视频/图片分类器——基于Google Teachable Machine
目标:构建一个能够分辨第一人称人类视角的分类器
第一阶段:制作“动作样板间”
首先,我们要告诉电脑:什么样的图才是我们想要的“第一人称视角(FPV)”。
-
找图: 获取50-100 张 典型的第一人称图片。 画面里一定要有操作者的双手(或单手),且手在画面中心或下方。
-
分类: 新建两个文件夹:
-
Positive_FPV(Positive):放第一人称视角的图。
-
Negative_Normal(Negative):放普通的第三人称视频截图(比如新闻、电影、自拍、风景)。
-
-
这就是“训练集”: 它相当于教科书,告诉 AI 什么是对的,什么是错的。
第二阶段:训练一个“AI 筛选器”
我们可以利用谷歌的工具快速训练一个 AI 模型。
-
打开工具: 访问 Google Teachable Machine。

-
选择项目: 点击 Image Project -> Standard Image Model。
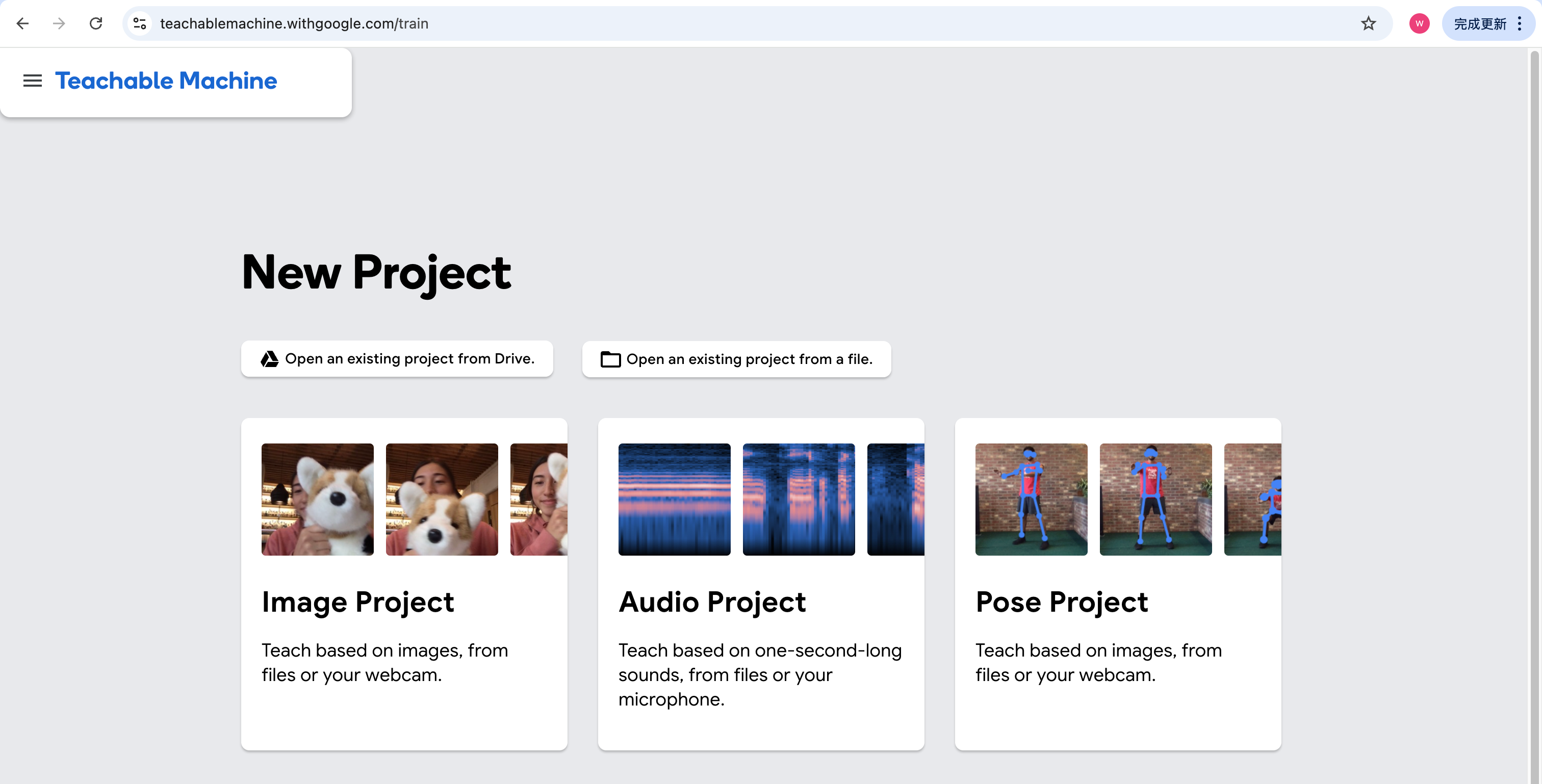
-
上传图片:
-
把 Positive_FPV 的图拖进第一个 Class(改名为 "FPV")。
-
把 Negative_Normal 的图拖进第二个 Class(改名为 "Normal")。(ps:我忘记改了)
-
-
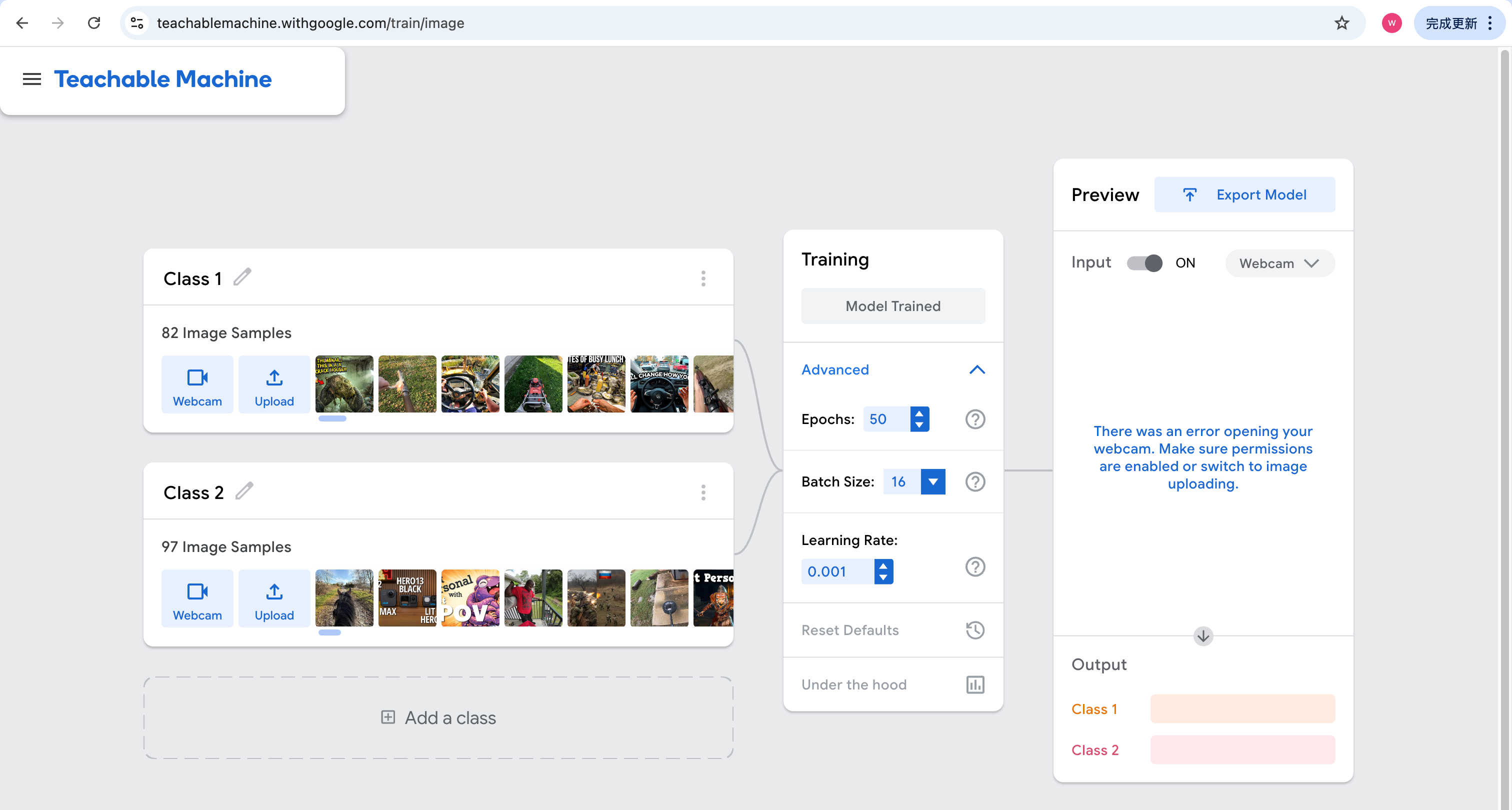
训练: 点击 Train Model。它会在浏览器里自动运行,大约几分钟就好。
-
导出: 训练完后,点击 Export Model。
-
我选择的是 Tensorflow.js 格式下载。
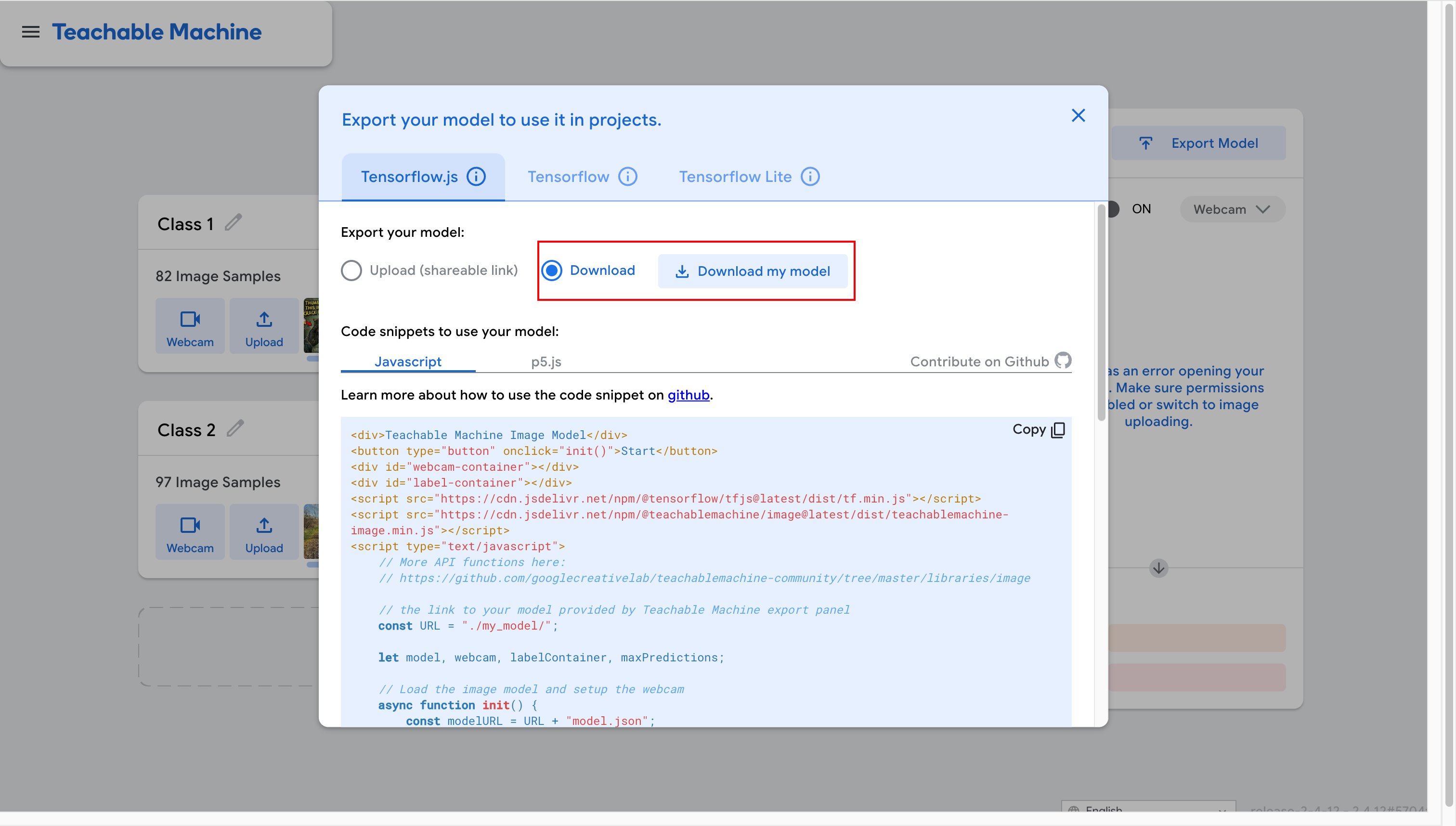
从 Teachable Machine 导出模型时,如果选择了 "Download",会得到一个 .zip 压缩包。解压它,看到三个文件:
-
model.json
-
metadata.json
-
weights.bin
在电脑上新建一个文件夹(比如叫 my_project),把这三个文件放进去,再新建一个子文件夹叫 my_model 专门放它们。
文件夹结构应该是这样的:
my_project/
├── index.html (把下图中的代码存成这个文件)
└── my_model/
├── model.json
├── metadata.json
└── weights.bin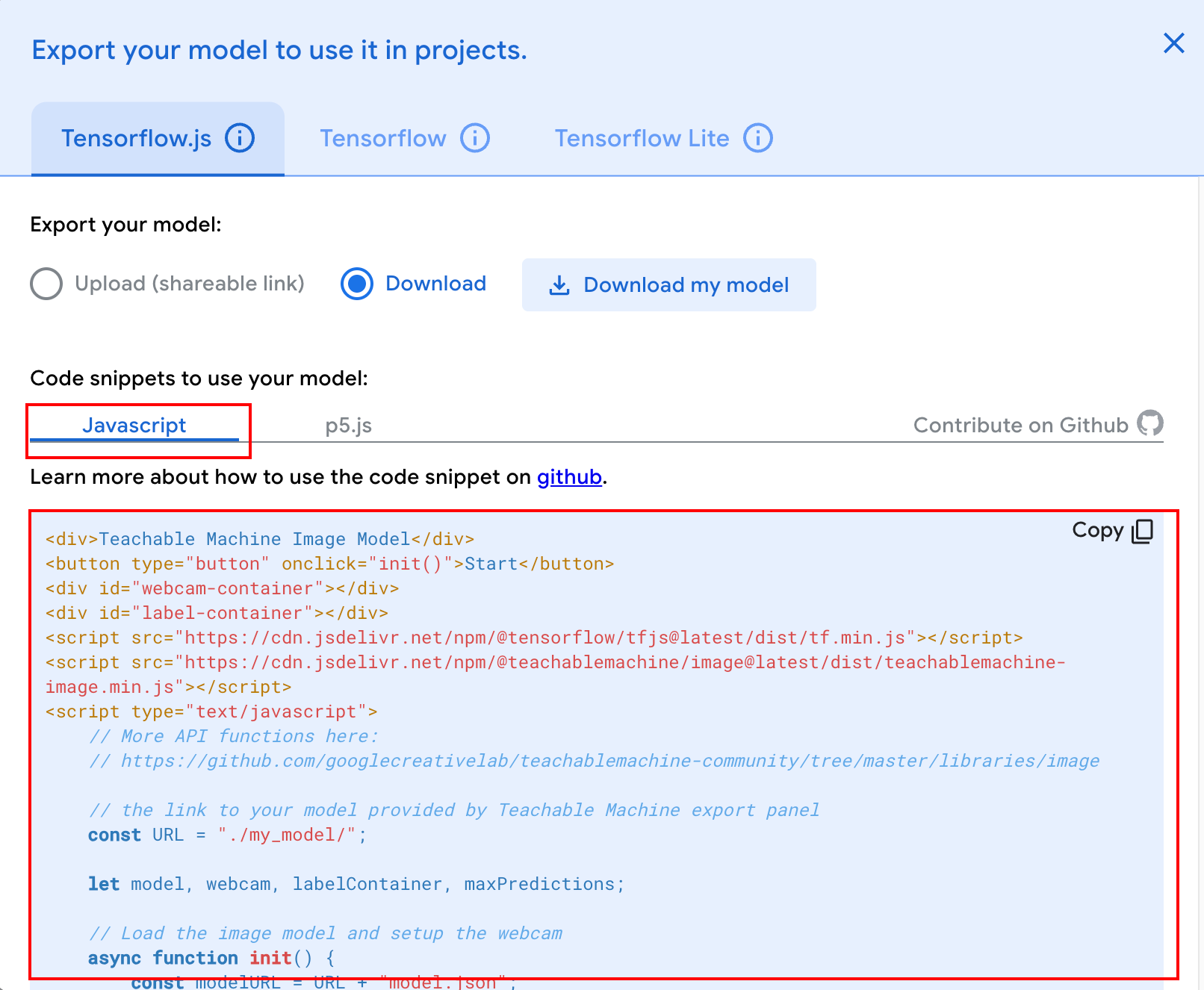
接着,启动“本地服务器”
注意: 你不能直接双击 index.html 打开。如果你直接双击,浏览器会因为安全原因(CORS 跨域限制)禁止读取本地的模型文件。
你需要运行一个简单的本地服务器。以下是几种最简单的方法:
方法 A:使用 VS Code (最推荐)
-
如果你用 VS Code 编辑代码,安装插件 "Live Server"。
-
打开 index.html,点击右下角的 "Go Live"。
-
浏览器会自动打开,这时模型就能正常加载了。
方法 B:使用 Python (如果你装了 Python)
-
在 my_project 文件夹里打开终端(Terminal/CMD)。
-
输入命令:python3 -msg http.server 8000。
-
在浏览器访问:http://localhost:8000。(此处注意将网址填写到地址栏,刷新或者回车,不要直接双击html文件访问)
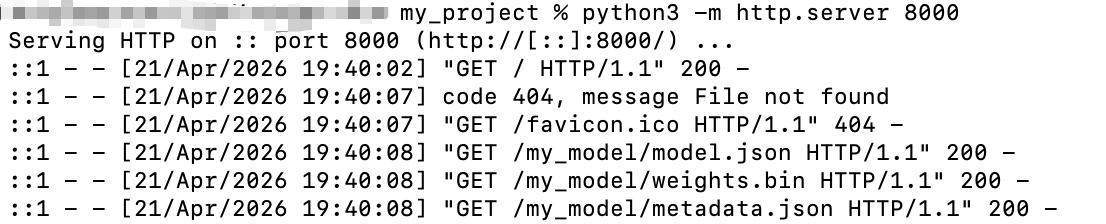
我使用的是macbook,如下所示访问成功:
然后就可以上传图片或者视频进行分类了: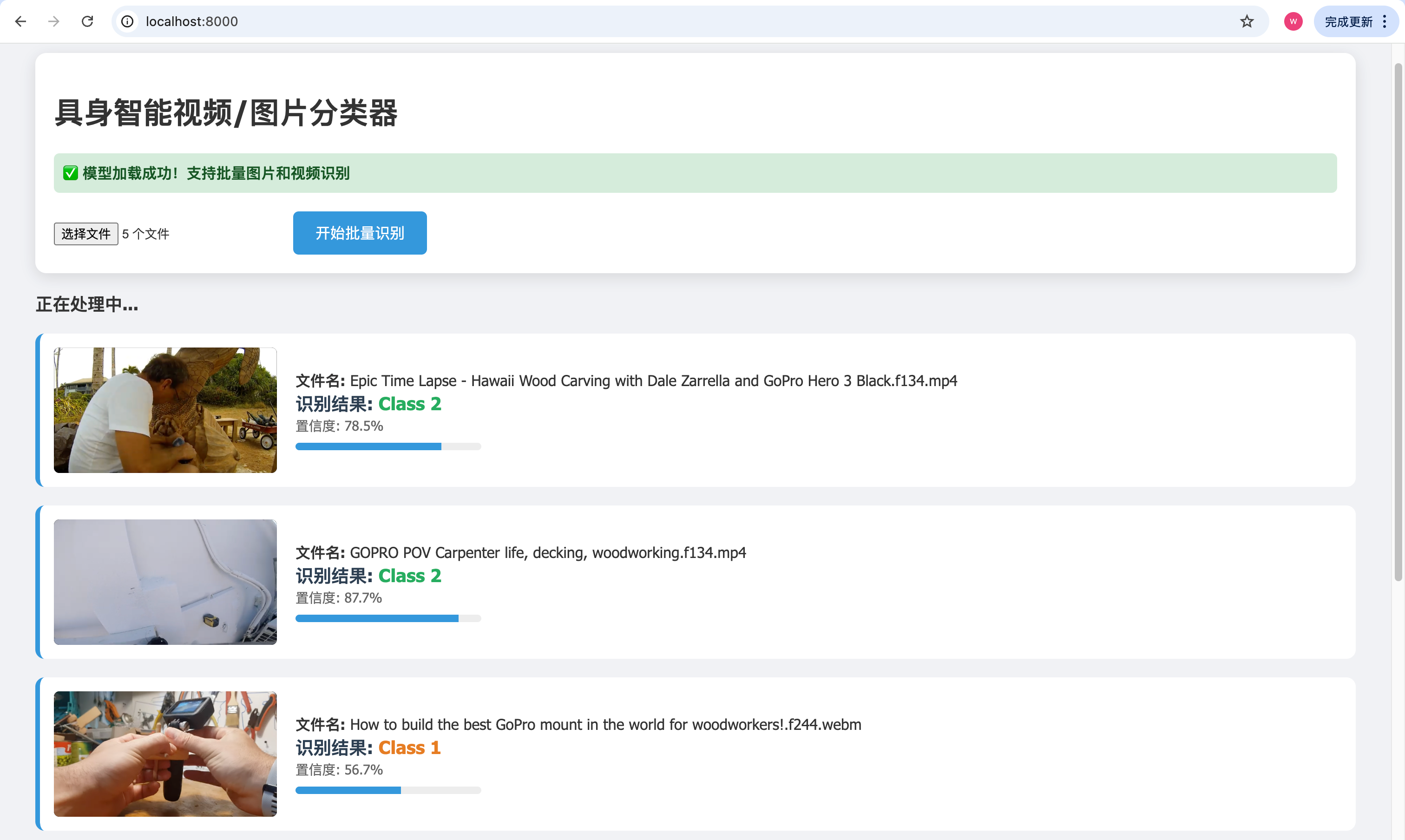
可以看出分类效果不是很好,这是因为我只是简单探索,使用的训练数据较少(80个正样本)且质量不是很高。使用更多质量高的数据,即可以得到高质量分类器。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)