深入理解 MPSC 无锁队列:从原理到三种实现
上一篇实现过 SPSC,已经理解了 memory ordering 在生产者和消费者之间建立的 happens-before 关系。现在我们把「一个生产者」变成「多个生产者」,难度曲线会突然变陡 —— 不是因为内存序更复杂了,而是多了一个根本性的新问题:多个生产者之间如何协调。
本文会带你走完 MPSC(Multi-Producer Single-Consumer)的完整学习路径:
- 从朴素实现的 race 切入,把问题的本质摊开
- 用基于 CAS 的链表给出第一个正确答案
- 深入 Vyukov 经典侵入式 MPSC —— 工程界的事实标准
- 给出基于数组的有界 MPSC 实现
- 内存序、瞬态不一致、ABA、内存回收等所有关键细节
- 如何验证你的实现是对的(大部分教程不讲,但最重要)
上一篇SPSC:https://blog.csdn.net/cookies_s_/article/details/160229302?fromshare=blogdetail&sharetype=blogdetail&sharerId=160229302&sharerefer=PC&sharesource=cookies_s_&sharefrom=from_link
一、从 SPSC 到 MPSC:问题的本质变化
回忆一下 SPSC 为什么能做到几乎零开销:
- 生产者只写
tail(对应上一节的write),消费者只读; - 消费者只写
head(对应上一节的read),生产者只读; - 跨线程可见性用一次
release/acquire内存序就能覆盖。
根本原因是 —— 两个"写者"在写不同的变量,互不干扰。
一旦变成 MPSC,事情就不一样了:
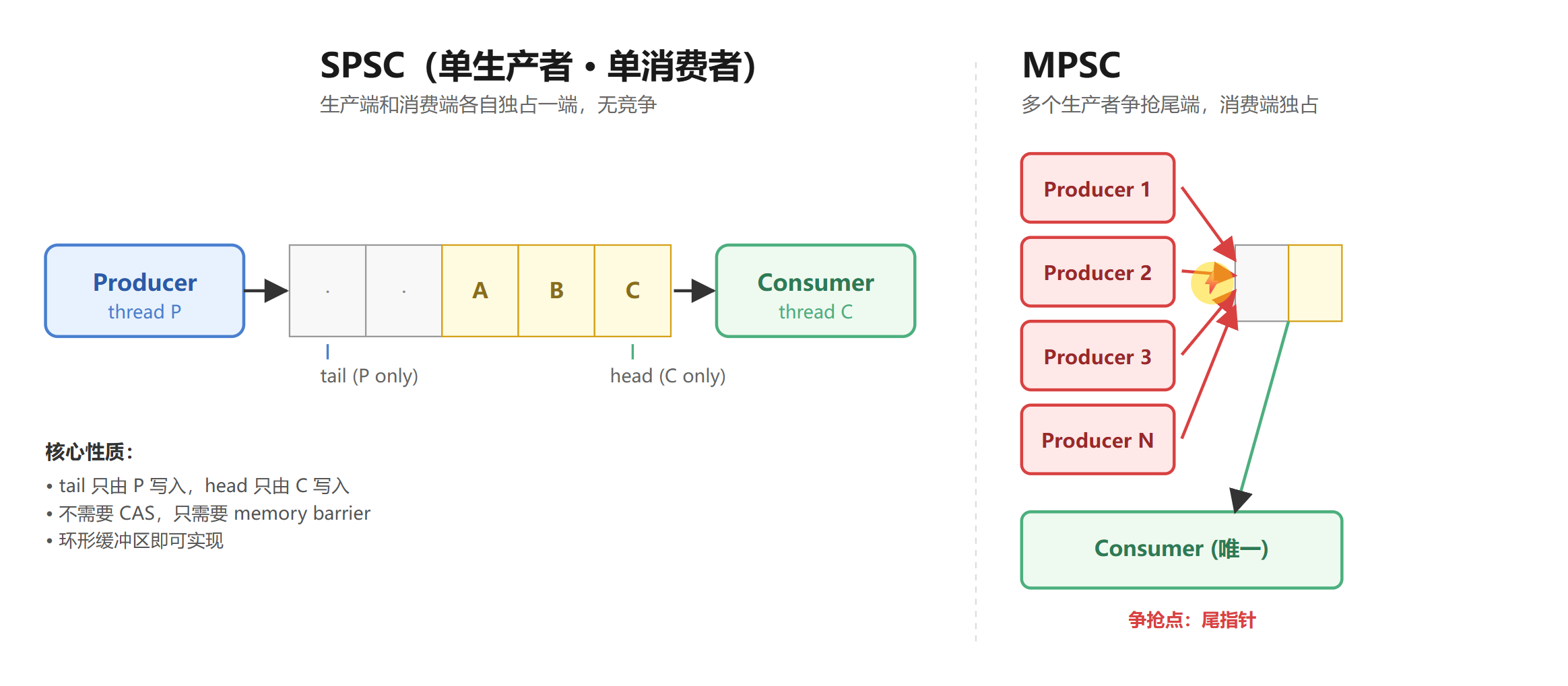
现在多个生产者都要写同一个尾指针。队列本质上还是个 FIFO,但"谁是当前队尾"成了一个需要所有生产者达成共识的全局状态。
这就是 MPSC 的核心问题:生产者之间的同步。消费者那一侧反而依旧简单(因为只有一个),这也是 MPSC 比 MPMC 简单不少的原因。
朴素实现错在哪
新手很容易写出这样的"入队":
// ❌ 错误示范:非原子版的 enqueue
void enqueue(Node* n) {
n->next = nullptr;
tail->next = n; // 步骤 1:连上新节点
tail = n; // 步骤 2:推进尾指针
}
只要两个生产者同时执行它,就必然出事:

- P1 和 P2 在 t0 都把
tail读成 A - P1 先写
A->next = N1 - P2 马上写
A->next = N2—— N1 彻底丢失 - 最后两个都更新
tail,N1 从此成了幽灵节点
问题根源是「读 tail → 写 tail」之间不是原子的。要修复它只有两条路:用 CAS 把"读改写"合成一步,或者用 exchange 直接替换。下面两节分别展示这两种思路。
二、方案一:基于 CAS 的链表 MPSC(入门版)
这是最直接的思路 —— 既然 race 发生在"读写 tail"之间,那就把它们包成一个 CAS 循环。
2.1 基本想法
loop:
prev = load(tail)
if CAS(tail, prev, n) succeeded:
prev->next = n // 把链接上
break
else:
retry
关键点:prev->next = n 在 CAS 成功之后才做。CAS 成功意味着「我独占了 prev 这个节点」—— 因为此时 tail 已经被改成 n,再也不会有其他生产者拿到同一个 prev 了。
2.2 代码实现
#include <atomic>
#include <utility>
template <typename T>
class CasMpscQueue {
struct Node {
T data;
std::atomic<Node*> next{nullptr};
};
alignas(64) std::atomic<Node*> tail_; // 生产端:最新入队的节点
alignas(64) Node* head_; // 消费端:下一个要取的节点的"前驱"
// 用 stub 节点简化边界:空队列时 head_ == tail_ == &stub_
Node stub_;
public:
CasMpscQueue() {
stub_.next.store(nullptr, std::memory_order_relaxed);
tail_.store(&stub_, std::memory_order_relaxed);
head_ = &stub_;
}
~CasMpscQueue() {
T tmp;
while (dequeue(tmp)) {}
// 读空后,最后一个已消费节点可能会滞留为新的前驱
if (head_ != &stub_) {
delete head_;
head_ = &stub_;
}
}
void enqueue(T value) {
Node* n = new Node();
n->data = std::move(value);
n->next.store(nullptr, std::memory_order_relaxed);
// 1) CAS 循环抢占尾指针
Node* prev = tail_.load(std::memory_order_relaxed);
while (!tail_.compare_exchange_weak(
prev, n,
std::memory_order_release, // 成功路径:发布 n 和其前置写
std::memory_order_relaxed)) {
// prev 被 CAS 自动刷新为最新的 tail,直接重试
}
// 2) CAS 成功后,prev 是"我"独占的 —— 安全链接
prev->next.store(n, std::memory_order_release);
}
bool dequeue(T& out) {
Node* head = head_;
Node* next = head->next.load(std::memory_order_acquire);
if (!next) return false;
// 把数据搬出来,然后把旧的"前驱"节点回收
out = std::move(next->data);
head_ = next;
if (head != &stub_) delete head;
return true;
}
};
2.3 这个版本的优缺点
先给这个版本一个准确定位:它是教学版实现。它非常适合拿来理解"多个生产者如何通过 CAS 协调争抢尾指针",但我不建议把它直接当成"生产环境里可原样落地的完整 MPSC 队列"。
优点:
- 思路直接,容易理解;
- 生产者侧的关键同步关系很清楚 —— CAS 保证每个生产者独占自己的
prev; dequeue里采用的是old-head reclamation(释放旧前驱):当前取出的节点会留下来充当新的前驱节点,下一次成功出队时再回收旧前驱。
缺点:
- CAS 循环会自旋,在高争用下多个生产者会不断失败重试;
- 每次 enqueue 都要
new一个节点,堆分配本身就是瓶颈; compare_exchange_weak在失败时会把最新的 tail 值写回prev,看似省事,但在激烈争用下相当于一直在读 cache line,触发大量 MESI 协议流量;- 它有断链窗口:某个生产者已经 CAS 成功把
tail_推进了,但还没来得及写prev->next。这时 consumer 可能暂时观察到"像是空队列"的状态,因此这个教学版不适合作为"严格线性化 queue"的最终实现; - 这个版本的回收逻辑还不够收尾:当队列被读空时,最后一个已消费节点会滞留为新的前驱;如果对象此时直接析构,析构函数还需要额外释放这个最终前驱节点,否则会漏掉最后一块堆内存。
- 是否有 use-after-free 风险?
use-after-free:例如在生产者被抢占导致 “CAS 成功但 prev->next 还没写” 的窗口里,consumer 可能已经把 prev 节点 dequeue 并 delete。此时恢复执行的生产者会写到已释放内存。
但这里没有这个问题,这得归功于"每次dequeue"释放旧的前驱节点(也就是释放当前dequeue的前驱的前驱)的设计;enqueue 在 CAS 成功后,生产者对旧尾节点 prev 的唯一后续访问,就是的prev->next.store(n, …)。 而 dequeue 只有在读到 head->next != nullptr时,才会删除旧的head。
这就意味着:如果某个生产者还没把 prev->next 链上,那么消费者看到的就是 next == nullptr。既然 next == nullptr,消费者就不会前进,更不会删除这个 prev。所以不会出现“消费者先 delete prev,生产者再写 prev->next”这种 UAF。
三、方案二:Vyukov 经典 MPSC 侵入式队列
这是 Dmitry Vyukov 在 2008 年前后提出的算法,是目前工程界 MPSC 的事实标准。很多知名项目(Facebook Folly、Pony 运行时、Rust 早期标准库等)都采用了它或其变体。
它精妙到什么程度?整个 enqueue 只有两行核心逻辑,且没有循环。
3.1 核心洞察
CAS 方案慢在哪里?—— 它反复"猜测 + 验证"。如果我们能用一个不会失败的原子操作把同步搞定,就能省掉所有重试。
std::atomic::exchange 就是这样的原语:无条件地把原子变量换成新值,并原子地返回旧值。从 C++ 语义上看,它是一个原子 read-modify-write;在硬件上通常会落到原子交换类指令,或者由 LL/SC 风格序列来实现。
Vyukov 的 enqueue 只做两步:
prev = head.exchange(n); // 原子地把 head 换成 n,旧值给 prev
prev->next = n; // 把 prev 的 next 链接到 n
为什么这是正确的?关键论点:
exchange定义了所有生产者的线性化顺序。 每个生产者拿到的prev都是独一无二的(因为任何两个exchange必然排出先后关系),因此每个生产者对prev->next的写也是独占的,不会冲突。
3.2 数据结构
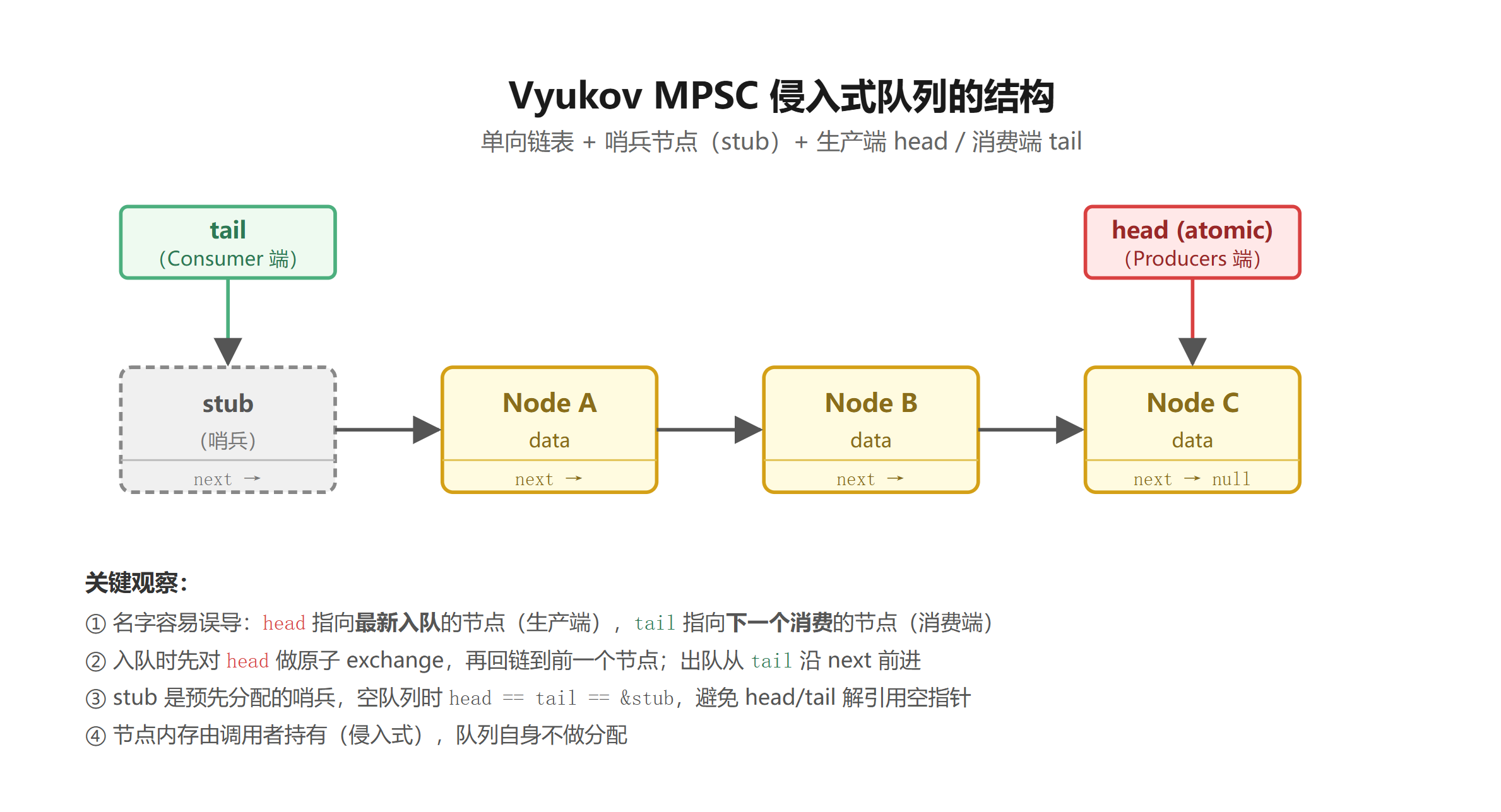
这里命名容易让人懵 —— 注意 Vyukov 习惯用 head 表示生产端(最新入队的节点),tail 表示消费端。
3.3 为什么要做成侵入式?这不只是风格选择,而是工程上的强约束
“侵入式” 指节点内存由调用者管理 —— 队列只存指针,不做 new/delete:
struct MyMessage : MpscQueue::Node { // 继承队列节点
int pid;
int seq;
// ... 业务字段 ...
};
auto* m = new MyMessage{...};
queue.enqueue(m); // 传入 MyMessage* 而不是值
// ... consumer ...
MyMessage* m = (MyMessage*)queue.dequeue();
// consumer 负责 delete m
这看起来只是个设计偏好,实际是无锁队列绕开内存回收地雷的关键。对比一下非侵入式的隐患:
// 假设我们写一个非侵入式的 Vyukov 风格队列
void enqueue(T value) {
Node* n = new Node(std::move(value)); // ← 队列分配
Node* prev = head.exchange(n);
prev->next.store(n, release);
}
T dequeue() {
Node* tail = tail_;
Node* next = tail->next.load(acquire);
if (!next) return ...;
T result = std::move(next->data);
tail_ = next;
delete tail; // ← 能安全 delete 吗?
return result;
}
delete tail 这一步看上去很吓人,但问题要说准确。对这种 exchange/XCHG + prev->next = n 结构来说,consumer 只有在已经观察到 tail->next != nullptr 之后,才可能把旧前驱 tail 回收;因此,这里更本质的风险不是"producer 还没补链,consumer 就先把 prev delete 掉",而是:
exchange与prev->next = n之间存在断链窗口;- 如果 producer 恰好卡在这个窗口里,consumer 会暂时看不到后续节点;
- 这会影响可见性和进展性,也是为什么这类非侵入式版本常被描述为"push 对 consumer 有 blocking window"、甚至不是严格线性化的 queue。
那为什么工程上依然常选侵入式?核心原因有三点:
- 节点生命周期边界更清楚:队列只负责链接与摘链,不再额外承担一层内部节点管理;
- 零额外内部节点:如果消息对象本来就需要动态分配,侵入式不会再多包一层 queue node;
- 热路径更轻:无需在队列内部再维护一套更通用的生命周期协议。
如果你真的要做"非侵入式 + 队列自己管理内部节点"的泛化版本,那么可选方案才会落到:
- 侵入式,把节点生命周期甩给调用者 —— 约定"谁 enqueue 谁负责让节点活到被 dequeue 出来后再释放";
- Hazard Pointer:当结构本身无法证明没有其他线程还握着节点指针时,用 hazard pointer 保护访问中的节点;
- Epoch-Based Reclamation:把 delete 推迟到所有可能的并发引用都失效之后。
方案 1 最简单,几乎零开销;方案 2、3 都要额外的数据结构和协议,在热路径上加开销。Vyukov 选侵入式不是偶然 —— 它首先把 ownership 边界外置,然后把队列内部保持在极简。
另外两个收益:
- 零分配:enqueue 不会
new,对硬实时和 allocator 敏感场景友好 - 缓存局部性:Node 和业务数据在同一块内存里,consumer 拿到节点时数据就在 cache line 里
3.4 enqueue 详解

分四步看最清楚:
① 初始状态:head == tail == &stub,stub 是 next 为 null 的哨兵。
② XCHG:生产者 P1 执行 prev = head.exchange(X)。现在 head 指向 X,但 A 的 next 还是 null —— 此刻队列"断链"。
③ 回链:P1 执行 prev->next.store(X, release),把 A 连上 X。链条修复。
④ 并发生产者:如果 P2 在 ② 之后紧跟着也做 XCHG,它拿到的 prev 是 X(因为 ② 已经把 head 换成 X 了)。P2 接下来会写 X->next = Y,完全不会和 P1 冲突。
注意这四步中步骤 ② 和 ③ 之间存在"断链窗口"—— 这是 Vyukov 算法最值得深入的地方,下一节专门讨论。
3.5 dequeue 深入解析(全文最绕的部分)
这里要先强调一个容易混淆的点:下面代码里的 tail_,并不总是“下一个可弹出节点的前驱”。只有当 tail_ == &stub_ 时,stub_ 才扮演哨兵/前驱节点;一旦 consumer 跳过 stub_,tail_ 通常就表示当前持有的真实节点。于是快速路径的语义是“返回当前 tail,并把 tail_ 推进到 next”,而不是“返回 tail->next”。前文把 tail 近似理解成消费端锚点,是为了帮助理解 stub 和最后一个节点的处理;真正读代码时,应以后面这个更精确的语义为准。
也就是说这里tail更精确的语义是:
tail == stub时,stub是前驱tail != stub时,tail往往就是当前待返回节点
表面上看 dequeue 应该很简单:沿着 tail->next 往前走就行。但瞬态不一致让它变得棘手。先看这个场景:
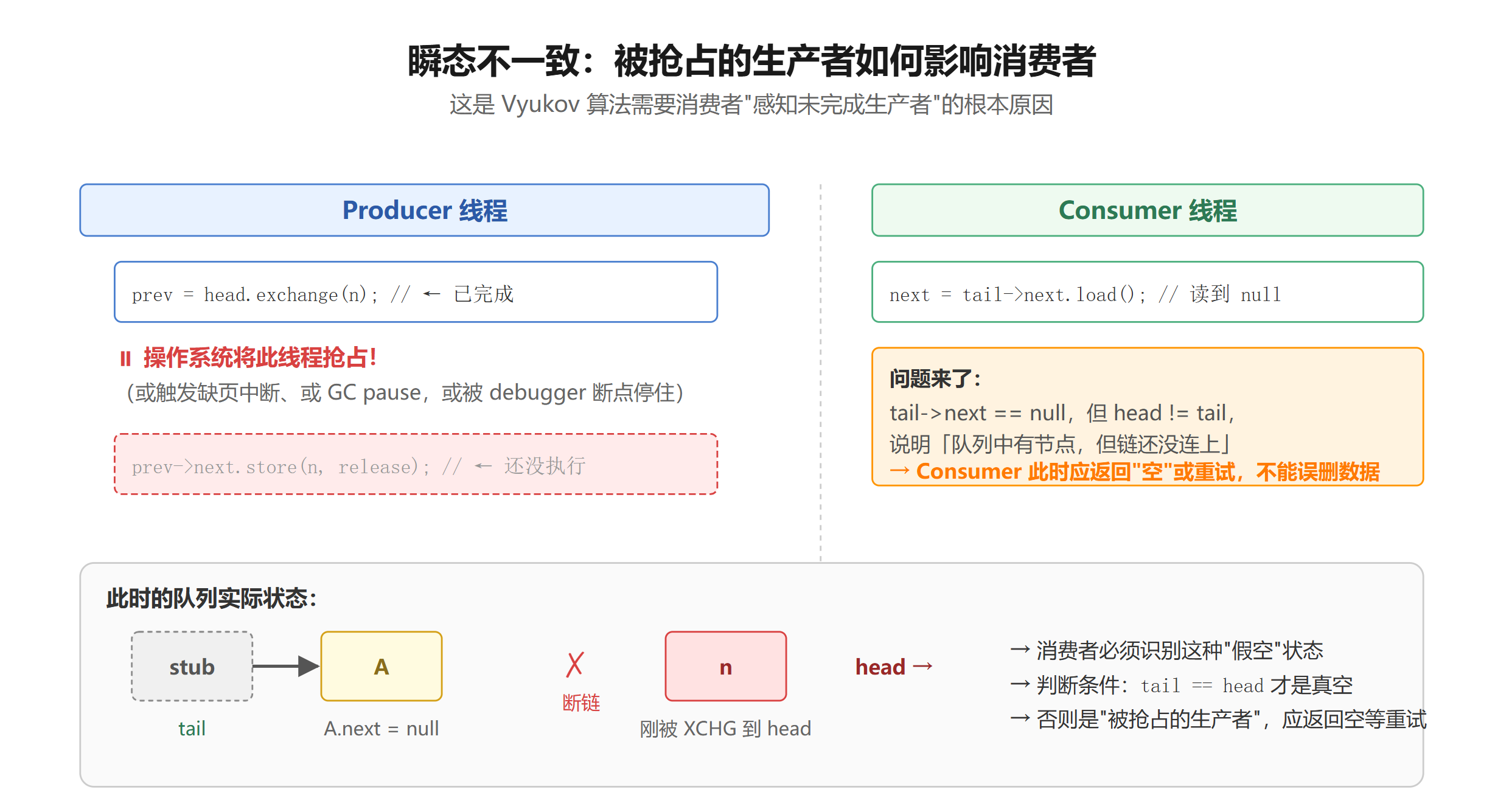
想象这个时序:
- 队列只有一个元素 A(
stub → A,其中head和stub.next都指向 A) - 生产者 P 执行
prev = head.exchange(n)—— 此时head = n,但A->next还是 null - P 在这时被抢占(OS 切换、缺页、debugger 停住……)
- Consumer 来读,它看到
tail = stub, stub->next = A, A->next = null
Consumer 怎么判断此时的状态?如果它以为"A 之后没有元素了",那完全错误 —— 元素 n 已经被 exchange 进来了,只是还没链上。
这也就是为什么 dequeue 的代码比 enqueue 复杂得多 —— 它要处理所有可能的队列状态,不只是"有数据"和"真空"。
dequeue 一共有四个出口,对应四种情况:
| 出口 | 语义 | 消费者应如何应对 |
|---|---|---|
① tail == stub && next == null |
真空,或生产者刚做完 XCHG 还没回链 | 返回 null,调用者 yield 后重试 |
② next != null |
最常走的快速路径,有下一个节点 | 推进 tail_,返回当前节点 |
③ tail != head && next == null |
断链窗口:head 已经超过 tail,但中间的 next 还没连上 | 返回 null,调用者 yield 后重试 |
④ tail == head && next == null |
队列里只剩最后一个节点,要取走它,但取完后 tail 会悬空 | 重新 enqueue stub,再取走节点 |
出口 ④ 是最微妙的一步,也是最多人问"为什么要这么做"的地方。 我们来详细走一遍。
假设当前状态是:
tail → A (stub 已经被跳过,tail_ 已经指向 A)
A.next = null
head → A (因为 A 是最新入队的)
Consumer 想取走 A。取走后 tail_ 应该指向谁?队列理论上空了,我们希望回到初始状态 tail == head == stub,但我们不能直接把 tail 设回 stub—— 因为这需要原子地"把 head 也改成 stub",这是两个变量的同步修改,多生产者环境下做不到。
Vyukov 的做法极其巧妙:把 stub 作为普通节点重新入队一次。
enqueue(&stub_); // stub 现在以"普通节点"身份插到 head 后面
enqueue 会做:
prev = head.exchange(&stub); // 原子地把 head 换成 stub,prev = A
prev->next = &stub; // 把 A 连上 stub
现在队列状态变成:
tail → A → stub
head → stub
这时 Consumer 再做 next = tail->next.load(),看到 next = stub,可以安全地取走 A —— 把 tail_ 推进到 stub。最终状态:
tail → stub (空哨兵)
head → stub
完美回到初始状态。代价是:这条路径做了一次额外的 XCHG + store,但它只在"队列正好被读空"这个临界状态触发,平均成本可以忽略。
更精彩的是:如果在 Consumer 刚调用 enqueue(&stub) 之前有生产者也在 enqueue,那么两者会走正常的 XCHG 排序路径,互不干扰 —— stub 被当成普通节点处理,整个算法依然自洽。
3.6 完整代码
// 侵入式 MPSC 队列 —— 节点内存由调用者管理
class VyukovMpscIntrusive
{
public:
struct Node
{
std::atomic<Node *> next;
};
// 初始化:tail_和head_都指向stub_,表示队列空
VyukovMpscIntrusive()
{
stub_.next.store(nullptr, std::memory_order_relaxed);
head_.store(&stub_, std::memory_order_relaxed);
tail_ = &stub_;
}
// ========== Producer 端 ==========
// 多线程并发调用安全;producer 端是 wait-free,队列整体进展性见 3.8
void enqueue(Node *n)
{
// 初始化新节点。relaxed 就够了 —— 这里还没发布给任何人
n->next.store(nullptr, std::memory_order_relaxed);
// [步骤 ①] 原子地把 head 换成 n,拿到旧的 head 作为 prev
// acq_rel 的含义:
// release 部分 → 把 n 及其初始化写"发布"出去,供后续 acquire 看到
// acquire 部分 → 看到之前所有 release 写过的 head(即前驱节点的完整状态)
// 硬件层面:x86 上是 LOCK XCHG(自带 full barrier)
Node *prev = head_.exchange(n, std::memory_order_acq_rel);
// [步骤 ②] 把 n 连到 prev 后面 —— 关闭断链窗口
// release 保证:consumer 在用 acquire 读到这个指针后,
// 能看到 n 的完整内容(包括业务字段)
// 注意:即便 prev == stub,这里也照样写,因为 stub.next 是 atomic
prev->next.store(n, std::memory_order_release);
}
// ========== Consumer 端 ==========
// 只能由单一线程调用
// 返回 nullptr 的情况(对应 3.5 的出口 ①/③ 和 ④ 的二次失败):
// a) 队列真空
// b) 有生产者在断链窗口内 —— 上层调用者应 yield 后重试
Node *dequeue()
{
Node *tail = tail_; // 本地快照
Node *next = tail->next.load(std::memory_order_acquire); // 与 enqueue 的 release 配对
// ---- 情况 A:tail 当前指向 stub ----
// stub 永远是"位于队头的哨兵",要么 next == null(无数据),
// 要么 next 指向真正的队头节点
if (tail == &stub_)
{
if (next == nullptr)
{
// 出口 ①:可能是真空,也可能是生产者正在断链窗口中
// 上层无需区分,yield 后重试即可
return nullptr;
}
// stub 后面有真节点,把 stub 跳过去
tail_ = next;
tail = next;
next = tail->next.load(std::memory_order_acquire);
}
// ---- 情况 B:快速路径 ----
// tail 是真节点,且后面还有节点
if (next != nullptr)
{
// 出口 ②:正常消费,推进 tail_,返回当前节点给调用者
tail_ = next;
return tail;
}
// ---- 情况 C:tail 是真节点,但 next == null ----
// 两种可能:
// (1) tail 确实是队列中最后一个节点
// (2) 有生产者已经 XCHG 到 head,但还没写 prev->next
// 通过比较 tail 和 head 来区分
Node *head = head_.load(std::memory_order_acquire);
if (tail != head)
{
// 出口 ③:head 已经超过 tail,说明处于断链窗口 —— 等生产者完成
return nullptr;
}
// ---- 情况 D:tail == head,队列里只剩 tail 这一个节点 ----
// 直接取走 tail 会让 tail_ 悬空(下次 enqueue 时 prev->next 写到哪?)
// 解决:把 stub 重新作为"普通节点"入队,变成 [tail → stub]
// 然后就能安全地走情况 B 的快速路径了
enqueue(&stub_);
// stub 入队之后,tail->next 应该被设为 &stub(除非又有新生产者插队)
next = tail->next.load(std::memory_order_acquire);
if (next != nullptr)
{
// 出口 ④ 成功:推进 tail_,返回原 tail
tail_ = next;
return tail;
}
// 出口 ④ 失败:在 enqueue(stub) 与重新 load 之间又有新生产者插入,
// 并且那个生产者也卡在断链窗口里。下次调用时重试即可。
return nullptr;
}
private:
alignas(64) std::atomic<Node *> head_; // 生产端热点
alignas(64) Node *tail_; // 消费端热点
alignas(64) Node stub_; // 独占一行,避免伪共享
};
3.7 内存序为什么是这样选的
逐行辨析:
| 位置 | 使用的内存序 | 为什么 |
|---|---|---|
n->next.store(nullptr, relaxed) |
relaxed | 新节点还没发布给任何其他线程,单线程可见即可 |
head_.exchange(n, acq_rel) |
acq_rel | release 部分:发布新节点 n 的初始化;acquire 部分:拿到 prev 时能看到上游生产者对 prev 的所有 release 写 |
prev->next.store(n, release) |
release | 发布 n 给 consumer —— consumer 用 acquire 加载 tail->next 就能看到 n 的完整内容 |
tail->next.load(acquire) |
acquire | 与上面的 release 配对,建立跨线程 happens-before |
head_.load(acquire) |
acquire | 判断断链窗口时,需要看到最新的 head 值 |
最关键的一对 happens-before 是 prev->next.store(release) ↔ tail->next.load(acquire),它负责让消费者看到节点的完整内容。head 的 acq_rel 只负责生产者之间的线性化。
💡 常见误区:很多人看到
exchange(acq_rel)会觉得"既然 acq_rel 这么强,后面的 store 用 relaxed 不就行了?"错 ——acq_rel作用于head,但prev->next是另一个变量。在 ARM/POWER 这样的弱内存模型上,如果prev->next.store用 relaxed,consumer 可能看到next指针已经设置,但 n 的 data 还没写入。必须 release。
3.8 Vyukov 算法的进展性
- producer / push 这一侧是 wait-free 的:每次入队固定做一次
exchange和一次链接写,没有 CAS 重试环; - consumer / pop 这一侧存在 blocking window:如果某个 producer 卡在
exchange和prev->next = n之间,consumer 需要等那条链接补上,期间可能连续返回空或重试; - 因此,整个队列不宜笼统地称为"完全 lock-free"。更准确的表述是:它的 producer 非常强,consumer 侧则受一个极小的瞬态不一致窗口影响。
这也是为什么很多资料会把它描述成:
- wait-free producers
- push is blocking with respect to consumer
- an algorithm with a tiny window of inconsistency
在生产环境中这通常可以接受,因为:
- 断链窗口只有一条普通链接写;
- 即便某个 producer 卡在窗口里,其他 producer 仍然可以继续推进 head;
- 这个窗口极短,正常运行时命中的概率很低。
如果场景要求严格 wait-free 的整个队列语义(例如某些硬实时场景),那就要看更重型的 wait-free 队列设计,例如 Kogan-Petrank 一类算法,代价是实现复杂度和常数开销都会显著上升。
四、方案三:基于数组的有界 MPSC
链表版的缺点是每次 enqueue 都要分配节点(除非像 Vyukov 那样侵入式)。在高性能日志、网络收包等场景,我们愿意用有界换取零分配和更好的缓存局部性。
4.1 设计思想:用序号当状态位
普通环形缓冲区在 MPSC 下的问题是:多个生产者都要抢 write_pos,写完还要"宣告这个槽位可读"。我们需要一个机制让消费者知道"第 k 号槽位是否写完"。
Dmitry Vyukov 的 bounded MPMC 算法 给出了一个漂亮的解法 —— 每个 cell 配一个原子序号。虽然它原本是 MPMC,用在 MPSC 上更简单(消费端不需要 CAS)。
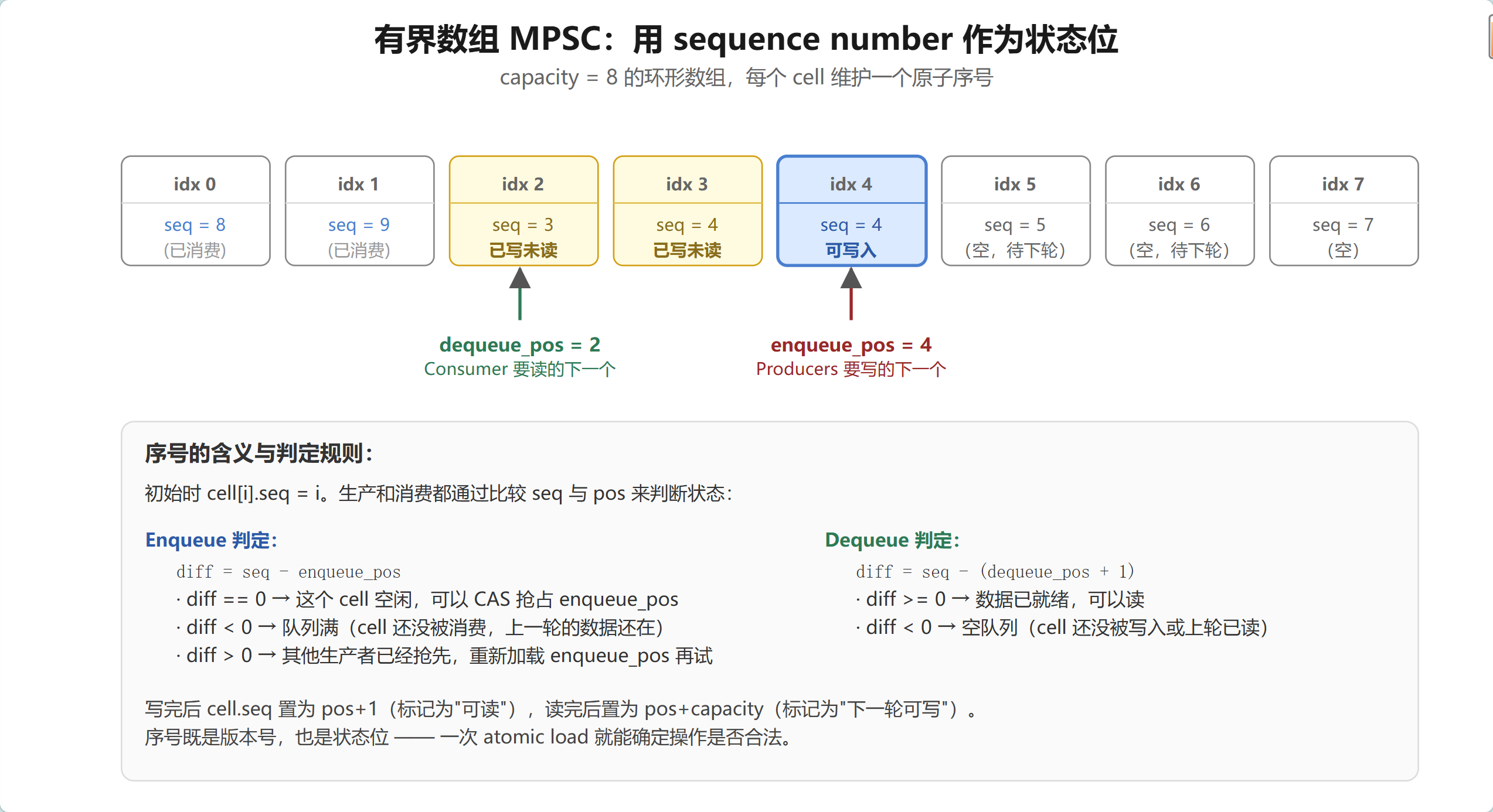
核心规则:
- 初始化时
cell[i].seq = i - 生产者想写 cell[i] 时,要求
cell[i].seq == enqueue_pos;写完后把 seq 置为enqueue_pos + 1(表示"该 cell 数据可读") - 消费者想读 cell[i] 时,要求
cell[i].seq == dequeue_pos + 1;读完后把 seq 置为dequeue_pos + capacity(表示"下一轮此 cell 可写")
序号既是版本号又是状态位,一次 atomic load 就能判定当前操作是否合法。
4.2 完整实现
// 数组版本
#include <atomic>
#include <cstddef>
#include <cstdint>
template <typename T, size_t Capacity>
class BoundedMpscQueue
{
private:
// 数组大小要求为2的幂次
static_assert((Capacity & (Capacity - 1)) == 0, "Capacity must be a power of two");
static_assert(Capacity >= 2, "Capacity must be >= 2");
// 单个元素包含:序号 + 数据
struct Cell
{
std::atomic<size_t> sequence;
T data;
};
alignas(64) Cell buffer_[Capacity]; // 环形队列
alignas(64) std::atomic<size_t> enqueue_pos_; // 递增入队序号 -- 下一个入队的序号
alignas(64) size_t dequeue_pos_; // 递增出队序号 -- 下一个出队的序号 - MPSC 下只有消费者读写,无需原子
static constexpr size_t kMask = Capacity - 1; // 取余掩码
public:
BoundedMpscQueue() : enqueue_pos_(0), dequeue_pos_(0)
{
for (size_t i = 0; i < Capacity; ++i)
{
// 初始化:buffer_[i].sequence = i
buffer_[i].sequence.store(i, std::memory_order_relaxed);
}
}
// 禁止拷贝和赋值
BoundedMpscQueue(const BoundedMpscQueue &) = delete;
BoundedMpscQueue &operator=(const BoundedMpscQueue &) = delete;
// 多生产者调用,返回 false 表示队列满
bool enqueue(T value)
{
Cell *cell; // ptr
size_t pos = enqueue_pos_.load(std::memory_order_relaxed);
for (;;)
{
cell = &buffer_[pos & kMask];
size_t seq = cell->sequence.load(std::memory_order_acquire);
intptr_t diff = static_cast<intptr_t>(seq) - static_cast<intptr_t>(pos);
if (diff == 0)
{
// 这个 cell 空闲,尝试抢占 enqueue_pos
if (enqueue_pos_.compare_exchange_weak(pos, pos + 1, std::memory_order_relaxed))
{
break; // 抢到了,跳出去写数据
}
// 失败:pos 被 CAS 更新为最新值,进入下一次循环
}
else if (diff < 0)
{
// cell.seq < pos:上一轮写入的数据还没被消费 → 队列满
return false;
}
else
{
// diff > 0:其他生产者抢先了,重新加载 pos
pos = enqueue_pos_.load(std::memory_order_relaxed);
}
}
// 独占了 cell,放入数据
cell->data = std::move(value);
// 把 seq 推进到 pos + 1,告诉消费者"可读了"
cell->sequence.store(pos + 1, std::memory_order_release);
return true;
}
// 单消费者调用,返回 false 表示队列空
bool dequeue(T &out)
{
Cell *cell = &buffer_[dequeue_pos_ & kMask];
size_t seq = cell->sequence.load(std::memory_order_acquire);
intptr_t diff = static_cast<intptr_t>(seq) - static_cast<intptr_t>(dequeue_pos_ + 1);
if (diff < 0)
return false; // 还没被写入
// MPSC 下消费者独占 dequeue,不用 CAS
out = std::move(cell->data);
// 把 seq 推进到 dequeue_pos + Capacity,告诉"下一轮的生产者"可写
cell->sequence.store(dequeue_pos_ + Capacity, std::memory_order_release);
dequeue_pos_++;
return true;
}
};
4.3 数组版与链表版的对比
| 维度 | Vyukov 链表侵入式 | 有界数组 |
|---|---|---|
| 容量 | 无界(只受内存限制) | 编译期固定 |
| 内存分配 | 调用者负责节点 | 完全静态 |
| 缓存局部性 | 取决于节点布局 | 极好(连续数组) |
| 满队列行为 | 不会满 | 需要上层处理 false |
| 实现复杂度 | 中 | 中 |
| 进展性 | 见 3.8 | enqueue 需要 CAS 循环;工程上可视为非阻塞实现,严格进展性不在本文里单独证明 |
何时选哪个?
- 消息速率不可预测、容量难估 → 链表版
- 硬实时、无法接受
new/ GC pause → 数组版 - 超高吞吐(几千万 msg/s)、数据小 → 数组版(cache 友好)
- 数据大(例如每条消息几 KB)→ 链表版避免数组内的拷贝
五、关键细节深挖
5.1 关于 ABA 问题
Vyukov MPSC 有没有 ABA?答案:没有。 原因:
- Vyukov enqueue 用的是
exchange而不是compare_exchange——exchange不比较,无条件交换,根本不存在"看到旧值以为没变"的问题 - CAS 链表版虽然用了 CAS,但作用在
tail_上。只要节点地址不被复用,这里就没有典型的 ABA;真正需要小心的是:一旦你把链表版改造成节点池 / freelist 复用,指针值就可能循环出现,这时 ABA 才会变成实打实的问题 - 数组版的 CAS 作用在
enqueue_pos(单调递增的整数),不可能 ABA
如果你把链表版改造成"节点池"以避免频繁 new/delete,就会引入真正的 ABA(CAS 前后读到相同指针但指向的节点已经换过几轮)。这种情况下需要:
- 带版本号的指针(tagged pointer),借助 128-bit CAS(x86 的
cmpxchg16b,ARM 的casp) - 用 hazard pointer 保护节点
- 用 epoch-based reclamation
所有这些方案都复杂且有额外开销。这也是为什么 Vyukov 侵入式版宁可让 ownership 外置,也不在队列内部引入更通用的节点复用与回收协议。
5.2 内存回收问题
已在 3.3 节讨论,这里把边界再讲清楚:单消费者场景对内存回收的要求,确实比多消费者松一个量级,但不等于"可以无脑 delete"。
- 多消费者 MPMC 下,一个消费者刚读完一个节点,另一个消费者可能仍在访问它 —— 这类场景通常离不开 hazard pointer、epoch、RCU 一类安全回收协议;
- 单消费者 MPSC 下,如果队列结构本身能证明"旧前驱被释放之前,不会再有其他线程访问它",那么像第 2 节这种 old-head reclamation(释放旧前驱) 是可以成立的;
- 但如果你继续泛化:加入节点池复用、freelist、helping、更多读者,或者让"还有没有线程握着这个节点"不再能从结构不变式直接推出,就该认真考虑 hazard pointer / epoch 了;
- Vyukov 侵入式把"节点什么时候释放"完全交给调用者,队列内部因此根本不需要实现一套自己的 SMR(safe memory reclamation)协议。
5.3 伪共享(False Sharing)
每次 MPSC 代码都要特别强调 alignas(64)。原因:现代 CPU 按缓存行(通常 64 字节)传输数据,如果 head_ 和 tail_ 恰好在同一行:
- 生产者频繁写
head_→ 该行在 P 的 cache 里 Modified - 消费者读
tail_→ 该行被迫从 P 传到 C,即使tail_根本没变化
这会导致大量 cache line 弹跳(ping-pong),吞吐量可能掉一个数量级。
正确做法:
alignas(64) std::atomic<Node*> head_; // 生产者热
alignas(64) Node* tail_; // 消费者热
alignas(64) Node stub_; // 静态,隔离作用
C++17 提供了更优雅的方式:
#include <new>
alignas(std::hardware_destructive_interference_size) std::atomic<Node*> head_;
但目前 hardware_destructive_interference_size 的编译器支持参差不齐,手动 64 最保险。
5.4 CAS 循环的指数退避
方案一和方案三里都有 CAS 循环。在高争用下,简单的 while(!CAS) 会让多个线程疯狂争抢同一个 cache line。优化手法:
for (int spin = 0; !tail_.compare_exchange_weak(prev, n, ...); ) {
if (++spin > 16) {
#if defined(__x86_64__)
__builtin_ia32_pause(); // x86 的 PAUSE
#elif defined(__aarch64__)
__asm__ __volatile__("yield");
#endif
spin = 0;
}
}
PAUSE 指令在 x86 上的作用:告诉 CPU “我在自旋”,减少推测执行、降低 pipeline 冲突,释放超线程兄弟核的资源。经验值:在 16~32 次失败后 pause 一下。
六、如何验证你的 MPSC 是对的
无锁代码最常见的故障模式是:“跑起来看似对,压测几小时偶发崩溃,但 gdb 附上去又复现不了”。这一节给出一个能捕捉绝大部分错误的最小验证套件。
6.1 per-producer 单调序号法
核心思想:每个生产者发一个单调递增的 seq,消费者收到后按生产者分桶验证。
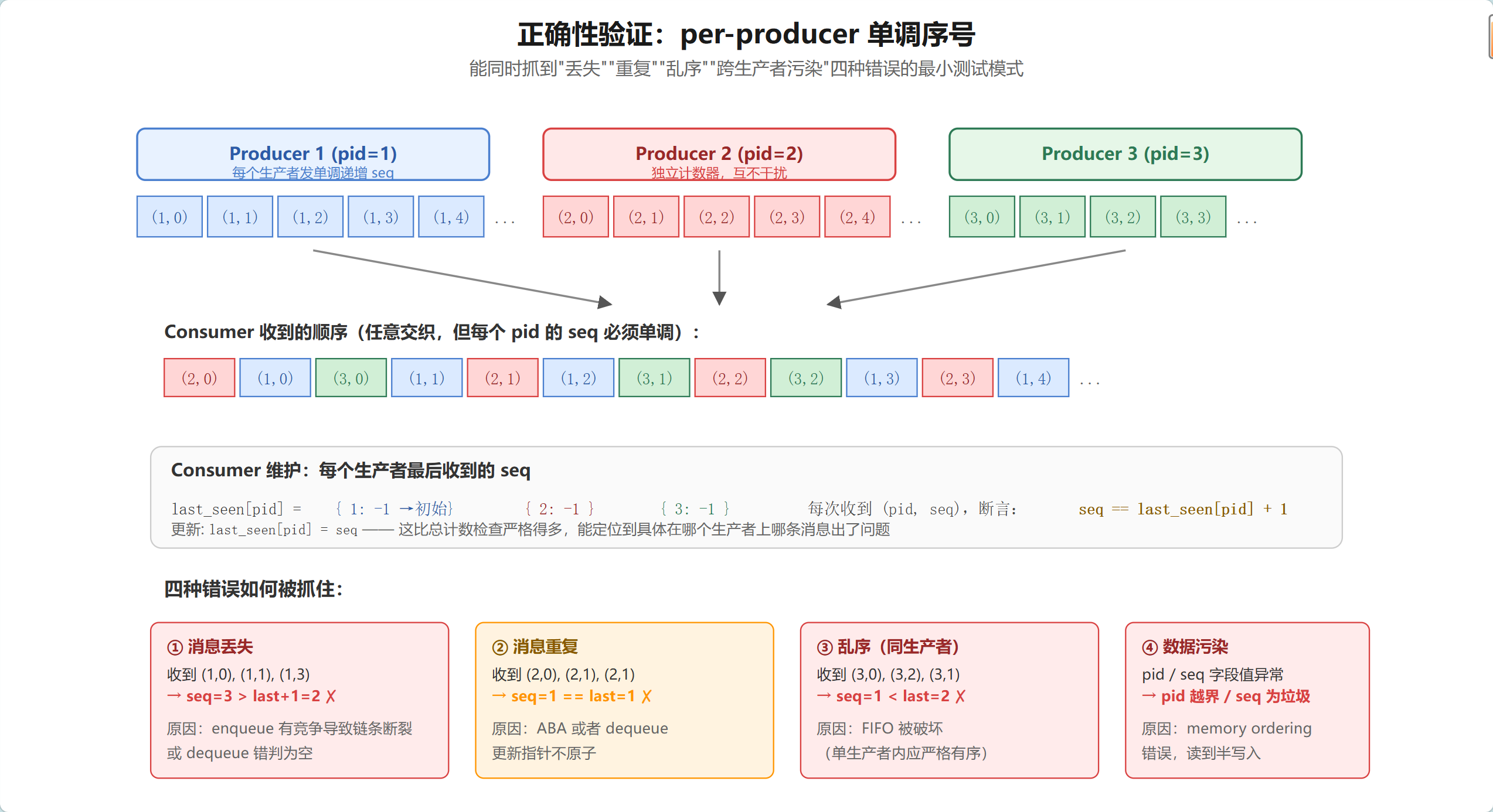
为什么这个方法好?—— 它能同时抓住四种错误:
- 消息丢失:消费者看到某个生产者的 seq 从 3 跳到 5,中间的 4 被吃掉了
- 消息重复:同一个 (pid, seq) 被收到两次
- FIFO 破坏:同一生产者的 seq 非单调(如从 5 倒退到 3)
- 数据污染:pid 越界或 seq 异常 —— 说明读到了半写入的节点
相比之下,只检查总条数(sent==received)的测试是不够的 —— 如果一条消息被丢了、另一条被重复接收了,总数反而是对的。
6.2 验证代码
#include <vector>
#include <atomic>
#include <thread>
#include <cstdio>
#include <cstdlib>
// 验证消息:pid + seq
struct Msg : public VyukovMpscIntrusive::Node {
int pid;
int seq;
};
void verify_mpsc(int n_producers, int per_producer) {
VyukovMpscIntrusive q;
std::vector<std::thread> producers;
for (int pid = 0; pid < n_producers; ++pid) {
producers.emplace_back([&, pid] {
for (int s = 0; s < per_producer; ++s) {
auto* m = new Msg();
m->pid = pid;
m->seq = s;
q.enqueue(m);
}
});
}
std::thread consumer([&] {
// last[pid] = 上次收到的 seq;初始为 -1
std::vector<int> last(n_producers, -1);
int total = n_producers * per_producer;
int received = 0;
while (received < total) {
auto* node = q.dequeue();
if (!node) {
std::this_thread::yield();
continue;
}
auto* m = static_cast<Msg*>(node);
// -------- 四重检查 --------
if (m->pid < 0 || m->pid >= n_producers) {
fprintf(stderr, "污染:pid 越界 %d\n", m->pid);
std::abort();
}
if (m->seq < 0 || m->seq >= per_producer) {
fprintf(stderr, "污染:pid=%d seq 越界 %d\n", m->pid, m->seq);
std::abort();
}
int expected = last[m->pid] + 1;
if (m->seq != expected) {
fprintf(stderr,
"FIFO 违反:pid=%d expected seq=%d, got seq=%d "
"(丢失/重复/乱序)\n",
m->pid, expected, m->seq);
std::abort();
}
last[m->pid] = m->seq;
received++;
delete m;
}
// -------- 收尾检查:每个生产者都应该收到完整的序列 --------
for (int i = 0; i < n_producers; ++i) {
if (last[i] != per_producer - 1) {
fprintf(stderr,
"生产者 %d 未收齐: last=%d, expected=%d\n",
i, last[i], per_producer - 1);
std::abort();
}
}
printf("验证通过:%d 条消息全部按序收到\n", total);
});
for (auto& t : producers) t.join();
consumer.join();
}
6.3 配合 ThreadSanitizer
即便验证测试跑通了,也可能存在数据竞争(两个线程无序地读写同一个非原子变量)。这种 bug 在宽松的 x86 上经常隐而不发,但会在 ARM 上炸掉。Clang/GCC 的 TSan 是排查这类问题的核武器:
g++ -std=c++17 -O1 -g -fsanitize=thread -pthread mpsc_demo.cpp -o mpsc_tsan
./mpsc_tsan --verify
TSan 会在任何数据竞争点打印详细的栈。无锁代码里 TSan 偶尔会误报(比如它不理解某些高级回收协议),但对基础并发错误仍然非常有用。
不过这里要提醒一件很重要的事:看到 TSan 报告,并不等于可以立刻把它翻译成"某个经典并发 bug 的完整因果链"。 像第 2 节这种 old-head reclamation 结构,真正需要你核对的是:
- 报警的地址是不是同一个逻辑节点,还是 allocator 复用了同一块地址;
- consumer 回收旧前驱的前提是否已经满足;
- 这个问题究竟是真实的 use-after-free、地址复用导致的可疑并发写,还是你对队列不变式理解错了。
因此,TSan 在本文里更适合承担两个角色:
- 第一层筛查:抓明显的数据竞争、非原子访问、遗漏的同步;
- 辅助定位:告诉你"这里有并发写/并发读写值得看",但最终定性仍要回到算法不变式本身。
对第 2 节 CAS 教学版,更值得重点验证的是两类问题:
- 断链窗口下的行为:producer 已经推进了
tail_,但prev->next还没补上时,consumer 会不会把"暂时不可见"误判成"真实为空"; - 回收收尾是否完整:最后一个已消费节点会滞留为新的前驱,析构时是否显式释放了这个最终前驱。
所以,TSan 很重要,但不要把它当成自动判案机;它给你的是线索,最终结论仍然要靠时序推演和不变式验证来下。
6.4 更严格的:Relacy Race Detector
TSan 只能检测实际发生的 race,而 Relacy 能穷举所有可能的内存序列来发现潜在的 race。它是一个单头 C++ 库,把你的测试代码放进它的框架里:
#include <relacy/relacy_std.hpp>
// 把原来的 std::atomic 换成 rl::atomic
// 把 std::thread 换成 rl::thread
// 用 $() 包住每个原子操作
Relacy 会模拟各种可能的执行顺序,特别擅长抓 Vyukov 这种"实际 CPU 上几乎不会触发但理论上有风险"的竞争。缺点是写起来很繁琐。工业级 MPSC 实现一般都会过一遍 Relacy。
6.5 压力测试要持续多久?
经验值:
- 几秒钟的跑通只能证明基础逻辑对,说明不了什么
- 10 分钟:能抓到大部分明显的竞争
- 几小时:能抓到极小概率的内存序问题
- 长期 fuzz(几天):能抓到硬件异常引发的边界情况
建议做法:写好验证测试后,在 CI 上跑 30 分钟,并在 ARM/ARM64 机器上至少跑一次(x86 的强内存模型会掩盖很多问题)。
七、常见陷阱自检清单
实现 MPSC 时建议逐项检查:
- stub 节点初始化:空队列时
head == tail == &stub,且stub.next == nullptr -
head和tail分离缓存行:至少相差 64 字节 - enqueue 中
exchange用acq_rel,prev->next.store用release - dequeue 中所有
load用acquire - dequeue 处理断链窗口:
next == nullptr且tail != head时返回空等重试,不要把暂时不可见误判成真正空队列 - dequeue 处理"只剩最后一个节点":re-enqueue stub 逻辑不能缺
- 节点内存归属清晰:侵入式场景下让调用者负责 delete;非侵入式场景要明确 old-head reclamation 的边界
- 析构能收尾:如果最后一个已消费节点会滞留为新前驱,析构函数要显式释放它
- 容量是 2 的幂(数组版),可以用
& mask代替昂贵的% capacity - CAS 循环有退避:至少加个
pause指令 - 有正确性验证测试:per-producer 单调序号 + TSan
- 弱内存模型测试:如果能在 ARM/ARM64 机器上跑一下最好
八、延伸阅读
按推荐顺序:
- Dmitry Vyukov 的 1024cores.net —— 无锁算法圣经级资源,尤其推荐他对 bounded MPMC 和 intrusive MPSC 的分析
- Maged Michael & Scott, “Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms” (1996) —— 奠基性论文,读懂它能把链表 MPMC 也拿下
- Herlihy & Shavit, The Art of Multiprocessor Programming —— 第 10 章专门讲并发队列
- Paul E. McKenney, Is Parallel Programming Hard? —— 对内存模型和 RCU 讲得极透彻,免费 PDF
- moodycamel::ConcurrentQueue 源码 —— C++ 工业级 MPMC 实现,代码注释详尽
- Kogan & Petrank, “Wait-Free Queues With Multiple Enqueuers and Dequeuers” (2011) —— 想深入 wait-free 队列再看

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)