论文精读:《Lost in the Middle》—— 为什么 LLM 会“迷失在长上下文的中间“
论文信息:Lost in the Middle: How Language Models Use Long Contexts
作者:Nelson F. Liu 等(Stanford, UC Berkeley, Samaya AI)
发表:arXiv:2307.03172,2023年7月
核心发现:当前语言模型在处理长上下文时存在显著的"U型性能曲线"——对开头和结尾的信息敏感,对中间信息严重遗忘。
1. 想象一下这个场景
你正在参加一场漫长的会议,会议室里坐了20个人,每个人都要发言5分钟。会议持续了2小时。现在主持人突然提问:“大家还记得第8个发言者说了什么吗?”
你可能会发现:
- 开头几个人的发言印象深刻( primacy bias,首因效应)
- 最后几个人的发言也还记得(recency bias,近因效应)
- 中间那群人说了什么?已经模糊成一团了
这正是这篇论文发现的核心现象:语言模型就像参加会议的人一样,对长上下文中间的信息"迷失"了。
2. 研究背景:长上下文能力的幻觉
2.1 上下文窗口的军备竞赛
2023年以来,各大厂商疯狂扩展模型的上下文窗口:
- GPT-3.5:4K → 16K
- Claude:8K → 100K
- GPT-4:128K
- 甚至出现了声称支持"无限上下文"的模型
💡 理解要点:窗口变大了 ≠ 模型会用好。就像给你一间1000平米的会议室,不代表你能同时听清1000个人的发言。
2.2 研究的切入点
论文作者提出了一个关键问题:
如果模型真的能"稳健地"使用长上下文,那么答案文档放在第1个、第10个还是第20个位置,不应该影响回答准确率。
但现实是这样吗?
3. 核心实验设计:"大海捞针"的变体
3.1 任务一:多文档问答(Multi-Document QA)
场景模拟:类似于 Bing Chat 或 Perplexity 的检索增强生成(RAG)
实验设置:
- 准备一个问题(如"谁获得了第一个诺贝尔物理学奖?")
- 准备 k 个文档,其中恰好有1个包含答案,其余 k-1 个是干扰文档
- 将包含答案的文档放在不同位置(第1个、第5个、第10个…)
- 测试模型能否准确找出答案
输入上下文示例:
Document [1]: 亚洲美国人在科技领域(无关文档)
Document [2]: 诺贝尔物理学奖得主名单(**包含答案的文档**)← 答案在这里!
Document [3]: 科学家的定义(无关文档)
...
Question: 谁获得了第一个诺贝尔物理学奖?
变量控制:
- 上下文长度:10个文档(~2K tokens)、20个文档(~4K tokens)、30个文档(~6K tokens)
- 答案位置:第1、5、10、15、20、25、30个位置
3.2 任务二:键值检索(Key-Value Retrieval)
更简单的测试:模型能否从一堆"键值对"中找到特定键对应的值?
输入上下文:
{"key": "apple", "value": "苹果"}
{"key": "banana", "value": "香蕉"}
...(共100个键值对)...
{"key": "zucchini", "value": "西葫芦"}
Query: orange 对应的 value 是什么?
这个任务极其简单——不需要推理,只需要匹配。如果连这都做不到,说明模型根本没有"看到"中间的信息。
4. 震撼发现:U型性能曲线
4.1 核心图表解读
论文的 Figure 5 展示了一个惊人的发现:
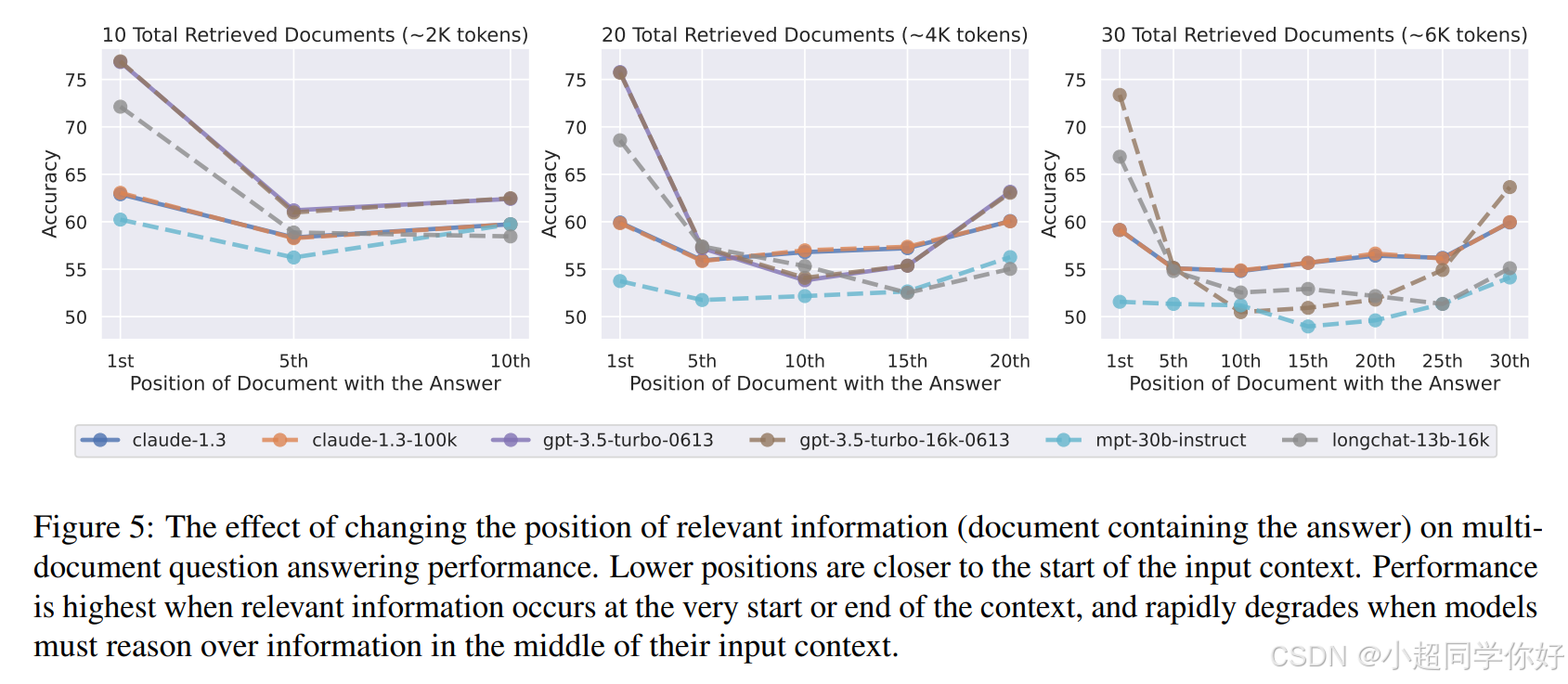
X轴:包含答案的文档位置(越靠左越靠前)
Y轴:模型回答准确率
曲线形状:明显的 U型
| 答案位置 | GPT-3.5-Turbo (20 docs) | Claude-1.3 (20 docs) | MPT-30B |
|---|---|---|---|
| 第1个(开头) | ~75% | ~70% | ~65% |
| 第10个(中间) | ~55% | ~60% | ~50% |
| 第20个(结尾) | ~70% | ~68% | ~62% |
🔍 关键发现:
- 开头和结尾表现最好(primacy bias + recency bias)
- 中间位置性能暴跌——GPT-3.5-Turbo在中间位置的表现甚至比"不看任何文档"(closed-book,约56%)还要差!
- 上下文越长,中间性能越差——30个文档时的中间性能比10个文档时更差
4.2 一个简单的键值对都找不出来
在键值检索任务中,即使是 GPT-3.5-Turbo 和 Claude,当目标键值对放在第50-75个位置时(共100个),准确率也会从近乎完美的100%暴跌到约60%。
💡 理解要点:这不是"理解能力"的问题,而是**“能不能看到”**的问题。模型根本没有把注意力分配到中间的信息上。
5. 深挖原因:为什么模型会"迷失"?
5.1 架构差异:Encoder-Decoder vs Decoder-Only
论文测试了两种架构:
| 架构类型 | 代表模型 | 对位置变化的鲁棒性 |
|---|---|---|
| Decoder-only | GPT-3.5, Claude, MPT | 差(明显的U型曲线) |
| Encoder-decoder | Flan-T5-XXL, Flan-UL2 | 相对好(在训练长度内) |
关键差异:
- Encoder-decoder:编码器可以双向关注,文档之间可以互相"看见"
- Decoder-only:只能单向关注(从左到右),中间的文档被"淹没"了
⚠️ 但是:Encoder-decoder 模型只在训练时的上下文长度内表现好。一旦超出(如 Flan-UL2 超出2048 tokens),也会出现U型曲线。
5.2 Query-Aware Contextualization 有用吗?
一个常见的工程技巧:把 Query(问题)同时放在文档前面和后面,让模型能"带着问题"去阅读文档。
实验结果:
- 在简单的键值检索任务中:完全解决了U型曲线问题
- 在复杂的多文档问答任务中:几乎没用,U型曲线依然存在
💡 理解要点:对于需要深度推理的任务,仅仅"让模型看到问题两次"是不够的。模型仍然倾向于只关注开头和结尾的文档。
5.3 根本原因假说
作者提出了几个可能的解释:
-
注意力机制的固有偏差:
- Decoder-only 模型的注意力权重倾向于累积在开头(system/指令)和结尾(当前任务)
- 中间token的注意力被"稀释"了
-
训练数据的分布偏差:
- 预训练语料中,重要信息通常出现在文档的开头(标题、摘要)或结尾(结论)
- 模型学会了"不用仔细看中间"
-
位置编码的局限性:
- 即使是声称支持长上下文的模型(如 LongChat-13B-16K),其位置编码外推能力有限
- 超出训练长度的位置,模型难以准确估计相对距离
6. 对工程实践的启示
6.1 RAG系统的设计调整
传统做法(有风险):
[Top-10检索结果] + [用户问题]
→ 把最相关的文档放在第5-6个位置
→ 模型可能"看不见"
改进做法(基于论文发现):
[Top-3最相关文档] + [其他7个文档] + [用户问题]
→ 把最关键的文档放在开头或结尾
→ 确保模型一定能看到
6.2 上下文组装策略
基于这篇论文的发现,推荐的上下文组装顺序:
messages = [
# 1. System rules(必须置顶)
{"role": "system", "content": SYSTEM_PROMPT},
# 2. 最关键的信息(放开头,利用 primacy bias)
{"role": "system", "content": MOST_IMPORTANT_CONTEXT},
# 3. 辅助信息(放中间,接受可能的信息损失)
{"role": "system", "content": SECONDARY_CONTEXT},
# 4. 再次强调关键约束(放结尾前,利用 recency bias)
{"role": "system", "content": KEY_CONSTRAINTS_REMINDER},
# 5. 当前任务(必须放最后)
{"role": "user", "content": CURRENT_TASK}
]
6.3 "重锚"策略(Re-anchoring)
对于必须在多轮对话中保持的关键信息(如 order_id、user_id),不要指望模型"记住"——在每一轮都重新放在开头或结尾。
第1轮:
[ANCHOR: order_id=ORD-123, user_id=U-456]
User: 我的订单到哪了?
第5轮(经过4轮闲聊后):
[ANCHOR: order_id=ORD-123, user_id=U-456] ← 重新锚定!
User: 那退款要多久?
6.4 文档数量 vs 质量的权衡
论文发现(见Figure 10和Table 2):
| 检索文档数 | GPT-3.5-Turbo 准确率 | 边际收益 |
|---|---|---|
| 1个 | ~65% | - |
| 10个 | ~68% | +3% |
| 20个 | ~70% | +2% |
| 50个 | ~71.5% | +1.5% |
💡 关键洞察:文档数量从20增加到50,性能只提升1.5%,但上下文成本增加了2.5倍,且中间文档更难被发现。
工程建议:
- RAG检索Top-K时,K不要设太大(10-20个足够)
- 与其堆数量,不如做精排——用reranker选出最相关的3-5个
- 关键文档强制放在开头或结尾
7. 局限与未来方向
7.1 论文的局限
- 只测试了特定类型的任务:问答和键值检索,没有涉及代码生成、创意写作等
- 模型版本较旧:GPT-3.5-Turbo-0613、Claude-1.3, newer models may have improved
- 没有分析注意力热力图:如果能可视化attention weight会更有说服力
7.2 2024年以来的进展
论文发表后,业界有一些改进尝试:
-
Lost in the Middle 的缓解技术:
- Prompt Compression:自动压缩中间文档(如 LLMLingua)
- Hierarchical Retrieval:先做粗排,再把精选文档放在关键位置
- Query Rewriting:根据对话历史改写query,使其更具体,减少需要检索的范围
-
新架构的探索:
- Ring Attention:更高效的注意力机制
- RAG Fusion:多路召回后的智能合并
-
但核心问题依然存在:
- 即使是 GPT-4、Claude 3,在极端长的上下文(>50K tokens)中仍会出现"迷失"
8. 小结:三个关键 takeaway
🔑 Takeaway 1:长上下文是一种"奢侈品",不是"免费资源"
- 窗口变大了,但有效利用范围没有同比扩展
- 超过20个文档的边际收益极低
- 设计系统时,应假设模型只能"稳健地"使用开头的3-5个和结尾的3-5个
🔑 Takeaway 2:位置就是一切
- 在组装上下文时,信息的位置比信息的数量更重要
- 关键约束放开头(system)或结尾(user task之前)
- 接受"中间位置的信息可能会丢失"这一事实,并设计相应的重锚机制
🔑 Takeaway 3:测试你的系统
如果你正在构建RAG或长上下文应用,建议做这个测试:
1. 准备10个问题,每个问题有对应的答案文档
2. 把答案文档分别放在:第1个、第5个、第10个位置
3. 测试你的系统的回答准确率
4. 如果出现U型曲线,说明你需要调整上下文组装策略
参考资料
-
原始论文:Liu et al., “Lost in the Middle: How Language Models Use Long Contexts”, arXiv:2307.03172, 2023.
[参考:https://arxiv.org/abs/2307.03172] -
后续相关研究:
- “Lost in the Middle, Yet Again: Sequence Construction and the Needle in the Haystack” (2024) - 对更长的上下文和更新模型的验证
- “RAG Fusion” - 多路召回后的智能合并技术
- “LLMLingua” - Prompt压缩技术
-
工程实践参考:
- OpenAI Prompt Caching 文档(长前缀/静态指令置前的优化)
- Anthropic Context Window 最佳实践指南

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)