超越模型:为什么“智能体驾驭工程”才是 AI 开发的新战场?
目录
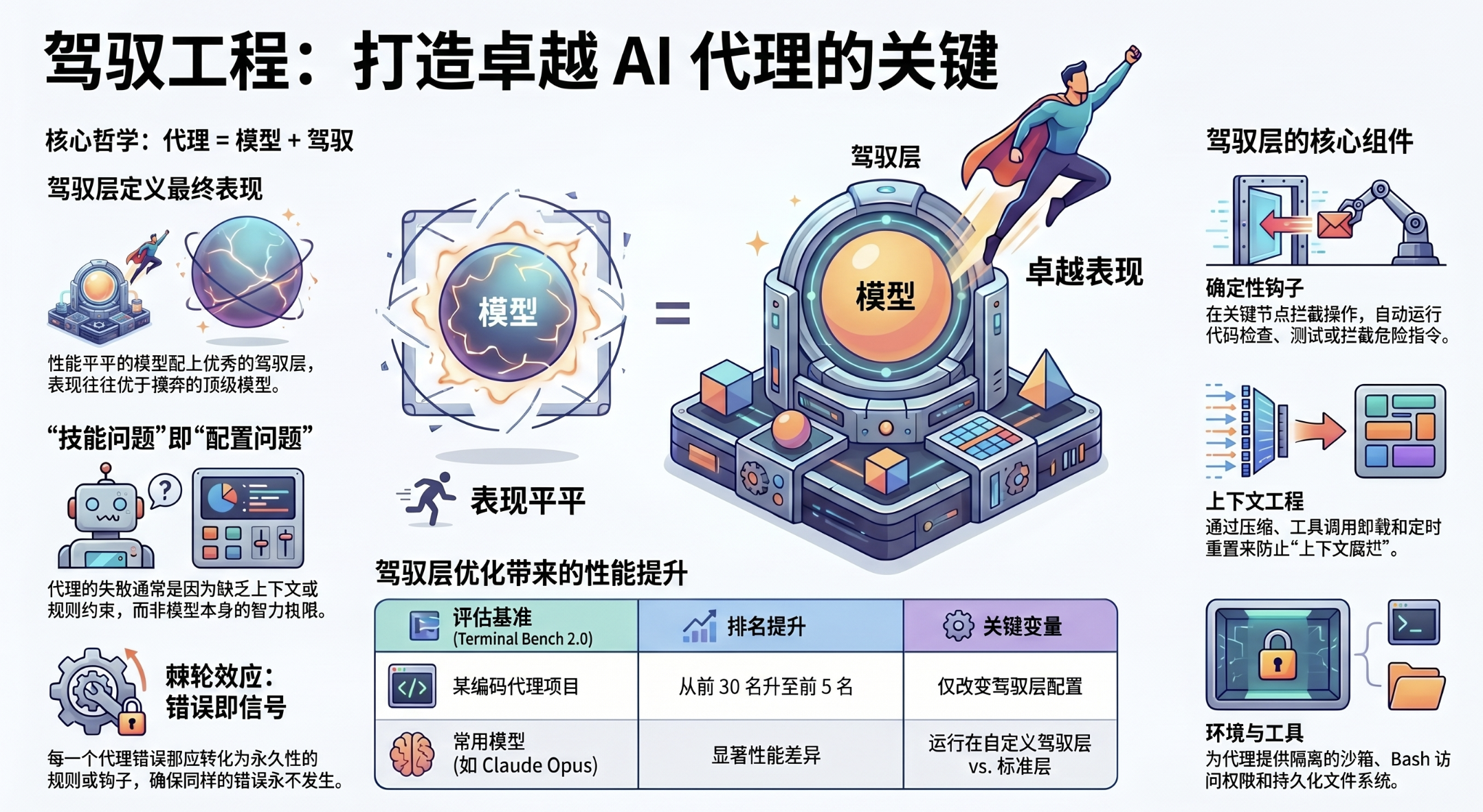
2. 核心公式:智能体 = 模型 + 驾驭 (Agent = Model + Harness)
3. 震撼结论:平庸模型 + 顶级驾驭 > 顶级模型 + 劣质驾驭
1. 引言:摆脱“GPT-6 焦虑症”
当前的开发者社区正处于一种病态的瘫痪中,我称之为“GPT-6 焦虑症”。每个人都在屏息以待下一个基础模型的发布,偏执地对比哪个模型生成的 React 代码更干净,或者哪个模型的幻觉率降低了 0.1%。
作为 AI 架构师,我必须告诉你:这种讨论只触及了系统的一半。基础模型固然重要,但它仅仅是输入。正如 Addy Osmani 所指出的,一个被长期忽视的核心范式正在崛起——“驾驭工程”(Harness Engineering)。模型只是发动机,而“驾驭”是整台赛车的底盘、悬挂和控制系统。
本文的目标是揭示:如何通过构建围绕模型的承重脚手架,让现有的模型爆发出超越其原生性能的统治力。
2. 核心公式:智能体 = 模型 + 驾驭 (Agent = Model + Harness)
Viv Trivedy 提出的这个公式,彻底重新定义了 AI 工程的边界:
智能体 = 模型 + 驾驭 (Agent = Model + Harness)
在这个架构中,“驾驭”不再是辅助性的代码,而是核心的人造产物。它涵盖了模型之外的所有逻辑:
· 指令层: 系统提示词、CLAUDE.md、AGENTS.md 和技能描述文件。
· 工具链: MCP 服务器、API 定义及执行环境。
· 策略层: 上下文压缩策略、钩子(Hooks)和中间件。
· 基础设施: 文件系统、隔离沙盒、浏览器环境。
· 闭环设计: 任务分解、反馈循环与故障恢复路径。
请记住这个架构准则:“只要不是模型,就都属于驾驭。”
原始模型本身并不是智能体。只有当驾驭赋予其状态管理、工具执行能力和强制性约束后,它才真正进化为能够解决问题的智能体。这意味着,工程重点已经从“挑选最聪明的模型”转向了“设计最强悍的驾驭代码”。
3. 震撼结论:平庸模型 + 顶级驾驭 > 顶级模型 + 劣质驾驭
Addy Osmani 的观察揭露了一个令人震惊的事实:即使使用完全相同的模型权重,用户体验到的行为表现也几乎完全由驾驭决定。
在 Terminal Bench 2.0 的性能测试中,出现了一个典型的“驾驭悖论”:运行在 Claude Code 内部的 Claude Opus 4.6(即便使用了该前沿模型),其表现也曾一度低于在更优驾驭中运行的旧模型。Viv 的团队通过仅修改驾驭逻辑,在保持模型不变的情况下,将一个编码智能体的排名从前 30 名直接推到了前 5 名。这就是驾驭工程的“冒烟枪”证据。
“有趣的工程并不在于挑选模型,而是在于设计模型周围的脚手架。目前的模型能力与你实际看到的表现之间,存在着巨大的‘驾驭鸿沟’(Harness Gap)。”
4. 重新定义失败:“技能问题”而非“模型瓶颈”
当智能体在复杂任务中“翻车”时,平庸的开发者会抱怨模型太蠢并开始等待 GPT-6。而驾驭架构师则会将其重构为“技能问题”——即配置和执行逻辑的失效。
驾驭工程通过主动干预来解决所谓的模型局限:
· 约定缺失? 在 AGENTS.md 中强制注入项目规范。
· 行为失控? 使用钩子(Hooks)拦截 rm -rf 或危险的数据库操作。
· 逻辑迷失? 通过驾驭将任务强制拆分为“规划器(Planner)”和“执行器(Executor)”,引入外部验证逻辑。
这种心态的转变,让开发者从被动的等待者变成了主动的掌控者。我们不再祈求模型变得更聪明,而是通过工程手段立即修复它的“技能缺陷”。
5. 棘轮效应:让错误成为永久的规则 (The Ratchet)
在驾驭工程中,我们推崇“棘轮”(Ratchet)习惯:智能体的每一次失败都是极其宝贵的改进信号,绝非一次性的运气不好。
优秀的 AGENTS.md 应该是飞行员的检查清单,而不是文学创作的风格指南。 它的每一行文字都应该能追溯到一个具体的、曾经发生过的生产环境失败。
标准的“棘轮”反馈流程如下:
· 捕捉失败: 智能体在提交 PR 时忘记了运行 Lint 检查。
· 强化驾驭: 编写一个 pre-commit 钩子强制执行检查,并在 AGENTS.md 中添加关于 Lint 的硬性规则。
· 固化规则: 遵循“只有在看到真实失败时才添加约束”的原则。
这种学科是无法直接下载的。它必须结合你的代码库特性,通过不断的失败、反馈和修正积淀而成。
6. 反馈设计的金律:成功是沉默的,失败是嘈杂的
HumanLayer 提出了一项关键的架构原则,用于优化智能体的反馈回路并节省宝贵的 Token:
“成功是沉默的,失败是嘈杂的。” (Success is silent, failures are verbose)
· 沉默通过: 当类型检查(Typecheck)或单元测试通过时,驾驭不需要给模型任何反馈。
· 嘈杂失败: 只有在任务失败时,驾驭才将详尽的、带有上下文的错误堆栈注入循环。
这种设计能强迫模型进入“自我修复”模式,让反馈回路在正常时保持最高效率,在异常时提供最强的纠偏动力。
7. 上下文衰退的对抗:从压缩到技能分级
随着对话加深,模型会遭遇“上下文腐烂”(Context Rot)。驾驭必须作为动态的上下文管理系统来介入:
· 智能压缩(Compaction): 当窗口接近极限时,由驾驭总结并卸载陈旧信息。
· 工具调用卸载(Tool-call offloading): 将几千行的日志输出存入文件系统,仅让模型按需读取其摘要或特定片段。
· 渐进式披露(Progressive disclosure): 仅在当前任务需要时才加载相关工具的描述,防止指令过载。
Anthropic 的研究强调,对于超长时程的任务,简单的压缩是不够的。驾驭需要执行完整的上下文重置,并生成一份“结构化简报”——就像人类工程师交接班一样,进行清晰的任务状态同步。
8. 结论:迈向“驾驭即服务”(HaaS) 的未来
我们正在见证从“构建 LLM API 调用”到“构建驾驭运行时(Harness Runtime)”的范式转移。
一个核心洞察是:驾驭不会随着模型的进步而萎缩,它们只会发生迁移。 当模型变得更强大,旧的焦虑(如上下文焦虑)会消失,但新的挑战(如多日记忆管理、多智能体协同、UI 设计审美评测)会随之而来。正如 Anthropic 所言,驾驭的每一部分都代表了模型尚不能独立完成的假设。
未来的驾驭将不再是静态的配置文件,而是演变为类似编译器的动态系统——能够根据任务实时组装工具链和上下文。
目前的顶级工具(Cursor, Aider, Cline)在驾驭模式上的高度趋同,正证明了这一工程领域的承重价值。
最后留下一个思考题: 当模型能力不断进化,你的驾驭是在随之进化、为它开辟更广阔的战场,还是已经成为了限制它潜力的枷锁?
作者:道一云低代码
作者想说:喜欢本文请点点关注~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)