【LangGraph】实战:支持搜索的智能代理系统(Agent + Tool)
【LangGraph】本文主要整理: LangGraph真正上手,以及做一些简单的案例
上一篇 【LangGraph】基于 LangGraph 的智能快递配送系统(实战案例)
一、为什么要做这个?
在前面的学习中,我们已经知道:
大模型本身不具备实时信息能力。例如,问“明天烟台天气怎么样?”,模型其实并不知道。
因此需要一种机制,让模型在必要时调用外部工具(如搜索)。
这就是 Agent 的核心能力:让模型学会“什么时候自己回答,什么时候去查资料”。
二、整体思路(核心结构)
本系统本质上是一个循环:
用户问题输入大模型
模型判断是否需要调用工具
若需要,则调用搜索工具
若不需要,直接回答
搜索返回结果后,再次交给大模型总结
用 LangGraph 表示如下: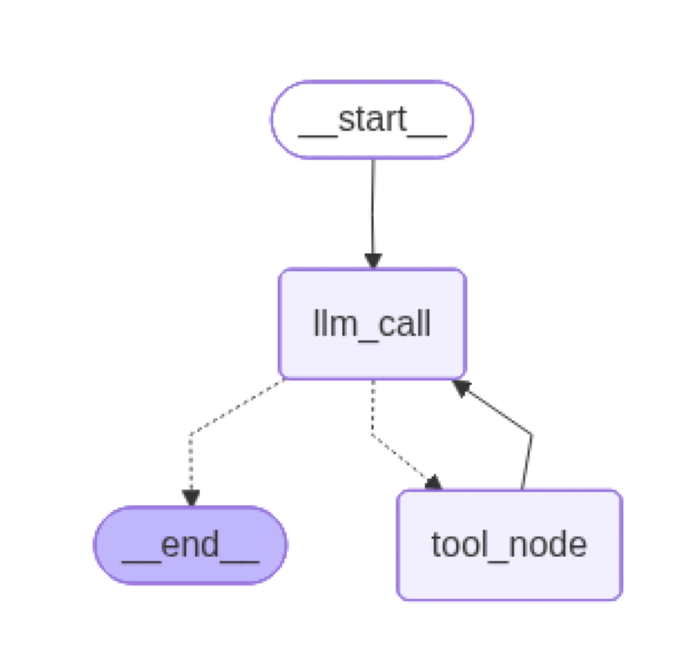
三、代码拆解
- 准备工具 + 模型
search = TavilySearch(max_results=4)
tools = [search]
定义一个搜索工具,最多返回 4 条结果
#这里以阿里的千问模型为例
model = init_chat_model(
model="qwen-plus",
model_provider="openai",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="xxx",
temperature=0
)
初始化大模型(阿里云兼容 OpenAI 接口)
model_with_tool = model.bind_tools(tools)
关键点:绑定工具,让模型具备“可以调用 search 工具”的能力
- 定义状态(State)
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
llm_calls: int
#messages:存储整个对话过程,包括用户消息(HumanMessage)、模型消息(AIMessage)和工具返回消息(ToolMessage)
#operator.add 表示自动追加
#llm_calls:记录调用大模型的次数
- 节点一:LLM 决策
def llm_call(state: MessagesState):
result = model_with_tool.invoke(
[SystemMessage(content="你是一位乐于助人的助手,支持文件调用和搜索")]
+ messages
)
return {
"messages": [result],
"llm_calls": state.get("llm_calls", 0) + 1
}
模型可能返回两种结果:
1.返回 AIMessage(tool_calls=[…]):
表示“我需要调用工具”
2.返回普通 AIMessage(content=“…”):
表示“我可以直接回答”
- 节点二:工具执行
def tool_node(state: MessagesState):
"""执行工具调用"""
result=[]
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
obs = tool.invoke(tool_call["args"])
result.append(
ToolMessage(content=obs, tool_call_id=tool_call["id"])
)
return {"messages": result}
拿到模型刚刚决定调用的工具,执行搜索
将结果包装成 ToolMessage,因为下一步大模型需要“读懂”工具返回的结果
- 条件判断(核心)
def should_call(state: MessagesState):
last_message = state["messages"][-1]
if last_message.tool_calls:
return "tool_node"
return END
如果模型返回的消息包含 tool_calls,则下一步进入 tool_node
否则,流程结束
- 构建图(LangGraph)
#构件图
agent_builder = StateGraph(MessagesState)
#添加节点:
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
#添加边:
python
agent_builder.add_edge(START, "llm_call")
#条件边:
agent_builder.add_conditional_edges(
"llm_call",
should_call,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "llm_call")
这样就实现了:查完资料后,再让模型总结
- 执行
messages = agent_search.invoke({
"messages": [
HumanMessage(content="明天烟台的天气怎样?")
]
})
- 输出结果
print(f"调用 LLM 总次数:{messages['llm_calls']}次")
for i in messages["messages"]:
i.pretty_print()
四、运行流程
以“天气问题”为例:
用户提问:明天烟台天气怎样?
LLM 判断:模型发现不知道实时天气,返回 tool_calls = [search]
调用搜索工具:TavilySearch 返回天气信息
再回到 LLM:模型根据搜索结果生成最终答案
流程结束
今天的分享先到这里,下期再见~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)