从提示词到驾驭工程:一文读懂 AI Agent 完整架构与 LLM 可控化进阶之路
前言
大模型(LLM)本身只是一个根据上文预测下一个 token 概率的基础模型,天生具有发散、不可控、无目标性的特点。单纯把大模型包装成聊天界面、API 接口,只能实现被动对话;而AI Agent,才是让大模型变成自主、稳定、可控、能完成复杂长任务智能体的完整解决方案。
本文将结合完整分层架构,从提示词工程→上下文工程→驾驭工程,一步步拆解 AI Agent 的底层逻辑、核心能力与进阶设计,彻底讲明白:我们到底要如何「驾驭」强大但不可控的大模型。
一、AI Agent 五层标准架构:大模型不是 Agent 的全部
很多人误以为 AI Agent = 大模型,这是完全错误的认知。大模型只是 Agent 的大脑核心,完整的 AI Agent 是一套五层协同的工程化体系:
表格
| 层级 | 核心定位 | 作用 |
|---|---|---|
| 编排层 | 任务总指挥 | 拆解复杂目标、规划执行步骤、调度各个模块 |
| 大模型(LLM) | 智能大脑 | 推理、思考、决策、语言理解与生成 |
| 记忆层 | 长期记忆库 | 存储历史对话、项目知识、历史状态、经验数据 |
| 执行层 | 行动手脚 | 调用工具、读写数据库、执行代码、外部交互 |
| 反馈层 | 纠错闭环 | 收集执行结果、评估效果、反向优化后续决策 |
大模型本身没有记忆、没有规划、不会主动执行、无法自我纠错。记忆层、编排层、执行层、反馈层,都是为了约束、增强、驱动大模型工作;而这套给大模型「套上缰绳、定向引导」的完整工程体系,就是本文核心 ——Harness Engineering(驾驭工程)。
AI Agent = 基础大模型 + 驾驭工程(提示词工程 + 上下文工程 + 记忆层)驾驭工程,就是把一个天生发散、不可控的强大模型,变成稳定、安全、可控、朝着用户目标前进的智能体的全部方法论。
二、第一层:提示词工程(Prompt Engineering)—— 规范模型「说话方式」
1. 大模型天生的问题
大模型的本质:根据当前输入,预测下一个字词的最大概率结果。如果输入宽泛、无约束,模型输出就会极度发散、答非所问、自由发挥;我们需要主动设计输入,引导模型按照我们预期的逻辑、格式、范围回答。
有意识地设计、优化提示词,引导模型定向输出的全部手段,就是提示词工程。
2. 提示词工程核心优化方法
- 内容具体化:明确角色、背景、任务边界,拒绝模糊提问
- 强制推理链路:结尾添加
think step by step,让模型先分步思考、再给出答案,大幅提升逻辑推理能力 - 固定输出格式:强制约束返回结构,杜绝冗余废话
- 清晰行为约束:明确告诉模型能做什么、不能做什么
3. 优质提示词标准模板(可直接复用)
plaintext
你是资深Python后端工程师。
背景:我需要优化一段现有数据处理代码。
历史上下文:我之前提到过XXX业务逻辑。
参考依据:严格遵循Python3官方语法文档。
约束规则:不改动原有代码核心逻辑,仅新增排序功能。
输出要求:直接返回完整可运行函数代码,禁止多余解释、说明文字。
请一步步思考后给出最终代码。
提示词工程解决的核心问题:大模型无引导乱说话、逻辑混乱、输出不可控。
三、第二层:上下文工程(Context Engineering)—— 给模型提供完整信息
1. 提示词工程的瓶颈:上下文窗口限制
提示词工程只优化了「说话方式」,但解决不了信息总量问题:再好的提示词,也塞不下海量项目文档、历史对话、业务知识;同时大模型有上下文窗口长度限制,输入信息越多,模型回答越准确,但窗口超限就会截断、遗忘、错乱。
在有限上下文窗口内,高效传递精准、必要、完整信息的工程方法,就是上下文工程。
提示词只是上下文的其中一部分,上下文工程包含提示词,但远大于提示词。
2. 上下文工程核心实现方案
- 静态手写上下文:固定业务规则、角色定义、行业规范
- RAG 检索增强:动态从知识库、数据库查询相关知识,实时注入上下文
- 工具调用结果回填:执行层工具返回的数据,自动补充到上下文
- 对话历史压缩:精简历史对话,在窗口限制内保留核心信息
- 规则文件化管理:把约束、规则、角色写入仓库固定文件(如 Claude Code 的
CLAUDE.md、Cursor 的rule.md),系统调用大模型时自动注入上下文;长规则可拆分、路由管理,避免窗口溢出。
上下文工程解决的核心问题:模型信息不足、知识匮乏、回答不准确。
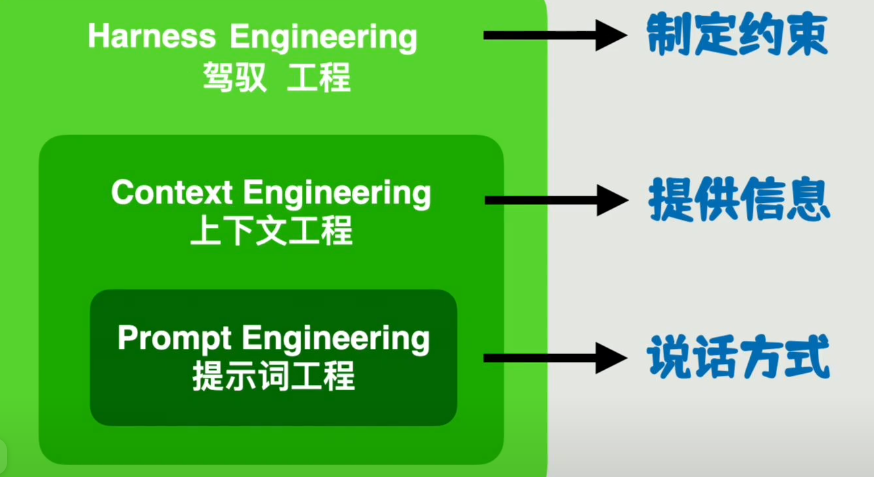
四、第三层:驾驭工程(Harness Engineering)—— 给模型制定约束、守住边界
提示词工程管「怎么说话」,上下文工程管「给什么信息」,而驾驭工程管「模型可以做什么、不能做什么、朝着什么目标走」,是整个 Agent 可控化的顶层设计。
表格
| 工程类型 | 英文 | 核心作用 |
|---|---|---|
| 提示词工程 | Prompt Engineering | 规范模型说话方式 |
| 上下文工程 | Context Engineering | 给模型提供完整信息 |
| 驾驭工程 | Harness Engineering | 制定全局约束、权限、目标边界 |
驾驭工程核心能力
- 权限收敛:严格限制模型可调用工具、可访问数据、可执行操作,防止越权、幻觉、有害输出
- 颗粒度对齐:统一模型理解、业务需求、执行结果的标准,避免理解偏差
- 行为规范制定:全局定义 Agent 工作流程、决策逻辑、纠错规则
- 长任务稳定性保障:跨 Agent 同步交接方案长任务场景下,上下文持续膨胀极易导致 Agent 失忆、连贯性断裂。驾驭工程采用不压缩上下文、重启全新 Agent 实例的方案:传递前一个 Agent 的完整状态、总结、进度,新 Agent 直接继承上下文成果,无需重新阅读全量文档。举例:让 Agent 读完整个项目源码文档,下次启动新 Agent 时,无需重新读取源码,只需读取项目总结文档;项目源码更新时,同步更新总结文档即可,完美解决长任务失忆问题。
驾驭工程的终极目标:让一个强大、不可控、天生发散的大模型,朝着用户预期的方向,安全、稳定、可靠、持续地完成目标。
五、深度思考:大模型越强,驾驭工程越重要?
很多人有误区:模型能力越来越强、知识越来越丰富,Agent 层、驾驭工程是不是就可以少做甚至不做了?
答案恰恰相反:
- 基础大模型会把公开知识内化为常识,Agent 的记忆、检索工作确实可以适当简化;
- 但模型越强,发散性、不可控性、幻觉风险、越权风险就越高,驾驭、约束、引导模型的驾驭工程,只会越来越重要。
LLM 永远只是一个预测下一个 token 的基础模型,它永远不会天生拥有「目标感、安全性、稳定性、任务规划能力」。这些能力,全部来自 Agent 架构,来自提示词、上下文、驾驭三层工程化设计。
六、总结:重新理解 LLM 与 AI Agent
LLM 本质:磁盘上的超大参数文件,加载到显存 + HTTP 接口 = 大模型 API;加聊天界面 = 聊天 AI;加代码编辑器 = AI IDE;加完整驾驭工程 + 五层架构 = AI Agent。
我们用一张图总结完整进阶路径:
- 提示词工程:优化模型说话方式,解决乱回答问题
- 上下文工程:补充模型信息知识,解决回答不准问题
- 驾驭工程:制定模型行为约束,解决不可控问题
- 五层 Agent 架构:让大模型拥有记忆、规划、执行、反馈能力,变成真正自主工作的智能体
驾驭工程,是 AI Agent 时代最核心、最底层的能力,也是未来大模型落地商业化、企业化、安全化的核心基石。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)