NL2SQL — 自然语言问数助手
·
NL2SQL — 自然语言问数助手
基于 LangGraph + DashScope + ZhipuAI 实现的自然语言转 SQL 查询系统。用户用中文提问,系统自动匹配相关表结构、生成 SQL 并执行返回结果。
项目源码
演示案例
功能特性
- 自然语言 → SQL 全自动转换
- 向量相似度匹配表结构,无需手动指定表名
- SQL 执行失败自动重试(最多 2 次),错误信息反馈给 LLM 自动修正
- 多轮对话支持,基于 LangGraph MemorySaver 保存会话上下文
- 未匹配到相关表时提示用户重新描述,不中断会话
技术栈
| 组件 | 选型 |
|---|---|
| Embedding | DashScope qwen3-vl-embedding |
| LLM | ZhipuAI glm-4 |
| 向量相似度 | NumPy 余弦相似度(Python 侧计算) |
| 数据库 | PostgreSQL + psycopg2 连接池 |
| 流程编排 | LangGraph StateGraph + MemorySaver |
项目结构
nl2sql/
├── 初始化表.sql # 建表 DDL 及测试数据
├── db_connection.py # PostgreSQL 连接池管理
├── models.py # 数据库实体类
├── repository.py # 常用查询方法
├── init_table_embbeding.py # 表结构向量化初始化(一次性运行)
├── langGraph_sql_agent.py # NL2SQL 主流程(LangGraph)
└── README.md
快速开始
1. 安装依赖
pip install langgraph langchain-community langchain-core numpy psycopg2-binary dashscope
2. 初始化数据库
在 PostgreSQL 中执行建表脚本:
psql -U root -d demo01 -f nl2sql/初始化表.sql
数据库连接配置在 db_connection.py 中修改:
POSTGRES_SERVER = "localhost"
POSTGRES_PORT = 5432
POSTGRES_DB = "demo01"
POSTGRES_USER = "root"
POSTGRES_PASSWORD = "Password123@pg"
3. 配置 API Key
在 langGraph_sql_agent.py 中填入你的 Key:
dashscope.api_key = "your-dashscope-api-key"
os.environ["ZHIPUAI_API_KEY"] = "your-zhipuai-api-key"
4. 初始化表结构向量(首次运行必须)
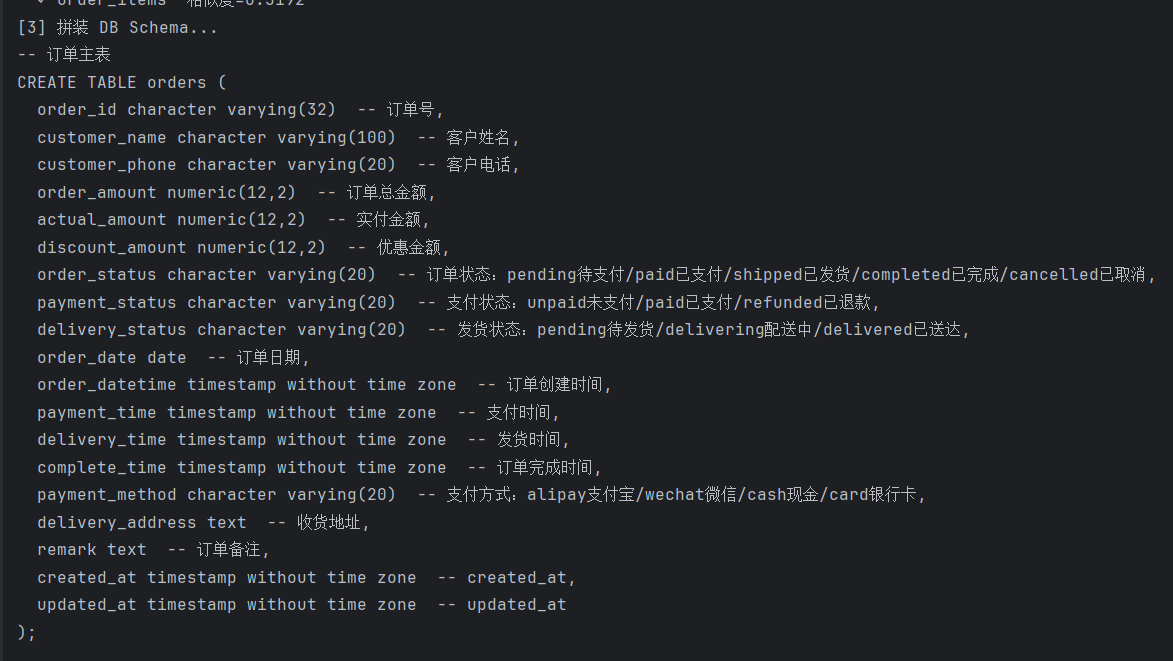
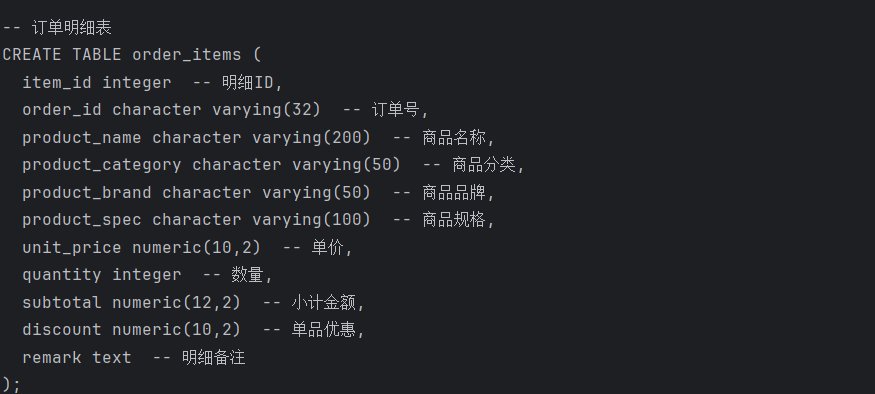
将 orders、order_items 两张表的结构和注释向量化,写入 core_table / core_field:
python nl2sql/init_table_embbeding.py
输出示例:
>>> 处理表: orders
[core_table] 插入: orders id=1
[core_field] 插入: order_id
[core_field] 插入: customer_name
...
>>> 处理表: order_items
[core_table] 插入: order_items id=2
...
初始化完成
5. 启动问数助手
python nl2sql/langGraph_sql_agent.py
============================================================
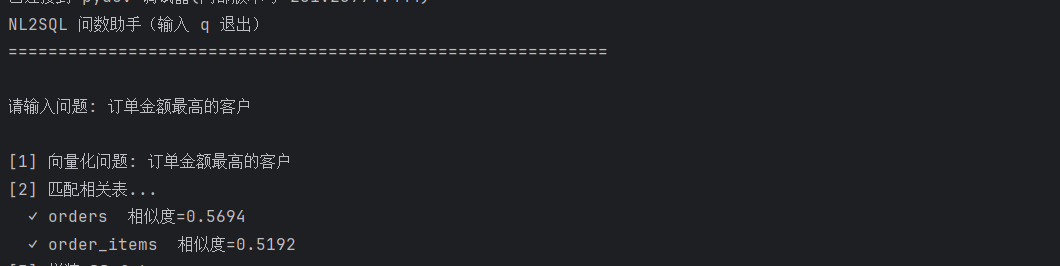
NL2SQL 问数助手(输入 q 退出)
============================================================
请输入问题: 查询10月份所有已完成的订单
执行流程
用户提问
│
[1] embed_query ← 向量化用户问题(DashScope)
│
[2] retrieve_tables ← 余弦相似度匹配 TopN 表(阈值 0.5)
│
├── no_match → 提示用户重新描述(保留会话上下文)
│
[3] build_db_schema ← 查询 core_field,拼装 CREATE TABLE schema
│
[4] build_prompt ← 组装 System + Human 消息
│
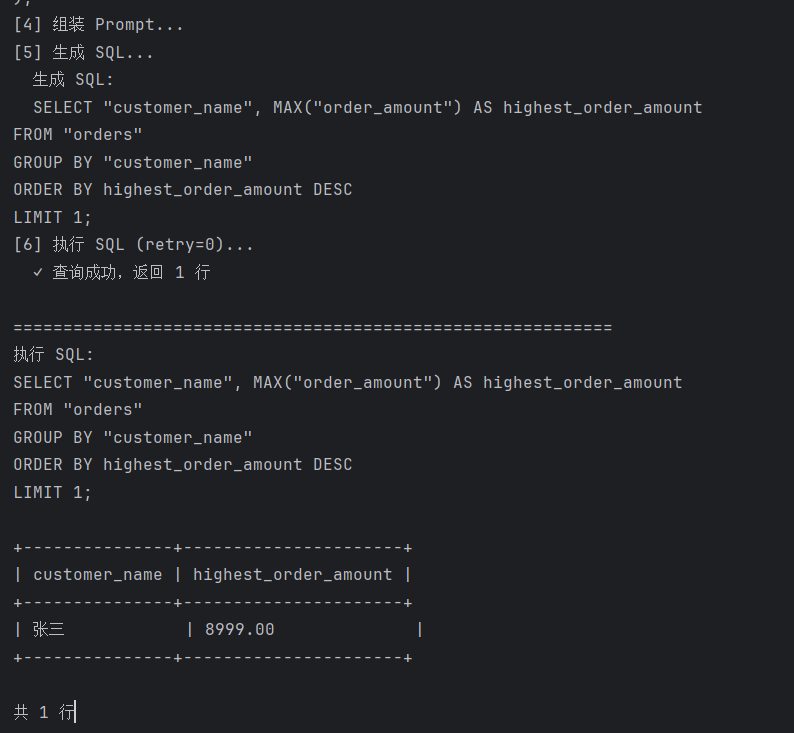
[5] generate_sql ← 调用 glm-4 生成 SQL
│
[6] execute_sql ← 执行 SQL,失败自动重试(≤2次)
│ └── 出错 → 带错误信息回到 build_prompt 让 LLM 修正
│
[7] format_result ← 格式化输出表格结果
元数据表说明
向量初始化后,表结构信息存储在两张元数据表中:
core_table — 表级元数据
| 字段 | 说明 |
|---|---|
| table_name | 表名 |
| table_comment | 原始表注释 |
| custom_comment | 自定义描述(可手动修改以优化匹配效果) |
| embedding | custom_comment 的向量值(text 存储) |
| checked | 是否参与匹配,默认 true |
core_field — 字段级元数据
| 字段 | 说明 |
|---|---|
| table_id | 关联 core_table.id |
| field_name | 字段名 |
| field_type | 字段类型 |
| field_comment | 原始字段注释 |
| custom_comment | 自定义描述(会出现在 schema 中供 LLM 理解) |
| checked | 是否暴露给 LLM,默认 true |
修改
custom_comment可以优化 LLM 对字段含义的理解,无需重新向量化字段(只有表级custom_comment影响向量匹配)。
关键配置
在 langGraph_sql_agent.py 顶部可调整:
TOP_N = 3 # 最多匹配几张表
SIM_THRESHOLD = 0.5 # 余弦相似度阈值,低于此值视为无匹配
MAX_RETRY = 2 # SQL 执行失败最大重试次数
示例问题
查询10月份所有已完成的订单
统计每个客户的订单总金额
查询购买了手机的订单明细
本月销售额最高的商品是什么
查询还未支付的订单列表
扩展建议
- pgvector:表数量增多后,将
embedding字段迁移为vector类型,使用<=>算子在数据库侧计算相似度,性能更好 - Web UI:在
run_repl外层包一层 FastAPI 或 Streamlit,即可变成 Web 服务 - SQL 审计:在
execute_sql节点前加interrupt_before,让用户确认 SQL 后再执行

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)