PersonaVLM: Long-Term Personalized Multimodal LLMs
论文:个性化大模型
摘要
多模态大语言模型(MLLM)已成为数百万用户的日常助手。但这类模型贴合用户个人偏好的生成能力仍然有限。
现有方案大多只能依靠输入增强、输出对齐,实现静态、单轮的个性化,无法捕捉用户随时间不断变化的偏好与人格特质(见图1)。
本文提出 PersonaVLM,一套面向长期个性化的全新多模态智能体框架。
该框架通过三大核心能力,将通用多模态大模型改造为专属个性化助手:
- 记忆留存:从历史交互中主动抽取、归纳时序化多模态记忆,沉淀构建个人专属记忆库;
- 记忆推理:多轮对话中检索并融合相关记忆,完成个性化逻辑推理;
- 输出对齐:在长期交互中动态推断用户变化的人格特征,让模型回复始终贴合用户个性化特点。
为开展评测,本文构建了 Persona-MME 综合评测基准,包含2000+条人工筛选的交互样本,从七大维度、14项细粒度任务,全面衡量多模态大模型的长期个性化能力。
大量实验验证了该方案的有效性:
在 128k 上下文条件下,相比基线模型,Persona-MME 指标提升 22.4%,PERSONAMEM 指标提升 9.8%;
同时两项指标分别超越 GPT-4o 5.2%、2.0%。
项目主页:https://PersonaVLM.github.io
1. 引言
多模态大语言模型(MLLM)正深度融入亿万用户的日常生活,扮演智能助手、创意协作伙伴与情感陪伴角色。随着普及度提升,用户需求不再局限于通用问题解答,转而追求具备个性化、共情能力的长期交互体验。由此引出一个核心问题:
如何让通用多模态大模型进化为真正的个性化助手——精准理解用户意图、贴合个人偏好与性格动态调整输出行为,并长期记忆用户专属的多模态信息?
解决该问题不仅能提升用户满意度与信任感,还能释放多模态大模型在推荐、医疗、教育等领域的落地价值。
即便是当前顶尖的闭源大模型,在贴合用户独特偏好、适配个性化特质方面依旧存在明显短板。
瓶颈主要来自两点:
- 模型层面:现有模型大多基于固定上下文窗口、「一刀切」的通用范式做优化;
- 用户层面:每个人的偏好与性格具备多样性、动态性,会在持续交互中不断变化。
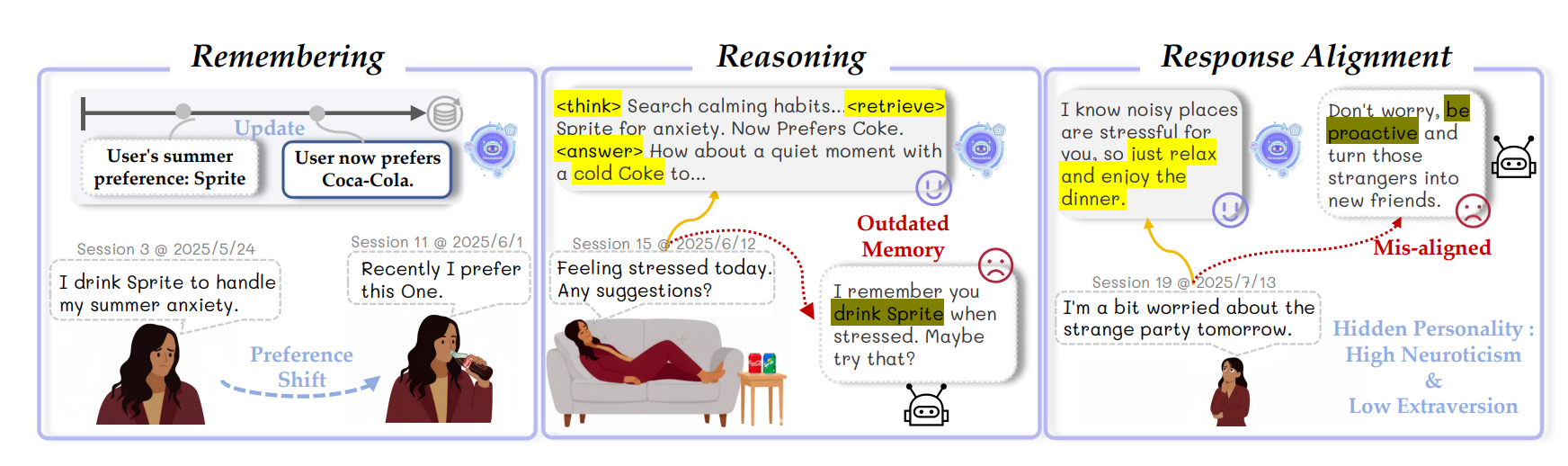 图1:PersonaVLM 在长期个性化方面的三大核心能力示意图。与现有的输入增强和输出对齐等个性化策略不同——这些策略会因过时的记忆而导致推荐效果差,并且回复与用户个性不匹配——PersonaVLM 能够主动记忆用户偏好的变化,执行结合检索的多轮推理,并生成与用户个性相符的回复。
图1:PersonaVLM 在长期个性化方面的三大核心能力示意图。与现有的输入增强和输出对齐等个性化策略不同——这些策略会因过时的记忆而导致推荐效果差,并且回复与用户个性不匹配——PersonaVLM 能够主动记忆用户偏好的变化,执行结合检索的多轮推理,并生成与用户个性相符的回复。
文中举例:用户起初喜欢雪碧,后续为缓解焦虑转而选择可乐;当用户再次表达压力时,传统检索增强模型无法捕捉这种偏好变化,导致推荐错位。
同时,通用化的输出风格往往过于外向,无法适配内向、高敏感人格——这类性格特征往往分散隐藏在大量碎片化对话中,很难被现有模型感知。
这类问题的本质:当前个性化方案全部基于静态交互设计。
- 以输入增强为代表的模型(Yo’LLaVA、RAP)只能识别用户专属概念,但缺少记忆管理与更新机制,无法捕捉偏好切换;
- 以对齐优化为代表的方法(ALIGNXPERT、PAS)默认用户性格永久不变,难以适配长期对话中逐步显露的内向等隐性特质。
因此,长期个性化必须依托两大核心基础:
- 个性化记忆架构:主动构建并维护以用户为中心、可动态迭代的多模态专属记忆库;
- 记忆利用与输出对齐:高效调用记忆库,结合推理与检索,生成贴合用户当下特质与动态变化的回复。
基于以上两大基础,本文提出 PersonaVLM,面向长期个性化交互的多模态智能体框架。
- 设计全新记忆架构:包含用户人格档案 + 四类分层记忆(核心属性记忆、语义事实记忆、行为习惯记忆、事件情景记忆),系统化存储管理用户信息;
- 双阶段协同工作流,将通用大模型改造为个性化助手:
- 回复阶段:结合多模态输入与上下文,完成多步推理+记忆检索,输出贴合用户性格的内容;
- 更新阶段:通过动量式人格演化机制(PEM),持续推断并更新用户大五人格分数等隐性特质;同时自动提炼对话关键信息,同步更新四类记忆,服务后续交互。
除此之外,针对个性化多模态训练数据稀缺的问题,本文构建数据合成流水线,生成大规模数据集:包含500种不同人设、超3万条多模态交互样本。
数据集可本地离线使用,兼顾模型训练效果与用户数据隐私安全。
同时,针对现有评测基准偏静态、纯文本的缺陷,自建 Persona-MME 评测集,专门衡量大模型长期、多维度、多模态的个性化能力。
本文核心贡献四点:
- 提出 PersonaVLM 智能体框架,通过主动记忆、多步推理、人格对齐三大核心能力,实现多模态大模型的长期个性化;
- 创新个性化记忆体系:结合动态人格演化机制 PEM,以及核心/语义/习惯/情景 多类型分层记忆库;
- 构建 Persona-MME 综合评测基准,全面测评大模型长期个性化能力,并对十余款主流开源/闭源模型完成横向对比;
- 大规模实验验证效果:在128k长上下文条件下,PersonaVLM 在 Persona-MME 提升22.4%、在 PERSONAMEM 提升9.8%,综合指标与开放场景表现超越 GPT-4o。
2. 相关工作
大语言模型(LLM)的飞速发展,催生了 GPT-4o、LLaVA、通义千问系列等高性能多模态大模型,这类模型在各类通用任务中表现优异。但想要进化为真正的个人助手,模型必须摆脱一刀切的通用范式,针对不同用户的知识背景、个人偏好定制化生成回复。
现有个性化研究主要分为三大方向:基于适配、基于增强、基于对齐。
1. 基于适配的个性化(Adaptation-based)
该类方法在模型层面实现个性化:通过微调,将用户专属信息直接编码进可训练参数中。
诸多研究采用参数高效微调(PEFT),让大模型适配个人/特定群体需求。
这一思路同样延伸至多模态领域:
- MyVLM 引入可学习嵌入向量;
- Yo’LLaVA 借助软提示;
二者均可建模用户专属视觉特征,让模型从识别“通用的狗”,升级为识别“用户自家的宠物狗”。
缺点:
每新增用户/新偏好都要单独微调,扩展性差;且完全无法适配用户偏好随时间变化的场景。
2. 基于增强的个性化(Augmentation-based)
不同于模型微调,该方案在输入层面优化:外接独立记忆数据库,存储、检索用户历史记忆,突破固定上下文窗口限制,适配长期连续对话。
已有工作将该方案拓展到多模态:先通过开放词汇目标检测器,从图像中裁剪关键视觉特征,再完成记忆匹配与检索。
优点:
无需额外训练,推理阶段即可直接新增用户个性化内容,灵活度高。
缺点:
- 依赖人工预设知识库,缺少动态交互下的记忆主动管理、更新机制;
- 现有通用记忆框架(A-Mem、Memory OS)以纯文本为主,无法适配多模态输入;
- 多数依赖闭源模型,不利于开源研究,且存在数据隐私风险。
3. 基于对齐的个性化(Alignment-based)
传统大模型对齐(如 RLHF 人类反馈强化学习)只追求统一、通用的输出规范,无法兼容差异化的用户偏好与沟通风格。
例如:过度热情的通用回复,对焦虑、内向用户反而不合适。
个性化对齐则优化目标:从「全局统一标准」改为「用户专属标准」:
- 通过 DPO 直接偏好优化,结合用户特征约束输出风格;
- PAS 为每个用户训练专属探测模块,推理时引导个性化生成。
缺点:
需要按用户单独训练,落地成本高、难以规模化;
且用户人格、偏好是动态变化的,这类静态对齐模块会逐渐失效。
–
本章收尾
现有研究只解决了碎片化的个性化问题:要么是静态记忆、要么是固定风格对齐,无法兼顾动态演化与长期交互。
本文提出的 PersonaVLM 是首个统一智能体框架,专门解决多模态场景下动态、长期的个性化交互难题。
3. Methods
3.1. PersonaVLM 框架
PersonaVLM 智能体的整体架构如图 2 所示。它基于个性化记忆架构构建,并通过回复与更新两个协同阶段实现长期个性化。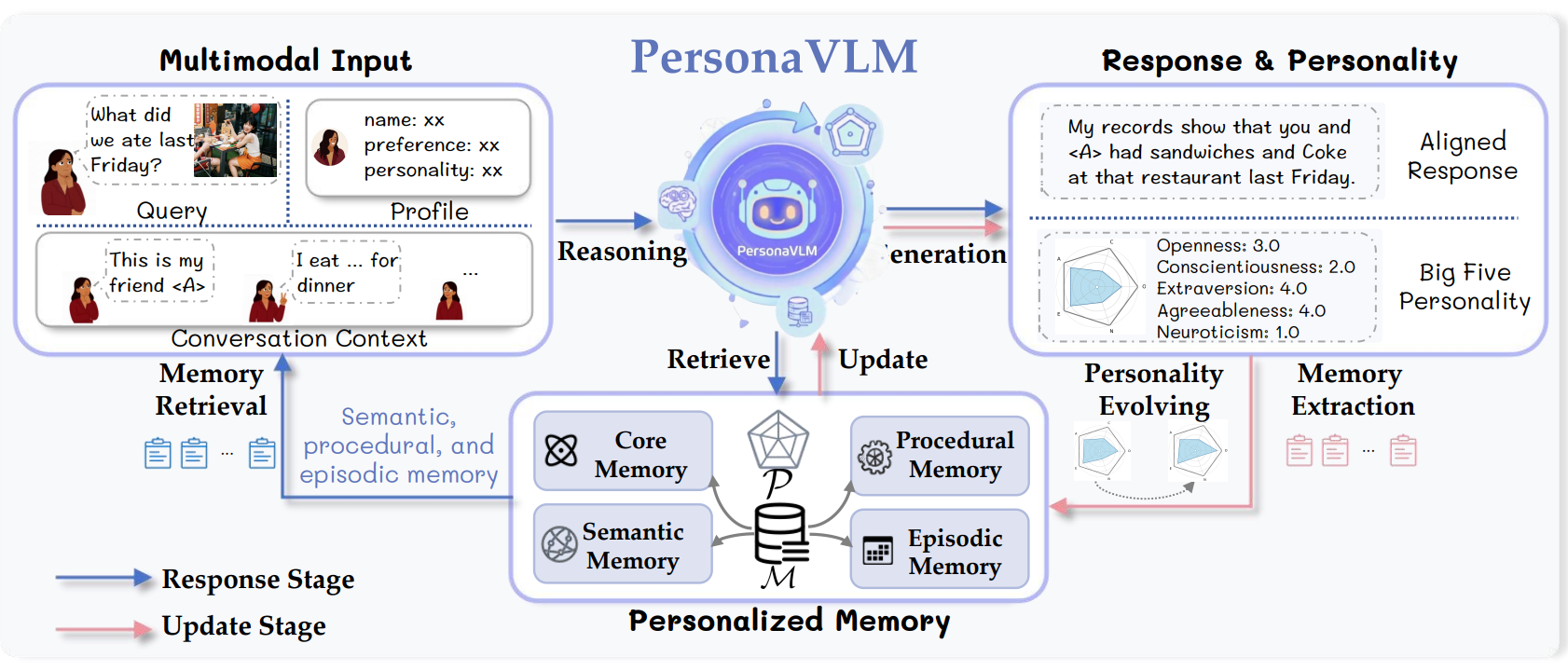
图2:PersonaVLM框架概览。该框架利用个性化记忆架构,通过两个协同阶段实现长期个性化。在响应阶段(蓝色箭头),框架处理多模态输入,从个性化记忆中检索信息,并生成与个性特征对齐的响应。随后,在更新阶段(粉色箭头),框架分析完整的交互记录,提取关键记忆,并更新用户不断演变的个性档案¹。
个性化记忆架构
该架构旨在构建和维护全面、长期的用户档案,存储两大类核心信息:
- 用户人格档案(P):以大五人格维度(开放性、尽责性、外向性、宜人性、神经质)的分数向量,对用户性格进行量化表示。
- 多类型记忆库(M):存储广泛的用户相关知识。这是一个基于时间线的智能体系统,支持灵活的增删改查(CRUD)操作,包含四种不同类型的记忆:
- 核心记忆(Core Memory):存储用户的基础属性(如个人信息、人设模块),灵感来源于 MemGPT,并会动态更新以反映最新的用户画像。
- 语义记忆(Semantic Memory):通过提取关键实体、关系和多模态概念,沉淀与具体事件无关的抽象知识。
- 情景记忆(Episodic Memory):将原始对话组织为带时间戳的原子事件,每个事件包含摘要、对话轮次和关键词,以支持高效检索。
- 过程记忆(Procedural Memory):记录以用户为中心的计划、目标以及重复的行为或习惯。
在存储方式上,情景记忆和语义记忆按时间顺序存储,而核心记忆、过程记忆和人格档案则仅保留最新版本,以确保信息的相关性。我们的设计克服了现有系统的局限性,使记忆架构具备以下特点:(a) 自包含,不依赖闭源模型;(b) 明确的个性化,优先处理以用户为中心的知识;© 支持多模态,实现对用户更全面的理解。记忆架构的更多细节见附录 A。
回复阶段
此阶段的目标是通过多步推理和基于时间线的检索,生成对齐的回复。在第 m m m 轮交互中,过程可以形式化为:
R m = R ( Q m , C m , M m − 1 ) R_m = R(Q_m, C_m, M_{m-1}) Rm=R(Qm,Cm,Mm−1)
其中, R m R_m Rm 是个性化回复。该回复依赖于三个输入:
- 当前用户查询 Q m = ( T m , I m , t m ) Q_m = (T_m, I_m, t_m) Qm=(Tm,Im,tm),由文本指令 T m T_m Tm、可选图像 I m I_m Im 和时间戳 t m t_m tm 组成;
- 对话上下文 C m = { ( Q i , R i ) ∣ 0 < i < m and ∣ t i − t m ∣ ≤ t s } C_m = \{(Q_i, R_i) \mid 0 < i < m \text{ and } |t_i - t_m| \le t_s\} Cm={(Qi,Ri)∣0<i<m and ∣ti−tm∣≤ts};
- 上一轮迭代后的个性化记忆库状态 M m − 1 M_{m-1} Mm−1。
如正文所述,该过程是 PersonaVLM 智能体与其记忆系统之间的多步交互。模型首先接收用户指令、上下文和整合档案(核心记忆+人格特征),输出推理过程和行动结果。若判定信息不足,则输出包含时间范围和关键词的检索条件,执行多轮检索与推理,直至生成最终回复 R m R_m Rm。
更新阶段
该阶段在回复生成后的空闲期自动执行,主要包括两部分:演化用户人格档案和主动更新记忆。在第 m m m 轮交互中,过程可表示为:
( P m , M m ) = U ( Q m , R m , M m − 1 ) (P_m, M_m) = U(Q_m, R_m, M_{m-1}) (Pm,Mm)=U(Qm,Rm,Mm−1)
-
人格档案更新(PEM):我们提出的**人格演化机制(PEM)**维护一个长期人格向量 p ∈ R 5 p \in \mathbb{R}^5 p∈R5,对应大五人格维度。在第 m m m 轮,PEM 首先根据用户最新查询 Q m Q_m Qm 推断临时人格分数,归一化得到本轮人格向量 p m ′ p'_m pm′。随后,使用指数移动平均(EMA)更新长期人格:
p m ← λ ⋅ p m − 1 + ( 1 − λ ) ⋅ p m ′ p_m \leftarrow \lambda \cdot p_{m-1} + (1-\lambda) \cdot p'_m pm←λ⋅pm−1+(1−λ)⋅pm′
其中 λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1] 是动态平滑因子,采用余弦衰减策略,实现初期快速适配、后期稳定收敛。最终将数值向量 p m p_m pm 转换为文本描述 P m P_m Pm,供回复阶段使用。 -
记忆更新:针对四类记忆采用差异化更新策略:
- 语义记忆:每轮对话后更新,提取用户偏好、多模态概念和关键请求;
- 核心与过程记忆:会话结束后批量更新,分析整个会话并执行增删改查;
- 情景记忆:按话题分段,结构化存储摘要、关键词和对话片段。
完整实现流程见附录 B.1。
3.2. PersonaVLM 训练流程
我们以 Qwen2.5-VL-7B 作为主干模型,采用两阶段训练流程。
阶段1:有监督微调(SFT)
在包含 78k 样本的高质量合成数据集上进行 SFT,使模型掌握基础的记忆管理和多轮推理能力。数据包含两类:(a) 记忆机制示例(人格推理、四类记忆的增删改查);(b) 包含完整多步推理轨迹的问答对。SFT 为后续阶段提供了良好的冷启动初始化。
阶段2:强化学习(RL)
采用改进的 PPO 算法——**分组相对策略优化(GRPO)**训练策略模型 π θ \pi_\theta πθ。训练时强制模型输出严格的结构化格式:推理过程用 包裹,后续输出 `<retrieve></retrieve>` 或。
对于训练样本 { Q , R b } \{Q, R_b\} {Q,Rb},其中 Q Q Q 为用户输入, R b R_b Rb 为偏好回复,从策略模型中采样一组多轮轨迹 { τ 1 , … , τ G } \{\tau_1, \dots, \tau_G\} {τ1,…,τG}。第 i i i 条轨迹 τ i \tau_i τi 的奖励 r i r_i ri 计算如下:
r i = f a c c ( R b , R τ i ) ⋅ f c o n s ( Q , R τ i ) + 0.5 ⋅ f f o r m a t ( R τ i ) r_i = f_{acc}(R_b, R_{\tau_i}) \cdot f_{cons}(Q, R_{\tau_i}) + 0.5 \cdot f_{format}(R_{\tau_i}) ri=facc(Rb,Rτi)⋅fcons(Q,Rτi)+0.5⋅fformat(Rτi)
其中, f a c c f_{acc} facc、 f c o n s f_{cons} fcons 和 f f o r m a t f_{format} fformat 分别为准确率、推理逻辑一致性和格式合规性的奖励函数。我们使用 Qwen3-30B-A3B 作为 LLM-as-a-Judge,通过零样本提示计算 f a c c f_{acc} facc 和 f c o n s f_{cons} fcons。训练中,单条轨迹的最大检索次数限制为 3 次,且损失仅在生成的 token 上计算。
训练数据和实现的更多细节见附录 B.2。
4 数据集与 Persona-MME 评测集构建
为实现并评估长期动态个性化能力,本文完成两项核心工作:
第一,针对高质量个性化训练数据稀缺的问题,搭建专用数据合成流水线,构建大规模多模态交互数据集;
第二,自研 Persona-MME 综合评测基准,用于多模态场景下的个性化能力测评。
现有主流数据集普遍存在场景局限:大多为静态单轮交互,或不支持多模态输入,无法满足长期个性化研究需求,因此亟需本次双维度的数据与评测体系建设。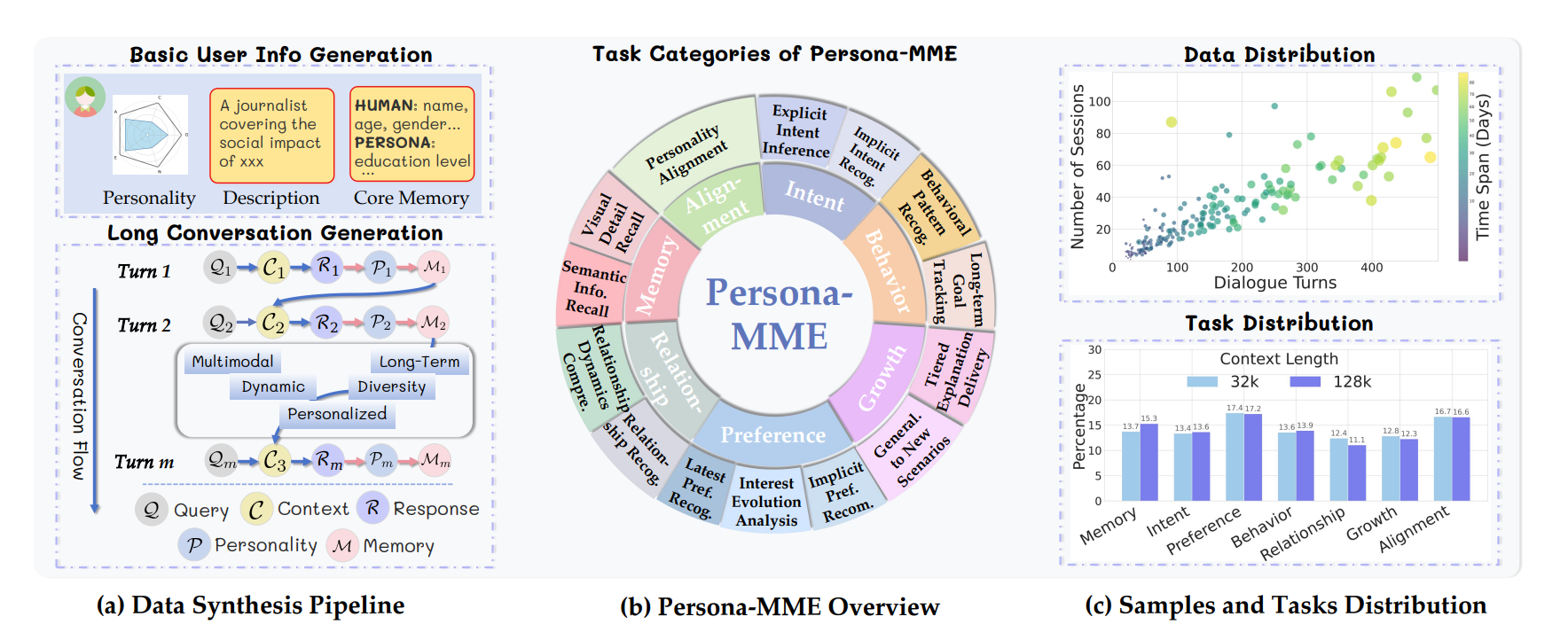
数据集合成流水线
如图 3(a) 所示,本文设计可规模化生成训练数据的自动化合成流程:
首先从 PersonaHub 中抽取基础人设,随机搭配差异化人格特征,扩充生成完整角色描述与初始用户档案,以此初始化核心记忆。
依托 Seed1.6-thinking 模型,按照标准化流程引导生成多轮对话,整体生成严格遵循三大原则:
- 长期动态性
对话扩展至数百轮,模拟数周乃至数月的真实交互;通过概率化机制,主动诱导用户偏好、聊天话题、人格特质发生动态变化,复刻真实用户的长期演化特征。 - 多模态与场景多样性
超 15 % 15\% 15% 的对话包含图文多模态内容;交互场景覆盖办公业务、日常闲聊等各类现实场景,适配复杂落地环境。 - 结构化监督信号
数据生成不仅输出原始对话内容,同时同步产出中间推理过程、记忆检索行为、信息存储操作等结构化步骤,为 PersonaVLM 全流程训练提供充足、精细的监督信号。
数据集分布与质量校验细节详见附录 C。
Persona-MME:多模态大模型长期个性化评测
现有评测基准仅能覆盖个性化的单一碎片化维度:
PERSONAMEM 侧重考核模型追踪用户档案动态变化的能力;
ALIGNX-test 围绕静态人格对齐设计;
Yo’LLaVA 等评测集仅聚焦用户专属视觉概念理解。
目前尚无一套体系,能够完整覆盖动态个性化的全部核心评估维度。
为弥补该空白,本文构建 Persona-MME 综合评测基准:
包含 200 类差异化人设、超 2000 个真实场景测试样本。
如图 3(b) 所示,评测体系分为七大核心维度:记忆能力、意图理解、偏好识别、行为匹配、关系感知、成长适配、人格对齐;
七大维度进一步拆解为 14 项细粒度任务,具体划分见附录表 5。
为适配不同长度上下文环境,设置两套评测配置:
- 32 k 32\text{k} 32k 上下文版本:适配 100 轮以内短对话;
- 128 k 128\text{k} 128k 上下文版本:适配超长时序交互;
两套配置均各包含 100 类独立人设样本。
单条测试用例由两部分组成:
- 选择题题型:考核模型的个性化记忆留存与用户需求理解能力;
- 可选人格测试项:量化评估模型输出与用户特质的对齐程度。
多维度、多层次的设计,让 Persona-MME 可全面衡量多模态大模型在不同人设下的长期个性化综合性能。
评测集指标统计与详细规则见附录 D。
5 实验分析
本章通过一系列定量实验与定性实验,全面验证 PersonaVLM 框架的综合效果。
正文实验围绕以下三大研究问题(RQ)展开:
- RQ1:PersonaVLM 在用户个性化理解、记忆回溯任务上的表现如何?
- RQ2:PersonaVLM 能否持续捕捉用户不断变化的人格特征,实现稳定的人格对齐?
- RQ3:PersonaVLM 在个性化开放式文本生成场景中的综合表现如何?
Persona-MME 完整评测结果、记忆模块消融实验、拓展讨论内容,分别详见附录 D、附录 E、附录 F。
5.1 个性化理解能力评测
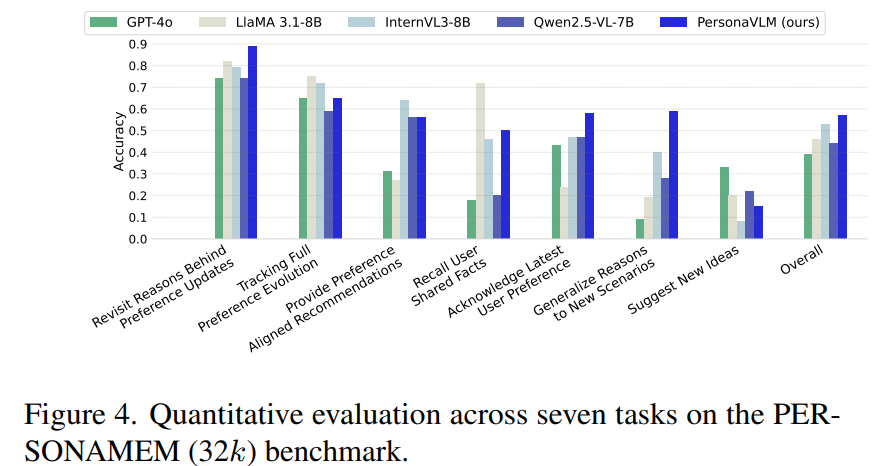
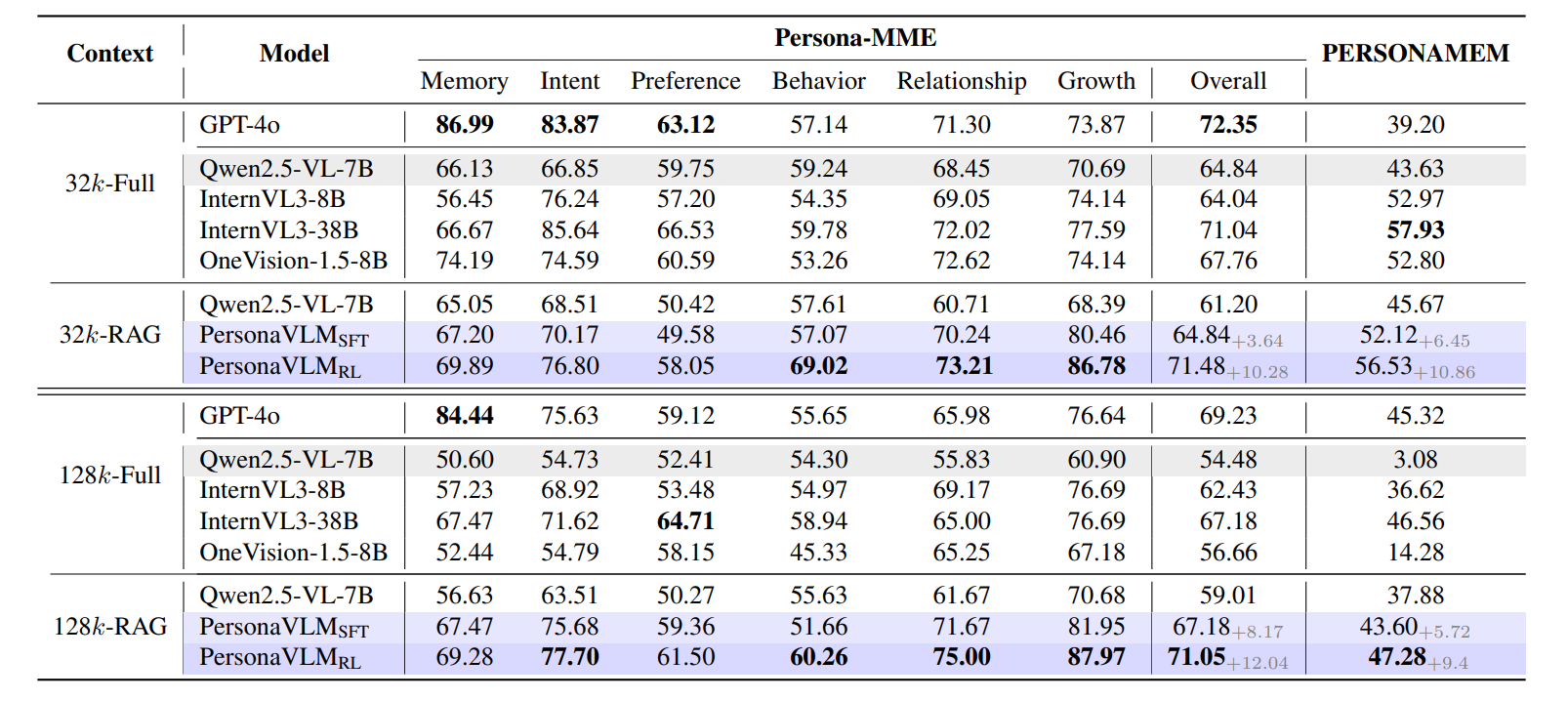 表1:在Persona-MME和PERSONAMEM基准上的评估结果,测试上下文长度为32k和128k。我们报告了Persona-MME(总体及六个方面)和PERSONAMEM的准确率(%)。比较包括两种设置:全上下文(“Full”)和检索增强生成(“RAG”)。最佳结果以粗体显示。PERSONAMEM上的GPT-4o结果来自文献[14]。
表1:在Persona-MME和PERSONAMEM基准上的评估结果,测试上下文长度为32k和128k。我们报告了Persona-MME(总体及六个方面)和PERSONAMEM的准确率(%)。比较包括两种设置:全上下文(“Full”)和检索增强生成(“RAG”)。最佳结果以粗体显示。PERSONAMEM上的GPT-4o结果来自文献[14]。
针对研究问题 RQ1,本文基于两大评测集开展实验:自研评测集 Persona-MME 与公开评测集 PERSONAMEM。
其中 PERSONAMEM 包含 7 类任务,专门用于考核模型长期动态偏好追踪能力。
实验统一设置两种长上下文环境: 32 k 32\text{k} 32k 与 128 k 128\text{k} 128k 上下文长度,详细实验数据如表 1、图 4 所示。
对比基线模型涵盖主流闭源与开源方案:闭源模型选用 GPT-4o;开源模型包含 Qwen2.5-VL-7B、LLaVA-OneVision-1.5-8B、InternVL3-8B/38B。
更多主流模型横向对比结果见附录图 10。
在同等参数量级下,以完整上下文输入的 InternVL3-8B、LLaVA-OneVision-1.5-8B 为对比基线:
在 128 k 128\text{k} 128k 配置下,PersonaVLM 在 Persona-MME 上分别提升 8.62 % 8.62\% 8.62%、 14.39 % 14.39\% 14.39%。
即便对比体量更大的 InternVL3-38B,PersonaVLM 在 128 k 128\text{k} 128k 条件下仍高出 3.87 % 3.87\% 3.87%。
本文同时对原生 Qwen2.5-VL-7B 接入基础 RAG 检索方案进行对照实验(参考现有工作,每次召回 Top-5 历史对话)。
实验发现:RAG 效果与上下文长度强相关
- 短上下文场景:RAG 存在负向干扰,偏好理解任务性能下降最高达 9.33 % 9.33\% 9.33%;
- 长上下文场景:RAG 带来明显增益,指标提升 4.53 % 4.53\% 4.53%。
除此之外,表 1 结果证明:双阶段训练策略效果显著,在 Persona-MME 上平均提升 5.35 % 5.35\% 5.35%。
与闭源模型 GPT-4o 相比:
PersonaVLM 在 Persona-MME 上具备竞争力;
在 PERSONAMEM 任务中, 32 k 32\text{k} 32k 配置提升 17.3 % 17.3\% 17.3%、 128 k 128\text{k} 128k 配置提升 2.0 % 2.0\% 2.0%。
虽然在纯记忆回溯场景中,完整上下文下的 GPT-4o 表现更优(与过往研究结论一致),但 PersonaVLM 在其余维度优势显著,尤其成长建模、行为感知两大任务,超出 GPT-4o 10% 以上。
5.2 个性化人格对齐评测
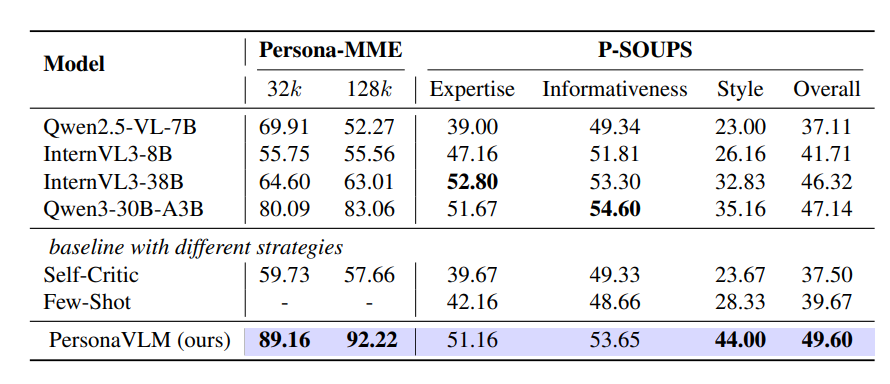 表2:在Persona-MME和P-SOUPS基准上的个性化对齐评估结果。
表2:在Persona-MME和P-SOUPS基准上的个性化对齐评估结果。
针对研究问题 RQ2,选取两项权威评测基准:
- Persona-MME 内置人格对齐子任务,共 812 条测试样本;
- P-SOUPS 评测集,共 1800 条测试样本。
前者考核模型能否结合对话上下文,判断回复与用户人格的匹配度;
后者从专业度、信息丰富度、语言风格三大维度,评估模型与固定用户人设的对齐效果。
对照组选用 InternVL3-8B/38B、强文本能力模型 Qwen3-30B-A3B,
同时在基础模型上叠加自我纠错、少样本提示等优化策略进行对照。
如表 2 结果所示:
PersonaVLM 在两项评测集上全面超越现有模型:
- 在 Persona-MME 上,相较次优模型领先 9.16 % 9.16\% 9.16%;
- 在 P-SOUPS 上领先 2.46 % 2.46\% 2.46%;
相较原始基线模型整体提升超 12 % 12\% 12%。
实验还发现:纯文本大模型的人格对齐能力往往优于多模态大模型。
例如 Qwen3-30B-A3B 在 128 k 128\text{k} 128k 条件下,人格对齐指标比 InternVL3-38B 高出 20%。
以上结果充分证明,PersonaVLM 具备强大且稳定的长期人格对齐能力。
5.3 定性效果评测


图6:开放型生成任务的定性比较。案例研究表明,与基线模型和GPT-4o相比,PersonaVLM在记忆回忆、上下文整合以及个性对齐方面具有更优越的能力。
针对开放式生成的研究问题 RQ3,
从 Persona-MME 中随机抽取 200 条测试问题开展自动化定性评测。
对照组:InternVL3-8B、Qwen2.5-VL-7B、GPT-4o;
统一采用 Gemini-2.5-Pro 作为自动化裁判模型。
评测标准包含两项核心维度:回答准确率、人格匹配度,
模型两两对比结果分为三类:领先(win)、持平(tie)、落后(loss),评测提示词详见图 23。
由图 5 可见:PersonaVLM 整体胜率大幅高于所有对比模型。
尤其与 GPT-4o 直接对标时:
胜率高达 79 % 79\% 79%,落后率仅 16 % 16\% 16%。
图 6 案例进一步直观验证该结论:
PersonaVLM 可精准完成视觉信息回忆、融合长期上下文记忆、稳定维持长期人设风格。
反观其他模型普遍存在严重缺陷:记忆幻觉、语言风格错位、忽略用户历史个性化信息等问题。
该部分充分验证了 PersonaVLM 在长期个性化生成场景中的落地价值与优越性。
6 结论
本文提出了 PersonaVLM 这一全新智能体框架,通过融合记忆存储、逻辑推理、回复对齐三大核心能力,实现多模态大模型(MLLM)的长期动态个性化交互。
为实现严谨、全面的能力测评,本文进一步构建面向多模态个性化理解的综合评测基准 Persona-MME。
大量实验结果表明:PersonaVLM 能够显著增强模型的个性化适配能力,综合表现稳定超越当前主流模型,既包括闭源商用模型 GPT-4o,也涵盖各类顶尖开源多模态模型。
本研究为构建真正以用户为核心的智能助手提供了全新范式。未来工作将在此基础上持续拓展,进一步赋能全沉浸式多模态交互体验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)