Agent Memory全解析:让AI拥有“过目不忘“的超能力
开篇:为什么你的AI总是"健忘"?
想象这样一个场景:
你正在使用一个AI助手规划旅行。第一次对话中,你告诉它:“我对海鲜过敏,喜欢历史文化,预算在1万元左右。”
三天后,你再次打开对话:“帮我规划一下去日本的行程。”
结果AI问你:“请问你有什么饮食禁忌吗?预算大概多少?”
你是不是瞬间崩溃?
这就是当前大多数AI应用的致命缺陷——缺乏记忆能力。
但2026年,一切正在改变。
Agent Memory(智能体记忆)技术正在成为AI应用的核心竞争力。从OpenAI的Memory功能,到Anthropic的Claude Code,再到估值20-30亿美元被Meta收购的Manus,顶级玩家都在押注同一个技术方向。
本文将深度拆解:
- • Agent Memory的三层架构设计
- • 向量数据库 vs 知识图谱的终极对决
- • Mem0、Letta、A-MEM等主流框架实战对比
- • 从0到1构建生产级记忆系统的完整指南
准备好了吗?让我们一起揭开AI记忆的奥秘!
一、Agent为何需要"记忆"?
1.1 从" Stateless "到"Stateful"的进化
传统的大语言模型(LLM)是无状态的——每次请求都是独立的,模型不会记住之前的交互。
这就像每次见面的陌生人,无论你们之前聊过什么,它都会问:“我认识吗?”
而具备记忆能力的Agent,则是有状态的系统。它能够:
- • 记住过去的交互经验
- • 学习用户的偏好和习惯
- • 跨会话保持上下文连贯性
- • 从错误中持续改进
1.2 记忆带来的商业价值
根据2025年的实践数据,记忆系统为AI应用带来的提升:
用户满意度:提升40-60%
任务完成率:提升35-50%
重复使用率:提升3-5倍
Token消耗:降低30-50%(通过精准检索而非全量上下文)
💡 典型案例:某头部电商客服机器人,引入长期记忆后,客户问题解决率从68%提升到89%,平均对话轮次从8.3轮降低到4.1轮。
二、记忆的本质:从人脑到AI的映射
2.1 人类记忆的启示
认知科学将人类记忆分为多个层次,AI记忆系统的设计正是借鉴了这一框架:
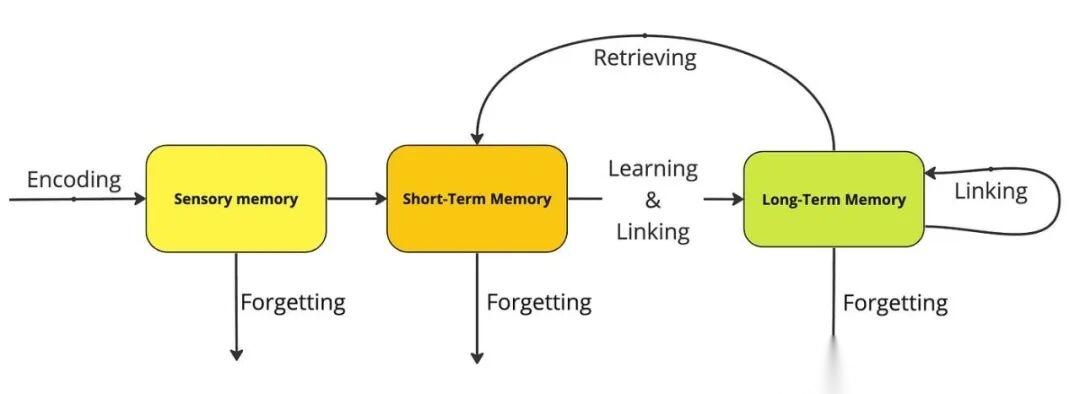
感官记忆 → 短期记忆 → 长期记忆
- • 感官记忆:瞬时缓存,保留几毫秒到几秒
- • 短期记忆:工作记忆,容量有限(7±2个组块)
- • 长期记忆:持久存储,理论上无限容量
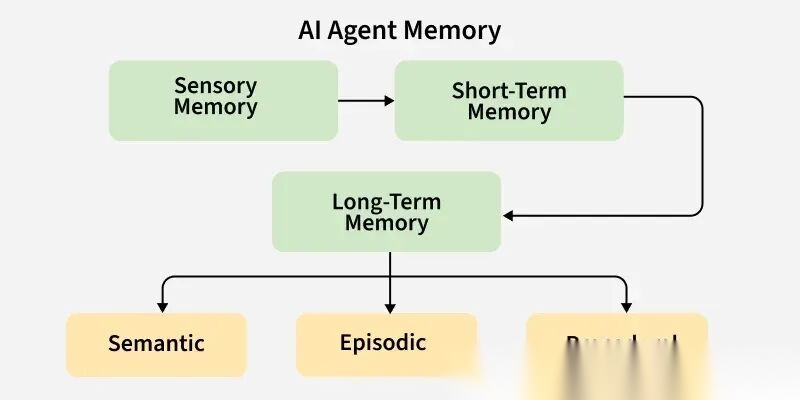
2.2 AI Agent的记忆分类
2026年,Agent Memory已经形成清晰的分类体系:
(1)按时间维度
短期记忆(Short-Term Memory, STM)
- • 存储:最近几轮对话
- • 容量:受限于上下文窗口(通常4K-128K tokens)
- • 更新:滑动窗口机制,频繁更新
- • 场景:单次会话的上下文连贯
长期记忆(Long-Term Memory, LTM)
- • 存储:跨会话的关键信息
- • 容量:理论上无限(外部存储)
- • 更新:选择性巩固,低频率
- • 场景:用户偏好、历史经验、领域知识
(2)按内容类型
情景记忆(Episodic Memory)
- • 记录:具体的事件和交互
- • 示例:“用户昨天询问了iPhone 15的价格”
- • 特点:时间戳、上下文关联
语义记忆(Semantic Memory)
- • 存储:事实和概念
- • 示例:“用户喜欢苹果品牌”、“预算5000-8000元”
- • 特点:抽象化、去时间化
程序记忆(Procedural Memory)
- • 存储:技能和规则
- • 示例:“如何调用支付API”、“价格比较的流程”
- • 特点:自动化执行,无需显式推理
三、核心架构:三层记忆系统设计
3.1 生产级记忆架构蓝图
2026年的最佳实践采用三层记忆架构:
┌─────────────────────────────────────────┐│ 短期记忆(STM) ││ • 滑动窗口管理 ││ • 最近N轮对话 ││ • 直接参与推理 │└─────────────────────────────────────────┘ ↓ 巩固┌─────────────────────────────────────────┐│ 中期记忆(MTM) ││ • 摘要压缩 ││ • 热度评分 ││ • 选择性保留 │└─────────────────────────────────────────┘ ↓ 索引┌─────────────────────────────────────────┐│ 长期记忆(LTM) ││ • 向量数据库(语义检索) ││ • 知识图谱(关系推理) ││ • 结构化存储(事实记录) │└─────────────────────────────────────────┘
3.2 记忆的生命周期管理
完整的记忆系统包含6大核心操作:
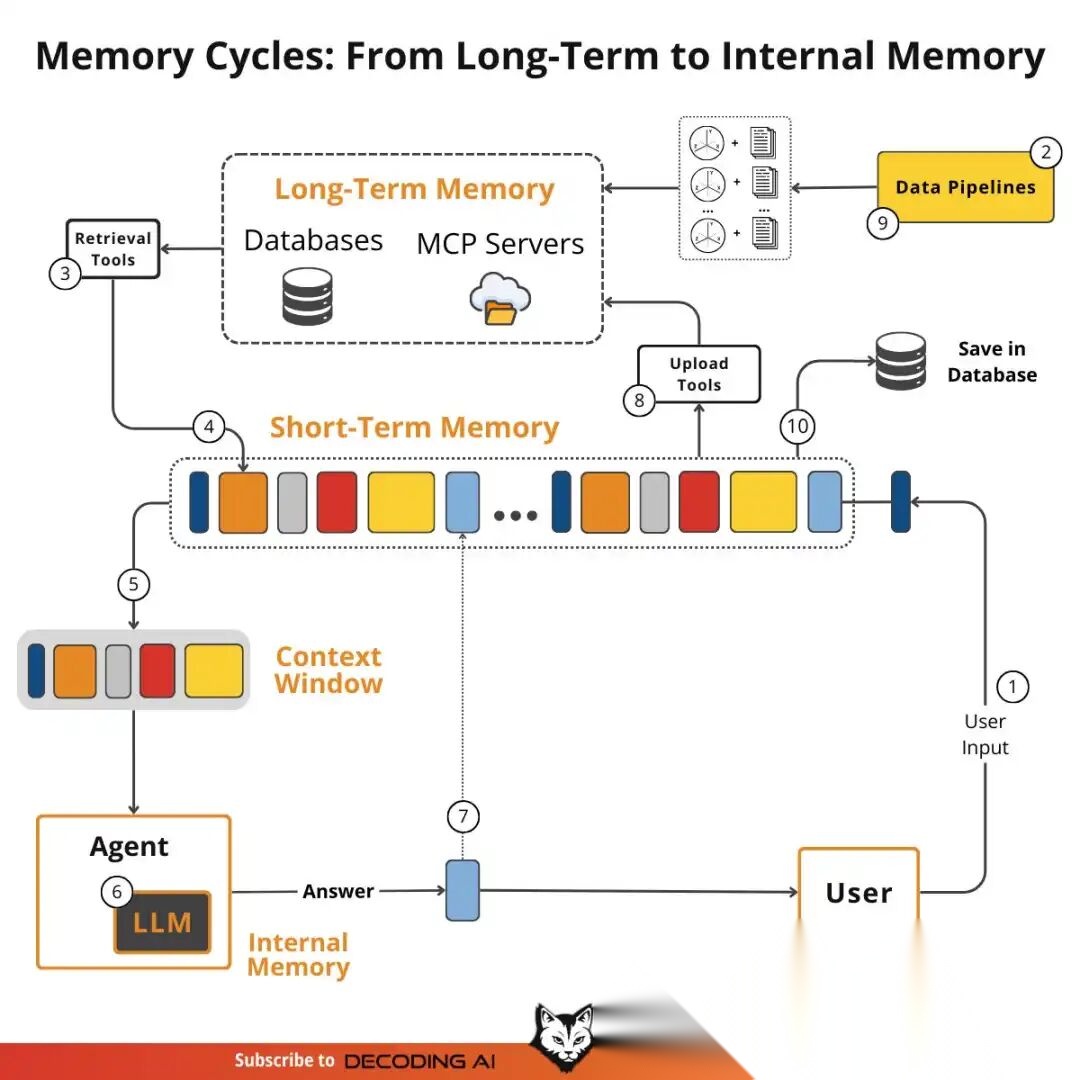
1. 编码(Encoding)
- • 从原始对话中提取关键信息
- • 生成向量嵌入(Embedding)
- • 添加元数据(时间戳、重要性、来源)
2. 巩固(Consolidation)
- • 短期记忆 → 长期记忆的转化
- • 通过LLM进行摘要和压缩
- • 去除冗余,保留精华
3. 索引(Indexing)
- • 构建向量索引(ANN)
- • 建立知识图谱关系
- • 元数据标注
4. 检索(Retrieval)
- • 语义相似度搜索
- • 关键词匹配
- • 图遍历查询
5. 链接(Linking)
- • 建立记忆间的关联
- • 发现隐含的模式
- • 形成知识网络
6. 遗忘(Forgetting)
- • 基于时间衰减
- • 基于使用频率
- • 基于重要性评分
💡 关键技术:A-MEM框架提出了动态记忆演化机制,记忆不是静态存储,而是像生物神经网络一样,能够自组织、自生长、自优化。
四、技术实现:主流方案深度对比
4.1 向量数据库方案
技术原理:
将文本转化为高维向量(通常768-1024维),通过近似最近邻(ANN)算法实现毫秒级语义检索。
代表产品:
- • 开源:Milvus、Faiss、Chroma、Qdrant
- • 商业:Pinecone、Weaviate、阿里云DashVector
- • 数据库扩展:PostgreSQL(pgvector)、MongoDB、Elasticsearch
优势:
✅ 语义理解能力强
✅ 检索速度快(毫秒级)
✅ 实现相对简单
✅ 生态成熟
局限:
❌ 难以处理时序关系
❌ 事实冲突检测困难
❌ 无法进行复杂推理
❌ 存储成本随规模线性增长
适用场景:
- • 通用对话记忆
- • 语义搜索
- • 个性化推荐
4.2 知识图谱方案
技术原理:
使用图结构存储实体(节点)和关系(边),支持复杂的关系推理和路径查询。
用户 ——[喜欢]→ 苹果品牌用户 ——[过敏]→ 海鲜产品 ——[品牌]→ 苹果产品 ——[价格]→ 6999元
代表产品:
- • 图数据库:Neo4j、Nebula Graph、Amazon Neptune
- • 混合方案:PolarDB(向量+图双模)
优势:
✅ 关系推理能力强
✅ 事实一致性保障
✅ 可解释性好
✅ 支持复杂查询
局限:
❌ 构建成本高
❌ 语义相似度搜索弱
❌ 查询性能受图规模影响
❌ 需要专业知识建模
适用场景:
- • 领域知识库
- • 复杂决策支持
- • 需要强一致性的场景
4.3 混合架构方案
2026年的最佳实践:向量数据库 + 知识图谱 + 结构化存储。
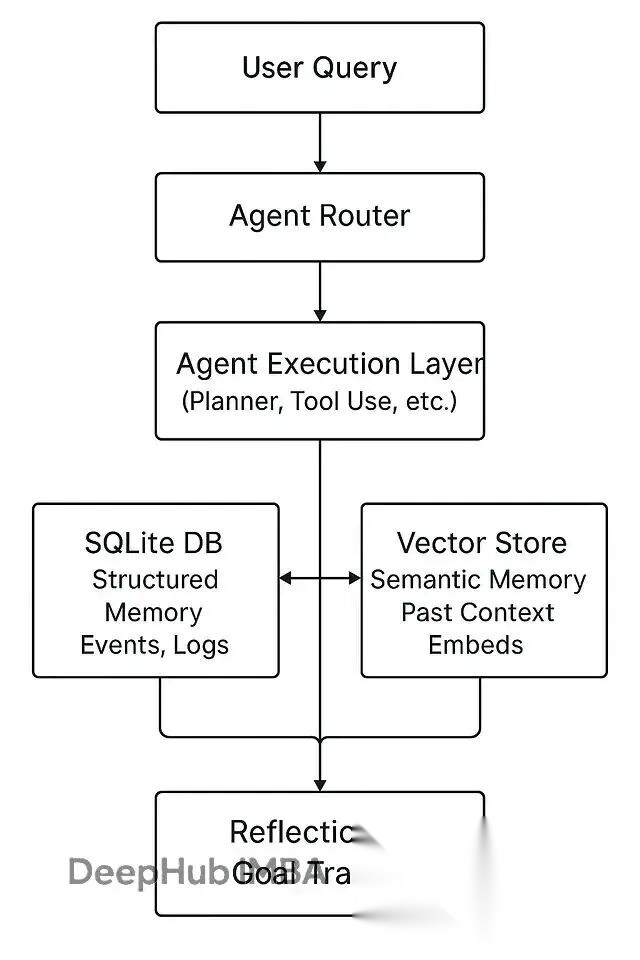
架构设计:
# 伪代码示例class HybridMemory: def __init__(self): self.vector_store = VectorDB() # 语义检索 self.graph_db = GraphDB() # 关系推理 self.sql_db = SQLiteDatabase() # 结构化数据 def store(self, memory): # 向量化存储 embedding = embed(memory.content) self.vector_store.insert(embedding, memory) # 图谱关系提取 entities = extract_entities(memory) self.graph_db.add_triplets(entities) # 结构化记录 self.sql_db.insert({ 'timestamp': memory.time, 'user_id': memory.user, 'type': memory.type }) def retrieve(self, query): # 多路召回 vector_results = self.vector_store.search(query) graph_results = self.graph_db.query(query) # 融合排序 return rerank(vector_results, graph_results)
阿里云PolarDB实践:
Polar Agent Memory采用双模存储架构,通过向量数据库与知识图谱的协同,实现:
- • 语义检索准确率:92%
- • 关系查询响应:< 50ms
- • 存储成本降低:40%
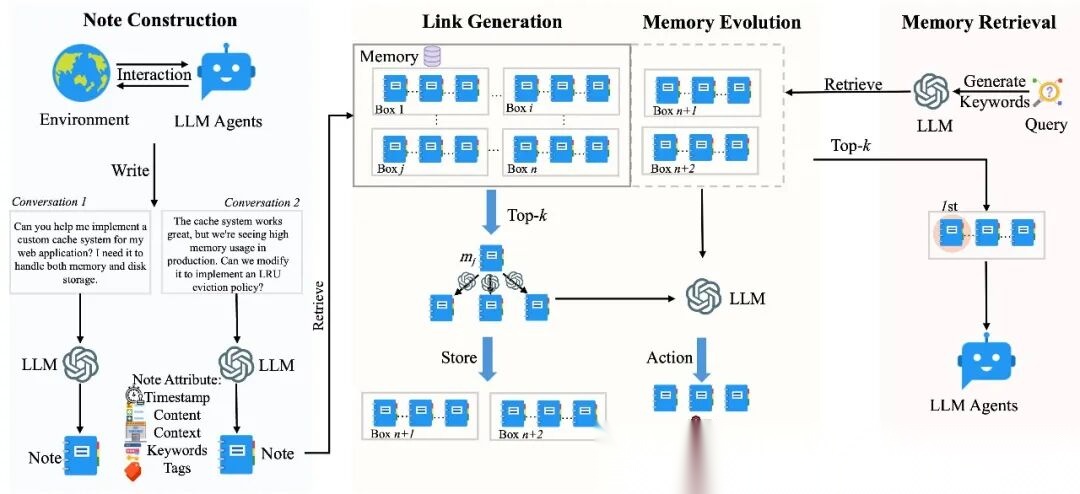
4.4 前沿方案:A-MEM
创新点:
受Zettelkasten(卡片盒笔记法)启发,A-MEM提出动态自组织记忆。
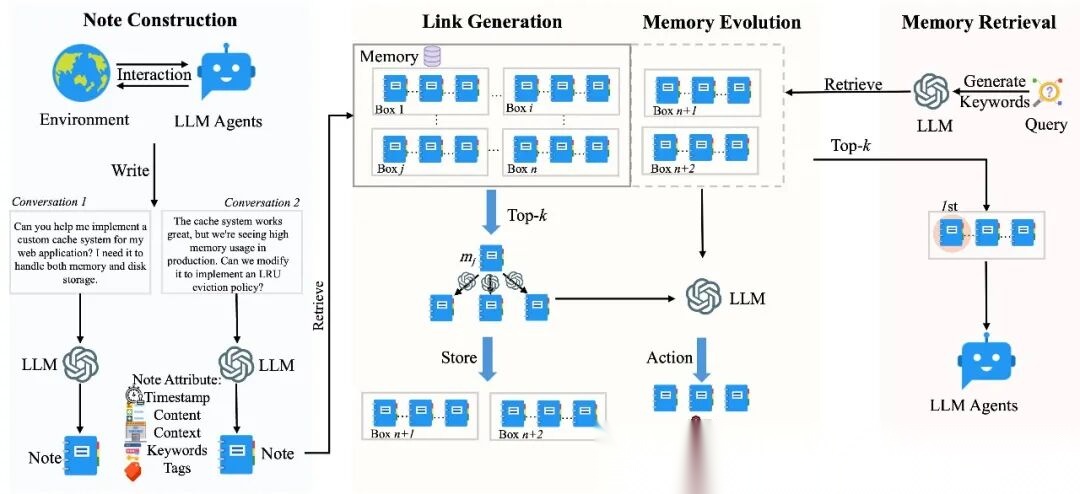
核心机制:
1. 笔记构建(Note Construction)
- • 每次交互生成结构化笔记
- • 包含:时间戳、内容、上下文、关键词、标签
2. 链接生成(Link Generation)
- • 自动发现记忆间的关联
- • 建立因果关系、主题关系、时序关系
3. 记忆演化(Memory Evolution)
- • 基于使用频率调整重要性
- • 动态合并相似记忆
- • 自动淘汰低价值记忆
4. 智能检索(Memory Retrieval)
- • LLM生成检索关键词
- • 多跳推理(Multi-hop Reasoning)
- • Top-k相关记忆召回
性能表现:
在复杂推理任务上,A-MEM相比传统向量检索:
- • 事实准确性:+23%
- • 多跳推理:+31%
- • 上下文一致性:+28%
五、框架选型:5大主流框架实战对比
5.1 Mem0 —— 生态之王
GitHub Stars:10K+
技术特点:
- • 支持向量+图谱双模式
- • 与LangChain、LlamaIndex深度集成
- • 提供API和SDK多种接入方式
优势:
✅ 生态完善,文档丰富
✅ 易于上手,开箱即用
✅ 支持多用户、多租户
✅ 生产案例多(通义千问App、阿里1688)
局限:
❌ 依赖外部服务
❌ 定制化能力有限
代码示例:
from mem0 import Memorymemory = Memory()# 存储记忆memory.add("用户喜欢Python编程", user_id="user123")# 检索记忆relevant = memory.search("用户的技术偏好", user_id="user123")
5.2 Letta(原MemGPT)—— 操作系统思维
核心理念:
将LLM视为操作系统,记忆视为虚拟内存。
创新机制:
- • 分层存储:核心内存(Context)+ 外部内存(Database)
- • 页面置换:基于LLM自主决定哪些记忆调入/调出
- • 函数调用:LLM通过工具调用管理记忆
优势:
✅ 理论创新强
✅ 记忆管理自主化
✅ 适合长周期任务
局限:
❌ 学习曲线陡峭
❌ 延迟较高(频繁LLM调用)
5.3 LangMem —— LangChain原生方案
定位:
LangChain生态的记忆增强模块。
特点:
- • 与LangGraph深度集成
- • 支持短期+长期记忆
- • 基于PostgreSQL实现
优势:
✅ LangChain用户无缝迁移
✅ 性能稳定
✅ 支持事务
局限:
❌ 绑定LangChain生态
5.4 Graphiti —— 图谱优先
技术路线:
专注知识图谱记忆。
适用场景:
- • 需要强关系推理
- • 领域知识复杂
- • 事实一致性要求高
5.5 自研方案 —— Tablestore实践
阿里云Tablestore:
提供Serverless的Agent Memory SDK。
优势:
✅ 弹性伸缩
✅ 多AZ容灾
✅ 成本可控(按量付费)
案例:
- • 通义千问App
- • 某头部浏览器AI搜索Memory
- • 阿里巴巴1688商品AI搜索
5.6 框架对比总表
| 框架 | 技术路线 | 易用性 | 性能 | 生态 | 适用场景 |
|---|---|---|---|---|---|
| Mem0 | 向量+图谱 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 通用场景 |
| Letta | 虚拟内存 | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | 复杂任务 |
| LangMem | 向量 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | LangChain用户 |
| Graphiti | 图谱 | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | 知识密集型 |
| Tablestore | 混合 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 企业级应用 |
💡 选型建议:
- • 快速验证:Mem0
- • 生产部署:Tablestore或自研混合架构
- • 复杂推理:Graphiti或A-MEM
- • LangChain生态:LangMem
六、生产实践:从0到1构建记忆系统
6.1 架构设计原则
原则1:分层存储
- • 热数据:Redis缓存(< 10ms)
- • 温数据:向量数据库(< 100ms)
- • 冷数据:对象存储/数据库
原则2:异步处理
- • 记忆写入异步化,不阻塞主流程
- • 批量处理,减少IO次数
原则3:缓存策略
- • Embedding缓存(TTL=3600s)
- • 检索结果缓存(基于Query Hash)
- • 记忆片段缓存(LRU策略)
6.2 性能优化技巧
技巧1:批量写入
# ❌ 错误:逐条写入for memory in memories: await db.insert(memory)# ✅ 正确:批量写入await db.batch_insert(memories, batch_size=100)
技巧2:延迟检索
- • 仅在必要时检索(用户Query变化)
- • 避免每次对话都检索全量记忆
技巧3:记忆压缩
# 使用LLM摘要压缩async def compress_memories(memories): prompt = f""" 将以下对话历史压缩为关键点(200字内): {memories} """ return await llm.generate(prompt)
技巧4:元数据过滤
# 先过滤元数据,再向量检索results = await vector_db.search( query_embedding, filter={ 'user_id': 'user123', 'timestamp': {'$gt': '2026-01-01'}, 'importance': {'$gte': 0.7} })
6.4 监控与评估
关键指标:
- • 检索准确率:Top-3相关记忆的人工评分
- • 响应延迟:P95 < 500ms
- • 记忆命中率:检索到相关记忆的比例
- • Token节省率:相比全量上下文的节省比例
评估框架:
class MemoryEvaluator: def evaluate(self, system): metrics = { 'precision': self.measure_precision(), 'recall': self.measure_recall(), 'latency_p95': self.measure_latency(), 'user_satisfaction': self.survey_users() } return metrics
七、未来趋势:Agent Memory的下一个风口
7.1 技术演进方向
方向1:多模态记忆
- • 不仅记住文本,还能记住图片、音频、视频
- • 跨模态关联检索
方向2:情感记忆
- • 记住用户的情感状态
- • 情感倾向分析
- • 个性化情感响应
方向3:预测性记忆
- • 基于历史预测用户需求
- • 主动推送相关信息
- • anticipatory computing(预见性计算)
7.2 2026年热门研究方向
根据NeurIPS、ICML 2025的论文数据:
1. 记忆的自我进化
- • Agent自主决定记住什么、遗忘什么
- • 基于强化学习的记忆优化
2. 多Agent共享记忆
- • 团队协作的记忆共享机制
- • 记忆权限管理
- • 知识传递与继承
3. 隐私保护记忆
- • 差分隐私
- • 联邦学习
- • 可遗忘权(Right to be Forgotten)
7.3 商业机会
万亿级市场:
- • 企业级AI助手(客服、销售、HR)
- • 个人AI秘书(日程管理、知识管理)
- • 教育AI导师(个性化学习路径)
- • 医疗AI助手(病历管理、诊疗建议)
💡 投资风向:2025年,记忆相关的AI初创公司融资额超过50亿美元,其中Manus(记忆增强型Agent)以20-30亿美元估值被Meta收购。
结语:记忆,AI智能体的灵魂
没有记忆的AI,就像没有过去的工具——强大但空洞。
而具备记忆能力的Agent,则是有历史、有经验、有个性的智能伙伴。
2026年,Agent Memory已经从"锦上添花"变成"必备能力"。
无论你是:
- • 创业者:寻找下一个独角兽机会
- • 工程师:构建生产级AI应用
- • 研究者:探索AI认知边界
Agent Memory都是你无法忽视的核心技术。
现在,是时候给你的AI装上"记忆芯片"了!
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献194条内容
已为社区贡献194条内容

所有评论(0)