论文阅读:G-REASONER: FOUNDATION MODELS FOR UNIFIED REASONING OVER GRAPH-STRUCTURED KNOWLEDGE
G-reasoner:面向图结构知识统一推理的基础模型
发表于ICLR 2026(国际学习表征会议,AI / 机器学习顶会)
1. 摘要
大语言模型(LLMs)虽然在复杂推理任务上表现很好,但是它们内部参数中存储的知识(parametric knowledge)是静态的(static)不完整的(incomplete)。
检索增强生成(RAG)通过引入外部知识缓解了这一问题,但现有 RAG 在知识密集型任务中表现不佳,原因是信息碎片化、知识结构建模能力弱。
图是建模知识间关联的天然方式,但 LLM 天生是无结构的,无法有效对图结构数据进行推理。
近期的图增强 RAG(GraphRAG)尝试通过构建定制化图、让 LLM 在图上推理来弥补这一差距。然而,这类方法往往依赖特设图设计、启发式搜索或高成本的智能体流水线,阻碍了可扩展性与泛化性。
为解决这些问题,我们提出 G-reasoner:一个融合图基础模型与语言基础模型的统一框架,实现对多样图结构知识的可扩展推理。
本方法的核心是QuadGraph(四层图抽象),它将异构知识源统一为标准的图表示。
在此基础上,我们提出一个3400 万参数的图基础模型(GFM),同时建模图拓扑与文本语义,并与 LLM 结合提升下游任务推理能力。为保证可扩展性与效率,我们采用混合精度训练与分布式消息传递机制,让 GFM 可在多 GPU 上扩展。
在 6 个基准数据集上的大量实验表明:G-reasoner 持续优于当前最优基线,显著提升 LLM 推理能力,同时具备高效性与跨图泛化能力。
逻辑链:
- LLM 缺点:知识记在参数里,过时、不全 → 用 RAG 查外部知识
- RAG 缺点:知识是零散文本,没结构 → 用 GraphRAG 把知识变成图
- GraphRAG 缺点:图是定制的、推理慢 / 贵、不能通用 → 我们做统一图 + 轻量图基础模型
- 最终效果:通用、高效、效果好
- 静态的(static)意味着:训练完以后知识不会自动更新。例如:GPT训练时不知道昨天发生的新闻。
- 不完整的(incomplete)意味着:模型参数里不可能装下所有知识。尤其:医疗知识、法律知识、企业私有知识经常缺失。
- Parametric Knowledge(参数知识)和外部知识区别:
类型 存哪里 Parametric knowledge(知识存在模型参数里) 模型参数 External knowledge 外部数据库
RAG:Question→Retrieve(检索)→Generate(生成)
问题1:信息碎片化(fragmented information)知识散落在很多地方。
例如:一个问题:“苹果为什么成为科技巨头?”
信息可能分散在:财报、产品文档、新闻、知识图谱
普通RAG只找几篇文本、容易漏掉关联信息。
问题2:知识结构建模能力弱(这是核心)
RAG会找文本,但不会建模:“知识和知识之间关系”
例如:Steve Jobs→创立→Apple→发布→iPhone 这是图结构。
普通RAG不会利用这种结构。
作者想说:传统RAG:只会搜文本。不会利用知识间连接。这是问题。
既然知识天然是图(知识图谱),那推理也应该在图上做。
但LLM本质是非结构化的(unstructured)不擅长处理图结构数据。
Transformer擅长:文本序列:word1、word2、word3
但图:节点乱连接:不是序列、是网络。Transformer天生不适合。
这也是:为什么需要:GNN(Graph Neural Network)
GNN :图神经网络
一个节点,吸收邻居信息:Neighbor message passing
比如:Apple节点:吸收:Steve Jobs、iPhone、financial report 的信息。更新自己表示。
GraphRAG:本质:RAG + 图结构。
普通RAG:Query→检索文档→LLM回答
GraphRAG:Query→构建图→在图上检索/推理→LLM回答
区别:从“文本检索”升级成:“结构化图推理”。
举例:问题:“乔布斯创立的公司发布了什么手机?”
普通RAG:可能搜:乔布斯文章、iPhone文章,未必关联起来。
GraphRAG:图:Steve Jobs→ founded→Apple→ released→iPhone
图上两跳:就推出来。这叫:Multi-hop reasoning(多跳推理)
问题1:ad-hoc graph design 临时拼凑图设计(图结构不统一)
意思:每篇GraphRAG:都自己造图。没有统一标准。
比如:HippoRAG:知识图谱;GraphRAG(MS):层次图;LightRAG:文档图;Youtu-GraphRAG:属性图。大家图长得都不一样。
问题:模型只能适配自己的图。换个图:完蛋。这叫:不能泛化(Generalization差)
作者为什么提出 QuadGraph?就是解决这个。统一所有图。
问题2:heuristic search 启发式搜索(只是搜索)
很多GraphRAG:其实不是神经网络推理。只是:图搜索。
比如:PageRank、BFS、neighbor expansion
本质:规则搜索。不是学习出来的推理。问题:规则死板。不够强。
作者意思:这不叫Foundation Model推理。这只是搜索。
这也是作者为什么搞:Graph Foundation Model
问题3:costly agent pipelines 昂贵Agent Pipeline(Agent成本高)
这说的是:Agent-based GraphRAG。比如:ToG、Think-on-Graph、KAG
流程:LLM:想一步→调工具→查图→再想一步→再调工具→反复循环。
这叫:Agent Pipeline。为什么贵?因为:每一步:都调用一次LLM。可能几十轮。推理成本爆炸。而且:很慢。latency高。
这是作者批评:Scalability差。不能扩展。
我们提出:G-reasoner
统一:图基础模型Graph Foundation Model 和 语言基础模型 LLM 一起做推理。
以前:LLM负责推理。图只是辅助检索。
现在:图本身也会推理。然后辅助LLM。
变成:图模型先推理→结果交给LLM→LLM生成答
这是论文最大创新之一:QuadGraph 四层图结构。统一所有知识。分四层:
Layer 1:Attribute layer 属性层
比如:iPhone:color、price、size
Layer 2:Knowledge graph layer 知识图谱层
实体关系:Apple→release→iPhone
Layer 3:Document layer 文档层
原始文本:新闻、论文、财报
Layer 4:Community layer社区层
更高层抽象:Tech companies 作为Apple所属社区。
这四层:统一所有GraphRAG。这是很重要创新。
他们训练了:3400万参数Graph Foundation Model(简称:GFM)
它负责:同时建模:图结构+文本语义
这比普通GNN强。因为普通GNN只看图结构。它同时看:图 + 文本。
类比:LLM是Text Foundation Model文本基础模型。它学:语言规律、推理能力、通用能力
GFM是:Graph Foundation Model图基础模型。
它学:图结构规律、图上的推理能力、通用图任务能力
为什么不是普通GNN?因为普通GNN:通常:一个任务一个模型。
比如:节点分类:训练一个。链路预测:再训练一个。很专用。不是基础模型。
而GFM:想像LLM一样:一次预训练,多任务通用。这叫:Foundation Model。
1 图拓扑(Graph topology)就是:谁连着谁。结构关系。
2 文本语义(Text semantics)节点还有文字。比如:Apple节点:“Apple is a multinational tech company…”边也有文字:founded by、released。这些语义也要理解。
jointly captures 联合建模。同时看:图结构 + 文字语义。这比普通GNN厉害。
普通GNN:只看:A连接B。但不知道:Apple是什么。
GFM:知道:Apple是科技公司;还知道:Apple连接iPhone。
同时利用:结构+语义推理。
举例:问题:“乔布斯创立的公司发布了什么?”
只看结构:Jobs->Apple->iPhone。可以推:iPhone
只看文本:苹果发布了手机。也能猜。
两个一起看:更稳。更强。这就是:joint reasoning。
integrated with LLMs。意思:GFM不是替代LLM。而是辅助LLM。
流程:用户问题→先交给GFM、GFM在图上推理→找重要节点→喂给LLM→LLM生成最终答案。
所以:GFM负责:图推理。LLM负责:语言生成。分工明确。
(1)Mixed Precision Training 混合精度训练。
正常训练:参数:float32。32位。很占显存。
混合精度:有些用:float16 或者 bfloat16。显存减半。训练更快。
论文说:吞吐:+111%。内存:-17.5%(Figure 3)这是工程优化。
(2)Distributed Message Passing 分布式消息传递机制
什么是message passing。GNN核心:节点更新:要收邻居消息:
Apple节点:收:Steve Jobs、iPhone、财报节点、信息。这叫:message passing
问题:如果图特别大:放不下一张GPU。怎么办?作者:拆图。
比如:GPU1:负责左半图。GPU2:负责右半图。各算各的。
但跨GPU节点:也要通信。交换消息。这就叫:distributed message passing分布式消息传递。本质:把GNN做成“多卡版”。
这个非常像:大模型并行训练。只是这里并行的是图。
为什么要这么做?因为他们想:更多GPU→更大图→更大GFM。这叫:scale GFM with more GPUs。不是:GPU变多、模型自动变聪明。而是:可以支持更大的模型和图。
整句话重新翻译(完整版)
基于QuadGraph,作者提出34M参数的图基础模型GFM,同时建模图结构关系和节点文本语义,并把图推理结果与LLM结合,提升下游任务推理能力。同时,为了让模型能够扩展到更大的图和更多GPU,作者采用:混合精度训练、分布式消息传递 提高效率和扩展性。
2. 引言
大语言模型(LLMs)已经展现了非常强的推理能力,并且成为解决复杂任务的基础模型。然而,LLM 的效果常受限于无法获取最新知识、无法用好领域专属知识。近年来,检索增强生成(RAG)通过让 LLM 基于外部知识源进行推理,解决了这一问题,进而提升了 LLM 在法律判决、医疗诊断等真实场景的实用性。尽管 RAG 改善了外部知识的获取能力,但现有 RAG 在知识密集型推理任务中表现不佳,核心原因是相关信息过于零散。这意味着我们不仅要检索相关信息,还必须有效捕捉知识间的关联与结构,才能更好地支撑推理。
什么叫知识密集推理?
就是:一个答案,需要拼很多知识。
不是:单跳问题:法国首都?(单条知识)
而是:多跳问题:乔布斯创立的公司发布了什么手机?
需要:Jobs→ Apple→ iPhone两跳。
这叫:Knowledge-intensive reasoning、Multi-hop reasoning
这是GraphRAG存在意义。
图是建模知识结构与关联的天然、灵活表示形式,特别适合捕捉复杂的知识关联,进而提升推理能力。但 LLM 天生是无结构的文本模型,无法有效处理图数据。这就催生了一类新方法:用图增强检索增强生成(GraphRAG),让 LLM 能在图结构知识上做有效推理。
现有 GraphRAG 工作主要聚焦两个模块:
- 图构建Graph Construction:设计图结构来有效组织、捕捉知识间的关联,比如文档图、知识图谱、层级图。设计良好的图结构能提供更多上下文与知识关联,提升检索效果。
- 图增强推理Graph-enhanced Reasoning:提升 LLM 在图结构上的推理能力。比如:HippoRAG 用 PageRank 算法在知识图谱上搜索;ToG 用基于智能体的方法,通过工具调用与图交互推理;GNN-RAG 用图神经网络(GNNs)实现图上的复杂推理。
知识适合图、但LLM不适合图。
- 给出最优解决方案:用图建模知识(节点 = 实体 / 文档,边 = 关系)。
- 再点出新矛盾:LLM 只会处理文本,看不懂图。
- 引出研究方向:GraphRAG(图 + RAG+LLM)
GraphRAG 拆成两大核心工作:先造图,再用图推理。
- 造图:文档图、知识图谱、层级图。
- 推理:搜索算法、智能体、图神经网络。
- 文档图(Document Graph)节点 = 文档 / 段落,边 = 文档间的相似 / 引用关系。
- 知识图谱(Knowledge Graph)节点 = 实体(人、物、地点),边 = 实体间的关系(出生于、位于、制作)。
- 层级图(Hierarchical Graph)分上层 / 下层的图,比如上层是主题,下层是具体文档 / 实体。
- PageRank 算法谷歌最早用的网页排序算法,这里用来给图中节点 “打分”,找最相关的节点。
- 智能体(Agent)让 LLM 像人一样分步思考、调用工具,比如先查实体,再查关系,一步步推理。
- 图神经网络(GNNs)专门处理图数据的神经网络,能学习节点、边的特征,做图上的预测 / 推理。
这里其实是在分类现有工作:
方向 代表 图构建 GraphRAG, HippoRAG 图搜索 PageRank Agent推理 ToG GNN推理 GFM-RAG
尽管 GraphRAG 已取得进展,但现有方法仍面临三大关键瓶颈,制约了其实际落地:
- 图构建缺乏标准化:现有 GraphRAG 的图构建严重依赖针对特定任务 / 数据集的特设设计(例如,用预定义规则构建文档图,或手工设计知识图谱的关系 schema)。这类任务专属图无统一标准,难以跨领域、跨知识库复用,严重削弱了跨域泛化能力。
- 推理策略低效且高成本:基于启发式搜索的方法(如 PageRank、贪心搜索)需对图进行多轮迭代,推理延迟高;而基于智能体流水线的方法(如 ToG)依赖复杂的工具调用流程,且需大 LLM(如 GPT-4)引导推理,带来高昂的资金与计算成本。
- 图增强推理泛化性不足:GNN-RAG 等方法用图神经网络(GNNs)建模图拓扑,但 GNN 存在图外泛化缺陷—— 无法泛化到训练数据中未出现的图结构或知识实体,限制了其在持续新增实体 / 关系的动态知识库中的适用性。
问题1:specific graph structures 依赖特定图结构。
这个我们讲过:换图:失效。这是:泛化差。
问题2:graph search weak 搜索能力弱。启发式搜索。不是模型推理。需对图进行多轮迭代,推理延迟高
问题3:agent expensive Agent太贵。计算成本高。延迟高。
问题4:图增强推理泛化性不足。新实体 / 新图学不会。
本段是全文的 “痛点总结”,点破前人工作的 3 个致命问题,也是本文要解决的核心目标:
- 痛点 1:图不通用 → 本文要做标准化图结构
- 痛点 2:推理慢 / 贵 → 本文要做轻量、高效的推理框架
- 痛点 3:新实体 / 新图学不会 → 本文要做强泛化能力的模型
- 特设设计(Ad-hoc Designs)定义:为某一任务 “量身定制” 的方案,无统一标准,换个任务 / 领域就失效。例:为医疗知识库设计的知识图谱,无法直接用于法律知识库。
- 启发式搜索(Heuristic Search)定义:用 “经验规则” 而非全局最优算法,快速搜索图中相关节点。例:PageRank 通过节点链接权重排序,贪心搜索优先选最相关的相邻节点。
- 智能体流水线(Agent Pipelines)定义:让 LLM 像 “智能体” 一样分步执行任务,需调用多个工具(如检索工具、图查询工具)完成推理,流程复杂且依赖大模型。
- 图外泛化(Out-of-graph Generalization)定义:模型仅能处理训练时见过的图结构 / 实体,遇到全新的图(如新增行业知识的图)或新实体(如刚成立的公司)时,推理效果骤降。
- 动态知识库(Dynamic Knowledge Bases)定义:持续新增实体、关系的知识库(如实时新闻、行业动态数据),而非固定不变的静态数据集。
问题3补充:
前面那些方法:PageRank、Agent 其实不是真正在“学习推理”。
但GNN不一样。GNN真的是在:学图上的推理规律。
如果:A → founded → B,B → released → C。那:A和C可能有关。
GNN问题:GNN 存在图外泛化缺陷。out-of-graph generalization 图外泛化。
模型仅能处理训练时见过的图结构 / 实体,遇到全新的图(如新增行业知识的图)或新实体(如刚成立的公司)时,推理效果骤降。
意思:训练时见过一个图。测试时来了新图。模型还能不能用?
训练图:Steve Jobs→ Apple→ iPhone。GNN学会:科技公司推理。
测试来了新图:Elon Musk→ SpaceX→ Starship
这是训练没见过的。新实体。新结构。
普通GNN:可能不会推。这叫:不能图外泛化。
因为普通GNN:很依赖:训练图分布。
本质:它学的是:“这个图”。不是:“通用图推理规律”。这是根本问题。
这也是为什么作者说:GNN不是Foundation Model。
它不能泛化到:没见过的新图结构。
训练:知识图谱:Entity — relation — entity
测试:层次图:Document-----Community
结构变了。GNN可能懵了。因为:训练时没学这种结构。
这叫:unseen graph structure 未见图结构。
无法泛化到训练数据中未出现的知识实体
训练:Apple、Microsoft、Google
测试:DeepSeek(新出现)
GNN可能处理不好。这叫:unseen entities。这在动态知识库里特别严重。
知识库是动态的。不断长新东西。
因为GNN适合:静态图。现实是:动态图。
需要:更通用的:Graph Foundation Model
本文提出G-reasoner,它融合图基础模型与语言基础模型,实现对多样图结构知识的可扩展训练与泛化推理,如图 1 所示。
为实现对多样图结构的推理,我们首先定义一种全新的四层图结构 QuadGraph,将异构图结构知识统一为标准化格式。这使得 G-reasoner 可灵活适配各类图结构。
基于统一的 QuadGraph,我们进一步释放由 GNN 驱动的图基础模型(GFM)的能力,同时对图的拓扑结构与文本语义进行联合推理。
为支撑大规模训练与推理,我们采用混合精度训练,并提出分布式消息传递机制,使 G-reasoner 可在多 GPU 与多数据集上有效扩展。
- 总述:G-reasoner = 图基础模型 GFM + 语言大模型 LLM,目标:通用 + 可扩展 + 强推理。
- 核心创新 1:QuadGraph 四层统一图把所有乱七八糟的图(知识图谱、文档图、层级图)都转成同一种四层标准格式,解决 “图不通用”。
- 核心创新 2:GFM 联合推理既看图的连接结构(拓扑),又看文本的意思(语义),比只看结构或只看文本更强。
- 工程创新:训练 / 推理效率拉满混合精度省显存、提速;分布式消息传递能跑超大图、多卡并行,工业可用。
统一标准化:就是QuadGraph。把各种异构图知识,统一成标准格式。
QuadGraph:统一输入。GFM:做推理
- heterogeneous graph-structured knowledge(异构图结构知识)类型不一样的图:知识图谱、文档图、层级图,格式完全不同。
- topology(拓扑)图的节点和边的连接关系,比如 A 连 B,B 连 C。
- text semantics(文本语义)文本的含义、内容,比如 “苹果” 是水果还是公司。
- mixed-precision training(混合精度训练)用半精度(BF16/FP16)算,单精度存,省显存、提速,不怎么掉效果。
- distributed message-passing(分布式消息传递)把大图拆到多块 GPU 上,一起算消息传递,能处理超级大的图。
最终,我们得到一个3400 万参数的 GFM,它能高效捕捉知识间的复杂关联与依赖关系,在图上完成通用预测。图推理结果可灵活集成到 LLM 中,提升 LLM 在下游任务中的推理能力。在6 个基准数据集上的实验表明:G-reasoner 性能优于当前最优基线,显著提升 LLM 在复杂推理任务上的表现。此外,G-reasoner 在各类图结构上展现出优异的效率与泛化能力,是适用于实际应用的通用方案。
- 模型亮点:34M 超轻量 GFM比大模型小得多,快、便宜、能端侧部署,还能抓复杂知识关系。
- 落地方式:GFM 给 LLM 打工GFM 先把图推理明白,把关键信息喂给 LLM,LLM 生成答案更准、更少幻觉。
- 效果证明:
- 6 个权威数据集吊打所有基线;
- 复杂推理(多跳问答)大幅提升;
- 快、通用、实际能用。
- 34M-parameter(3400 万参数)轻量模型,对比 GPT-4(万亿级)、普通 GNN(上亿),很小,跑得快。
- versatile predictions(通用预测)能预测实体、文档、属性、社区等多种节点,不是只能做一种任务。
- downstream applications(下游任务)实际用的任务:问答、医疗诊断、法律分析、摘要等。
- state-of-the-art baselines(SOTA 基线)领域里目前最好的方法,用来对比证明自己更强。
本文核心贡献总结如下:
- 提出G-reasoner 框架:融合图与语言基础模型,实现对多样图结构知识的统一推理。
- 研发3400 万参数图基础模型 GFM:联合推理图拓扑与文本语义,搭载分布式消息传递机制,支撑大规模训练与推理。
- 全面实验验证:在 6 个基准数据集上实验,证明 G-reasoner 优于 SOTA 基线,且在各类图结构与领域中具备高效性与强泛化能力。
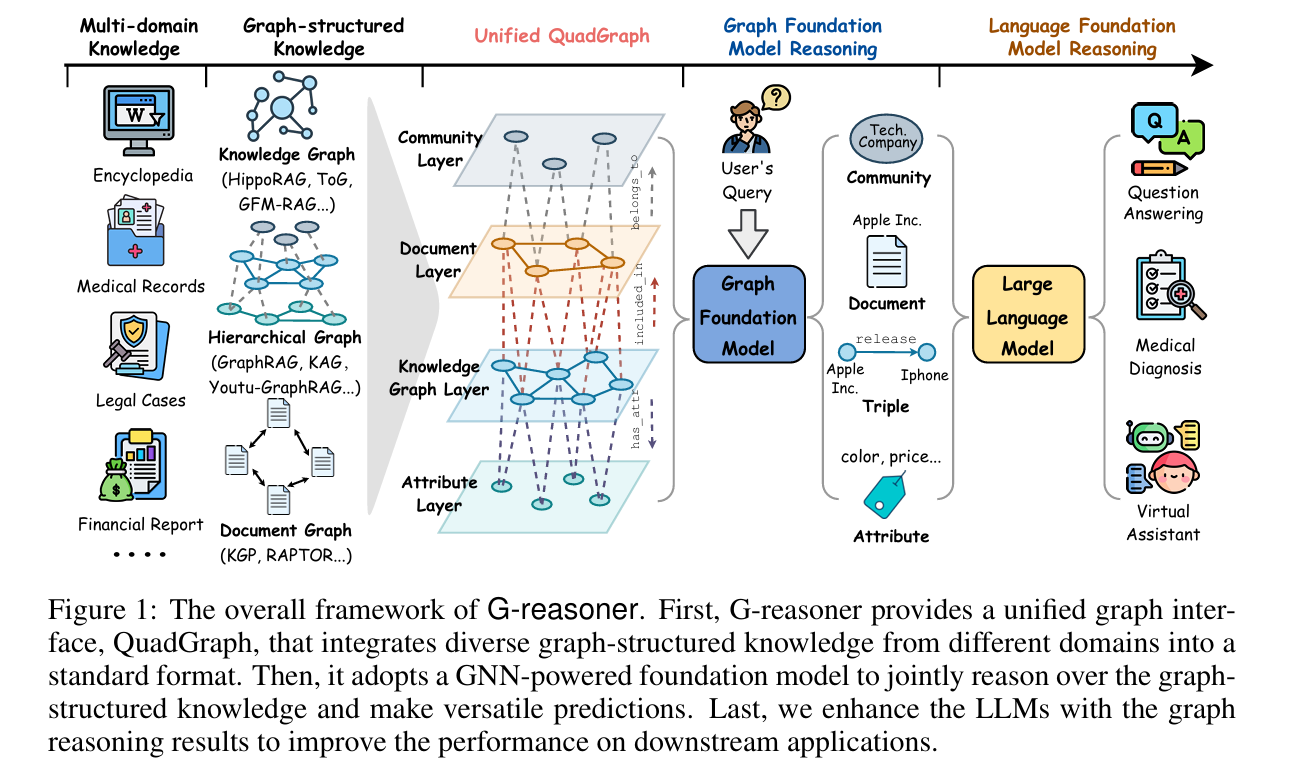
一、先给图 1 做个「总览」
这张图是 G-reasoner 的端到端工作流程,从左到右就是它解决问题的完整链路:
多领域异构知识 → 统一成QuadGraph标准格式 → 图基础模型(GFM)推理 → 给大语言模型(LLM)喂结构化知识 → 下游任务落地核心逻辑就是:先把乱七八糟的知识 “标准化”,再用专门的模型高效推理,最后给 LLM “开挂”,解决它知识不足、推理弱的问题。
二、模块 1:最左侧「Multi-domain Knowledge & Graph-structured Knowledge」
1. Multi-domain Knowledge(多领域知识源)
- 图里的例子:Encyclopedia(百科)、Medical Records(医疗病历)、Legal Cases(法律案件)、Financial Report(金融报告)……
- 本质:真实世界里的知识是跨领域、不同格式的,不是单一的。
- 痛点:这些知识没法直接给模型用,得先变成 “图结构”,但不同领域的图长得完全不一样。
2. Graph-structured Knowledge(异构图结构知识)
这里列了三类最常见的 GraphRAG 用到的图,也是之前论文里提到的 “现有方法的痛点”:
表格
图类型 例子(对应论文里的方法) 核心特点 问题所在 Knowledge Graph(知识图谱) HippoRAG、ToG、GFM-RAG 节点是实体(人 / 物 / 概念),边是关系(发布 / 属于) 只存实体关系,缺文本上下文 Hierarchical Graph(层级图) GraphRAG、KAG、Youtu-GraphRAG 节点按层级划分(上层是主题 / 社区,下层是实体 / 文档) 结构固定,换领域就得重新建 Document Graph(文档图) KGP、RAPTOR 节点是文档 / 段落,边是引用 / 相似关系 只存文本关联,缺实体间的深层逻辑
- 关键:这三类图格式完全不统一,之前的方法只能处理其中一种,没法通用,这就是论文说的 “ad-hoc 设计” 的问题。
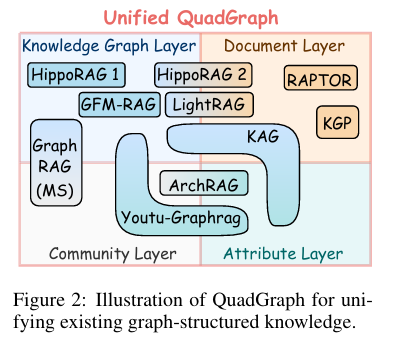
三、模块 2:核心创新「Unified QuadGraph(统一四层图)」
这是论文最核心的创新之一,专门解决 “异构图不通用” 的问题。它把上面三类完全不同的图,都转换成同一套四层标准结构,不管你是什么领域、什么类型的知识,都能塞进这个框架里。
我们从下往上,一层一层讲:
第 1 层:Attribute Layer(属性层)
- 节点是什么:实体 / 文档的具体属性,比如 “苹果手机的颜色、价格、发布时间”。
- 边 / 关联:没有横向边,只通过虚线和上一层(知识图谱层)相连,标注为
has attr(属于某个实体的属性)。- 作用:把零散的、具体的属性信息,绑定到对应的实体上,解决知识 “缺细节” 的问题。
第 2 层:Knowledge Graph Layer(知识图谱层)
- 节点是什么:知识图谱里的实体,比如 “Apple Inc.(苹果公司)”“Iphone(苹果手机)”。
- 边 / 关联:
- 横向边:实体间的关系,比如 “Apple Inc. → release → Iphone”(苹果公司发布了 iPhone),也就是知识图谱里的 “三元组(头实体 - 关系 - 尾实体)”。
- 纵向边:往下连属性层(
has attr),往上连文档层(included in),表示 “这个实体出现在哪些文档里”。- 作用:保留知识图谱的核心逻辑 —— 实体间的关系,让模型能做 “多跳推理”(比如 “谁发布了 iPhone?→苹果公司”)。
第 3 层:Document Layer(文档层)
- 节点是什么:文档 / 段落,比如一篇关于苹果公司的新闻、一份产品说明书。
- 边 / 关联:
- 横向边:文档间的引用 / 相似关系,比如 “新闻 A 引用了新闻 B”,对应文档图的逻辑。
- 纵向边:往下连知识图谱层(
included in),往上连社区层(belongs to),表示 “这个文档属于哪个主题 / 社区”。- 作用:把零散的实体,还原到它所在的文本上下文里,解决知识图谱 “缺背景信息” 的问题。
第 4 层:Community Layer(社区层)
- 节点是什么:按主题聚类的 “社区 / 主题”,比如 “科技公司”“消费电子”,对应层级图的上层结构。
- 边 / 关联:只有纵向边,往下连文档层(
belongs to),表示 “这些文档都属于同一个主题社区”。- 作用:提供 “宏观视角”,让模型能从主题层面理解知识,解决层级图 “结构固定、难泛化” 的问题。
QuadGraph 的设计巧思(为什么要这么设计?)
- 全兼容:不管是知识图谱、文档图还是层级图,都能对应到这四层里:
- 知识图谱 → 第 2 层 + 第 1 层
- 文档图 → 第 3 层
- 层级图 → 第 4 层 + 第 3 层
- 跨层关联:通过
has attr/included in/belongs to这些边,把四层打通,让模型推理时既能看实体关系,又能看文档上下文,还能看主题信息,信息是连通的。- 标准化:所有知识都用同一套格式存,不用再为每个任务重新设计图结构,解决了之前 “ad-hoc 设计” 的痛点。
四、模块 3:Graph Foundation Model Reasoning(图基础模型推理)
GFM在图上推理。输出:相关节点。
这部分对应论文里的 “轻量 GFM”,解决 “推理效率低、泛化差” 的问题。
1. 输入:User's Query(用户的问题)
比如用户问:“苹果公司发布的手机价格是多少?”,这个问题会先和 QuadGraph 一起,喂给 GFM。
2. 核心:Graph Foundation Model(图基础模型)
- 它是一个 34M 参数的轻量 GNN 模型,干两件事:
- 学拓扑:通过图消息传递,学习 QuadGraph 里的节点连接关系(比如 “Apple Inc. 连 Iphone,Iphone 连价格属性”)。
- 学语义:通过 Transformer 编码器,学习节点里的文本含义(比如 “release” 是 “发布”,不是 “释放”)。
- 本质:它会沿着 QuadGraph 的四层结构,从用户的问题出发,找到最相关的信息,把 “实体 - 文档 - 主题 - 属性” 的关联都理清楚。
3. 输出:多粒度的结构化推理结果
GFM 会输出不同层级的信息,给后面的 LLM 用:
- Attribute(属性层结果):比如 “Iphone 的价格、颜色”
- Triple(知识图谱层结果):比如 “(Apple Inc., release, Iphone)”
- Document(文档层结果):比如 “提到苹果发布 iPhone 的新闻原文”
- Community(社区层结果):比如 “这些信息都属于‘科技公司’主题”
这些都是结构化的、和用户问题强相关的知识,比之前 RAG 里的零散文本碎片要有用得多。
五、模块 4:Language Foundation Model Reasoning(大语言模型推理)
这部分就是 “GFM 给 LLM 开挂” 的环节,解决 LLM“知识不足、推理弱” 的问题。
1. 输入:GFM 的结构化推理结果
LLM 不用再自己去大海捞针找信息,直接用 GFM 整理好的、带关联的知识:比如 “苹果公司发布了 iPhone,iPhone 的价格是 XXX,这些信息来自哪篇文档,属于哪个主题”。
2. 核心:Large Language Model(大语言模型)
- 它的作用是把 GFM 的结构化结果,转换成自然语言,解决实际问题。
- 为什么要结合?
- GFM 懂图、懂知识关联,但不会说人话,没法直接回答用户问题;
- LLM 会说人话、懂用户需求,但知识零散、推理弱;
- 两者结合就是 1+1>2:既有结构化知识的准确性,又有自然语言的流畅性。
3. 输出:下游任务落地
图里列了三个典型场景:
- Question Answering(问答):比如回答用户的问题,准确率更高,更少幻觉。
- Medical Diagnosis(医疗诊断):基于病历知识图谱推理,辅助医生判断,减少错误。
- Virtual Assistant(虚拟助手):给助手喂实时知识,让它回答更靠谱。
六、整体流程串讲(组会汇报可以这么说)
- 第一步,我们有来自百科、医疗、法律等多个领域的知识,这些知识之前被转换成了知识图谱、层级图、文档图等不同格式,没法通用。
- 第二步,我们用 QuadGraph 把这些异构图统一成四层标准结构,不管是什么类型的知识,都能放进同一个框架里,解决了 “图不通用” 的问题。
- 第三步,用户的问题和 QuadGraph 一起输入 GFM,GFM 会沿着图结构,把和问题相关的实体、文档、主题、属性都找出来,生成结构化的推理结果,解决了 “推理效率低、泛化差” 的问题。
- 最后,把这些结构化结果喂给 LLM,LLM 就能生成更准确、更靠谱的答案,支撑问答、医疗诊断、虚拟助手等下游任务。
七、难懂概念再复盘(怕大家忘了,再提一遍)
- 异构图:不同结构、不同格式的图,比如知识图谱和文档图。
- QuadGraph:四层统一图结构,用来把异构图标准化。
- GFM:轻量图基础模型,同时学图的结构和文本的意思,输出结构化知识。
- GFM+LLM:用结构化知识给 LLM 赋能,既准又会说人话。
3. 相关工作
图构建图构建是基于图的推理的核心环节。早期方法如 KGP(Wang 等人,2024)仅利用超链接和 KNN 相似度构建图,丢失了语义关联。RAPTOR(Sarthi 等人,2024)通过递归摘要构建层级树形图。微软 GraphRAG(Edge 等人,2024)利用大模型抽取实体与关系,结合社区发现和摘要生成层级图。LightRAG(Guo 等人,2024)、ArchRAG(Wang 等人,2025)和 Youtu-GraphRAG(Dong 等人,2025)进一步通过属性与文档丰富图结构。HippoRAG 1&2(Jimenez Gutierrez 等人,2024、2025)采用开放信息抽取(OpenIE) 生成知识图谱,以捕获事实性关系。尽管这些方法取得了一定效果,但它们通常为特定图结构量身定制,在不同类型图之间的泛化能力极差。例如,微软 GraphRAG 和 LightRAG 构建的层级图主要面向摘要任务,相较于 HippoRAG 所用的知识图谱,并不适用于多跳推理任务。Youtu-GraphRAG(Dong 等人,2025)提出了一种垂直统一框架,通过图 schema 指导图构建。
这一段讲前人是怎么造图的,按时间线从简单到复杂,最后点出所有图构建方法的致命缺陷:
- 早期方法(KGP)做法:靠超链接、KNN 相似度连节点;缺点:只看表面关联,不理解文本语义,知识关联不准。
- 层级图方法(RAPTOR / 微软 GraphRAG)做法:用 LLM 抽实体、做社区聚类,造分层的图;用途:适合文本摘要,不适合复杂推理。
- 增强型图方法(LightRAG/ArchRAG/Youtu-GraphRAG)做法:加属性、加文档,让图信息更全;进步点:图的内容更丰富了。
- 知识图谱方法(HippoRAG)做法:用 OpenIE 抽实体关系,造标准知识图谱;用途:适合多跳推理。
- 核心缺陷总结所有方法都是专用图:摘要用层级图、推理用知识图谱,不能通用,换任务就要重新造图,这就是本文 QuadGraph 要解决的问题。
难懂概念单独拆解
- KNN similarity(K 近邻相似度)按文本 / 节点的特征距离,把相近的节点连边,只看表面相似,不懂语义。
- recursive summarization(递归摘要)把长文本摘要成短句,再把短句摘要成主题,层层向上造树形图。
- community detection(社区发现)把语义相近的节点聚成一个 “社区 / 主题”,造层级图的核心步骤。
- OpenIE(开放信息抽取)不用预定义关系,直接从文本里抽「实体 - 关系 - 实体」三元组,生成知识图谱。
- multi-hop reasoning(多跳推理)比如问 “苹果 CEO 的出生地”,需要跳 2 步:苹果→CEO→出生地,复杂推理任务。
- graph schema(图模式)图的结构规范,比如节点有哪些类型、边有哪些关系。
图增强推理图增强推理旨在让大模型在图结构知识上完成推理,提升其在知识密集型任务中的表现。HippoRAG(Jimenez Gutierrez 等人,2024)采用个性化 PageRank 算法在知识图谱上实现高效检索。LightRAG(Guo 等人,2024)采用双层检索策略:融合嵌入检索与图邻域扩展。但这类基于图搜索的方法,仍无法充分发挥基础模型的推理能力。基于智能体的方法,如 ToG(Sun 等人,2024)、KAG(Liang 等人,2025)、Youtu-GraphRAG(Dong 等人,2025),采用 LLM 智能体与图迭代交互完成推理。这类方法虽有效,但因多次调用大模型,计算成本极高、推理延迟极大。近期研究开始利用图神经网络(GNN) 做图推理并增强 LLM。例如 SubgraphRAG(Li 等人,2025a)用 GNN 将图结构编码为节点表征,再为 LLM 检索相关信息。更近的 GFM-RAG(Luo 等人,2025)提出基于 GNN 的图基础模型,旨在适配不同知识图谱的推理。但这些方法仍局限于特定图结构,无法在多样图结构间良好泛化。更多相关工作细节见附录 A。
这一段讲前人是怎么用图给 LLM 做推理的,分成三大流派,逐个讲优缺点,最后点出和本文的差距:
- 第一流派:图搜索方法(HippoRAG/LightRAG)做法:用 PageRank、邻域扩展等算法,在图上搜相关节点;缺点:靠规则搜索,没用到大模型的学习能力,推理能力弱。
- 第二流派:智能体方法(ToG/KAG/Youtu-GraphRAG)做法:让 LLM 当智能体,一步一步查图、推理;缺点:反复调用 LLM,慢、贵、延迟高,工业没法落地。
- 第三流派:GNN 方法(SubgraphRAG/GFM-RAG)做法:用 GNN 学图结构,给 LLM 提供信息;进步点:效率比智能体高,有学习能力;缺点:还是专用,GFM-RAG 只适配知识图谱,文档图、层级图用不了。
- 最终结论所有图增强推理方法,都不通用、效率 / 效果不可兼得,这就是本文 G-reasoner 的创新出发点。
难懂概念单独拆解
- personalized PageRank(个性化 PageRank)谷歌网页排序算法的改进版,给图中节点打分,找到和查询最相关的节点。
- dual-level retrieval(双层检索)先做文本嵌入检索,再做图邻域扩展,两层结合找信息。
- agent iterative interaction(智能体迭代交互)LLM 分多步:先查实体→再查关系→再找文档,一步步推理,多轮调用 LLM。
- node representations(节点表征)GNN 把节点的结构 + 语义转成向量,方便计算机处理和检索。
- graph foundation model(图基础模型)通用的图大模型,能适配多种图,不是专用模型。
核心逻辑总结(组会汇报可以直接说):
- 图构建:前人造的图都是专用的,层级图、知识图谱、文档图互不通用;
- 图推理:分搜索(弱)、智能体(贵慢)、GNN(专用)三类,都有致命缺陷;
- 本文价值:用 QuadGraph 统一所有图,用轻量 GFM 做通用高效推理,完美解决上述所有问题。
3. 预备知识(PRELIMINARY)
在本节中,我们正式定义「基于大语言模型的图结构知识推理」问题,该问题可统一为两阶段框架:1. 图结构构建;2. 图增强检索与大模型推理。
具体来说,给定一组文档D,我们先从中抽取知识,构建结构化图G=(V,E),例如知识图谱、文档图。其中V表示节点集合(如实体、文档),E表示边集合,用于建模知识间的关联,支撑高效检索与推理。基于构建好的图G和用户查询q,我们的目标是从G中检索相关知识,再通过大模型推理得到最终答案a。
整体流程可公式化为:公式 (1):图构建器将文档转为图;
公式 (2):检索器从图中查相关知识,大模型基于检索结果生成答案。
![]()
核心问题用 LLM + 图结构知识,做知识密集型推理(问答、诊断、分析等)。
标准两阶段流程(所有前人方法都逃不开)
- 阶段 1:Graph Construction(图构建)把零散文档→结构化的图,节点是实体 / 文档,边是它们的关系。
- 阶段 2:Graph-enhanced Retrieval + LLM Reasoning(图增强检索 + 大模型推理)先在图上找到和用户问题相关的知识,再把这些知识喂给 LLM,生成最终答案。
- 符号定义(组会必讲,清晰易懂)
- D:文档集合(所有外部知识)
- G=(V,E):构建好的图
- V:节点(实体、文档、属性、社区)
- E:边(知识间的关联,如 “发布”“包含”“相似”)
- q:用户的问题 / 查询
- a:模型输出的最终答案
- 公式拆解
- 公式 (1):G=GraphConstructor(D)图构建函数,输入一堆文档,输出结构化的图。
- 公式 (2):a=LLM(Retriever(q,G))先执行Retriever(图检索):输入查询 + 图,输出相关知识;再把相关知识喂给LLM,输出答案a。
预备知识部分讲完这一段的作用:统一问题范式,告诉大家:不管是 HippoRAG、LightRAG 还是 GFM-RAG,都在跑这个两阶段流程,而本文的 G-reasoner,就是在这个标准流程上,把图构建换成 QuadGraph、把检索推理换成 GFM,实现通用化。
4.核心方法(APPROACH)
G-reasoner目标:设计一个基础模型,统一不同图结构上的推理。实现:更有效、更高效图推理。结合LLM,在图结构知识上推理。整体框架:见Figure 1。包含三大核心组件:
(1)统一图接口:QuadGraph。将不同领域的多样图结构知识,标准化为统一格式;。
(2)GNN驱动的基础模型:GFM。对图结构知识进行联合推理,并完成通用化预测;
(3)LLM增强推理(LLM-enhanced reasoning)。融合图推理结果,提升模型在下游任务中的表现。
foundation model:通用模型。G-reasoner想:适配很多图。
unifies reasoning:统一推理。不是:统一图。(那是QuadGraph做的)而是:统一推理方式。不管:知识图谱、文档图、层次图、属性图。都用:同一种推理机制。
图负责:结构推理。LLM负责:语言理解生成。
QuadGraph不是模型。只是:标准输入格式。像:API接口。
把各种图:变成统一输入。
GFM(a GNN-powered foundation model)底层骨架:是GNN。不是Transformer。
用:message passing 做图推理。
联合推理。同时看:结构+语义
versatile predictions 通用预测。什么意思?不是只能QA。还能:检索、分类、推理、节点预测。多任务。这就是Foundation Model特征。
把图推理的结果喂给 LLM,让 LLM 生成准确、通顺的答案。
不是:LLM推理。是:被图推理增强后的LLM推理。
把图推理结果:注入LLM。怎么注入?后面会讲:通常:Prompt增强。把图推理结果:放进上下文。
下游任务:QA、医疗诊断、检索。这就是最终目标。实际落地任务:问答、医疗诊断、法律分析、虚拟助手等。
- versatile predictions(通用化预测)模型能对4 种节点类型(属性、实体、文档、社区)都做相关性预测,不是只能做一种任务。
- downstream applications(下游应用)实际落地任务:问答、医疗诊断、法律分析、虚拟助手等。
- jointly reasons(联合推理)同时结合图拓扑结构和文本语义推理,比只看结构或只看文本更强。
4.1 统一图接口:QuadGraph
现实世界的知识往往是复杂且多关系的,这类知识天然可以用图结构表示(Hogan 等人,2021;Safavi & Koutra,2021)。为了在推理中有效利用图结构知识,现有方法通常会根据知识的具体特征和下游任务需求,构建不同类型的图。例如,知识图谱(Jimenez Gutierrez 等人,2024)常用来表示实体间的事实信息,而文档图(Wang 等人,2024)则基于内容相似度或引用关系,捕获文档间的关联。但这类方法通常只聚焦某一种特定图结构,这限制了它们在其他类型图结构知识上的适用性,也阻碍了推理模型的泛化能力。
- 背景铺垫:现实知识复杂多关系→图是最优表示形式。
- 现有做法:不同任务 / 知识造不同的图(知识图谱做推理、文档图做检索、层级图做摘要)。
- 致命问题:专用图不通用,换知识类型、换任务就要重新造图,模型没法泛化。
- 引出创新:必须设计一个统一的图接口,把所有图都标准化 —— 这就是 QuadGraph。
知识图谱:三元组。表示事实知识。
文档图:表示文档间关系。比如:两篇论文:内容相似。
为解决这一缺陷,G-reasoner 提出了名为QuadGraph的统一图接口,它将不同领域的多样图结构知识,标准化为统一格式。具体而言,我们设计了四层图结构,包含以下层级:
- 属性层:捕获节点的通用属性;
- 知识图谱层:以三元组形式表示实体及其关系,存储结构化事实知识;
- 文档层:包含非结构化文本信息,如文档、段落;(KG不够,原文来补)
- 社区层:基于语义相似度或结构连通性,将相关节点聚为社区,提供全局信息。如图 2 所示,QuadGraph 能将各类图结构知识(知识图谱、文档图、层级图)有效统一为标准格式,为通用推理模型的设计提供便利。
- 四层结构
层级 英文 核心作用 存储内容 对应原有图类型 微观层 Attribute Layer 存节点属性 颜色、价格、日期等细节 补充知识图谱的细节 逻辑层 Knowledge Graph Layer 存实体关系 实体 - 关系 - 实体三元组 知识图谱 文本层 Document Layer 存原文上下文 文档、段落文本 文档图 宏观层 Community Layer 存主题聚类 语义相似的节点社区 层级图 - 统一能力:不管是知识图谱、文档图还是层级图,都能完美嵌入这四层,一套结构适配所有图。(KG、Document Graph、Hierarchical Graph)
- 价值:推理模型不用再适配不同图结构,一次训练,通用所有图。
QuadGraph 的形式化定义为:G=(V,E,R,T,S)其中:
- T= {属性,实体,文档,社区},表示节点类型集合;
- R 表示边类型集合,用于建模节点间的关系(如 “出生于”“位于”),以及层间特殊关系(如 “拥有属性”“包含于”“属于”);
- 图中的边定义为:E=(v,r,v′)∣tv,tv′∈T,r∈R,其中tv 表示节点v的类型;
- S 表示节点语义特征集合,如实体名称、文档文本内容。
- 层间关系 "has attribute(拥有属性)", "included in(包含于/被文档包含)", "belongs to(属于)"
- 五元组定义:QuadGraph 用 5 个核心要素完整描述,严谨且通用
- V:所有节点(属性、实体、文档、社区)
- E:所有边(层内关系 + 层间关联)
- R:所有关系类型(实体关系 + 层间关系)
- T:4 种节点类型
- S:节点的文本语义(让图既懂结构,又懂文本)
- 边的定义:任意两个不同类型节点都能连边,跨层关联打通,信息不割裂。
- 语义特征:把文本内容融入图,解决 “图只有结构没有语义” 的问题。
- QuadGraph 通过属性、知识图谱、文档、社区四层结构,把所有异构图统一成标准格式,彻底解决了前人 “专用图不通用” 的缺陷,为后续通用图推理模型 GFM 打下基础。
4.2 图基础模型推理(Graph Foundation Model Reasoning)GFM
为了在统一后的图结构知识上完成高效推理,G-reasoner 提出了一个基于图神经网络(GNN)的基础模型(GFM),它能在 QuadGraph 上进行联合推理,并完成通用化预测。图神经网络(GNN)擅长捕获节点间的复杂关联与依赖关系,在图结构数据推理上表现优异。此前,GFM-RAG 提出了面向知识图谱的图基础模型,证明了 GNN 能为 LLM 引入结构化知识。但GFM-RAG 仅针对知识图谱设计,无法直接用于文档图、层级图等包含多样节点类型、丰富文本语义的图结构知识。为解决这一缺陷,G-reasoner 设计了泛化性更强的 GFM,具备两大能力:
- 联合建模图拓扑结构与文本语义进行推理;
- 对任意类型的节点(属性、实体、文档、社区)都能做预测。
- 为什么要做 GFM?之前的 GNN 模型(比如 GFM-RAG)只能处理单一的知识图谱,只能识别实体节点,看不懂文档、属性、社区。而我们的 QuadGraph 有4 种节点,所以必须做一个通用的 GFM。
- GFM 的两大核心能力(组会必说)
- 既看图的连接结构(拓扑),又看文字意思(语义),双管齐下;
- 不管是属性、实体、文档、社区哪种节点,都能判断它和用户问题是否相关。
- 承上启下前面 QuadGraph 统一了图的格式,这里 GFM 统一了推理的能力。
- versatile predictions(通用化预测)对 4 种节点都能输出相关性分数,不是只能预测实体。
- synergizes structure and semantics(结构 + 语义联合)不只看节点连没连,还看节点的文字内容,更准确。
- arbitrary node types(任意节点类型)属性、实体、文档、社区,全都能处理。
(1)Synergized Reasoning over Structure and Semantics.结构与语义联合推理
G-reasoner 选用与查询相关的 GNN(query-dependent GNN)作为 GFM 的主干,它能捕获用户查询与图中知识之间的复杂关联。不同于 GFM-RAG 只考虑关系的语义,G-reasoner额外把节点的文本语义 s 加入推理过程。
【编码步骤:文本→向量】给定图 G,我们先用预训练文本嵌入模型(如 BGE、Qwen3 向量模型),将每个节点的文本特征 s_v 编码为节点向量 h_v。同样用该模型,把每个关系 r 的文本描述编码为关系向量 h_r。通过文本向量,我们能有效捕获图中的语义信息,并将所有信息统一到同一个向量空间,方便后续推理。
- 主干网络:query-dependent GNN(和问题相关的 GNN)普通 GNN 是 “看图说话”,这个 GNN 是带着用户的问题去看图,更精准。
- 对比前人的优势GFM-RAG:只看关系的文字(比如 “发布”);我们的 GFM:节点文字 + 关系文字 + 图结构三者一起看。
推理时,图 G 和用户查询 q 一起输入 GFM。模型先将查询编码为查询向量 h_q,理解用户意图并与图知识对齐。随后,通过L 层与查询相关的 GNN,基于消息传递机制联合推理图拓扑与文本语义,对每种节点类型做通用预测,公式如下:
- 初始化节点向量:结合原始节点向量 + 查询向量
- 每一层 GNN:更新节点向量(聚合邻居消息)
- 输出预测:节点和查询的相关性分数 p (v)
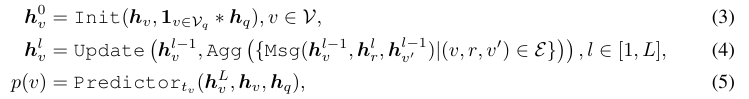
极简公式讲解(组会不用讲数学,讲逻辑)
- 公式 (3):初始化把节点本身的信息+用户问题的信息绑在一起。
- 公式 (4):消息传递(GNN 核心)每个节点向邻居 “打听信息”,把周围节点、关系的信息聚合过来。
- 公式 (5):输出分数给每个节点打一个分:这个节点和用户问题有多相关。
核心作用
GFM 最终输出:每个节点(属性 / 实体 / 文档 / 社区)的相关性分数,挑出最相关的给 LLM。


训练优化GFM 通过融合图G的拓扑结构(V,E)和文本语义S进行统一推理,预测节点与查询的相关性。我们通过最大化人工标注的真实相关节点Vq+的似然概率来优化 GFM 模型参数θ,公式如下 
为缓解这一问题,我们提出利用图中大量无标注节点,在大规模数据上进行弱监督训练。预训练文本嵌入模型(如 BERT、BGE)具备极强的语义理解能力,能基于文本特征S有效判断查询与节点的相关性。因此我们用预训练文本嵌入模型作为 “教师模型”,给图中所有节点自动生成伪标签,


用少量标准答案 + 用老师模型给大量节点打伪标签 → 一起训练 GFM
一、公式 (6):人工标注监督损失(最基础的损失)
公式意思
让模型给「人工标注的正确节点」打高分。
苹果例子
- 查询:iPhone15 价格是多少?
- 人工标注的正确节点Vq+:只有 v3(价格 5999 元)
- 公式 (6) 作用:逼着 GFM 把p(v3)往 1.0 拉,让模型记住「这个节点是对的」。
问题
人工标注太少了!图里有上万个节点,只标 1 个,模型学不会泛化。
二、解决方案:伪标签 + 知识蒸馏
1. 教师模型(Teacher):预训练文本嵌入
- 身份:已经训练好的文本向量模型(BGE/Qwen3)
- 能力:只看文字,就能算出节点和查询的相似度
- 工作:给图里所有节点自动打分数(伪标签)→ 不用人工标,全自动!
公式 (7):教师模型算伪标签
就是算节点向量和查询向量的相似度,转成 0~1 分数。
苹果例子
教师模型给所有节点打分:
- v3(价格 5999):0.92
- v2(iPhone15):0.88
- v1(苹果公司):0.21
- v4(黑色):0.08这些分数就是伪标签。
2. 知识蒸馏:让学生 GFM「模仿」老师
- 学生:我们的 GFM 模型
- 老师:预训练文本嵌入模型
- 目标:让 GFM 的预测分数,和老师的伪标签分数尽量一样
公式 (8):KL 散度
就是衡量两个分布差多少
- 差得大 → 损失大,模型要改
- 差得小 → 损失小,模型学得好
大白话:老师说 v3 是 0.92,你 GFM 也得预测成接近 0.92,不准差太远!
三、公式 (9):最终总损失(两个部分加起来)
总损失 = ①人工标注监督损失 + ②知识蒸馏损失
- 第一项(人工监督):学好「标准答案」,保证准确率
- 第二项(蒸馏):学好「老师的伪标签」,用海量无标注数据,让模型泛化更强
苹果例子总损失含义
- 第一项:必须把人工标对的 v3(价格) 打高分
- 第二项:同时模仿老师,给 v2、v1、v4 打出和老师接近的分数→ 既准又能泛化!
四、整段训练逻辑「大白话总结」(组会这么说)
- 问题:人工标注的相关节点太少,GFM 没法训练;
- 办法:
- 找个文本嵌入模型当老师,给所有节点自动打伪标签;
- 让 GFM 当学生,一边学人工标准答案,一边模仿老师的伪标签;
- 好处:
- 用少量标注保证准确;
- 用海量无标注数据让模型通用、泛化强;
- 公式 9就是把这两个目标合在一起,平衡训练。
- 伪标签是啥?老师模型自动算的分数,不是人工标,叫「伪标签」。
- 知识蒸馏是啥?让小模型(GFM)学大模型 / 预训练模型的能力,叫蒸馏。
- KL 散度是啥?衡量两个分数列表差多少,越小越像。
- 为什么要这么麻烦?人工标数据太贵、太少,不用无标注数据模型学不好。
原文翻译
大规模训练与推理为了让模型具备在多样图结构知识上的通用推理能力,G-reasoner 基于大规模弱监督数据集进行训练。具体来说,我们从多个领域收集了大量的查询 - 图对 {(qi,Vqi+,Gi)}i=1N(数据来源:Luo et al., 2025)。其中,图Gi由不同的图构造器生成(包括知识图谱、文档图、层级图),并通过 4.1 节介绍的QuadGraph 统一为标准格式。弱监督信号Vqi+是为每个查询标注的相关节点(比如答案对应的实体、支撑答案的文档)。随后,我们通过优化公式 (9) 的统一训练目标,在收集的数据集上训练 GFM。这让模型能有效学习查询与图中知识的复杂关联,并泛化到各类图结构知识。
为支撑大规模训练与推理,我们首先采用混合精度训练:训练吞吐量提升 2.1 倍,GPU 显存占用降低 17.5%。为进一步扩展模型与图的规模,我们实现了分布式消息传递机制,支持在多 GPU 上进行分布式训练与推理。具体来说,我们用METIS 算法将完整的图划分为均衡的子图,每个设备(GPU)仅在内存中存储图的一部分。在消息传递过程中,每个 GPU 先做本地信息聚合,再和其他 GPU交换消息,最终完成节点向量的更新。因此,G-reasoner 单设备的内存复杂度为O((∣V∣/N)∗d),其中N是 GPU 数量,d是向量维度。该设计让 G-reasoner 可通过增加 GPU 数量,有效适配更大规模的图、更大参数量的模型。详细的工程实现与效率分析见附录 C.2、C.3 和正文 5.5 节。
二、核心逻辑一句话概括
我们要让 G-reasoner能处理超大图、跑得快、省显存,所以做了两件事:
- 用海量多领域数据训练 → 让模型通用、能泛化;
- 用混合精度 + 分布式消息传递 → 让模型能跑超大图、多 GPU 并行。
三、逐句大白话拆解(全是人话,无术语)
第一部分:大规模弱监督训练(模型怎么练得通用)
1. 为什么要大规模训练?
之前小数据训练 → 模型只会处理「苹果 iPhone」这一种图;大规模多领域数据训练 → 模型能处理医疗、法律、百科、金融所有领域的图。
2. 训练数据长什么样?
我们收集了N 组数据,每组包含 3 个东西:
- qi:用户问题(比如 “iPhone15 价格”“糖尿病治疗方案”)
- Gi:对应的图(转成 QuadGraph)
- Vqi+:简单标注的相关节点(不用精细标,只标哪个节点是答案)
3. 图的来源五花八门
不管是知识图谱、文档图、层级图 → 全都转成QuadGraph,模型不用区分图类型,一套参数通吃。
4. 弱监督是什么意思?
- 强监督:要标全所有节点、关系、路径,极贵、极慢;
- 弱监督:只标 “哪个节点和答案相关”,便宜、快、能标海量数据。
第二部分:工程优化(怎么让模型跑得快、能处理超大图)
这部分是工业落地关键,解决两个问题:① 训练太慢;② 图太大,一张 GPU 存不下。
优化 1:混合精度训练(提速 + 省显存)
- 普通训练:用 **32 位浮点数(FP32)** 算,又慢又占显存;
- 混合精度:大部分计算用16 位浮点数(BF16),关键计算用 FP32;
- 效果:✅ 速度变快2.1 倍✅ 显存省17.5%
- 大白话:用更少算力,干更多活。
优化 2:分布式消息传递(多 GPU 一起算超大图)
核心痛点:
一张 GPU 显存有限,上亿节点的超大图存不下、算不动。
解决方案(比喻:分书阅读)
把整张超大图比作一本超级厚的书:
- METIS 算法切图:把书均匀切成 N 份(N=GPU 数量),每份大小差不多;
- 分 GPU 存储:每个 GPU 只拿其中一份子图,不用存整本书;
- 本地计算:每个 GPU 先算自己手里这部分的消息传递;
- 跨 GPU 交换消息:不同 GPU 交换 “邻居信息”,把结果拼起来;
- 完成更新:所有 GPU 一起算出完整的节点向量。
内存复杂度公式大白话
O((∣V∣/N)∗d)
- ∣V∣:总节点数
- N:GPU 数量
- 结论:GPU 越多,每张卡存的节点越少,就能处理无限大的图。
三、结合你熟悉的「苹果例子」讲解
假设我们要处理全球所有科技公司的超大图(1 亿节点):
- 一张 80G A100 显卡存不下 → 用10 张显卡;
- METIS 把 1 亿节点切成 10 份,每张卡存1000 万节点;
- 混合精度训练 → 每张卡显存省 17.5%,速度翻倍;
- 每张卡先算自己的子图,再交换消息 → 完美跑完超大图;
- 训练完的模型 → 既能处理苹果的图,也能处理华为、微软的图。
四、这段内容的核心价值(组会汇报必说)
- 数据层面:用大规模弱监督 + QuadGraph 统一格式 → 模型通用、能跨领域、跨图结构;
- 工程层面:混合精度 + 分布式消息传递 → 模型跑得快、省显存、能处理上亿节点的超大图;
- 落地意义:从实验室小模型,变成工业界能用的大规模系统。
我们要让 G-reasoner能处理超大图、跑得快、省显存,所以做了两件事:
- 用海量多领域数据训练 → 让模型通用、能泛化;
- 用混合精度 + 分布式消息传递 → 让模型能跑超大图、多 GPU 并行。
3. 图的来源五花八门
不管是知识图谱、文档图、层级图 → 全都转成QuadGraph,模型不用区分图类型,一套参数通吃。
4. 弱监督是什么意思?
- 强监督:要标全所有节点、关系、路径,极贵、极慢;
- 弱监督:只标 “哪个节点和答案相关”,便宜、快、能标海量数据。
.3 语言基础模型推理
依托统一的 QuadGraph 与基于 GNN 的图基础模型,G-reasoner 可高效对图结构知识进行推理,并为任意节点类型(属性、实体、文档、社区)提供通用化预测。这让 G-reasoner 能从图的不同层级中,灵活选取不同粒度的最相关信息,进而增强大语言模型的推理能力,提升下游任务的效果。
具体而言,给定用户查询q,GFM 首先在 QuadGraph 图G上完成推理,预测每个节点v∈V的相关性分数p(v)。随后,基于预测分数,选取每种节点类型的 top-k 个最相关节点Vqk={Vq,tk∣t∈T},为 LLM 提供最相关的信息以增强推理。该过程可公式化为:

- GFM 给所有节点打分(0~1 的相关性分数)
- 按节点类型,分别挑前 k 个最高分节点→ 实体挑 top-k、属性挑 top-k、文档挑 top-k、社区挑 top-k
- 把查询 + 挑出来的节点信息,拼成提示词(Prompt)
- 把 Prompt 喂给 LLM,LLM 生成最终答案
- 为什么要 “按类型选 Top-k”?避免某一类节点(比如文档)占满所有信息,保证属性、实体、文档、社区四类信息都能给到 LLM,信息更全面。
- Prompt 的作用把 GFM 筛选出的结构化关键信息,整理成 LLM 能看懂的自然语言。
- G-reasoner 的最终闭环异构知识→QuadGraph 统一→GFM 精准筛选→LLM 生成答案→ 解决 LLM 知识零散、推理不准的问题。
具体提示词:

作为一名高级阅读理解助手,你的任务是细致分析文本段落和对应的问题。你的回复需以 “Thought:” 开头,在这部分你要有条理地拆解推理过程,说明你是如何得出结论的。最后以 “Answer:” 结尾,给出简洁、明确的最终答案,无需额外解释。

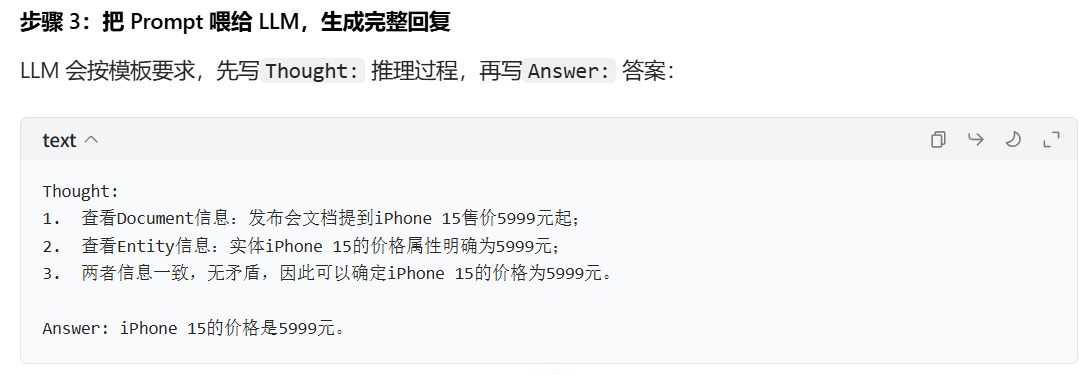
这个提示词模板的核心是 **“结构化输入 + 强制推理 + 标准化输出”**:我们把 GFM 筛选出的文档和实体信息分开喂给 LLM,让它先基于这些信息拆解推理过程,再给出简洁答案。这样既保证了 LLM 的答案有图知识支撑,又能通过
Thought:过程排查错误,提升了下游任务的准确性和可解释性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)