大模型是人工智能发展历程中的重要里程碑
1、 大模型是人工智能发展历程中的重要里程碑
人工智能(AI)是一门使机器模拟人类智能过程的学科,其中具体包括学习、推理、自我修正、感知和处理语言等功能。人工智能涉及计算机科学、数学、心理学等众多领域的知识,通过创建能够实现智能行为的算法或软件系统,来表现出与人类的智能行为相似的特性。
2 、大模型是什么?
大模型是指参数量庞大(通常超过十亿级别)的预训练深度学习模型。这类模型通过在广泛数据集上进行训练,具备强大的泛化能力,能够灵活适应多种任务和应用场景。
2.1 大模型主要有以下四个特点:
|
[1]规模和参数量大 大模型通过其庞大的规模(拥有从数亿到数千亿级别的参数数量)来捕获复杂的数据模式,使得它们能够理解和生成极其丰富的信息。 |
[2]适应性和灵活性强 模型具有很强的适应性和灵活性,能够通过微调(fine-tune)或少样本学习高效地迁移到各种下游任务,有很强的跨域能力。 |
|
[ 3]广泛数据集的预训练 大模型使用大量多样化的数据进行预训练,以学习广泛的知识表示,能够掌握语言、图像等数据的通用特征。 |
[4]计算资源需求大 巨大的模型规模带来了高昂的计算和资源需求,包括但不限于数据存储、训练时间、能量消耗和硬件设施。 |
2.2 大模型的训练
大模型的训练流程主要包含三个关键阶段:预训练、监督微调(SFT)以及基于人类反馈的强化学习(RLHF)。
A. 预训练阶段 预训练类似于人类从婴儿到中学生的成长过程,是构建基础认知能力的关键时期。在这个阶段:
- 人类会形成语言习惯和知识体系的基本框架
- 大模型通过海量语料学习语言的统计规律和通用知识
- 模型仅掌握文本补全能力,尚不具备理解人类意图的能力
例如,当询问预训练模型"埃菲尔铁塔在哪个国家?",它可能不会直接回答"法国",而是根据语料统计输出类似"东方明珠在哪个城市?"这样的补全句式。这表明模型需要进一步训练才能准确响应人类指令。
B. 监督微调阶段(SFT) SFT阶段类比于从中学生到大学生的专业培养过程:
- 人类开始专注于特定领域的专业知识学习
- 模型通过专业对话语料训练,掌握垂直领域知识
- 获得理解并响应人类意图的能力
经过SFT后,模型能准确回答"埃菲尔铁塔在法国"这类问题。虽然具备了基础对话能力,但输出内容可能存在不符合社会伦理的风险,如涉及敏感话题等,因此需要进一步优化。
C. 基于人类反馈的强化学习(RLHF) RLHF阶段类似于职场新人通过反馈提升工作表现的过程:
- 人类根据职场反馈调整工作方式
- 模型通过人类对多个回答的打分学习优化输出
- 最终形成符合人类偏好的应答模式
这一阶段使模型能够输出更安全、更有价值的回答,显著提升对话质量。
3、大模型是如何工作的
大模型的工作流程可以分为两部分,第一部分是分词化与词表映射,第二部分为生成文本。
3.1 分词化(Tokenization)与词表映射
分词化(Tokenization)是自然语言处理(NLP)中的重要概念,它是将段落和句子分割成更小的分词(token)的过程。举一个实际的例子,以下是一个英文句子:
I want to study ACA.
为了让机器理解这个句子,对字符串执行分词化,将其分解为独立的单元。使用分词化,我们会得到这样的结果:
['I' ,'want' ,'to' ,'study' ,'ACA' ,'.']
将一个句子分解成更小的、独立的部分可以帮助计算机理解句子的各个部分,以及它们在上下文中的作用,这对于进行大量上下文的分析尤其重要。分词化有不同的粒度分类:
-
词粒度(Word-Level Tokenization)分词化,如上文中例子所示,适用于大多数西方语言,如英语。
-
字符粒度(Character-Level)分词化是中文最直接的分词方法,它是以单个汉字为单位进行分词化。
-
子词粒度(Subword-Level)分词化,它将单词分解成更小的单位,比如词根、词缀等。这种方法对于处理新词(比如专有名词、网络用语等)特别有效,因为即使是新词,它的组成部分(子词)很可能已经存在于词表中了。
每一个token都会通过预先设置好的词表,映射为一个 token id,这是token 的“身份证”,一句话最终会被表示为一个元素为token id的列表,供计算机进行下一步处理。
3.2 大语言模型生成文本的过程
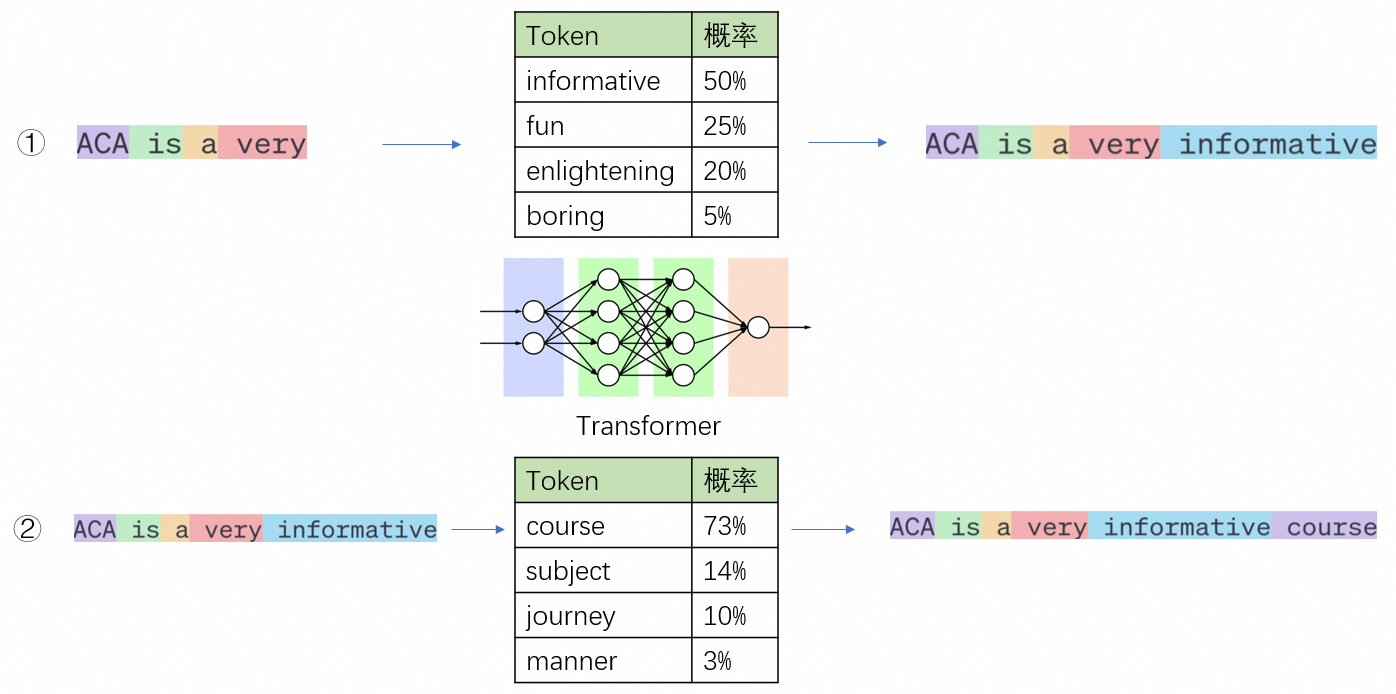
大语言模型的工作概括来说是根据给定的文本预测下一个token。对我们来说,看似像在对大模型提问,但实际上是给了大模型一串提示文本,让它可以对后续的文本进行推理。
大模型的推理过程不是一步到位的,当大模型进行推理时,它会基于现有的token,根据概率最大原则预测出下一个最有可能的token,然后将该预测的token加入到输入序列中,并将更新后的输入序列继续输入大模型预测下一个token,这个过程叫做自回归。直到输出特殊token(如<EOS>,end of sentence,专门用来控制推理何时结束)或输出长度达到阈值。
使用大模型并不复杂,但是用好大模型却有很多值得学习的技巧和技术。大模型的应用范畴实际上非常广泛。它们可以用于内容生成、机器翻译、情感分析、数据摘要、智能客服等领域。通过引入大模型技术,不仅能够提升现有系统的智能化水平,还能在医疗、金融、教育等垂直领域开辟出新的应用场景。
如果你想要扩展Al相关的知识储备,可以深入学习有关大模型的底层原理,例如深度学习、神经网络等技术。同时,可以参考最新的技术文献和研究成果,掌握前沿发展动态。结合实践案例,探索如何高效地训练和部署大模型,将理论与实战结合,从而更全面地理解和利用大模型技术。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)