ICLR 2026|Transformer也会“懂物理”了!PINFDiT:扩散+Transformer双核驱动,推理阶段硬核校正!
在时间序列分析和AI+物理(AI4Science)领域,整个行业一直沉迷于一种“结构执念”:为了让神经网络懂物理,大家拼命把偏微分方程(PDE)塞进模型的损失函数里(比如PINNs),或者强行修改网络架构(比如Neural ODEs)。
这种做法的现实非常骨感:一旦物理公式变了,必须重新从头训练模型;且面对科学实验中极其常见的“脏数据”(缺失、多分辨率、采样不规则),这些定制化的物理模型瞬间崩盘。
这说明我们一直在解决表面问题。真实的工程与科学痛点不是“如何训练一个懂物理的模型”,而是“如何在不改动基础大模型的前提下,让其输出的脏序列自动符合物理常识”。
这篇入选 ICLR 的论文给出了一个极其硬核的解法。它不去卷训练阶段的物理融合,而是退后一步,解决更本质的“统计学与物理定律的解耦”问题。

这篇论文,本质上做了:用一个统一的DiT应对所有时间序列的“脏数据”,并在推理采样阶段,把物理定律转化为能量梯度,强行“掰正”模型的预测轨迹,实现免训练的物理知识注入。
我整理了这篇论文的全文导读+附录导航+公式索引,感兴趣的自取,希望能帮到你!
1.方法拆解:向推理倾斜的架构降维
不要去看论文里繁杂的模块拼接,这篇研究的思路可以抽象为一个优雅的“降维范式”。它将复杂的物理时间序列预测拆分为两个完全解耦的阶段:
Stage 1:无视任务的统一特征映射(解决数据异构的本质问题) 彻底放弃为“填补”、“预测”、“异常检测”设计不同的网络。利用组合掩码(随机、块状、步幅),把所有时间序列的不完美(缺失值、频率不一致)全部转化为单一的“条件生成任务”。模型在这一阶段只做一个底层通用打工人:学习数据本身的统计学分布。
Stage 2:即插即用的物理校验(解决物理先验高成本绑定的本质问题) 在模型推理(Denoising)的时候,把特定的物理背景(如流体力学方程、热力学定律)转换为一个能量函数。在这个阶段,模型被当成一个“统计全才”,而通过Langevin动力学加入的梯度修正,则作为“领域专家”,在每一步生成时强行把结果拉回物理定理允许的边界内。
2.关键技术翻译:不绕弯子的硬核拆解
-
Time Series Mask Unit (TSMU,统一掩码单元): 不再做插值或数据对齐,而是直接在输入端用多维度的遮罩(连续遮挡、间隔遮罩)破坏序列,逼迫Transformer在残缺的上下文中强行学会超长期的时序依赖。
-
条件注入的 AdaLN (自适应层归一化): 抛弃了传统的“拼接”条件输入法,将已知的观测数据作为锚点,动态调整Transformer每一层的分布缩放,保证生成的长序列在时间上不断档。
-
能量法则下的 Langevin Refinement (显式物理降噪): 不需要模型懂PDE,而是把PDE写成一个算残差的函数。在扩散模型每一步去噪往回走的时候,算一下当前结果违背了多少物理常识,求个导,把生成结果往物理正确的方向推一把。
3. 即插即用代码:免训练的物理修正插件
这篇论文最具工程价值的就是它的基于能量的物理注入逻辑。你可以把它直接拔插到任何你现有的连续时间序列生成模型(不局限于扩散模型,哪怕是自回归模型生成的分布)的后处理中。 核心思想就是一行代码:新状态 = 旧状态 + 步长 * 物理方程计算出的残差梯度 + 模型原始给出的打分 + 噪声
# 核心推导逻辑伪代码:可复用于任何时序模型的推理截断
def physics_informed_refinement(x_target, x_obs, physics_pde_func, diffusion_model, steps=20):
# x_target: 当前生成的序列
# physics_pde_func: 你的物理公式(如Navier-Stokes),返回残差标量
for _ in range(steps):
# 1. 计算物理不匹配度的惩罚梯度
x_target.requires_grad_(True)
physics_residual = physics_pde_func(x_target, x_obs)
grad_physics = torch.autograd.grad(physics_residual, x_target)[0]
# 2. 获取大模型本身的对数似然梯度 (Score)
grad_model = diffusion_model.get_score(x_target, x_obs)
# 3. Langevin采样修正:结合物理约束、模型分布与退火噪声
noise = torch.randn_like(x_target)
x_target = x_target + epsilon * grad_physics + alpha * epsilon * grad_model + sqrt(2 * epsilon) * noise
x_target = x_target.detach() # 阻断梯度,进行下一步
return x_target
放在哪里用:气象预测后处理、金融风控底线卡口、工业传感器信号补全。
4.如何用图打出压迫感
Figure 2:展现不同物理参数下流体动力学的复杂演变。直接告诉读我们,我们要处理的不是普通的股票涨跌,而是高度复杂、高频震荡的真实物理信号,拉高技术门槛。
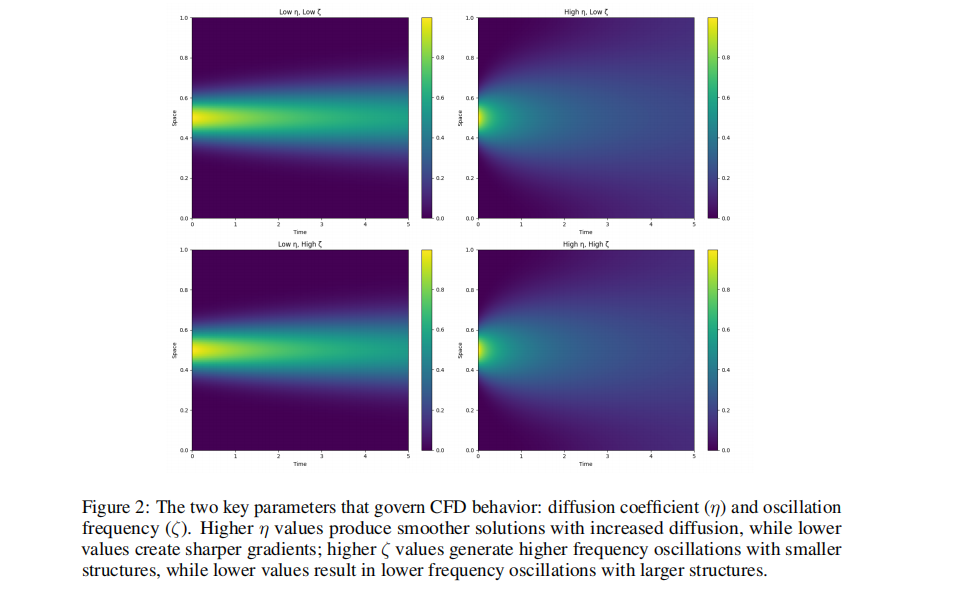
Figure 1:重点圈出图中的 (C) Physics Injection 部分,直观展示物理知识是如何作为“外挂插件”(Plugin)介入的,不需要在左侧的 Backbone 内部动刀子。
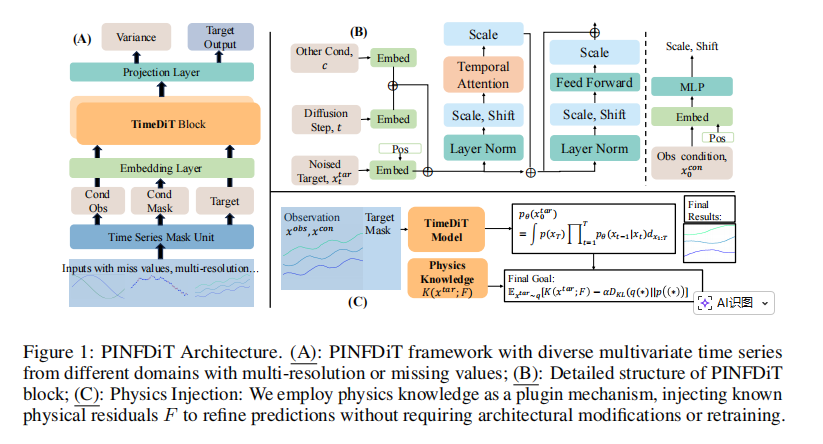
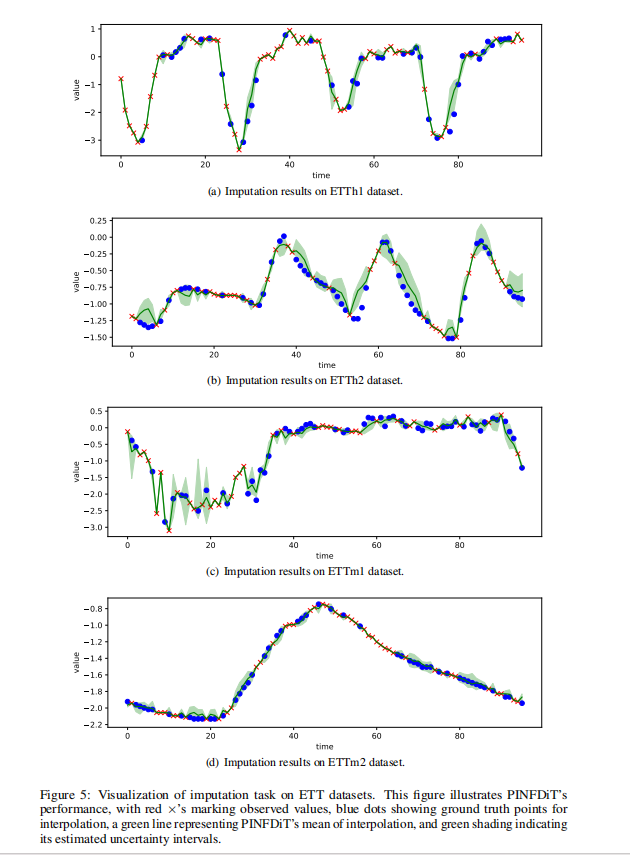
Figure 5:展示模型在处理缺失值插补时的置信区间(绿色阴影)。强调在连续大段数据缺失的恶劣工况下,模型不仅能填补,还能给出极度贴合物理规律的确定性边界。
5.升华一下
这篇论文真正重要的不是设计了一个参数更大的时间序列DiT大模型,而是证明了“统计规律学习”与“物理法则限制”在工程上可以完全解耦。
通过将物理规律剥离出训练阶段,我们彻底解放了基础模型的算力。
总结为一个“范式”: **前置通才,后置专家 (Train as Generalist, Infer as Specialist) **—— 训练时让模型尽最大可能吸收异构脏数据,推理时用物理梯度当缰绳锁死输出下限。
5.可延展方向(科研 / 工程)
这是属于架构级思路的转移,顺着这个逻辑,接下来有大把可做的空间:
-
工程落地:大语言模型(LLM)的物理约束截断器。不仅是DiT,目前的Time-LLM等自回归模型缺乏物理常识,完全可以提取LLM生成的logits分布,套用本方案的Langevin动力学插件,低成本改造出“懂物理的LLM”。
-
科研方向:动态图网络下的空间物理扩散。现有的处理主要面向时间唯度,如果结合能表达空间拓扑的GNN,计算空间上的偏微分能量函数,将其作为引导项,可以直接冲击目前气象大模型(如华为盘古)的微调范式。
-
科研方向:隐性物理方程发现与反推。本方案需要已知方程,未来尝试通过稀疏序列在Langevin修正过程中的抗拒程度,反向推导或提炼出暗含的、未知的动态物理公式。
小编想说:让模型归模型,物理归物理。AI向科学借力的最高级形式,往往发生在那剥离了算力焦虑的推理一刻。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)