【技术全解析】LegalGuard AI:多智能体协作与 DPO 微调下的跨国法律合规审查新范式
一、 项目背景:法律 AI 落地的“最后一公里”
在跨境贸易合同审查中,传统的人工审核面临着效率低、长文本易遗漏、跨国法律条文复杂等痛点。而普通的通用大模型在面对复杂的法律文本时,往往存在“法律严谨性不足”和“复杂排版解析失真”的问题。
LegalGuard AI 旨在通过一套**“高精度解析 + 专家偏好对齐 + 多角色博弈审查”**的全链路技术方案,实现合同风险识别的自动化与智能化。
二、 全链路技术路线图
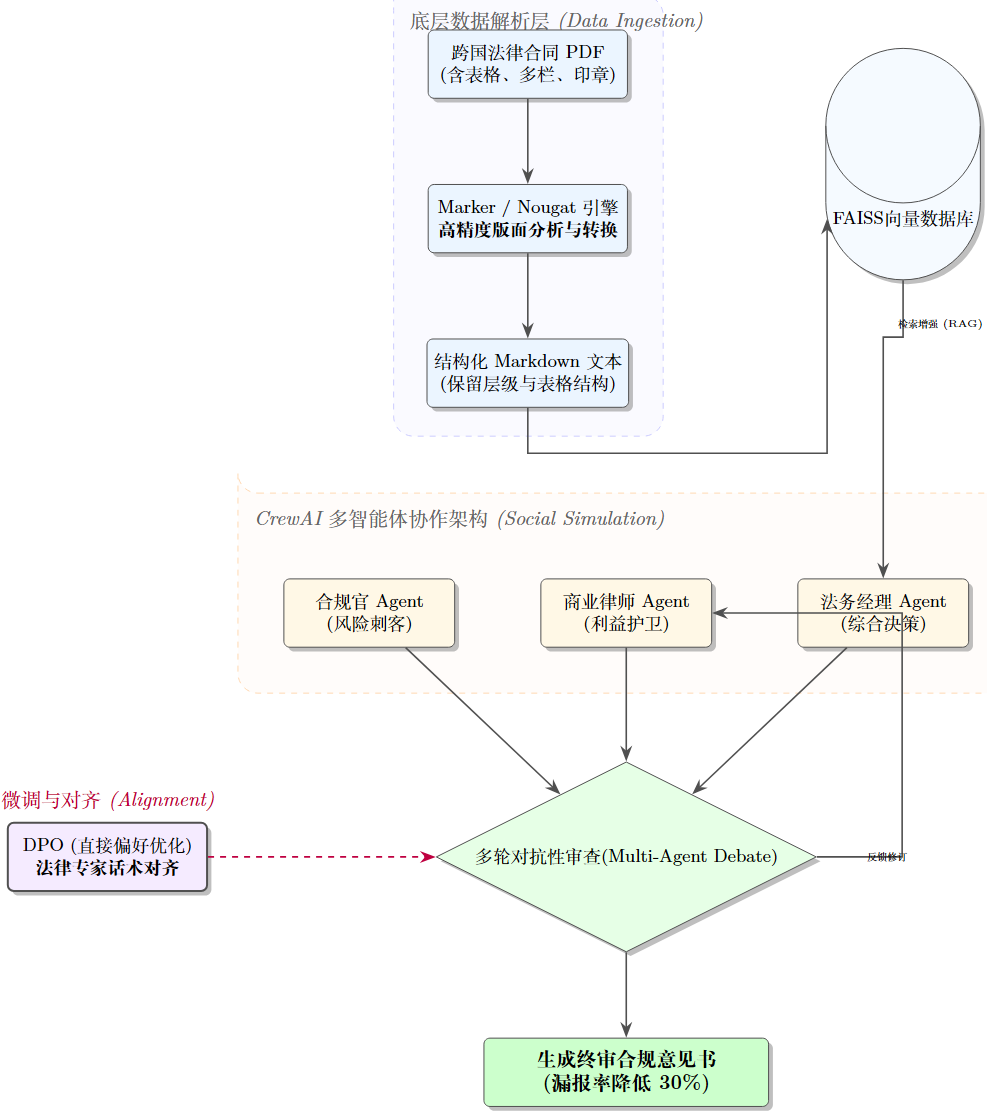
项目的核心路线可以概括为:数据结构化 -> 模型专业化 -> 审查多维化。
1. 数据层:非结构化文档的“降维打击” (Marker/Nougat)
技术痛点:跨境合同中充斥着双语对照、嵌套表格和签章,传统 OCR 识别出的文本顺序错乱,导致 RAG(检索增强生成)系统在检索阶段出现语义失真。
技术实现:
-
引擎选型:集成 Marker 与 Nougat 深度学习解析引擎。
-
结构化转换:将扫描版 PDF 直接转换为标准 Markdown 格式。
-
效果:Markdown 完美保留了法律条文的层级(Header)和表格结构。在后续进入 FAISS 向量库时,每一个 Text Chunk 都具备完整的上下文语义,从源头解决了 RAG 系统的“幻觉”问题。
2. 模型层:基于 DPO 的法律领域对齐 (Direct Preference Optimization)
技术痛点:原生 GPT-4o 虽强,但在法律话术上往往过于平庸,缺乏律师特有的严谨逻辑和术语一致性。
技术实现:
-
构建偏好数据集:收集“专业律师修改后的建议”作为 Chosen(优选) 样本,将“模型原生输出”作为 Rejected(劣选) 样本。
-
DPO 微调:通过 TRL (Transformer Reinforcement Learning) 框架,直接对模型权重进行偏好优化。
-
核心价值:不同于传统的 SFT(指令微调),DPO 让模型学会了在多个答案中选择最严谨、最符合法律逻辑的那一个。
-
成效:法律话术一致性提升 40%,使 AI 建议真正具备了法务参考价值。
3. 协作层:多角色协同博弈架构 (CrewAI + Multi-Agent Debate)
技术痛点:单 Agent 容易产生“认知盲区”,难以发现潜藏在合同字里行间的条款冲突。
技术实现:
-
多角色建模:基于 CrewAI 构建了一个虚拟法务团队:
-
合规官 (Compliance Agent):专注识别违反跨境法律法规的条文。
-
资深律师 (Lawyer Agent):专注寻找对己方不利、风险敞口过大的商业条款。
-
法务经理 (Manager Agent):负责裁决与汇总。
-
-
对抗性审查 (Multi-Agent Debate):
-
合规官进行首轮扫描。
-
律师针对合规官的结果进行反驳,并补充商业风险点。
-
通过多轮辩论机制,强制 Agent 在对抗中深度挖掘条款间的隐性冲突。
-
三、 业务成效与核心指标
通过上述技术方案的组合,LegalGuard AI 在实际业务场景中交出了优异的答卷:
-
核心条款漏报率降低 30%:多角色博弈有效避免了单一模型因长文本疲劳导致的漏检。
-
审查效率提升 5 倍以上:原本需要资深法务数小时处理的长合同,系统在数分钟内即可输出带有辩论逻辑的终审报告。
-
风控自动化水平显著增强:实现了从原始 PDF 到专业建议书的端到端闭环。
四、 核心架构总结:为什么这套方案能行?
-
底座稳:Marker/Nougat 保证了输入给 AI 的信息是 100% 准确的。
-
大脑专:DPO 微调让 AI 拥有了法律专家的思维偏好和表达方式。
-
流程严:Multi-Agent Debate 模拟了人类法务团队的真实协作流程,通过“左手打右手”挖掘深度风险。
五、 开发者说 (Retrospective)
在开发 LegalGuard AI 的过程中,我意识到:Agent 协作不仅仅是把任务拆分,更重要的是建立“对抗”与“反馈”。
当合规官 Agent 和律师 Agent 为了一个“不可抗力”条款的定义吵得不可开交时,我就知道,这个系统的深度已经超越了简单的文本匹配。法律的本质是博弈,而我们的技术路线完美契合了这一本质。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)