国产化实践:在海光 DCU 上成功部署 Qwen2.5-14B 大模型(vLLM + ROCm)
关键词:海光 DCU、ROCm、vLLM、Qwen2.5、大模型部署、国产算力、AI 推理
一、背景与挑战
随着国产 AI 芯片生态的快速发展,海光 DCU(Deep Computing Unit)作为兼容 ROCm 生态的国产 GPU,正逐步在大模型推理场景中崭露头角。然而,由于其与 NVIDIA CUDA 的底层差异,许多主流推理框架(如 vLLM)在 DCU 上运行时会遇到兼容性问题。
本文记录了我在 海光 DCU 环境下成功部署 Qwen2.5-14B-Instruct 模型 的全过程,并总结出一套可复用的部署方案,希望能为国产化 AI 推理提供参考。
二、硬件准备
- 操作系统:Kylin Linux Advanced Server V10 (Halberd)”(需安装 DTK 驱动)
这是一套专为海光处理器优化的银河麒麟服务器系统,运行在 x86_64 架构上,兼容部分 CentOS/RHEL 生态。
cat /etc/os-release
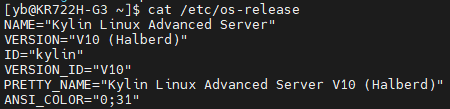
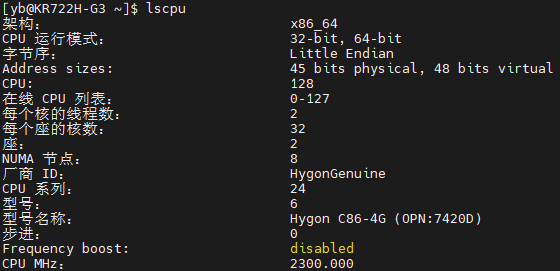
- CPU:海光7420D,1颗32核64线程就够用。
lscpu
- DCU:全称为“Deep Computing Unit”,功能类似于英伟达的GPU。本服务器使用的是海光K100 AI,这是海光推出的面向 AI 训练/推理和高性能计算(HPC)的加速器,兼容 AMD ROCm 软件生态(基于开源 ROCm 适配),并非传统意义上的“显卡”,但功能类似 NVIDIA GPU。需安装 海光 DCU 驱动 + ROCm 运行时环境(通常由服务器厂商提供,或可参考光合开发者社区文档安装)。安装好后可查询到DCU信息。
rocm-smi
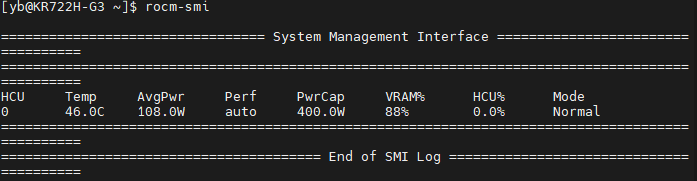
- DCU:推荐至少64G。(大模型部署运行后占内存大约10G)
二、软件准备
- 安装docker:详见在银河麒麟 + 海光CPU信创服务器上离线安装 Docker 20.10.21 全流程避坑指南-CSDN博客。
- 下载大模型:详见在银河麒麟 V10 + 海光 CPU 信创服务器上成功下载 Qwen2.5-14B-Instruct 模型:Git + Git LFS 实战避坑指南-CSDN博客
三、ROCm+vLLM安装
- 操作系统:Kylin Linux Advanced Server V10(需安装 DTK 驱动)
- 硬件:海光 DCU(支持 ROCm)
海光 K100 基于 GPGPU 架构,兼容 AMD ROCm 生态,因此可以走 ROCm 路线,使用 vLLM 的 ROCm 支持版本
1、采用Docker从内网镜像仓库 image.sourcefind.cn:5000 拉取了 专为海光 DCU 优化的 vLLM 镜像
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.8.5-ubuntu22.04-dtk25.04.1-rc5-das1.6-py3.10-20250724
Docker 镜像是分层存储在主机的 Docker 根目录中(默认为 /var/lib/docker/),你不需要手动管理这些文件。
但你可以通过以下方式查看和使用它:
docker images

注意可以使用镜像ID用于镜像加载,以上镜像ID为efc1a5d819c4。
五、启动部署命令
由于vLLM 默认启用 CUDA Graph 捕获(CUDAGraph Capture)以提升推理性能。但在 海光 DCU + ROCm 环境中,部分算子尚未完全兼容 CUDAGraph,导致进程在 warmup 阶段发生 段错误(Segmentation Fault),且无 Python 异常抛出。因此必须启用 Eager 模式:通过添加 --enforce-eager 参数,禁用 CUDAGraph 捕获,使用标准 PyTorch Eager Execution 模式,绕过兼容性问题。
✅ 完整 Docker 启动命令
docker run -d \
--shm-size 64g \
--network=host \
--name qwen-dcu \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal:/opt/hyhal:ro \
-v /models:/models:ro \
<your-vllm-dtk-image> \
python -m vllm.entrypoints.openai.api_server \
--model /models/Qwen2.5-14B-Instruct \
--dtype float16 \
--max-model-len 8192 \
--tensor-parallel-size 1 \
--host 0.0.0.0 \
--port 8000 \
--enforce-eager # ⭐ 关键参数!📌 注意:
- 必须挂载海光 HAL 库(
/opt/hyhal) - 使用
--network=host避免端口映射问题 - 初次调试建议去掉
--rm,便于查看日志
五、验证部署成功
1. 查看服务状态
docker logs -f qwen-dcu看到以下日志即表示成功:
INFO ... Starting vLLM API server on http://0.0.0.0:8000
INFO ... Application startup complete.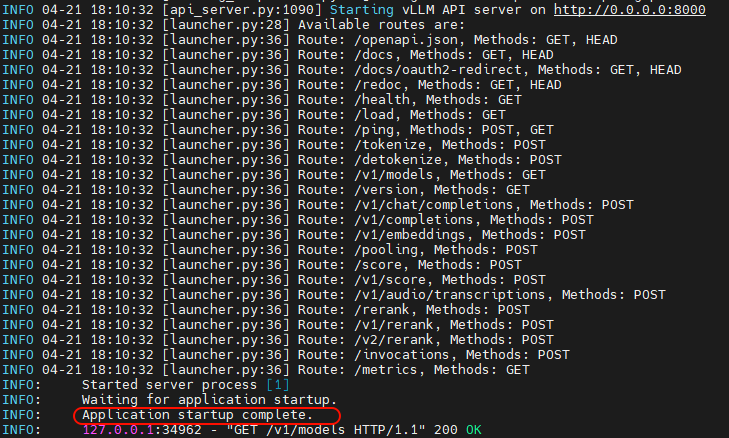
2.调用 OpenAPI 接口
curl http://localhost:8000/v1/models返回:
{
"object": "list",
"data": [{
"id": "/models/Qwen2.5-14B-Instruct",
"max_model_len": 8192,
"owned_by": "vllm"
}]
}
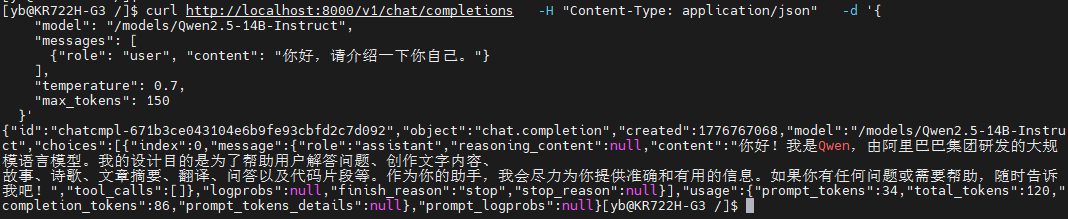
3.发起聊天请求
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"messages": [{"role": "user", "content": "你好!"}],
"max_tokens": 50
}'✅ 成功返回模型生成内容!
六、经验总结与建议
|
问题 |
解决方案 |
|
容器启动后立即退出 |
去掉 |
|
模型加载成功但服务未启动 |
极大概率是 CUDAGraph 不兼容 → 加 |
|
权限错误(/dev/kfd) |
确保用户在 |
|
性能略低 |
Eager 模式比 CUDAGraph 慢 10~20%,但稳定性优先 |
💡 生产建议:
- 添加
--restart always实现容器自愈 - 通过
VLLM_RANK0_NUMA=0绑定 NUMA 提升性能 - 监控 DCU 显存:使用
hccsmi或rocm-smi
七、结语
本次实践证明:在海光 DCU 上运行主流大模型是完全可行的!虽然存在一些兼容性细节需要处理,但通过合理配置(如 --enforce-eager),我们能够快速构建稳定、高效的国产化 AI 推理服务。
未来,随着 DTK 和 vLLM 对 ROCm 支持的不断完善,相信国产芯片在大模型领域的应用将更加广泛。
代码已跑通,服务已上线,国产 AI 正当时!
欢迎点赞、收藏、评论交流!
如果你也在做国产芯片适配,欢迎留言分享你的经验 👇
版权声明:本文为原创,转载请注明出处。禁止商业转载。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)