2026年如何微调大语言模型
本文深入探讨了强化学习在智能体训练中的应用,重点介绍了GRPO(组相对策略优化)算法和ART(智能体强化训练器)框架。GRPO通过比较多个模型输出的相对排名来指导学习,无需手写奖励函数。ART框架则提供了原生支持工具调用和多轮对话的功能,适用于复杂Agent的训练。此外,文章还介绍了RULER技术,利用LLM作为裁判评估智能体表现,进一步简化了强化学习过程。最后,文章展示了如何微调大语言模型并将其部署到手机上,实现了本地高效运行。
无需奖励函数的强化学习来了!
实战
2026年如何微调大语言模型[1]
如果你在用 GPT 或 Claude,你用的和其他所有人一样 — 相同的能力、相同的成本,没有任何竞争优势。但如果你拿一个小型开源模型,在你的特定任务上进行微调,它可以超越比它大 100 倍的模型,而成本和延迟只是零头。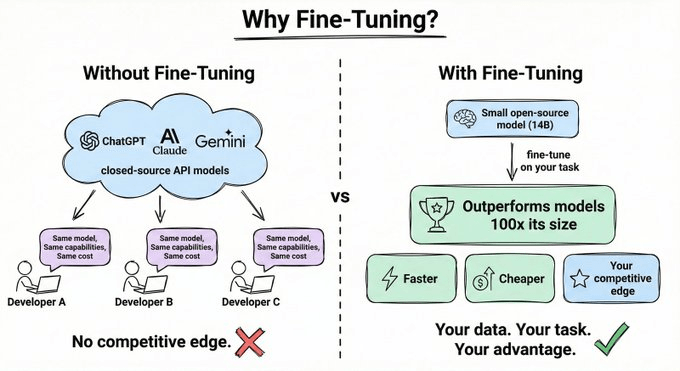
SFT vs. Reinforcement Fine-Tuning(强化微调)
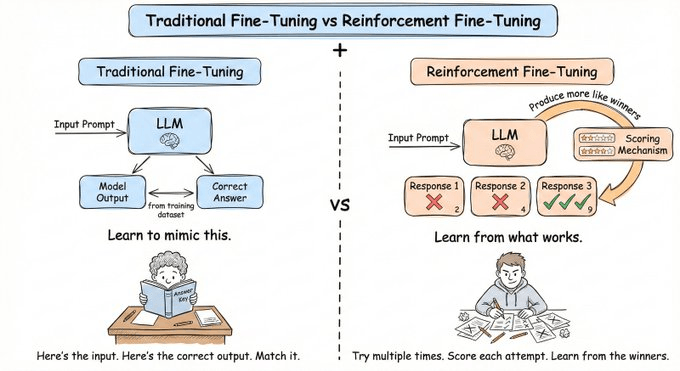
在 Supervised Fine-Tuning(监督微调,SFT)中,你收集输入-输出对,让模型学习模仿。问题在于,SFT 教的是模型说什么,而不是如何成功。对于需要搜索、调用 API、跨多步推理的 Agent 来说,光靠模仿是不够的。你需要的是通过试错来提升。可以这样理解:
- SFT = 看教科书(记住已知问题的答案)
- RL = 在岗培训(从实践、错误和反馈中学习)
GRPO 的工作原理
GRPO(Group Relative Policy Optimization,组相对策略优化)是目前最流行的 RFT 算法。它正是驱动 DeepSeek-R1 推理能力的同一算法。本质上,GRPO 不需要训练一个单独的模型来打分,而是生成多个补全结果,让它们相互比较。以下是每个 Prompt(提示)的处理流程:
- 采样一组:从当前模型生成 N 个补全结果
- 逐一评分:奖励函数评估每个尝试
- 组内归一化:计算相对于组均值的优势
- 更新模型:强化高于平均的行为,抑制低于平均的行为
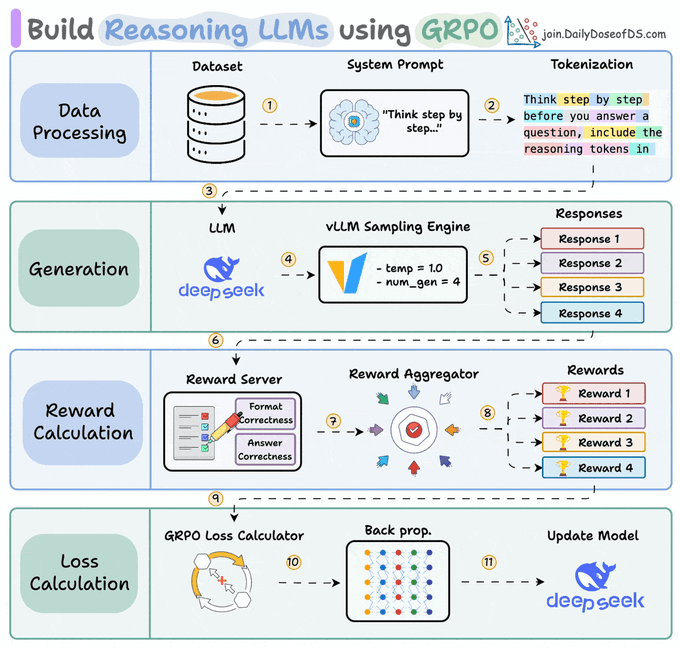
GRPO 只需要相对排名,不需要绝对分数。无论补全结果得分是 0.3、0.5、0.7 还是 30、50、70 都没关系,只有排序决定学习方向。
ART:Agent Reinforcement Trainer(智能体强化训练器)[2]
GRPO 很强大,但如何将它实际应用到真实世界的 Agent 上?ART(Agent Reinforcement Trainer)是一个 100% 开源框架[3],可以将 GRPO 应用到任何 Python 应用中。大多数 RL 框架是为简单的聊天交互而构建的 — 一个输入、一个输出,完事。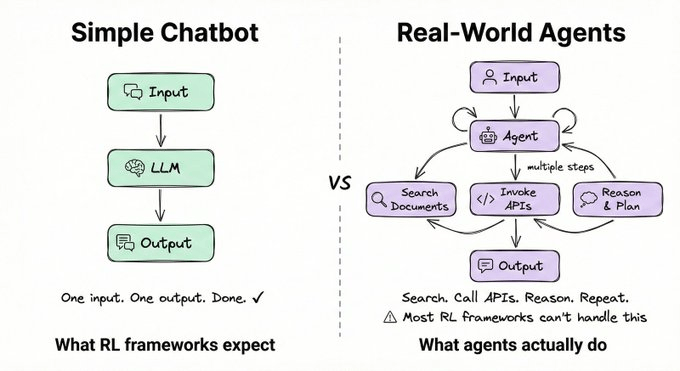
真实的 Agent 完全不同。它们要搜索文档、调用 API、跨多步推理才能给出答案。ART 正是为此而生。它提供:
- 原生支持工具调用和多轮对话
- 与 LangGraph、CrewAI 和 ADK 集成
- 训练期间的高效 GPU 利用
架构
ART 分为两部分:Client(客户端)和 Backend(后端)。Client 是你的 Agent 代码所在之处。它向 Backend 发送推理请求,并将每个动作记录到 Trajectory(轨迹)中 — 即一次 Agent 运行的完整历史。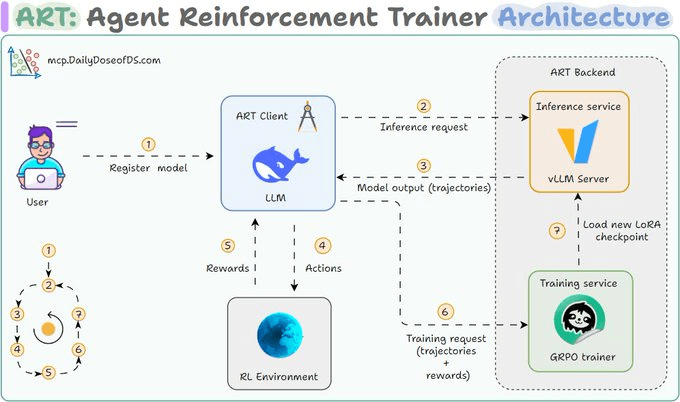
Backend 负责繁重的计算。它运行 vLLM 进行快速推理,使用 Unsloth 驱动的 GRPO 进行训练。每个训练步骤后,新的 LoRA Checkpoint(检查点)会自动加载到推理服务器中。
完整的训练循环
- Client 发送推理请求
- Backend 生成模型输出
- Agent 在环境中执行动作(工具调用、搜索等)
- 环境返回奖励
- Trainer(训练器)通过 GRPO 更新模型
- 新的 LoRA Checkpoint 加载到推理服务器
- 重复 — 每个循环,模型都比之前更好一点
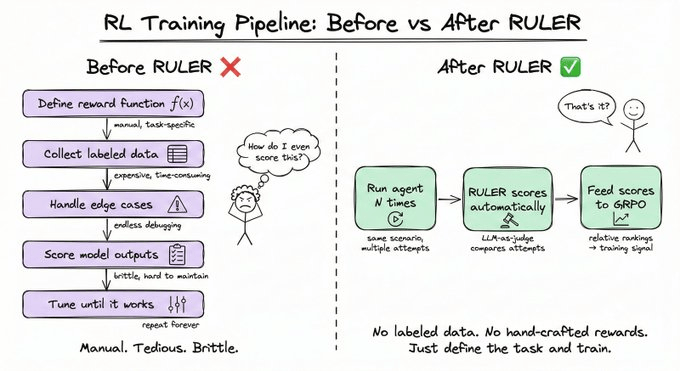
RULER:无需手写奖励函数的 RL
定义好的奖励函数一直是 RL 中最难的部分。训练一个邮件 Agent 需要标注的正确答案。训练一个代码 Agent 需要测试套件。每一个都是独立的工程项目。RULER(Relative Universal LLM-Elicited Rewards)彻底消除了这个瓶颈。它使用 LLM-as-Judge(LLM 作为裁判) 来比较多条 Agent 轨迹并排名 — 不需要任何标注数据。它之所以有效,基于两个关键洞察:
- 问 LLM “给这个打 0-10 分” 会产生不一致的结果
- 问 “这 4 次尝试中哪个最好地完成了目标?” 则可靠得多
而且由于 GRPO 只需要相对分数,绝对值根本不重要。流程只有三步:
- 为一个场景生成 N 条轨迹
- 传给 LLM 裁判,它为每条轨迹打 0 到 1 的分
- 将这些分数直接作为 GRPO 的奖励
一个实际示例
我们做了一个完整可运行的 Notebook,用 ART 通过强化学习训练一个 3B 模型来掌握如何使用任意 MCP Server。只需提供一个 MCP Server URL,这个 notebook[4] 就会:
- 查询服务器的工具列表
- 生成一组使用这些工具的输入任务
- 使用自动 RULER 评估在这些任务上训练模型
你可以在 ART GitHub 仓库中找到更多示例来适配和上手。GitHub 仓库在这里 →[5]
智能体
被驾驭的 LLM Agent[6]
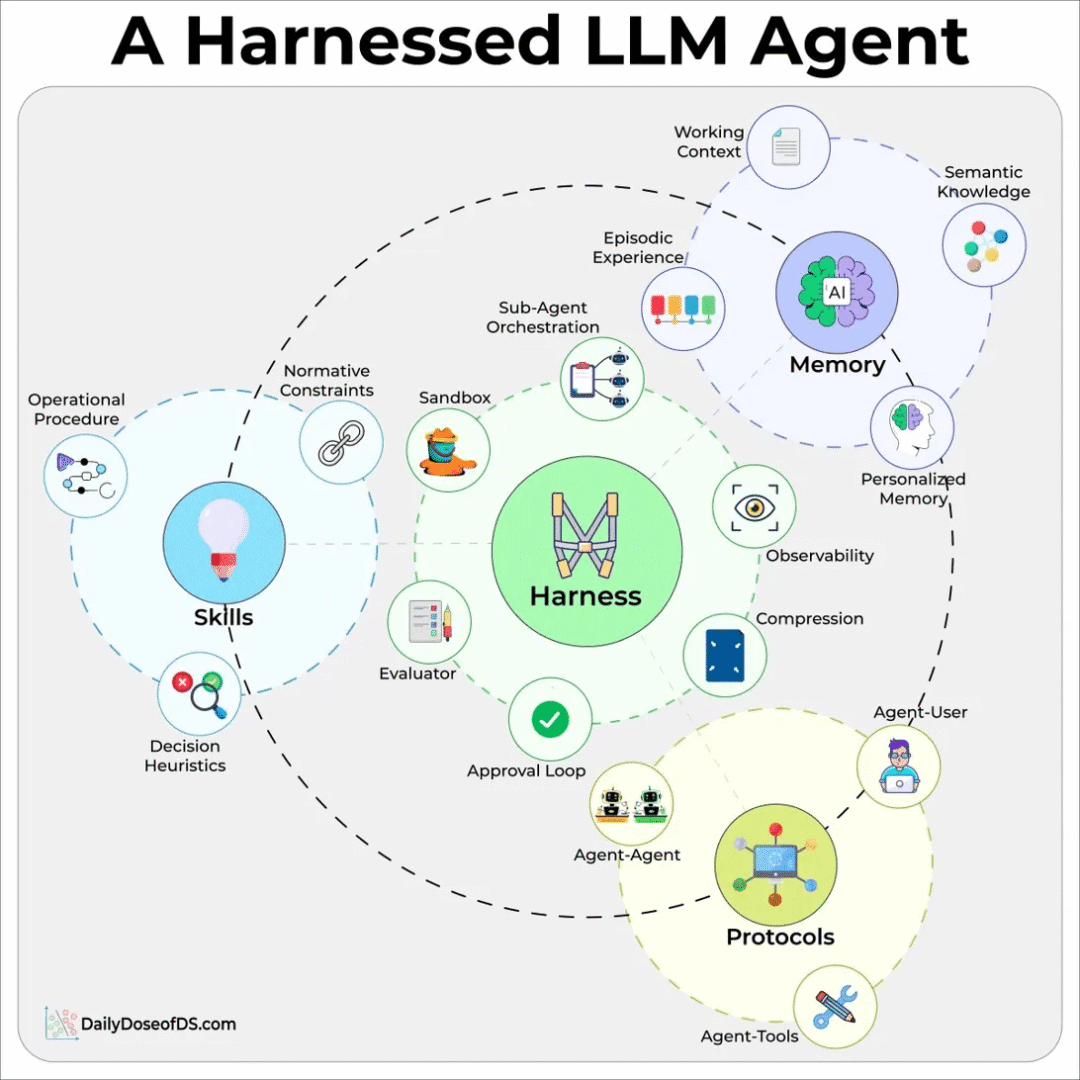
当人们描述一个 Agent 时,通常会说是一个配了工具的模型。但实际上,架构恰好相反。模型本身保持小而简单,真正的工作发生在模型之外的独立模块中,而 Harness(框架/驾具)[7] 是在运行时将这些模块组合在一起的东西。Harness 周围有三个核心区域:
- Memory(记忆) 保存模型不该写入权重或每轮都塞进上下文的信息。Working Context(工作上下文)、Semantic Knowledge(语义知识)、Episodic Experience(情景经验)和 Personalized Memory(个性化记忆)各有自己的读写路径和生命周期。
- Skills(技能) 保存可复用的分步操作知识,模型在任务匹配时调用。操作流程、决策启发式和规范约束让通用模型无需重新训练就能在特定领域发挥作用。
- Protocols(协议) 保存 Agent 与外界通信的规则。Agent 到用户、Agent 到 Agent、Agent 到工具是三个不同的接口面,各有各的故障模式。在代码中混用它们是不稳定行为的常见来源。
在核心和这三个区域之间,是维持循环运转的组件,包括沙箱、可观测性、压缩、评估、审批循环和子 Agent 编排。压缩比看起来更重要,因为长时间运行的 Agent 经常超出模型的 Token 预算。仅评估一项就能将输出质量提升两到三倍 — 据 Claude Code 的创建者 Boris Cherny 所言。这种架构让每个新能力都有明确的归属。稳定信息进入 Memory,可复用知识进入 Skills,通信规则进入 Protocols,循环管理进入支撑组件。当所有这些都被塞进一个 System Prompt(系统提示)时,通常意味着 Harness 还没有被拆解开。这也解释了为什么 Harness 设计变得如此重要。Meta 在 2025 年末以约 20 亿美元收购了 Manus,相关报道明确指出,收购的是 Harness,而不是模型。这个领域已经发展到模型周围的层才是产品。我们正在从零开始构建一个小型 Agent Harness,以便更直观地展示。我们很快就会发布。同时,你可以在这里阅读我们关于 Agent Harness 的深度解读 →[8]
实战
在手机上部署和运行大语言模型![9]
你现在可以微调大语言模型并直接部署到手机上。今天,我们将介绍一个分步指南,展示如何微调 Qwen3,然后将其导出为移动端格式,100% 本地运行在你的 iOS 或 Android 设备上。我们会用到:
- UnslothAI[10] 用于微调
- TorchAO 用于手机友好的量化
- ExecuTorch 用于在 iOS 上运行
开始吧!
1️⃣ 加载模型
首先,我们以手机部署模式加载 Qwen3-0.6B。这会启用量化感知训练(Quantization-Aware Training),确保一切与后续的移动端导出兼容。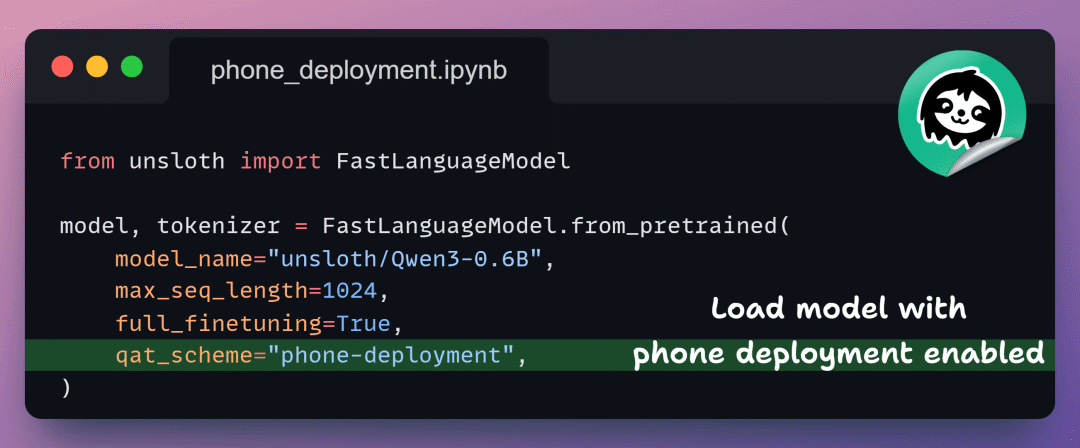
2️⃣ 加载数据集
接下来,我们决定模型要学什么。
我们加载:
- 一个推理数据集用于增强能力
- 一个对话数据集让它表现得像助手
此时,两个数据集仍是原始格式。
3️⃣ 转换推理数据
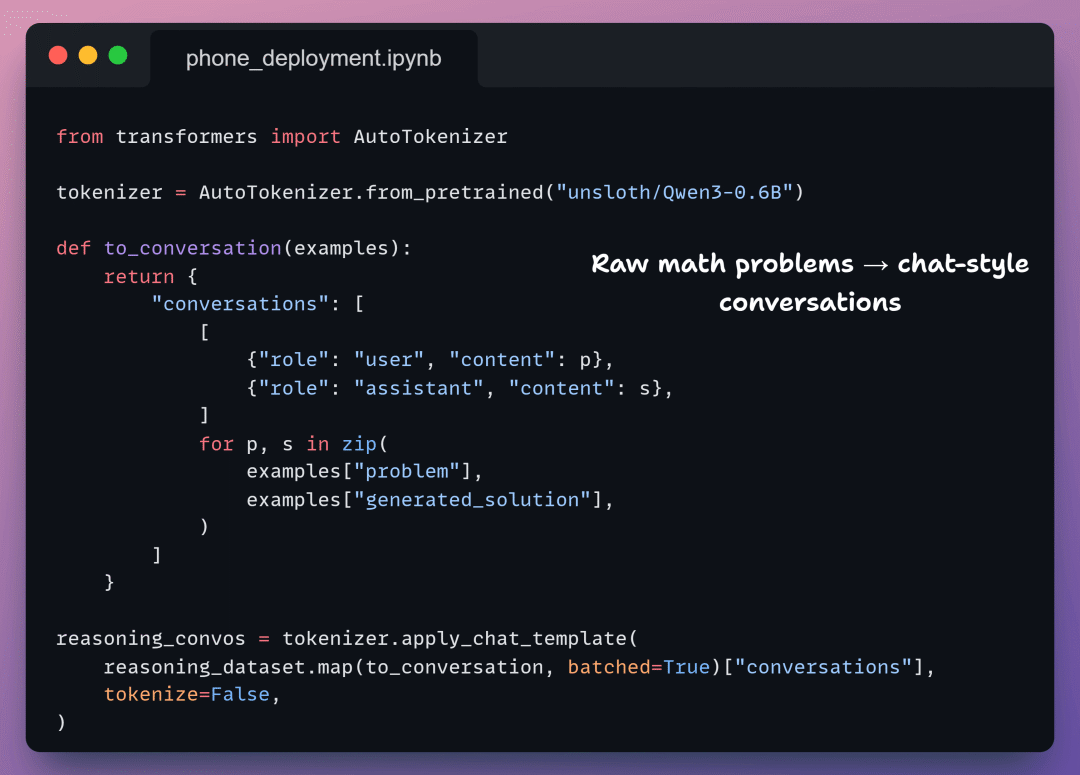
现在我们将推理数据转换为 用户 → 助手 的对话格式。这教模型的是如何推理,而不仅仅是最终答案。
4️⃣ 标准化对话数据
接下来,我们将它们转换为对话数据集格式。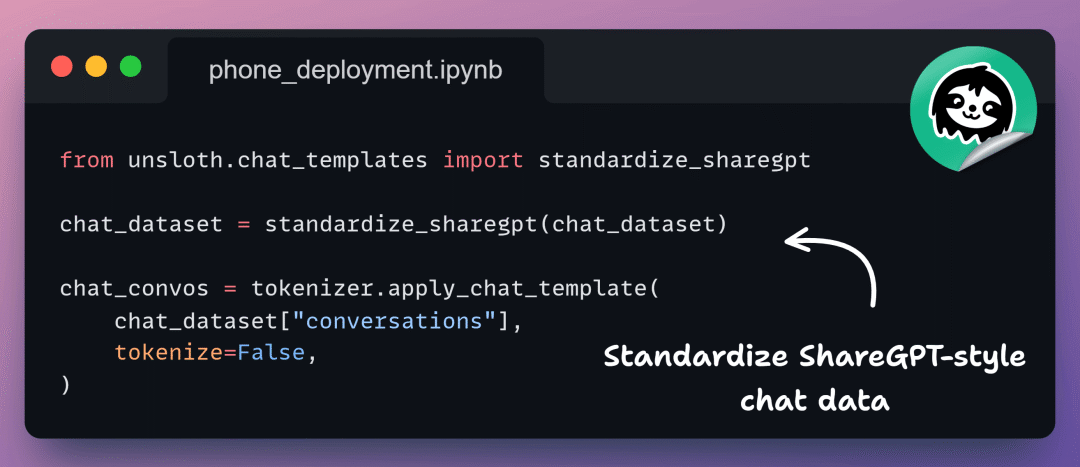
这确保两个数据集遵循相同的 Schema(结构)。此时,推理数据和对话数据对模型来说看起来完全一样。
5️⃣ 混合数据集
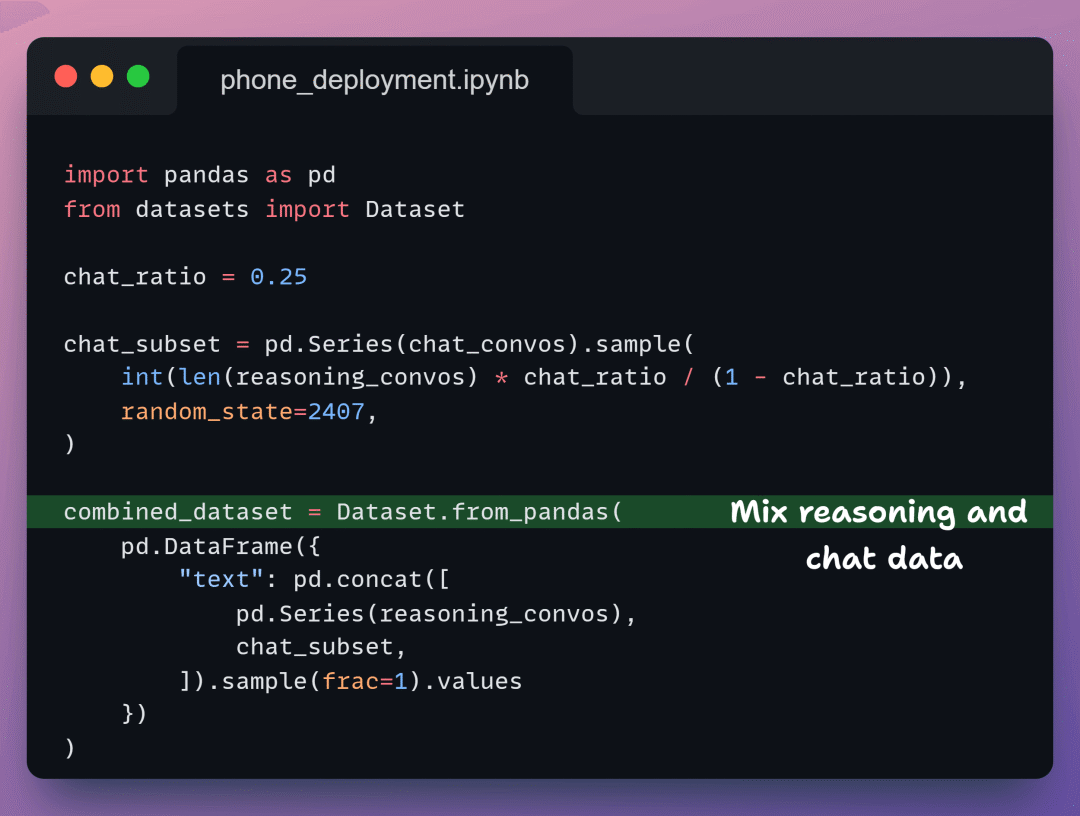
现在,我们决定模型应该多少比例用于推理、多少用于对话。我们保留 75% 推理让模型能思考,25% 对话让它说话自然。这给了我们一个兼具两种能力的干净数据集。
6️⃣ 训练模型

接下来,我们设置 Trainer 并开始微调。我们保持训练时间较短,以便快速进入移动端导出阶段。这里 Loss(损失)在下降,说明模型正在被正确训练。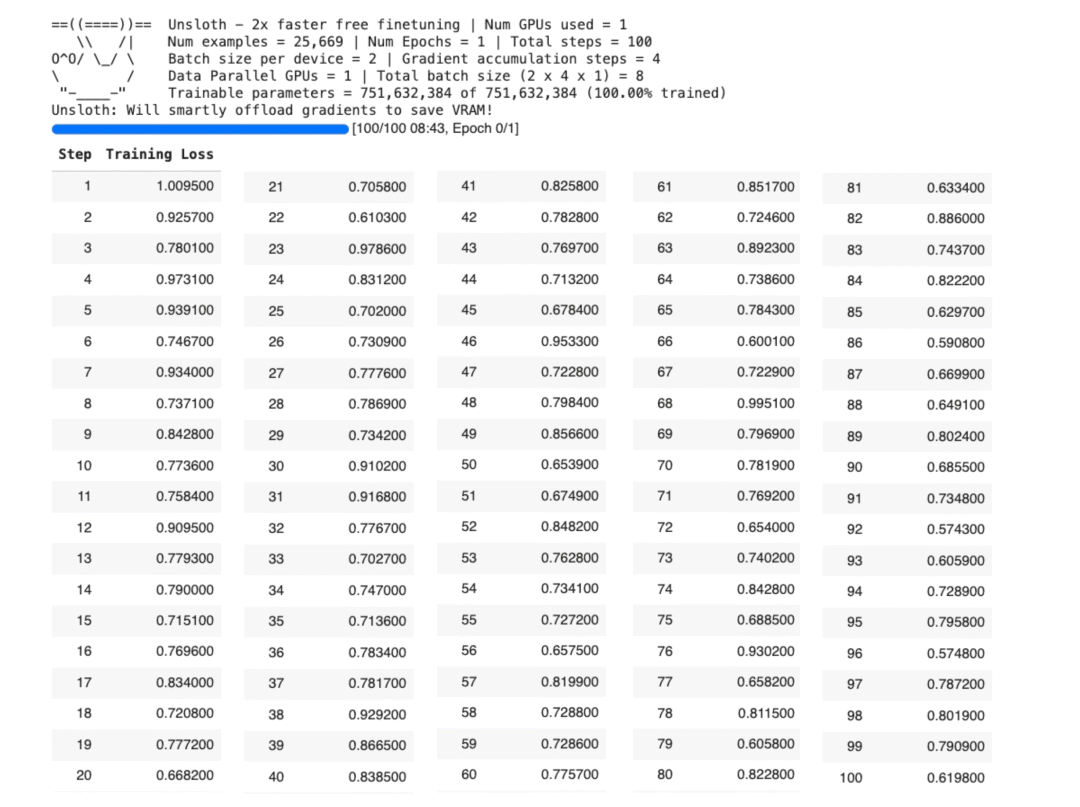
7️⃣ 保存模型
训练完成后,我们以 TorchAO 格式保存模型。这正是 ExecuTorch 下一步所需要的格式。
8️⃣ 导出为 .pte
现在我们导出一个 iOS 可以加载的 .pte 文件。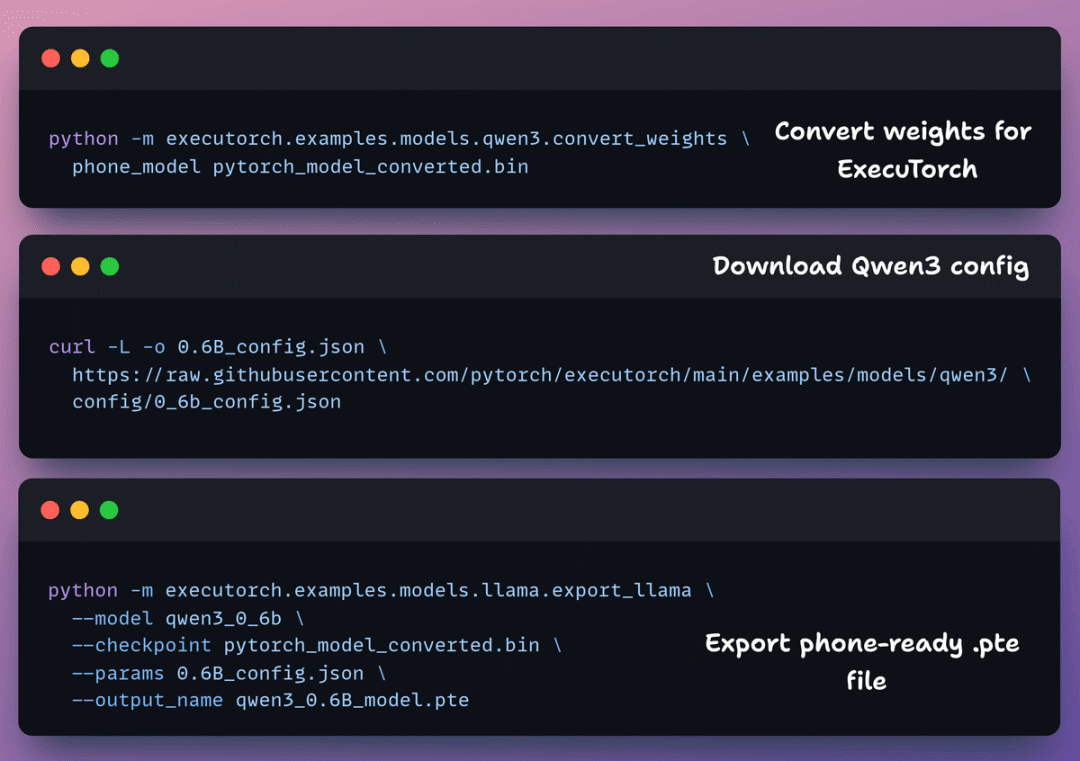
这里我们做三件事:
- 转换权重
- 获取模型配置
- 导出最终产物
注意:.pte 文件约 470 MB,这对端侧模型来说是正常的。
9️⃣ 在 iOS 上运行
最后,我们用 ExecuTorch iOS 示例应用运行模型。在模拟器上,我们复制 .pte 和 Tokenizer(分词器),在应用中加载它们,然后开始对话。模拟器不需要开发者账号。物理 iPhone 需要在 Xcode 中增加内存限制。
[11]
在上面的视频中,我们在 iPhone 17 Pro 上本地运行 Qwen3,速度约 25 tokens/s,由与 Meta 生产应用(Instagram、WhatsApp 和 Messenger)相同的 ExecuTorch 运行时驱动。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)