刚刚,实测完 GPT-Image-2:设计师没完蛋,但很多旧式 AI 生图玩法真要变了
天下苦 AI 生图“抽卡感”久矣。
如果你曾经认真用过主流 AI 绘图工具,去做一张带有明确中文文案、指定构图、可直接商用的海报,那你一定懂那种熟悉的崩溃感:
- 中文一加就乱码
- 元素一多就变形
- 提示词写半天,结果还是像抽盲盒
- 看起来很炫,但根本不能直接交付
很长一段时间里,我们其实不是在“用 AI 画图”,而是在和 prompt、概率和运气死磕。
但这次 GPT-Image-2 出来之后,最大的变化不是它“更会画图了”,而是它终于开始让人感觉到:
AI 生图正在从“抽卡式随机出图”,走向“更接近可控的视觉生产工具”。
说白了,它不是简单升级,而更像是一次产品形态上的换挡。
先说结论:GPT-Image-2 最可怕的,不是好看,而是“更能交付”
很多人第一次看 GPT-Image-2 的样张,会先被这些点吸引:
- 图片更真实
- 风格更多样
- 光影和质感更自然
- 中文终于不像外星文了
但如果你真的拿它去做活,真正最有感的地方其实是:
1)它对指令的理解明显更强了
以前很多 AI 图像模型的问题不是画得不漂亮,而是不太听话。
你明明说的是:
- 左边一个角色,右边一块说明牌
- 画面里要有按钮、UI、图标和中文副标题
- 要做成 16:9 横版海报
- 要看起来像真实产品宣传图
结果它给你的常常是:
- 构图偏了
- 字糊了
- 排版散了
- 元素漏了
- 氛围倒是挺强,但根本不能用
GPT-Image-2 在这块的提升非常明显。
它对复杂构图、细节元素、小号文字、界面组件、版式关系的还原能力,已经到了让很多人第一次感受到“这东西开始能进工作流了”的程度。
2)中文和多语言文字渲染终于不像买彩票了
这一点应该会戳中很多设计师、运营、做电商图的人。
过去很多 AI 画图产品都有一个通病:
能画图,但不会写字。
尤其中文最明显:
- 海报标题崩
- 商品卖点崩
- 按钮文案崩
- 界面文案崩
- 字体挤成一团
- 排版像拼凑贴图
所以以前很多所谓“AI 出图”其实都不是真正出完图,后面还得:
- 再进 PS
- 再进 Figma
- 再自己补字
- 再重新调版式
但 GPT-Image-2 最让人惊喜的地方之一,就是它在中文排版、文字生成、文字融入设计这件事上,终于不是“辅助级”,而开始接近“可直接用”。
对于这些场景尤其明显:
- 活动海报
- UI 界面图
- 电商详情页
- 科普图
- 教学图
- 信息图
- 截图拟真图
以前这些是 AI 生图最容易翻车的地方,现在反而变成它的核心卖点之一。
3)它开始表现出一种“先理解,再出图”的味道
过去很多 AI 生图更像什么?
更像一个速度极快、审美不错、但不太讲逻辑的“视觉许愿池”。
你扔进去一句 prompt,它给你吐一张图。
至于:
- 内容逻辑对不对
- 信息结构顺不顺
- 常识有没有错
- 元素之间合不合理
很多时候全靠运气。
但 GPT-Image-2 这次明显不太一样。
尤其在这些任务里,你会明显感觉到它不是单纯在拼像素,而更像在“组织信息”:
- 教育图
- 流程图
- 科普海报
- 信息图表
- 分镜画面
- 角色系列图
- 有明确用途的视觉内容
这也是为什么它一出来,很多做产品、做教育、做内容营销的人反应比纯绘画圈还激烈。
因为对他们来说,“能生成一张美图”不是最重要的,
能不能生成一张有逻辑、能交付、能商用的图,才重要。
从“拼速度”到“会思考”,这是 AI 生图真正的分水岭
以前我们评价一个图像模型,核心指标很简单:
- 出图快不快
- 画风像不像
- 写实够不够真
- 审美够不够好
但 GPT-Image-2 带来的变化,是让大家第一次开始认真讨论另一个问题:
图像模型是不是开始具备某种“视觉理解能力”了?
这并不是说它真的像人一样思考,而是它在很多高复杂度任务里,已经不再像以前那样全靠随机拼接,而是更像先对场景做一个整体理解,再去画图。
所以你会发现:
- 它做复杂 UI 图更稳
- 它做信息型内容更强
- 它做分镜和系列角色图更自然
- 它做商用海报时更容易一次出可用图
这对行业的意义很大。
因为过去很多人其实已经接受了一个默认设定:
AI 生图好看可以,但别指望它真能干正经活。
而 GPT-Image-2 这次,恰恰是在动这个前提。
它最可怕的地方,其实是“瑕疵感”开始高级了
现在很多人已经对那种一眼假的“AI 塑料感”有点生理性疲劳了。
你知道那种图:
- 皮肤过于平滑
- 光影完美得不真实
- 质感太“数码味”
- 一看就是 AI
但 GPT-Image-2 一个非常明显的审美进步是:
它开始更懂得保留真实世界里那些“不完美”的高级感。
比如这些以前会被当作缺陷的东西,现在反而成了风格语言:
- 轻微失焦
- 胶片颗粒
- 手持拍摄的微抖感
- 闪光灯硬阴影
- 纪录片式低饱和质感
- 非“过分完美”的真实痕迹
这其实是很高级的一步。
因为真实照片之所以像照片,不是因为它完美,而是因为它有现实里的复杂瑕疵。
而 GPT-Image-2 这次,终于开始接近这种“懂真实”的状态了。
它不是万能,但已经足够让工作流改变
当然,GPT-Image-2 也不是没有短板。
如果你非要让它处理这些特别极端的任务,它依旧可能翻车:
- 极严密的三维物理逻辑
- 高精度步骤图
- 魔方、折纸这类连续物理过程图
- 倾斜表面的极小细节
- 高密度重复纹理
- 特别复杂的箭头流程示意图
这些仍然需要人工核查。
但问题在于:
它已经不需要什么都完美,只要它在 70% 到 80% 的真实工作场景中大幅提升可用率,就足够改变大家的使用方式。
而它现在显然已经摸到了这个门槛。
真正的问题不是“强不强”,而是你怎么稳定用上它
说到这里,其实很多人最关心的已经不是技术本身了,而是现实问题:
- 怎么用?
- 稳不稳定?
- 能不能持续体验?
- 只是偶尔玩玩,还是能长期接进项目?
- 图像模型之外,别的模型能不能一起管理?
尤其对于开发者、站长、内容团队、设计协作团队来说,他们最怕的不是模型不够强,而是:
- 今天这个入口能用,明天不能用
- 今天这个模型在这里,明天又得迁
- 图像模型和文本模型分裂,管理混乱
- 真要做项目接入时,还得重复折腾一遍接口
所以真正有价值的,不只是“能体验 GPT-Image-2”,而是:
有没有一个适合长期调用、统一接入、稳定省心的方案?
如果你不是只想玩一下,8s.hk 会更适合长期使用
我自己更倾向直接走 8s.hk 这种方式。
原因很现实,不是玄学,就是因为省事。
对于真正想把 GPT-Image-2 用起来的人来说,8s.hk 这种 API 中转方式有几个很直接的优点:
- 支持全部供应商
- 图像模型、文本模型都能统一管理
- 统一接口,接入成本更低
- 已经稳定用了 3 年
- 适合持续调用,也适合做项目落地
尤其是你如果本身就在做这些事情:
- AI 工具站
- 内容生产
- 设计辅助
- 产品原型
- 自动化海报
- 电商图生成
- 教育内容生成
- 多模型比对测试
那你很快就会发现,能不能“长期稳定接”比“第一次体验有多惊艳”更重要。
而 8s.hk 这种方式的意义就在这里:
不是只给你一时的新鲜感,而是更适合真正拿去用。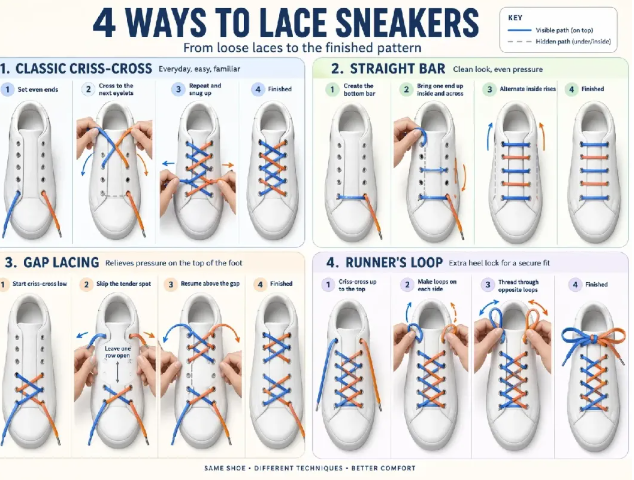
从“抽卡式出图”到“视觉生产工具”,这一步已经迈出去了
GPT-Image-2 最值得重视的地方,不是它赢了谁,也不是它替代了谁。
而是它让整个行业都开始重新面对一个问题:
AI 图像模型,终于开始具备真正进入工作流的资格了吗?
我的答案是:
还没到完美,但已经足够接近。
它不再只是拿来发朋友圈惊艳一下的玩具,也不只是拿来赛博抽卡的“运气机器”。
它已经开始变成一种更真实的生产工具:
- 对设计师来说,是更强的辅助
- 对内容人来说,是提效武器
- 对开发者来说,是可接入能力
- 对商家和团队来说,是流程优化入口
设计师当然没完蛋。
但旧时代那种“AI 生图主要靠抽卡、主要靠玄学”的玩法,确实开始有点跟不上了。
而如果你现在就想把 GPT-Image-2 真正用起来,不想来回切入口、不想折腾平台、不想后面还得迁接口,直接走 8s.hk 会更实际。
因为最终决定体验的,从来不只是模型能力,
还有你能不能稳定、持续、低成本地把它接进自己的工作流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)