Meta分析异质性太高怎么办?手把手教你找异质性来源,四大核心策略和实操指南就看这篇!
Meta分析中,各个独立研究在受试者基线特征、干预方案细节以及研究设计上客观存在差异,这就会产生异质性。排查并准确解释异质性的来源,不仅是决定统计模型选择、评估合并结果稳健性的核心步骤,更是我们在顶刊发表研究的硬性条件。今天,我们【医嘉研】团队为大家详细梳理一套符合科研规范的异质性排查流程。
一、明确meta分析异质性的三大基本类型
在进行操作之前,要从医学专业角度界定文献之间的差异到底来源于哪里。通常来说,异质性主要来源于以下三个方面:
1.临床异质性
基于PICO原则的客观差异:包括受试人群的年龄分布、性别比例、疾病严重程度或并发症;干预措施的具体给药途径、精确剂量、疗程长短;对照组是安慰剂还是阳性药物;以及结局指标的具体测量量表和随访截止时间。
2.方法学异质性
主要指研究设计和实施过程中的质量差异:例如,有没有采用严格的随机化分配隐藏、有没有对受试者和测量者实施盲法、缺失数据的插补处理方式,以及研究设计本身是随机对照试验还是队列研究。
3.统计学异质性
这是上述临床和方法学差异在数据分析上的最终表现,指的是各个独立研究的效应量偏离总体合并效应量的程度,且这种偏离超出了单纯由抽样随机误差所能解释的范围。
二、meta分析异质性的确认与量化(前沿规范深度解读)
接下来咱们进入实际操作的第一步:如何判断这组数据是否存在异质性,以及如何科学量化它的严重程度。在这里,我们引入《Cochrane干预措施系统评价手册》第6版的最新规范。
1.图形观察(森林图)
重点观察各研究的点估计值分布是否广泛,以及各个独立研究的95%置信区间是否有重叠。重叠部分越少,统计学异质性越大。
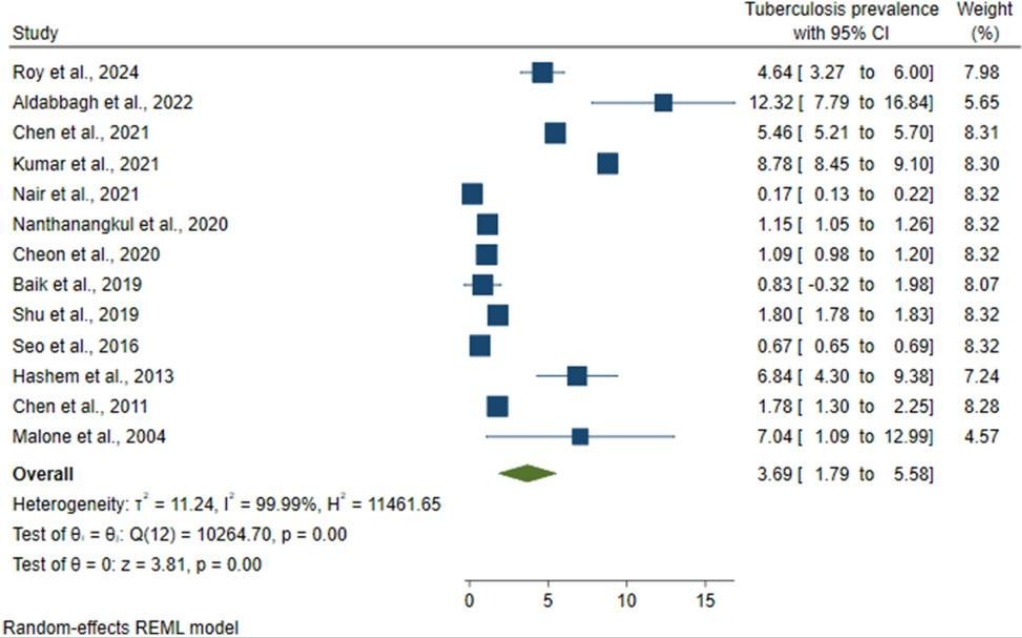 提示高度异质性的森林图
提示高度异质性的森林图
2.核心统计量(Cochrane Q检验与I²)
Cochrane Q检验的统计效能比较低,我们通常将显著性阈值放宽,当P<0.10时,就认为存在统计学意义上的显著异质性。
I²统计量用于量化异质性在总变异中所占的百分比。过去常以25%、50%、75%作为低、中、高的划分界值。但是,最新的方法学强调,绝对不能机械固定这些界值。因此,对I²值的解释应结合研究背景、临床意义以及P值的具体数值进行综合判断。
I²的数值受纳入研究数量和样本量的直接影响。如果纳入的研究少于5篇,I²的计算极不稳定;如果在总样本量极大的Meta分析中,即使是临床上微不足道的差异,也会导致I²呈现接近100%的极高数值。因此,解释I²一定要结合临床实际情况。
3.绝对方差与预测区间(τ²与95%PI)
τ²用于衡量研究间真实效应量的绝对方差,它能更真实地反映跨研究的绝对变异程度,不受样本量增大的干扰。
目前高质量的Meta分析强烈建议在存在异质性时报告95%预测区间(PI)。置信区间评估的是“平均效应量”的确定性,而95%预测区间结合了τ²,反映的是如果未来在类似临床背景下开展一项全新的独立研究,其真实效应量可能落入的绝对数值区间。
如果合并效应量的95%置信区间提示有效,但95%预测区间跨越了无效线,这就意味着在未来的某些特定临床场景中,这种干预措施可能完全无效。
三、统计模型的先验选择原则
在排查异质性来源之前,一定要纠正一个常见的操作误区:过去很多人先看I²的结果,如果I²>50%,就换成随机效应模型,反之则用固定效应模型。
当前方法学推荐,在医学Meta分析中,由于不同研究间的受试者与实施条件存在差异,都应优先使用随机效应模型;
固定效应模型适用于有充分理由相信所有研究估计的是同一个真实效应量的情况。不建议仅根据I²值是否超过某个阈值(如50%)来机械地切换模型。
四、meta分析异质性的核心排查策略与详细操作指南
当我们确认存在显著的异质性后,就开始启动排查流程,找到导致差异的具体变量。咱们主要有以下几种专业手段:
1.敏感性分析
这种方法用于定位对总体异质性影响极大的单个异常数据点。操作上采用逐一剔除法,每次从分析模型中移除一项研究,重新计算剩余研究的合并效应量和I²值。
如果剔除某一项特定的研究后,I²值发生显著的大幅度降低,说明这项研究是导致整体异质性的主要来源。这时候,要重新审查这篇文献的全文,详细比对它的受试者特征、干预细节或随访时间是否与其他文献存在明显不同。
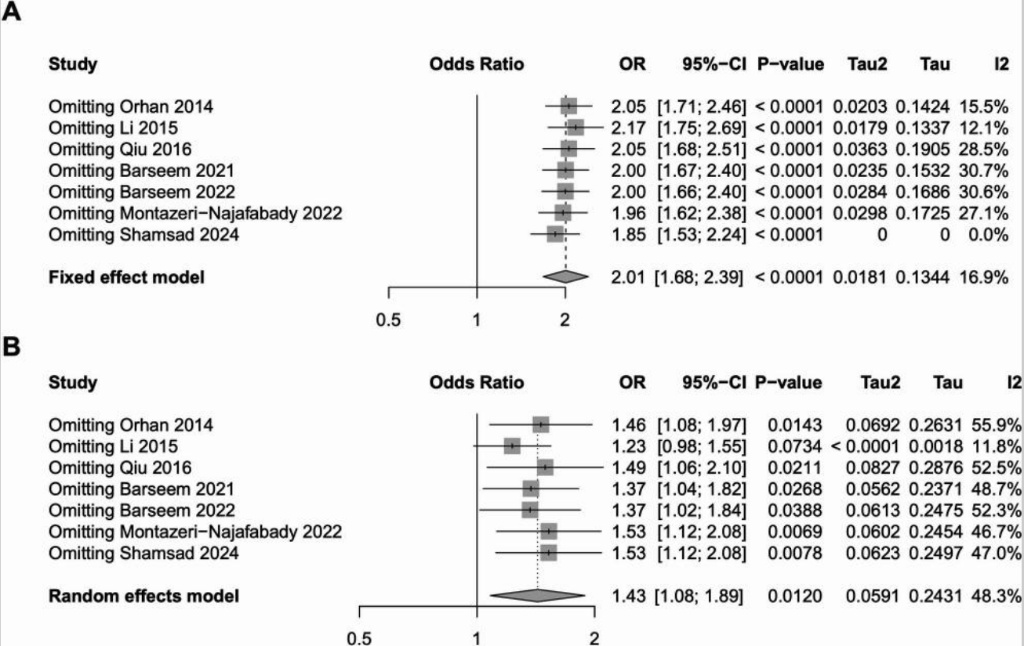
逐一剔除法敏感性分析森林图定位异质性来源
2.亚组分析
当我们假设某种分类变量是异质性的来源时,可以用亚组分析:
操作上根据事先确定的临床或方法学特征,将文献分为不同的子集(例如:根据干预剂量分为高剂量组与低剂量组)。
结果解读时,首先观察各亚组内部的I²是否比整体有所下降。
其次,极其关键的是查看亚组间交互作用检验的P值:如果交互作用检验的P<0.05,说明不同亚组之间的合并效应量存在显著的统计学差异,从而证实这个分类变量确实是异质性的重要来源。
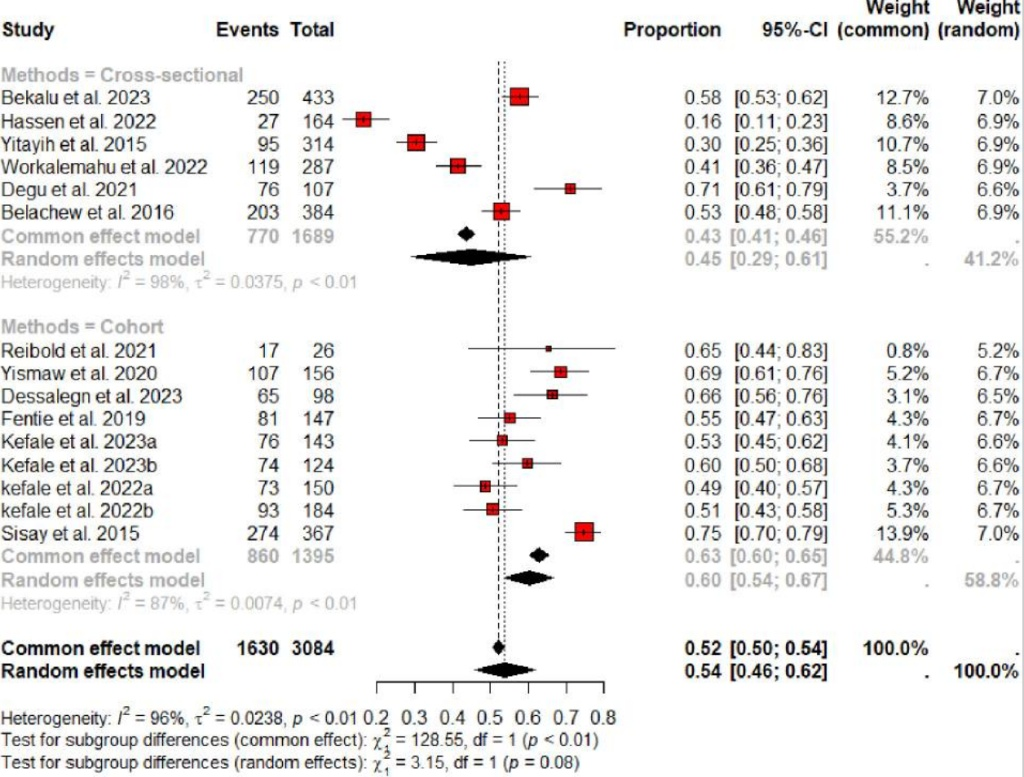
亚组分析森林图评估方法学异质性
3.Meta回归分析
当我们要排查连续变量时,亚组分析无法适用,这时候要使用Meta回归:
进行Meta回归分析时,需要有足够数量的研究来保证统计效能。一个常用的经验法则是,每个待考察的协变量至少对应10个独立研究的数据,但实际应用中需结合具体情况判断。当研究数量有限时,对回归结果的解释应该格外谨慎。
4.图形化辅助工具(Galbraith图)
除了常规的森林图,我们可以使用Galbraith图来辅助定位:
这张图清晰地展示了各个研究偏离总体回归线的距离,有助于识别那些可能对整体异质性贡献较大的研究,需要结合研究背景进行进一步审查。
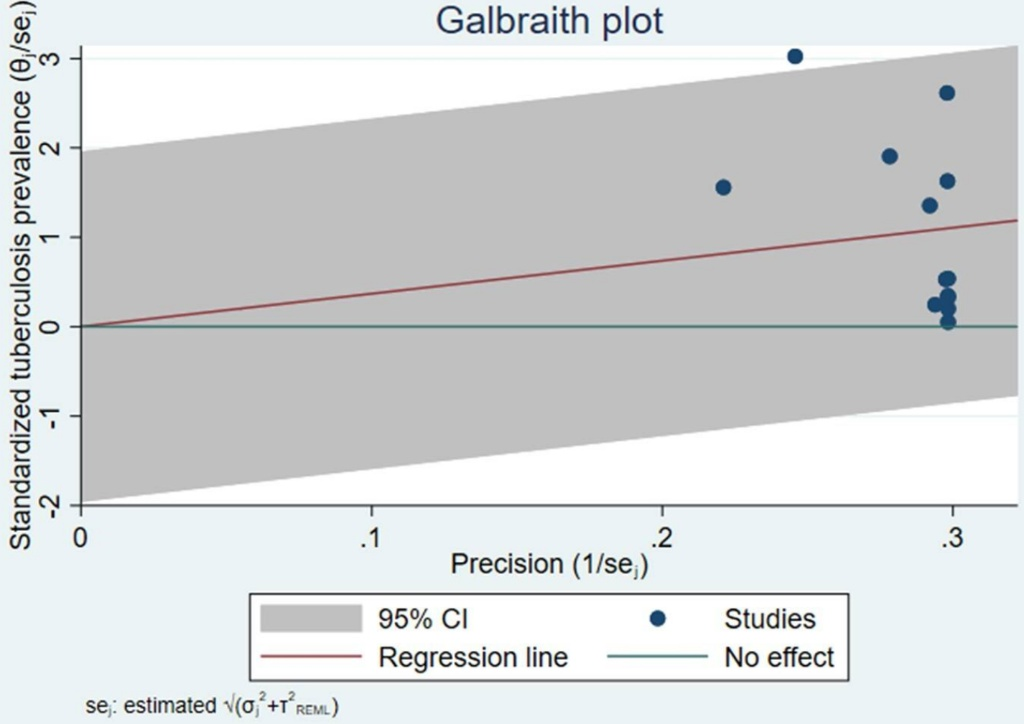 Galbraith图辅助定位异质性异常值
Galbraith图辅助定位异质性异常值
五、排查后的专业处理措施
在得出排查结果后,我们要采取相应的处理措施。如果通过上述步骤找到了异质性的来源,一定要在讨论部分从临床或方法学角度给出严谨的学术解释。
如果经过反复比对发现,纳入的研究在临床特征或方法学上存在根本性的差异,且统计学异质性极高,强行进行数学合并是违反统计学原则的。这时候,要果断放弃定量分析,转而撰写描述性的系统评价,客观陈述各研究的独立结果及其差异原因。
总结来说,在医学Meta分析中遇到异质性是常态。我们不要刻意回避异质性,而是要通过敏感性分析定位异常数据,利用亚组分析和Meta回归去验证临床与方法学假设。
严格遵循事先决定的模型选择原则,并补充报告预测区间,能够极大地提升系统评价的学术深度和透明度。希望这篇详尽的实战梳理能为您手头的科研数据分析提供标准化的参考!如果您没有临床数据、或者没有实验条件,那meta分析绝对是您的最佳选择!如果您在meta分析选题、统计分析等方面有困难,不妨来【医嘉研】学习!
【医嘉研】有专业的meta分析团队,提供选题到文章发表的一站式教学服务!并且为每一位学员建立专属服务群,配备专属伴学老师,提供多对一优质服务!同时采取灵活约课制度,不管您是平时有时间,还是晚上、周末有时间,都能匹配适合自己时间的授课老师!
【医嘉研】多年来不仅坚持授人以鱼,也坚持授人以渔,让您学完后不仅能得到一篇可发表的SCI文章,还能学会整个SCI的发表流程,在往后在临床工作中,也能举一反三,产出更多符合您自身实际情况同时也贴合临床实际的科研成果!
【医嘉研】专注医学SCI全流程指导,为您合理规划时间,靠谱且高效!
公司简介:
医嘉研是河北橙方信息技术有限公司旗下专注医学科研服务的品牌,公司坐落于河北石家庄CBD恒大中心,自 2019 年成立以来,始终专注于医学科研解决方案的研发与落地,围绕科研思维培养--科研技能实训--科研成果转化三大核心维度,为临床医生、医院科室及医学院校提供系统化、可落地的科研支持。公司已与多家医院及高校医学院建立战略合作关系,成为稳定可靠的院外教学实践基地,能够精准匹配临床一线的真实需求,让科研不再成为额外负担,而是与临床工作相互促进、协同提升。
业务简介:
针对临床医生、医学生,根据个人实际临床经验及科研条件,提供一对一个性化培训,提升科研思维、讲解科研技能,并指导其完成科研成果的转化(如产出高水平SCI、发明专利等);
针对医院具体科室,根据科室特点,结合前沿文献及AI技术,对科室进行科研相关指标量化指导,强化科室优势,并结合海量临床数据库及生信多组学分析方法等,为科室量身定制科研方案,并实现相应的科研成果转化;
针对医院,根据国家及地方卫健委、科技厅等部门的科研政策,结合医院学科优势与临床特点,协助医院整合院内跨科室资源,为医院申报科研项目类型(如重点研发计划、自然基金等)提供针对性指导,并协助完成目标课题申报。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)