【内涵】NaVIT解读
[内涵]NaVIT源码解读
前言
[内涵]VIT源码解读中介绍了目前在LLM/VLLM领域已经占据主流地位的VIT。但是在VIT中将不同分辨率强行resize到同一个尺寸的方式,显然直觉上有点生硬。在QWenvl系列中,采用的是VIT的改进版本,支持任意分辨率图像输入的NaVIT,本文章是对NaVIT的理解和记录。从下面的论文主图上也可以看出,该文章已经直接省去了architecture的介绍, 而是直接展示了Data Preprocessing—>Self-Attention—>Pooling Representations不同的阶段如何pack-pad-mask的。

下面,依旧是确定一个具体的调用场景,来说明NaVIT的机制。
import torch
from vit_pytorch.na_vit import NaViT
v = NaViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0,
emb_dropout = 0,
token_dropout_prob = 0 # token dropout of 10% (keep 90% of tokens)
)
images = [
torch.randn(3, 256, 256),
torch.randn(3, 128, 128),
torch.randn(3, 128, 256),
torch.randn(3, 256, 128),
torch.randn(3, 64, 256)
]
preds = v(
images,
group_images = True,
group_max_seq_len = 64
) # (5, 1000)
带着问题来阅读源码
问题1:设想如果是自己,会如何做任意分辨率的VIT改进
如果是我,大概率会做成如下不做resize,而是pad的形式,来达到任意分辨率的输入。
这样做,确实是一种办法,而且在CNN领域的数据resize_and_pad预处理操作中是有这样的选项。但是如果是这样的话,就不值得发表一篇paper且其贡献程度还被nerlps审稿人认可。
问题2:事实上,NaVIT是如何做的,和我自己想的有什么更优秀之处
之所以,navit会比自己的直觉更胜一筹,原因在于我的上述做法是来源于CNN时代,这种想法没有利用到transfromer架构中两点很有用的信息:
- transformer是一种point-wise架构;
- 可以利用mask机制来做同一token sequence中信息的隔离;
有了这样两个更进一步的insigts,就可以不单单的做padding,而是可以进一步的做packing。具体来讲是做成如下的packing(红色表示当前sequence的第一副图片,绿色表示另外一副图片,灰色表示padding区域) 。也就是说原本batch_size为5,经过pack之后,可以将其压缩为batch_size为3。因为是point-wise架构,大家不同的sequence token互不干扰,拼在一起也没关系。
而attention的mask机制则用来在需要的时候区分同一sequence中的不同图片边界。其实该机制已经在transformer架构中应用过,例如很常见的通过mask_attention来防止 t i t_i ti处的token看到 t j t_j tj处oken的信息,其中 j > i j>i j>i。其数学原理是
s o f t m a x ( Q K T d i m + m a s k ) V softmax(\frac{QK^{T}}{\sqrt{dim}} + mask)V softmax(dimQKT+mask)V, mask默认值为0,如果想屏蔽掉 t j t_j tj处token对 t i t_i ti处token的“影响”,只需要将 m a s k i , j = − i n f mask_{i,j}=-inf maski,j=−inf即可,因为 e − i n f = 0 e^{-inf}=0 e−inf=0。而对应这一实际例子的场景,其三个mask为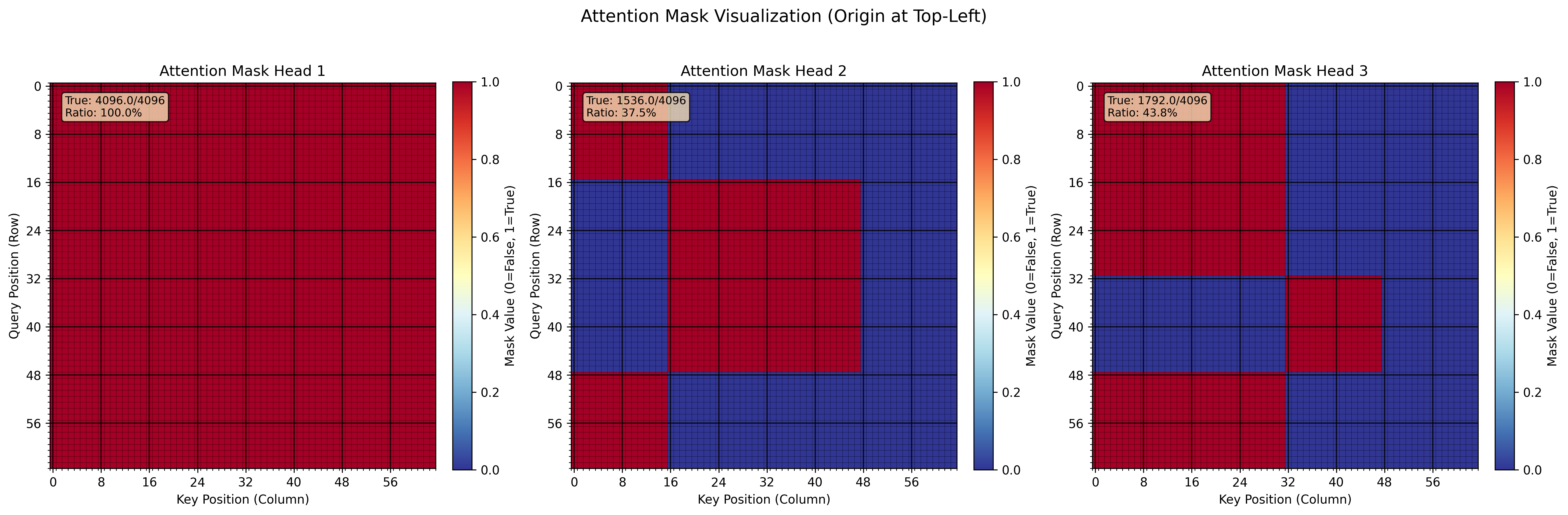
另外一个点是如何做cls head头呢?在[内涵]VIT源码解读中,讲过它是通过在一开始添加一个learnable 的cls token,然后最后提取该cls token的信息来做分类头;另外一种做法是直接在image token中接一个GAP(global average pool)的操作。在NAVIT中是出现了目前遇到的第三种做法:基于query的attention pool操作。具体说来,就是在transformer的末端是一个 t e n s o r 3 ∗ 64 ∗ 1024 tensor_{3*64*1024} tensor3∗64∗1024, 它会有5个learnable的 q u e r y 5 ∗ 1 ∗ 1024 query_{5*1*1024} query5∗1∗1024 然后去做query, 这里当然我们还是有mask可用来做隔断处于同一个sequence pack中的实际两幅图片的信息。这种做法的一个直观操作是它不是一种简单信息average的操作,但是也没有引入额外的参数量。
问题3:NaVIT真的比VIT要好吗?
是的,navit是要比vit更好的。体现在三个方面:(在达到相同pretrain/finetune的目标下)训练速度更快;(在训练到极致的情况下,pretrain/finetune)acc天花板更高;应用时分辨率的鲁棒性更强。
- pretrian阶段有优势:
- 对应左图:相同的pretrain时间,navit的pretrain acc更高;无限的pretrain时间,navit的潜力天花板更高
- fine阶段有优势:
- 对应中图:相同的pretrain时间拿出来的pretrain模型来做finetune获得的finetune acc更高;如果大家都pretrain到底,到自己的最好状态,navit的finetune acc更高
- inference阶段更有优势:
- 对应右图:拿出两个在高分辨率推理场景下,finetuen相同的模型,我们逐步的降低inference分辨率,navit微调出来的模型acc对于分辨率的变化更加鲁棒(表现为几乎与x轴平行的线),只有在极端推理分辨率的情形下,才会出现模型acc下降的情形。
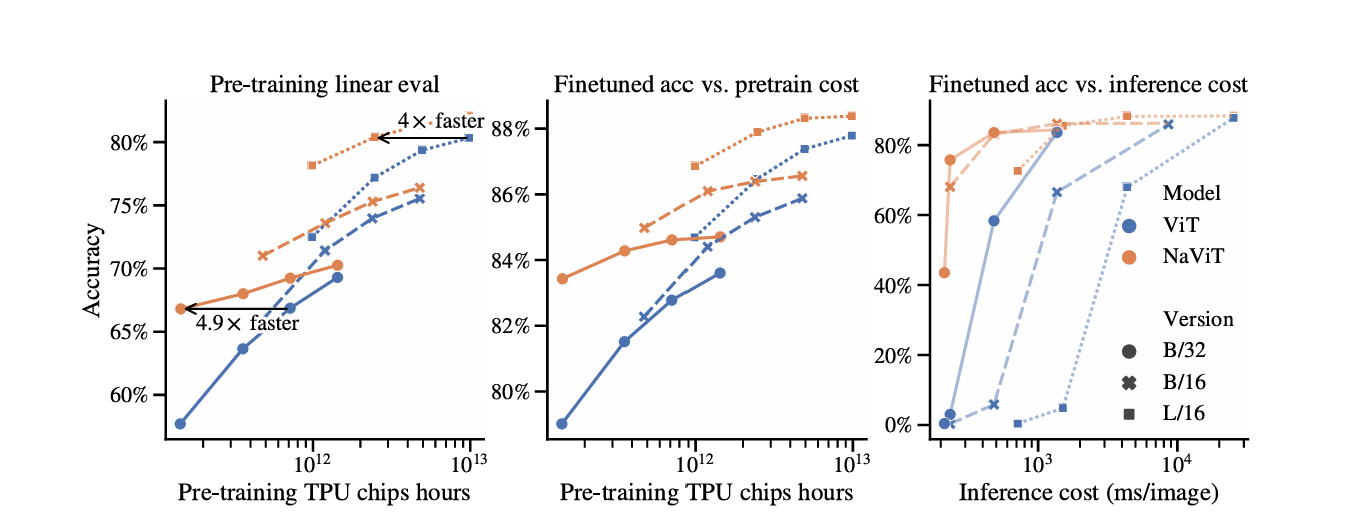
- 对应右图:拿出两个在高分辨率推理场景下,finetuen相同的模型,我们逐步的降低inference分辨率,navit微调出来的模型acc对于分辨率的变化更加鲁棒(表现为几乎与x轴平行的线),只有在极端推理分辨率的情形下,才会出现模型acc下降的情形。
问题4:NaVIT还有什么需要改进的地方吗?
暂且略过。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)