RAG混合检索【有效提高召回率】
导读: 搭好了向量库,检索却总差点意思——要么搜不到同义词,要么关键词一变就全军覆没?本文带你认识混合检索(Hybrid Search):稀疏 + 密集双路出击,把召回率和准确率同时拉满。附完整 Milvus 实战代码,一篇搞定。
附代码实战含动图讲解零基础友好

一、两个工程师的对话,说出了你的心声
上周,同事小张来找我吐槽:
“我做了一个古诗词知识库,用向量检索,用户搜’秋天落叶思念家乡’,能搜到《静夜思》,挺好的。但一换成’含秋风两个字的七言律诗’,结果全错了——它完全不理解我要精确匹配’秋风’这个词。”
我问他:“那你换回关键词搜索呢?”
他说:“更惨。用 BM25,搜’秋风’能找到刘彻的《秋风辞》,但用户一说’写秋天的思乡诗’,它一个相关的都捞不上来。”
这就是单一检索方案的经典两难困境:
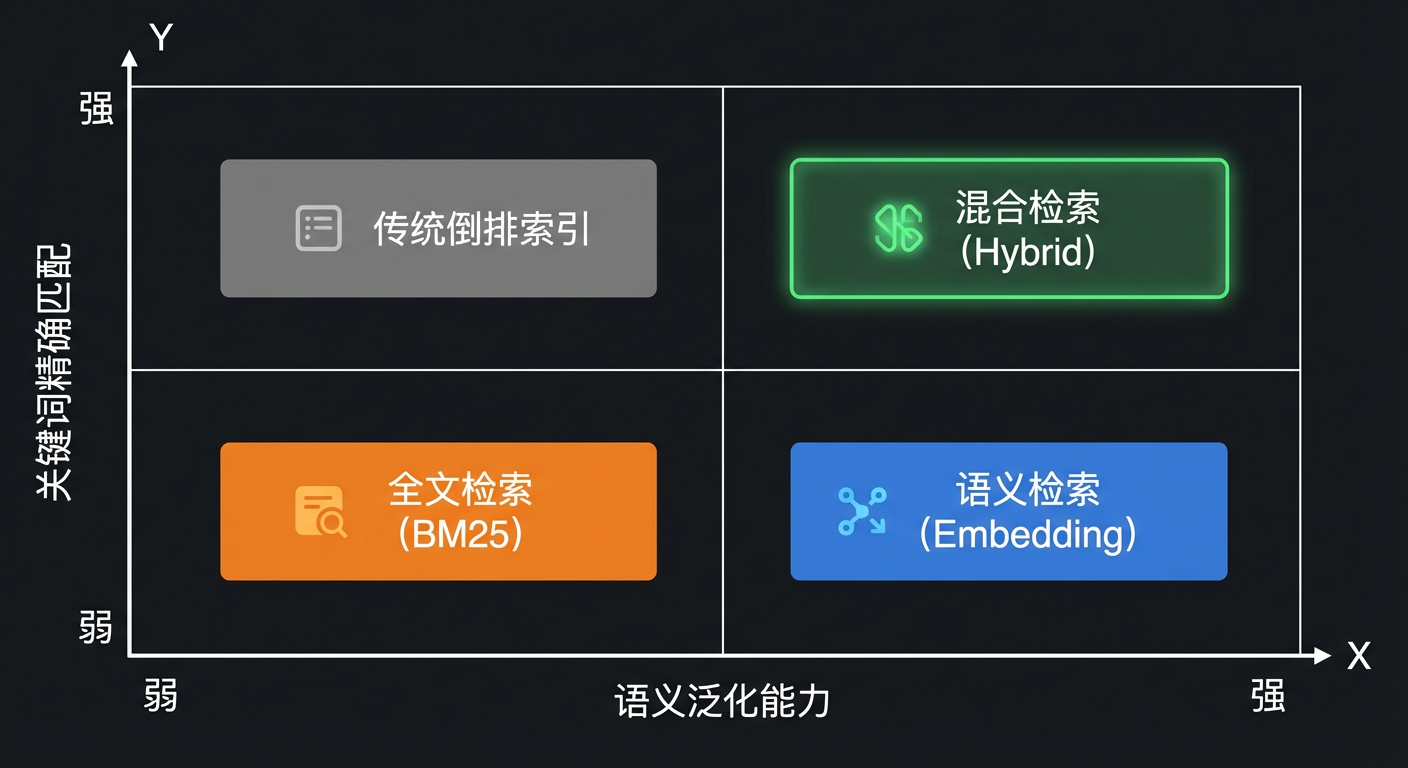
- 纯语义检索(密集向量):懂意思,不认字,遇到专业术语、精确词牌就犯难
- 纯关键词检索(稀疏向量):认字,不懂意思,近义词、同义词全是盲区
就像你找人帮忙,一个是"万事通但不识字",另一个是"认字超快但不懂你说什么"——两个人合作,才能把活干漂亮。
这就是混合检索(Hybrid Search) 要解决的事。
二、先搞清楚两种向量是啥
要理解混合检索,先得认识两个主角。

动图:稀疏向量只有少数位置有非零值,密集向量每个维度都有值——两种截然不同的表达方式
2.1 稀疏向量:认字的"词典派"
💡 一句话定义:稀疏向量(Sparse Vector)就像给每个词发一张工牌——每个词对应一个编号,文档里出现哪个词,就在对应位置记下权重,其余全是零。
想象一个包含 5 万个词的字典,每个词有一个编号。"秋风"排在第 14732 位,"故乡"在第 31433 位。一首诗里出现了这两个词,它的稀疏向量就只在这两个位置有值,其余 49998 个位置全是 0。
最经典的稀疏权重算法是 BM25(Best Matching 25),它的得分公式如下:
Score(Q,D)=∑i=1nIDF(qi)⋅f(qi,D)⋅(k1+1)f(qi,D)+k1⋅(1−b+b⋅∣D∣avgdl)Score(Q, D) = \sum_{i=1}^{n} IDF(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{avgdl})}Score(Q,D)=i=1∑nIDF(qi)⋅f(qi,D)+k1⋅(1−b+b⋅avgdl∣D∣)f(qi,D)⋅(k1+1)
公式看起来吓人,核心思想其实很朴素:一个词越稀有(IDF 高),且在文档中出现越多(词频高),得分就越高。k₁ 控制词频饱和度(同一个词反复出现,重要性增长不是无限的),b 控制文档长度归一化。
优点:无需训练,可解释,专业术语命中精准(“秋风"就是"秋风”,不会混淆)。
缺点:词汇鸿沟——"秋风"和"西风"在稀疏空间里是两个完全不相关的点,模型不知道它们都能代表萧瑟与离愁。
2.2 密集向量:懂意思的"语义派"
💡 一句话定义:密集向量(Dense Vector)是深度学习模型把文本"翻译"成的一串浮点数坐标,意思相近的文本,坐标在空间里也靠在一起。
这就是前几期讲过的 嵌入(Embedding) 技术。一首《静夜思》被编码成 1024 个浮点数,它在语义空间里的邻居可能包括《枫桥夜泊》、《长相思》——因为模型理解了它们共享"羁旅思乡"、"月夜孤寂"等核心语义。
举个对比:
// 稀疏表示:"秋风起兮白云飞"
// 只有"秋"、"风"、"白"、"云"等词的位置有值
{
"6": 0.0659, // 对应"秋"字
"7977": 0.1459, // 对应"风"字
"14732": 0.2959, // 对应"白"字
"31433": 0.1463 // 对应"云"字
}
// 密集表示:同一句话
// 1024 个维度全有值,每个维度没有直观含义,
// 但向量整体的"位置"代表了语义
[0.89, -0.12, 0.77, ..., -0.45] // 1024 维
优点:能理解语义,“西风”、“秋风”、"金风"在它看来都有相通之处。
缺点:可解释性差,对精确词汇的命中不如稀疏向量可靠;遇到生僻专有名词,模型可能一脸茫然。
2.3 两种向量对比一览
| 维度 | 稀疏向量(BM25 系) | 密集向量(Embedding 系) |
|---|---|---|
| 核心能力 | 关键词精确匹配 | 语义理解与泛化 |
| 向量维度 | 极高(词汇表大小,50K+) | 低(256~2048 维) |
| 非零元素 | 极少(0.01% 以下) | 全部有值 |
| 处理同义词 | ❌ 无法识别 | ✅ 天然支持 |
| 处理专业术语 | ✅ 精确命中 | ⚠️ 依赖训练数据 |
| 是否需要训练 | ❌ 不需要 | ✅ 需要预训练模型 |
三、混合检索:让两种向量协同作战
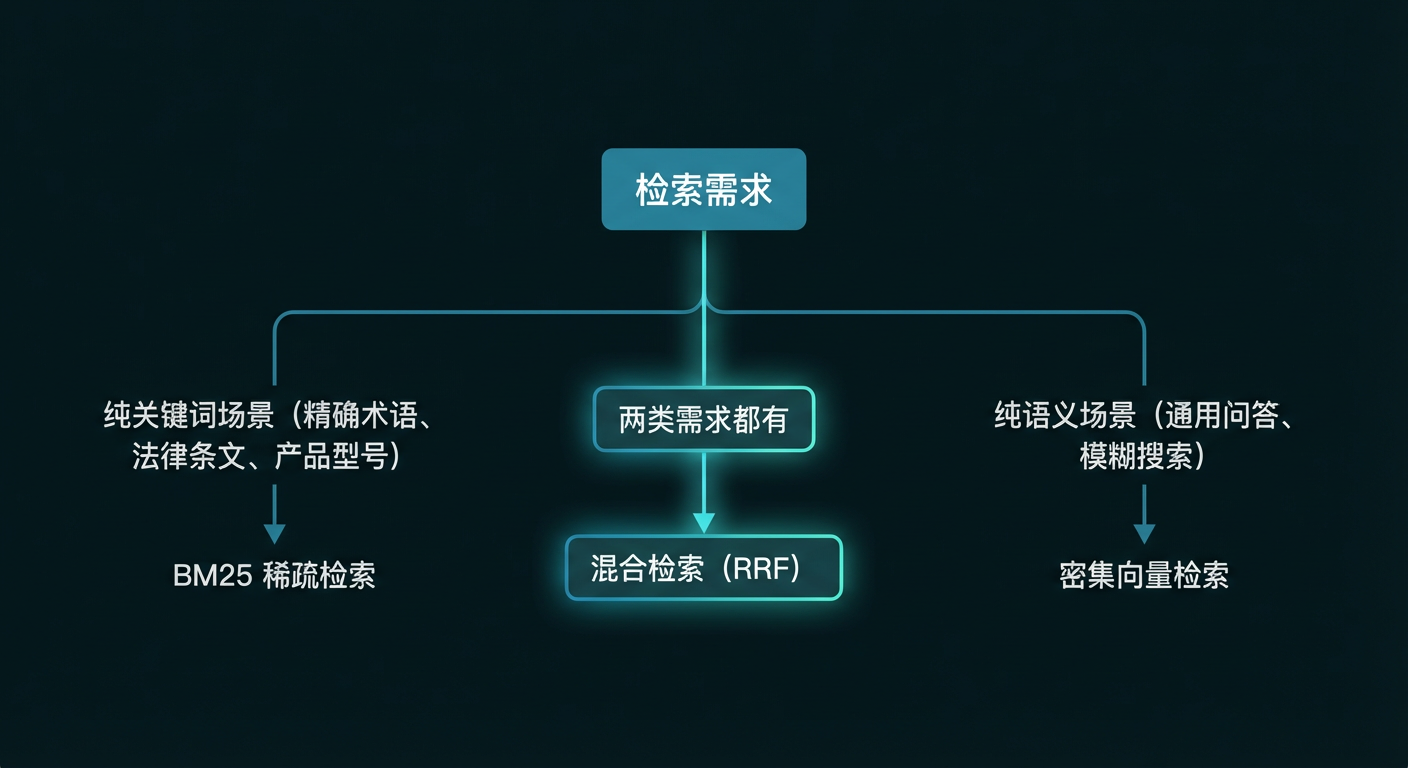
💡 一句话定义:混合检索(Hybrid Search)同时跑稀疏和密集两路检索,再用一个融合算法把两份结果合并成一个统一排序——取长补短,覆盖更广。

动图:稀疏和密集各出一份排名,RRF 按排名位次重新打分,融合成最终榜单
3.1 融合策略一:RRF(倒数排序融合)
RRF(Reciprocal Rank Fusion) 是目前最流行的融合方法,原理极简单:不看原始分数,只看排名。一个文档在多个检索系统里排名越靠前,最终分数就越高。
公式:
RRFscore(d)=∑i=1k1ranki(d)+cRRF_{score}(d) = \sum_{i=1}^{k} \frac{1}{rank_i(d) + c}RRFscore(d)=i=1∑kranki(d)+c1
rankᵢ(d):文档 d 在第 i 个检索系统中的排名c:平滑常数,通常取 60,防止排名第 1 的文档权重过于悬殊
为什么用排名而不用原始分数? 因为稀疏向量的分数(如 0.23)和密集向量的分数(如 0.72)根本不在一个量纲里,直接加起来没有意义,就像把摄氏度和华氏度直接相加一样荒谬。
3.2 融合策略二:加权线性组合
另一种方法是先把两路分数归一化到 [0, 1] 区间,再用权重 α 线性叠加:
Hybridscore=α⋅Densescore+(1−α)⋅SparsescoreHybrid_{score} = \alpha \cdot Dense_{score} + (1 - \alpha) \cdot Sparse_{score}Hybridscore=α⋅Densescore+(1−α)⋅Sparsescore
通过调整 α,可以灵活配置偏向语义还是偏向关键词。比如做法律文书检索时调高稀疏权重(法条词汇必须精确),做通用问答时调高密集权重。
3.3 混合检索的优势与局限
| 优势 | 局限 |
|---|---|
| 召回全面:同义词和精确词都能捞到 | 计算翻倍:需维护两套索引 |
| 灵活可调:融合策略适配不同业务场景 | 参数调优:α 或 k 值需要实验调整 |
| 容错性强:一路失败另一路兜底 | 可解释性弱:融合后排名理由难以直观分析 |
大多数场景直接用 RRF——不用调参数,效果稳定,是最好的起点。
四、代码实战:用 Milvus 搭一个诗词混合检索系统

动图:查询文本经 BGE-M3 生成双路向量,分别进入 Milvus 稀疏和密集索引,RRF 融合后输出最终排名
下面用 Milvus + BGE-M3 搭一个古诗词混合检索系统。BGE-M3 是目前少数能同时生成稀疏和密集向量的模型,一个模型搞定两件事,非常适合混合检索场景。
整体分三步:建库 → 写数据 → 混合搜索。
步骤一:定义 Collection 结构
这段代码做四件事:
- 连接 Milvus 服务,初始化 BGE-M3 嵌入模型
- 如果同名 Collection 已存在就先删掉(方便重复运行)
- 按 Schema 创建新 Collection,同时支持稀疏和密集两种向量字段
- 分别为两种向量字段创建索引
import json
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 国内镜像,加速模型下载
import numpy as np
from pymilvus import (
connections, MilvusClient, FieldSchema, CollectionSchema,
DataType, Collection, AnnSearchRequest, RRFRanker
)
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
# -----------------------------------------------
# 🔧 【按你的环境修改这里】
# -----------------------------------------------
# Collection 名称:随便起,不与已有的冲突即可
COLLECTION_NAME = "poetry_hybrid_demo"
# Milvus 地址:本地 Docker 默认这个;Zilliz Cloud 改成控制台 URI
MILVUS_URI = "http://localhost:19530"
# 数据文件路径:改成你自己的 JSON 数据路径
DATA_PATH = "../../data/C4/metadata/poetry.json"
# 批量插入大小:内存充足可以调大,默认 50 条
BATCH_SIZE = 50
# -----------------------------------------------
# === 步骤 1:连接 Milvus + 初始化嵌入模型 ===
print(f"--> 正在连接到 Milvus: {MILVUS_URI}")
connections.connect(uri=MILVUS_URI)
print("--> 正在初始化 BGE-M3 嵌入模型...")
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
# BGE-M3 的密集向量固定 1024 维,稀疏向量维度与词汇表大小相当(约 25 万维)
print(f"--> 嵌入模型初始化完成。密集向量维度: {ef.dim['dense']}")
# === 步骤 2:创建 Collection ===
milvus_client = MilvusClient(uri=MILVUS_URI)
if milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在删除已存在的 Collection '{COLLECTION_NAME}'...")
milvus_client.drop_collection(COLLECTION_NAME)
# 定义字段 Schema:7 个标量字段 + 2 个向量字段
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="poem_id", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=256), # 诗集出处
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256), # 诗词标题
FieldSchema(name="verse", dtype=DataType.VARCHAR, max_length=4096), # 诗词正文
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=64), # 题材分类
FieldSchema(name="dynasty", dtype=DataType.VARCHAR, max_length=64), # 朝代
FieldSchema(name="author", dtype=DataType.VARCHAR, max_length=128), # 作者
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR), # BM25 稀疏向量
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=ef.dim["dense"]) # 语义密集向量
]
if not milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在创建 Collection '{COLLECTION_NAME}'...")
schema = CollectionSchema(fields, description="古诗词混合检索演示")
collection = Collection(name=COLLECTION_NAME, schema=schema, consistency_level="Strong")
print("--> Collection 创建成功。")
# 为稀疏向量创建倒排索引(专为稀疏向量设计,IP = 内积,等价于点积相似度)
print("--> 正在为新集合创建索引...")
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
collection.create_index("sparse_vector", sparse_index)
print("稀疏向量索引创建成功。")
# 为密集向量创建 AUTOINDEX(Milvus 自动选择最优索引类型,省去手动调参)
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
collection.create_index("dense_vector", dense_index)
print("密集向量索引创建成功。")
collection = Collection(COLLECTION_NAME)
collection.load() # 把索引加载进内存,查询前必须执行
print(f"--> Collection '{COLLECTION_NAME}' 已加载到内存。")
运行输出:
--> 正在连接到 Milvus: http://localhost:19530
--> 正在初始化 BGE-M3 嵌入模型...
--> 嵌入模型初始化完成。密集向量维度: 1024
--> 正在创建 Collection 'poetry_hybrid_demo'...
--> Collection 创建成功。
--> 正在为新集合创建索引...
稀疏向量索引创建成功。
密集向量索引创建成功。
--> Collection 'poetry_hybrid_demo' 已加载到内存。
字段设计说明:
pk:主键,auto_id=True让 Milvus 自动生成,避免手动维护 ID 冲突verse:诗词正文,max_length=4096足够容纳大多数古诗词全文sparse_vector:SPARSE_FLOAT_VECTOR类型,专门存 BM25 风格的稀疏权重dense_vector:FLOAT_VECTOR类型,固定 1024 维,存语义嵌入
步骤二:加载数据并生成双路向量
这段代码做三件事:
- 从 JSON 文件读取诗词数据,把多个字段拼接成一段检索文本
- 用 BGE-M3 一次性生成稀疏和密集两种向量
- 批量插入到 Collection
if collection.is_empty: # 避免重复运行时反复插入数据
print(f"--> Collection 为空,开始插入数据...")
with open(DATA_PATH, 'r', encoding='utf-8') as f:
dataset = json.load(f)
# === 步骤 3:多字段拼接,生成检索文本 ===
docs, metadata = [], []
for item in dataset:
# 把标题、正文、朝代、作者拼在一起,让向量同时捕获多维度信息
parts = [
item.get('title', ''),
item.get('verse', ''),
item.get('dynasty', ''),
item.get('author', ''),
]
docs.append(' '.join(filter(None, parts))) # filter 去掉空字段
metadata.append(item)
# === 步骤 4:BGE-M3 双路向量生成 ===
print("--> 正在生成向量嵌入...")
embeddings = ef(docs) # 一次调用,同时输出稀疏和密集向量
sparse_vectors = embeddings["sparse"] # 稀疏向量:词频/BM25 权重
dense_vectors = embeddings["dense"] # 密集向量:语义嵌入
print("--> 向量生成完成。")
# === 步骤 5:批量插入数据 ===
# 按 Schema 字段顺序逐字段提取,顺序必须与 fields 定义严格对应
poem_ids = [doc["poem_id"] for doc in metadata]
sources = [doc["source"] for doc in metadata]
titles = [doc["title"] for doc in metadata]
verses = [doc["verse"] for doc in metadata]
categories = [doc["category"] for doc in metadata]
dynasties = [doc["dynasty"] for doc in metadata]
authors = [doc["author"] for doc in metadata]
collection.insert([
poem_ids, sources, titles, verses, categories, dynasties, authors,
sparse_vectors, dense_vectors # 7 个标量字段 + 2 个向量字段
])
collection.flush() # 强制刷盘,确保数据落库后立即可搜索
print(f"--> 数据插入完成,共 {len(docs)} 条。")
步骤三:三路对比搜索——感受混合检索的差异
最后用相同的查询对比三种检索策略,直观感受混合检索的价值:
# === 步骤 6:执行三路对比搜索 ===
search_query = "秋风起处念故人" # 故意混合了"秋风"关键词和"思念"语义
# 过滤器:只在这几类诗词里检索
search_filter = 'category in ["思乡", "送别", "写景"]'
top_k = 5
print(f"\n{'='*20} 开始混合搜索 {'='*20}")
print(f"查询: '{search_query}'")
print(f"过滤器: '{search_filter}'")
# 生成查询向量(同样用 BGE-M3,保持编码一致性)
query_embeddings = ef([search_query])
dense_vec = query_embeddings["dense"][0]
sparse_vec = query_embeddings["sparse"]._getrow(0) # 取第 0 行(单条查询)
打印向量信息,可以直观感受两种向量的差异:
=== 向量信息 ===
密集向量维度: 1024
密集向量前5个元素: [-0.0035305 0.02043397 -0.04192593 -0.03036701 -0.02098157]
密集向量范数: 1.0000
稀疏向量维度: 250002
稀疏向量非零元素数量: 6
稀疏向量前5个非零元素:
- 索引: 6, 值: 0.0659 # 对应"秋"
- 索引: 7977, 值: 0.1459 # 对应"风"
- 索引: 14732, 值: 0.2959 # 对应"起"
- 索引: 31433, 值: 0.1463 # 对应"念"
- 索引: 141121, 值: 0.1587 # 对应"故人"
稀疏向量密度: 0.00239998%
这就是"稀疏"的真实含义——25 万维的向量,只有 6 个非零值,其余都是 0。
search_params = {"metric_type": "IP", "params": {}}
# --- 路线一:单独的密集向量搜索(语义派)---
print("\n--- [单独] 密集向量搜索结果 ---")
dense_results = collection.search(
[dense_vec],
anns_field="dense_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "source", "verse", "category", "dynasty", "author"]
)[0]
for i, hit in enumerate(dense_results):
print(f"{i+1}. 《{hit.entity.get('title')}》·{hit.entity.get('author')} (Score: {hit.distance:.4f})")
print(f" 出处: {hit.entity.get('source')}")
print(f" 内容: {hit.entity.get('verse')[:50]}...")
# --- 路线二:单独的稀疏向量搜索(关键词派)---
print("\n--- [单独] 稀疏向量搜索结果 ---")
sparse_results = collection.search(
[sparse_vec],
anns_field="sparse_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "source", "verse", "category", "dynasty", "author"]
)[0]
for i, hit in enumerate(sparse_results):
print(f"{i+1}. 《{hit.entity.get('title')}》·{hit.entity.get('author')} (Score: {hit.distance:.4f})")
print(f" 出处: {hit.entity.get('source')}")
print(f" 内容: {hit.entity.get('verse')[:50]}...")
# --- 路线三:混合检索(RRF 融合)---
print("\n--- [混合] 稀疏+密集向量搜索结果 ---")
# RRFRanker 核心参数 k(默认 60):
# k 越大,排名靠前的文档权重越平均(结果更分散);
# k 越小,第一名的权重越突出(结果更集中)
rerank = RRFRanker(k=60)
# 分别构建两路搜索请求,最终由 hybrid_search 并行执行
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k)
# hybrid_search:并行跑两路,RRF 融合,返回统一排序结果
results = collection.hybrid_search(
[sparse_req, dense_req],
rerank=rerank,
limit=top_k,
output_fields=["title", "source", "verse", "category", "dynasty", "author"]
)[0]
for i, hit in enumerate(results):
print(f"{i+1}. 《{hit.entity.get('title')}》·{hit.entity.get('author')} (Score: {hit.distance:.4f})")
print(f" 出处: {hit.entity.get('source')}")
print(f" 内容: {hit.entity.get('verse')[:50]}...")
最终输出对比:
--- [单独] 密集向量搜索结果 ---
1. 《静夜思》·李白 (Score: 0.7219)
出处: 《全唐诗》卷一六一
内容: 床前明月光,疑是地上霜。举头望明月,低头思故乡。...
2. 《枫桥夜泊》·张继 (Score: 0.5131)
出处: 《全唐诗》卷二四二
内容: 月落乌啼霜满天,江枫渔火对愁眠。姑苏城外寒山寺,夜半钟声到客船。...
3. 《长相思》·纳兰性德 (Score: 0.5119)
出处: 《饮水词》
内容: 山一程,水一程,身向榆关那畔行,夜深千帐灯。...
--- [单独] 稀疏向量搜索结果 ---
1. 《秋风辞》·刘彻 (Score: 0.2319)
出处: 《汉书》卷六
内容: 秋风起兮白云飞,草木黄落兮雁南归。兰有秀兮菊有芳,怀佳人兮不能忘。...
2. 《天净沙·秋思》·马致远 (Score: 0.0923)
出处: 《全元散曲》
内容: 枯藤老树昏鸦,小桥流水人家,古道西风瘦马。夕阳西下,断肠人在天涯。...
3. 《秋夕》·杜牧 (Score: 0.0691)
出处: 《全唐诗》卷五二四
内容: 银烛秋光冷画屏,轻罗小扇扑流萤。天阶夜色凉如水,卧看牵牛织女星。...
--- [混合] 稀疏+密集向量搜索结果 ---
1. 《静夜思》·李白 (Score: 0.0328)
出处: 《全唐诗》卷一六一
内容: 床前明月光,疑是地上霜。举头望明月,低头思故乡。...
2. 《秋风辞》·刘彻 (Score: 0.0320)
出处: 《汉书》卷六
内容: 秋风起兮白云飞,草木黄落兮雁南归。兰有秀兮菊有芳,怀佳人兮不能忘。...
3. 《天净沙·秋思》·马致远 (Score: 0.0318)
出处: 《全元散曲》
内容: 枯藤老树昏鸦,小桥流水人家,古道西风瘦马。夕阳西下,断肠人在天涯。...
4. 《枫桥夜泊》·张继 (Score: 0.0313)
出处: 《全唐诗》卷二四二
内容: 月落乌啼霜满天,江枫渔火对愁眠。姑苏城外寒山寺,夜半钟声到客船。...
5. 《长相思》·纳兰性德 (Score: 0.0310)
出处: 《饮水词》
内容: 山一程,水一程,身向榆关那畔行,夜深千帐灯。...
对比三个结果,规律很清晰:
- 密集向量:认出了"念故人"的思乡语义,搜出《静夜思》、《长相思》,但完全忽略了"秋风"这个关键词
- 稀疏向量:紧抓"秋风"词形,找到《秋风辞》,但理解不了"念故人"的语义内涵
- 混合检索:两者都顾到了,TOP 5 里既有语义相关的《静夜思》,也有关键词命中的《秋风辞》,覆盖更全面
这就是混合检索的核心价值:不是谁更强,而是两种视角同时起作用,减少盲区。
五、总结:何时该上混合检索?
三句话收尾:
- ✅ 是什么:混合检索 = 稀疏向量(精确匹配)+ 密集向量(语义理解)+ RRF 融合,三者缺一不可
- ✅ 为什么用:任何单一检索方案都有盲区,混合检索把召回率和准确率同时拉高,尤其适合搜索词多变的真实场景
- ✅ 怎么做:Milvus + BGE-M3 五步跑通——建 Collection → 定 Schema(含双向量字段)→ 批量写数据 → 建双路索引 →
hybrid_search+RRFRanker
现在就可以做的三件事
- 跑通环境:
pip install pymilvus pymilvus[model]+ 启动本地 Docker Milvus(10 分钟) - 替换你的数据:把
DATA_PATH指向你自己的 JSON 文件,字段对应上就能跑 - 感受差距:把同一个查询分别跑一遍纯稀疏、纯密集、混合,对比 TOP 5 结果,差异一目了然
进阶路线
| 阶段 | 方向 | 要掌握的 |
|---|---|---|
| 入门 | 跑通混合检索 | BGE-M3 双路向量、Milvus hybrid_search、RRFRanker |
| 进阶 | 加入重排序 | Cross-Encoder Reranker,对 TOP-K 结果二次精排 |
| 高级 | 多路融合 | 图检索 + 混合检索,多模态信息融合 |
下一期,我们聊聊 Reranker(重排序)——混合检索把候选集召回来了,但排第一的不一定真的最好,Reranker 就是那个"最终裁判员",能把结果质量再提升一档。
觉得有用的话,点个在看,让更多人搜得更准 🙏
关注「阿杰Agent开发日志」,和我一起把 RAG 搞明白。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)