LLM系列:2.pytorch入门:4.动态计算图与梯度下降入门
动态计算图与梯度下降入门
先复习上一节的autograd.grad和backward方法
一.AutoGrad 的回溯机制与动态计算图
PyTorch 的核心威力在于其自动求导(AutoGrad)模块。它不仅能进行微分运算,更通过一种“回溯机制”记录了张量之间的所有运算关系,从而构建出计算图。
1. 可微分性相关属性
在 PyTorch 中,张量是否参与自动求导由以下两个关键属性决定:
requires_grad:可微分性开关。手动设置为True后,该张量及其后续衍生出的所有张量都将被引擎追踪。grad_fn:导数函数存储器。记录了该张量是通过何种数学运算(算子)得来的。- 叶节点(Leaf Node):用户直接创建的张量(如输入 xxx),其
grad_fn为None。 - 非叶节点:通过运算生成的张量(如 y=x2y = x^2y=x2),其
grad_fn会显示具体的算子(如<PowBackward0>)。
- 叶节点(Leaf Node):用户直接创建的张量(如输入 xxx),其
x = torch.tensor(1.,requires_grad=True)
# tensor(1., requires_grad=True)
y = x**2
# tensor(1., grad_fn=<PowBackward0>)
2. 张量计算图的概念
(1).回溯机制
在PyTorch的张量计算过程中,如果我们设置初始张量是可微的,则在计算过程中,每一个由原张量计算得出的新张量都是可微的,并且还会保存此前一步的函数关系,这也就是所谓的回溯机制。而根据这个回溯机制,我们就能非常清楚掌握张量的每一步计算,并据此绘制张量计算图。
(2).计算图
计算图是将复杂的张量运算抽象为“有向无环图(DAG)”的机制。
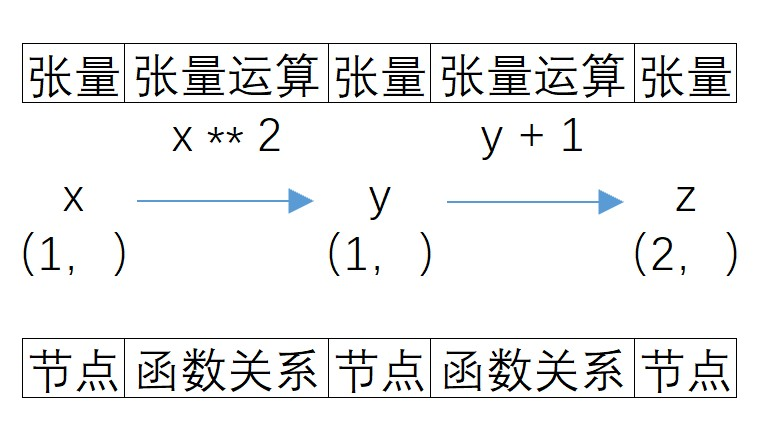
-
节点(Node):表示张量(分为叶节点、中间节点、输出节点)。
在张量计算图中,虽然每个节点都表示可微分张量,但节点和节点之间却略有不同。就像在前例中,y和z保存了函数计算关系,但x没有,而在实际计算关系中,我们不难发现z是所有计算的终点,因此,虽然x、y、z都是节点,但每个节点却并不一样。此处我们可以将节点分为三类,分别是:
- 叶节点,也就是初始输入的可微分张量,前例中x就是叶节点;.
- 输出节点,也就是最后计算得出的张量,前例中z就是输出节点;.
- 中间节点,在一张计算图中,除了叶节点和输出节点,其他都是中间节点,前例中y就是中间节点。.
当然,在一张计算图中,可以有多个叶节点和中间节点,但大多数情况下,只有一个输出节点,若存在多个输出结果,我们也往往会将其保存在一个张量中。
-
有向边(Edge):表示函数运算关系及运算方向。
-
动态性:PyTorch 采用动态计算图,图会随着代码运行自动生成和更新,比静态图更灵活,符合面向对象编程习惯。
二.反向传播与梯度计算
1. 反向传播(Backpropagation)流程
反向传播是利用链式法则求导的过程。
- 执行前提:必须是计算图中的非叶节点(通常是最终的 Loss)。
- 触发函数:调用
.backward()。 - 结果存储:计算出的梯度会存储在叶节点的
.grad属性中。
2. grad 属性详解
grad 属性是理解自动微分结果的核心。我们需要重点掌握以下特性:
- 存储时机:只有在调用了
.backward()之后,对应的叶节点才会生成grad属性值。 - 默认状态:所有张量在创建时
grad属性均为None。 - 数值类型:
x.grad本身也是一个张量(Tensor),其形状(shape)与x完全一致。 - 只读性建议:虽然可以直接手动修改
.grad,但在常规训练流程中,我们应通过backward()自动填充它。
x = torch.tensor(1., requires_grad=True)
y = x ** 2
z = y + 1
z.backward() # 执行反向传播
print(x.grad) # tensor(2.) -> dz/dx = 2*x,当x=1时为2
3. retain_grad() - 保留中间节点梯度
在 PyTorch 动态计算图中,出于对内存占用的极度优化,非叶节点(即中间生成的张量)的梯度在反向传播计算完毕后,会被系统立刻丢弃/释放。这意味着你无法直接通过 .grad 查看中间节点的梯度。
如果出于调试或特殊算法的需求,必须查看中间节点的梯度,就需要在调用 .backward() 之前,对该中间节点调用 .retain_grad() 方法。
x = torch.tensor(1., requires_grad=True)
y = x ** 2
# 声明保留中间节点 y 的梯度
y.retain_grad()
z = y + 1
z.backward() # 执行反向传播
print(x.grad) # tensor(2.) -> dz/dx = 2*x,当x=1时为2
print(y.grad) # tensor(1.) -> dz/dy = 1,因为显式调用了 retain_grad(),所以不为 None
4. grad.zero_() - 梯度清零(原地操作)
梯度累加机制:PyTorch 默认会累加梯度。在循环进行梯度下降时,务必记得使用 .grad.zero_() 清空梯度。
作用:清空当前张量所累积的梯度值,将其全部强制重置为 0。因为 PyTorch 默认在每次调用 .backward() 时,会将新算出的梯度累加 (Accumulate) 到原有的 .grad 属性上,而不是覆盖。为了保证每轮(Batch)训练的梯度都是全新且独立的,在下一轮反向传播之前,必须手动将旧梯度清零。
数学表示:截断历史积累的误差方向,强制令 ∇w=0\nabla w = 0∇w=0。
tensor.grad.zero_()
参数:
- 无参数。
- 避坑提醒:在 PyTorch 中,所有带有下划线结尾的方法(如
zero_(),add_(),fill_())都代表“原地操作 (In-place operation)”。这意味着它不会开辟新的内存空间创建新张量,而是直接在原有内存上擦除旧数据写入新数据,这对于节省显存极其关键。
返回值:
- 返回被清零后的梯度张量自身(全 0 张量)。由于它是原地操作,通常我们不需要用任何变量去接收返回值。
注:调用时机限制:只有当张量经过了至少一次 .backward() 计算,且其 .grad 属性被真正赋值(不再是 None)之后,才能调用此方法。如果张量刚被创建,直接调 x.grad.zero_() 会因为 NoneType 没有 zero_ 方法而报错!
5. 阻止计算图追踪
在模型评估(Evaluation)或推理(Inference)阶段,我们并不需要计算梯度。通过阻断计算图的追踪,可以显著减少内存消耗并加快运算速度。
(1).torch.no_grad():上下文管理器
- 作用范围:全局(该代码块内的所有运算)。
- 特点:在此环境下的所有计算都不会记录在计算图中,输出张量的
requires_grad自动为False。注:只要录像机还开着,你就绝对不能对叶子节点进行原地修改! - 适用场景:验证集测试、测试集推理、或者不需要梯度更新的参数处理。
(2).detach():创建一个不可导的相同张量
- 作用范围:局部(针对特定张量)。
- 特点:创建一个与原张量共享内存空间(存储区一致)但
requires_grad=False的新张量。 - 避坑提醒:由于是共享内存,修改分离后的张量也会影响原张量的值,但它不再拥有
grad_fn,从计算图中脱离。
示例:
x = torch.tensor(1.0, requires_grad=True)
# 1. 使用 torch.no_grad() 阻断块内追踪
with torch.no_grad():
y = x * 2
print(y.requires_grad) # False
print(y.grad_fn) # None
# 2. 使用 .detach() 分离特定张量
z = x.detach()
print(z.requires_grad) # False
print(x.requires_grad) # True (原张量不受影响)
# 3. 证明共享内存
z.fill_(5.0)
print(x) # tensor(5., requires_grad=True) -> 值被同步修改了
6. 识别叶节点
在 PyTorch 的计算图中,判定一个张量是否为“叶节点(Leaf Node)”主要通过 is_leaf 属性。了解叶节点的判定规则对于理解梯度回传和内存管理至关重要。
(1).is_leaf 属性判定规则
叶节点的两种核心情况:
- 用户创建的张量:所有手动创建且设置了
requires_grad=True的张量。 - 不需梯度的张量:所有
requires_grad=False的张量(无论它是手动创建的还是通过运算生成的),在计算图中都会被视为叶节点。
非叶节点通常是指:
- 通过函数/算子运算生成的,且其
requires_grad=True的张量(这类张量会拥有grad_fn)。
其实只要是手动创建的无论requires_grad是什么is_leaf 都是true
(2).示例:
x = torch.tensor(1., requires_grad=True) # 用户创建,且需要梯度
y = x ** 2 # 运算生成,且继承了需要梯度
print(x.is_leaf) # True (叶节点:梯度回传的终点/起点)
print(y.is_leaf) # False (中间节点:梯度计算的路径,默认不保存梯度)
# 特殊情况:detach 或 no_grad
z = y.detach()
print(z.is_leaf) # True (因为 requires_grad=False,被强制识别为叶节点)
三.梯度下降算法原理
1. 最小二乘法的局限与岭回归优化
在所有的优化算法中最小二乘法虽然高效并且结果精确,但也有不完美的地方,核心就在于最小二乘法的使用条件较为苛刻,要求特征张量的交叉乘积(XTX)(X^TX)(XTX)结果必须是满秩矩阵,才能进行求解。而在实际情况中,很多数据的特征张量并不能满足条件,此时就无法使用最小二乘法进行求解。
最小二乘法结果:w^=(XTX)−1XTy\boldsymbol{\hat{w} = (X^TX)^{-1}X^Ty}w^=(XTX)−1XTy
- w^\boldsymbol{\hat{w}}w^ (权重向量/Weight Vector): 模型最终需要求出的未知参数列向量。它包含了所有特征对应的权重系数 (w1,w2,...,wd)(w_1, w_2, ..., w_d)(w1,w2,...,wd) 以及截距/偏置项 bbb。
- X\boldsymbol{X}X (特征矩阵/Feature Matrix): 包含了所有已知样本数据的输入特征。每一行代表一个独立的样本数据,每一列代表一种特征(为了方便矩阵计算,通常会在最右侧人为追加一列全为 111 的列来捕捉截距 bbb)。
- y\boldsymbol{y}y (目标向量/Target Vector): 包含了所有已知样本数据对应的真实输出标签/结果(列向量)。
当最小二乘法失效的情况时,其实往往也就代表原目标函数没有最优解或最优解不唯一。针对这样的情况,有很多中解决方案,例如,我们可以在原矩阵方程中加入一个扰动项λI\lambda IλI,修改后表达式如下:
w^T∗=(XTX+λI)−1XTy\hat w ^{T*} = (X^TX + \lambda I)^{-1}X^Tyw^T∗=(XTX+λI)−1XTy
其中,λ\lambdaλ是扰动项系数,III是单元矩阵。由矩阵性质可知,加入单位矩阵后,(XTX+λI)(X^TX + \lambda I)(XTX+λI)部分一定可逆(因为单位阵一定可逆),而后即可直接求解w^T∗\hat w^{T*}w^T∗,这也就是岭回归的一般做法。
当然,上式修改后求得的结果就不再是全域最小值,而是一个接近最小值的点。鉴于许多目标函数本身也并不存在最小值或者唯一最小值,在优化的过程中略有偏差也是可以接受的。
**随着深度学习的逐渐深入,我们会发现,最小值并不唯一存在才是目标函数的常态。**基于此情况,很多根据等式形变得到的精确的求解析解的优化方法(如最小二乘)就无法适用,此时我们需要寻找一种更加通用的,能够高效、快速逼近目标函数优化目标的最优化方法。在机器学习领域,最通用的求解目标函数的最优化方法就是著名的梯度下降算法。
2. 梯度 (Gradient)
- 物理意义:梯度把所有方向的偏导数打包在了一起,形成了一个向量(有方向的箭头)。这个箭头在空间中永远指向函数值上升最快的方向。(反过来说,梯度的反方向,就是你做“梯度下降”找 Loss 最小值的方向)。
- 数学表达:∇f(x1,x2,…,xd)=[∂f∂x1∂f∂x2⋮∂f∂xd]\nabla f(x_1, x_2, \dots, x_d) = \begin{bmatrix} \frac{\partial f}{\partial x_1} \\ \frac{\partial f}{\partial x_2} \\ \vdots \\ \frac{\partial f}{\partial x_d} \end{bmatrix}∇f(x1,x2,…,xd)= ∂x1∂f∂x2∂f⋮∂xd∂f
- 结果形态:它是一个列向量!
3. 核心思想
我们通常指的梯度下降算法,并不是某一个算法,而是某一类依照梯度下降基本理论基础展开的算法簇,包括梯度下降算法、随机梯度下降算法、小批量梯度下降算法等等。接下来,我们就从最简单的梯度下降入手,讲解梯度下降的核心思想和一般使用方法。
梯度下降是一种通用的最优化算法,旨在通过迭代运算,从随机初始点出发,顺着梯度相反的方向不断逼近目标函数的最小值。
4. 数学表达式
wnew=wold−η⋅∇f(w)\boldsymbol{w}_{new} = \boldsymbol{w}_{old} - \eta \cdot \nabla f(\boldsymbol{w})wnew=wold−η⋅∇f(w)
其中:
- η\etaη (Eta):学习率(Learning Rate),决定步长大小。
- ∇f(w)\nabla f(\boldsymbol{w})∇f(w):梯度,函数在当前点增长最快的方向。
5. 损失函数的修正与标准迭代流程
出于加快迭代收敛速度的目标,我们在定义梯度下降的损失函数 LLL 时,通常会在原误差平方和 (SSE) 的基础上进行比例修正。
新的损失函数定义为:
L(w1,w2,...,wd,b)=12mSSE=12MSEL(w_1,w_2,...,w_d,b) = \frac{1}{2m}SSE = \frac{1}{2}MSEL(w1,w2,...,wd,b)=2m1SSE=21MSE
(其中,mmm 为样本个数。除以 mmm 是为了消除样本数量对损失值绝对大小的影响;除以 222 则是为了在后续求导时,刚好能与平方项产生的常数 222 互相抵消,极大简化计算流程)
-
MSE叫均方误差
MSE定义为:L(w1,w2,...,wd,b)=1mSSEL(w_1,w_2,...,w_d,b) = \frac{1}{m}SSEL(w1,w2,...,wd,b)=m1SSE
展开后的损失函数具体表现为:
L(w1,w2,...,wd,b)=12m∑j=1m(f(x1(j),x2(j),...)−yj)2L(w_1,w_2,...,w_d,b) = \frac{1}{2m}\sum_{j=1}^{m}(f(x_1^{(j)}, x_2^{(j)}, ...) - y_j)^2L(w1,w2,...,wd,b)=2m1j=1∑m(f(x1(j),x2(j),...)−yj)2
梯度下降的 3 步迭代流程:
在开始梯度下降求解参数之前,我们首先需要设置一组参数的初始取值 (w1,w2...,wd,b)(w_1, w_2..., w_d, b)(w1,w2...,wd,b),以及学习率 α\alphaα(或称 η\etaη)。然后即可执行迭代运算,其中每一轮迭代过程必须严格执行以下三步:
-
计算梯度表达式
对于任意一个参数 wiw_iwi,其梯度计算表达式如下:
∂∂wiL(w1,w2...,wd,b)\frac{\partial}{\partial w_i}L(w_1, w_2..., w_d, b)∂wi∂L(w1,w2...,wd,b)
-
计算迭代移动距离
用学习率 α\alphaα 乘以损失函数梯度,得到该参数本轮应该移动的距离:
α∂∂wiL(w1,w2...,wd,b)\alpha \frac{\partial}{\partial w_i}L(w_1, w_2..., w_d, b)α∂wi∂L(w1,w2...,wd,b)
-
更新参数
用原参数减去 Step 2 中计算得到的距离,更新所有的参数 www:
wi=wi−α∂∂wiL(w1,w2...,wd,b)w_i = w_i - \alpha \frac{\partial}{\partial w_i}L(w_1, w_2..., w_d, b)wi=wi−α∂wi∂L(w1,w2...,wd,b)
什么是迭代与停止条件?
- 迭代的本质:更新完所有参数后,即完成了一轮的迭代。接下来就能以新的一组 wiw_iwi (上一轮的计算结果) 作为下一轮计算的初始值,继续循环上述三步。
- 何时停止迭代? 一般来说有两种情况:
- 设置最大迭代次数 (Epochs):到达设定的迭代次数即强制停止迭代。
- 设置收敛区间 (阈值):即当某两次迭代过程中,每个 wiw_iwi 更新的数值(移动距离)都小于某个预设的极小值时,证明模型已基本不再变化,则停止迭代。
6. 矩阵解析推导
将上述的代数迭代公式转化为矩阵乘法运算,基于修正后的损失函数 L=12mSSE=12m∣∣y−Xw^∣∣22L = \frac{1}{2m}SSE = \frac{1}{2m}||y - X\hat{w}||_2^2L=2m1SSE=2m1∣∣y−Xw^∣∣22,其对权重向量 w^\hat{w}w^ 的梯度矩阵推导为:∇f(w^)=1mXT(Xw^−y)\nabla f(\hat{w}) = \frac{1}{m} X^T(X\hat{w} - y)∇f(w^)=m1XT(Xw^−y)
代入参数更新的迭代公式 w^new=w^old−α⋅∇f(w^old)\boldsymbol{\hat{w}_{new}} = \boldsymbol{\hat{w}_{old}} - \alpha \cdot \nabla f(\boldsymbol{\hat{w}_{old}})w^new=w^old−α⋅∇f(w^old),即可得到矩阵解析迭代公式:
w^new=w^old−α⋅1mXT(Xw^old−y)\boldsymbol{\hat{w}_{new}} = \boldsymbol{\hat{w}_{old}} - \alpha \cdot \frac{1}{m}X^T(X\boldsymbol{\hat{w}_{old}} - y)w^new=w^old−α⋅m1XT(Xw^old−y)
公式中各关键参数的含义说明:
- L\boldsymbol{L}L 或 L(w^)\boldsymbol{L(\hat{w})}L(w^):损失函数 (Loss Function)。
- m\boldsymbol{m}m:样本总数,即参与计算的数据条数。
- y\boldsymbol{y}y:真实标签向量,形状为 m×1m \times 1m×1 的列向量,包含所有样本的真实输出值。
- X\boldsymbol{X}X:特征矩阵 (Feature Matrix),形状为 m×(d+1)m \times (d+1)m×(d+1) 的矩阵(包含 ddd 个特征,且通常外加一列全 111 用于计算截距/偏置 bbb)。它的每一行代表一个独立样本的特征。
- w^\boldsymbol{\hat{w}}w^:权重参数列向量,形状为 (d+1)×1(d+1) \times 1(d+1)×1,包含了所有的待优化参数(包括各个特征的权重 wiw_iwi 以及截距 bbb)。w^old\boldsymbol{\hat{w}_{old}}w^old 代表本轮迭代前的旧参数,w^new\boldsymbol{\hat{w}_{new}}w^new 代表更新后的新参数。
- Xw^\boldsymbol{X\hat{w}}Xw^:预测值向量,即当前模型对所有 mmm 个样本的预测结果向量。
- (Xw^−y)\boldsymbol{(X\hat{w} - y)}(Xw^−y):误差向量 (Error Vector),即模型预测值与真实值之间的差值。
- α\boldsymbol{\alpha}α:学习率 (Learning Rate),决定了参数更新时每次迈出的步长大小(等同于前文提到的 η\etaη)。
- ∇f(w^)\boldsymbol{\nabla f(\hat{w})}∇f(w^):梯度向量,损失函数对所有参数求偏导后组合而成的列向量,代表函数值上升最快的方向。
下面给出 L=12mSSE=12m∣∣y−Xw^∣∣22L = \frac{1}{2m}SSE = \frac{1}{2m}||y - X\hat{w}||_2^2L=2m1SSE=2m1∣∣y−Xw^∣∣22到∇f(w^)=1mXT(Xw^−y)\nabla f(\hat{w}) = \frac{1}{m} X^T(X\hat{w} - y)∇f(w^)=m1XT(Xw^−y)的推导全过程
已知目标函数(修正后的损失函数):
L(w^)=12m∣∣y−Xw^∣∣22L(\hat{w}) = \frac{1}{2m} ||y - X\hat{w}||_2^2L(w^)=2m1∣∣y−Xw^∣∣22推导目标:求 LLL 对列向量 w^\hat{w}w^ 的导数(梯度):
∇f(w^)=∂L∂w^=1mXT(Xw^−y)\nabla f(\hat{w}) = \frac{\partial L}{\partial \hat{w}} = \frac{1}{m} X^T(X\hat{w} - y)∇f(w^)=∂w^∂L=m1XT(Xw^−y)Step 1. 将 L2 范数平方展开为矩阵乘法
根据矩阵性质,一个列向量 vvv 的 L2 范数平方等于它的转置乘以它自己:∣∣v∣∣22=vTv||v||_2^2 = v^Tv∣∣v∣∣22=vTv。
我们将 v=(y−Xw^)v = (y - X\hat{w})v=(y−Xw^) 代入:
L(w^)=12m(y−Xw^)T(y−Xw^)L(\hat{w}) = \frac{1}{2m} (y - X\hat{w})^T(y - X\hat{w})L(w^)=2m1(y−Xw^)T(y−Xw^)根据转置的分配律 (A−B)T=AT−BT(A - B)^T = A^T - B^T(A−B)T=AT−BT,以及矩阵乘法转置律 (AB)T=BTAT(AB)^T = B^TA^T(AB)T=BTAT,将括号展开:
L(w^)=12m(yT−w^TXT)(y−Xw^)L(\hat{w}) = \frac{1}{2m} (y^T - \hat{w}^TX^T)(y - X\hat{w})L(w^)=2m1(yT−w^TXT)(y−Xw^)
L(w^)=12m(yTy−yTXw^−w^TXTy+w^TXTXw^)L(\hat{w}) = \frac{1}{2m} (y^Ty - y^TX\hat{w} - \hat{w}^TX^Ty + \hat{w}^TX^TX\hat{w})L(w^)=2m1(yTy−yTXw^−w^TXTy+w^TXTXw^)Step 2. 合并中间的标量项
观察展开式中间的两项:yTXw^y^TX\hat{w}yTXw^ 和 w^TXTy\hat{w}^TX^Tyw^TXTy。
由于它们的结果最终都是表示“误差平方和”的一部分,其计算结果必定是一个实数(标量)(维度为 1×11 \times 11×1)。
在矩阵代数中,一个标量的转置等于它本身。 因此:
(yTXw^)T=w^TXTy(y^TX\hat{w})^T = \hat{w}^TX^Ty(yTXw^)T=w^TXTy
这意味着中间两项其实是完全相等的。我们可以将它们合并为一项(通常保留 w^T\hat{w}^Tw^T 在前的形式以便于后续套用求导公式):
L(w^)=12m(yTy−2w^TXTy+w^TXTXw^)L(\hat{w}) = \frac{1}{2m} (y^Ty - 2\hat{w}^TX^Ty + \hat{w}^TX^TX\hat{w})L(w^)=2m1(yTy−2w^TXTy+w^TXTXw^)Step 3. 利用矩阵求导法则逐项求导
接下来,我们对式子中的每一项关于列向量 w^\hat{w}w^ 求导。
前置复习:必备的两个矩阵求导公式
- 线性项法则:∂(w^Ta)∂w^=a\frac{\partial (\hat{w}^T a)}{\partial \hat{w}} = a∂w^∂(w^Ta)=a (其中 aaa 是常数列向量)
- 二次项法则:∂(w^TAw^)∂w^=(A+AT)w^\frac{\partial (\hat{w}^T A \hat{w})}{\partial \hat{w}} = (A + A^T)\hat{w}∂w^∂(w^TAw^)=(A+AT)w^。如果常数矩阵 AAA 是对称矩阵(即 A=ATA = A^TA=AT),则结果化简为 2Aw^2A\hat{w}2Aw^。
现在,对常数 12m\frac{1}{2m}2m1 内部的三项分别求导:
- 第一项 yTyy^TyyTy:不包含变量 w^\hat{w}w^,视为常数,导数为 000。
- 第二项 −2w^TXTy-2\hat{w}^TX^Ty−2w^TXTy:这是一个线性项。把 (XTy)(X^Ty)(XTy) 看作常数向量 aaa,套用线性项法则:
∂(−2w^TXTy)∂w^=−2XTy\frac{\partial (-2\hat{w}^TX^Ty)}{\partial \hat{w}} = -2X^Ty∂w^∂(−2w^TXTy)=−2XTy- 第三项 w^TXTXw^\hat{w}^TX^TX\hat{w}w^TXTXw^:这是一个二次项。把 (XTX)(X^TX)(XTX) 看作常数矩阵 AAA。由于任意矩阵乘以自身的转置一定是对称矩阵(即 (XTX)T=XTX(X^TX)^T = X^TX(XTX)T=XTX),套用对称矩阵的二次项法则:
∂(w^TXTXw^)∂w^=2XTXw^\frac{\partial (\hat{w}^TX^TX\hat{w})}{\partial \hat{w}} = 2X^TX\hat{w}∂w^∂(w^TXTXw^)=2XTXw^Step 4. 汇总求导结果并化简
将上述三项的导数结果放回原式,并乘以外面的常数 12m\frac{1}{2m}2m1:
∂L∂w^=12m(0−2XTy+2XTXw^)\frac{\partial L}{\partial \hat{w}} = \frac{1}{2m} \Big( 0 - 2X^Ty + 2X^TX\hat{w} \Big)∂w^∂L=2m1(0−2XTy+2XTXw^)提取括号内的公因数 222 与外面的 12m\frac{1}{2m}2m1 约分抵消:
∂L∂w^=1m(−XTy+XTXw^)\frac{\partial L}{\partial \hat{w}} = \frac{1}{m} ( -X^Ty + X^TX\hat{w} )∂w^∂L=m1(−XTy+XTXw^)调换顺序,并提取公因式 XTX^TXT:
∂L∂w^=1m(XTXw^−XTy)\frac{\partial L}{\partial \hat{w}} = \frac{1}{m} (X^TX\hat{w} - X^Ty)∂w^∂L=m1(XTXw^−XTy)
∇f(w^)=1mXT(Xw^−y)\nabla f(\hat{w}) = \frac{1}{m} X^T(X\hat{w} - y)∇f(w^)=m1XT(Xw^−y)
7. 最小二乘法 vs 梯度下降
- 最小二乘法:直接通过公式求解解析解,要求矩阵满秩,计算量大(涉及求逆),但结果精确。
- 梯度下降:通过迭代寻找数值解。不要求矩阵满秩,适用于极大规模数据和复杂的非线性目标函数,是深度学习的灵魂。
8. 算法家族分类
- BGD (Batch Gradient Descent):全量梯度下降。每次更新使用全部数据,稳定但慢。
- SGD (Stochastic Gradient Descent):随机梯度下降。每次仅用一条数据,快但震荡剧烈。
- Mini-batch GD:小批量梯度下降。折中方案,是目前深度学习最常用的训练方式。
四.动手实现梯度下降(简易版)
# 以MSE均方误差为例
# 1. 准备数据和模型
# 点(1,2),(2,4);模型:y=wx+b
# X:第1列是特征x,第2列是常数项 1
X = torch.tensor([[1., 1.], # 样本1:特征x=1, 常数项=1
[2., 1.]], # 样本2:特征x=2, 常数项=1
requires_grad=False)
y = torch.tensor([[2.], # 样本1的真实值 y=2
[4.]]) # 样本2的真实值 y=4
# 根据X * w的矩阵乘法:
w = torch.tensor([[0.], # 对应斜率 w1 (因为 X 的第1列是 x)
[0.]], # 对应截距 b (因为 X 的第2列是 1)
requires_grad=True)
# 2. 设置超参数
lr = 0.1
epochs = 1000
# 3. 迭代训练
for i in range(epochs):
y_hat = X.mm(w)
loss = torch.mean((y - y_hat)**2) #(y-y_hat)**2等于torch.pow((y-y_hat),2)
loss.backward()
with torch.no_grad():
w -= lr * w.grad
w.grad.zero_()
# 必须加 torch.no_grad()!相当于反向传播算完账后关掉计算图录像机。
# 如果不加,就无法对叶子节点进行原地修改(w -=)。因为引擎为了保证计算图的纯洁性,
# 严禁在记录过程中篡改源头数据,否则会直接引发RuntimeError导致程序崩溃。
# (如果改成异地修改 w = w - ...,则会让计算图无限展开,最终撑爆显存)
print("训练后的权重 [w1, b]^T:\n", w)
# 训练后的权重 [w1, b]^T:
# tensor([[2.0000e+00],
# [1.6615e-06]], requires_grad=True)
总结:梯度下降的本质是利用 AutoGrad 提供的导数信息,不断修正权重 www,使得预测值与真实值之间的差距(Loss)达到最小。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)