【人工智能/AI】项目实战三:AI图片生成产品汇总(非完全)
·
本文主要介绍当前市场上可以通过文字生成图片的大模型产品,列出各大模型的发布方、使用方式、资费情况、擅长领域、优缺点等,所有数据均来自于网络。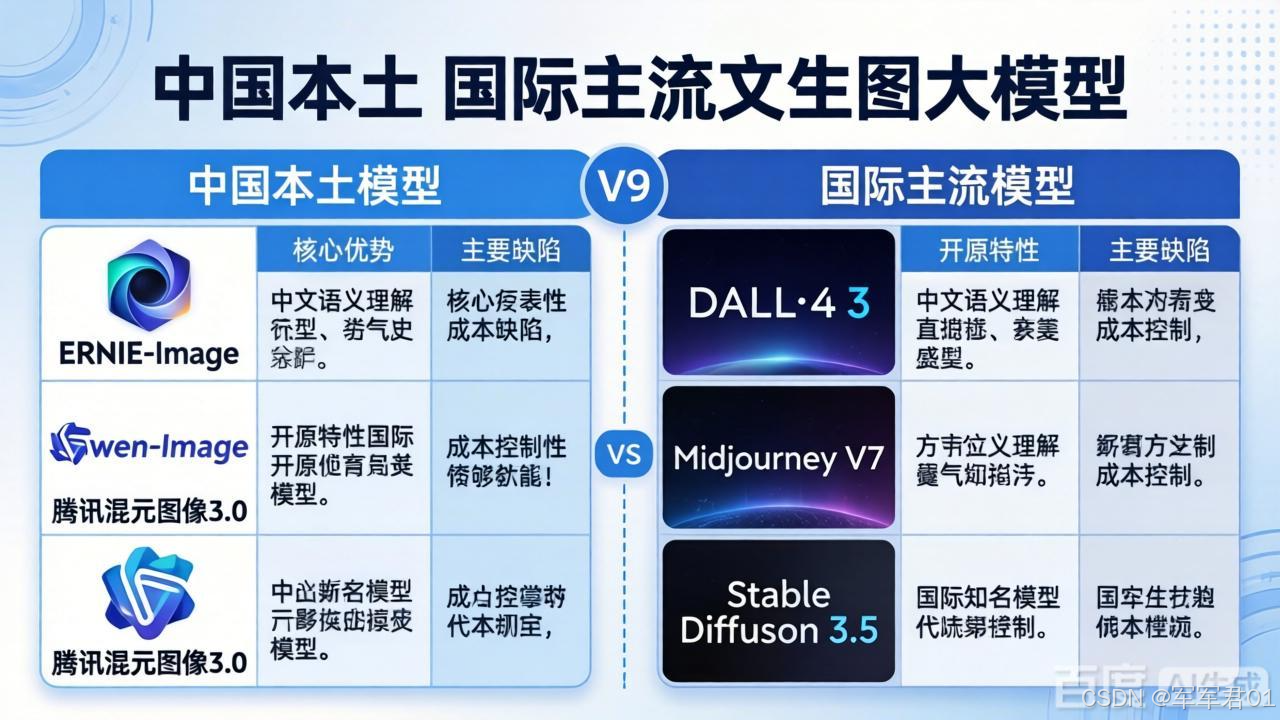
一.各大模型产品汇总
1.1 国际主流文本生成图像大模型
| 模型名称 | 开发机构 | 发布时间 | 核心特点 | 开源状态 |
|---|---|---|---|---|
| DALL·E 3 | OpenAI | 2023年 | 深度集成GPT-4,支持复杂提示词理解、自动提示优化、高保真细节生成 | 闭源(通过ChatGPT Plus调用) |
| DALL·E 2 | OpenAI | 2022年 | 基于unCLIP架构,支持文本到图像的高分辨率生成(1024×1024) | 闭源 |
| Midjourney V7 | Midjourney Inc. | 2025年 | 以艺术风格表现力著称,支持精细提示词控制、多图融合、风格迁移 | 闭源(Discord平台使用) |
| Stable Diffusion 3.5 | Stability AI | 2025年 | 支持百万级像素生成,改进文本对齐与多对象布局,引入MMDiT架构 | 开源(Hugging Face) |
| Stable Diffusion XL (SDXL) | Stability AI | 2023年 | 双编码器架构,提升细节与构图能力,广泛用于本地部署 | 开源 |
| Flux | Alibaba Cloud / ModelScope | 2025年 | 高效推理模型,支持消费级显卡部署,细节生成与融合度领先 | 开源 |
| Imagen & Imagen 2 | 2022–2024年 | 基于Pathways Language Model,文本理解能力极强,图像真实感突出 | 闭源(部分技术开源) | |
| GPT-Image-1.5 | OpenAI | 2026年 | 作为GPT-4的视觉扩展,支持多轮图文交互与语义推理,登顶2026中文测评榜 | 闭源 |
| Nano Banana 2 | 2026年 | 2026年SuperCLUE测评榜首,综合图像质量与图文一致性表现最优 | 闭源 |
1.2 中国本土文本生成图像大模型
| 模型名称 | 开发机构 | 发布时间 | 核心突破 | 应用场景 |
|---|---|---|---|---|
| ERNIE-Image | 百度 | 2026年 | 中文文生图测评榜首(SuperCLUE 2026),汉字生成准确率、语境还原能力国内第一,融合知识增强预训练 | 广告设计、教育内容、品牌视觉 |
| Qwen-Image | 阿里云通义 | 2025年8月 | 全球首个印刷级中文文本渲染模型,支持多行、段落级中英文混排,标点悬挂、字间距自动校正 | 出版、电商海报、UI设计 |
| 通义万相 Wan2.6 | 阿里云通义 | 2025年12月 | 支持角色扮演、分钟级数字人视频生成,国内首个支持动态语义一致性的视频生成模型 | 影视动画、虚拟偶像、AI短剧 |
| 腾讯混元图像3.0 | 腾讯 | 2025年 | 首个工业级原生多模态生图模型(80B参数),支持一句话P图、多图融合、草稿转商稿 | 广告创意、游戏美术、电商视觉 |
| PanGu-Draw | 华为 | 2024年 | 采用时间解耦训练与Coop-Diffusion,支持多控制信号(如姿态、布局),资源效率高 | 企业级AI设计工具 |
| 智谱AI 图像模型 | 智谱AI | 2025年 | 基于GLM架构的多模态扩展,支持中文语义驱动的可控生成,已开源部分轻量模型 | 学术研究、教育辅助 |
| 月之暗面 图像生成器 | 月之暗面 | 2025年 | 聚焦长上下文理解,支持复杂叙事性提示生成,尚未公开完整架构 | 专业创意领域 |
1.3 开源与社区模型(可本地部署)
- Stable Diffusion 3.5 —— 支持本地部署,社区插件丰富(ControlNet、LoRA)
- Flux —— 轻量级,17GB显存即可运行,ComfyUI工作流支持完善
- Qwen-Image —— 阿里开源,支持中文文本渲染,ModelScope平台可直接调用
- PixArt-α / PixArt-Σ —— 基于Transformer架构,参数效率高,适合研究
- Lumina —— 清华大学与智谱联合发布,支持高分辨率与长文本生成
- Kandinsky 3 —— Sber(俄罗斯)开发,多语言支持良好,开源权重可用
1.4 当前技术瓶颈与挑战
- 文字渲染:尽管Qwen-Image实现突破,多数模型仍难以准确生成复杂排版、小字号、非拉丁字符。
- 语义一致性:长提示词(>500 token)下,模型易丢失细节(如PRISM论文指出)。
- 版权与伦理:商业使用中,模型训练数据来源的版权争议持续存在(如Adobe Firefly为唯一明确授权的商业模型)。
- 计算成本:高端模型(如混元3.0、GPT-Image-1.5)依赖云端API,本地部署门槛高。
二.各大模型产品使用方式及费用
2.1国际主流模型
| 模型名称 | 官方访问网址 | 费用情况 |
|---|---|---|
| DALL·E 3 | https://chat.openai.com | 仅限ChatGPT Plus订阅:- 月费 **$20/月**,包含无限次图像生成;- 无独立API,不支持开发者调用。 |
| Midjourney V7 | https://www.midjourney.com | Discord订阅制:- Basic:10/月(25张/月); −Standard:10/月(25张/月); - Standard:10/月(25张/月); −Standard:30/月(150张/月);- Pro:60/月(300张/月+高分辨率); −Mega:60/月(300张/月 + 高分辨率); - Mega:60/月(300张/月+高分辨率); −Mega:120/月(无限张 + 优先队列)。 |
| Stable Diffusion 3.5 | https://huggingface.co/stabilityai | 完全开源免费:- 模型权重可免费下载、商用、本地部署;- 第三方云平台API收费: - Replicate:0.001–0.001–0.001–0.005/张(1024×1024); - RunPod:按GPU时长计费,约**$0.003/张(**FP8量化版)。 |
| Flux | https://www.modelscope.cn/models/alimama-creative/FLUX.1-dev | 完全开源免费:- 支持ComfyUI、Stable Diffusion WebUI部署;- 无官方API,社区提供轻量推理服务,无收费。 |
| GPT-Image-1.5 | https://platform.openai.com/docs/models/gpt-image-1.5 | 开放官方API,按Token计费:- 输入(Prompt):5.00 / 1M tokens**; - 输出(图像):**10.00 / 1M tokens;- 生成1张1024×1024图约消耗150–300 tokens,单图成本约 0.0015–0.0015–0.0015–0.003;- 支持图像编辑,费用同上。 |
| Nano Banana 2 | https://ai.google.dev/gemini-api/docs/pricing | 官方API定价全球最低:- $0.015 / 张(4K分辨率,含编辑);- 比竞品低50%以上,支持多图融合、实时搜索、中文文本渲染;- 通过Google AI Studio免费试用,开发者可申请API密钥。 |
2.2中国本土模型
| 模型名称 | 官方访问网址 | 费用情况 |
|---|---|---|
| ERNIE-Image | https://aistudio.baidu.com/ernieimage | 完全免费开源。模型权重与推理代码已开源(Apache 2.0协议),支持本地部署,无API调用费用。百度AI Studio提供免费算力体验。 |
| Qwen-Image | https://modelscope.cn/models/qwen | 免费额度 + 资源包:- 新用户通过阿里云百炼平台可领取80张/3个月资源包(抵扣Qwen-Image生成);- 超额后按¥0.25/张计费(1024×1024分辨率);- 支持企业API调用,按Token计费,详情见百炼计费文档。 |
| 通义万相 Wan2.6 | https://tongyi.aliyun.com/wan/ | 90天免费额度:- 文生图:50张;- 文生视频/图生视频:50秒(720P);- 超额后:¥0.20/张(图像),¥1.00/秒(1080P视频);- 企业版支持定制API,按量计费。 |
| 腾讯混元图像3.0 | https://hunyuan.tencent.com/image | 开源免费 + 企业后付费:- 源代码与权重完全开源,可自由下载、商用、二次开发;- 企业API调用采用后付费模式,按生成图片张数计费,¥0.15/张起(1024×1024);- 首次开通赠送免费额度,优先扣减后进入后付费。 |
| PanGu-Draw | 无独立Web入口 | 无公开API计费。模型集成于华为云ModelArts平台,需绑定昇腾AI芯片实例,费用按云服务资源使用量(如GPU时长)计费,无独立图像生成单价。 |
| 智谱AI 图像模型 | https://open.bigmodel.cn/ | 部分免费:- GLM-4-Vision等轻量模型免费开放;- 高阶图像生成API按¥0.10–0.30/1M tokens计费,具体视模型版本而定。 |
| 月之暗面 图像生成器 | https://kimi.moonshot.cn/ | 仅支持图像理解,不支持文生图:- 提供多模态图像理解API(moonshot-v1-vision-preview),按¥12/1M tokens计费(单图≈1024 tokens);- 无图像生成能力,非文生图模型。 |
2.3开源与社区模型(可本地部署)
| 模型名称 | 访问方式 | 费用情况 |
|---|---|---|
| Stable Diffusion 3.5 | Hugging Face / ModelScope | 免费开源,部署成本仅硬件(显存≥16GB) |
| Flux | ModelScope | 免费开源,17GB显存可运行,支持ComfyUI |
| Qwen-Image | ModelScope | 免费开源,中文优化版,支持本地部署 |
| PixArt-α / Σ | Hugging Face | 免费开源,参数效率高,适合研究 |
| Lumina | 清华大学开源 | 免费开源,支持长文本与高分辨率生成 |
三.各大模型优缺定分析
3.1 中国本土模型优缺点对比
| 模型名称 | 核心优势 | 主要缺陷 |
|---|---|---|
| ERNIE-Image | - 中文语义理解国内第一(SuperCLUE 2026得分76.37)- 开源轻量:仅8B参数,24GB显存可本地部署- 提示增强机制自动扩展简短指令,提升生成一致性- 支持图表、多主体空间控制,适合教育与广告设计 | - 复杂多语言混排(如中英日韩并存)偶现错字或笔画缺失- 人物关系、精细动作理解仍弱于GPT-Image-1.5- 无官方API,依赖百度AI Studio平台,企业级服务有限 |
| Qwen-Image | - 印刷级中文渲染:支持1000+ token长文本,准确率97.29%- 多字体/排版控制:可精准指定字体、字号、颜色、行距- 支持漫画分镜、PPT生成,子图一致性优秀- 开源且集成于ModelScope,开发者生态完善 | - 低分辨率(<1024×1024)下文字模糊、锯齿明显- 对提示词格式敏感,需明确指定“黑体72pt”等参数- 不擅长超现实风格或抽象艺术表达 |
| 腾讯混元图像3.0 | - 全球首个开源工业级模型,可商用、可二次开发- 性价比高:API调用仅¥0.15/张(1024×1024)- 支持“一句话P图”、多图融合、草稿转商稿- 与微信生态深度集成,适合电商与社交内容生成 | - 文字渲染能力弱于Qwen-Image,无法处理复杂排版- 缺乏对中文语义的深层理解,易误解抽象描述- 无视频生成能力,功能聚焦静态图像 |
| 通义万相 Wan2.6 | - 国内首个支持动态语义一致性的视频生成模型- 可分钟级生成数字人视频、AI短剧- 图像生成与视频生成共享底层架构,风格统一 | - 图像生成非核心能力,画质与细节弱于Qwen-Image- 视频生成存在内容合规风险,部分场景被平台限流- 未开源,仅限阿里云平台调用 |
| PanGu-Draw | - 支持姿态、布局、草图等多控制信号输入- 资源效率高,适配华为昇腾芯片,企业级部署稳定 | - 无独立Web入口,需绑定华为云ModelArts- 无公开评测数据,中文语义理解能力未验证- 社区生态薄弱,工具链支持有限 |
3.2 国际主流模型优缺点对比
| 模型名称 | 核心优势 | 主要缺陷 |
|---|---|---|
| GPT-Image-1.5 | - 全球综合第一(SuperCLUE 87.03分)- 逻辑控制与图像编辑精度顶尖,支持多轮交互修改- 生成细节丰富,擅长复杂叙事、科学插图 | - 中文支持极差,生成含中文图像错误频出- 成本高:单图约$0.0015–0.003,API调用门槛高- 生成稳定性依赖提示词结构,对模糊指令响应差 |
| Nano Banana 2 | - 全球文生图榜首(SuperCLUE 83.73分)- 性价比之王:$0.015/张,为竞品1/3价格- 多模态理解强,支持实时搜索、图文融合、中文文本渲染 | - 闭源且依赖Google AI Studio,无本地部署可能- 未开放API给中国开发者,访问受限- 对艺术风格控制弱于Midjourney |
| Midjourney V7 | - 艺术表现力无出其右,电影感光影、油画质感顶尖- 风格迁移能力强,适合品牌视觉、插画创作- Discord平台交互流畅,社区创意生态活跃 | - 完全不支持中文,提示词需英文撰写- 文本遵循能力弱,易忽略关键描述- 无图像编辑、图生图、参考图控制功能 |
| Stable Diffusion 3.5 | - 完全开源,支持ComfyUI、ControlNet、LoRA等丰富插件- 社区模型生态最庞大,可定制化程度最高- 生成稳定,适合科研、个人创作者长期使用 | - 对复杂语义理解弱,需专业提示词工程- 生成一致性差,同一提示多次结果波动大- 高分辨率生成需高端显卡(≥24GB) |
3.3 开源与社区模型优缺点
| 模型名称 | 核心优势 | 主要缺陷 |
|---|---|---|
| Flux | - 推理速度极快,17GB显存即可运行- 生成细节与融合度领先开源模型- 与ComfyUI深度兼容,工作流成熟 | - 无官方API,依赖社区部署- 中文支持弱,仅限英文提示- 模型版本更新快,稳定性待长期验证 |
| PixArt-α/Σ | - Transformer架构,参数效率高- 适合学术研究与轻量级部署 | - 生成分辨率受限,不适合商业海报- 社区文档少,上手门槛高 |
| Lumina | - 支持长文本(>1000 token)与高分辨率(4K)生成- 清华与智谱联合研发,中文优化较好 | - 未开源完整权重,仅部分模型公开- 推理速度慢,需A100级算力 |
3.4 共性技术瓶颈与挑战
- 文字渲染: 除Qwen-Image外,几乎所有模型在小字号、多语言混排、非拉丁字符上仍存在模糊、错字、断字问题。
- 语义一致性: 长提示(>500 token)下,模型易丢失细节(如“左手持剑、右脚踩石”),PRISM论文指出当前模型平均丢失率超35%。
- 版权与伦理: 训练数据含受版权保护图像,商业使用存在法律风险;Adobe Firefly是唯一明确授权的商业模型。
- 计算成本: 高端模型(GPT-Image-1.5、Nano Banana 2)依赖云端,本地部署成本高,中小企业难以承受。
- 可控性缺失: 除Stable Diffusion生态外,多数闭源模型不支持参考图、草图、姿态控制,创作自由度受限。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)