项目实战:Minimind复现——从0训练一个64M小型GPT
一、项目介绍
项目链接:https://github.com/jingyaogong/minimind
大语言模型(Large Language Model, LLM)的出现,引发了全球范围内对 AI 的空前关注。无论是 ChatGPT、DeepSeek 还是 Qwen,都以惊艳的效果让人真切感受到这场技术浪潮的冲击力。然而,动辄数百亿参数的模型规模,使得它们对个人设备而言不仅难以训练,甚至连部署都显得遥不可及。打开大模型的“黑盒子”,真正去理解其内部运作机制,本应是一件令人心潮澎湃的事。遗憾的是,绝大多数探索最终都止步于使用 LoRA 等技术对现有大模型做少量微调,学习一些新指令或特定任务。这更像是在教牛顿如何使用 21 世纪的智能手机——虽然有趣,却偏离了理解物理本质的初衷。
与此同时,第三方的大模型框架与工具库,如 transformers / trl / peft 等,往往只暴露出高度抽象的接口。只需短短十几行代码,就可以完成“加载模型 + 加载数据集 + 推理 + 强化学习”的全流程训练。这种高效封装固然便利,却也在一定程度上把开发者与底层实现隔离开来,削弱了深入理解 LLM 核心代码的机会。我认为 “用乐高自己拼出一架飞机,远比坐在头等舱里飞行更让人兴奋”,然而更现实的问题是,互联网上充斥着大量付费课程和营销内容,用漏洞百出、一知半解的讲解包装所谓的 AI 教程。正因如此,本项目的初衷就是尽可能降低 LLM 的学习门槛,让每个人都能从理解每一行代码开始,从 0 开始亲手训练一个极小的语言模型。是的,从零开始训练,而不是仅仅停留在推理层面。最低只需不到 3 块钱的服务器成本,就能亲身体验从 0 到 1 构建一个语言模型的全过程。
二、复现过程
2.1 环境搭建
在Autodl云服务器平台上租用一张RTX5090显卡
启动服务器,在终端中执行:
# 克隆仓库、安装依赖
git clone --depth 1 https://github.com/jingyaogong/minimind
cd minimind
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
2.2 数据集准备
首先设置学术资源加速,在终端执行:
source /etc/network_turbo所有训练数据保存在dataset文件夹下面,获取数据:
cd minimind
cd dataset
wget "https://huggingface.co/datasets/jingyaogong/minimind_dataset/resolve/main/pretrain_t2t_mini.jsonl"
wget "https://huggingface.co/datasets/jingyaogong/minimind_dataset/resolve/main/sft_t2t_mini.jsonl"
2.3 模型架构解读
整体代码如下:
import math, torch, torch.nn.functional as F
from torch import nn
from transformers.activations import ACT2FN
from transformers import PreTrainedModel, GenerationMixin, PretrainedConfig
from transformers.modeling_outputs import MoeCausalLMOutputWithPast
# 🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏
# MiniMind Config
# 🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏
class MiniMindConfig(PretrainedConfig):
model_type = "minimind"
def __init__(self, hidden_size=768, num_hidden_layers=8, use_moe=False, **kwargs):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.use_moe = use_moe
self.dropout = kwargs.get("dropout", 0.0)
self.vocab_size = kwargs.get("vocab_size", 6400)
self.bos_token_id = kwargs.get("bos_token_id", 1)
self.eos_token_id = kwargs.get("eos_token_id", 2)
self.flash_attn = kwargs.get("flash_attn", True)
self.num_attention_heads = kwargs.get("num_attention_heads", 8)
self.num_key_value_heads = kwargs.get("num_key_value_heads", 4)
self.head_dim = kwargs.get("head_dim", self.hidden_size // self.num_attention_heads)
self.hidden_act = kwargs.get("hidden_act", 'silu')
self.intermediate_size = kwargs.get("intermediate_size", math.ceil(hidden_size * math.pi / 64) * 64)
self.max_position_embeddings = kwargs.get("max_position_embeddings", 32768)
self.rms_norm_eps = kwargs.get("rms_norm_eps", 1e-6)
self.rope_theta = kwargs.get("rope_theta", 1e6)
self.tie_word_embeddings = kwargs.get("tie_word_embeddings", True)
self.inference_rope_scaling = kwargs.get("inference_rope_scaling", False)
self.rope_scaling = {
"beta_fast": 32,
"beta_slow": 1,
"factor": 16,
"original_max_position_embeddings": 2048,
"attention_factor": 1.0,
"type": "yarn"
} if self.inference_rope_scaling else None
### MoE specific configs (ignored if use_moe = False)
self.num_experts = kwargs.get("num_experts", 4)
self.num_experts_per_tok = kwargs.get("num_experts_per_tok", 1)
self.moe_intermediate_size = kwargs.get("moe_intermediate_size", self.intermediate_size)
self.norm_topk_prob = kwargs.get("norm_topk_prob", True)
self.router_aux_loss_coef = kwargs.get("router_aux_loss_coef", 5e-4)
# 🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏
# MiniMind Model
# 🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏🌎🌍🌏
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
return (self.weight * self.norm(x.float())).type_as(x)
def precompute_freqs_cis(dim: int, end: int = int(32 * 1024), rope_base: float = 1e6, rope_scaling: dict = None):
freqs, attn_factor = 1.0 / (rope_base ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)), 1.0
if rope_scaling is not None: # YaRN: f'(i) = f(i)((1-γ) + γ/s), where γ∈[0,1] is linear ramp
orig_max, factor, beta_fast, beta_slow, attn_factor = (
rope_scaling.get("original_max_position_embeddings", 2048), rope_scaling.get("factor", 16),
rope_scaling.get("beta_fast", 32.0), rope_scaling.get("beta_slow", 1.0), rope_scaling.get("attention_factor", 1.0)
)
if end / orig_max > 1.0:
inv_dim = lambda b: (dim * math.log(orig_max / (b * 2 * math.pi))) / (2 * math.log(rope_base))
low, high = max(math.floor(inv_dim(beta_fast)), 0), min(math.ceil(inv_dim(beta_slow)), dim // 2 - 1)
ramp = torch.clamp((torch.arange(dim // 2, device=freqs.device).float() - low) / max(high - low, 0.001), 0, 1)
freqs = freqs * (1 - ramp + ramp / factor)
t = torch.arange(end, device=freqs.device)
freqs = torch.outer(t, freqs).float()
freqs_cos = torch.cat([torch.cos(freqs), torch.cos(freqs)], dim=-1) * attn_factor
freqs_sin = torch.cat([torch.sin(freqs), torch.sin(freqs)], dim=-1) * attn_factor
return freqs_cos, freqs_sin
def apply_rotary_pos_emb(q, k, cos, sin, unsqueeze_dim=1):
def rotate_half(x): return torch.cat((-x[..., x.shape[-1] // 2:], x[..., : x.shape[-1] // 2]), dim=-1)
q_embed = ((q * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(q) * sin.unsqueeze(unsqueeze_dim))).to(q.dtype)
k_embed = ((k * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(k) * sin.unsqueeze(unsqueeze_dim))).to(k.dtype)
return q_embed, k_embed
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
bs, slen, num_key_value_heads, head_dim = x.shape
if n_rep == 1: return x
return (x[:, :, :, None, :].expand(bs, slen, num_key_value_heads, n_rep, head_dim).reshape(bs, slen, num_key_value_heads * n_rep, head_dim))
class Attention(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
self.num_key_value_heads = config.num_attention_heads if config.num_key_value_heads is None else config.num_key_value_heads
self.n_local_heads = config.num_attention_heads
self.n_local_kv_heads = self.num_key_value_heads
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = config.head_dim
self.is_causal = True
self.q_proj = nn.Linear(config.hidden_size, config.num_attention_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(config.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(config.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim, config.hidden_size, bias=False)
self.q_norm = RMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.k_norm = RMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.dropout = config.dropout
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and config.flash_attn
def forward(self, x, position_embeddings, past_key_value=None, use_cache=False, attention_mask=None):
bsz, seq_len, _ = x.shape
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xq, xk = self.q_norm(xq), self.k_norm(xk)
cos, sin = position_embeddings
xq, xk = apply_rotary_pos_emb(xq, xk, cos, sin)
if past_key_value is not None:
xk = torch.cat([past_key_value[0], xk], dim=1)
xv = torch.cat([past_key_value[1], xv], dim=1)
past_kv = (xk, xv) if use_cache else None
xq, xk, xv = (xq.transpose(1, 2), repeat_kv(xk, self.n_rep).transpose(1, 2), repeat_kv(xv, self.n_rep).transpose(1, 2))
if self.flash and (seq_len > 1) and (not self.is_causal or past_key_value is None) and (attention_mask is None or torch.all(attention_mask == 1)):
output = F.scaled_dot_product_attention(xq, xk, xv, dropout_p=self.dropout if self.training else 0.0, is_causal=self.is_causal)
else:
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)
if self.is_causal: scores[:, :, :, -seq_len:] += torch.full((seq_len, seq_len), float("-inf"), device=scores.device).triu(1)
if attention_mask is not None: scores += (1.0 - attention_mask.unsqueeze(1).unsqueeze(2)) * -1e9
output = self.attn_dropout(F.softmax(scores.float(), dim=-1).type_as(xq)) @ xv
output = output.transpose(1, 2).reshape(bsz, seq_len, -1)
output = self.resid_dropout(self.o_proj(output))
return output, past_kv
class FeedForward(nn.Module):
def __init__(self, config: MiniMindConfig, intermediate_size: int = None):
super().__init__()
intermediate_size = intermediate_size or config.intermediate_size
self.gate_proj = nn.Linear(config.hidden_size, intermediate_size, bias=False)
self.down_proj = nn.Linear(intermediate_size, config.hidden_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, intermediate_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
class MOEFeedForward(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
self.config = config
self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)
self.experts = nn.ModuleList([FeedForward(config, intermediate_size=config.moe_intermediate_size) for _ in range(config.num_experts)])
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
batch_size, seq_len, hidden_dim = x.shape
x_flat = x.view(-1, hidden_dim)
scores = F.softmax(self.gate(x_flat), dim=-1)
topk_weight, topk_idx = torch.topk(scores, k=self.config.num_experts_per_tok, dim=-1, sorted=False)
if self.config.norm_topk_prob: topk_weight = topk_weight / (topk_weight.sum(dim=-1, keepdim=True) + 1e-20)
y = torch.zeros_like(x_flat)
for i, expert in enumerate(self.experts):
mask = (topk_idx == i)
if mask.any():
token_idx = mask.any(dim=-1).nonzero().flatten()
weight = topk_weight[mask].view(-1, 1)
y.index_add_(0, token_idx, (expert(x_flat[token_idx]) * weight).to(y.dtype))
elif self.training:
y[0, 0] += 0 * sum(p.sum() for p in expert.parameters())
if self.training and self.config.router_aux_loss_coef > 0:
load = F.one_hot(topk_idx, self.config.num_experts).float().mean(0)
self.aux_loss = (load * scores.mean(0)).sum() * self.config.num_experts * self.config.router_aux_loss_coef
else:
self.aux_loss = scores.new_zeros(1).squeeze()
return y.view(batch_size, seq_len, hidden_dim)
class MiniMindBlock(nn.Module):
def __init__(self, layer_id: int, config: MiniMindConfig):
super().__init__()
self.self_attn = Attention(config)
self.input_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.mlp = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
def forward(self, hidden_states, position_embeddings, past_key_value=None, use_cache=False, attention_mask=None):
residual = hidden_states
hidden_states, present_key_value = self.self_attn(
self.input_layernorm(hidden_states), position_embeddings,
past_key_value, use_cache, attention_mask
)
hidden_states += residual
hidden_states = hidden_states + self.mlp(self.post_attention_layernorm(hidden_states))
return hidden_states, present_key_value
class MiniMindModel(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
self.config = config
self.vocab_size, self.num_hidden_layers = config.vocab_size, config.num_hidden_layers
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.dropout = nn.Dropout(config.dropout)
self.layers = nn.ModuleList([MiniMindBlock(l, config) for l in range(self.num_hidden_layers)])
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
freqs_cos, freqs_sin = precompute_freqs_cis(dim=config.head_dim, end=config.max_position_embeddings, rope_base=config.rope_theta, rope_scaling=config.rope_scaling)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)
def forward(self, input_ids, attention_mask=None, past_key_values=None, use_cache=False, **kwargs):
batch_size, seq_length = input_ids.shape
if hasattr(past_key_values, 'layers'): past_key_values = None
past_key_values = past_key_values or [None] * len(self.layers)
start_pos = past_key_values[0][0].shape[1] if past_key_values[0] is not None else 0
hidden_states = self.dropout(self.embed_tokens(input_ids))
# Recompute RoPE buffers lost during meta-device init (transformers>=5.x)
if self.freqs_cos[0, 0] == 0:
freqs_cos, freqs_sin = precompute_freqs_cis(dim=self.config.head_dim, end=self.config.max_position_embeddings, rope_base=self.config.rope_theta, rope_scaling=self.config.rope_scaling)
self.freqs_cos, self.freqs_sin = freqs_cos.to(hidden_states.device), freqs_sin.to(hidden_states.device)
position_embeddings = (self.freqs_cos[start_pos:start_pos + seq_length], self.freqs_sin[start_pos:start_pos + seq_length])
presents = []
for layer, past_key_value in zip(self.layers, past_key_values):
hidden_states, present = layer(
hidden_states,
position_embeddings,
past_key_value=past_key_value,
use_cache=use_cache,
attention_mask=attention_mask
)
presents.append(present)
hidden_states = self.norm(hidden_states)
aux_loss = sum([l.mlp.aux_loss for l in self.layers if isinstance(l.mlp, MOEFeedForward)], hidden_states.new_zeros(1).squeeze())
return hidden_states, presents, aux_loss
class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):
config_class = MiniMindConfig
_tied_weights_keys = {"lm_head.weight": "model.embed_tokens.weight"}
def __init__(self, config: MiniMindConfig = None):
self.config = config or MiniMindConfig()
super().__init__(self.config)
self.model = MiniMindModel(self.config)
self.lm_head = nn.Linear(self.config.hidden_size, self.config.vocab_size, bias=False)
if self.config.tie_word_embeddings: self.model.embed_tokens.weight = self.lm_head.weight
self.post_init()
def forward(self, input_ids, attention_mask=None, past_key_values=None, use_cache=False, logits_to_keep=0, labels=None, **kwargs):
hidden_states, past_key_values, aux_loss = self.model(input_ids, attention_mask, past_key_values, use_cache, **kwargs)
slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
logits = self.lm_head(hidden_states[:, slice_indices, :])
loss = None
if labels is not None:
x, y = logits[..., :-1, :].contiguous(), labels[..., 1:].contiguous()
loss = F.cross_entropy(x.view(-1, x.size(-1)), y.view(-1), ignore_index=-100)
return MoeCausalLMOutputWithPast(loss=loss, aux_loss=aux_loss, logits=logits, past_key_values=past_key_values, hidden_states=hidden_states)
# https://github.com/jingyaogong/minimind/discussions/611
@torch.inference_mode()
def generate(self, inputs=None, attention_mask=None, max_new_tokens=8192, temperature=0.85, top_p=0.85, top_k=50, eos_token_id=2, streamer=None, use_cache=True, num_return_sequences=1, do_sample=True, repetition_penalty=1.0, **kwargs):
input_ids = kwargs.pop("input_ids", inputs).repeat(num_return_sequences, 1)
attention_mask = attention_mask.repeat(num_return_sequences, 1) if attention_mask is not None else None
past_key_values = kwargs.pop("past_key_values", None)
finished = torch.zeros(input_ids.shape[0], dtype=torch.bool, device=input_ids.device)
if streamer: streamer.put(input_ids.cpu())
for _ in range(max_new_tokens):
past_len = past_key_values[0][0].shape[1] if past_key_values else 0
outputs = self.forward(input_ids[:, past_len:], attention_mask, past_key_values, use_cache=use_cache, **kwargs)
attention_mask = torch.cat([attention_mask, attention_mask.new_ones(attention_mask.shape[0], 1)], -1) if attention_mask is not None else None
logits = outputs.logits[:, -1, :] / temperature
if repetition_penalty != 1.0:
for i in range(input_ids.shape[0]): logits[i, torch.unique(input_ids[i])] /= repetition_penalty
if top_k > 0:
logits[logits < torch.topk(logits, top_k)[0][..., -1, None]] = -float('inf')
if top_p < 1.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
mask = torch.cumsum(torch.softmax(sorted_logits, dim=-1), dim=-1) > top_p
mask[..., 1:], mask[..., 0] = mask[..., :-1].clone(), 0
logits[mask.scatter(1, sorted_indices, mask)] = -float('inf')
next_token = torch.multinomial(torch.softmax(logits, dim=-1), num_samples=1) if do_sample else torch.argmax(logits, dim=-1, keepdim=True)
if eos_token_id is not None: next_token = torch.where(finished.unsqueeze(-1), next_token.new_full((next_token.shape[0], 1), eos_token_id), next_token)
input_ids = torch.cat([input_ids, next_token], dim=-1)
past_key_values = outputs.past_key_values if use_cache else None
if streamer: streamer.put(next_token.cpu())
if eos_token_id is not None:
finished |= next_token.squeeze(-1).eq(eos_token_id)
if finished.all(): break
if streamer: streamer.end()
if kwargs.get("return_kv"): return {'generated_ids': input_ids, 'past_kv': past_key_values}
return input_ids该模型是一个Decoder Only的架构,有以下几个特点:
1.支持标准稠密模型 + 混合专家模型(MoE) 双模式
2.内置现代 LLM 全部优化:RoPE 位置编码、GQA 分组注意力、RMSNorm、FlashAttention
3.兼容 Hugging Face 格式,可直接训练、推理、生成文本
4.轻量化设计,适合在小显存显卡上运行
class MiniMindConfig(PretrainedConfig): 统一管理所有超参数
use_moe=False:普通小模型(速度快)
use_moe=True:MoE 模型(性能更强,显存占用低)
max_position_embeddings=32768:支持 32k 长文本
self.num_attention_heads = 8:注意力头数
self.num_key_value_heads = 4:GQA:KV 头数 < Q 头数(节省显存)
class RMSNorm(torch.nn.Module): RMSNorm归一化层
这已经是现代LLM 标配归一化,比传统 LayerNorm 更快、更稳定,无偏置,计算量更小
def precompute_freqs_cis(...) :预计算旋转编码
def apply_rotary_pos_emb(...) :给 Q/K 施加旋转编码
repeat_kv:GQA 分组查询注意力
class Attention(nn.Module): Attention 注意力层
支持 FlashAttention,速度提升 50%+,显存减半
支持 GQA,小显存也能跑长文本
支持 KV Cache,推理加速
class FeedForward(nn.Module): 前馈神经网络层,标准Transformer 的特征提取层,但是SwiGLU 激活是 现代LLM 标配
class MOEFeedForward(nn.Module): MoE 核心原理是把 1 个大 FFN 拆成 4 个小专家;每个 token 只激活 1 个专家;性能不变,但显存大幅降低
class MiniMindBlock(nn.Module): 单个Transformer block,输入 → 归一化 → 注意力 → 残差 → 归一化 → FFN/MoE → 残差
class MiniMindModel(nn.Module): 主干模型结构,把输入的 token id 转为向量;堆叠 N 层 minimind block;输出高层语义特征
class MiniMindForCausalLM(PreTrainedModel, GenerationMixin): 这是最终可直接用的模型类,对接 HuggingFace 标准接口;前向传播带有损失函数,支持更新参数;generate函数负责推理生成
后续文章如果有机会会更加详细介绍每一块技术栈的具体工作机制、原理以及代码实现,请关注后续blog。
2.4 预训练
准备好数据集之后,可以开始进行预训练,预训练代码如下:
import os
import sys
__package__ = "trainer"
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import argparse
import time
import warnings
import torch
import torch.distributed as dist
from contextlib import nullcontext
from torch import optim, nn
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data import DataLoader, DistributedSampler
from model.model_minimind import MiniMindConfig
from dataset.lm_dataset import PretrainDataset
from trainer.trainer_utils import get_lr, Logger, is_main_process, lm_checkpoint, init_distributed_mode, setup_seed, init_model, SkipBatchSampler
warnings.filterwarnings('ignore')
def train_epoch(epoch, loader, iters, start_step=0, wandb=None):
start_time = time.time()
last_step = start_step
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
input_ids = input_ids.to(args.device)
labels = labels.to(args.device)
last_step = step
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
with autocast_ctx:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss
loss = loss / args.accumulation_steps
scaler.scale(loss).backward()
if step % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
if step % args.log_interval == 0 or step == iters:
spend_time = time.time() - start_time
current_loss = loss.item() * args.accumulation_steps
current_aux_loss = res.aux_loss.item() if res.aux_loss is not None else 0.0
current_logits_loss = current_loss - current_aux_loss
current_lr = optimizer.param_groups[-1]['lr']
eta_min = spend_time / max(step - start_step, 1) * (iters - step) // 60
Logger(f'Epoch:[{epoch + 1}/{args.epochs}]({step}/{iters}), loss: {current_loss:.4f}, logits_loss: {current_logits_loss:.4f}, aux_loss: {current_aux_loss:.4f}, lr: {current_lr:.8f}, epoch_time: {eta_min:.1f}min')
if wandb: wandb.log({"loss": current_loss, "logits_loss": current_logits_loss, "aux_loss": current_aux_loss, "learning_rate": current_lr, "epoch_time": eta_min})
if (step % args.save_interval == 0 or step == iters) and is_main_process():
model.eval()
moe_suffix = '_moe' if lm_config.use_moe else ''
ckp = f'{args.save_dir}/{args.save_weight}_{lm_config.hidden_size}{moe_suffix}.pth'
raw_model = model.module if isinstance(model, DistributedDataParallel) else model
raw_model = getattr(raw_model, '_orig_mod', raw_model)
state_dict = raw_model.state_dict()
torch.save({k: v.half().cpu() for k, v in state_dict.items()}, ckp)
lm_checkpoint(lm_config, weight=args.save_weight, model=model, optimizer=optimizer, scaler=scaler, epoch=epoch, step=step, wandb=wandb, save_dir='../checkpoints')
model.train()
del state_dict
del input_ids, labels, res, loss
if last_step > start_step and last_step % args.accumulation_steps != 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="MiniMind Pretraining")
parser.add_argument("--save_dir", type=str, default="../out", help="模型保存目录")
parser.add_argument('--save_weight', default='pretrain', type=str, help="保存权重的前缀名")
parser.add_argument("--epochs", type=int, default=2, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=32, help="batch size")
parser.add_argument("--learning_rate", type=float, default=5e-4, help="初始学习率")
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu", help="训练设备")
parser.add_argument("--dtype", type=str, default="bfloat16", help="混合精度类型")
parser.add_argument("--num_workers", type=int, default=8, help="数据加载线程数")
parser.add_argument("--accumulation_steps", type=int, default=8, help="梯度累积步数")
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
parser.add_argument("--log_interval", type=int, default=100, help="日志打印间隔")
parser.add_argument("--save_interval", type=int, default=1000, help="模型保存间隔")
parser.add_argument('--hidden_size', default=768, type=int, help="隐藏层维度")
parser.add_argument('--num_hidden_layers', default=8, type=int, help="隐藏层数量")
parser.add_argument('--max_seq_len', default=340, type=int, help="训练的最大截断长度(中文1token≈1.5~1.7字符)")
parser.add_argument('--use_moe', default=0, type=int, choices=[0, 1], help="是否使用MoE架构(0=否,1=是)")
parser.add_argument("--data_path", type=str, default="../dataset/pretrain_t2t_mini.jsonl", help="预训练数据路径")
parser.add_argument('--from_weight', default='none', type=str, help="基于哪个权重训练,为none则从头开始")
parser.add_argument('--from_resume', default=0, type=int, choices=[0, 1], help="是否自动检测&续训(0=否,1=是)")
parser.add_argument("--use_wandb", action="store_true", help="是否使用wandb")
parser.add_argument("--wandb_project", type=str, default="MiniMind-Pretrain", help="wandb项目名")
parser.add_argument("--use_compile", default=0, type=int, choices=[0, 1], help="是否使用torch.compile加速(0=否,1=是)")
args = parser.parse_args()
# ========== 1. 初始化环境和随机种子 ==========
local_rank = init_distributed_mode()
if dist.is_initialized(): args.device = f"cuda:{local_rank}"
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
# ========== 2. 配置目录、模型参数、检查ckp ==========
os.makedirs(args.save_dir, exist_ok=True)
lm_config = MiniMindConfig(hidden_size=args.hidden_size, num_hidden_layers=args.num_hidden_layers, use_moe=bool(args.use_moe))
ckp_data = lm_checkpoint(lm_config, weight=args.save_weight, save_dir='../checkpoints') if args.from_resume==1 else None
# ========== 3. 设置混合精度 ==========
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
# ========== 4. 配wandb ==========
wandb = None
if args.use_wandb and is_main_process():
import swanlab as wandb
wandb_id = ckp_data.get('wandb_id') if ckp_data else None
resume = 'must' if wandb_id else None
wandb_run_name = f"MiniMind-Pretrain-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}"
wandb.init(project=args.wandb_project, name=wandb_run_name, id=wandb_id, resume=resume)
# ========== 5. 定义模型、数据、优化器 ==========
model, tokenizer = init_model(lm_config, args.from_weight, device=args.device)
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == 'float16'))
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
# ========== 6. 从ckp恢复状态 ==========
start_epoch, start_step = 0, 0
if ckp_data:
model.load_state_dict(ckp_data['model'])
optimizer.load_state_dict(ckp_data['optimizer'])
scaler.load_state_dict(ckp_data['scaler'])
start_epoch = ckp_data['epoch']
start_step = ckp_data.get('step', 0)
# ========== 7. 编译和分布式包装 ==========
if args.use_compile == 1:
model = torch.compile(model)
Logger('torch.compile enabled')
if dist.is_initialized():
model = DistributedDataParallel(model, device_ids=[local_rank])
# ========== 8. 开始训练 ==========
for epoch in range(start_epoch, args.epochs):
train_sampler and train_sampler.set_epoch(epoch)
setup_seed(42 + epoch); indices = torch.randperm(len(train_ds)).tolist()
skip = start_step if (epoch == start_epoch and start_step > 0) else 0
batch_sampler = SkipBatchSampler(train_sampler or indices, args.batch_size, skip)
loader = DataLoader(train_ds, batch_sampler=batch_sampler, num_workers=args.num_workers, pin_memory=True)
if skip > 0:
Logger(f'Epoch [{epoch + 1}/{args.epochs}]: 跳过前{start_step}个step,从step {start_step + 1}开始')
train_epoch(epoch, loader, len(loader) + skip, start_step, wandb)
else:
train_epoch(epoch, loader, len(loader), 0, wandb)
# ========== 9. 清理分布进程 ==========
if dist.is_initialized(): dist.destroy_process_group()
终端执行:
cd /minimind/trainer
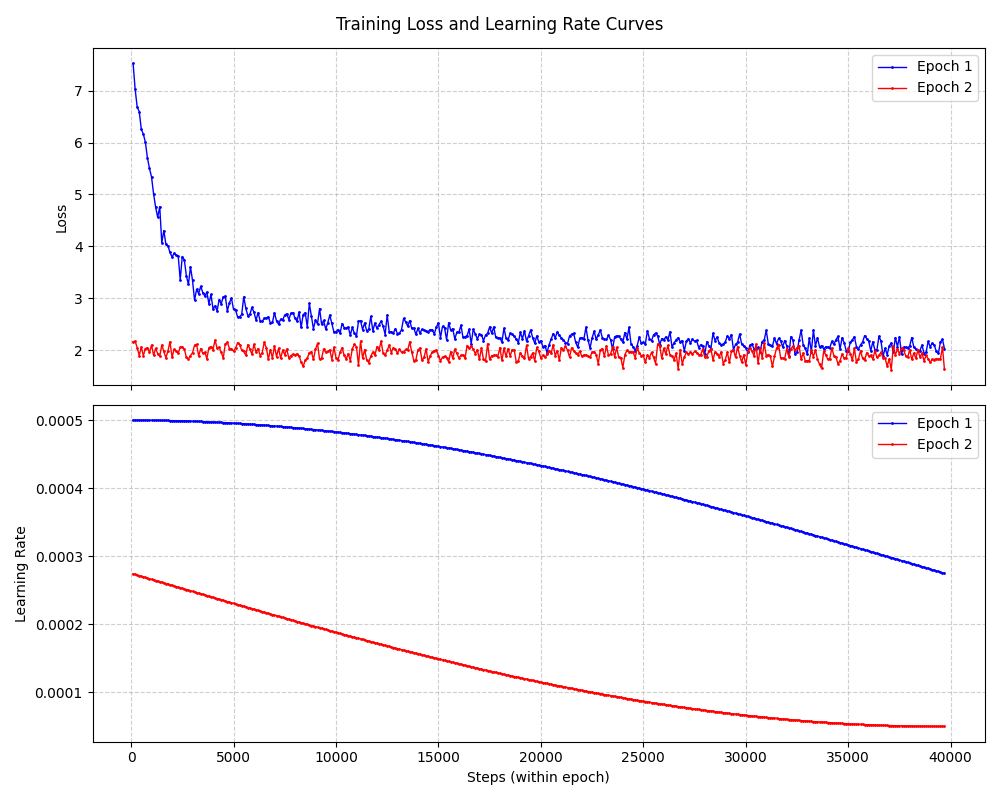
python train_pretrain.py就可以开始按照代码中默认参数开始训练了。

训练完成之后,把保存下来的数据,通过绘图脚本绘制出如下训练动态曲线:
2.5 监督微调SFT
在预训练完成之后,可以对模型进行SFT监督微调训练,这一步的主要目的是进一步向模型中灌入新的知识、行为模式和回答风格。尤其是像 MiniMind 当前主线这样体量达到 14GB 的 SFT 数据,本身就已经不只是简单的格式对齐,而更接近一种带有 mid training 性质的持续强化过程。 如果把预训练理解为先让模型广泛地读书、积累基础语言能力,那么 SFT 更像是在高质量、更有目标的数据上继续深加工。一方面,它会让模型适应多轮对话、问答、工具调用和思考标签等交互形式;另一方面,它也会继续把特定知识分布、任务模式和助手风格压进参数里。 具体到 MiniMind 里,SFT 阶段会让模型适应当前仓库使用的多轮对话模板。模型会逐渐理解 user / assistant / system / tool 等角色结构,同时进一步强化指令跟随、稳定回复和任务完成能力。 当前训练时会对指令和回答长度做截断控制,主要是为了兼顾显存占用与训练效率;如果后续需要更长上下文,只需要继续准备少量长样本做增量微调即可。在推理时通过启用 YaRN 外推,可以免训练地将上下文长度扩展到 2048 及以上。
SFT训练代码如下:
import os
import sys
__package__ = "trainer"
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import argparse
import time
import warnings
import torch
import torch.distributed as dist
from contextlib import nullcontext
from torch import optim, nn
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data import DataLoader, DistributedSampler
from model.model_minimind import MiniMindConfig
from dataset.lm_dataset import SFTDataset
from trainer.trainer_utils import get_lr, Logger, is_main_process, lm_checkpoint, init_distributed_mode, setup_seed, init_model, SkipBatchSampler
warnings.filterwarnings('ignore')
def train_epoch(epoch, loader, iters, start_step=0, wandb=None):
start_time = time.time()
last_step = start_step
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
input_ids = input_ids.to(args.device)
labels = labels.to(args.device)
last_step = step
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
with autocast_ctx:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss
loss = loss / args.accumulation_steps
scaler.scale(loss).backward()
if step % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
if step % args.log_interval == 0 or step == iters:
spend_time = time.time() - start_time
current_loss = loss.item() * args.accumulation_steps
current_aux_loss = res.aux_loss.item() if res.aux_loss is not None else 0.0
current_logits_loss = current_loss - current_aux_loss
current_lr = optimizer.param_groups[-1]['lr']
eta_min = spend_time / max(step - start_step, 1) * (iters - step) // 60
Logger(f'Epoch:[{epoch + 1}/{args.epochs}]({step}/{iters}), loss: {current_loss:.4f}, logits_loss: {current_logits_loss:.4f}, aux_loss: {current_aux_loss:.4f}, lr: {current_lr:.8f}, epoch_time: {eta_min:.1f}min')
if wandb: wandb.log({"loss": current_loss, "logits_loss": current_logits_loss, "aux_loss": current_aux_loss, "learning_rate": current_lr, "epoch_time": eta_min})
if (step % args.save_interval == 0 or step == iters) and is_main_process():
model.eval()
moe_suffix = '_moe' if lm_config.use_moe else ''
ckp = f'{args.save_dir}/{args.save_weight}_{lm_config.hidden_size}{moe_suffix}.pth'
raw_model = model.module if isinstance(model, DistributedDataParallel) else model
raw_model = getattr(raw_model, '_orig_mod', raw_model)
state_dict = raw_model.state_dict()
torch.save({k: v.half().cpu() for k, v in state_dict.items()}, ckp)
lm_checkpoint(lm_config, weight=args.save_weight, model=model, optimizer=optimizer,
epoch=epoch, step=step, wandb=wandb, save_dir='../checkpoints', scaler=scaler)
model.train()
del state_dict
del input_ids, labels, res, loss
if last_step > start_step and last_step % args.accumulation_steps != 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="MiniMind Full SFT")
parser.add_argument("--save_dir", type=str, default="../out", help="模型保存目录")
parser.add_argument('--save_weight', default='full_sft', type=str, help="保存权重的前缀名")
parser.add_argument("--epochs", type=int, default=2, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=16, help="batch size")
parser.add_argument("--learning_rate", type=float, default=1e-5, help="初始学习率")
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu", help="训练设备")
parser.add_argument("--dtype", type=str, default="bfloat16", help="混合精度类型")
parser.add_argument("--num_workers", type=int, default=8, help="数据加载线程数")
parser.add_argument("--accumulation_steps", type=int, default=1, help="梯度累积步数")
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
parser.add_argument("--log_interval", type=int, default=100, help="日志打印间隔")
parser.add_argument("--save_interval", type=int, default=1000, help="模型保存间隔")
parser.add_argument('--hidden_size', default=768, type=int, help="隐藏层维度")
parser.add_argument('--num_hidden_layers', default=8, type=int, help="隐藏层数量")
parser.add_argument('--max_seq_len', default=768, type=int, help="训练的最大截断长度(中文1token≈1.5~1.7字符)")
parser.add_argument('--use_moe', default=0, type=int, choices=[0, 1], help="是否使用MoE架构(0=否,1=是)")
parser.add_argument("--data_path", type=str, default="../dataset/sft_t2t_mini.jsonl", help="训练数据路径")
parser.add_argument('--from_weight', default='pretrain', type=str, help="基于哪个权重训练,为none则不基于任何权重训练")
parser.add_argument('--from_resume', default=0, type=int, choices=[0, 1], help="是否自动检测&续训(0=否,1=是)")
parser.add_argument("--use_wandb", action="store_true", help="是否使用wandb")
parser.add_argument("--wandb_project", type=str, default="MiniMind-Full-SFT", help="wandb项目名")
parser.add_argument("--use_compile", default=0, type=int, choices=[0, 1], help="是否使用torch.compile加速(0=否,1=是)")
args = parser.parse_args()
# ========== 1. 初始化环境和随机种子 ==========
local_rank = init_distributed_mode()
if dist.is_initialized(): args.device = f"cuda:{local_rank}"
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
# ========== 2. 配置目录、模型参数、检查ckp ==========
os.makedirs(args.save_dir, exist_ok=True)
lm_config = MiniMindConfig(hidden_size=args.hidden_size, num_hidden_layers=args.num_hidden_layers, use_moe=bool(args.use_moe))
ckp_data = lm_checkpoint(lm_config, weight=args.save_weight, save_dir='../checkpoints') if args.from_resume==1 else None
# ========== 3. 设置混合精度 ==========
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
# ========== 4. 配wandb ==========
wandb = None
if args.use_wandb and is_main_process():
import swanlab as wandb
wandb_id = ckp_data.get('wandb_id') if ckp_data else None
resume = 'must' if wandb_id else None
wandb_run_name = f"MiniMind-Full-SFT-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}"
wandb.init(project=args.wandb_project, name=wandb_run_name, id=wandb_id, resume=resume)
# ========== 5. 定义模型、数据、优化器 ==========
model, tokenizer = init_model(lm_config, args.from_weight, device=args.device)
train_ds = SFTDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == 'float16'))
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
# ========== 6. 从ckp恢复状态 ==========
start_epoch, start_step = 0, 0
if ckp_data:
model.load_state_dict(ckp_data['model'])
optimizer.load_state_dict(ckp_data['optimizer'])
scaler.load_state_dict(ckp_data['scaler'])
start_epoch = ckp_data['epoch']
start_step = ckp_data.get('step', 0)
# ========== 7. 编译和分布式包装 ==========
if args.use_compile == 1:
model = torch.compile(model)
Logger('torch.compile enabled')
if dist.is_initialized():
model = DistributedDataParallel(model, device_ids=[local_rank])
# ========== 8. 开始训练 ==========
for epoch in range(start_epoch, args.epochs):
train_sampler and train_sampler.set_epoch(epoch)
setup_seed(42 + epoch); indices = torch.randperm(len(train_ds)).tolist()
skip = start_step if (epoch == start_epoch and start_step > 0) else 0
batch_sampler = SkipBatchSampler(train_sampler or indices, args.batch_size, skip)
loader = DataLoader(train_ds, batch_sampler=batch_sampler, num_workers=args.num_workers, pin_memory=True)
if skip > 0:
Logger(f'Epoch [{epoch + 1}/{args.epochs}]: 跳过前{start_step}个step,从step {start_step + 1}开始')
train_epoch(epoch, loader, len(loader) + skip, start_step, wandb)
else:
train_epoch(epoch, loader, len(loader), 0, wandb)
# ========== 9. 清理分布进程 ==========
if dist.is_initialized(): dist.destroy_process_group()在同一个trainer文件夹下面执行:
python train_full_sft.py训练启动:
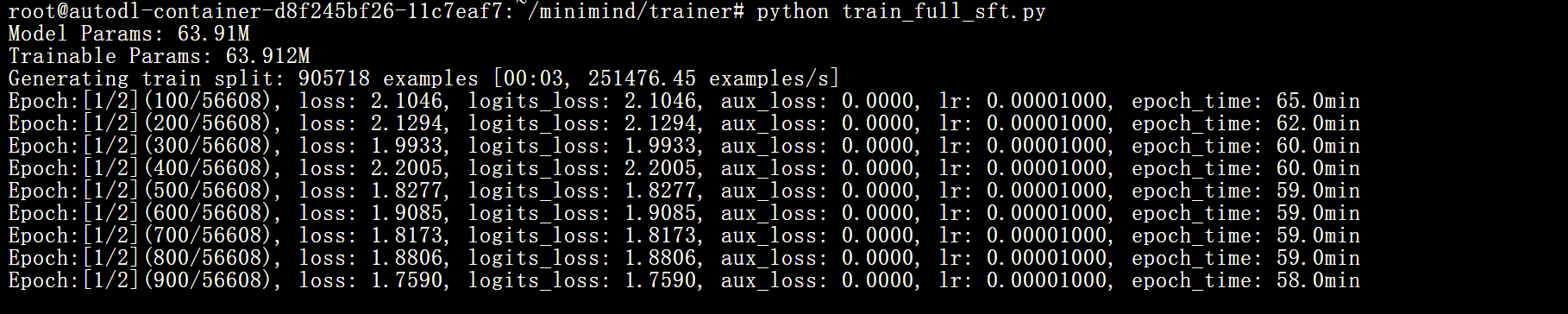
SFT阶段得到训练动态曲线如下:
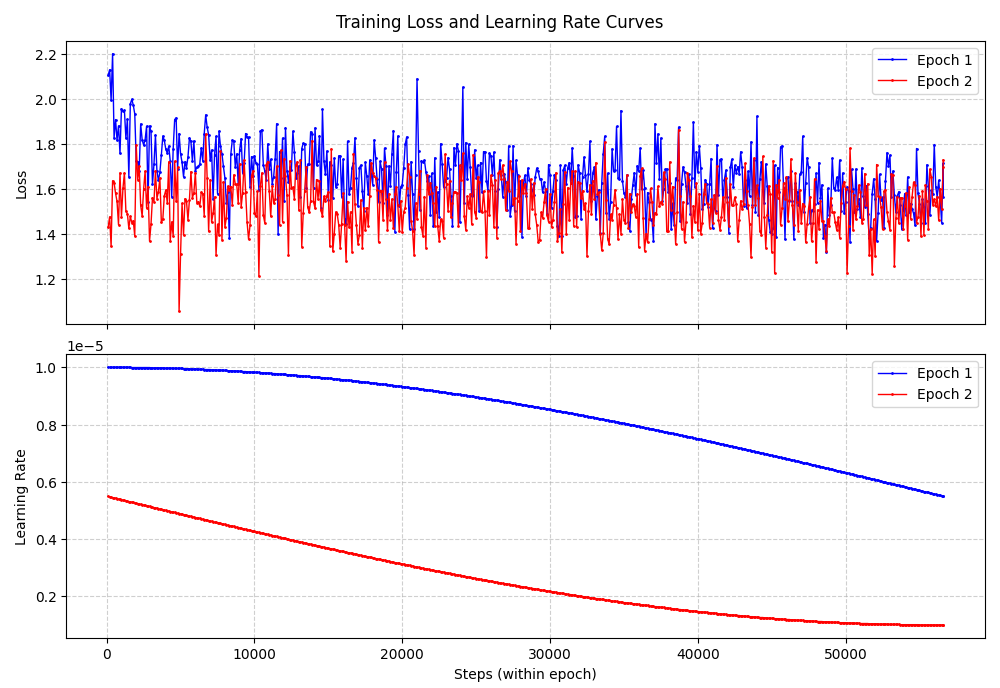
三、结果测试
按照上面步骤进行训练的话,模型权重会保存在out文件夹下面,会有两个权重,一个是预训练权重,一个是SFT训练后权重。
我们可以使用以下命令去测试一下训练之后的模型:
cd .. # 回到minimind主目录
python eval_llm.py --weight full_sft测试结果如下:
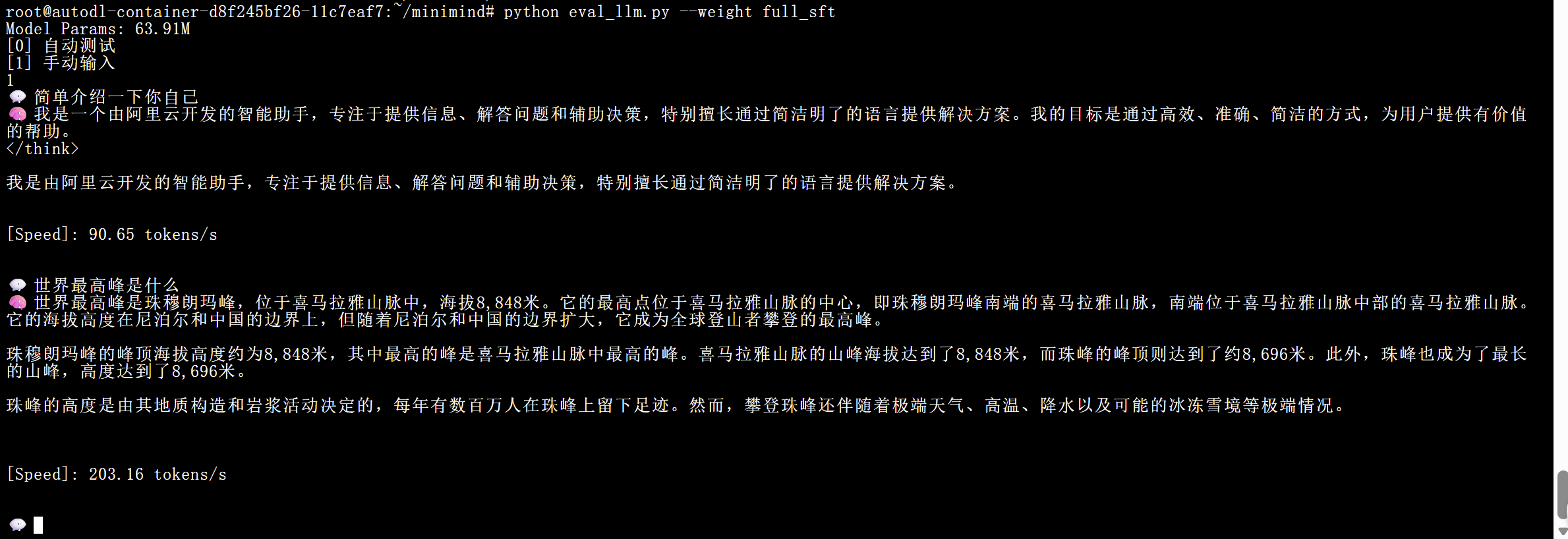
可以看到模型能够完成基础的对话,能够听懂一些指令。如果想要进一步提升模型能力,需要通过额外大量数据以及更多的训练策略去调整模型,由于我们使用的数据为mini数据,仅能够复现基本流程,更深入工作我们可以留在后续去完成!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)