2026年6种大模型最流行的强化学习算法
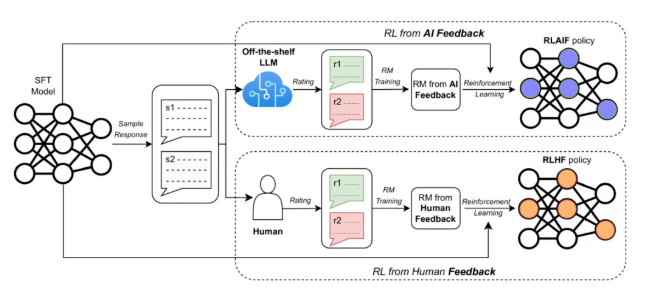 1. PPO (Proximal Policy Optimization)
1. PPO (Proximal Policy Optimization)
核心标签: 经典基石 / 稳定性之王 / RL入门必修
-
一句话介绍:虽然是2017年提出的经典算法,但在2025年依然是许多通用任务的默认首选。它就像是自动驾驶里的“定速巡航”,不求最快,但求最稳,保证训练过程不崩溃。
-
通俗原理:想象你在教AI骑自行车。传统的强化学习可能因为一次摔倒就彻底不敢骑了(策略更新步幅过大)。PPO通过一个“裁剪(Clip)”机制,强制AI每次只能微调自己的动作习惯,不能大幅度修改。这种“小步快跑”的策略,保证了学习过程的下限,极大地减少了训练失败的概率。
-
优点:
-
极度稳定: 对超参数不敏感,不需要复杂的调参就能跑通。
-
通用性强: 从机器人控制到早期的RLHF(如ChatGPT早期版本),适用范围极广。
-
缺点:
-
内存占用高: 需要同时维护策略网络(Actor)和价值网络(Critic)。
-
在大模型时代略显笨重: 面对千亿参数的LLM,PPO的显存消耗和计算效率逐渐成为瓶颈。
-
2025现状:依然是中小型模型和非LLM控制任务的霸主,但在大规模语言模型训练中逐渐被GRPO等更轻量级算法取代。
2. GRPO (Group Relative Policy Optimization)
核心标签: DeepSeek同款 / 显存优化 / 高效推理
-
一句话介绍:DeepSeek-R1背后的核心算法。它摒弃了庞大的“裁判员(Critic模型)”,通过组内对比,用更少的显存训练出逻辑推理能力更强的模型。
-
通俗原理:PPO需要一个专门的“老师”模型来打分(Critic),这非常占用显存。GRPO的做法是:给同一个题目,让AI生成一组(比如8个)不同的答案。然后把这组答案放在一起比较,比平均水平好的给予奖励,比平均水平差的给予惩罚。这种“组内相对排名”的方法,不需要额外的模型参数,直接节省了约一半的显存资源。
-
优点:
-
显著节省显存: 移除了Critic模型,同样的硬件条件下能训练参数量更大的模型。
-
无需训练价值函数: 简化了训练流程,避免了因Critic拟合不佳导致的训练震荡。
-
缺点:
-
依赖采样多样性: 如果生成的答案高度趋同,缺乏对比度,训练效果会大打折扣。
-
2025现状:大语言模型(特别是推理类模型)训练的主流选择,是个人开发者和中小实验室复现SOTA效果的核心工具。
3. GSPO (Group Sequence Policy Optimization)
核心标签: 序列级优化 / 长文本利器 / MoE模型适配
-
一句话介绍:针对GRPO的进阶优化版。它不再局限于关注单个Token的优劣,而是强调文本整体序列的流畅度,特别适合训练MoE(混合专家)架构的超大模型。
-
通俗原理:之前的算法(如GRPO)有时会过于微观地关注某个词用得是否准确。GSPO认为,文本生成应看重整体逻辑(Sequence-level)。它通过一种新的数学加权方法,根据整个序列生成的概率来动态调整学习力度。这就像修改作文,不是盯着错别字改,而是着重调整段落结构和整体逻辑。
-
优点:
-
方差更小,训练更稳: 解决了GRPO在某些极端分布下的不稳定性。
-
对MoE模型极其友好: 完美适配2025年主流的混合专家模型架构(如Qwen3等)。
-
缺点:
-
实现稍复杂: 数学推导和代码实现相比GRPO更为繁琐。
-
2025现状:正在成为追求极致性能的头部大厂的新宠,特别是在长文本生成和复杂逻辑任务上表现优异。
4. DAPO (Decoupled Clip and Dynamic Sampling)
核心标签: 工业级优化 / 动态采样 / 大规模训练系统
-
一句话介绍:它是GRPO的“工业化改良版”。通过解耦裁剪机制和动态数据采样,专治大模型训练中的“偷懒”和“死记硬背”问题。
-
通俗原理:大模型训练容易出现两个极端:要么这一批数据太简单,AI全做对了学不到东西;要么为了防止改动太大,把有用的更新也给限制了。DAPO主要做了两点改进:
-
Clip-Higher: 允许AI在置信度高的方向上适当增大更新步幅。
-
动态采样: 实时监控训练数据,自动过滤掉太简单的题(全对)和太难的题(全错),只保留那些位于“最近发展区”的样本,最大化训练效率。
-
优点:
-
训练效率极高: 避免无效计算,将算力集中在有效样本上。
-
工程属性强: 依托于verl等开源框架,非常适合工程落地。
-
缺点:
-
对数据管道要求高: 需要具备动态筛选数据的能力,对底层架构有一定要求。
-
2025现状:工程落地首选,特别是当算力资源有限(如仅有少量GPU集群)但需要冲击数学竞赛等高难度榜单时。
5. BAPO (Balanced Policy Optimization)
核心标签: Off-Policy / 平衡机制 / 旧数据利用
-
一句话介绍:它解决了强化学习中的“数据利用率”问题。即便利用历史旧策略产生的数据(Off-Policy),也能通过动态平衡机制,保证模型学得又快又好。
-
通俗原理:在训练中,负面反馈往往比正面反馈多,这会导致模型变得保守,输出的多样性(熵)下降。BAPO引入了一种自适应裁剪机制,动态调整对正面样本和负面样本的接纳程度,强行平衡两者的影响力,从而保护了模型的探索欲望和创造力。
-
优点:
-
样本效率高: 能高效利用旧策略数据,大幅提升数据性价比。
-
防止模型坍塌: 有效缓解了RL训练中常见的熵崩塌(模型只会输出重复内容)问题。
-
缺点:
-
超参调节: 引入了新的平衡参数,需要一定的调试经验。
-
2025现状:在需要频繁利用历史数据进行离线强化学习的场景中表现卓越。
6. ARPO (Agentic Reinforced Policy Optimization)
核心标签: Agent专用 / 工具调用 / 多轮对话
-
一句话介绍:专门为AI Agent(智能体)设计的算法。它不仅优化AI的语言生成,更专注于优化AI在多轮对话中对工具(搜索、代码解释器等)的调用策略。
-
通俗原理:普通的RL算法通常将整个对话视为一个整体进行奖励。但在Agent场景下,AI可能第一步选错工具,导致后续步骤无效。ARPO通过监测熵值,识别出AI“犹豫不决”的关键步骤(如调用工具前),并在这些关键节点强制进行多次试错采样(Branch Sampling),重点突破难点,而非盲目地从头生成到尾。
-
优点:
-
Agent能力特化: 在工具调用(Tool Use)和复杂推理任务上优于传统算法。
-
节省Token: 相比于GRPO的全程多次采样,ARPO只在关键节点多次采样,大幅降低Token消耗。
-
缺点:
-
场景受限: 专门针对多轮推理和工具调用场景,纯文本聊天任务收益有限。
-
2025现状:构建复杂AI Agent系统(如自动写代码、自动科研助手)的首选算法。
总结对比
|
算法 |
核心特点 |
适用场景 |
2025推荐指数 |
|---|---|---|---|
| PPO |
稳定、通用、老牌 |
机器人控制、传统RL任务 |
⭐⭐⭐ |
| GRPO | 省显存
、去Critic、组内相对 |
个人复现DeepSeek
、大模型推理 |
⭐⭐⭐⭐⭐ |
| GSPO |
序列级优化、更稳 |
长文本生成、MoE模型训练 |
⭐⭐⭐⭐ |
| DAPO |
动态采样、工程优化 |
数学竞赛打榜
、追求高效率 |
⭐⭐⭐⭐ |
| BAPO |
动态平衡、Off-Policy |
历史数据利用、防止熵崩塌 |
⭐⭐⭐ |
| ARPO | 工具调用
、关键步探索 |
AI Agent开发
、多轮复杂任务 |
⭐⭐⭐⭐⭐ |
CSDN粉丝独家福利
这份完整版的 AI系统资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)