如何理解扩散diffusion模型
文章主要解决以下问题
1什么是diffuson
2.什么是噪声,噪声的作用
3.为什么去噪后可以预测轨迹
一.首先介绍扩散模型
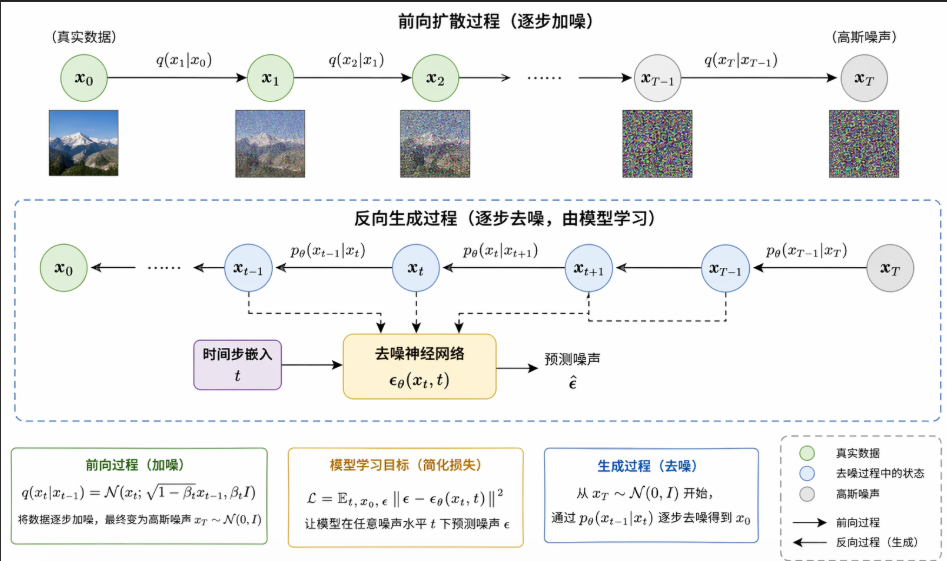
一句话总结扩散模型本质:如何把“纯噪声”一步一步还原成“有结构的数据”
它先定义一个“破坏数据”的过程:把真实样本一点点加噪,最后变成近似高斯白噪声。
然后训练一个神经网络去学它的逆过程:从噪声开始,一步步去噪,最后生成样本。
所以你可以把它理解成:
- 正向扩散:把图像/轨迹/语音慢慢“弄坏”
- 反向去噪:学会怎么把它“修回来”
传统生成模型常常想“一次性”生成结果。
扩散模型不是,它是:
- 先从随机噪声开始
- 第一步去掉一点无意义噪声
- 再去掉一点
- 再修正一点结构
- 最后得到清晰结果
这带来一个很关键的优点:
- 生成过程更稳定
- 训练目标更简单
- 多模态更自然
这也是为什么它在图像生成、视频生成、3D、分子生成、轨迹预测里都这么强。
二、噪声到底是什么
在轨迹 diffusion 里,噪声通常就是:
ε ~ N(0, I)
也就是一个和轨迹张量同形状的高斯随机变量。
如果未来轨迹是:x0: [B, 12, 2]
那噪声也是:ε: [B, 12, 2]
每个未来时刻、每个坐标维度,都会被加上随机扰动。
训练时不是“从噪声生成轨迹”,而是先拿到真实未来轨迹 GT。
设:
x0= 真实未来轨迹t= 随机采样的扩散步数ε= 随机噪声
然后构造一个“被污染后的轨迹”:
![]()
这公式是什么意思
它的意思是:
- 当
t很小,x_t还很像真实轨迹 - 当
t很大,x_t基本接近纯噪声
所以 x_t 是一条 “不同脏乱程度的轨迹”
你可以这样理解:
t=0几乎就是真实轨迹
t=100真实轨迹还能勉强看出来一点
t=1000基本已经是一团随机点了
diffusion模型训练的目标不是预测轨迹,而是预测噪声,why?
当我们将加噪(即污染过的)轨迹,在某些条件下,喂给模型,其实是要模型猜这条轨迹哪些是噪声。所以模型的预测输出其实是噪声。训练的损失通常就是预测的噪声与真实加入噪声的差
三、为什么去噪可以得到轨迹
推理流程
Step 1:先初始化一条纯噪声轨迹
xT ~ N(0, I)
shape = [B, 12, 2]
这时候它根本不是轨迹,只是一堆随机数。
可以理解为:
- 12 个未来时刻
- 每个时刻一个
(x, y) - 但这些点毫无运动意义
Step 2:把它送进模型
模型看:
- 当前随机轨迹
x_t - 历史观测条件
condition - 当前时间步
t
输出:
- 这条“假轨迹”里面哪些成分是噪声
Step 3:去掉一部分噪声,得到更干净的 x_{t-1}
也就是:
xt → 预测噪声 → 去噪 → x(t-1)
Step 4:反复执行
从 T → T-1 → T-2 → ... → 1 → 0
最后得到:x0,这个 x0 就是最终生成的未来轨迹。
给一个超简版例子
假设未来只预测 3 帧,不是 12 帧。
真实未来轨迹:x0 = [(1,1), (2,2), (3,3)]
采样一个时间步 t,加噪后:xt = [(0.7,1.8), (1.2,2.5), (4.1,1.9)]
这时候模型看见:
xt:这条又歪又乱的“伪轨迹”obs:过去轨迹一直朝右上移动short_intent:接下来还会继续朝右上goal:终点大概率也在右上
模型就会学会判断:
- 第一帧 y 偏高了,是噪声
- 第二帧 x 偏低了,是噪声
- 第三帧整体方向不对,是噪声
然后逐步修回来。
最后采样结束,就得到一条平滑、方向合理、终点合理的轨迹。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)