OS69.【Linux】使用线程求和、pthread_self、了解clone系统调用、创建多个线程、线程栈
目录
C++11的thread线程库和Linux的pthread原生线程库有什么关系?
反思: 为什么thread线程库底层用了pthread线程库?
1.知识回顾
2.线程求和代码
新建如下文件:
test_thread/
├── makefile
└── test_thread.cppmakefile写入:
test_thread.out:test_thread.cpp
g++ -o $@ $^ -g -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f test_thread.out主线程创建一个新线程,新线程负责运算,主线程负责取得运算的结果
这里用两个类: Request类和Response类
Request类实例化后的对象存储相加的范围[_start,_end]和线程名称
class Request
{
public:
Request(int start,int end,const std::string& thread_name)
:_start(start)
,_end(end)
,_thread_name(thread_name)
{}
int _start;
int _end;
std::string _thread_name;
};Response类实例化后的对象存储计算结果
class Response
{
public:
Response(int result=0)
:_result(result)
{}
int _result;
};线程函数:
void* sum_routine(void* arg)
{
Request* request=static_cast<Request*>(arg);
Response* response=new Response;
int cnt=0;
for (int i=request->_start;i<=request->_end;i++)
{
cnt+=i;
std::cout<<request->_thread_name<<" : "<<"i="<<i<<std::endl;
}
response->_result=cnt;
delete request;
return response;
}
注意: static_cast用于类型安全的转换
main函数:
int main()
{
pthread_t tid;
Request* request=new Request(1,100,std::string("new thread"));
pthread_create(&tid, nullptr,sum_routine, request);
void* tmp;
pthread_join(tid,&tmp);
Response* retval=static_cast<Response*>(tmp);
std::cout<<"main thread : "<<retval->_result<<std::endl;
delete retval;
return 0;
}上方代码中,主线程new的对象在新线程中也可以用,新线程new的对象在主线程中也可以用,说明堆空间是主线程和新线程共享的
注: static_cast是C++的
运行结果:
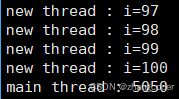
结论: 线程函数参数类型是void*,但是也可以传入对象指针
3.C++11的thread线程库
Linux的原生线程库是pthread,C++11有thread线程库
test_thread.cpp写入:
#include <iostream>
#include <thread>
#include <unistd.h>
void thread_func()
{
int cnt=3;
while(cnt--)
{
std::cout<<"新线程正在运行..."<<std::endl;
sleep(1);
}
}
int main()
{
std::thread new_t(thread_func);
new_t.join();//阻塞等待
std::cout<<"新线程已经退出"<<std::endl;
return 0;
}运行结果:
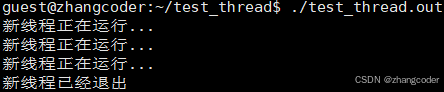
C++11的thread线程库和Linux的pthread原生线程库有什么关系?
运行以下命令:
nm -D /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep pthread注: nm 是一个符号表查看工具,可用于分析目标文件、可执行文件、共享库里的符号, -D是只显示参与动态链接的符号
运行结果:
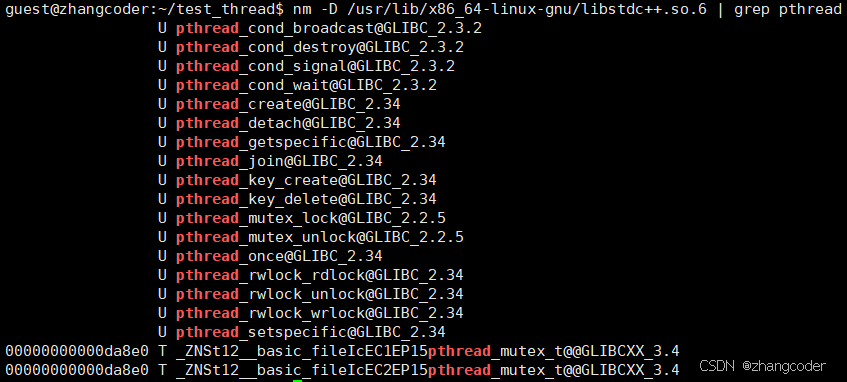
结论
结论: Linux系统,C++11的thread线程库底层用了Linux的pthread原生线程库
反思: 为什么thread线程库底层用了pthread线程库?
Linux系统中已经有成熟的pthread原生线程库,那么C++的thread线程库不需要自己造轮子
C++的线程库具有跨平台性, 推荐用C++上的线程库,这样有可移植性
5.了解clone系统调用
之前在OS68.【Linux】pthread线程库的使用文章说过"Linux内核中没有很明确的线程的概念,只有轻量级进程的概念那么Linux就没有直接提供线程的系统调用,只会给程序员提供轻量级进程的系统调用",例如clone系统调用
这里只看其中一些参数:
参数fn: 函数指针,新的执行流执行的就是fn指向的函数
参数stack: 创建新线程自定义的栈(线程的栈是线程自己私有的)
可以肯定的是: pthread的底层封装了clone系统调用
验证代码
这里不考虑pthread_create和pthread_join执行失败的情况
#include <pthread.h>
#include <string.h>
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
void *start_routine(void*)
{
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr,start_routine, nullptr);
pthread_join(tid,nullptr);
return 0;
}使用strace跟踪代码执行时调用系统调用和信号:
用了clone3系统调用(是clone系统调用的加强版)
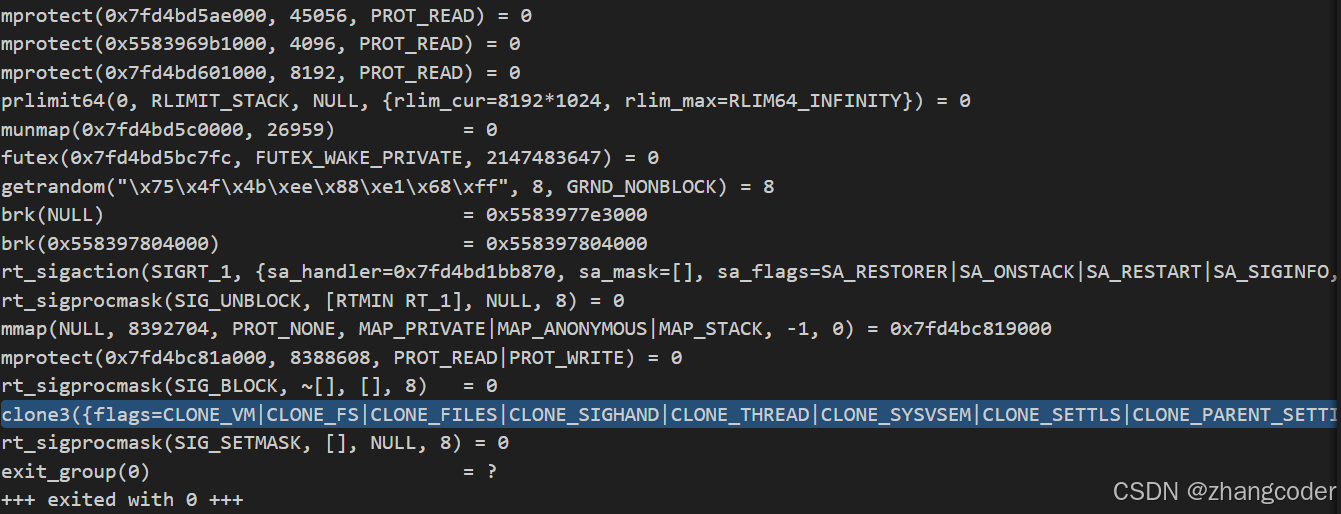
clone3({flags=CLONE_VM|CLONE_FS|CLONE_FILES|
CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|
CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID,
child_tid=0x7fd4bd019910, parent_tid=0x7fd4bd019910,
exit_signal=0, stack=0x7fd4bc819000, stack_size=0x7fff00,
tls=0x7fd4bd019640} => {parent_tid=[181007]}, 88) = 1810076.pthread线程库需要维护线程
程序员使用pthread线程库的各个函数的前提是: pthread线程库需要加载到物理内存中! 之后由操作系统映射到进程地址空间的共享区
Linux操作系统没有线程的概念, 线程id、栈空间(主线程和新线程都有自己私有的栈空间)、线程的回调函数......这些都属于线程的属性Linux操作系统不关心,这些用户级线程的属性由pthread线程库维护,注: pthread线程库不维护线程的执行流
显然pthread线程库需要管理这些线程: 先描述再组织
描述线程可以用线程控制块tcb
在glibc-2.42的/nptl/descr.h定义了线程控制块tcb: struct pthread
限于篇幅,这里只摘取一部分:
struct pthread
{
union
{
#if !TLS_DTV_AT_TP
/* This overlaps the TCB as used for TLS without threads (see tls.h). */
tcbhead_t header;
#else
struct
{
int multiple_threads;
int gscope_flag;
} header;
#endif
void *__padding[24];
};
//......
};其实x86_64下,pthread_self()的返回值tid就是线程控制块struct pthread的地址,因为地址是唯一的,所以满足Tid是唯一的这个要求证明过程参见OS71.【Linux】证明: x86_64,glibc的pthread库中,线程的tid就是线程控制块tcb的起始地址文章
注: 其它架构下,pthread_self()的返回值tid不一定是线程控制块struct pthread的地址
一般情况下,用户级线程的属性存储在线程库内部
如下图:
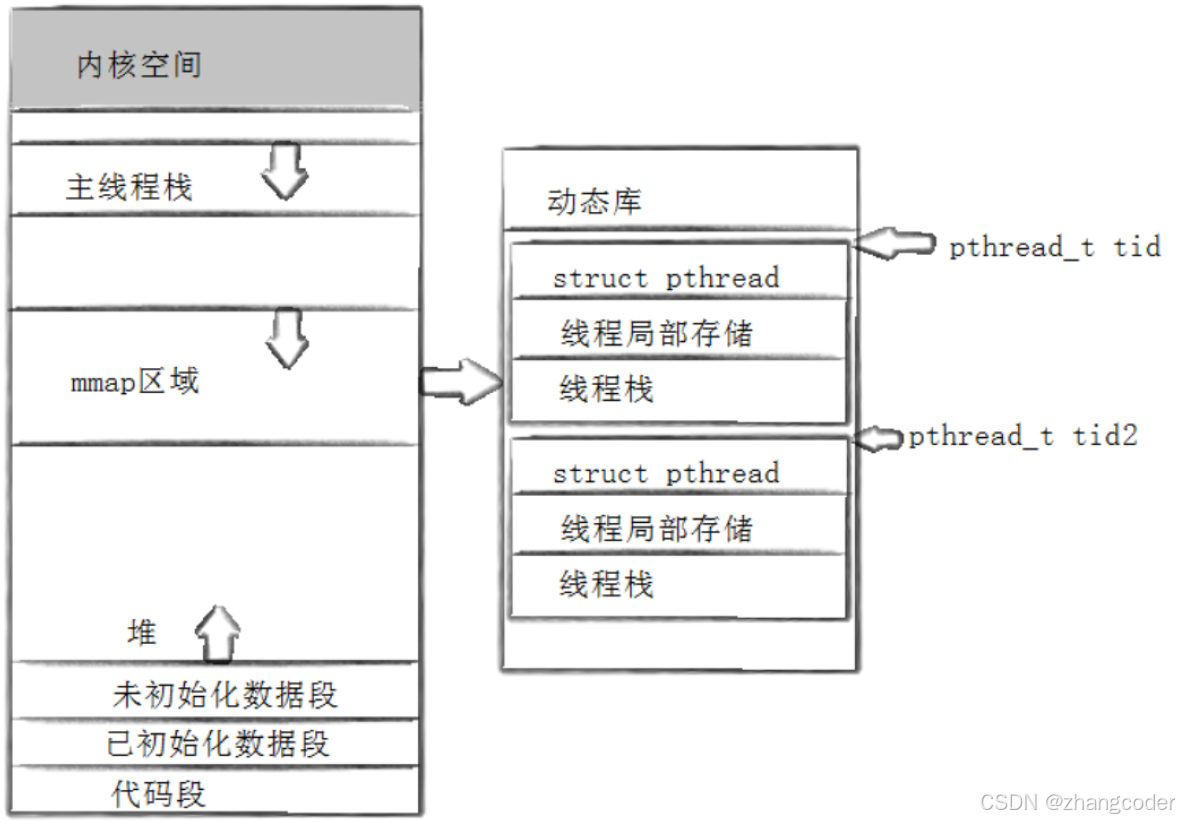
举例线程的私有部分 1.线程的上下文 2.线程的栈
除了主线程(线程库自己是不维护主线程的栈的),所有其他线程的独立栈,都在共享区中,具体来讲是在pthread库中,即tid指向的用户tcb中
7.Linux的线程=用户级线程+内核的LWP
Linux的线程==用户级线程(pthread库)+内核的LWP(轻量级进程)
而且用户级线程:内核的LWP==1:1
8.创建一批线程的方法
之前在OS68.【Linux】pthread线程库的使用文章演示过创建一个线程,这次创建一批线程的方法
主线程需要创建一批线程,主线程等待每个新线程,主线程是最后退出的
创建一批线程的代码
主线程可以将每个新线程的tid暂存起来,方便主线程等待每个新线程
#include <pthread.h>
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <vector>
#define NUM 10
void* thread_routine(void*)
{
sleep(1);
return nullptr;
}
int main()
{
std::vector<pthread_t> tid_arr;
for (int i=1;i<=NUM;i++)
{
pthread_t tid;
pthread_create(&tid, nullptr,thread_routine, nullptr);
tid_arr.push_back(tid);
}
for (auto tid:tid_arr)
{
if (!pthread_join(tid,nullptr))
std::cout<<"主线程成功等待tid为"<<tid<<"的新线程"<<std::endl;
}
return 0;
}注意: 不能写成
运行结果:
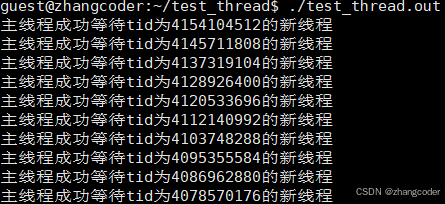
证明: 每个线程都有自己独立的栈结构
要证明每个线程有独立的栈,最直接的办法就是打印它们的RSP寄存器值进行对比,RSP寄存器指向当前栈的栈顶
修改以上代码,让每个线程执行thread_routine时,都打印当前RSP寄存器的值
要获取RSP寄存器的值需要使用内联汇编
#include <pthread.h>
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <vector>
#include <string>
#define NUM 10
void* thread_routine(void* args)
{
unsigned long long rsp_val;
__asm__ volatile ("movq %%rsp, %0" : "=r" (rsp_val));
printf("新线程RSP寄存器的值:0x%llx\n",rsp_val);
return nullptr;
}
int main()
{
std::vector<pthread_t> tid_arr;
std::vector<std::string*> thread_name_arr;
for (int i=1;i<=NUM;i++)
{
pthread_t tid;
std::string* thread_name=new std::string("thread_"+std::to_string(i));
thread_name_arr.push_back(thread_name);
pthread_create(&tid, nullptr,thread_routine, thread_name);
tid_arr.push_back(tid);
}
for (auto tid:tid_arr)
{
if(pthread_join(tid,nullptr))
std::cout<<"主线程等待失败"<<std::endl;
}
for (auto thread_name:thread_name_arr)
delete thread_name;
return 0;
}运行结果:每个新线程打印的RSP寄存器的值都不一样
python脚本处理RSP数据
addresses =
[
"0x7fc470db2e30",
"0x7fc4705b1e30",
"0x7fc46fdb0e30",
"0x7fc46f5afe30",
"0x7fc46edaee30",
"0x7fc46d5abe30",
"0x7fc467ffee30",
"0x7fc46cdaae30",
"0x7fc46e5ade30",
"0x7fc46ddace30"
]
sorted_addresses = sorted(addresses, key=lambda x: int(x, 16))
for addr in sorted_addresses:
print(addr)
int_addresses = [int(addr, 16) for addr in sorted_addresses]
for i in range(1,len(int_addresses)):
print(hex(int_addresses[i]-int_addresses[i-1]))
RSP排序后:
0x7fc46cdaae30
0x7fc46d5abe30
0x7fc46ddace30
0x7fc46e5ade30
0x7fc46edaee30
0x7fc46f5afe30
0x7fc46fdb0e30
0x7fc4705b1e30
0x7fc470db2e30从相邻RSP寄存器值作差结果来推测每个线程栈的近似大小
python脚本运行结果:
0x4dac000
0x801000
0x801000
0x801000
0x801000
0x801000
0x801000
0x801000
0x801000除了第一个0x4dac000,其它都是0x801000,如果各个线程栈在内存中是连续存放的话,那么0x801000(8MB+4KB,按1B=1024KB,1024KB=1MB算)极有可能是每个线程栈的大小
用系统调用获取每个线程栈的大小
线程栈的大小属于线程的属性,需要通过pthread_attr_getstack获取
#include <pthread.h>
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
#include <vector>
#include <string>
#define NUM 10
void* thread_routine(void* args)
{
pthread_attr_t attr;
void *stackaddr;
size_t stacksize;
pthread_getattr_np(pthread_self(), &attr);
pthread_attr_getstack(&attr, &stackaddr, &stacksize);
printf("当前%s线程的栈大小: 0x%lx 字节\n", (*((std::string*)args)).c_str(),stacksize);
pthread_attr_destroy(&attr);
return nullptr;
}
int main()
{
std::vector<pthread_t> tid_arr;
std::vector<std::string*> thread_name_arr;
for (int i=1;i<=NUM;i++)
{
pthread_t tid;
std::string* thread_name=new std::string("thread_"+std::to_string(i));
thread_name_arr.push_back(thread_name);
pthread_create(&tid, nullptr,thread_routine, thread_name);
tid_arr.push_back(tid);
}
for (auto tid:tid_arr)
{
if(pthread_join(tid,nullptr))
std::cout<<"主线程等待失败"<<std::endl;
}
for (auto thread_name:thread_name_arr)
delete thread_name;
return 0;
}运行结果:
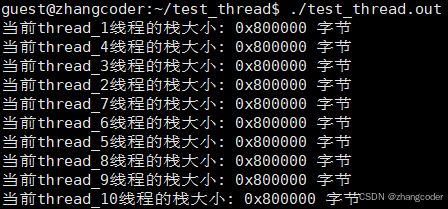
发现估计的0x801000(8MB+4KB)和系统给出的0x800000(8MB)非常接近,仅差一个4KB页的大小,这个差的一个页是glibc库设置的保护页,用于保护相邻线程栈之间的安全,防止栈溢出导致越界访问

在glibc-2.42的/nptl/allocatestack.c中定义了分配线程栈的函数allocate_thread_stack,其中需要提供保护页的大小guardsize:
static void *
allocate_thread_stack (size_t size, size_t guardsize)
{
/* MADV_ADVISE_GUARD does not require an additional PROT_NONE mapping. */
int prot = stack_prot ();
if (atomic_load_relaxed (&allocate_stack_mode) == ALLOCATE_GUARD_PROT_NONE)
/* If a guard page is required, avoid committing memory by first allocate
with PROT_NONE and then reserve with required permission excluding the
guard page. */
prot = guardsize == 0 ? prot : PROT_NONE;
return __mmap (NULL, size, prot, MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1,
0);
}结论
每个线程都有自己独立的栈结构,且各个线程栈在内存中近似连续存放的,"近似"的原因是相邻线程栈之间有保护页,防止栈溢出导致越界访问
→其实线程和线程之间,几乎没有秘密,线程的栈上的数据,也是可以被其他线程看到并访问的(读者可以自己验证),因为进程的地址空间是共享给所有线程的

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)