DBdoctor 让数据库运维告别“盲人摸象”:从经验主义到AI驱动的“CT式”精准诊断
在数字化转型的浪潮中,数据库作为核心基础设施,其性能的稳定性直接决定了业务的生死。然而,一个普遍的困境是:我们明明“看见”了系统变慢了,却总是在“为什么变慢”这个问题上陷入无尽的猜疑链。 传统的监控工具只会抛出海量的、碎片化的指标,DBA们如同“盲人摸象”,被迫在SQL、锁、硬件资源之间进行低效的排查。
Gartner曾指出,到2025年,50%的数据库运维自动化将依赖于AI和机器学习技术,以解决日益复杂的问题。这意味着,数据库运维的范式正在发生根本性转变——从被动救火、依赖个人经验,转向主动发现、精准定位的“CT式”诊断。以DBdoctor为代表的数据库性能诊断平台,正是这一趋势下的产物,它通过数学量化模型和内核级技术,重新定义了“可观测性”的边界。
一、突破传统瓶颈:构建高维度的“性能洞察”体系
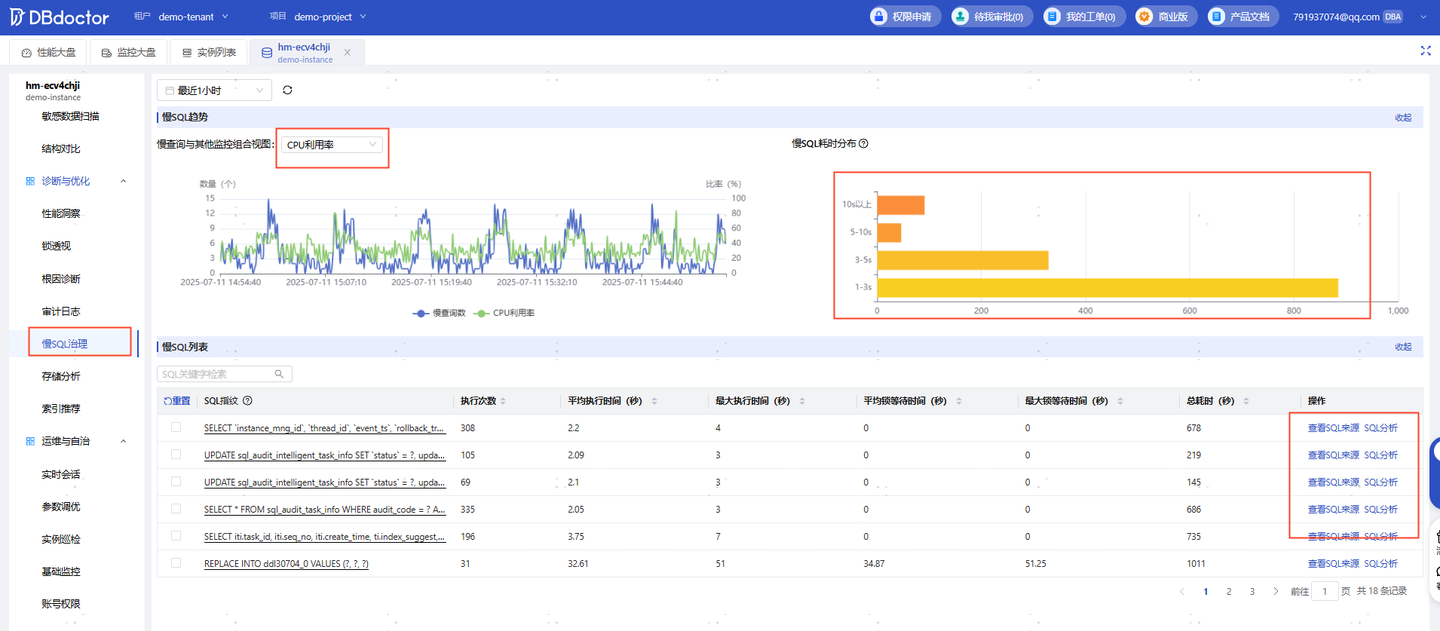
传统的监控为何低效?根源在于数据的“断层”。CPU高了,IO满了,但这些指标和具体是哪条SQL引起的,中间缺少了关键的关联环节。
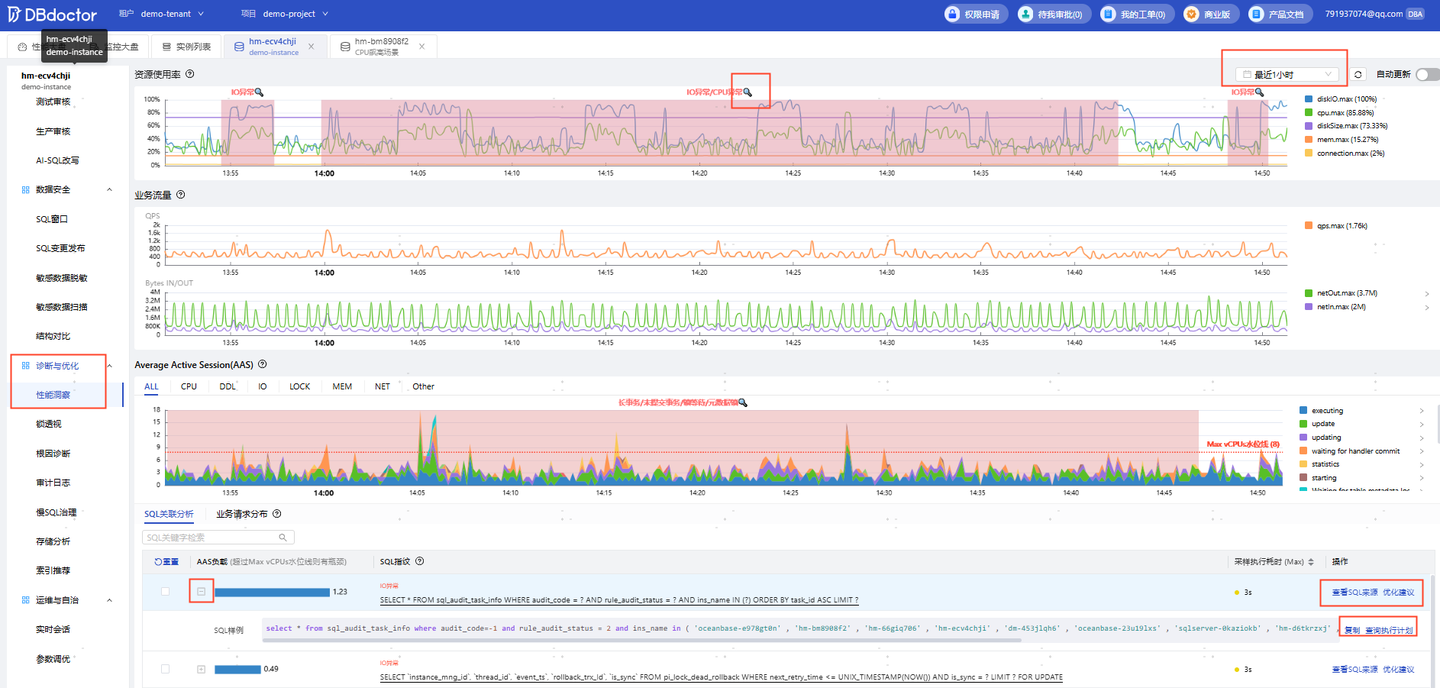
DBdoctor的创新在于,它利用 eBPF技术深入内核,采集到了传统工具无法触及的“黄金数据”。在此基础上,它构建了一个核心模型:平均活跃会话(AAS)。该模型将CPU、IO等系统资源消耗与数据库的活跃会话数量同屏关联,形成了一个多维度的性能坐标系。
当一个突发的红色异常区块被特征值检测算法自动识别时,DBA不再是面对一堆杂乱无章的曲线,而是可以直接点击查看该时间点下的“ 根因SQL列表”。这种从“指标异常”到“问题SQL”的秒级关联,将平均问题定位时间(MTTR)从小时级压缩到了分钟级,是运维效率的一次质的飞跃。
二、复杂问题可视化:将“锁与事务”的黑盒彻底打开
在所有数据库问题中, 锁等待、死锁和长事务无疑是最棘手的难题之一。它们往往随机发生、间歇性重现,排查过程如同“解一团乱麻”。根据一份针对DBA的行业调查,超过30%的性能问题与锁争用有关。
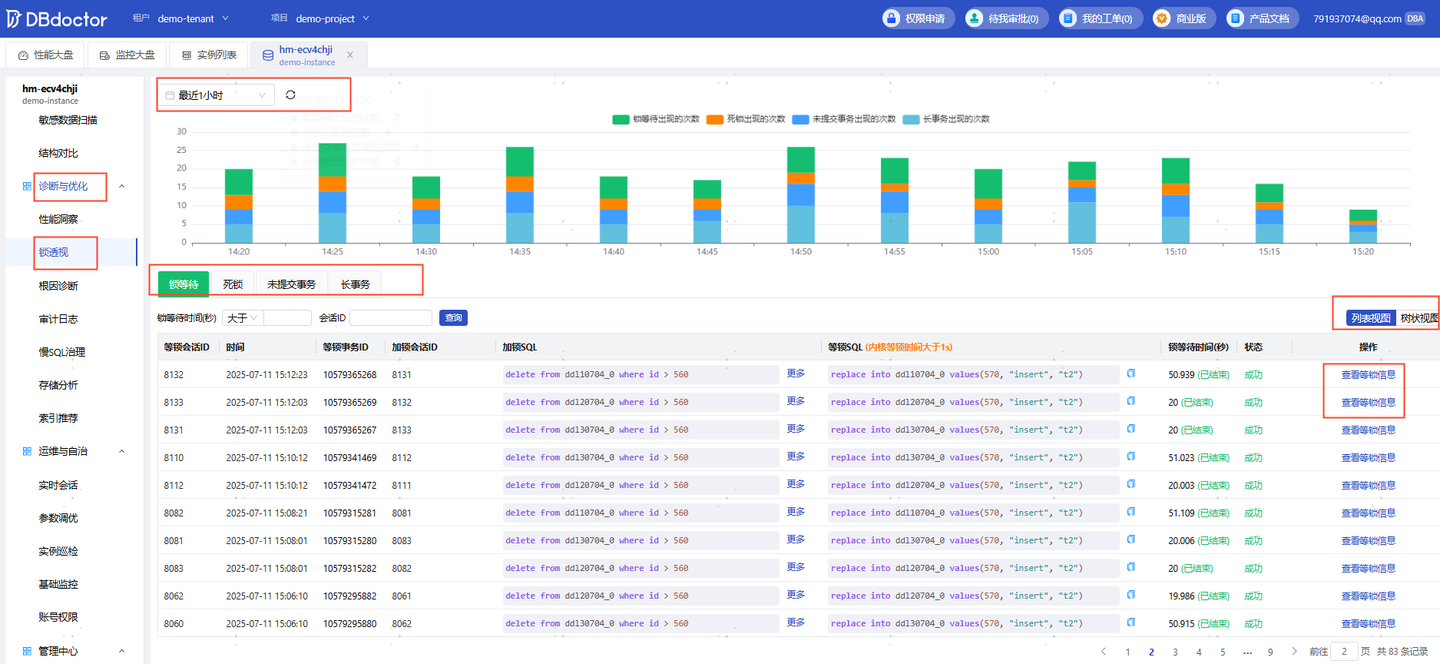
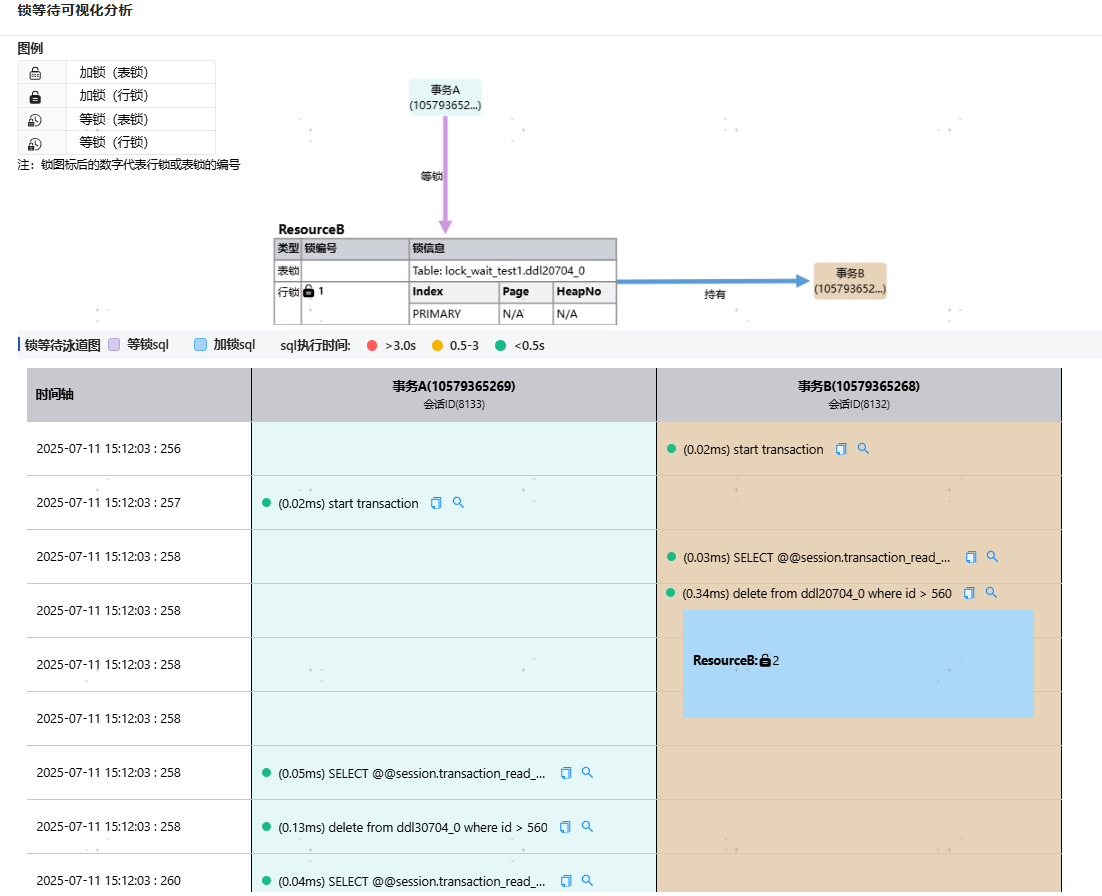
解决复杂问题的关键在于“ 可视化”。先进的可观测性平台,如DBdoctor,通过“ 锁透视”功能,将抽象的内核事件转化为直观的环形图和泳道图。它不再仅仅是告诉你“发生了死锁”,而是像“慢动作回放”一样,清晰地展示出:是哪两个事务互相抢占资源?每个事务执行的SQL步骤是什么?甚至能追溯到事务发起的源头IP。
这种能力极具价值。例如,当你看到泳道图中一个事务长时间持有锁而不释放时,可以立即定位到“未提交事务”的始作俑者,并一键终止。这让原本高度依赖专家经验的“玄学”问题,变成了一套标准化的、可视化的操作流程。
三、从“定位”到“解决”:构建闭环的智能诊断与优化引擎
发现问题只是第一步,如何高效、安全地解决问题才是核心。尤其是对于经验尚浅的运维人员来说,即使定位到慢SQL,也可能因为错误的执行计划分析或不恰当的索引建议而“二次踩坑”。
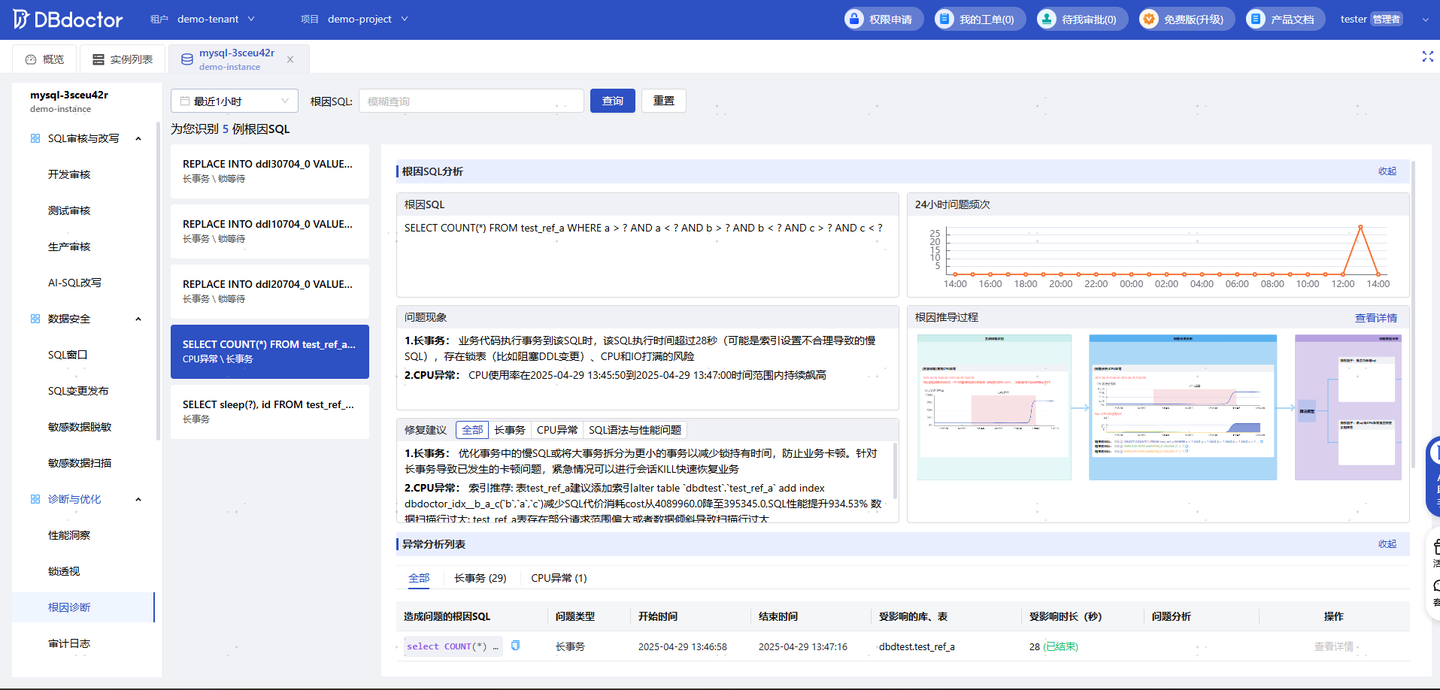
现代的数据库诊断平台正在集成更强大的 AI能力来破解这一难题。它内置了一个基于成本(Cost)模型的索引推荐器。以一条导致CPU飙升的UPDATE语句为例,系统不仅会指出它有问题,还会通过其独有的 外置Cost优化器,进行全场景的代价计算,最终推荐一个全局最优的索引方案。
更重要的是,这个过程是量化、可解释的。用户可以看到优化后的Cost值如何从几万降至个位数,清晰地预估性能提升幅度。这相当于为每一位DBA配备了一位“资深专家”,将复杂的SQL调优工作从“技术难题”变成了“常规操作”。
四、总结:迈向“自动驾驶”的数据库运维新时代
数据库性能优化的未来,一定是数据驱动、AI增强、高度自治的。从实时会话的“直播”监控,到存储空间的提前预警,再到AI驱动的参数自动调优,我们看到,一套强大的性能监控与诊断系统,其价值已远超出“工具”的范畴,它正在成为保障业务稳定性的核心大脑。
对于企业而言,投资这样的平台意味着:
- 降低风险:提前发现锁竞争、索引缺失等隐患,避免流量高峰期的业务故障。
- 提升效率:让高级DBA从繁重的救火工作中解放出来,专注于架构优化。
- 赋能团队:帮助初级工程师快速成长,交付专业级的优化方案。
数据库的“CT机”已经就位。它正在帮助我们的业务从一个“被动响应”的黑暗时代,迈入一个“主动发现、精准打击、自我优化”的光明未来。如果你的团队也正受困于性能迷雾,是时候拥抱这种全新的诊断范式了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)