玩转 AI 空间控制:告别人物乱放,精准掌控角色站位
导语:写满提示词,AI 还是把人物乱放?
即便 Nano Banana Pro、即梦 AI 等主流工具的语义理解能力已大幅升级,“空间位置的精准控制” 依然是绝大多数 AI 创作者的核心痛点。
为了让人物站到指定位置,很多人会堆砌大段方位描述,甚至去学习复杂的坐标轴系统、节点编辑工具,不仅学习成本极高,最终效果也往往不尽如人意 ——AI 依然会把人物乱放、动作错位、轨迹混乱。
本期教程,我们回归最直观、零门槛的 “看图说话” 逻辑,教你用一套名为 “视觉锚点标注法” 的极简技巧,只需简单的画框、箭头搭配基础提示词,就能让 AI 精准执行你的指令,指哪打哪。这套方法不仅能锁定静态画面的角色站位,更能完美控制 AI 视频中人物的运动轨迹,零基础也能直接上手。
第一章:为什么 AI 总是不听话?揭秘空间失控的底层逻辑
想要解决问题,先要搞透问题的根源:为什么你写了再详细的方位描述,AI 也很难精准执行?
答案藏在当前主流 AI 生成工具的扩散模型底层机制里。
扩散模型的核心工作逻辑,是从一堆无序的随机噪点中,根据提示词的引导,逐步 “雕刻” 出清晰的画面。在这个从无到有的生成过程中,AI 的核心注意力,始终集中在 “元素的特征匹配”上 —— 比如画面的整体质感、人物的五官脸型、服装的材质纹理,而非我们在意的 “空间绝对坐标”。

扩散模型核心原理
扩散模型(Diffusion Model)是一种基于概率的深度生成模型,其核心思想源于非平衡热力学中的扩散现象,通过模拟数据在隐空间中的渐进噪声化与去噪过程,实现高质量数据生成。
- 正向扩散:给原始图像数据逐步添加高斯噪声,让清晰的画面最终变成完全无序的随机噪点;
- 反向扩散:从完全的随机噪点出发,通过模型逐步去噪,还原出符合提示词要求的清晰画面。
通俗类比理解:这个过程就像把墨水滴入清水,看着它慢慢扩散成浑水(正向扩散);而 AI 生成画面,就是把这杯浑水,逆向还原成最初的那滴墨水的过程。
正是这个底层机制,导致了一个必然现象:文本提示词在传递 “空间位置” 信息时,信号强度极其微弱。
当你写下 “人物站在画面最左侧”“从左向右奔跑” 这类强空间属性的描述时,这些信息在 AI 的多轮降噪过程中,很容易被权重更高的 “人物特征、画面质感” 等描述覆盖,甚至直接丢失。这就是为什么单靠文本提示词约束位置,往往吃力不讨好。
想要让 AI 精准识别空间信息,我们就需要一种比文字信号强度高数十倍的引导方式 —— 那就是 “图像本身”。
第二章:降维打击 ——“视觉锚点” 控制法原理与全流程实操
既然 AI 对文字的空间感知能力薄弱,我们就直接用图像给它划定边界,这就是本次教程的核心方法 ——视觉锚点标注法。
这套方法的核心逻辑,是用图像的物理像素,强行锁定 AI 的生成兴趣区域,精准度远超万字文本提示词。它适用于市面上所有支持 “图生图(垫图)”“参考图” 功能的 AI 工具,包括 Nano Banana Pro、Midjourney、即梦 AI、Stable Diffusion 等,全平台通用。
核心操作全流程(3 步零门槛落地)
第一步:先造空镜,生成纯净场景底图
先不添加任何人物描述,单独生成一张无人物的纯净场景空镜,作为后续标注的基础画布。这一步的核心,是提前固定好画面的透视、光影、构图,避免后续人物与场景出现融合错位。
第二步:人工标记,用简单图形划定视觉锚点
在生成好的空镜底图上,用任意画图工具(哪怕是手机自带的截图编辑、系统画图工具都可以),通过简单的选框、箭头、色块,标注出角色的站位、朝向、动作范围。
- 单人物静态站位:用闭合选框圈出人物站立的位置,箭头标注人物朝向;
- 多人物站位:用不同颜色的选框,分别圈出不同人物的站位;
- 固定动作范围:用线条简单勾勒人物的动作边界,比如 “抬手的高度”“坐下的区域”。

第三步:带图生成,喂入参考图 + 精准提示词
把标注好锚点的图片作为参考图 / 垫图喂给 AI,再输入对应提示词,AI 就会严格在你标记的区域内生成人物,完美匹配场景的透视与光影。

提示词:让图一的人物在图二标注位置倒立 ,光影融合自然,与背景融合,随后去掉红框

多人复杂站位的精准控制方案
当画面需要出现 2 个及以上人物,且每个人物有不同的特征、站位、动作时,只用同一种颜色标记,AI 极易出现人物特征混淆、站位错位的问题。
解决方案:用不同颜色做视觉隔离,提示词精准对应
标记环节:在底图上,用不同颜色的闭合选框,分别标注不同人物的站位,比如红色框对应男性角色,蓝色框对应女性角色,黄色框对应儿童角色;

提示词环节:明确告知 AI “颜色 - 人物 - 动作” 的对应关系,让 AI 精准识别每个锚点的生成要求。
多人站位提示词:将图2角色坐在图1红框的沙发上,图3角色坐在图1绿框的椅子上,图4角色自然的站在蓝框图1处,光影重构,最后需要去掉框

第三章:视频生成落地 —— 让角色按指定轨迹精准运动
这套视觉锚点法,不仅能精准控制静态画面的人物站位,更能完美适配 AI 视频生成,彻底解决人物运动轨迹混乱、穿模、出画的核心痛点,适配可灵 AI、即梦 AI、海螺 AI 等所有主流 AI 视频生成工具。
视频生成全流程实操
第一步:标注完整运动轨迹
在生成好的空镜底图上,用带箭头的连续线条,清晰画出人物的起点、运动路径、终点,同时标注运动方向;如果是多段动作,可用数字标记动作的先后顺序。

提示词:图中的人物按照红色箭头的轨迹行走,生成的画面中不要有红线
第二步:输入精准提示词,做好避坑设置
把标注好轨迹的底图作为参考图喂入 AI 视频生成工具,输入对应提示词,核心要明确两个信息:一是人物的运动规则,二是画面的禁用元素。
人物行动轨迹
关键避坑注意事项
一定要在提示词 / 负面提示词中,明确要求 AI 移除所有标记元素。如果缺少这一步,AI 大概率会把你画的箭头、选框、线条一起生成到最终视频里,导致画面穿帮、元素错乱。
第四章:高阶避坑 —— 多角色运动的色彩隔离法
单人物的运动轨迹控制难度较低,但当画面中有 2-3 个角色,且每个角色都有不同的运动方向、动作、速度时,AI 极易出现人物混淆、轨迹错位、动作穿模的问题 —— 也就是我们常说的 “张三跑到了李四的轨迹上”。
想要彻底解决这个问题,就要用到进阶的 **“色彩隔离法”**,它是视觉锚点法的高阶延伸,也是多角色 AI 视频生成的核心控场技巧。
多角色运动控制全流程
第一步:分色标记,隔离不同角色的运动轨迹
在空镜底图上,用不同颜色的箭头 + 线条,分别为每个角色标注独立的运动轨迹,同时用数字标注运动的起点、终点和关键动作节点。
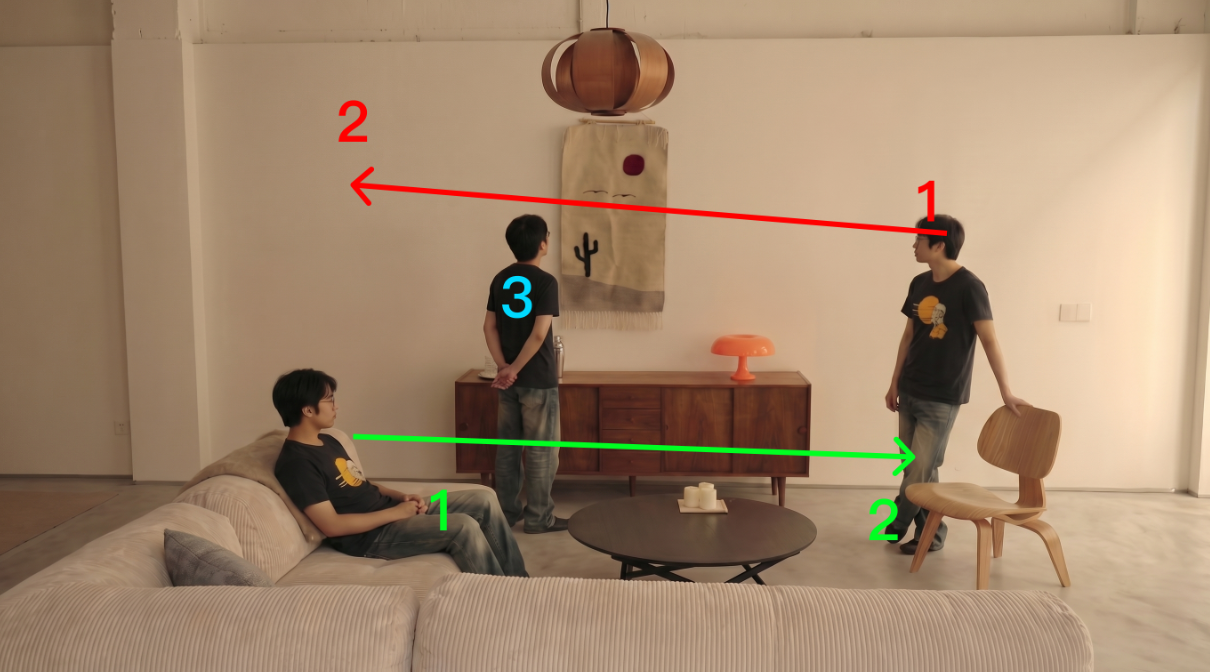
第二步:提示词精准对应,锁定每个角色的动作规则
在提示词中,严格按照 “颜色 - 人物 - 动作 - 轨迹” 的对应关系,清晰描述每个角色的生成要求,不给 AI 留下模糊解读的空间。
图中有三个人物,分别是红色标,绿色标,蓝色标,绿色标人物按照箭头从1处走到2处,红色标人物按照箭头从1处走到2处,蓝色人物保持不动,四处观望。视频中不要有箭头显示
人物轨迹2
国内稳定 AI 创作 API 接入方案(纯实操分享)
想要落地这套视觉锚点精准控制工作流,无论是批量生成场景空镜、多模型同步出图,还是 AI 动态视频生成,都离不开稳定、高效的 AI 模型 API 支持。
很多创作者在商业落地时,都遇到过海外 API 访问不稳定、延迟高、频繁丢包、成本高昂、配置繁琐的痛点,这里给大家分享一套实测可用的国内直连接入方案 ——云雾 AI,无论是开发者批量对接项目,还是普通创作者批量生成商业内容,都能轻松上手。
云雾 AI 核心优势(全场景实测验证)
- 国内网络直连,无需代理与特殊网络配置,实测低延迟、无超时丢包,批量出图、视频生成全程不中断
- 100% 兼容 OpenAI、Gemini 原生接口格式,主流 AI 绘画、视频生成工具、开发框架无缝接入,零迁移成本
- 按 Token / 张数透明计费,无最低充值门槛,无隐藏消费,日常创作月均成本极低,远低于官方 API
- 覆盖文本创作、图文生成、视频制作等全品类 AIGC 能力,完美适配 Nano Banana Pro、Midjourney、可灵 AI 等全工具,一站式满足全流程创作需求
- 提供完整开发文档与新手教程,新用户注册即可领取免费体验额度,调用失败自动返还,零试错成本
核心接入信息(纯实操参考,直接复制可用)
- 基础访问地址(Base URL):http://yunwu.site/register?aff=NxvH
- 支持模型:涵盖 Midjourney、Gemini、Claude 等文本、绘画、视频全场景主流模型,持续更新最新版本
- 接入方式:
- 开发者:替换 api_key 与 base_url 即可直接调用,无需额外适配,完美兼容现有开发框架
- 普通用户:可通过 Cherry Studio、Chatbox 等主流 AI 客户端零代码配置使用,操作简单无门槛
第五章:总结与创作心得
回过头来看,这套看似 “画框框、画箭头” 的简单方法,实则蕴含了人机协作最高效的智慧:我们不需要强迫自己适配 AI 的底层逻辑,去钻研复杂的节点连线、三维坐标系、空间参数,而是用 AI 最能识别的语言 —— 图像,去和它沟通。
无论是主打图像生成的 Nano Banana Pro、Midjourney,还是主攻视频创作的可灵 AI、海螺 AI,这套基于 “视觉锚点”的空间控制方法论,都是全平台通用的。
掌握了这个技巧,你就能把画面构图、人物站位、运动轨迹的控制权,牢牢握在自己手里,彻底告别 “抽卡式生成”,大幅降低废片率,把更多精力放在创意本身,而非反复调整提示词的无效内耗中。
现在就打开你手头的 AI 工具,亲自试一试这种 “指哪打哪” 的精准控制快感吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)