超越固定基因词汇表:HEIST如何用分层图模型统一解读空间多组学
论文信息
标题:HEIST: A Graph Foundation Model for Spatial Transcriptomics and Proteomics Data
超越固定基因词汇表:HEIST如何用分层图模型统一解读空间多组学
一句话速览 耶鲁大学团队提出了首个面向空间转录组学和蛋白质组学的分层图基础模型HEIST。它通过创新的跨层信息传递,将细胞的空间邻域信息与内部的基因共表达网络动态耦合,不仅实现了跨技术、跨器官的卓越预测性能,还能发现被传统模型忽略的、由微环境驱动的细胞亚群。
背景与痛点:当细胞有了“地址”,我们却还在用“电话簿” 想象一下,你拿到了一张超高分辨率的城市卫星地图。地图上不仅标注了每栋建筑(细胞),还显示了建筑内每个房间的实时活动(基因表达)。你的任务是理解这座“城市”如何运作:为什么金融区的建筑风格相似?为什么工业区附近的住宅表现出特定的压力特征?这些局部模式又如何影响整个城市的规划?
这就是空间多组学技术(如MERFISH、Xenium、CODEX)带来的生物学新图景。它让我们首次能在保留细胞原始位置的同时,测量其内部成千上万个基因或蛋白质的丰度。然而,现有的分析方法在处理这张复杂的“地图”时,却显得力不从心。
传统方法主要有两大局限:
-
“只见树木,不见森林”或反之:一些单细胞基础模型(如scGPT、scFoundation)擅长分析单个细胞的基因表达“电话簿”,却完全无视细胞的“地理地址”(空间信息)。反之,一些空间分析方法(如STAGATE、GraphST)能捕捉细胞邻居关系,却对细胞内部复杂的基因调控程序视而不见。这就像只分析每个家庭的购物清单,却不看他们住在哪个社区,或者只研究社区规划,却不关心每家每户的生活细节。
-
僵化的“基因词汇表”:大多数基础模型依赖于一个固定的基因列表进行预训练。当遇到新数据集(尤其是测量蛋白质的CODEX、MIBI技术)时,如果目标分子不在预训练的“词汇表”里,模型就束手无策,要么直接报错,要么需要费力地手动将蛋白质“映射”到近似的基因上,这无疑会丢失大量信息并引入偏差。
因此,领域急需一个能同时理解“细胞社区”规划与“家庭内部”活动,并且能灵活适应新“词汇”的通用模型。这正是HEIST要解决的难题。
核心方法:构建细胞的“社会网络”与“家庭关系图” 耶鲁大学Smita Krishnaswamy和Rex Ying团队提出的HEIST,其核心思想非常直观:用分层图来建模组织。
-
高层图:细胞的“社会网络”。这是一个空间图,节点是细胞,边连接空间上相邻的细胞。这张图刻画了组织的物理结构和细胞间的邻里关系。
-
底层图:细胞的“家庭关系图”。每个细胞内部,基因并非独立工作。HEIST为每种细胞类型构建一个基因共表达网络。节点是基因,如果两个基因的表达模式在该类细胞中高度协同(通过互信息计算),它们之间就有一条边。这捕捉了细胞内部的功能模块。
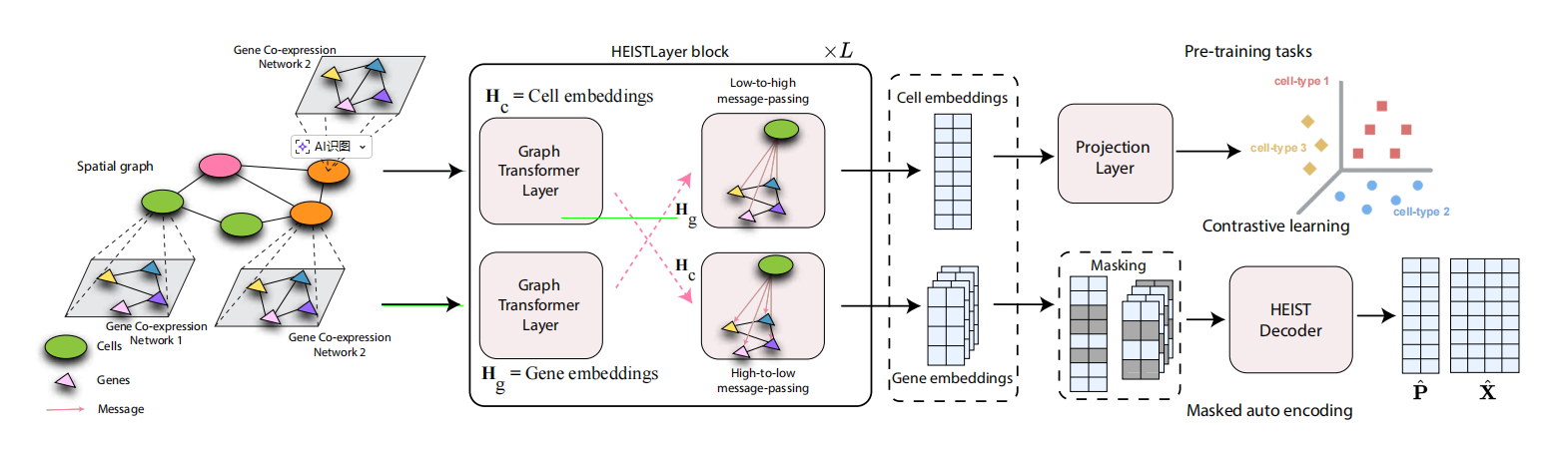
真正的创新在于连接这两层图的跨层信息传递机制。HEIST通过一种定向注意力机制,让两层信息双向流动:
-
自上而下(社会影响家庭):一个基因的嵌入表示,会受到其所在细胞的空间上下文信息影响。这意味着,同一个基因在肿瘤边缘的细胞和核心的细胞中,可能具有不同的表示,因为它所处的“社区压力”不同。
-
自下而上(家庭构成社会):一个细胞的嵌入表示,由其内部所有基因嵌入的聚合来更新。这样,细胞的“社会身份”由其内部的“家庭活动”所定义。
这种动态耦合是关键。它使得模型无需依赖固定的基因嵌入表。基因的表示是从其所在的共表达网络结构以及与空间环境的互动中动态学习而来的。因此,当遇到全新的蛋白质标记物时,HEIST可以基于其与其他分子的共表达关系以及空间位置,即时为其生成有意义的嵌入,实现了真正的“零样本”泛化能力。
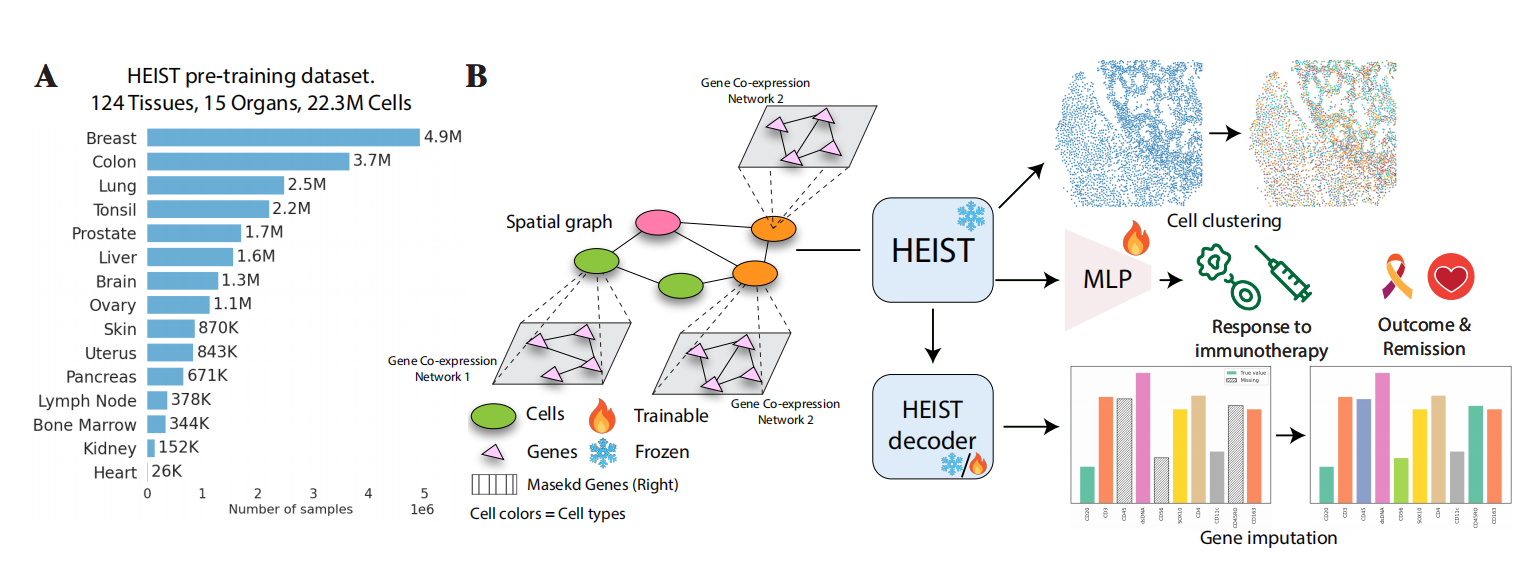
模型通过对比学习(让相似细胞/基因靠近,不相似的远离)和掩码自编码(随机掩盖部分基因或位置信息让模型重建)两种自监督任务进行预训练,使用了来自15个器官、124个组织切片、总计2230万个细胞的大规模空间转录组数据。
实验结果:全面领先,并照亮“隐秘的角落” 研究团队在四大下游任务上对HEIST进行了严格评估,结果均显示其显著优势。
-
临床结果预测(核心应用):预测患者对免疫疗法的反应、癌症复发风险等。如表2所示,在结肠癌(Charville)、头颈癌(UPMC, DFCI)和黑色素瘤数据上,HEIST的AUC-ROC全面领先。特别是在蛋白质组学数据(CODEX)上,由于HEIST能利用所有标记物,其性能远超依赖固定基因词汇表的模型(如scGPT-spatial在UPMC任务上提升25.4%)。
-
基因/蛋白表达填补:填补因技术噪音丢失的数据。如表1所示,经过微调后,HEIST在胎盘和皮肤数据集上的皮尔逊相关性分别达到0.821和0.807,超越所有基线方法。
-
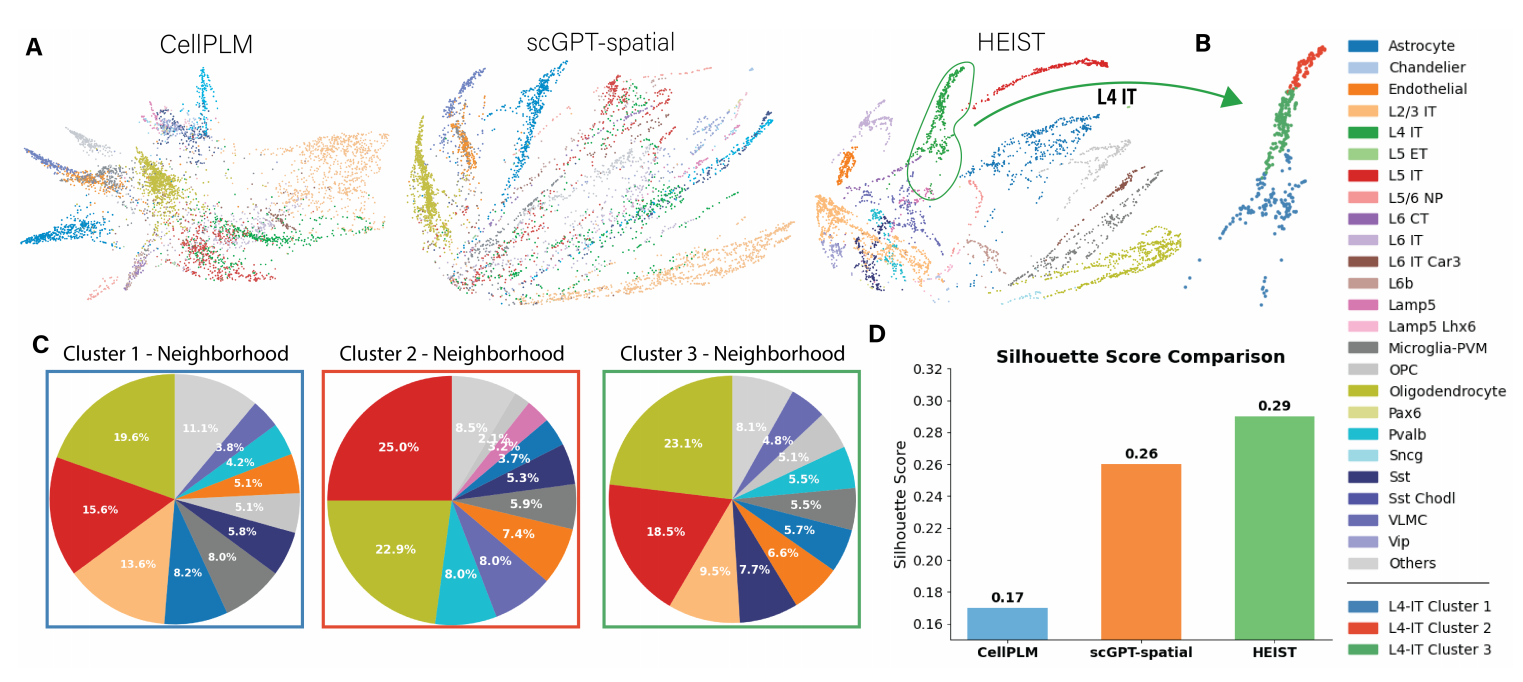
细胞类型注释与聚类:HEIST的嵌入能更清晰地区分细胞类型(表3)。更重要的是,它发现了传统方法无法识别的、由空间微环境定义的细胞亚群。例如,在图3中,大脑皮层中的L4-IT神经元被进一步分成了三个亚群,这些亚群具有独特的空间分布模式,可能对应着不同的功能状态或微环境互动。
-
计算效率:得益于对稀疏图结构的高效利用,HEIST提取嵌入的速度比scGPT-spatial快8倍,比scFoundation快48倍(表A4)。
意义与展望:通向“空间感知”生物医学AI的一步 HEIST的提出,标志着空间多组学分析从针对特定数据集的任务型模型,向通用、可迁移的基础模型迈出了关键一步。
其潜在应用深远:
-
新生物标志物发现:通过识别那些由特定微环境塑造的细胞状态,可能找到更精准的疾病诊断或治疗反应预测标志物。
-
药物靶点探索:理解基因/蛋白功能如何随空间环境变化,有助于发现只在特定组织区域起效的潜在靶点。
-
跨技术、跨模态整合:为统一分析日益多样的空间测量技术(转录组、蛋白组、代谢组)提供了框架。
-
推动精准医疗:更准确地预测患者预后和治疗反应,为临床决策提供支持。
局限性 当然,HEIST仍有改进空间。论文指出,其基因共表达网络基于互信息构建,可能未捕捉因果或方向性关系。模型目前处理的是静态切片,未来需要扩展以整合时序动态信息。此外,尽管效率已提升,大规模预训练仍需要可观的算力资源。
结语 HEIST的成功,本质上在于它尊重并编码了生物系统固有的层次结构:分子在细胞内形成功能模块,细胞在组织中形成空间社群。它将深度学习从学习静态的“词汇表”,推进到了学习动态的“语境化语法”。这或许预示着,未来理解生命复杂性的关键,不仅在于罗列所有“零件”,更在于精准刻画这些零件在时空维度上如何“对话”与“协作”。
随着空间多组学数据爆炸式增长,像HEIST这样能够融汇多层次信息的基础模型,将成为不可或缺的分析引擎。一个值得深思的问题是:当模型能够如此精细地解析静态组织的空间逻辑后,我们该如何设计下一代模型,才能让它同样深刻地理解生命过程中随时间演化的空间动态——例如胚胎发育或肿瘤演进——这其中的核心挑战又是什么?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)