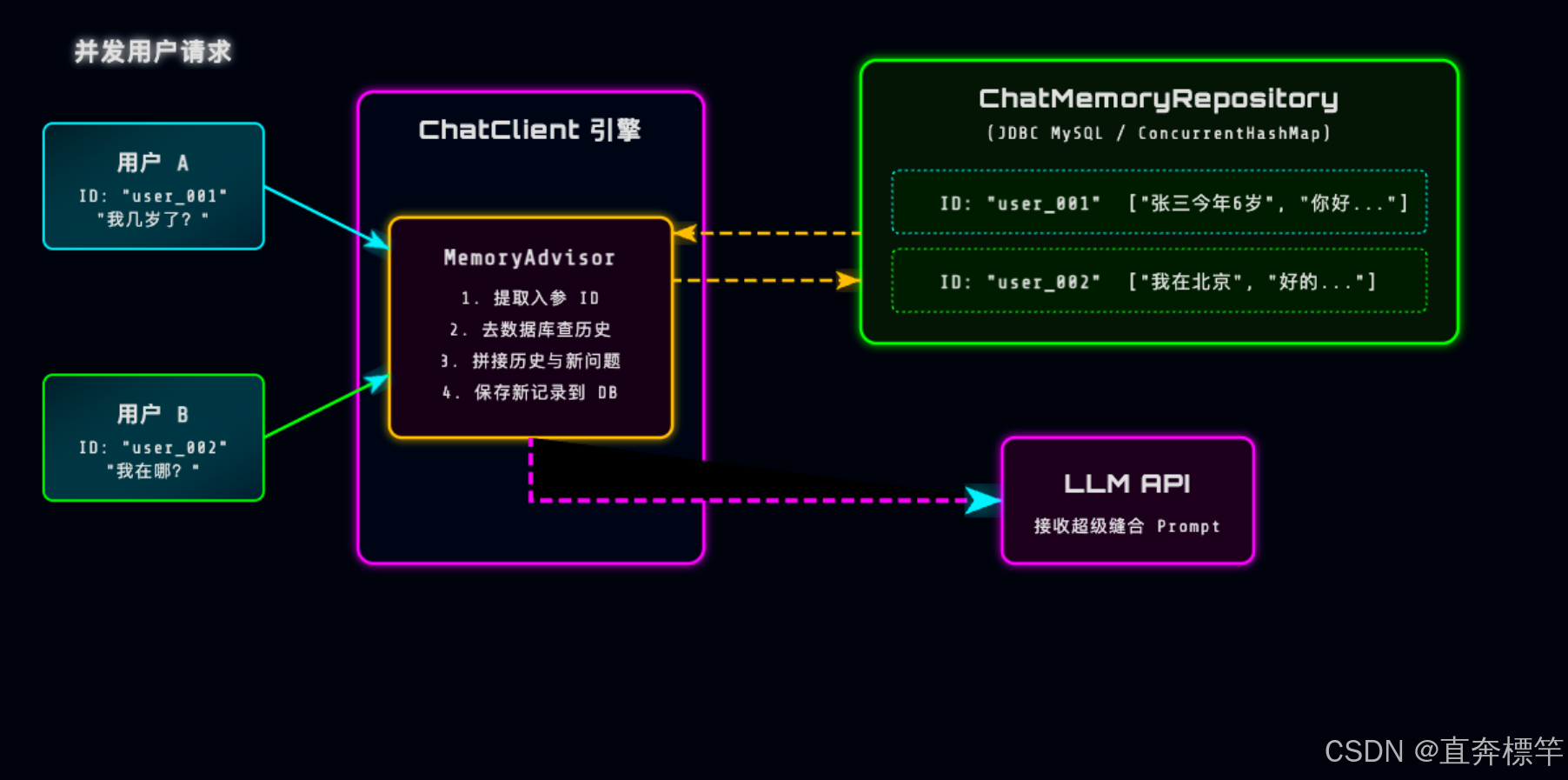
这张图的核心关键的就是ChatMemoryRepository,咱们可以把它类比成一个大型文件柜,方便大家记忆:
-
抽屉(Key):就是咱们传入的conversationId(会话ID,比如user_001,可对应用户唯一标识);
-
内容(Value):就是该用户与AI之前所有的聊天记录(List<Message>)。
每次收到用户的提问时,MemoryAdvisor会自动根据请求中的会话ID,从这个“文件柜”里取出该用户的历史聊天数据,自动拼接上下文,彻底省去咱们手动处理的繁琐操作,这就是Spring AI的强大之处!
深入理解:大模型为什么会“失忆”?
在动手写代码之前,咱们先纠正一个很多初学者都会踩的误区:不少同仁觉得,大模型是一个能随时记住数据的“智能伙伴”,其实不然。
无论是ChatGPT、DeepSeek还是通义千问,咱们调用它们的API时,其本质就是一个无状态(Stateless)的数学函数:f(prompt) = response。简单说,就是你的HTTP请求发过去,它只识别本次发送的文本内容;一旦请求结束,你的聊天数据就会被彻底清除,不会在它的内存中留存。
那网页版的Deepseek为什么能记住咱们之前说的话?答案很简单:它的前端或后端会悄悄帮咱们保存所有聊天记录,每次发送新消息时,系统会自动把“历史聊天记录+本次新问题”拼接成一个完整的Prompt,再打包发给大模型——说白了,就是手动帮大模型“记笔记”。
在Spring AI中,这些聊天记录被抽象成了两个核心接口,咱们重点掌握即可,不用死记原理,结合实操理解更高效:
-
ChatMemory:负责记忆管理策略(比如只保留最近10条消息,防止记忆过长撑爆Token,避免不必要的损耗);
-
ChatMemoryRepository:负责物理存储(决定聊天记录存在内存里,还是存入MySQL等数据库)。
实战上手:引入ChatMemory与Advisor(零代码侵入实现自动记忆)
咱们先回顾一下,不使用Spring AI框架时,AI开发中处理聊天记忆有多繁琐:需要手动创建List<Message>,每次对话后还要手动add()用户提问和AI回答,重复工作多,还容易出错。
而Spring AI框架已经帮咱们封装好了一切,借助ChatClient的流式API和内置Advisor,就能省去这些繁琐操作,咱们直接上手实操,步骤清晰,跟着做就能搞定!
第一步:注册全局记忆组件(Spring自动装配,无需手动写大量代码)
要让系统拥有记忆能力,首先需要在Spring容器中注册一个ChatMemory。最简洁的方式是使用MessageWindowChatMemory(滑动窗口记忆法),它会维护一个消息窗口,窗口大小不超过指定上限(默认20条消息),当消息数量超出上限时,会自动删除较旧的消息,但会保留系统消息。
重点来了:这一步咱们完全不用手动实现!当咱们引入模型相关的starter(比如spring-ai-starter-model-deepseek)时,Spring会自动向容器中注册ChatMemoryRepository和MessageWindowChatMemory,底层默认使用InMemoryChatMemoryRepository(本质就是ConcurrentHashMap),将数据存在JVM内存中,核心自动装配代码如下(大家可以参考理解,不用手动编写):
/**
* 自动装配逻辑(Spring默认实现,供大家参考学习)
*
* 账号:直奔標杆(CSDN),专注Java AI转型实战分享
*/
@AutoConfiguration
@ConditionalOnClass({ChatMemory.class, ChatMemoryRepository.class})
public class ChatMemoryAutoConfiguration {
@Bean
@ConditionalOnMissingBean
ChatMemoryRepository chatMemoryRepository() {
return new InMemoryChatMemoryRepository();
}
@Bean
@ConditionalOnMissingBean
ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder().chatMemoryRepository(chatMemoryRepository).build();
}
}这里重点提醒一下:@ConditionalOnMissingBean注解的作用是“当容器中没有该Bean时才自动注册”,这意味着咱们可以根据自己的需求,在项目配置中自行替换组件,灵活性拉满。
第二步:挂载Memory Advisor(将记忆组件绑定到ChatClient)
注册好全局记忆组件后,咱们需要将它通过拦截器挂载到ChatClient上,这样ChatClient就能自动调用记忆功能了,直接上Controller代码,注释详细,大家可以直接复制实操:
/**
* 自动记忆功能实战(可直接复制到项目中测试)
*
* @author 直奔標杆(CSDN),专注Java AI转型实战,与大家共同进步
*/
@RestController
public class AutoMemoryController {
private final ChatClient chatClient;
// 构造器注入 Builder 和 ChatMemory(推荐构造器注入,更规范)
public AutoMemoryController(ChatClient.Builder builder, ChatMemory chatMemory) {
this.chatClient = builder
// 为ChatClient挂载全局记忆拦截器,实现自动记忆
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.defaultSystem("你是一个贴心的私人助理,你需要努力记住用户的偏好。")
.build();
}
@GetMapping("/api/chat")
public String chatWithMemory(@RequestParam String msg) {
// 重点:配置Advisor后,每次call()前后都会自动读写chatMemory,无需手动处理
return chatClient.prompt()
.user(msg)
.call()
.content();
}
}测试验证(必做!加深理解)
咱们分两步测试,就能看到效果,非常直观:
-
先访问接口:/api/chat?msg=我叫张三,我最喜欢吃火锅。
-
再访问接口:/api/chat?msg=我是谁,我喜欢吃什么?
大家会发现,AI终于不再失忆,能准确回答出你的名字和喜好——这就是Advisor和ChatMemory的作用,自动帮咱们拼接了上下文!
关键优化:解决记忆“串线”问题(多租户隔离,生产级必备)
上面的代码虽然能实现自动记忆,但在真实服务器环境中会出现致命问题:咱们只注册了一个全局ChatMemory,如果张三和李四同时访问/api/chat接口,就会出现“串记忆”的情况——张三能看到李四的聊天记录,李四也能看到张三的,直接导致业务异常,这是生产环境绝对不能容忍的。
要实现多租户(多用户)的物理隔离,核心就是给每个用户分配一个专属的“记忆抽屉”,关键操作就是:每次请求时,通过ChatMemory.CONVERSATION_ID告诉Advisor,当前对话属于哪个用户。
咱们稍微改造一下Controller,就能完美解决这个问题,代码如下(重点修改部分已标注,可直接替换测试):
/**
* 多租户隔离版聊天接口(生产级可用)
* @param userId 用户唯一标识(比如登录用户的token、uuid等,确保唯一)
* @param msg 用户的新问题
*/
@GetMapping("/api/chat/isolated")
public String chatWithIsolatedMemory(
@RequestParam String userId,
@RequestParam String msg) {
return chatClient.prompt()
.user(msg)
// 重点:动态传入用户专属会话ID,实现记忆物理隔离(取值参考BaseChatMemoryAdvisor#getConversationId)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId))
// 备注:参数设置在call()时生效,可参考DefaultChatClientUtils#toChatClientRequest源码
.call()
.content();
}测试验证(多租户隔离效果)
按以下步骤测试,就能确认隔离效果,建议大家实际操作一遍:
-
访问:/api/chat/isolated?userId=zhangsan&msg=我叫张三
-
访问:/api/chat/isolated?userId=lisi&msg=我叫李四
-
交叉访问:/api/chat/isolated?userId=lisi&msg=你知道张三吗?
测试后会发现,李四的对话中无法获取张三的信息,多用户记忆物理隔离完美生效,再也不用担心串线问题!
进阶实战:从内存到JDBC数据库持久化(生产级落地关键)
咱们前面用到的InMemoryChatMemory,是将数据存在JVM的ConcurrentHashMap中,这就意味着:只要Spring Boot服务重启,所有的聊天记录都会丢失——这在开发测试环境没问题,但在生产环境中是绝对不可接受的。
Spring AI提供了官方JDBC存储方案,咱们只需几行代码,就能将聊天记录永久存入MySQL或PostgreSQL数据库,彻底解决内存丢失问题,直接适配生产环境,咱们一步步实操:
1. 引入JDBC相关依赖(pom.xml中添加)
首先引入JDBC记忆库的官方Starter和MySQL驱动,版本可根据自己的项目需求调整,代码如下:
<!-- JDBC 记忆库官方 Starter(Spring AI官方提供,直接引入即可) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
<version>${mysql.version}</version>
</dependency>2. 配置数据库连接(application.yml中配置)
在配置文件中填写MySQL连接信息,同时配置memory的初始化策略,重点是initialize-schema的设置,代码如下(注释详细,可直接复制修改):
spring:
ai:
chat:
memory:
repository:
jdbc:
# 初始化数据库:默认值为embedded(仅适配H2、HSQL等嵌入式数据库)
# 改为always,Spring AI启动时会自动创建表,无需手动建表
initialize-schema: always
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/springai?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowPublicKeyRetrieval=true&useSSL=false&allowMultiQueries=true
username: root # 替换为自己的MySQL用户名
password: 123456 # 替换为自己的MySQL密码重点提醒:配置initialize-schema: always后,Spring AI启动时会自动在MySQL中创建名为spring_ai_chat_memory的表,无需咱们手动建表,省去繁琐操作。
3. 将Memory库切换为JDBC驱动(手动配置,可选)
咱们可以手动构建ChatMemory,将存储方式切换为JDBC,代码如下(可直接复制到项目中,注释详细,方便理解):
package com.uka.springai.demo;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;
import org.springframework.ai.chat.memory.repository.jdbc.MysqlChatMemoryRepositoryDialect;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
/**
* JDBC 存储记忆配置(生产级实战,可直接复用)
*
* @author 直奔標杆(CSDN),分享Java AI转型实战经验,与大家共同成长
*/
@Configuration
public class AiMemoryConfig {
@Bean
public ChatMemory chatMemory(JdbcTemplate jdbcTemplate) {
// 1. 构建基于MySQL语法的JDBC记忆库,也可通过@Bean覆盖默认的内存存储
JdbcChatMemoryRepository repository = JdbcChatMemoryRepository.builder()
.jdbcTemplate(jdbcTemplate)
// 重点:设置MySQL方言,适配MySQL数据库
.dialect(new MysqlChatMemoryRepositoryDialect())
.build();
// 2. 将JDBC记忆库注入到滑动窗口策略中
return MessageWindowChatMemory.builder()
.chatMemoryRepository(repository)
.build();
}
}配置完成后,再调用之前的/api/chat/isolated接口,所有的对话记录都会被永久存入MySQL数据库——即使服务器断电、重启,只要传入相同的userId,大模型就能精准回忆起之前的所有对话,彻底解决记忆丢失问题!
补充知识点:JDBC自动装配(无需手动配置,更便捷)
上面咱们演示的是手动构建ChatMemory,其实还有更便捷的方式:由于咱们引入了spring-ai-starter-model-chat-memory-repository-jdbc,Spring会自动帮咱们装配JdbcChatMemoryRepository,因此上面第3步的手动替换操作,咱们可以选择忽略,Spring会自动覆盖默认的内存存储。
给大家贴出Spring的自动装配代码,方便大家理解底层逻辑(不用手动编写,参考学习即可):
@AutoConfiguration(
after = {JdbcTemplateAutoConfiguration.class},
// 关键:在ChatMemoryAutoConfiguration之前执行,实现对内存存储的覆盖
before = {ChatMemoryAutoConfiguration.class}
)
@ConditionalOnClass({JdbcChatMemoryRepository.class, DataSource.class, JdbcTemplate.class})
@EnableConfigurationProperties({JdbcChatMemoryRepositoryProperties.class})
public class JdbcChatMemoryRepositoryAutoConfiguration {
@Bean
@ConditionalOnMissingBean
JdbcChatMemoryRepository jdbcChatMemoryRepository(JdbcTemplate jdbcTemplate, DataSource dataSource) {
// 根据数据库配置,自动获取对应的数据库方言
JdbcChatMemoryRepositoryDialect dialect = JdbcChatMemoryRepositoryDialect.from(dataSource);
return JdbcChatMemoryRepository.builder().jdbcTemplate(jdbcTemplate).dialect(dialect).build();
}
// 其余自动装配逻辑省略,大家可自行查看Spring AI源码学习
}本节课总结(共勉复盘)
本节课咱们重点攻克了大模型“失忆”的核心难题,结合Spring AI的Advisor机制和ChatMemory组件,实现了AI的长久记忆,同时完成了多租户隔离和数据库持久化,直接达到生产级标准,咱们一起复盘一下核心要点:
-
依托MessageChatMemoryAdvisor切面机制,彻底省去了手动拼接聊天历史的繁琐代码,实现零代码侵入的自动记忆;
-
通过ChatMemory.CONVERSATION_ID,轻松实现多用户会话的物理隔离,解决了记忆串线的生产级痛点;
-
引入JdbcChatMemoryRepository,无需修改核心业务代码,就能将记忆从内存平滑迁移到MySQL数据库,彻底解决记忆丢失问题。
建议大家课后多动手实操一遍,把代码跑起来,感受Spring AI的便捷性,遇到问题可以在评论区留言,咱们一起交流解决,共同进步!
下节预告(精彩继续)
随着用户与AI的聊天次数增多,记忆中的上下文会越来越多,这会导致传递给大模型的Prompt越来越大——不仅会让API计费暴涨(Token成本太高),还可能超出大模型的窗口限制,直接报错OOM,这也是生产环境中必须解决的问题。
下一节课,咱们将带来《Java开发者AI转型第八课!避开Token陷阱!Spring AI记忆裁剪源码解析与Token级防溢出核心技巧》,深入剖析Token的本质,教大家如何在Spring AI中精确计算和动态裁剪长文本,守住钱包和服务器的底线!
干货持续输出,咱们下节不见不散!
往期实战内容(连贯学习,效果更佳)
-
Java开发者AI转型第四课!告别硬编码!Spring AI 提示词模板 (Prompt) 注入与多模态识图全攻略
-
Java开发者AI转型第五课!让AI懂规矩!Spring AI 结构化输出 (DTO) 映射与 Flux 流式打字机极速响应
-
Java开发者AI转型第六课!Spring AI 灵魂架构 Advisor 切面拦截与自定义实战
我是直奔標杆,专注Java开发者AI转型实战分享,每天进步一点点,一起向标杆靠拢!觉得本文有用的话,欢迎点赞、收藏、关注,评论区交流实操心得~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)