本地部署大模型成趋势!AI养虾者必看:参数设置与避坑指南,轻松实现低成本、高效率、强隐私的AI体验!
随着AI圈“养虾”震荡,Anthropic切断第三方框架接入导致成本暴涨,小米MiMo罗福莉指出第三方框架低效管理造成云端算力浪费。本地部署大模型成为最优解,既能避开云端计费套路,又能兼顾数据安全与工作流自主。本文以LMStudio为例,结合16GB内存起步的硬件要求,讲解大模型参数配置(以Qwen3.5-9B为例),让养虾和日常使用稳定流畅。文章详细介绍了模型加载参数(上下文长度、GPU卸载层数、CPU线程、评估批处理大小)和推理生成参数(系统提示、温度、上下文溢出策略、Top K采样、Top P采样、重复惩罚、最小P采样),并提供了小白稳妥避坑总结,帮助读者在正常使用电脑的前提下,稳定流畅地运行本地大模型。
AI 圈 “养虾” 迎震荡:Anthropic 切断第三方框架对Claude-Pro/Max 订阅的接入,用户转 API 模式后成本暴涨数十倍。小米MiMo罗福莉点破核心,第三方框架的低效管理造成云端算力严重浪费。
这一变动让本地部署大模型成为养虾开发者与普通用户的最优解,既能避开云端计费套路、摆脱API成本束缚,还能兼顾数据安全与工作流自主。而本地部署的关键是做好硬件与参数适配,日常电脑需运行各类后台程序,盲目调参易致模型崩溃、电脑卡顿。
本文以LMStudio为例(ollama也可以参考),结合16GB内存起步的硬件要求,讲解大模型参数配置(以Qwen3.5-9B为例,适配多数大模型),让养虾和日常使用稳定流畅。
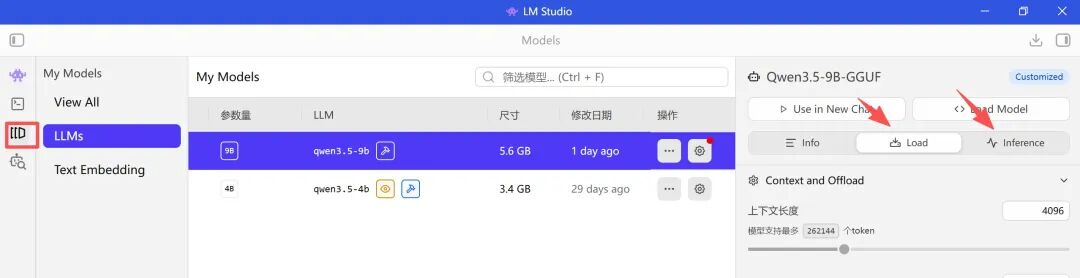
一、模型加载参数
这部分决定模型能不能稳定启动、运行流不流畅,和硬件强相关。
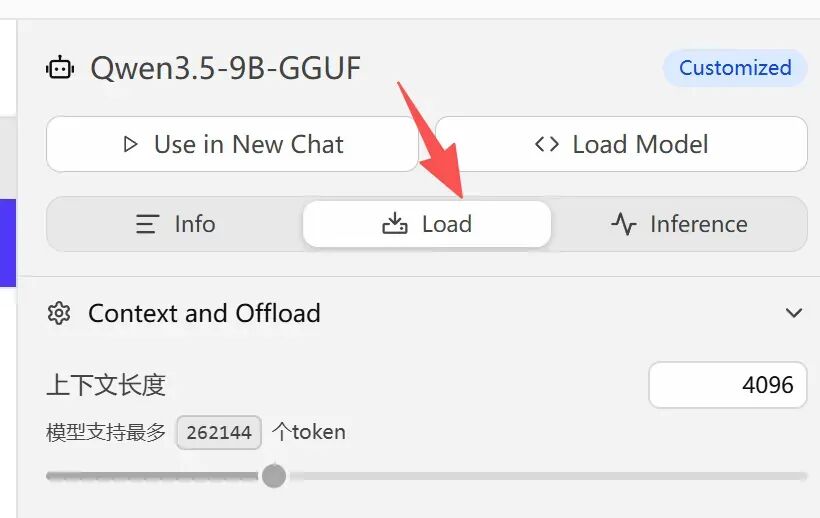
1.上下文长度(Context Length)

参数名称:上下文长度(上下文窗口)。
作用:控制模型一次性能处理+记住的全部内容长度,包括你的问题、历史对话、模型回复,全部都会计入这个上限。
通俗原理:模型以token(词元)为最小单位计算文本长度,不同模型分词规则略有差异,行业通用标准为:1token≈0.5~2个汉字【一个汉字对应的token数量取决于所使用的分词模型或编码方式】,标点、数字、空格同样会占用token。数值越大,模型能记住的对话越长、能读的文档越长,但占用的内存/显存也会同步升高;再加上电脑后台程序占用,小内存设备绝对不能盲目设大。
举例与效果:2048:约对应3000~4000字,仅能做极简短问答,聊多了就会丢失前文;4096:约对应6000~8000字,满足日常多轮聊天、简单文档问答,流畅稳定;8192:约对应1.2~1.6万字,可处理短篇文档、长对话,需要更大内存支撑;16384及以上:适合超长文档分析,仅推荐32GB以上内存设备使用;
保守最佳实践(兼顾后台程序):8GB内存(仅玩玩):2048;16GB内存(推荐起步配置):4096;32GB及以上内存:8192;任何情况都不要超过模型自身支持的最大上下文长度。
重要提醒:小内存设备强行拉高数值,会直接出现内存占满、模型闪退、电脑卡顿;即使内存够大,也不建议无脑拉满,预留一部分空间给系统更安全。
2.GPU卸载层数(n_gpu_layers)

参数名称:GPU卸载层数。
作用:将模型的计算层分配给显卡运行,显卡参与计算越多,模型速度越快,但对显存/共享内存的占用也越高。
通俗原理:大模型由数十层神经网络构成(如Qwen3.5-9B约35层),卸载层数就是交给GPU处理的工作量,剩余部分由CPU完成。GPU并行计算能力远强于CPU,但集显共享系统内存,过高设置反而会挤占内存资源。
举例与效果:0层:完全由CPU运行,速度偏慢,但对显卡无要求,兼容性最稳;10~20层:部分计算交予显卡,适合入门级独显,平衡速度与硬件压力;30层以上:绝大部分计算由显卡承担,运行最流畅,适合中高端独显/苹果M系列。
保守最佳实践(兼顾后台程序):Windows集显(16GB内存):0~5层,不建议设置过高,避免挤占系统内存。苹果M系列芯片(16GB统一内存):可设置20~30层,不建议强行拉满。4GB显存独显:10层以内。6~8GB显存独显:20层左右。8GB以上显存独显:可设置30层左右,不建议长期满负荷运行
重要提醒:小显存/集显设备层数设太高,会触发显存/内存溢出,模型直接启动失败;即使硬件够用,也建议留一点余量,避免开其他软件后突然崩溃。
3.CPU线程(CPU Threads)

参数名称:CPU线程数。
作用:分配给模型推理的CPU线程数量,线程越多计算越快,但会占用系统资源,影响浏览器、办公软件等后台程序运行。
通俗原理:CPU需要同时支撑系统、软件和模型运算,若把线程全部分给模型,电脑会直接卡死,必须为系统和后台预留足够资源。
举例与效果:2~3线程:仅低配设备应急使用,模型速度慢,但不影响基本办公;4~5线程:稳妥通用档位,模型速度够用,后台开软件也不会卡顿;6~8线程:高性能CPU专用,适合专注跑模型、少开后台的场景
保守最佳实践(兼顾后台程序)统一原则:仅使用CPU总核心数的40%~60%,大幅预留资源给系统和后台软件:4核CPU:2线程;6核CPU:3线程;8核CPU:4线程;12核及以上CPU:6线程。
重要提醒:线程拉满会导致CPU占用100%,打开网页、编辑文档都会严重卡顿,模型也可能因资源抢占中断运行。
4.评估批处理大小(Evaluation Batch Size)

参数名称:评估批处理大小。
作用:控制模型每一步并行处理的token数量,数值越大理论速度越快,但对内存/显存压力更大,尤其集显设备会直接占用系统内存。
通俗原理:批量处理是提升效率的方式,但在日常开着后台软件的场景下,过大的批处理会快速耗尽硬件资源,反而更不稳定。
举例与效果:128~256:低配/集显稳妥值,完全不挑硬件,稳定不报错;512:通用舒适值,速度够用,硬件压力可控;1024:仅高端大内存设备使用,普通设备设置极易崩溃
保守最佳实践(兼顾后台程序):集显/16GB内存设备:256;苹果16GB统一内存/中端独显:512;32GB以上内存+高端独显:1024。
重要提醒:批处理大小并非越大越好,日常使用场景下,稳定远比极限速度重要,低配设备设高会直接闪退。
二、推理生成参数
这部分只影响回答质量、风格、逻辑性,和硬件关联较小,所有设备通用,设置偏向自然、稳定、不犯错。
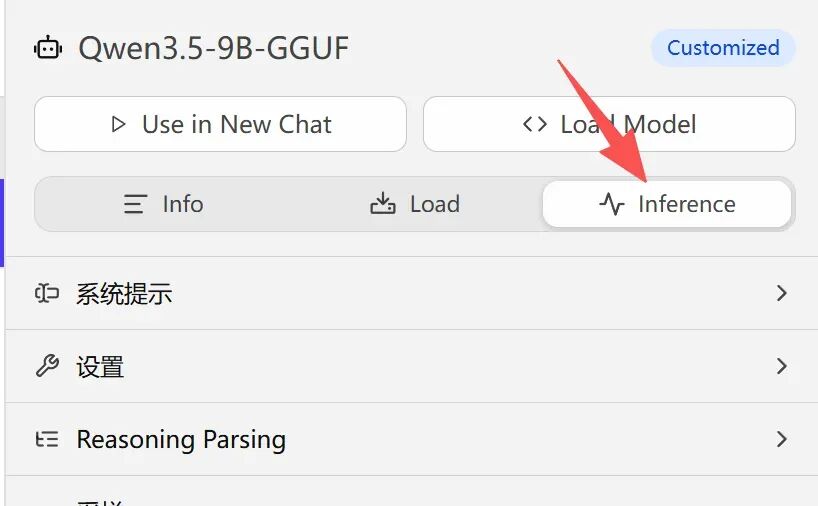
1.系统提示(System Prompt)
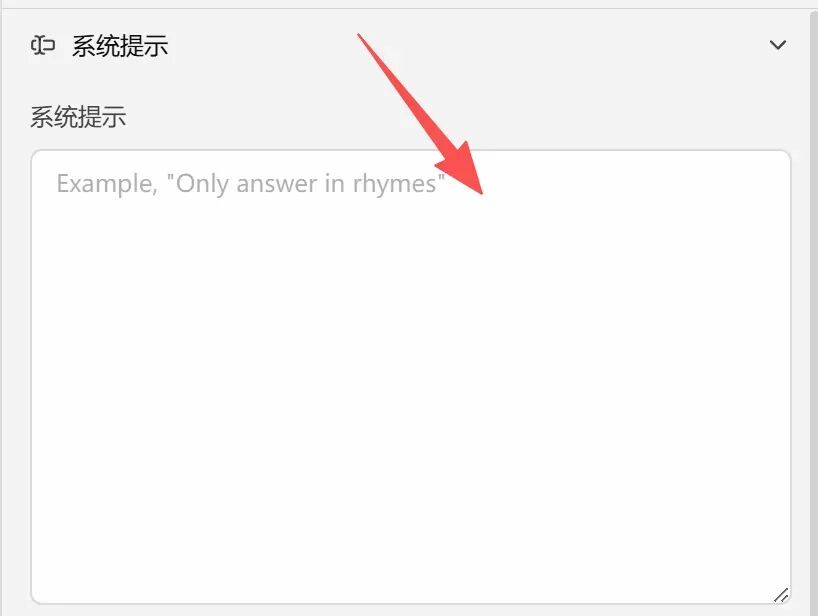
参数名称:系统提示。
作用:给模型设定身份、规则、回答风格,相当于给AI定下行为准则,指令越清晰,回答越贴合需求。
通俗原理:系统提示是模型的最高优先级指令,会贯穿整个对话,同时系统提示本身也会占用上下文token,简洁清晰的提示能节省更多对话空间。
举例与效果:1.日常聊天:你是友好简洁的AI助手,用口语化中文回答,不使用专业术语,表达简洁;2.代码生成:你是专业程序员,只输出可直接运行的代码,不添加多余解释,保证语法正确;3.文案创作:你是文案创作者,语言生动自然,符合日常阅读习惯,不生硬不浮夸。
最佳实践:提示词尽量简洁明确,包含角色、风格、要求即可,不用写过长内容,避免占用过多上下文token。
2.温度(Temperature)

参数名称:温度。
作用:控制回答的随机性与严谨性,是最核心的生成参数。
通俗原理:数值越低,模型越倾向选择概率最高的内容,回答越准确、稳定;数值越高,模型选择越发散,创意越强,但出错概率也会上升。
举例与效果:0.1~0.3:高度严谨,适合代码、数学、事实问答,几乎不会出现错误;0.6~0.8:平衡通用,日常聊天、科普问答最合适,自然又准确;1.0~1.2:创意增强,适合文案、小故事,集显设备不建议再高
保守最佳实践:工作学习、知识查询:0.2~0.5;日常聊天对话:0.7~0.8;创意写作:1.0~1.2。
重要提醒:温度超过1.5后,逻辑混乱、胡说的概率大幅上升;代码、数学类场景严禁使用高温度。
3.上下文溢出策略

参数名称:上下文溢出策略。
作用:当对话总token超过设置的上限时,模型自动删减内容,防止崩溃。
通俗原理:对话过长必然超出上下文限制,不同删减方式会影响对话连贯性,小内存设备更需要稳妥的策略。
举例与效果:截断中间:删除中间无关对话,保留系统提示和最新内容,连贯性最好;丢弃开头:删除最早的对话,容易丢失前期设定;报错停止:直接报错,不适合日常使用。
最佳实践:所有设备、所有场景,统一选择截断中间,这是兼顾稳定性和对话体验的最优方案。
4.Top K采样

参数名称:Top K采样。
作用:限制模型每次选词的候选范围,K越小越稳定,K越大越多样。
通俗原理:模型只从概率最高的K个词里选择,范围越小越不容易跑题,范围越大创意越强。
举例与效果:20~30:高度稳定,适合专业、事实类内容;40:通用默认值,流畅自然,不跑偏不重复;60:创意更强,适合写作、头脑风暴。
最佳实践:通用场景固定40,事实类场景30,创意类场景60,不建议设置过高。
5.Top P采样

参数名称:TopP采样(核采样)。
作用:与TopK配合使用,按概率总和筛选词汇,进一步控制回答的多样性。
通俗原理:只保留概率总和达到P的词汇,P越小越聚焦,P越大越开放。
举例与效果:0.8~0.9:高度聚焦,适合专业问答;0.95:通用最优值,流畅稳定;0.97~0.98:开放多样,适合创意场景。
最佳实践:通用固定0.95,与TopK=40搭配,是适配绝大多数场景的黄金组合。
6.重复惩罚(Repetition Penalty)

参数名称:重复惩罚。
作用:避免模型反复说同样的话、段落复读、语句啰嗦。
通俗原理:数值大于1会抑制重复词汇,数值越高抑制越强,但过高会导致语句生硬不通顺。
举例与效果:1.0:无惩罚,极易出现重复啰嗦;1.1~1.2:温和去重,语句通顺自然;1.3:强力去重,适合长文本写作。
最佳实践:所有日常场景统一1.1~1.2,长文本可设1.2~1.3,绝对不超过1.5。
7.最小P采样(Min P)

参数名称:最小P采样。
作用:过滤概率极低、不通顺的奇怪词汇,保证回答流畅可读。
通俗原理:设置概率阈值,丢掉低质量无效词汇,提升回答的可读性。
举例与效果:0.03:宽松过滤,适合创意写作;0.05:标准过滤,通用最优;0.1:严格过滤,适合正式文档。
最佳实践:默认开启,固定0.05,所有场景通用,无需修改。
三、小白稳妥避坑总结
1、硬件底线优先:本地跑大模型建议16GB内存起步。
2、上下文长度保守设置:16GB内存用4096最稳妥,不盲目拉高。
3、Windows集显GPU层数设0~5层即可,苹果M系列也不要强行拉满。
4、CPU线程只给40%~60%,必须预留资源给系统和后台软件。
5、温度按场景设置,工作低、聊天中、创意不超高,避免逻辑混乱。
6、重复惩罚不超过1.5,否则语句破碎无法阅读。
7、万能采样组合:TopK=40 + TopP=0.95 + MinP=0.05。
8、上下文溢出策略永远选「截断中间」,稳妥不丢关键信息。
按照以上保守稳妥的参数设置,无论是集显轻薄本、苹果电脑还是独立显卡设备,都能在正常使用电脑的前提下,稳定流畅地运行本地大模型。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献136条内容
已为社区贡献136条内容

所有评论(0)