Snap7的基本使用
1.下载与安装
Snap7 是一个开源的、跨平台的通信库,专门用于与西门子 S7 系列 PLC(可编程逻辑控制器)进行以太网通信。
官网:https://snap7.sourceforge.net/
选择下载:
下载此版本:
解压后的文件:
进入rich-demos:
选择对应版本,这里选择64位的windows
进入bin目录:
这里有4个文件
serverdemo.exe
-
- 功能:这是一个PLC 模拟器,扮演着“服务器”的角色。启动它之后,电脑就会模拟成一台真实的西门子 PLC。其他程序(比如你写的 Java 代码或
clientdemo.exe)就可以像连接真实 PLC 一样连接到它,进行读写数据操作。这是在没有硬件时进行软件开发和调试的关键工具。
- 功能:这是一个PLC 模拟器,扮演着“服务器”的角色。启动它之后,电脑就会模拟成一台真实的西门子 PLC。其他程序(比如你写的 Java 代码或
clientdemo.exe
-
- 功能:这是一个通信测试客户端,扮演着“客户端”的角色。可以用它来连接
serverdemo.exe模拟的 PLC,或者连接网络中真实的 PLC。它提供了一个图形界面,可以方便地测试读写数据块(DB)、输入(I)、输出(Q)、位存储区(M)等功能,验证通信是否正常。
- 功能:这是一个通信测试客户端,扮演着“客户端”的角色。可以用它来连接
snap7.dll
-
- 功能:这是 Snap7 库的核心动态链接库。它是所有通信功能的实际执行者。无论是
serverdemo.exe、clientdemo.exe,还是你用 Java、C#、Python 等语言编写的程序,最终都是通过调用这个.dll文件里的函数来实现与 PLC 的数据交换。
- 功能:这是 Snap7 库的核心动态链接库。它是所有通信功能的实际执行者。无论是
PartnerDemo.exe
-
- 功能:这是一个用于演示 Snap7 Partner 功能的程序。Partner 是一种更高级的通信模式,允许两个设备之间进行对等通信。
这里我需要使用java程序和服务端进行通信,所以只需要启动服务端。
双击启动:
查看数据块:
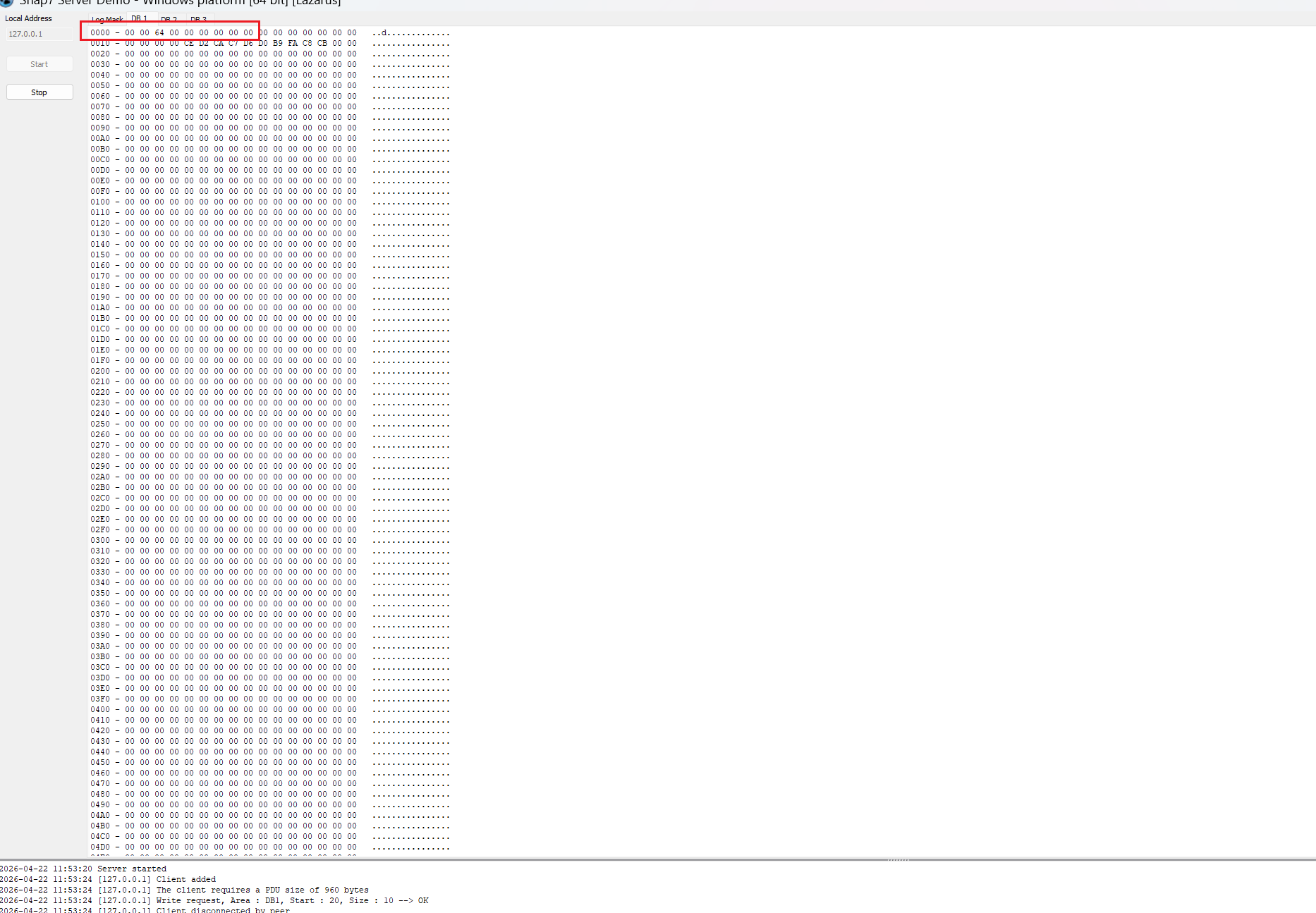
DB 1 的数据视图,左侧的 0000、0010 等代表字节偏移量,右侧的 00 代表当前存储的十六进制数据。最右边的.....是ASCII码。

数据块里的数据全部为0,不支持手动修改,只能在程序里写入修改。
2.基本使用
2.1.s7connector工具类
s7connector 是一个专门为 Java 开发者设计的开源库,它的核心作用是让你的 Java 程序能够直接与西门子 S7 系列 PLC 进行通信。
你可以把它理解成一个“翻译官”或“桥梁”,它屏蔽了底层复杂的工业通信协议(S7 协议),无需关心繁琐的字节流和握手过程,只需调用简单的 Java 方法,就能轻松实现对 PLC 数据的读写。
核心作用与优势
- 简化开发:它封装了所有底层协议细节,如连接建立、数据打包/解包、错误处理等。你只需要关注业务逻辑,比如“从 DB1 的第 20 个字节读取 10 个字节的数据”,而不用去研究 S7 协议的具体报文格式。
- 跨平台与免授权:与西门子官方的解决方案(如 SIMATIC NET 或 OPC UA Server)不同,
s7connector是一个纯 Java 库。这意味着你的程序可以在 Windows、Linux 等任何支持 Java 的系统上运行,并且完全免费,无需购买昂贵的软件授权。 - 底层通信基础:它底层依赖于我们之前讨论的 Snap7 库(通过 Java Native Interface 调用
snap7.dll或其他平台的库文件)来实现真正的网络通信。s7connector在此基础上,为 Java 开发者提供了更友好、更面向对象的 API。
主要功能
通过 s7connector,你的 Java 程序可以实现以下功能:
- 建立连接:通过 IP 地址、机架号和插槽号连接到 S7-200/300/400/1200/1500 等全系列 PLC。
- 读取数据:从 PLC 的指定区域(如数据块 DB、输入 I、输出 Q、位存储区 M)读取原始字节数据。
- 写入数据:向 PLC 的指定区域写入字节数据,从而控制设备或修改参数。
- 数据转换:提供工具类,方便地将读取到的原始字节转换成 Java 中的基本数据类型(如 int, float, boolean)或字符串。
总而言之,s7connector 让你能够用熟悉的 Java 语言,以最少的代码量,快速开发出稳定可靠的工业数据采集和控制应用。
引入依赖:
<dependency>
<groupId>com.github.s7connector</groupId>
<artifactId>s7connector</artifactId>
<version>2.1</version>
</dependency>2.2.建立连接
/**
* 初始化PLC连接
*/
public static S7Connector initConnect(){
//PLC地址
String ipAddress = "127.0.0.1";
//默认端口
int port = 102;
S7Connector s7Connector = S7ConnectorFactory
.buildTCPConnector()
.withHost(ipAddress)
.withPort(port)
.withTimeout(10000) //连接超时时间
.withRack(0)
.withSlot(1)
.build();
return s7Connector;
}withRack(0) 和 .withSlot(1):
- 这是西门子 PLC 寻址的关键参数,代表 CPU 在机架上的物理位置。
- Rack 0, Slot 1: 这是 S7-1200 / S7-1500 系列 PLC 的典型配置。
- 如果是 S7-300/400,Slot 通常可能是 2 或 3,具体取决于硬件组态。
首先启动服务端:

下面有启动的日志。
测试代码:
S7Connector s7Connector = S7ConnectorUtil.initConnect();
System.err.println(s7Connector);
服务端日志区域:

日志逐行解析
2026-04-22 10:44:41 Server started
-
- 含义:服务端(Snap7 Server)已启动。
- 状态:服务端正在监听端口(默认 102),等待客户端连接。
2026-04-22 10:45:27 [127.0.0.1] Client added
-
- 含义:检测到一个来自
127.0.0.1(本机)的客户端连接请求,并已接受。 - 对应代码:这正是你的 Java 代码执行到
.build()时,底层 Snap7 库向服务端发起 TCP 连接的时刻。
- 含义:检测到一个来自
2026-04-22 10:45:27 [127.0.0.1] The client requires a PDU size of 960 bytes
-
- 含义:客户端(你的 Java 程序)告诉服务端:“我最大能接收 960 字节 的数据包(PDU)。”
- 解释:PDU 是通信中单次传输的最大数据单元。S7 协议在连接建立时会协商这个大小。960 是 S7-1200/1500 常见的默认值。这说明握手协议正在正常进行。
2026-04-22 10:45:28 [127.0.0.1] Client disconnected by peer
-
- 含义:客户端(你的 Java 程序)主动断开了连接。
- 关键点:
by peer意味着是对方(你的 Java 代码) 挂断了电话,而不是服务端踢掉的。
2.3.写入数据
格式:
// 方法签名大致如下:
s7Connector.write(Area, DBNumber, StartByte, data);DaveArea.DB—— 存储区域
-
- 含义:指定要写入 PLC 的哪个内存区域。
- 常用选项:
-
-
DaveArea.DB:数据块(最常用)。DaveArea.MK:位存储区。DaveArea.PE:输入区。DaveArea.PA:输出区。DaveArea.TM:定时器。DaveArea.CT:计数器。
-
1—— DB 块编号
-
- 含义:如果第一个参数选了
DaveArea.DB,这里填的就是 DB 块的号码。这里填1代表 DB1。
- 含义:如果第一个参数选了
20—— 起始字节
-
- 含义:从该数据块的第几个字节开始写入。
data—— 数据内容
-
- 含义:这是一个
byte[](字节数组)。Snap7 原生接口只能接收字节数组。你不能直接传int或float,必须先手动把它们转换成字节数组,否则代码会报错或写入乱码。
- 含义:这是一个
因为 data 必须是字节数组,直接写比较麻烦。
写入String类型
比如我要写入“我是中国人”
public static void writePlcData() {
S7Connector s7Connector = initConnect();
try {
// 1. 准备要写入的数据
String text = "我是中国人";
// 将字符串转换为字节数组
// 注意:通常PLC使用GBK编码来处理中文,这样1个汉字占2个字节
// 如果使用UTF-8,1个汉字通常占3个字节,可能会导致乱码或长度不够
byte[] data = text.getBytes("GBK");
// 2. 执行写入
// 参数解释:
// DaveArea.DB -> 区域:数据块
// 1 -> DB编号:DB1
// 20 -> 起始位置:从第20个字节开始写 (对应截图的 0010)
// data -> 数据内容:转换后的字节数组
s7Connector.write(DaveArea.DB, 1, 20, data);
System.out.println("写入成功!写入长度:" + data.length + " 字节");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
s7Connector.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}数据块:
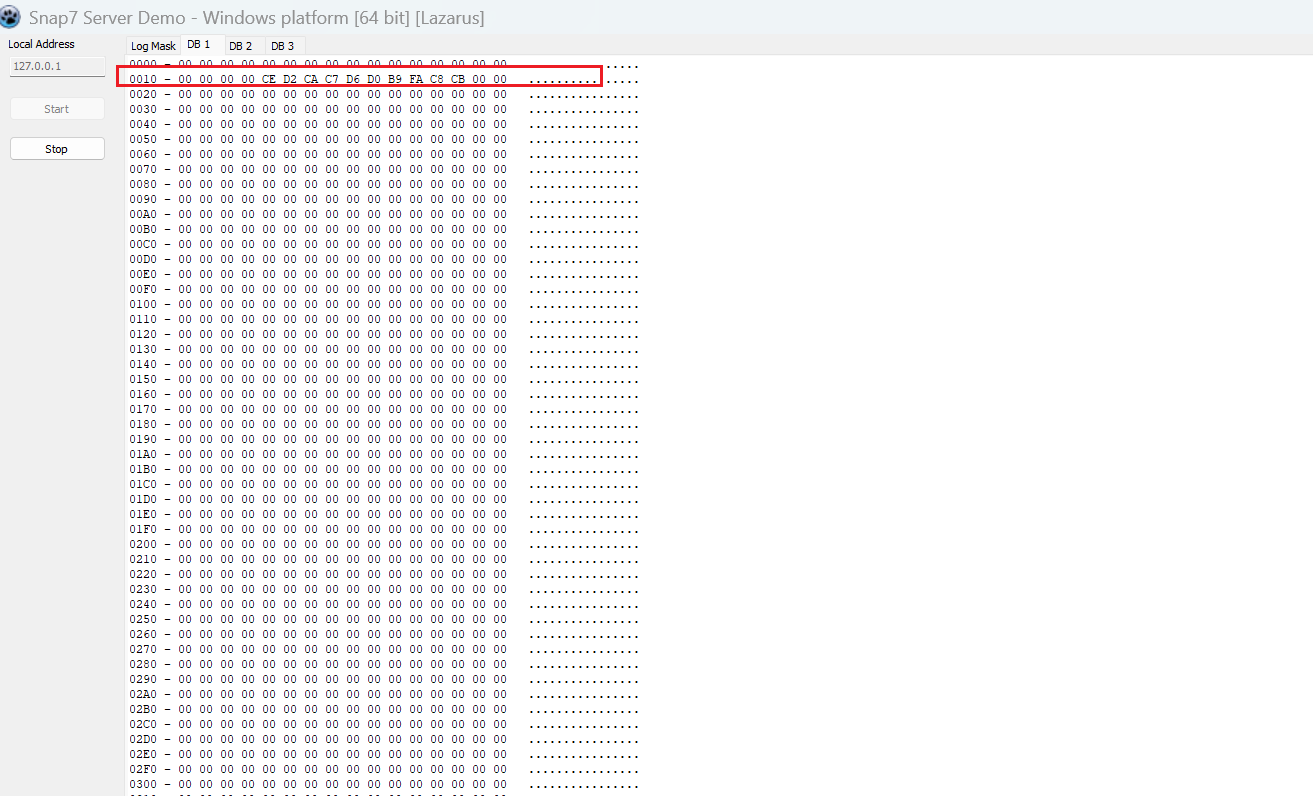
之所以写在0010的位置:
- 地址换算
-
- 你的代码写的是十进制
20。 - 十进制
20转换为十六进制是14(即0x14)。
- 你的代码写的是十进制
- 界面布局
-
0010行:代表地址范围0x10(16) 到0x1F(31)。0020行:代表地址范围0x20(32) 到0x2F(47)。
- 结论
-
- 你要写入的起始地址是
0x14。 0x14位于0x10和0x1F之间,所以它必须显示在0010这一行。
- 你要写入的起始地址是
看日志:

日志中 Write request, Area : DB1, Start : 20, Size : 10 --> OK 的含义如下:
Write request:这是一个写入操作的请求。Area : DB1:目标区域是数据块 1。Start : 20:起始地址是第 20 个字节(十进制)。Size : 10:写入的数据长度是 10 个字节。--> OK:操作成功。
写入int类型
假如要存储100的数字到DB1里,也就是64,但是这里不能直接把100转换为字节数组直接写入,因为计算机在存储多字节数据(如 int)时,需要决定是先存高位还是先存低位。
在 Java 中,一个 int 类型占用 4 个字节(32位),而在 S7 PLC 中,一个 INT 类型(如你代码中的 100)通常占用 2 个字节(16位)。
假设 int myValue = 100,它的二进制是 00000000 00000000 00000000 01100100。
如果你使用 Java 的标准方法(如 ByteBuffer)直接转换,默认是 大端模式(Big-Endian),结果是 4 个字节:[00] [00] [00] [64](十六进制,每个【】是一个字节)
问题在于:
- 长度不对:PLC 的
INT只需要 2 个字节,你传 4 个字节会覆盖掉后面相邻的变量。 - 数值不对:如果你截取后两个字节
[00] [64],这在 PLC 里是100。但如果你截取前两个字节[00] [00],那就是0。
所以在转换为字节数组的时候需要进行位运算。
public static void writePlcData() {
S7Connector s7Connector = initConnect();
try {
// 1. 准备数据
int myValue = 100;
// 2. 手动将 int 转为 byte[] (高位在前)
// 在创建字节数组的同时初始化参数
// 第一个参数是将32位的二进制数据右移低8位挤出去,结果为0
// 第二个当你把一个占用空间大的类型(如 4 字节的 int)强制转换成一个占用空间小的类型(如 1 字节的 byte)时
// 只保留原始数据的低 8 位(也就是最右边的 8 位)。
byte[] data = new byte[]{
(byte) (myValue >> 8),
(byte) myValue
};
s7Connector.write(DaveArea.DB, 1, 1, data);
System.out.println("写入成功!写入长度:" + data.length + " 字节");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
s7Connector.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}结果:
2.4..读取数据
格式:
// 方法签名大致如下:
s7Connector.write(Area, DBNumber, readNumber,StartByte)读取字符串
比如读取我是中国人:
/**
* 读取PLC中的数据,字符串类型
**/
public static void readPlcData() throws UnsupportedEncodingException {
S7Connector s7Connector = initConnect();
// 这四个参数共同定义了一次“读取操作”的完整指令,它们告诉连接器:去哪里、拿什么、拿多少、从哪开始。
byte[] barcodeByte = s7Connector.read(DaveArea.DB, 1, 10, 20);
//由于当前PLC地址中保存的数据类型是字符串类型,所以直接将byte[] 转成string即可;
String barcode = new String(barcodeByte, "GBK");
System.out.println(barcode);
try {
s7Connector.close();
} catch (IOException e) {
e.printStackTrace();
}
}
因为在写入的时候是从20的位置上写的,所以读取的时候需要从这里读,读取的数量就是你存入数据的字节数。
结果:

读取int类型
public static void readPlcData() throws UnsupportedEncodingException {
S7Connector s7Connector = initConnect();
// 这四个参数共同定义了一次“读取操作”的完整指令,它们告诉连接器:去哪里、拿什么、拿多少、从哪开始。
byte[] barcodeByte = s7Connector.read(DaveArea.DB, 1, 2, 1);
int barcode = ((barcodeByte[0] & 0xFF) << 8) | (barcodeByte[1] & 0xFF);
try {
s7Connector.close();
} catch (IOException e) {
e.printStackTrace();
}
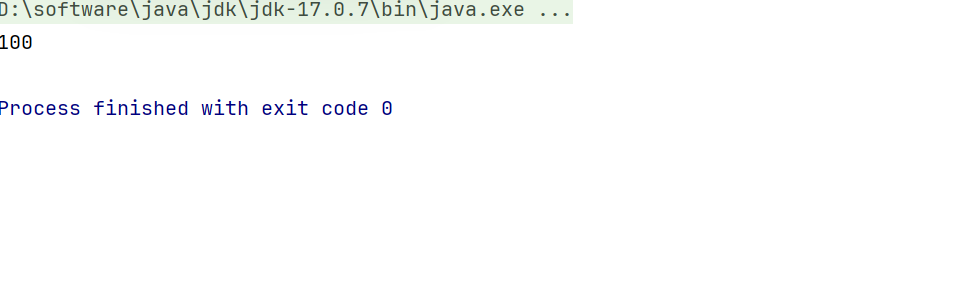
}结果是100

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)