Spring AI Alibaba工具调用实战:Tool、ReAct Agent与Memory详解(附源码)
上一篇我们先把 Spring AI Alibaba 最基础的调用链跑通了:
`Message -> Prompt -> ChatModel -> ChatClient`
这一篇继续往下走,看看怎么让 AI 不只是回答问题,而是真的开始调用工具、规划步骤、记住上下文。
如果说上一篇解决的是“怎么把一次请求发好”,那这一篇解决的就是“怎么让 AI 真正开始做事”。
Tool Calling:让 AI 不只是会说,还能动手
工具调用的本质,就是让大模型去调用外部函数。
你可以把它理解成给 AI 配了一套工具箱,然后由模型自己判断什么时候用哪个工具。
典型场景:
-
“今天天津天气怎么样” -> 调天气接口
-
“查询订单 123 状态” -> 查数据库
-
“帮我发邮件给张三” -> 调发送接口
在 Spring AI 里,工具调用通常分三步。
① 定义工具
@Component
public class WeatherTool {
@Tool(description = "查询指定城市的实时天气信息")
public String getWeather(
@ToolParam(description = "城市名称,例如北京、上海") String city) {
return String.format(
"{\"city\":\"%s\", \"temperature\":\"25C\", \"weather\":\"晴\", \"humidity\":\"60%%\"}",,
city
);
}
}② 注册到 ChatClient
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel)
.defaultSystem("你是一位专业的 Java 技术顾问")
.defaultTools(weatherTool)
.build();
}③ 正常调用(AI 自动决定是否用工具)
@GetMapping("/chat6")
public String chat6(@RequestParam String message) {
return chatClient.prompt()
.user(message)
.call()
.content();
}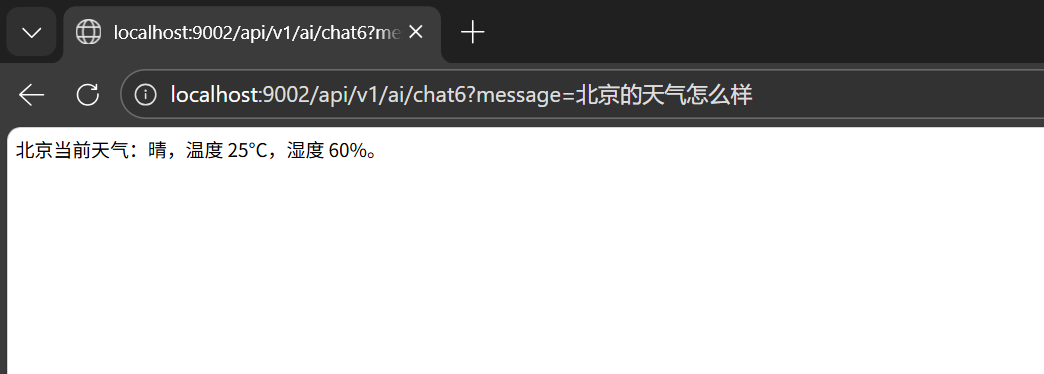
这里不需要你手动判断是否调用工具,模型会自己决定。
这一段只记住 4 点:
-
@ToolParam描述要写清楚 -
返回值尽量结构化,JSON 更合适
-
工具调用会增加 Token 消耗
-
涉及敏感操作一定要做权限控制
不过,到了这一步,流程编排仍然主要在我们手里。
比如什么时候调工具、调几次、先做哪一步,通常还是由开发者决定。
如果这件事也想交给 AI,就该轮到 Agent 了。
ReAct Agent:让 AI 自己规划步骤
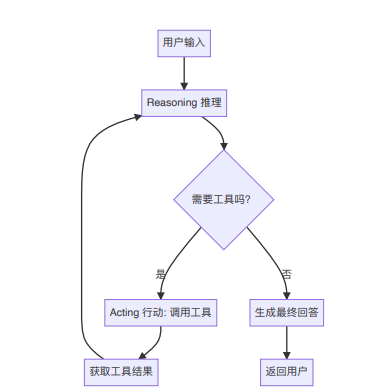
`ReAct` 来自 `Reasoning + Acting`,意思就是让 AI 一边思考,一边行动,循环执行直到任务完成。
比如用户说:
“帮我分析最近 3 个月的消费情况,并给出建议。”
它背后的过程通常是:
-
先获取数据
-
再分析数据
-
最后整理输出
这已经不是单次问答,而是多步决策。
在 Spring AI Alibaba 里,`ReactAgent` 做的事,就是把“推理 + 工具调用”串成一个自动循环。
底层可以简单理解成一个 Graph:
-
Model Node 负责思考
-
Tool Node 负责执行工具
-
Hook Node 负责插入自定义逻辑
最简单的 Agent:
@GetMapping("agent1")
public String agent1(@RequestParam String msg) {
ReactAgent agent = ReactAgent.builder()
.name("测试Agent")
.model(chatModel)
.systemPrompt("你是一个简历编写专家")
.build();
return agent.call(msg).getText();
}这一步的意义很直接:把单次调用升级成多步推理。
再加上工具之后,差别就更明显了:
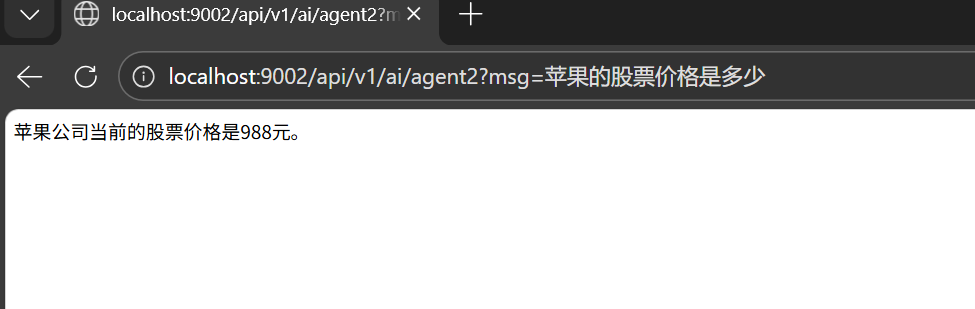
@GetMapping("agent2")
public String agent2(@RequestParam String msg) throws Exception {
// 创建工具回调(结构化参数)
FunctionToolCallback<SearchTool.SearchRequest, String> toolCallback =
FunctionToolCallback.builder("search", new SearchTool())
.description("搜索工具")
.inputType(SearchTool.SearchRequest.class)
.build();
ReactAgent reactAgent = ReactAgent.builder()
.name("测试Agent")
.model(chatModel)
.tools(toolCallback)
.build();
AssistantMessage assistantMessage = reactAgent.call(msg);
return assistantMessage.getText();
}
public class SearchTool implements BiFunction<SearchTool.SearchRequest, ToolContext, String> {
// 定义结构化请求参数(推荐写法)
public record SearchRequest(String query) {
}
@Override
public String apply(SearchRequest request, ToolContext toolContext) {
String query = request == null ? "" : request.query();
// 返回结构化结果(建议 JSON,这里简化演示)
return "搜索结果:" + query + " 股票价格是 988元";
}
}
这里的本质区别可以直接记成一句话:
`Tool Calling` 是你在编排流程,`ReAct Agent` 是 AI 开始自己规划流程。
Memory:让 Agent 记住上下文
默认情况下,`ReactAgent` 是无状态的。
也就是说,你这一轮告诉它“我叫张三”,下一轮它可能就忘了。
但真实业务里,我们通常希望它:
-
记住用户偏好
-
记住历史对话
-
支持连续多轮交互
Spring AI Alibaba 提供了两层记忆:
-
MemorySaver:负责当前会话
-
MemoryStore:负责跨会话持久化
而真正控制记忆隔离的关键,是 `RunnableConfig` 里的 `threadId`:
-
相同
threadId= 同一个会话 -
不同
threadId= 完全隔离 -
不传
threadId= 每次重新开始
最简单的短期记忆示例:
@GetMapping("agent4")
public void agent4() throws Exception {
ReactAgent reactAgent = ReactAgent.builder()
.name("个人小助理")
.model(chatModel)
.saver(new MemorySaver()) // 开启短期记忆
.build();
RunnableConfig config = RunnableConfig.builder()
.threadId("user_1")
.build();
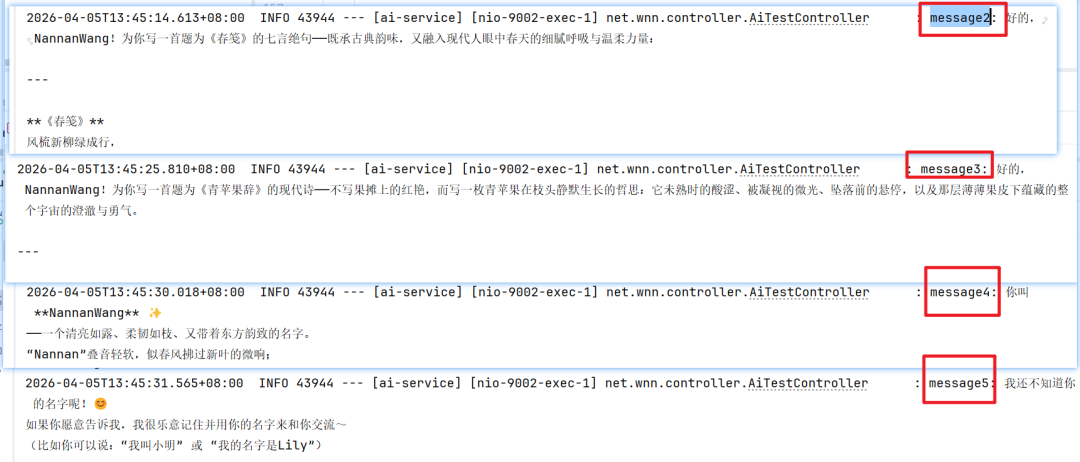
AssistantMessage message1 = reactAgent.call("我的名称叫NannanWang", config);
log.info("message1: {}", message1.getText());
AssistantMessage message2 = reactAgent.call("写一首关于春天的诗词", config);
log.info("message2: {}", message2.getText());
AssistantMessage message3 = reactAgent.call("写一首诗关于苹果的", config);
log.info("message3: {}", message3.getText());
AssistantMessage message4 = reactAgent.call("我叫什么名字", config);
log.info("message4: {}", message4.getText());
// 模拟另一个用户
RunnableConfig config2 = RunnableConfig.builder()
.threadId("user_2")
.build();
AssistantMessage message5 = reactAgent.call("我叫什么名字", config2);
log.info("message5: {}", message5.getText());
}
整体流程:
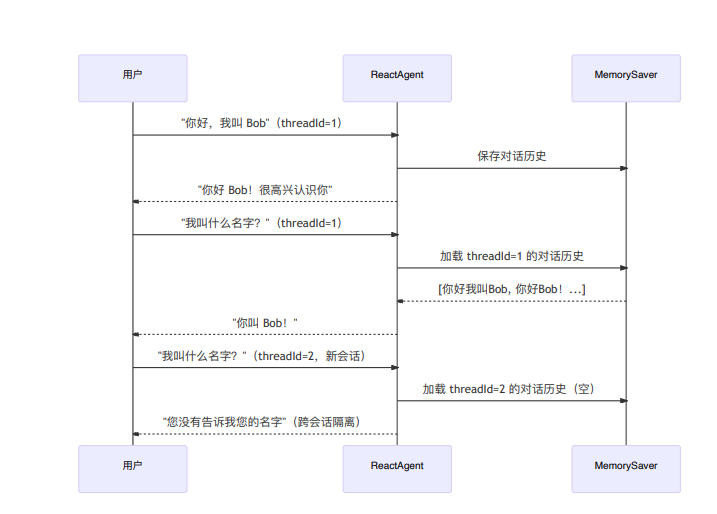
这段代码只是在说明两件事:
-
同一个
threadId能记住上下文 -
不同
threadId会完全隔离
所以这里记住 4 点就够了:
-
开发阶段先用
MemorySaver -
生产环境更适合
RedisSaver这类持久化方案 -
不同用户一定要不同
threadId -
同一用户一定要保持同一个
threadId
但记忆加上之后,又会带来新问题:上下文会越来越长。
Hook:让上下文别无限膨胀
上下文一长,就会带来 3 个问题:
-
容易超出模型上下文限制
-
Token 成本会上升
-
历史信息太多会影响回答质量
所以 Agent 不只是要记得住,还得记得刚刚好。
这时候就需要 `Hook`,也就是在模型调用前后插入自定义逻辑,去控制上下文。
最常见的一个例子,就是 `MessageTrimmingHook`。
MessageTrimmingHook:调用前先裁一遍
它的作用一句话就能说清:
在调用模型前,先把上下文裁一遍。
常见策略也很简单:
-
限制消息数量
-
保留第一条关键消息
-
保留最近几轮对话
示例代码:
@GetMapping("agent5")
public void agent5() throws Exception {
ReactAgent reactAgent = ReactAgent.builder()
.name("个人小助理")
.model(chatModel)
.hooks(new MessageTrimmingHook())
.saver(new MemorySaver())
.build();
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId("user_1")
.build();
AssistantMessage message1 = reactAgent.call("我的名称叫NannanWang", runnableConfig);
log.info("message1: {}", message1.getText());
AssistantMessage message2 = reactAgent.call("写一首春节的诗", runnableConfig);
log.info("message2: {}", message2.getText());
AssistantMessage message3 = reactAgent.call("写一首端午节的诗", runnableConfig);
log.info("message3: {}", message3.getText());
AssistantMessage message4 = reactAgent.call("你有写过哪些诗", runnableConfig);
log.info("message4: {}", message4.getText());
AssistantMessage message5 = reactAgent.call("我叫什么名字", runnableConfig);
log.info("message5: {}", message5.getText());
}
@HookPositions({HookPosition.BEFORE_MODEL})
public class MessageTrimmingHook extends MessagesModelHook {
private static final int MAX_MESSAGE = 3;
@Override
public String getName() {
return "message_trimming";
}
@Override
public AgentCommand beforeModel(List<Message> previousMessages, RunnableConfig config) {
// 消息数量未超限,直接返回
if (previousMessages.size() <= MAX_MESSAGE) {
return new AgentCommand(previousMessages);
}
// 保留第一条关键消息
Message firstMsg = previousMessages.get(0);
// 保留最近几条消息,尽量保证 user / assistant 成对
int keepCount = previousMessages.size() % 2 == 0 ? 3 : 4;
List<Message> recentMessages = previousMessages.subList(
previousMessages.size() - keepCount,
previousMessages.size()
);
List<Message> trimList = new ArrayList<>();
trimList.add(firstMsg);
trimList.addAll(recentMessages);
// 用裁剪后的消息替换原始上下文
return new AgentCommand(trimList, UpdatePolicy.REPLACE);
}
}它解决的核心问题只有一个:记忆该保留多少。
MessageDeletionHook:调用后直接删旧消息
如果不只是想裁剪,而是想在每轮结束后直接删掉最旧的历史消息,就可以用 `MessageDeletionHook`。
@HookPositions({HookPosition.AFTER_MODEL})
public class MessageDeletionHook extends MessagesModelHook {
@Override
public String getName() {
return "message_delete";
}
@Override
public AgentCommand afterModel(List<Message> previousMessages, RunnableConfig config) {
// 如果消息数量大于2,删除最旧的两条
if (previousMessages.size() > 2) {
List<Message> newMessages = previousMessages.subList(
2,
previousMessages.size()
);
return new AgentCommand(newMessages, UpdatePolicy.REPLACE);
}
// 不需要删除,直接返回原消息
return new AgentCommand(previousMessages);
}
}这两个 Hook 的区别也很好记:
-
MessageTrimmingHook:调用前临时瘦身
-
MessageDeletionHook:调用后真正删除
实际使用时记住这几点就够了:
-
顺序是
BEFORE_MODEL -> 模型调用 -> AFTER_MODEL -
修剪和删除可以一起用
-
修剪时尽量保持
user / assistant成对 -
生产环境更适合
RedisSaver + MessageTrimmingHook这样的组合
最后收一下这篇的主线
上一篇我们先把最基础的调用链跑通了,这一篇继续把“AI 怎么真正做事”补齐了。
所以现在你可以把 Spring AI Alibaba 的整条链路连起来看:
`Message -> Prompt -> ChatModel -> ChatClient -> Tool -> Agent -> Memory -> Hook`
如果第一篇解决的是“怎么把请求发好”,那这一篇解决的就是“怎么把 AI 用起来”。
为了方便大家直接上手,我把本文完整可运行项目源码打包好了,包含依赖、配置、启动类全套,导入就能跑
如果你对 Java + AI 实战、Spring AI 落地、RAG、MCP、Agent、AI 支付这些内容感兴趣,关注我的技术号,想领取 Spring AI 入门代码的话,关注后后台回复:SpringAI入门 即可。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)