基于 LangChain1.1 从零搭建 AI 文档审核系统
基于 LangChain1.1 从零搭建 AI 文档审核系统
本文详细介绍了如何基于 LangChain1.1 从零搭建一个 AI 文档审核系统,包括智能文档审核 Agent 的技术架构、MinerU 解析 PDF、DeepSeek 大模型审核、Pydantic 结构化输出、自定义审核规则、大文档分块处理,以及最后通过 HITL(Human-in-the-Loop)实现人机交互审核。简单来说,就是让 AI 先自动发现文档中的问题,再让人工在关键操作前进行确认、修改或者拒绝,从而让文档审核系统真正变得可控、可落地。
这套内容可以理解为之前“文档审核 Agent”项目的 V2.0 升级版。上一版重点是讲清楚文档审核 Agent 的基本方案,而这一版进一步升级到了 LangChain1.1,并加入了更完整的结构化审核 Pipeline 和 HITL 人工确认流程。
1、项目功能介绍
首先先看一下这个项目主要做什么。智能文档审核系统的核心目标是:自动读取 PDF 文档内容,识别文档中的语法错误、用词不当、逻辑问题、敏感表述以及自定义业务规则问题,并输出结构化审核结果。
在实际业务场景中,文档审核一般不会只是让 AI 给出一段自然语言说明,而是需要:
- 能知道问题出现在第几段;
- 能知道问题属于什么类型;
- 能给出具体解释和修改建议;
- 能把审核结果保存到数据库或者展示到前端;
- 对关键操作支持人工确认,避免 AI 误判直接生效。
所以本项目整体分为三部分:
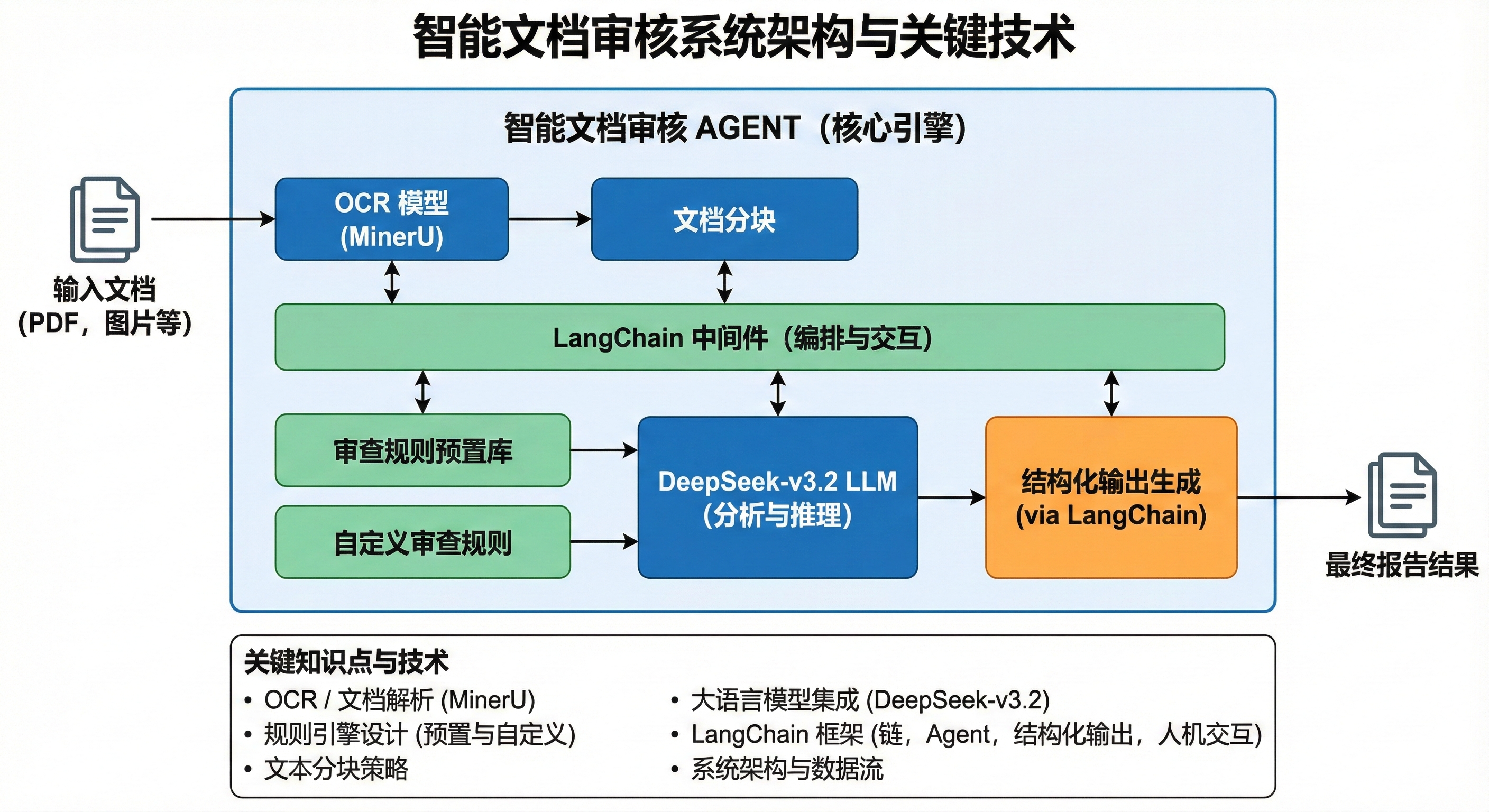
Part 1:智能文档审核 Agent 技术架构概览
Part 2:基于 LangChain1.1 从零搭建 AI 文档审核系统
Part 3:基于 LangChain1.1 实现 HITL 人机交互审核
整体流程如下:
PDF 文档
↓
MinerU 解析
↓
提取段落文本
↓
LangChain1.1 调用 DeepSeek 审核
↓
Pydantic 结构化输出
↓
自定义规则 + 分块处理
↓
生成审核问题
↓
HITL 人工确认
↓
批准 / 修改 / 拒绝
如下图所示:
2、为什么说这是文档审核 Agent 的升级版
之前的文档审核 Agent 项目主要讲的是文档审核类应用的整体技术方案,比如 OCR、VLM、RAG、Agent 编排、文档解析等核心模块。
这一版的升级点主要有三个:
- 使用 LangChain1.1 重新搭建审核 Pipeline。
- 使用 PydanticOutputParser 让模型输出结构化 JSON。
- 使用 HumanInTheLoopMiddleware 实现人工确认机制。
也就是说,这一版不是单纯讲“AI 能不能审核文档”,而是更接近真实业务系统:
AI 发现问题 → 结构化保存问题 → 人工确认 → 决定是否更新状态
这样就能避免一个很常见的问题:AI 自动审核看起来很方便,但如果误判后直接修改数据库,风险就比较大。所以企业级文档审核系统里面,HITL 基本是必须考虑的一环。
3、安装项目依赖
首先安装本项目需要的 Python 库:
pip install langchain langchain-openai langgraph pydantic python-dotenv httpx
如果是在 Jupyter Notebook 里面运行,可以直接执行:
%pip install langchain langchain-openai langgraph pydantic python-dotenv httpx
这些库的作用分别如下:
langchain:大模型应用开发核心框架。langchain-openai:用于调用 OpenAI 兼容接口,DeepSeek 也可以用这个方式接入。langgraph:用于 Agent 状态管理和 HITL 中断恢复。pydantic:用于定义结构化输出数据模型。python-dotenv:用于读取.env环境变量。httpx:用于异步请求 MinerU API。
安装完成后,导入基础库:
import os
import json
import time
import zipfile
import io
import asyncio
from pathlib import Path
import httpx
from dotenv import load_dotenv
没有报错就说明环境准备完成。
4、配置 API Key
本项目主要用到两个 API Key:
DEEPSEEK_API_KEY:用于调用 DeepSeek 模型进行文档审核。MINERU_API_KEY:用于调用 MinerU API 解析 PDF 文档。
建议在项目根目录创建 .env 文件:
DEEPSEEK_API_KEY=your-deepseek-api-key
MINERU_API_KEY=your-mineru-api-key
然后在代码中加载:
load_dotenv(override=True)
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
MINERU_API_KEY = os.getenv("MINERU_API_KEY")
注意:这里的 your-deepseek-api-key 和 your-mineru-api-key 要换成自己的,不要直接写真实 Key 到公开代码里面。
5、使用 MinerU 解析 PDF
文档审核的第一步,是先把 PDF 里面的内容解析出来。这里我们使用 MinerU API。它可以把 PDF 中的文字、段落、页面信息解析成结构化结果,后续再交给大模型审核。
MinerU 的解析流程主要分为四步:
请求上传 URL → 上传 PDF 文件 → 轮询解析状态 → 下载解析结果
先定义 PDF 解析函数:
async def parse_pdf_with_mineru(pdf_path: str, api_key: str) -> list[dict]:
base_url = "https://mineru.net"
file_path = Path(pdf_path)
file_name = file_path.name
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
async with httpx.AsyncClient(timeout=300) as client:
print("步骤1:请求上传 URL...")
resp = await client.post(
f"{base_url}/api/v4/file-urls/batch",
headers=headers,
json={
"files": [{"name": file_name, "data_id": file_name}],
"model_version": "vlm",
}
)
resp.raise_for_status()
data = resp.json()["data"]
batch_id = data["batch_id"]
upload_url = data["file_urls"][0]
print("步骤2:上传 PDF 文件...")
with open(pdf_path, "rb") as f:
await client.put(upload_url, content=f.read())
print("步骤3:等待解析完成...")
max_wait = 300
start_time = time.time()
while True:
resp = await client.get(
f"{base_url}/api/v4/extract-results/batch/{batch_id}",
headers={"Authorization": f"Bearer {api_key}"}
)
result = resp.json()["data"]["extract_result"][0]
if result["state"] == "done":
full_zip_url = result["full_zip_url"]
break
elif result["state"] == "failed":
raise RuntimeError(f"解析失败: {result.get('err_msg')}")
if time.time() - start_time > max_wait:
raise TimeoutError("解析超时")
await asyncio.sleep(2)
print("步骤4:下载解析结果...")
resp = await client.get(full_zip_url)
zip_bytes = resp.content
with zipfile.ZipFile(io.BytesIO(zip_bytes)) as zf:
json_files = [n for n in zf.namelist() if n.endswith(".json")]
if not json_files:
raise RuntimeError("未找到解析结果")
with zf.open(json_files[0]) as f:
content = json.loads(f.read().decode("utf-8"))
paragraphs = extract_paragraphs(content)
return paragraphs
接下来定义一个段落提取函数,因为 MinerU 返回的 JSON 结构可能有多种格式,所以这里做一点兼容处理:
def extract_paragraphs(content) -> list[dict]:
paragraphs = []
if isinstance(content, list):
for item in content:
if isinstance(item, dict):
text = item.get("text") or item.get("content") or ""
if text.strip():
paragraphs.append({
"content": text.strip(),
"page_num": item.get("page_idx", 0) + 1,
"bbox": item.get("bbox"),
})
return paragraphs
if isinstance(content, dict):
pages = content.get("pages") or []
for page in pages:
page_num = page.get("page", 1)
blocks = page.get("paragraphs") or page.get("blocks") or []
for block in blocks:
text = block.get("text") or block.get("content") or ""
if text.strip():
paragraphs.append({
"content": text.strip(),
"page_num": page_num,
"bbox": block.get("bbox"),
})
return paragraphs
这样,PDF 文档就会被转换成类似下面这样的段落列表:
[
{
"content": "本公司承诺绝对保证产品质量,必须满足所有客户需求。",
"page_num": 1,
"bbox": [...]
}
]
到这里,文档解析部分就完成了。
6、初始化 DeepSeek 模型
接下来使用 LangChain1.1 接入 DeepSeek 模型。DeepSeek 提供 OpenAI 兼容接口,所以可以直接使用 ChatOpenAI。
from langchain_openai import ChatOpenAI
def init_llm(api_key: str) -> ChatOpenAI:
llm = ChatOpenAI(
model="deepseek-chat",
api_key=api_key,
base_url="https://api.deepseek.com/v1",
temperature=0.2,
max_tokens=4096,
)
return llm
llm = init_llm(DEEPSEEK_API_KEY)
简单测试一下:
from langchain_core.messages import HumanMessage
response = llm.invoke([
HumanMessage(content="你好,请用一句话介绍你自己。")
])
print(response.content)
能正常返回内容,说明模型调用成功。
7、理解 LangChain 消息类型
在 LangChain 中,和大模型对话不是直接传一段字符串,而是由不同类型的消息组成。
常见消息类型如下:
SystemMessage:系统消息,用来定义 AI 的角色和行为边界。HumanMessage:用户消息,也就是用户输入的内容。AIMessage:AI 返回的消息。
例如:
from langchain_core.messages import SystemMessage, HumanMessage
messages = [
SystemMessage(content="你是一位专业的文档审核专家,擅长发现文档中的问题。"),
HumanMessage(content="请检查这句话是否有问题:我们的产品必须满足所有客户需求。"),
]
response = llm.invoke(messages)
print(response.content)
这一步主要是为了后面构建文档审核 Prompt 做准备。
8、定义结构化输出格式
如果让大模型直接输出自然语言,虽然人能看懂,但程序不好处理。比如我们需要把问题展示到前端、统计问题类型、保存到数据库,就必须要结构化数据。
这里使用 Pydantic 定义审核问题的数据结构:
from pydantic import BaseModel, Field
from typing import List
class ReviewIssue(BaseModel):
type: str = Field(description="问题类型,如:语法错误、用词不当、逻辑问题、敏感表述")
text: str = Field(description="问题所在的原文片段")
explanation: str = Field(description="问题的详细说明")
suggested_fix: str = Field(description="修改建议")
para_index: int = Field(description="问题所在段落的索引,从0开始")
class ReviewOutput(BaseModel):
issues: List[ReviewIssue] = Field(description="发现的问题列表")
然后使用 LangChain 的 PydanticOutputParser:
from langchain_core.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=ReviewOutput)
format_instructions = parser.get_format_instructions()
这个解析器会自动生成 JSON Schema,告诉模型应该按照什么格式输出。后面解析时,也可以直接把模型结果转成 Python 对象。
9、设计文档审核提示词
接下来设计系统提示词。系统提示词要告诉模型四件事:
- 它是什么角色;
- 它需要检查哪些问题;
- 它如何定位问题;
- 它必须按 JSON 格式输出。
示例提示词如下:
SYSTEM_PROMPT = """你是一位专业的文档审核专家。
请仔细审查提供的文本,识别其中的问题。
需要检查的问题类型:
- 语法错误:错别字、标点符号错误、语病等
- 用词不当:使用了不恰当的词语或表达
- 敏感表述:使用了"必须"、"保证"、"一定"、"绝对"等过度承诺的措辞
注意事项:
1. 文档可能是中文或英文,请根据语言选择合适的审核标准
2. 使用输入中提供的段落索引来标识问题位置
3. 每个问题都需要提供具体的修改建议
4. 如果没有发现问题,返回空的问题列表
5. 按照要求的 JSON 格式输出结果
"""
然后构建用户提示词:
def build_user_prompt(paragraphs: list[dict], parser: PydanticOutputParser) -> str:
formatted_text = "\n".join([
f"[{i}] {p['content']}"
for i, p in enumerate(paragraphs)
])
user_prompt = f"""请审核以下文本内容:
{formatted_text}
如果发现问题,请按以下格式输出;如果没有问题,返回空的 issues 列表。
{parser.get_format_instructions()}
"""
return user_prompt
这里每个段落都加上了 [0]、[1] 这样的索引,后面模型发现问题时就能返回 para_index。
10、实现核心审核函数
有了提示词和结构化输出格式,就可以封装核心审核函数了:
from langchain_core.messages import SystemMessage, HumanMessage
def review_document(paragraphs: list[dict], llm: ChatOpenAI) -> ReviewOutput:
parser = PydanticOutputParser(pydantic_object=ReviewOutput)
messages = [
SystemMessage(content=SYSTEM_PROMPT),
HumanMessage(content=build_user_prompt(paragraphs, parser)),
]
print("正在调用 LLM 进行审核...")
response = llm.invoke(messages)
try:
result = parser.parse(response.content)
print(f"审核完成,发现 {len(result.issues)} 个问题")
return result
except Exception as e:
print(f"解析输出失败: {e}")
return ReviewOutput(issues=[])
测试数据:
sample_paragraphs = [
{"content": "本公司承诺绝对保证产品质量,必须满足所有客户需求。", "page_num": 1},
{"content": "根据市场调研,我们的产品销量将一定达到预期目标。", "page_num": 1},
{"content": "公司简介:我们是一家专注于人工智能领域的科技公司。", "page_num": 2},
]
result = review_document(sample_paragraphs, llm)
打印审核结果:
for issue in result.issues:
print("类型:", issue.type)
print("位置:", issue.para_index)
print("原文:", issue.text)
print("说明:", issue.explanation)
print("建议:", issue.suggested_fix)
到这里,一个最基础的 AI 文档审核 Pipeline 就跑通了。
11、支持自定义审核规则
真实项目里,每个企业的审核规则都不一样。比如有的企业更关注“夸大宣传”,有的更关注“数据引用是否标注来源”,所以审核规则必须可以自定义。
先定义规则结构:
from enum import Enum
class RiskLevel(str, Enum):
HIGH = "高"
MEDIUM = "中"
LOW = "低"
class RuleExample(BaseModel):
text: str = Field(description="示例文本")
explanation: str = Field(description="说明")
class ReviewRule(BaseModel):
name: str = Field(description="规则名称")
description: str = Field(description="规则描述")
risk_level: RiskLevel = Field(description="风险等级")
examples: list[RuleExample] = Field(default=[], description="示例列表")
创建两条示例规则:
sample_rules = [
ReviewRule(
name="夸大宣传",
description="检查是否有夸大产品效果或功能的表述,如'最好'、'第一'、'独家'等",
risk_level=RiskLevel.HIGH,
examples=[
RuleExample(text="我们的产品是市场上最好的", explanation="使用了绝对化用语'最好'")
]
),
ReviewRule(
name="数据引用",
description="检查引用的数据是否标注了来源",
risk_level=RiskLevel.MEDIUM,
examples=[
RuleExample(text="据统计,90%的用户表示满意", explanation="未标注统计数据的来源")
]
),
]
然后把自定义规则动态加入系统提示词:
def build_system_prompt(custom_rules: list[ReviewRule] = None) -> str:
issue_types = [
"- 语法错误:错别字、标点符号错误、语病等",
"- 用词不当:使用了不恰当的词语或表达",
"- 敏感表述:使用了'必须'、'保证'、'一定'等过度承诺的措辞",
]
if custom_rules:
for rule in custom_rules:
rule_desc = f"- {rule.name}:{rule.description}"
if rule.examples:
examples_str = ";".join([f'"{ex.text}"' for ex in rule.examples[:2]])
rule_desc += f"(示例:{examples_str})"
issue_types.append(rule_desc)
prompt = f"""你是一位专业的文档审核专家。
请仔细审查提供的文本,识别其中的问题。
需要检查的问题类型:
{chr(10).join(issue_types)}
注意事项:
1. 文档可能是中文或英文,请根据语言选择合适的审核标准
2. 使用输入中提供的段落索引来标识问题位置
3. 每个问题都需要提供具体的修改建议
4. 如果没有发现问题,返回空的问题列表
5. 按照要求的 JSON 格式输出结果
"""
return prompt
这样,我们就可以根据不同业务场景传入不同审核规则。
12、分块处理大文档
如果 PDF 文档比较长,一次性全部传给大模型可能会超过上下文限制,也不利于稳定输出。所以需要把段落切成多个小块,逐块审核。
def chunk_paragraphs(paragraphs: list[dict], chunk_size: int = 20) -> list[list[dict]]:
chunks = []
for i in range(0, len(paragraphs), chunk_size):
chunk = paragraphs[i:i + chunk_size]
chunks.append(chunk)
return chunks
然后定义流式审核函数:
from typing import Generator
def stream_review_document(
paragraphs: list[dict],
llm: ChatOpenAI,
custom_rules: list[ReviewRule] = None,
chunk_size: int = 20
) -> Generator[ReviewOutput, None, None]:
chunks = chunk_paragraphs(paragraphs, chunk_size)
parser = PydanticOutputParser(pydantic_object=ReviewOutput)
system_prompt = build_system_prompt(custom_rules)
for i, chunk in enumerate(chunks):
print(f"正在处理第 {i+1}/{len(chunks)} 块...")
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=build_user_prompt(chunk, parser)),
]
response = llm.invoke(messages)
try:
result = parser.parse(response.content)
yield result
except Exception as e:
print(f"解析失败: {e}")
yield ReviewOutput(issues=[])
这样做的好处是,长文档也可以稳定处理,而且可以边处理边展示进度。
13、生成文档审核报告
审核完成后,可以把所有问题汇总成 Markdown 报告:
def generate_report(issues: list[ReviewIssue], output_path: str = None) -> str:
type_counts = {}
for issue in issues:
type_counts[issue.type] = type_counts.get(issue.type, 0) + 1
report = []
report.append("# 文档审核报告")
report.append("")
report.append("## 概要")
report.append(f"- 发现问题总数:**{len(issues)}**")
report.append("")
report.append("## 问题类型分布")
for issue_type, count in sorted(type_counts.items(), key=lambda x: -x[1]):
report.append(f"- {issue_type}:{count} 个")
report.append("")
report.append("## 问题详情")
for i, issue in enumerate(issues, 1):
report.append(f"\n### 问题 {i}")
report.append(f"- **类型**:{issue.type}")
report.append(f"- **位置**:段落 {issue.para_index}")
report.append(f"- **原文**:{issue.text}")
report.append(f"- **说明**:{issue.explanation}")
report.append(f"- **建议**:{issue.suggested_fix}")
report_text = "\n".join(report)
if output_path:
with open(output_path, "w", encoding="utf-8") as f:
f.write(report_text)
return report_text
执行:
report = generate_report(all_issues, "review_report.md")
到这里,AI 自动审核部分就已经比较完整了。
14、为什么还需要 HITL
上面我们已经完成了 AI 自动审核,但是实际业务里还有一个关键问题:
AI 的判断不一定 100% 正确,我们如何让人类来把关?
比如 AI 认为某个问题应该被采纳,并准备更新数据库状态。如果这个动作直接执行,就可能出现误判风险。
所以在执行关键操作之前,我们需要插入一个“人工确认”环节。这就是 HITL,也就是 Human-in-the-Loop。
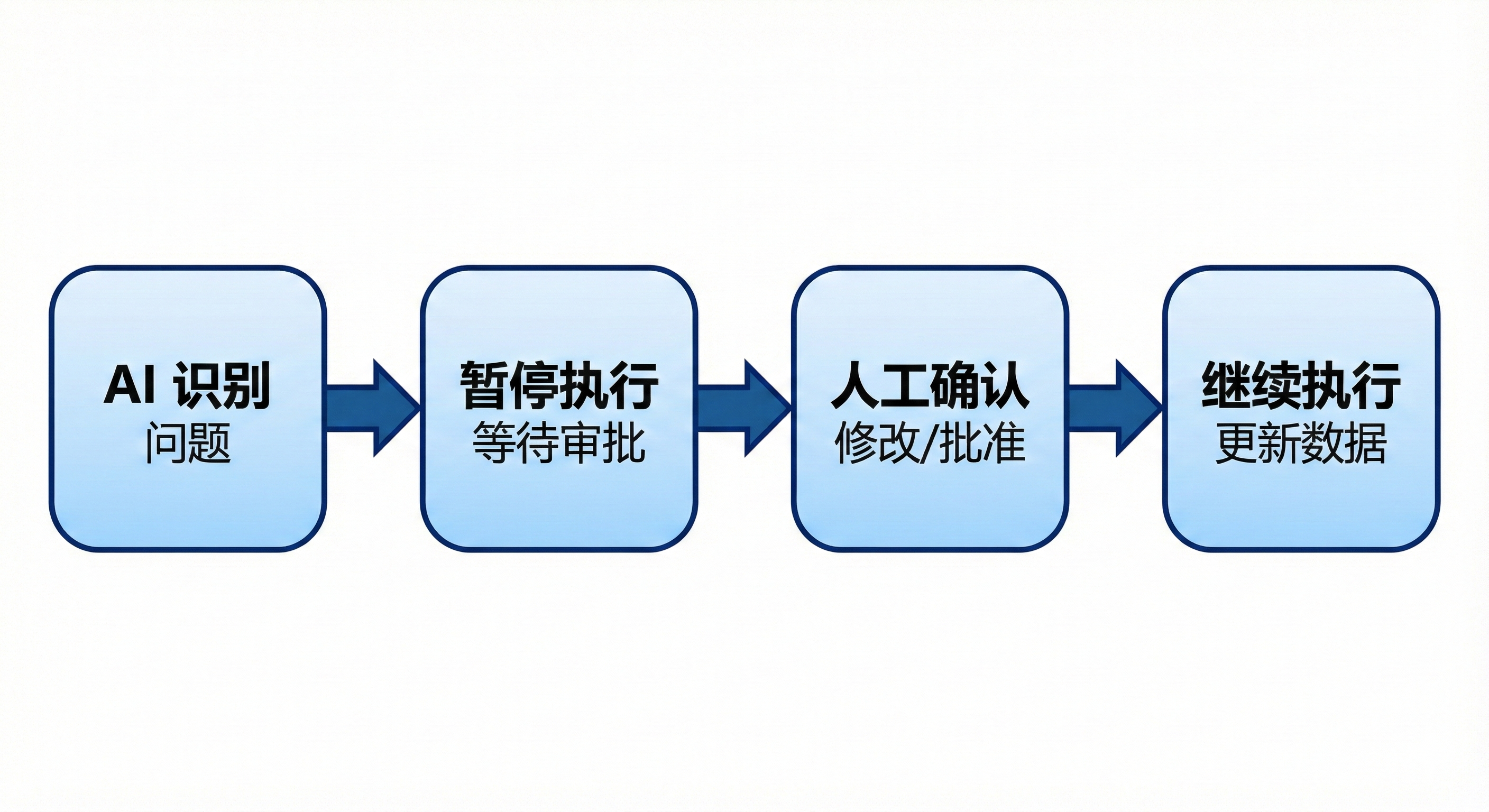
HITL 的核心思想很简单:
AI 提议操作 → 系统暂停 → 人工审核 → 批准 / 修改 / 拒绝 → 系统继续执行
如下图所示:
在 LangChain1.1 中,可以使用 HumanInTheLoopMiddleware 实现这个流程。
15、定义 HITL 问题数据结构
先定义问题状态:
from pydantic import BaseModel, Field
from typing import Dict, Any, Optional, List
from enum import Enum
from datetime import datetime
import uuid
class IssueStatus(str, Enum):
not_reviewed = "not_reviewed"
accepted = "accepted"
dismissed = "dismissed"
然后定义问题对象:
class Issue(BaseModel):
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
doc_id: str
text: str
type: str
status: IssueStatus = IssueStatus.not_reviewed
explanation: str = ""
suggested_fix: str = ""
resolved_by: Optional[str] = None
resolved_at: Optional[str] = None
接下来创建一个简单的内存数据库,用于演示:
class IssuesDatabase:
def __init__(self):
self._issues: Dict[str, Issue] = {}
def add_issue(self, issue: Issue) -> None:
self._issues[issue.id] = issue
def get_issue(self, issue_id: str) -> Optional[Issue]:
return self._issues.get(issue_id)
def update_issue(self, issue_id: str, update_fields: Dict[str, Any]) -> Issue:
issue = self._issues.get(issue_id)
if not issue:
raise ValueError(f"问题不存在: {issue_id}")
issue_dict = issue.model_dump()
issue_dict.update(update_fields)
updated_issue = Issue(**issue_dict)
self._issues[issue_id] = updated_issue
return updated_issue
def list_issues(self) -> List[Issue]:
return list(self._issues.values())
db = IssuesDatabase()
这里用内存数据库是为了方便演示,实际项目中可以换成 SQLite、PostgreSQL 或者业务系统数据库。
16、创建支持 HITL 的 Agent
HITL 的关键是:在执行某个工具之前触发中断。这里我们把 update_issue 作为需要人工确认的关键工具。
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langchain_core.messages import HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
定义工具函数:
def update_issue(issue_id: str, update_fields: Dict[str, Any]) -> str:
db.update_issue(issue_id, update_fields)
return "ok"
定义系统提示词:
SYSTEM_PROMPT = """你是一个审阅工作流执行器。
你会收到 issue_id 和 update_fields。
你必须且只能调用一次 update_issue 工具,并严格使用提供的参数。
不要自行猜测、不要新增字段、不要修改字段含义。
"""
创建 Agent:
hitl_agent = create_agent(
model=llm,
tools=[update_issue],
system_prompt=SYSTEM_PROMPT,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"update_issue": True,
},
description_prefix="需要人工确认的操作",
),
],
checkpointer=InMemorySaver(),
)
这里有三个重点:
interrupt_on={"update_issue": True}:表示调用update_issue前先暂停。HumanInTheLoopMiddleware:负责触发人工确认。InMemorySaver:负责保存中断状态,后面才能恢复执行。
17、启动 HITL 流程
我们封装一个 start_hitl() 函数,用于启动 Agent 并触发中断:
async def start_hitl(
thread_id: str,
issue_id: str,
update_fields: Dict[str, Any]
) -> Dict[str, Any]:
config = {"configurable": {"thread_id": thread_id}}
prompt = (
"请按照提供的参数更新 issue。\n"
f"issue_id: {issue_id}\n"
f"update_fields(JSON): {json.dumps(update_fields, ensure_ascii=False)}\n"
"你必须调用 update_issue。\n"
)
async for step in hitl_agent.astream(
{"messages": [HumanMessage(content=prompt)]},
config,
stream_mode="values"
):
if "__interrupt__" in step:
interrupt = step["__interrupt__"][0]
return {
"id": getattr(interrupt, "id", None),
"value": getattr(interrupt, "value", interrupt),
"thread_id": thread_id,
}
return None
这里的 thread_id 很重要。它相当于本次 HITL 流程的唯一编号,后面恢复执行时就靠它找到之前保存的状态。
18、恢复 HITL 流程
人工做出决策后,需要用 resume_hitl() 恢复执行:
async def resume_hitl(
thread_id: str,
decision: Dict[str, Any],
interrupt_id: str = None
) -> None:
config = {"configurable": {"thread_id": thread_id}}
cmd = Command(resume={"decisions": [decision]})
async for step in hitl_agent.astream(cmd, config, stream_mode="values"):
if "__interrupt__" in step:
raise RuntimeError("HITL 恢复后产生了新的中断")
print("HITL 流程已完成")
LangChain HITL 支持三种人工决策:
| 决策类型 | 数据结构 | 说明 |
|---|---|---|
| 批准 | {"type": "approve"} |
按 AI 原计划执行 |
| 修改 | {"type": "edit", "edited_action": {...}} |
按人工修改后的参数执行 |
| 拒绝 | {"type": "reject", "message": "..."} |
取消操作,不执行 |
接下来分别看这三种情况。
19、场景一:批准 AI 的提议
假设 AI 提议把某个问题状态改成 accepted:
update_fields = {
"status": IssueStatus.accepted.value,
"resolved_by": "user_001",
"resolved_at": datetime.now().isoformat(),
}
thread_id = f"issue:{ISSUE_ID}:{uuid.uuid4()}"
interrupt_info = await start_hitl(
thread_id=thread_id,
issue_id=ISSUE_ID,
update_fields=update_fields,
)
此时系统会暂停,等待人工确认。如果审核员同意,就传入批准决策:
approve_decision = {"type": "approve"}
await resume_hitl(
thread_id=thread_id,
decision=approve_decision,
interrupt_id=interrupt_info.get("id")
)
执行完成后,数据库中的问题状态就会更新为 accepted。
20、场景二:修改 AI 的提议
有时候 AI 的方向对了,但参数不完全对。比如 AI 原本要忽略问题,但审核员认为应该采纳,这时就可以使用 edit。
edit_decision = {
"type": "edit",
"edited_action": {
"name": "update_issue",
"args": {
"issue_id": ISSUE_ID,
"update_fields": {
"status": IssueStatus.accepted.value,
"resolved_by": "supervisor_001",
"resolved_at": datetime.now().isoformat(),
}
}
}
}
await resume_hitl(
thread_id=thread_id,
decision=edit_decision,
)
这样最终执行的就不是 AI 原始提议,而是人工修改后的操作。
21、场景三:拒绝 AI 的提议
如果审核员完全不同意 AI 的判断,可以直接拒绝:
reject_decision = {
"type": "reject",
"message": "这不是真正的问题,AI 判断有误,无需采纳"
}
await resume_hitl(
thread_id=thread_id,
decision=reject_decision,
)
拒绝后,update_issue 不会真正执行,问题状态也会保持原样。
22、完整 HITL 流程总结
整个 HITL 流程可以理解为:
用户请求更新问题状态
↓
Agent 准备调用 update_issue
↓
HumanInTheLoopMiddleware 触发中断
↓
Checkpointer 保存当前状态
↓
人工查看 AI 提议
↓
选择 approve / edit / reject
↓
Command 恢复执行
↓
系统完成或取消更新
这个机制非常适合放在文档审核系统里,因为文档审核结果通常会影响业务流程,不能完全依赖 AI 自动决定。HITL 让 AI 负责提高效率,让人类负责关键把关。
23、总结
到这里,一个基于 LangChain1.1 的 AI 文档审核系统就搭建完成了。整体来看,这个项目相比之前的文档审核 Agent 版本更工程化:前面通过 MinerU 解析 PDF,再通过 DeepSeek + LangChain 完成结构化审核;中间支持自定义审核规则和大文档分块处理;最后通过 HITL 人机交互机制,让 AI 的审核结果在关键操作前必须经过人工确认。
这个系统的核心不是简单调用一次大模型,而是把文档审核拆成了完整流程:文档解析、段落抽取、规则审核、结构化输出、报告生成、人工确认和状态更新。这样做之后,AI 文档审核才更适合进入真实业务场景。
24、系统演示
主界面:
上传文档开始分析审核:
AI审核完成,待人工审批: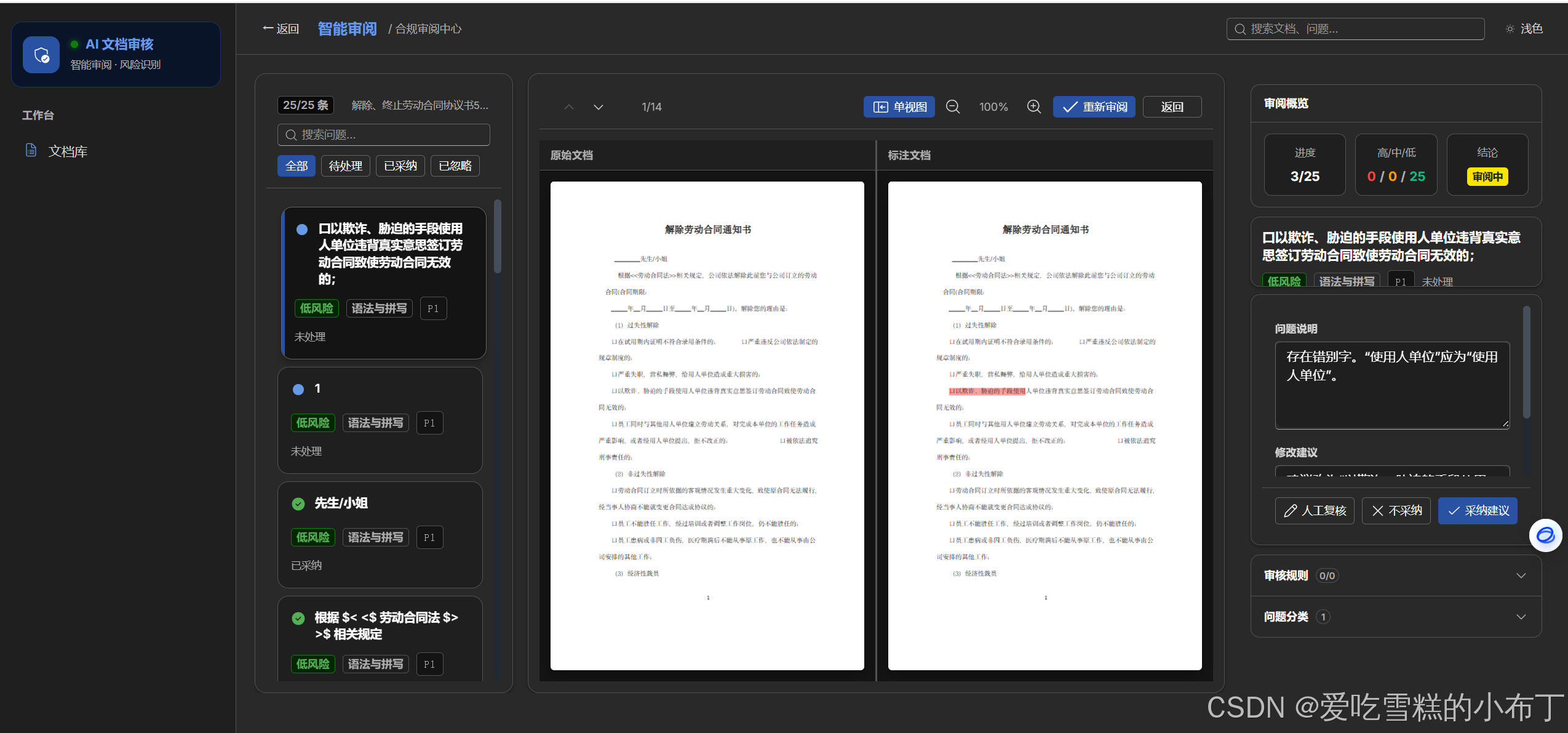

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)