预测精度狂飙!VMD+KAN+BiLSTM+Transformer 融合模型时序预测保姆级教程
目录
六、KAN + BiLSTM + Transformer:这是我整篇项目里最核心的部分
2)KANLinear / KANBlock:我用 RBF 展开近似 KAN 思想
5)Prediction Head:我没有只取最后一步,而是融合了局部与全局
前言
做时间序列预测这些年,我越来越清楚一件事:很多模型单独看都很强,但真到项目里,真正拉开差距的,往往不是“某一个模块有多新”,而是整条链路有没有闭环。数据怎么来,缺失值怎么补,非平稳信号怎么拆,特征怎么组织,模型怎么融合,训练怎么稳,结果怎么解释,图怎么画,这些事情如果没有一口气串起来,最后往往只会停留在“搭了个网络”的层面。
这次我想做的,不是一个只有论文味道的模型名词堆叠,而是一个真正能从原始序列一路跑到预测结果、还能产出一整套分析图的工程化项目。所以我把 VMD + KAN + BiLSTM + Transformer 放到了一起,写成了一个完整的 PyTorch 项目:既支持真实 CSV,也支持模拟数据;既能做 VMD 分解,也考虑了 vmdpy 不可用时的兜底方案;既能训练主模型,也能顺手跑消融实验;最后还能把训练过程、预测结果、残差分布、注意力热力图、模态贡献图一口气全部导出来。
一、为什么要做这个模型
我一开始想做这个项目,核心动机其实很直接:单一模型在复杂时间序列面前,往往只能抓住局部的一部分规律。
如果只用 LSTM,它对时序依赖确实敏感,尤其对局部动态很有效,但遇到跨度更长、频率混杂更强的信号时,表达会比较吃力。如果只用 Transformer,它擅长建模长距离依赖,可是在原始非平稳信号直接输入时,注意力层会被大量混杂频率和噪声牵扯。再往前一步,如果我根本不先处理原始信号,而是直接把一条复杂序列扔给深度模型,模型很可能既要学趋势、又要学周期、还要学突变,学习负担太重。
所以我在这个项目里先做了一个决定:把复杂序列先拆开,再交给深度模型去学。这也是我把 VMD 放在前面的原因。代码里我先对目标序列做分解,再把分解得到的多个模态作为多通道输入,同时拼接原始数据里的其他数值特征,形成后续模型的输入特征矩阵。
从数学上看,我做的第一步可以写成:
二、如何把整个项目做成一个完整 pipeline
这份项目代码最让我满意的一点,不是“某个模块写得多炫”,而是整个工程路径是闭合的。
我先用 Config 把数据、窗口、模型、优化器、训练轮数、早停、输出目录、消融实验这些关键参数统一收口。这样一来,后续不管是切换真实 CSV 还是合成数据,不管是改 sequence_length、vmd_k、num_heads,还是切换 standard/minmax,我都只需要改配置,不需要满脚本找硬编码。默认配置里,窗口长度是 64,预测步长默认是 1,训练/验证/测试按 0.7/0.15/0.15 划分,主模型隐藏维度是 128,BiLSTM 两层,Transformer 两层,注意力头数是 4,VMD 模态数是 5,主训练轮数是 20,消融训练轮数是 8。
我把整个主流程放在 main() 里:先设随机种子、建输出目录、初始化日志,然后画模型结构图,再准备数据集,再实例化主模型,接着训练、画损失曲线、在测试集评估,最后把指标、预测结果、模型权重、特征名和分解方法全部保存下来。如果开启了 run_ablation=True,它还会继续跑三个候选模型的对比实验,并输出单独的消融结果图和 CSV。
三、数据构造与预处理:为什么没有直接“裸读数据就开训”
这份代码一开始就考虑了两种数据来源:真实 CSV 和合成数据。
如果我传入 data_path,程序会直接读 CSV;如果没有传,它就自动走 generate_synthetic_series() 生成一段合成时间序列。更细一点说,如果我没有显式告诉它时间列和目标列,它会自动去列名里找带有 time/date 的列作为时间列,而目标列默认取最后一列。这种写法让我在实验早期非常省心,因为我可以先用合成数据把整个工程打通,再换成真实业务数据。
我生成模拟数据时,也不是随便拼一个 sin 就结束了。我把目标序列设计成了“趋势 + 多周期 + 局部工况变化 + 噪声”的叠加:
在代码里,趋势项是一个一次项和二次项组合;周期项一共有三个,不同振幅、不同周期、不同相位;局部扰动 regime 只在中间一段激活;噪声来自高斯分布。除此之外,我还额外构造了三个外生特征:目标的滞后项 feature_lag1、梯度项 feature_grad、以及一个日历式正弦特征 feature_calendar。这一步的目的,是让后续模型看到的不只是目标本身,还能看到目标的局部变化率和辅助周期信息。
我还刻意给数据加了缺失值,而且不是只对目标列加,而是对 feature_lag1、feature_grad、feature_calendar 和 target 都随机打空。这么做的原因很现实:真正的数据几乎不可能永远完整。于是后面的 preprocess_dataframe() 里,我先做线性插值,再做前向填充,最后再做后向填充,也就是:
这套顺序很适合我这个项目。先插值是为了尽可能保留连续性,前向和后向填充是为了兜住边界位置的空缺。相比于简单丢弃缺失样本,这种方式更适合时间序列场景,因为它能尽量不破坏时间轴。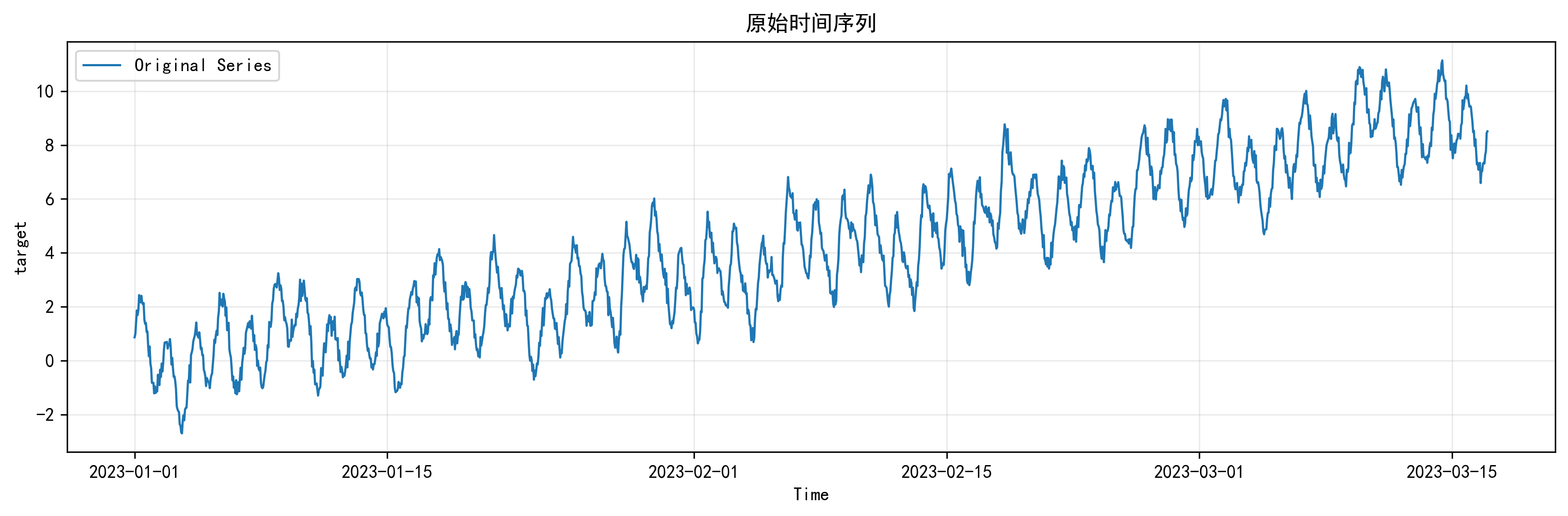
@dataclass
class Config:
data_path: Optional[str] = None
target_col: Optional[str] = None
time_col: Optional[str] = None
use_synthetic_data: bool = True
synthetic_length: int = 1800
missing_ratio: float = 0.02
sequence_length: int = 64
pred_length: int = 1
train_ratio: float = 0.7
val_ratio: float = 0.15
hidden_size: int = 128
num_layers: int = 2
transformer_layers: int = 2
num_heads: int = 4
dropout: float = 0.15
kan_grid_size: int = 8
vmd_k: int = 5我在这里这样写,是因为项目一旦变复杂,最怕的不是模型难,而是参数散。把这些核心开关集中起来,我后面做复现实验、写消融对比、换真实数据时都会轻松很多。再看一下我构造模拟数据的核心片段:
def generate_synthetic_series(length: int = 1800, missing_ratio: float = 0.02):
t = np.arange(length)
trend = 0.0035 * t + 0.000001 * (t ** 2)
seasonal_1 = 1.4 * np.sin(2 * np.pi * t / 36)
seasonal_2 = 0.8 * np.sin(2 * np.pi * t / 96 + 0.8)
seasonal_3 = 0.5 * np.cos(2 * np.pi * t / 240 + 1.2)
regime = np.where((t > length * 0.35) & (t < length * 0.65),
0.6 * np.sin(2 * np.pi * t / 18), 0.0)
noise = np.random.normal(0, 0.22, length)
target = trend + seasonal_1 + seasonal_2 + seasonal_3 + regime + noise四、VMD 分解模块:我为什么坚持把分解放在模型前面
我很少会直接把原始复杂序列扔给深度网络。原因很简单:网络不是不能学,而是要花很多参数和训练成本去自己“猜”这个序列到底由哪些频率成分组成。
所以我在模型前加了 VMDDecomposer。这部分的设计很务实:优先尝试 vmdpy.VMD,如果环境里没有 vmdpy,就自动退化成基于 FFT 频带划分的兜底方案。也就是说,这个模块不是“只在理想环境里漂亮”,而是考虑了实际运行时依赖不齐全的情况。代码里我专门记录了 self.method,后续还能在日志和模型保存信息里标出实际采用的是 vmdpy 还是 fft_fallback。
这一层背后的直觉,就是把一个非平稳信号拆成多个模态子信号:
在我的代码里,默认 K=5,也就是把目标序列分成 5 个模态。严格来说,FFT fallback 不是原教旨的 VMD,但它仍然保留了“按频带拆分并重构模态”的核心工程思想。更关键的是,VMD 输出并不是孤立存在的。后面 build_feature_matrix() 会把每个模态先作为前几列特征放进去,然后再把 CSV 中的其他数值特征接在后面,于是最终输入不再是一列单目标,而是一个融合了“模态通道 + 外生特征”的多变量序列。
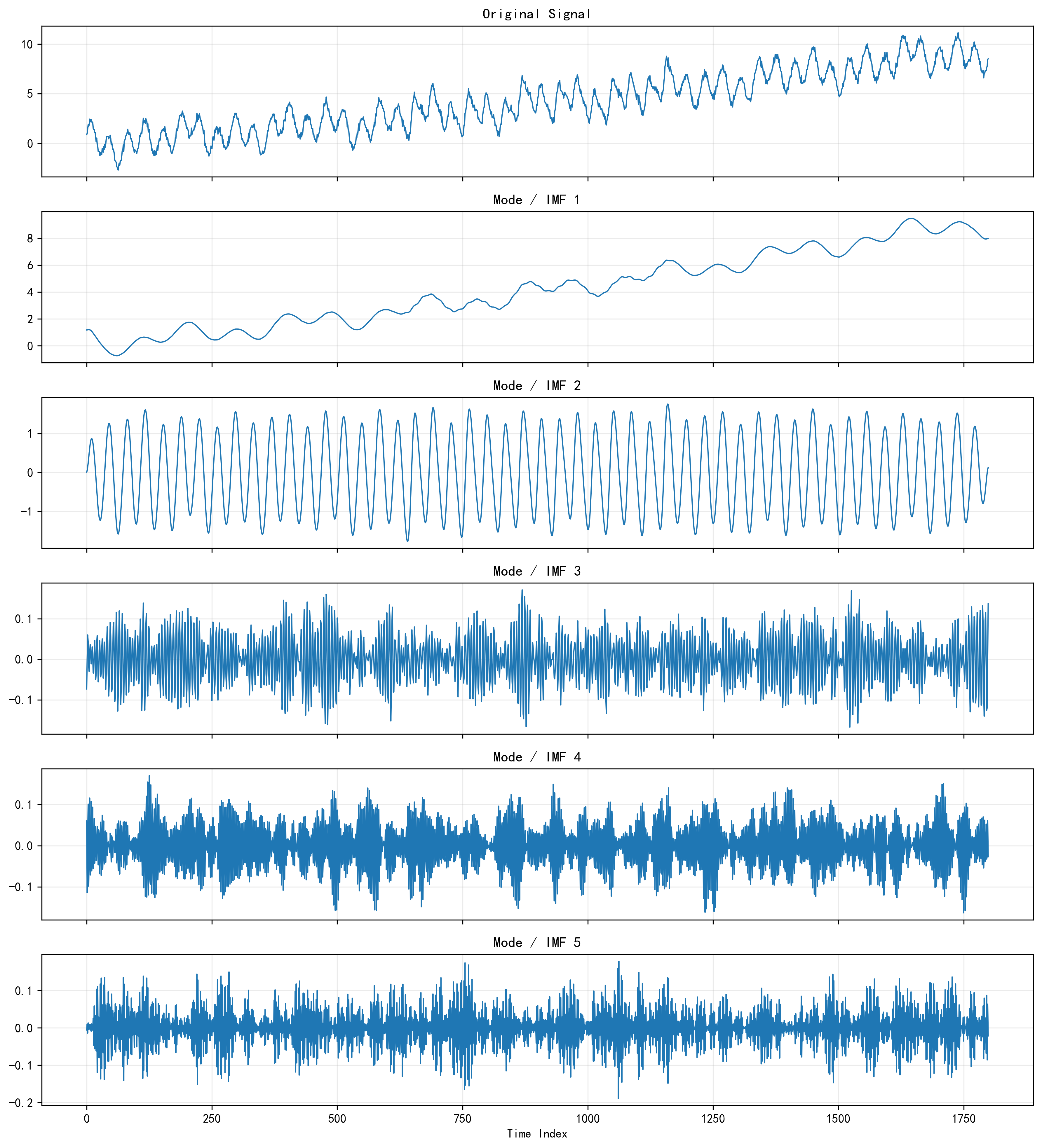
用来展示不同模态的频率分布差异。因为只有把“拆分前”和“拆分后”的结构对比展示出来,后面再讲 KAN、BiLSTM、Transformer 接力建模才更有说服力。
class VMDDecomposer:
def decompose(self, signal: np.ndarray) -> np.ndarray:
signal = np.asarray(signal, dtype=np.float64).flatten()
try:
from vmdpy import VMD
u, _, _ = VMD(signal, self.alpha, self.tau, self.K,
self.DC, self.init, self.tol)
self.method = 'vmdpy'
return np.asarray(u)
except Exception:
self.method = 'fft_fallback'
return self._fft_band_decompose(signal, self.K)五、滑动窗口与样本构造:我如何把连续序列变成可训练样本
时间序列预测最容易被忽视的一步,其实是样本化。
我的模型并不是直接拿整条 [T, F] 的序列去训练,而是通过 SequenceDataset 把它切成很多长度为 seq_len 的输入窗口,再配上长度为 pred_len 的预测目标。默认配置下,sequence_length=64,pred_length=1,所以每个样本都表示“用过去 64 个时间步,预测未来 1 个时间步”。
这个过程可以写成:
其中 LLL 是窗口长度,PPP 是预测步长。在我的实现里,indices 还会顺手记录当前样本对应的预测起点位置,这样后面做预测结果对齐、误差分析和结果落盘时会更方便。
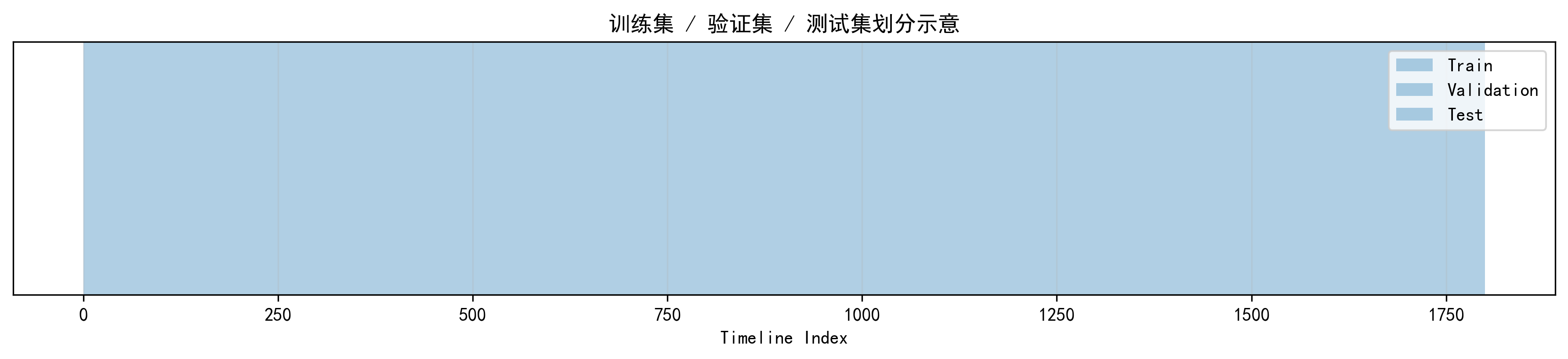 数据集划分示意图,我是先按时间顺序切训练/验证/测试,再分别做窗口化,而不是把时间序列打乱。对时序问题来说,这种顺序感非常重要。对应代码如下:
数据集划分示意图,我是先按时间顺序切训练/验证/测试,再分别做窗口化,而不是把时间序列打乱。对时序问题来说,这种顺序感非常重要。对应代码如下:
class SequenceDataset(Dataset):
def __init__(self, x, y, seq_len, pred_len):
self.x, self.y, self.indices = [], [], []
total = len(x)
for i in range(total - seq_len - pred_len + 1):
self.x.append(x[i:i + seq_len])
self.y.append(y[i + seq_len:i + seq_len + pred_len])
self.indices.append(i + seq_len)
self.x = np.asarray(self.x, dtype=np.float32)
self.y = np.asarray(self.y, dtype=np.float32)
self.indices = np.asarray(self.indices, dtype=np.int64)我在这里这样写,是因为滑动窗口本质上不是“切片技巧”,而是把时序任务转成监督学习任务的关键桥梁。没有这一步,后面的网络结构再复杂,也没有办法吃到规范化的批量样本。
六、KAN + BiLSTM + Transformer:这是我整篇项目里最核心的部分
1)Feature Gating:我先让模型学会“该看谁”
在这个模型里,我没有一上来就把所有通道平等送进去,而是先做了一个动态特征门控。
FeatureGating 的做法很直观:我先对输入 x 在时间维上做平均池化,得到 [B, F] 的全局特征摘要;然后把它送进一个小型 MLP,输出每个通道的打分;最后用 softmax 归一化成权重,再把这些权重乘回原始输入。也就是说,输入是 [B, S, F],门控后的输出还是 [B, S, F],但每个特征通道的重要性已经被重新分配了。
这个过程可以写成:
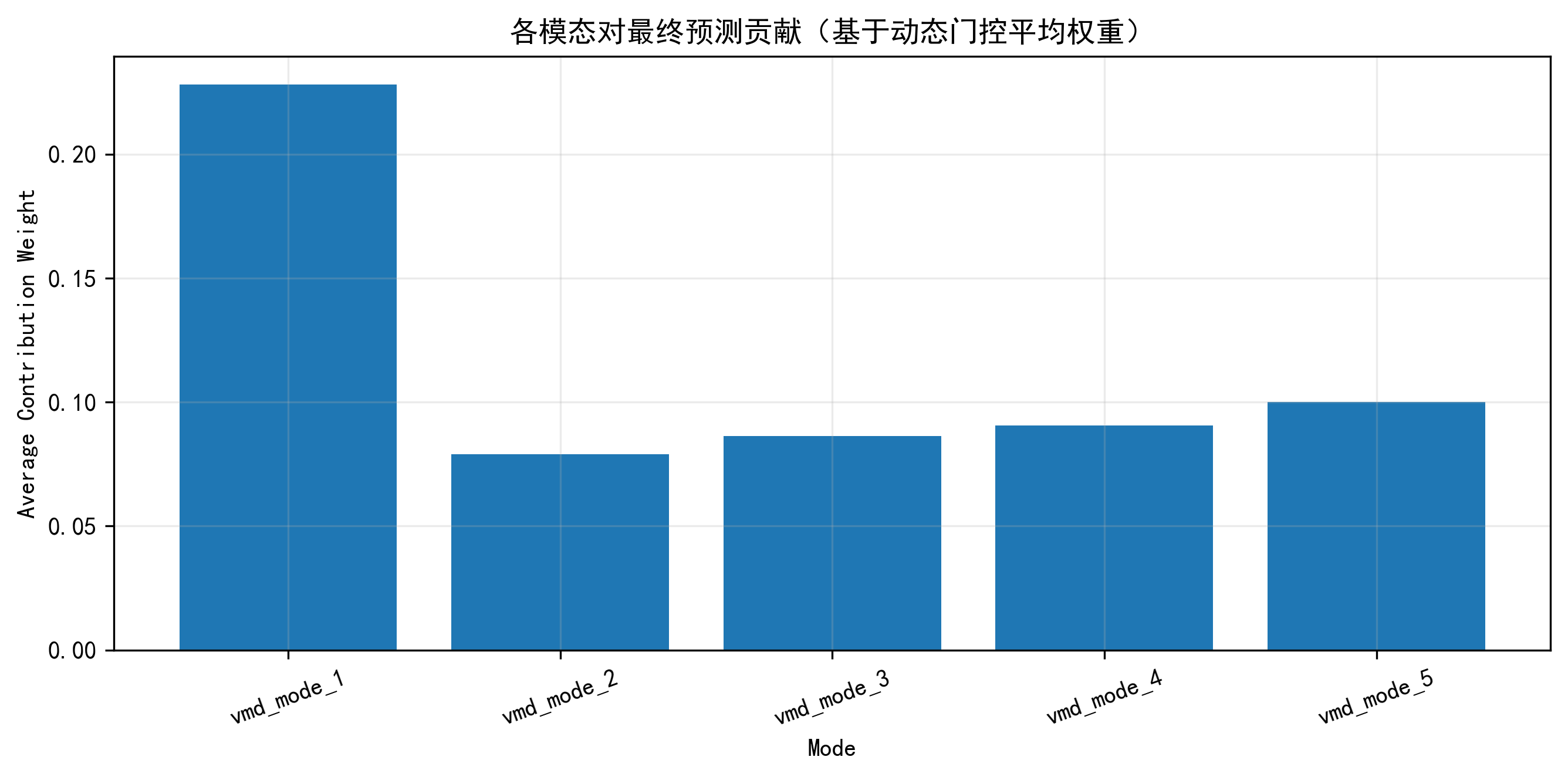
这里的 xˉ\bar{x}xˉ 是对时间维做平均后的特征摘要。在我的项目里,这一步尤其适合 VMD 之后的多模态输入,因为不是所有模态都对最终预测同等重要。后面我还把平均门控权重拿去画了模态贡献图,让这一步不只是“暗箱操作”,而是可视化、可解释的。
代码如下:
class FeatureGating(nn.Module):
def __init__(self, input_dim, hidden_dim=64, dropout=0.1):
super().__init__()
self.gate_net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, input_dim)
)
def forward(self, x):
pooled = x.mean(dim=1)
gate_logits = self.gate_net(pooled)
gate = torch.softmax(gate_logits, dim=-1)
x_weighted = x * gate.unsqueeze(1)
return x_weighted, gate我这里没有用特别复杂的注意力门控,就是因为这一步的目标很明确:在计算开销可控的前提下,先做一次动态通道重标定。
2)KANLinear / KANBlock:我用 RBF 展开近似 KAN 思想
这一部分是我觉得很有意思的地方。代码里的 KANLinear 并不是原版 KAN 的严格复刻,但它保留了一个非常重要的思想:不只是做一次普通线性映射,而是先把输入投影到一组可学习的基函数上,再做线性组合。
我这里选的是 RBF 基函数。对每个输入特征 xix_ixi,我都会在若干中心点 ci,jc_{i,j}ci,j 上做径向基展开:
然后把这些展开后的响应拼起来,再做线性投影。这个思路特别适合时间序列中的非线性局部结构,因为很多波动模式不是简单 MLP 一次线性变换就能刻画好的。我的代码里,中心点 centers 是可学习参数,宽度由 log_sigma 决定;展开后的 RBF 特征维度从 F 变成 F * G,其中 G=grid_size。默认网格数是 8。
如果按张量维度来跟,输入 x 是 [B, S, F]。我先把它 reshape 成 [B*S, F],再扩展成 [B*S, F, 1] 去和中心点 [1, F, G] 做广播运算,得到 [B*S, F, G] 的 RBF 响应,最后再展平为 [B*S, F*G],经过 rbf_linear 和 base_linear 叠加后回到输出维度,最终 reshape 回 [B, S, H]。这个过程其实非常贴近“先做非线性基函数展开,再回到表示空间”的直觉。
对应代码如下:
class KANLinear(nn.Module):
def __init__(self, in_features, out_features, grid_size=8, dropout=0.1):
super().__init__()
centers = torch.linspace(-2.5, 2.5, grid_size)
self.centers = nn.Parameter(centers.repeat(in_features, 1), requires_grad=True)
self.log_sigma = nn.Parameter(torch.zeros(in_features, grid_size))
self.base_linear = nn.Linear(in_features, out_features)
self.rbf_linear = nn.Linear(in_features * grid_size, out_features)
def forward(self, x):
b, s, f = x.shape
x_flat = x.reshape(-1, f)
centers = self.centers.unsqueeze(0)
sigma = torch.exp(self.log_sigma).unsqueeze(0) + 1e-6
x_expand = x_flat.unsqueeze(-1)
rbf = torch.exp(-((x_expand - centers) ** 2) / (2 * sigma ** 2))
rbf = rbf.reshape(x_flat.shape[0], -1)
out = self.base_linear(x_flat) + self.rbf_linear(rbf)
return out.reshape(b, s, self.out_features)KANBlock 在这之上又叠了两层 KANLinear,并且加了残差投影和 LayerNorm。我这么写,是想让它不只是“非线性映射器”,同时也成为一个稳定的序列特征提取块。
3)BiLSTM:我需要它来抓住双向时序依赖
经过门控和 KAN 之后,序列表征已经从原始通道特征变成了更高维的抽象特征。接下来我用 BiLSTM 去建模。
为什么是双向?因为在一个长度为 64 的输入窗口里,某个时间步的重要性,往往要同时参考它前后的上下文。虽然最终预测是“向未来看”,但在输入窗口内部,双向编码能更充分地利用历史片段之间的关系。我的实现里,hidden_size=128,但 LSTM 的单向隐藏维是 hidden_size // 2 = 64,因为双向拼接后正好回到 128。这样后面接 Transformer 时张量尺寸就非常自然。
LSTM 的核心门控逻辑,通常会简写成:
在我这个项目里,这一块最重要的价值不是公式本身,而是它帮我把 KAN 提取出的局部非线性模式,继续组织成更有时序感的隐藏状态序列。
4)Transformer:我再让模型看更远的依赖关系
BiLSTM 很擅长按顺序编码,但我还是希望模型能显式看到更长距离的依赖,所以后面我又接了 TemporalTransformer。
这部分先做位置编码,再串多个自定义的 TransformerEncoderLayerWithWeights。我这里特意保留了注意力权重 attn_weights,因为后面我想把它画成热力图,而不只是让 Transformer 当一个黑箱。对应的注意力公式大家都很熟悉:
但在我的项目里,它真正的意义是:当序列某一段模式需要参考更早或更晚的关键片段时,Transformer 能通过显式权重把这种关系拉出来,而不仅仅依赖递归状态去“隐式记忆”。
5)Prediction Head:我没有只取最后一步,而是融合了局部与全局
很多序列模型最后只取最后一个 token 去做预测,但我这里没有这么简单粗暴。
在 forward() 里,我同时取了 x_tf[:, -1, :] 作为最后时刻表征,又取了 x_tf.mean(dim=1) 作为全局平均表征,然后把它们拼成 [B, 2H],再送进 head 做预测。这个设计我很喜欢,因为最后时刻表征更偏向近期状态,全局平均表征更偏向整个窗口的总体模式,两者拼起来通常比单独用一个更稳。
如果把整个维度流动写清楚,就是这样:
- 输入:
[B, S, F] - 门控后:
[B, S, F] - KAN 后:
[B, S, H] - BiLSTM 后:
[B, S, H] - Transformer 后:
[B, S, H] last_token:[B, H]mean_pool:[B, H]- 拼接后:
[B, 2H] - 输出:
[B, pred_len]
这套尺寸设计在代码里是完全自洽的。
核心 forward 代码如下:
def forward(self, x):
x_weighted, gate = self.gating(x) # [B, S, F]
x_kan = self.kan(x_weighted) # [B, S, H]
x_lstm, _ = self.bilstm(x_kan) # [B, S, H]
x_tf, attn = self.transformer(x_lstm) # [B, S, H]
last_token = x_tf[:, -1, :]
mean_pool = x_tf.mean(dim=1)
fused = torch.cat([last_token, mean_pool], dim=-1)
out = self.head(fused)
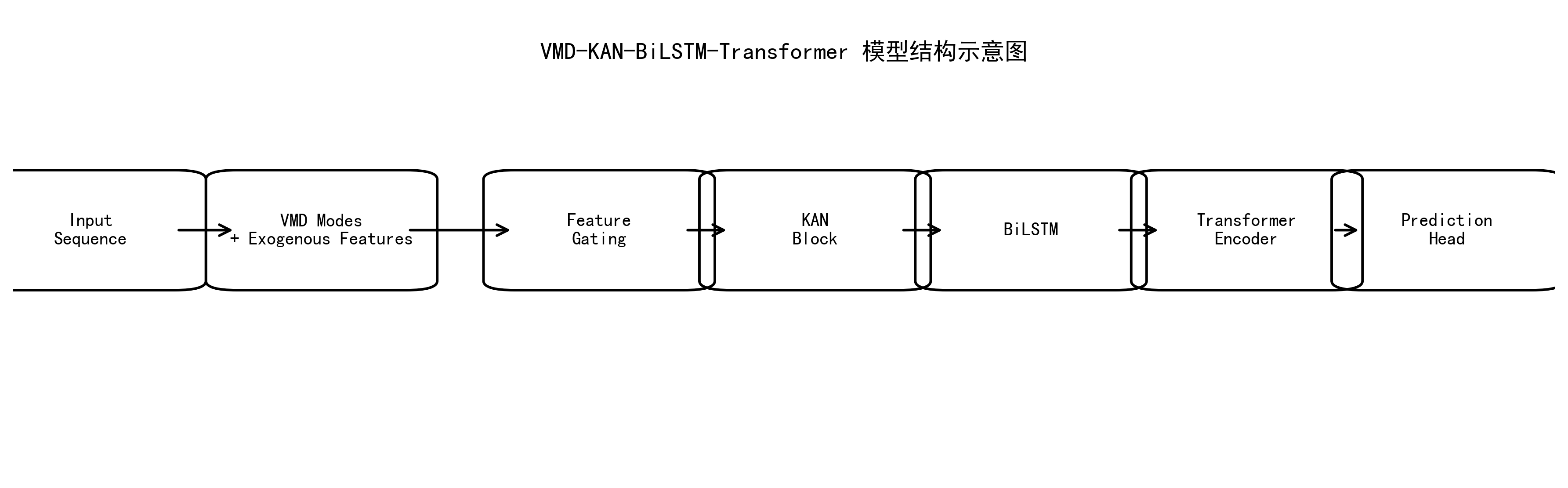
return {'pred': out, 'attn': attn, 'gate': gate}我会在这一节插入模型结构示意图。这张图在我的代码里是直接画出来的,不需要额外手工绘制。它能把“输入序列 -> VMD 模态与外生特征 -> Gating -> KAN -> BiLSTM -> Transformer -> Head”的流程一眼讲清楚。
七、训练策略与评估方法:我怎么让训练过程更像一个规范实验
这份代码在训练部分并不花哨,但很扎实。
我用的是 MSELoss 作为损失函数,优化器选了 AdamW,同时加了 ReduceLROnPlateau 学习率调度器和 EarlyStopping。我这么搭配的原因很明确:AdamW 在时序深度模型里通常足够稳,权重衰减可以稍微抑制过拟合;ReduceLROnPlateau 会在验证损失不再下降时自动把学习率减半;EarlyStopping 则会在连续若干轮没有改善时提前结束训练,避免无意义迭代。除此之外,我还加了梯度裁剪 clip_grad_norm_,默认阈值是 1.0,用来避免梯度爆炸。
对应的训练逻辑其实很清晰:
def train_one_epoch(model, loader, optimizer, criterion, device, grad_clip=1.0):
model.train()
total_loss = 0.0
for batch_x, batch_y, _ in loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device).squeeze(-1)
optimizer.zero_grad()
outputs = model(batch_x)
pred = outputs['pred']
loss = criterion(pred, batch_y)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
optimizer.step()
total_loss += loss.item() * batch_x.size(0)
return total_loss / len(loader.dataset)我在这里这样写,是因为训练过程最怕“看似能跑,实际上不可控”。把标准训练步骤、验证步骤、早停、调度器、最佳权重保存都写完整,后面出图和复盘就会非常自然。
评估时,我先调用 predict() 收集预测值、真实值、索引、注意力和门控结果,再用目标缩放器做反归一化,最后计算 MAE、MSE、RMSE、MAPE、SMAPE 和 R²。对应公式分别是:
在代码里,MAPE 和 SMAPE 都额外加了一个很小的 eps=1e-8,是为了避免分母过小导致数值不稳定。
def evaluate_model(model, test_loader, target_scaler, cfg, info, save_prefix):
preds_scaled, trues_scaled, indices, attn, gates = predict(model, test_loader, cfg.device)
preds, trues = inverse_transform_predictions(preds_scaled, trues_scaled, target_scaler)
metrics = compute_metrics(trues, preds)
np.save(os.path.join(cfg.output_dir, f'{save_prefix}_preds.npy'), preds)
np.save(os.path.join(cfg.output_dir, f'{save_prefix}_trues.npy'), trues)
plot_saved_prediction_windows(trues, preds, cfg.output_dir)
plot_metric_bar(metrics, os.path.join(cfg.output_dir, 'metrics_bar.png'))
plot_attention_heatmap(attn, os.path.join(cfg.output_dir, 'attention_heatmap.png'))
plot_mode_contribution(gates, info['feature_names'], cfg.vmd_k,
os.path.join(cfg.output_dir, 'mode_contribution.png'))八、可视化设计与结果分析:我不想让项目停在一串数字上
这份项目的可视化部分,我是认真下过功夫的。因为我一直觉得,一个高质量的时间序列项目,绝不应该只展示“最终指标表”。
原始时间序列图
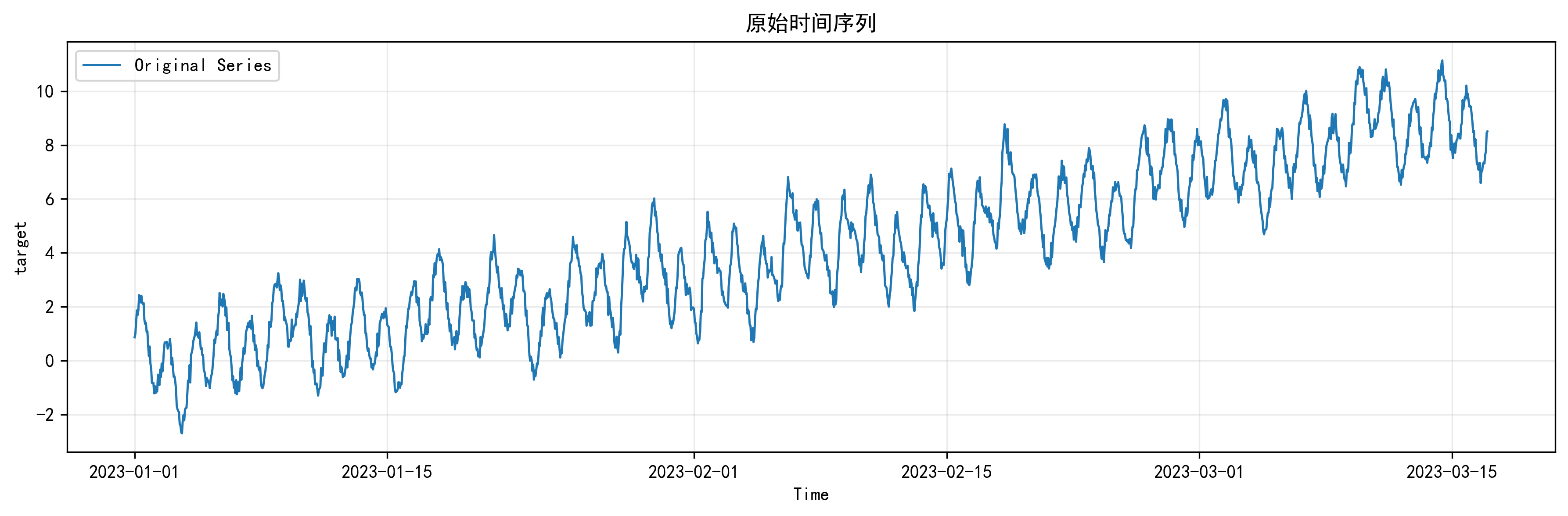
这张图是整个项目的起点。我会用它展示原始数据整体的趋势抬升、周期起伏和局部扰动区间。如果是合成数据,这张图能很好地说明数据构造是否合理;如果换成真实数据,它也能帮我快速判断这个任务到底是趋势驱动、周期驱动,还是噪声主导。
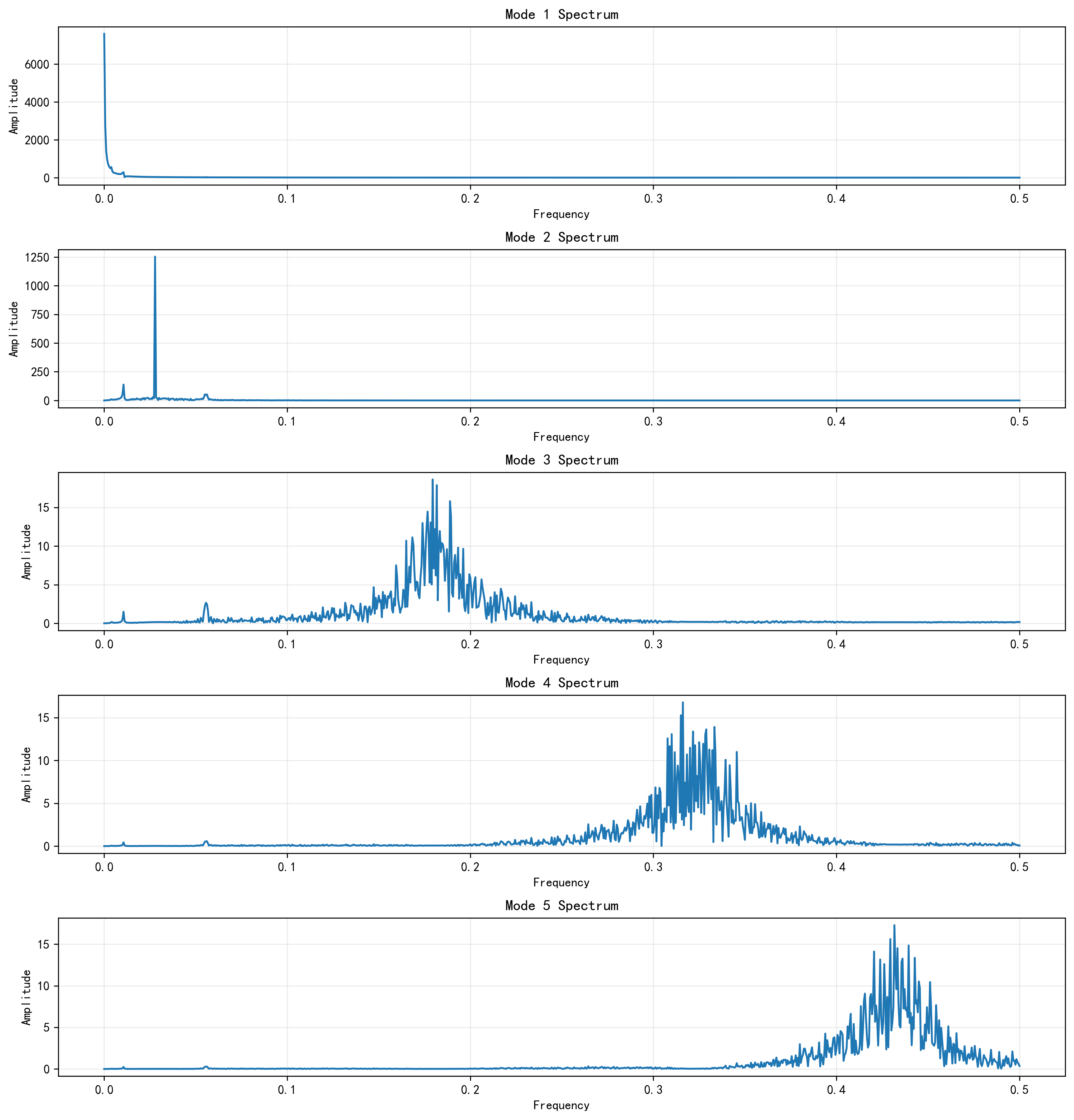
VMD 分解图与频谱图
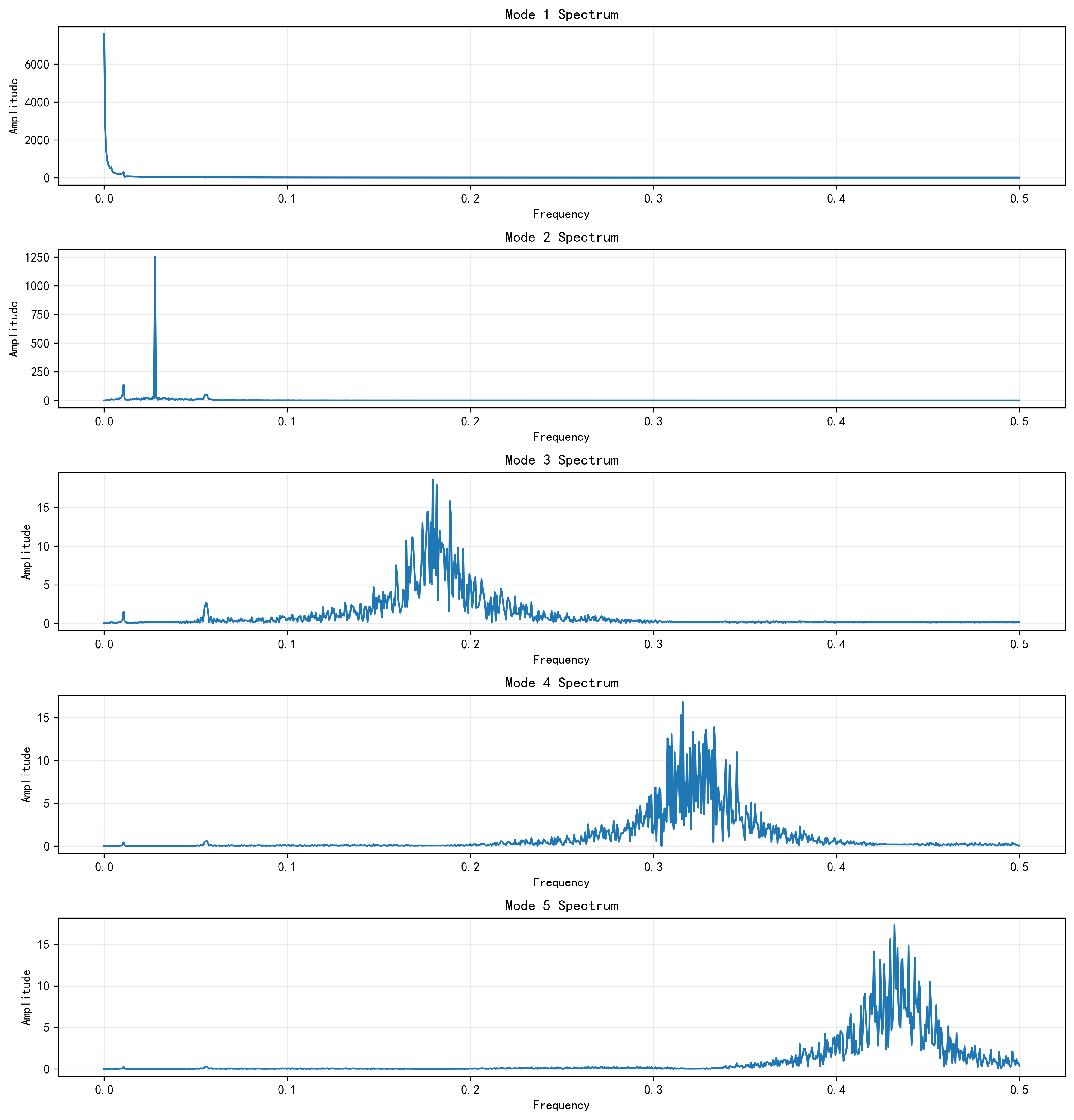
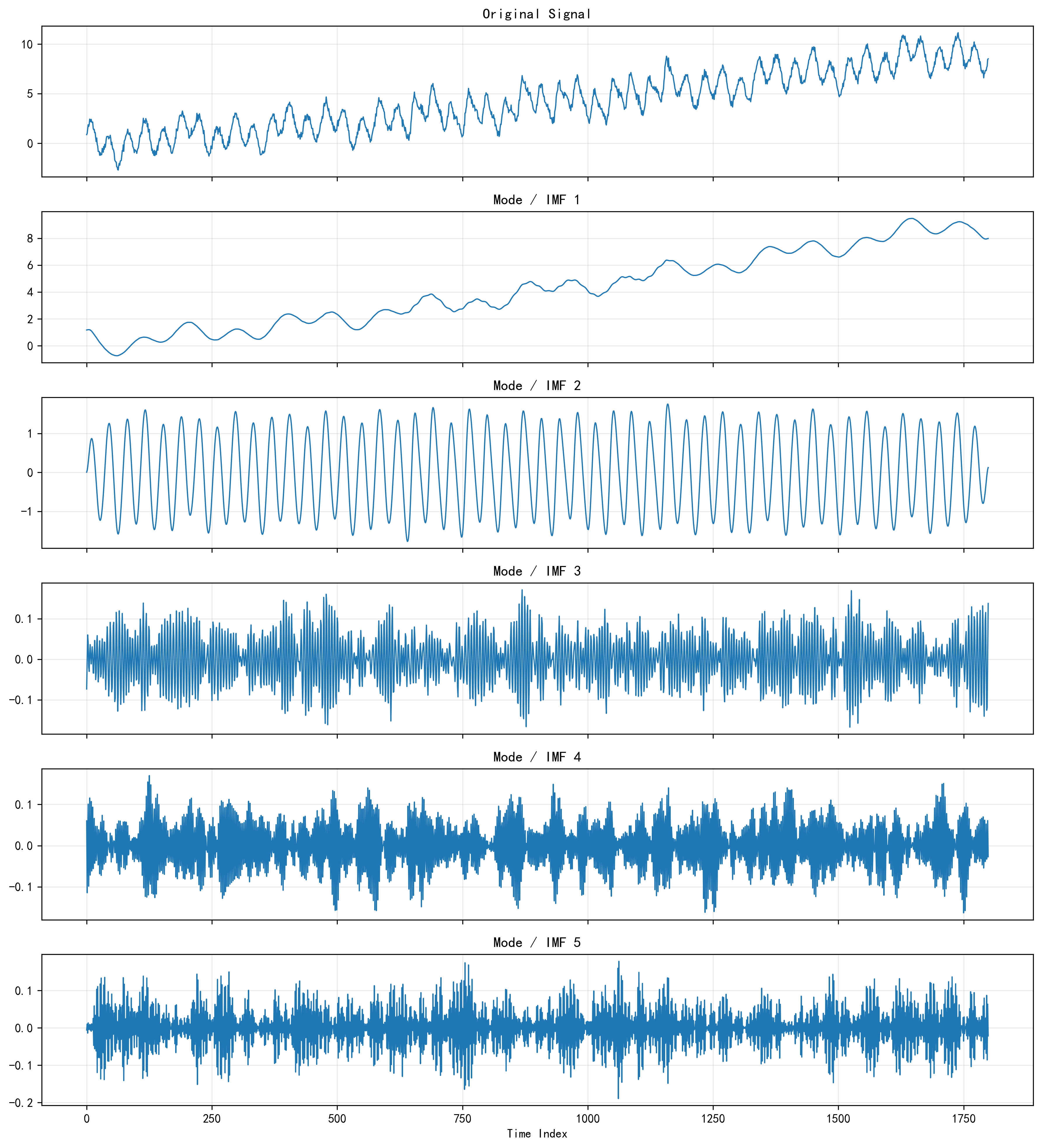
接下来我会放出 VMD 分解图,观察不同模态的时域形态;再放 VMD 频谱图,观察不同模态的频带集中程度。前者告诉我“每个模态长什么样”,后者告诉我“每个模态主要在什么频率范围活动”。如果这两张图能明显把高频扰动、低频趋势、中频周期区分开,那说明前置分解起到了作用。
数据集划分示意图
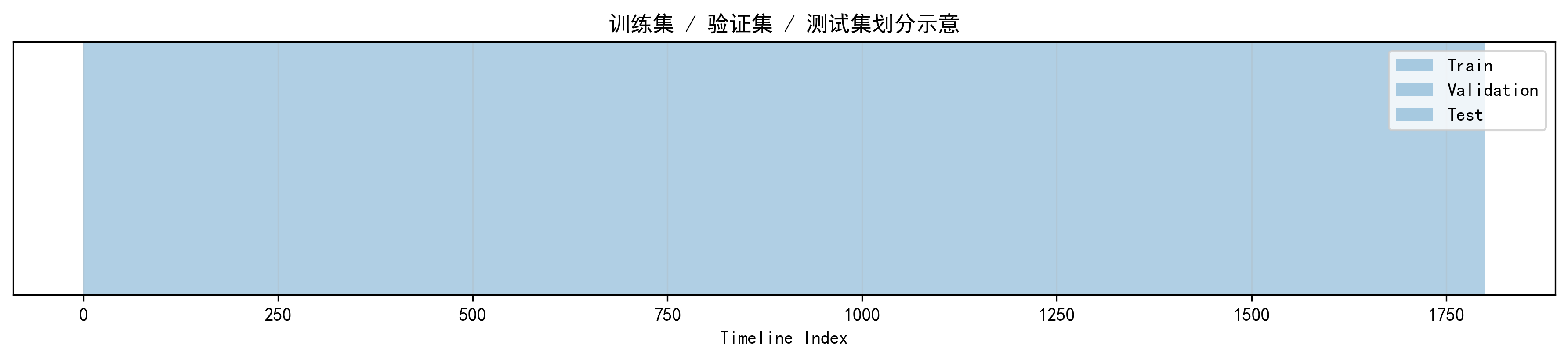
这张图看起来简单,但很适合博客展示。它可以直接说明我不是随机切分,而是按时间顺序划分 train/val/test,符合时间序列实验的基本规范。
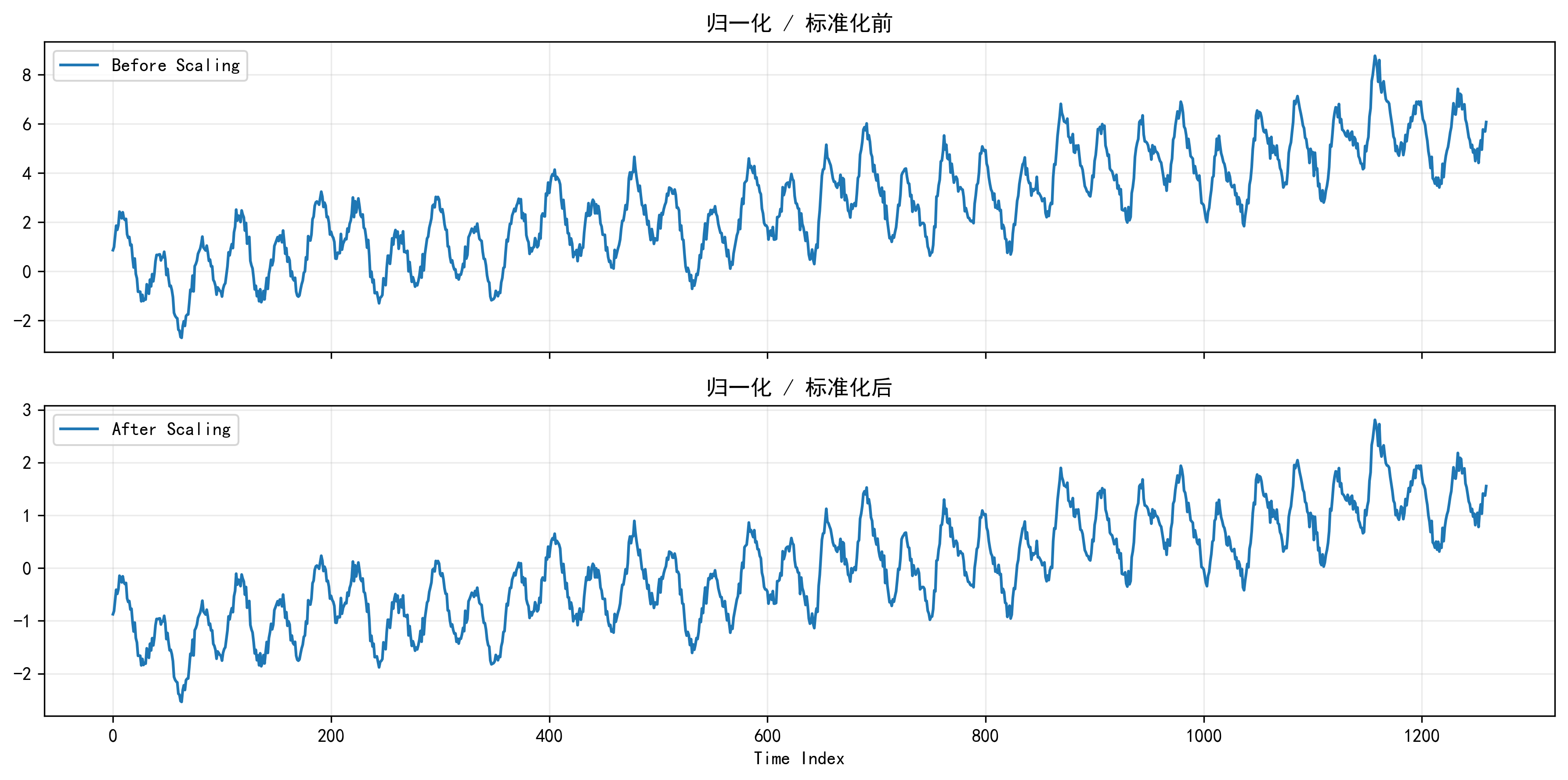
归一化前后对比图
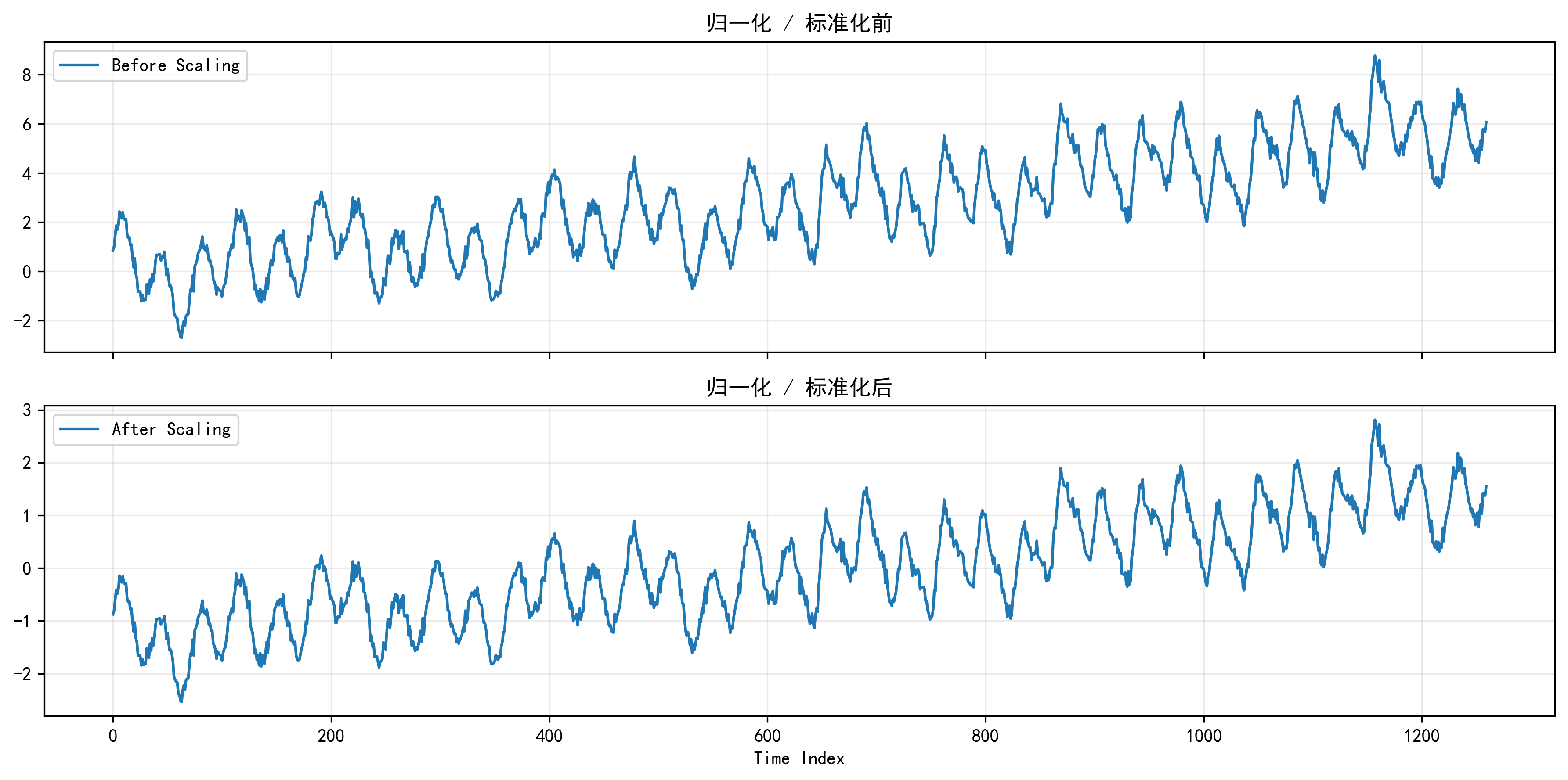
我会在数据预处理部分插入这张图,让读者直观看到同一序列在缩放前后的幅值差别。很多人嘴上说“归一化有助于训练”,但没有图往往就显得很空。这张图正好能把这一步讲实。
训练损失曲线、验证损失曲线、学习率变化曲线
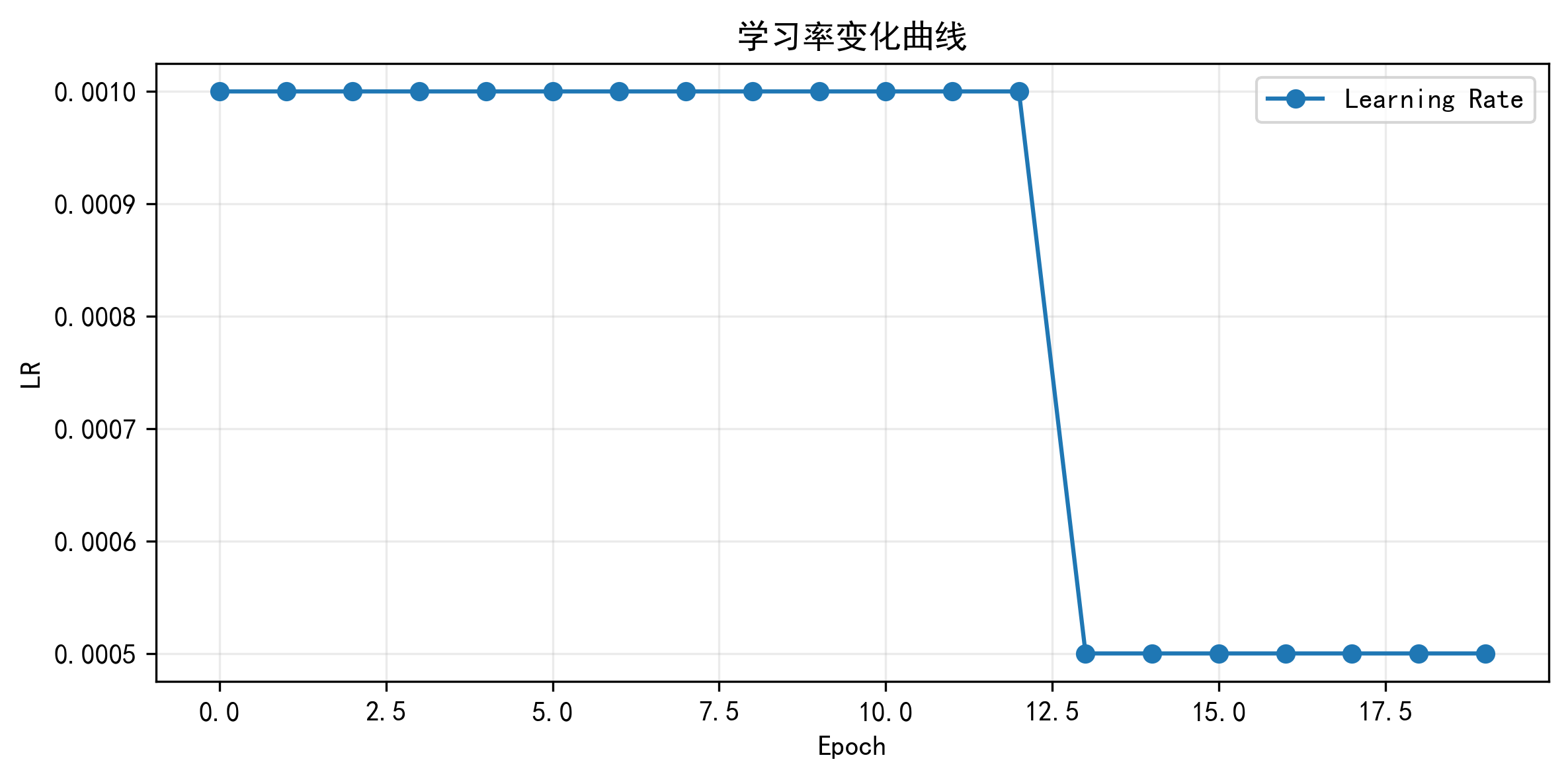
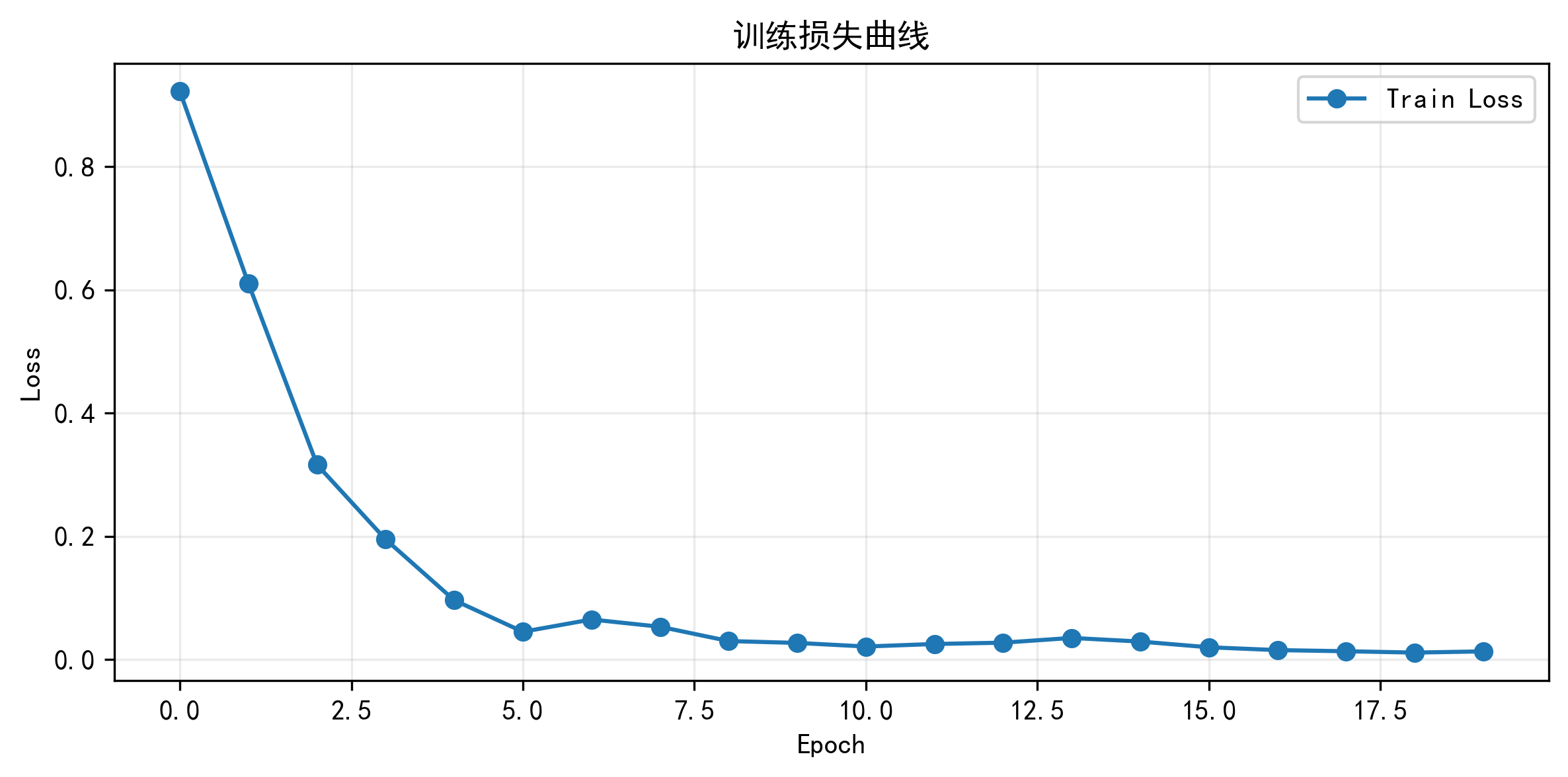
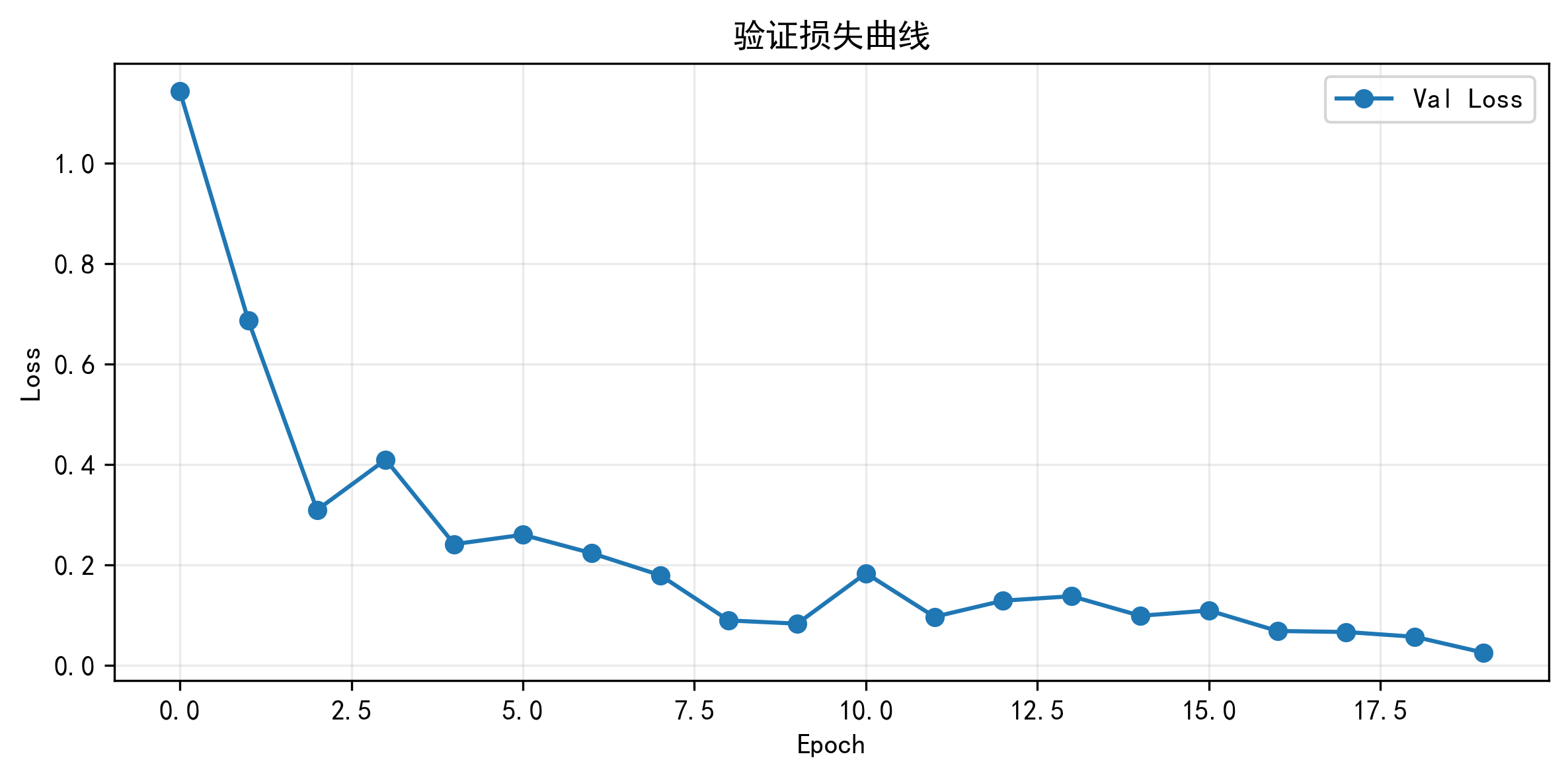
训练结束后,我最先看的不是测试集,而是三张训练过程图:训练损失、验证损失、学习率。
训练损失图看收敛速度,验证损失图看泛化趋势,学习率图则能说明调度器是否真的在验证停滞时起了作用。如果验证损失在下降后逐渐稳定,同时学习率出现阶段性下降,那通常说明 ReduceLROnPlateau 发挥了作用;如果验证损失持续不改善后训练提前终止,那也能印证早停逻辑是有效的。
真实值 vs 预测值曲线、局部放大图
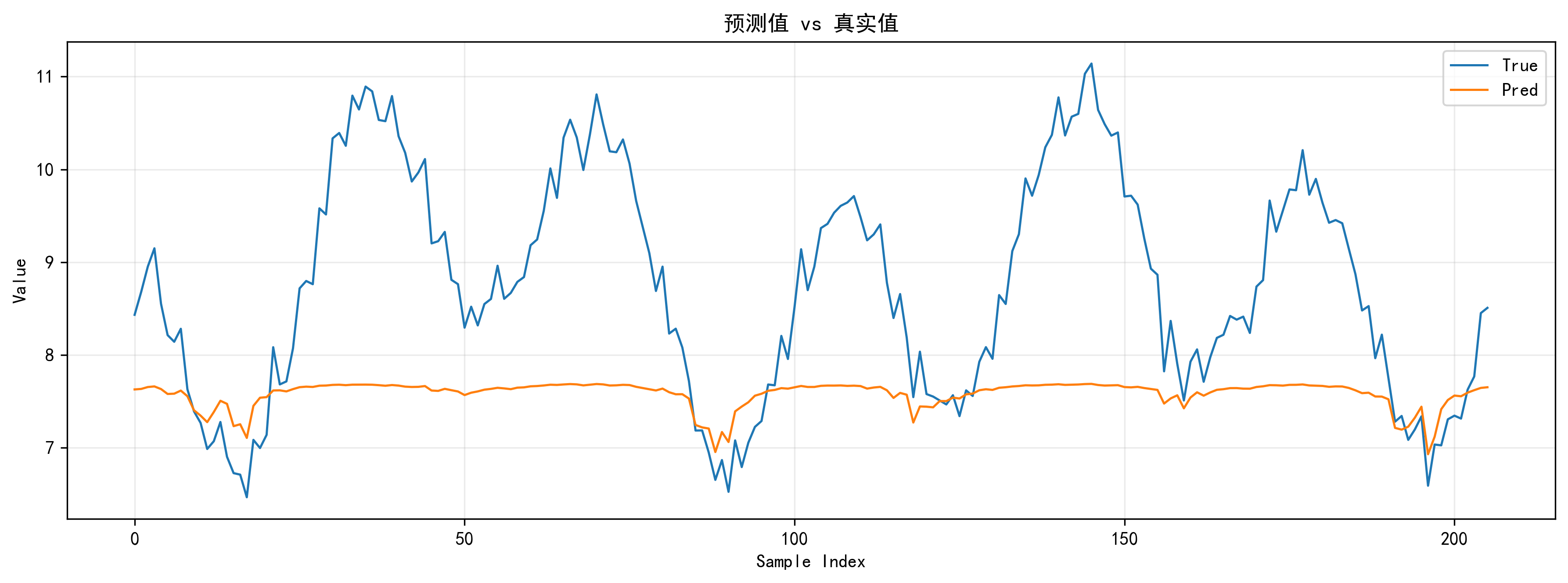
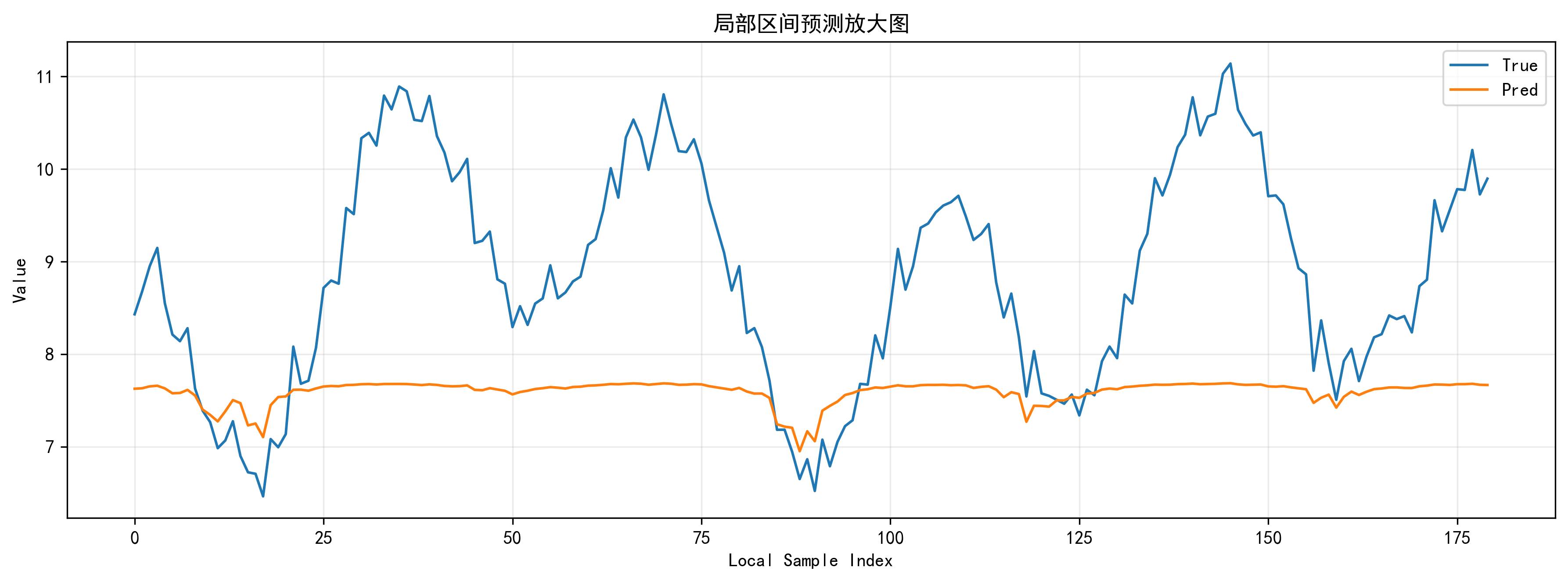
这是我最喜欢展示的两张图。全局图看整体拟合走势,局部放大图看模型能不能跟住峰谷变化。我的代码里局部窗口默认从起点开始,长度 180,所以很适合拿来展示连续一段的细节跟踪能力。
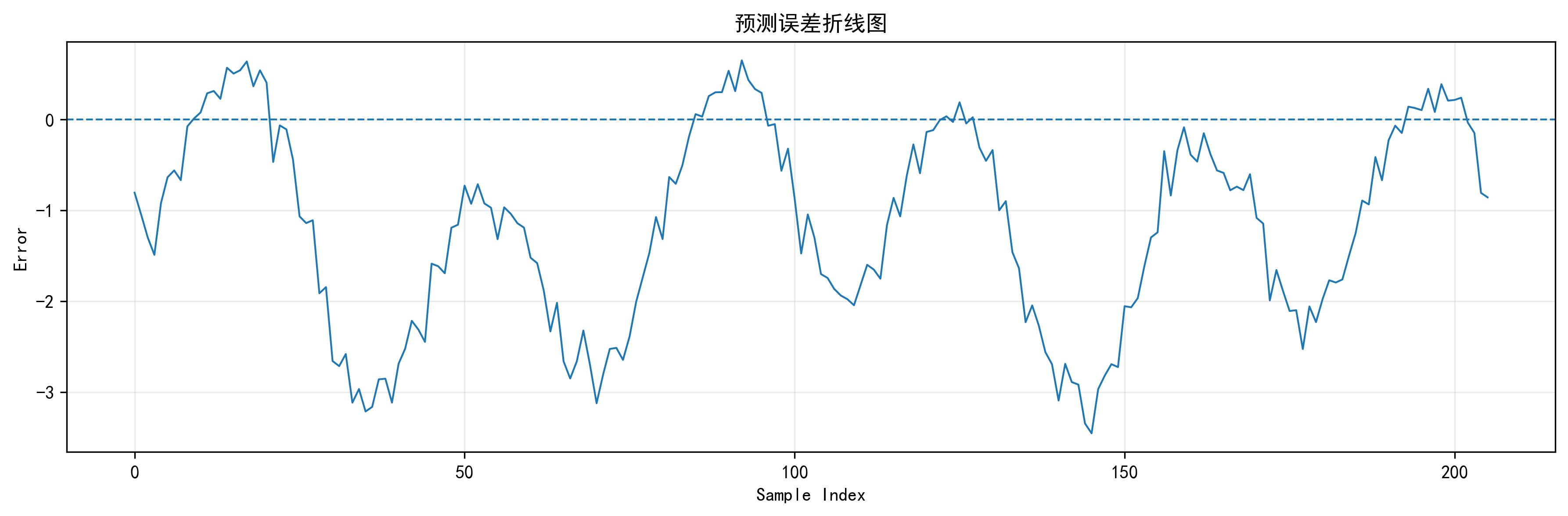
误差随时间变化图、残差直方图、残差箱线图
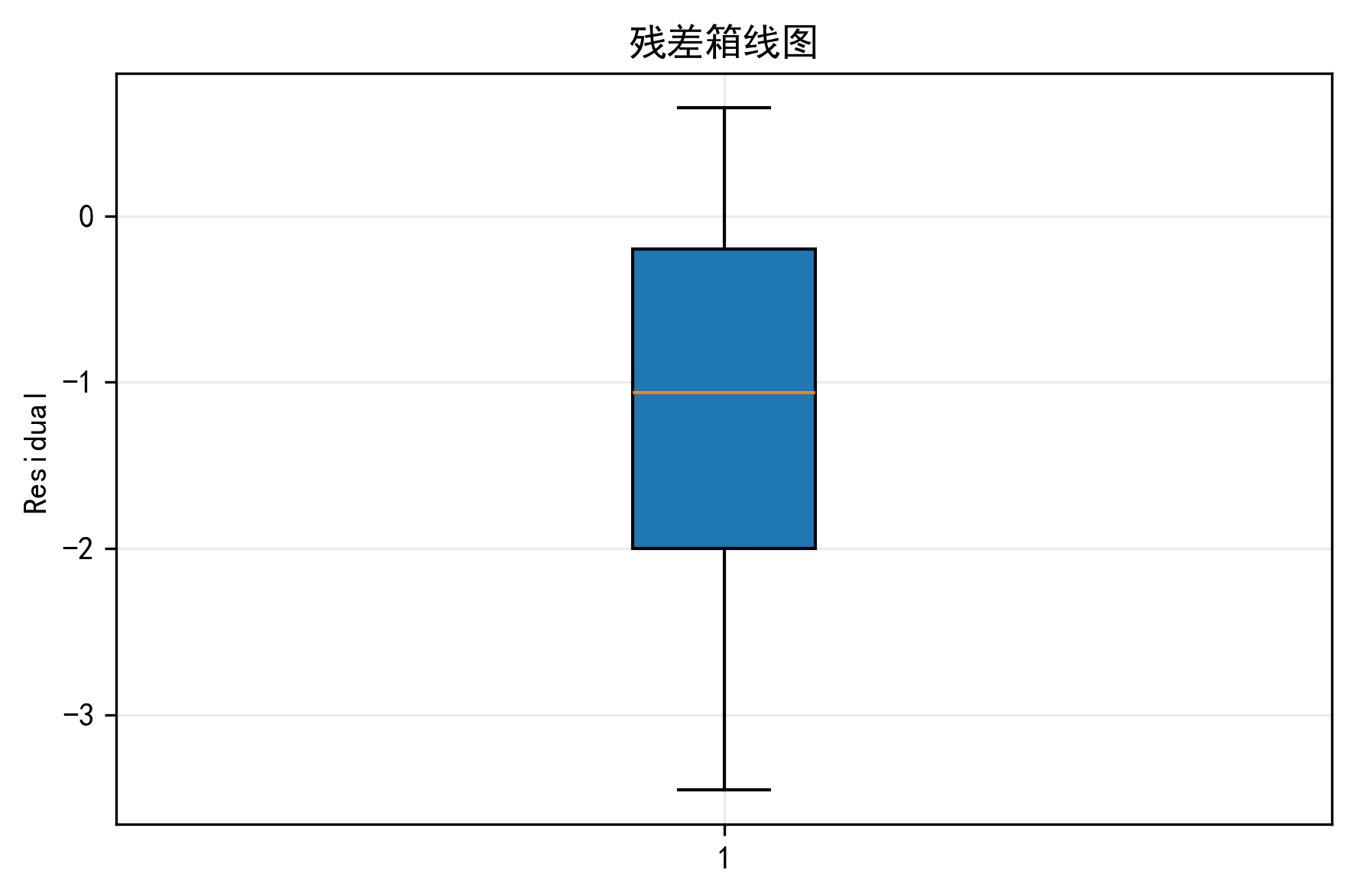
如果预测对比图看的是“像不像”,那误差图和残差图看的是“错在哪里”。
误差随时间变化图可以帮助我定位某些区间是否系统性偏高或偏低;残差直方图可以看误差是否大致集中在 0 附近;箱线图则能帮我观察离群误差是否明显。如果残差分布过宽,或者箱线图里异常点很多,那通常意味着模型对某些局部模式还不够稳。
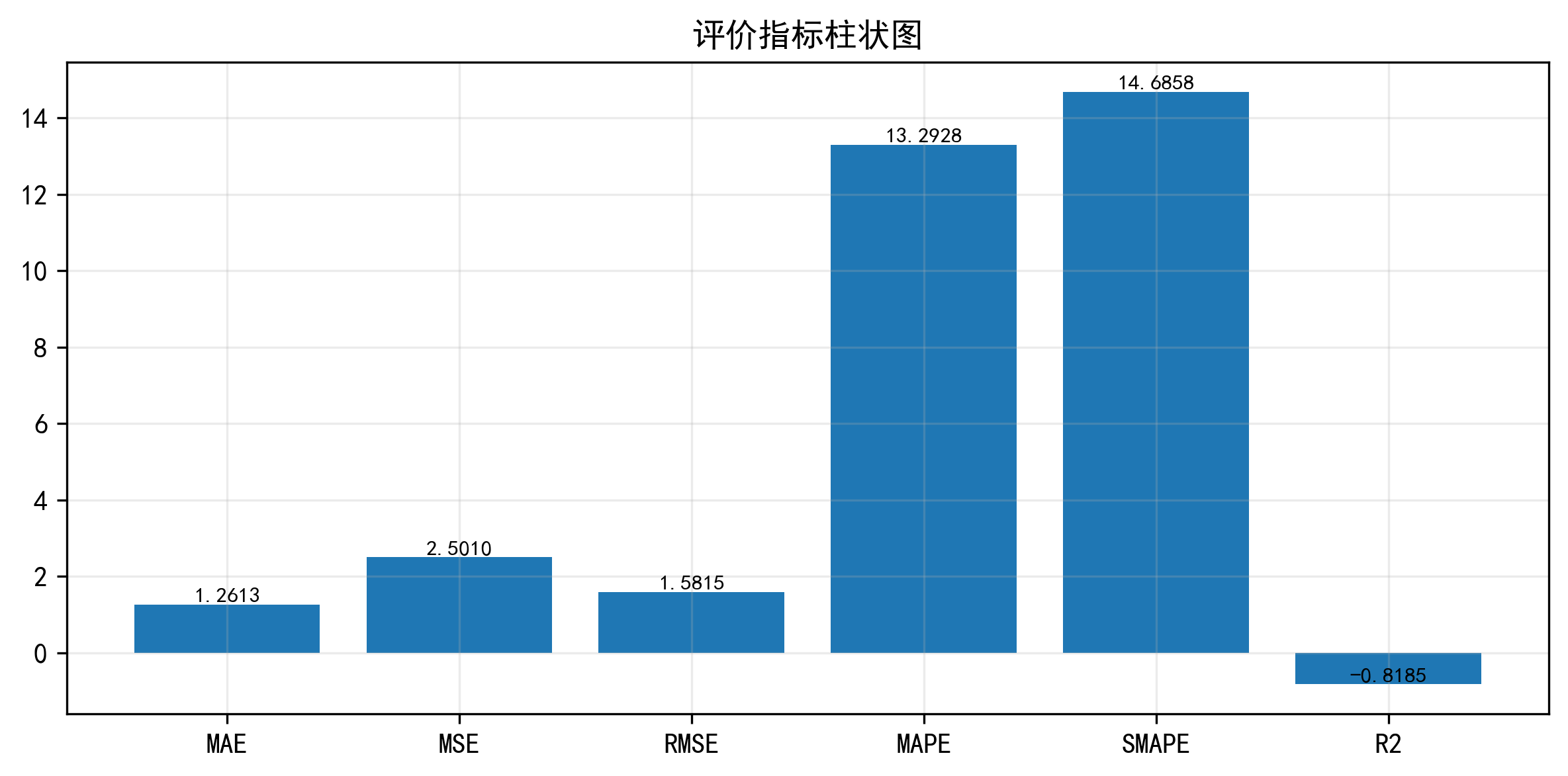
指标柱状图
这一张图非常适合博客和答辩。因为 MAE、RMSE、MAPE、SMAPE、R² 这些指标如果只写在文字里,读者很难一眼抓重点。做成柱状图之后,模型整体表现会更直观。

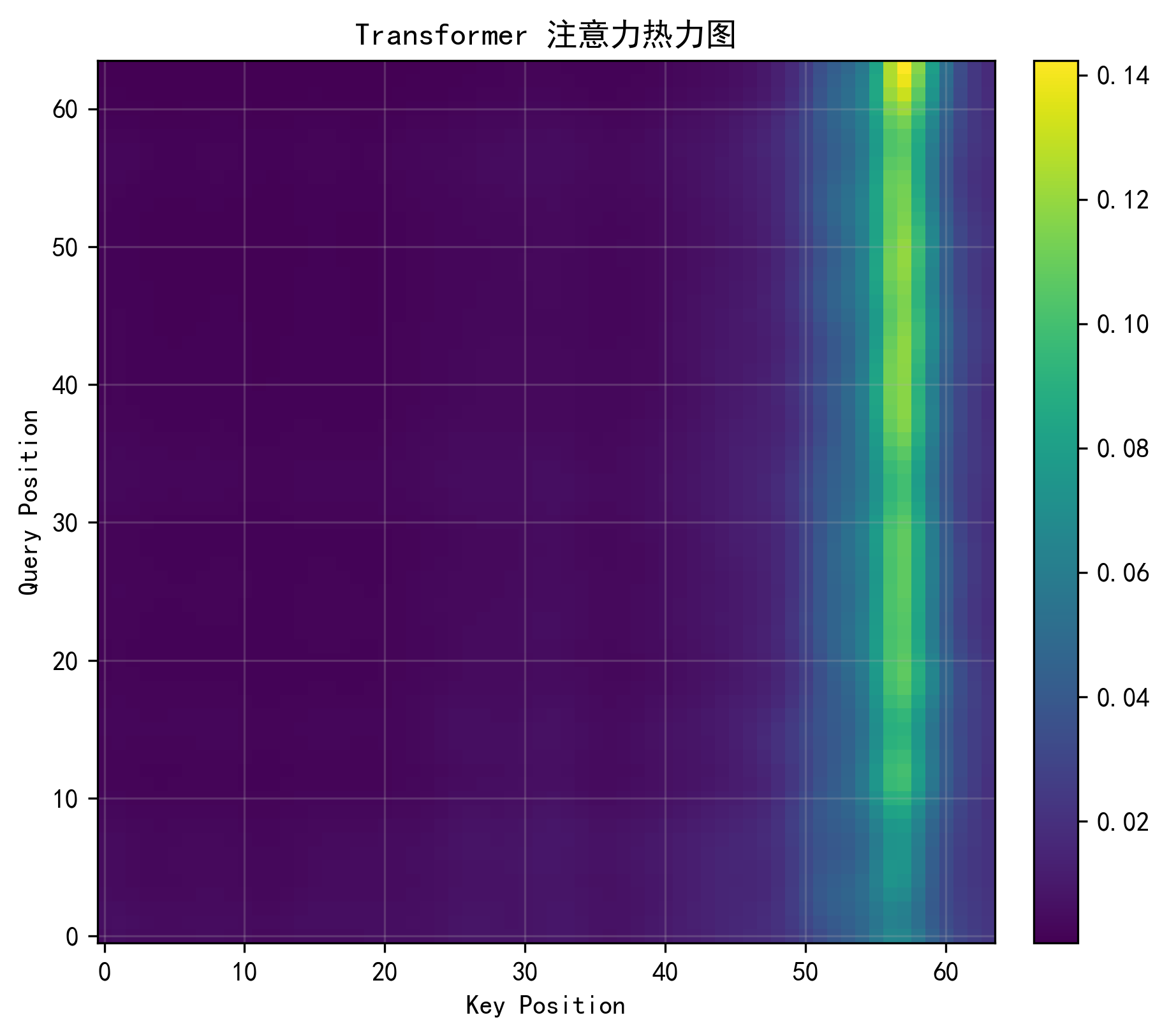
注意力热力图
这是 Transformer 部分最有“展示感”的一张图。我在自定义编码器层里保留了每一层的注意力权重,最终取最后一层的注意力并在 head 维上平均,然后画成热力图。这样我就能观察模型在某个样本上,到底更关注哪些时间位置。
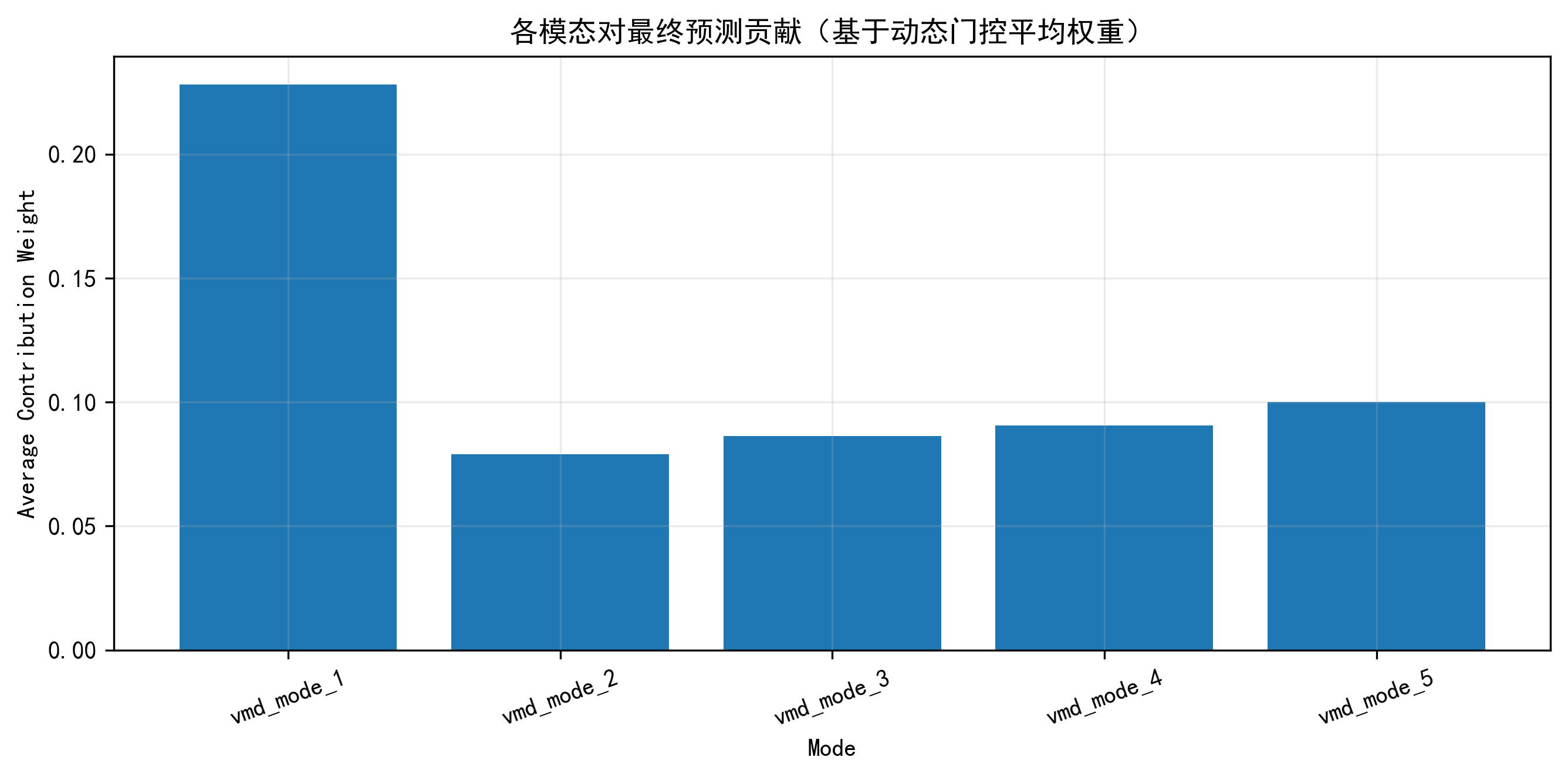
模态贡献图
这张图是我非常想保留的,因为它把 Feature Gating 的输出变成了可解释结果。平均门控权重越高,说明对应模态在整体预测中越重要。对于做信号分解的时间序列项目来说,这张图比单纯说“我做了门控”更有说服力。
真实值 vs 预测值散点图
这张图的作用是看点云是否尽量贴近对角线。如果散点围绕 y=xy=xy=x 分布得很紧,说明整体拟合质量较好;如果偏离严重,则说明模型可能存在系统性偏差。
多步预测图
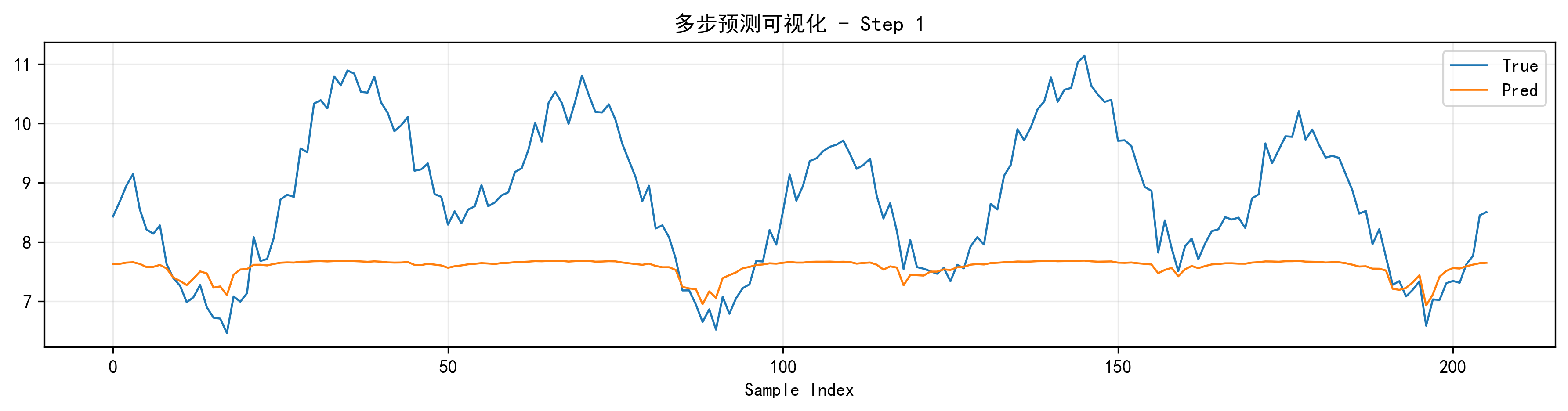
虽然默认 pred_length=1,但我的代码已经预留了多步预测接口,plot_multistep_prediction() 会在需要时自动按步展开作图;如果是一维输出,它也会自动扩成单步格式来画。这种写法对后续扩展很友好。
消融实验对比图
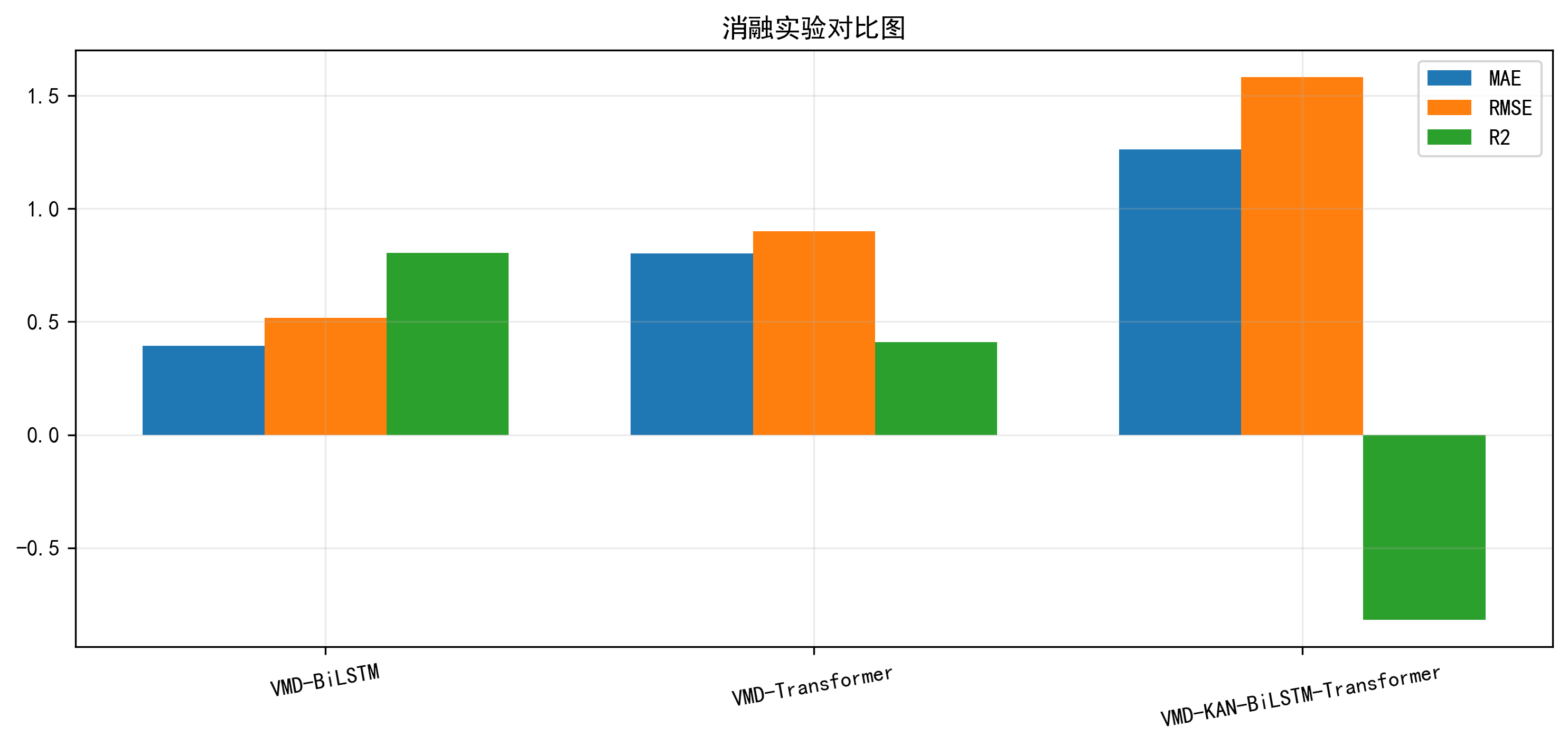
这张图直接用来比较 VMD-BiLSTM、VMD-Transformer 和 VMD-KAN-BiLSTM-Transformer 三个模型在 MAE、RMSE、R² 上的表现。对博客来说,这张图几乎是“方法合理性”的核心证据。
模型结构示意图
这张图用的是 Matplotlib 里的圆角框和箭头绘出来的,不依赖外部绘图软件。它特别适合放在文章前半段,帮助读者先建立整体印象,再往后深入细节。
下面这段代码,就是我把多种预测结果图统一打包输出的入口:
def plot_saved_prediction_windows(y_true, y_pred, save_dir):
plot_prediction_vs_true(y_true, y_pred, os.path.join(save_dir, 'prediction_vs_true.png'))
plot_zoom_prediction(y_true, y_pred, os.path.join(save_dir, 'zoom_prediction.png'),
start=0, length=180)
plot_error_series(y_true, y_pred, os.path.join(save_dir, 'prediction_error_line.png'))
plot_error_series(y_true, y_pred, os.path.join(save_dir, 'error_over_time.png'),
title='误差随时间变化图')
plot_residual_distribution(y_true, y_pred,
os.path.join(save_dir, 'residual_histogram.png'),
os.path.join(save_dir, 'residual_boxplot.png'))九、消融实验:为什么完整模型应该更强
我的消融实验没有做得很复杂,但非常直接。代码里一共比较了三个模型:
第一种是 VMD-BiLSTM,也就是保留 VMD 和 BiLSTM,但去掉 KAN 与 Transformer;第二种是 VMD-Transformer,保留 VMD 和 Transformer,但不用 BiLSTM 与 KAN;第三种是完整的 VMD-KAN-BiLSTM-Transformer。为了提高实验效率,我把消融轮数单独设成了 ablation_epochs=8。
从建模逻辑上讲,我预期这三个模型会体现出很明确的层次差异。
VMD-BiLSTM 的优势在于,它已经能吃到分解后的多模态输入,而且双向循环网络对局部时序模式的编码天然顺手。但它对更长距离的依赖关系建模不如 Transformer 显式。VMD-Transformer 则相反,它更擅长从整个窗口里找远程关联,但对局部连续动态的顺序编码不如 BiLSTM 那么“贴着时序走”。至于完整模型,多出来的 KAN 风格 RBF 非线性展开,相当于先把输入映射到更丰富的基函数空间,再交给后面的时序模块去编码,所以它理论上更适合处理复杂非线性时间序列。
如果从我这个项目的结构来理解,三者差异可以概括为:
- 分解层面:三个模型都使用了 VMD,多模态输入基础一致。
- 非线性表达层面:只有完整模型额外引入了 KAN 风格的 RBF 展开。
- 局部时序层面:BiLSTM 路线更强调窗口内部的双向顺序关系。
- 长程依赖层面:Transformer 路线更强调更远位置之间的关联。
- 融合层面:完整模型把这三类优势串在了一起。
所以我不会简单写“完整模型效果更好”,而会更愿意写成:完整模型在特征重标定、非线性基函数展开、双向局部时序编码和全局注意力关系建模之间形成了更完整的接力链路。也正因为如此,它才更有机会在复杂时间序列上表现得更稳。
需要源代码的,请在评论区下留言,作者会逐个回复,制作不易,请各位看官老爷点个赞

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)