Langchain学习笔记
** Langchain介绍**
Langchain是一个开源框架,用于开发由大语言模型(LLMs)驱动的应用程序。
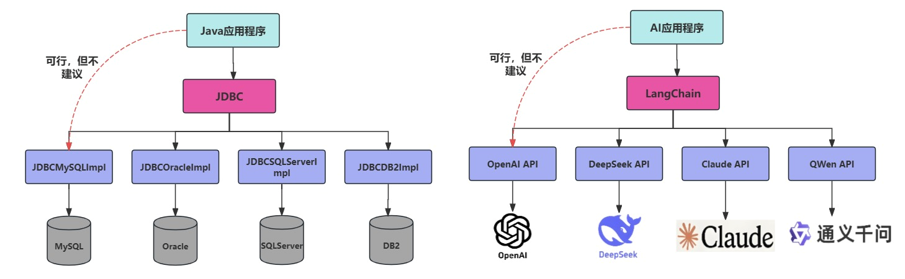
LangChain 是一个帮助你构建 LLM 应用的全套工具集。这里涉及到prompt 构建、LLM 接入、记忆管理、工具调用、RAG、Agent开发等模块
使用场景
**Model I/O **
Model I/O 部分是与语言模型进行交互的核心组件,包括输入提示(Prompt Template)、调用模型(Model)、输出解析(Output Parser)。简单来说,就是输入、处理、输出这三个步骤。
1.1 OpenAI SDK 调用模型
OpenAI 的GPT 系列模型影响了大模型技术发展的开发范式和标准。所以无论是Qwen、ChatGLM 等模型,它们的使用方法和函数调用逻辑基本遵循OpenAI 定义的规范,没有太大差异。这就使得能够通过一个较为通用的接口来接入和使用不同的模型。
# pip install langchain langchain-openai
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1", # 平台提供的 URL
api_key="sk-...", # 平台提供的 API-Key
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free", # 模型名称
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}], # 用户输入
)
print(completion.choices[0].message.content)
1.2 LangChain API 调用模型
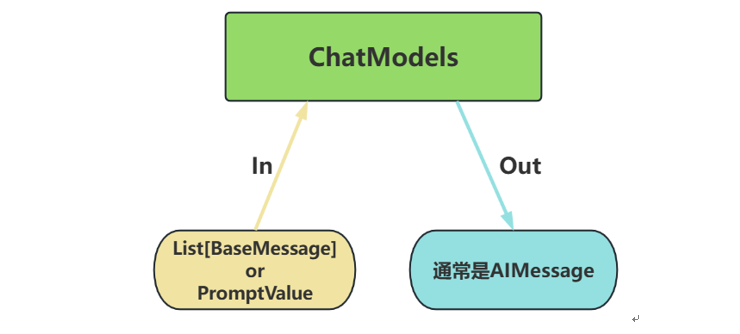
通常通过聊天模型接口访问LLM,该接口通常以消息列表作为输入并返回一条消息作为输出。
输入:接受文本PromptValue 或消息列表List[BaseMessage],每条消息需指定角色(如System Message、HumanMessage、AIMessage)
输出:返回带角色的消息对象(BaseMessage 子类),通常是AIMessage
import os
from langchain.chat_models import init_chat_model
from langchain.messages import SystemMessage, HumanMessage, AIMessage
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
SystemMessage(content="你是一个诗人"),
HumanMessage(content="写一首关于春天的诗"),
]
resp = llm.invoke(messages)
print(type(resp)) # <class 'langchain_core.messages.ai.AIMessage'>
print(resp.content)
初始化参数
| 参数 | 说明 |
|---|---|
| model | 模型名称或标识符 |
| base_url | 发送请求的 API 端点的 URL。常由模型的提供商提供 |
| api_key | 与模型提供商进行身份验证所需的 API 密钥 |
| temperature | 控制模型输出的随机性。数字越高,回答越有创意;数字越低,回答越确定 |
| timeout | 在取消请求之前,等待模型响应的最大时间(以秒为单位) |
| max_tokens | 限制响应中的总tokens 数量,控制输出长度 |
| max_retries | 请求失败时系统尝试重新发送请求的最大次数 |
消息类型参数
| 消息类型 | 描述 |
|---|---|
| SystemMessage | 代表一组初始指令,用于引导模型的行为。可以使用系统消息来设定语气、定义模型的角色,并建立响应的指导方针 |
| HumanMessage | 表示用户输入 |
| AIMessage | 模型生成的响应,包括文本内容、工具调用和元数据 |
| ToolMessage | 表示工具调用的输出 |
调用方法
| invoke / ainvoke | 将单个输入转换为输出 |
|---|---|
| batch / abatch | 批量将多个输入转换为输出 |
| stream / astream | 从单个输入生成流式输出 |
1.2.1 非流式/流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出与非流式输出。
- **非流式输出:**用户提出需求请编写一首诗,系统在静默数秒后突然弹出了完整的诗歌。如同一种“提交请求,等待结果”的流程,实现简单,但体验单调。
这是LangChain 与LLM 交互时的默认行为,是最简单、最稳定的语言模型调用方式。当用户发出请求后,系统在后台等待模型生成完整响应,然后一次性将全部结果返回。
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一名数学家"},
{"role": "user", "content": "请证明以下黎曼猜想"},
]
resp = llm.invoke(messages)
print(resp.content)
- 流式输出:用户提问,请编写一首诗,当问题刚刚发送,系统就开始一字一句(逐个token)进行回复,更像是“实时对话”,贴近人类交互的习惯。
流式输出是一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token地实时返回内容。适合构建强调“实时反馈”的应用。
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一名数学家"},
{"role": "user", "content": "请证明以下黎曼猜想"},
]
# 使用 stream() 方法流式输出
for chunk in llm.stream(messages):
# 逐个打印内容块,并刷新缓冲区以即时显示内容
print(chunk.content, end="", flush=True)
** 1.2.2 批量调用**
将一组独立的请求批量发送给模型并行处理。
batch 默认没有依赖底层 API 的原生批量接口,而是使用线程池并行执行多个 invoke()。所以它对 IO 密集型任务(如调用远程 LLM API)很有效。
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
resp = llm.batch(messages) # 批量调用,返回一个消息列表
print(resp)
1.2.3 同步/异步调用
- **同步调用 : **每个操作依次执行,直到当前操作完成后才开始下一个操作,总的执行时间是各个操作时间的总和。
- **异步调用 : **允许程序在等待某些操作完成时继续执行其他任务,而不是阻塞等待。这在处理I/O 操作(如网络请求、文件读写等)时特别有用,可以显著提高程序的效率和响应性。
import os
import time
import asyncio
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messagess = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
async def async_invoke():
tasks = [llm.ainvoke(messages) for messages in messagess]
return await asyncio.gather(*tasks)
start_time = time.time()
resps = asyncio.run(async_invoke())
print(resps)
end_time = time.time()
print(f"Total time: {end_time - start_time}")
1.3 调用本地模型
1.3.1 Ollama
Ollama是一个开源项目,其项目定位是:一个本地运行大模型的集成框架。目前主要针对主流的LlaMA架构的开源大模型设计,可以实现如 Qwen、Deepseek 等主流大模型的下载、启动和本地运行的自动化部署及推理流程。
# pip install langchain-ollama
from langchain_ollama import ChatOllama
ollama_llm = ChatOllama(
model="deepseek-r1:7b"
# base_url="http://your-ip:port", # 不在本地端口运行,自定义地址
)
messages = {"role": "user", "content": "你好,请介绍一下你自己"}
resp = ollama_llm.invoke(messages)
print(resp.content)
1.4 Prompt Template
1.4.1 Prompt Template
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,Prompt Template 是一个模板化的字符串,我们可以将变量插入到模板中,从而创建出不同的提示。Prompt Template 接收用户输入,返回一个传递给LLM的信息(即提示词prompt)。
提示模板以字典作为输入,其中每个键代表要填充的提示模板中的变量。并输出一个 PromptValue。这个 PromptValue 可以传递给聊天模型,也可以转换为字符串或消息列表。PromptValue 存在的目的是为了方便在字符串和消息之间切换。
from langchain_core.prompts import PromptTemplate
# 使用构造方法实例化提示词模板
template = PromptTemplate(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
input_variables=["product", "aspect1", "aspect2"],
)
# 使用模板生成提示词
prompt_1 = template.format(product="智能手机", aspect1="电池续航", aspect2="拍照质量")
prompt_2 = template.format(product="笔记本电脑", aspect1="处理速度", aspect2="便携性")
print(prompt_1) # 请评价智能手机的优缺点,包括电池续航和拍照质量。
print(prompt_2) # 请评价笔记本电脑的优缺点,包括处理速度和便携性。
| 参数 | |
|---|---|
| template | 提示模板,包括变量占位符 |
| input_variables | 需要将其值作为提示输入的变量名称列表 |
| partial_variables | 提示模板携带的部分变量的字典。使用部分变量预先填充模板,无需后续在每次调用时再传递这些变量 |
| 方法 | |
| format() | 使用输入格式化提示 |
from langchain_core.prompts import PromptTemplate
# 使用 from_template 方法实例化提示词模板
template = PromptTemplate.from_template("请给我一个关于{topic}的{type}解释。")
# 使用模板生成提示
prompt = template.format(type="详细", topic="量子力学")
print(prompt) # 请给我一个关于量子力学的详细解释。
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template("{foo} {bar}")
prompt = template.invoke({"foo": "hello", "bar": "world"})
print(prompt, type(prompt))
# text='hello world' <class 'langchain_core.prompt_values.StringPromptValue'>
prompt_str = prompt.to_string()
print(prompt_str, type(prompt_str))
# hello world <class 'str'>
1.4.2 ChatPromptTemplate
ChatPromptTemplate是创建_聊天消息列表_的提示模板。相较于普通 PromptTemplate更适合处理多角色、多轮次的对话场景。支持_System_/Human/_AI_等不同角色的消息模板。
实例化时需要传入 messages 参数,messages 参数支持如下格式:
- tuple 构成的列表,格式为[(role, content)]
- dict 构成的列表,格式为[{“role”:… , “content”:…}]
- Message 类构成的列表
from langchain_core.prompts import ChatPromptTemplate
template = ChatPromptTemplate(
[
("system", "你是一个AI开发工程师,你的名字是{name}。"),
("human", "你能帮我做什么?"),
("ai", "我能开发很多{thing}。"),
("human", "{user_input}"),
]
)
prompt = template.format_messages(name="小谷AI", thing="AI", user_input="行")
print(prompt)
# [
# SystemMessage(content="你是一个AI开发工程师,你的名字是小谷AI。",...),
# HumanMessage(content="你能帮我做什么?", ...),
# AIMessage(content="我能开发很多AI。", ...),
# HumanMessage(content="行", ...),
# ]
多模态提示词
可以使用提示模板来格式化多模态输入,比如将图片链接作为输入。
import os
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
llm = init_chat_model(
model="google/gemini-2.0-flash-exp:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
template = ChatPromptTemplate(
[
{"role": "system", "content": "用中文简短描述图片内容"},
{"role": "user", "content": [{"image_url": "{image_url}"}]},
]
)
prompt = template.format_messages(
image_url="https://img2.baidu.com/it/u=2976763563,2523722948&fm=253&app=138&f=JPEG?w=800&h=1200"
)
resp = llm.invoke(prompt)
print(resp.content) # 图片中是...
1.4.3 外部加载Prompt
可以将prompt 保存为JSON 或者YAML 等格式的文件,通过读取指定路径的格式化文件,获取相应的prompt。这样方便对prompt 进行管理和维护。
prompts目录下创建json文件:prompt.json
{
"_type": "prompt",
"input_variables": ["name", "what"],
"template": "请{name}讲一个{what}的故事"
}
from langchain_core.prompts import load_prompt
template = load_prompt("prompts/prompt.json", encoding="utf-8")
print(template.format(name="张三", what="搞笑的"))
# 请张三讲一个搞笑的的故事
prompts目录下创建yaml文件:prompt.yaml
_type: "prompt"
input_variables: ["name", "what"]
template: "请{name}讲一个{what}的故事"
from langchain_core.prompts import load_prompt
template = load_prompt("prompts/prompt.yaml", encoding="utf-8")
print(template.format(name="年轻人", what="滑稽"))
# 请年轻人讲一个滑稽的故事
1.5 Output Parsers
在应用开发中,大模型的输出可能是下一步逻辑处理的关键输入。因此,在这种情况下,_规范化输出_是必须要做的任务,以确保应用能够顺利进行后续的逻辑处理。
语言模型返回的内容通常都是文本字符串,而实际AI 应用开发过程中有时希望模型可以返回更直观、更格式化的内容,LangChain 提供了输出解析器(Output Parser)将模型输出解析为结构化数据。
有多种类型的输出解析器,常用的有_StrOutputParser_(字符串解析器)与_JsonOutputParser_(JSON解析器)。
1.5.1 StrOutputParser
StrOutputParser 是一个简单的解析器,从结果中提取content 字段。
import os
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一个机器人"},
{"role": "user", "content": "你好"},
]
resp = llm.invoke(messages)
print(resp) # content='你好!有什么我可以帮忙的吗?' additional_kwargs=......
str_resp = StrOutputParser().invoke(resp)
print(str_resp) # 你好!有什么我可以帮忙的吗?
1.5.2 JsonOutputParser
JSON 解析器用于将大模型的_自由文本输出_转换为_结构化__JSON__数据_的工具。特别适用于需要严格结构化输出的场景,比如API 调用、数据存储或下游任务处理。
JsonOutputParser 能够结合Pydantic 模型进行数据验证,自动验证字段类型和内容(如字符串、数字、嵌套对象等)
使用get_format_instructions() 获取JSON解析的格式化指令:
import os
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import JsonOutputParser
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
class Prime(BaseModel):
prime: list[int] = Field(description="素数")
count: list[int] = Field(description="小于该素数的素数个数")
json_parser = JsonOutputParser(pydantic_object=Prime)
messages = [
{"role": "system", "content": json_parser.get_format_instructions()},
{
"role": "user",
"content": "任意生成5个1000-100000之间素数,并标出小于该素数的素数个数",
},
]
resp = llm.invoke(messages)
json_resp = json_parser.invoke(resp)
print(json_resp)
# {'prime': [1009, 2003, 3001, 4001, 5003], 'count': [168, 303, 430, 584, 669]}
1.6 Structured Outputs
可以要求模型按照给定的模式格式提供其响应,这有助于确保输出可以被轻松解析并在后续处理中使用。LangChain 支持多种模式类型和强制结构化输出的方法。
1.6.1 TypedDict
TypedDict 提供了一个使用 Python 内置类型的简单方案,但是没有验证功能。
import os
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
class Animal(TypedDict):
animal: Annotated[str, "动物"]
emoji: Annotated[str, "表情"]
class AnimalList(TypedDict):
animals: Annotated[list[Animal], "动物与表情列表"]
messages = [{"role": "user", "content": "任意生成三种动物,以及他们的 emoji 表情"}]
llm_with_structured_output = llm.with_structured_output(AnimalList)
resp = llm_with_structured_output.invoke(messages)
print(resp)
# {'animals': [{'animal': '猫', 'emoji': '🐱'}, {'animal': '老虎', 'emoji': '🐯'}, {'animal': '企鹅', 'emoji': '🐧'}]}
Annotated是typing模块提供的增强型类型注解工具,python原生语法,核心公式:
Annotated[类型,元数据1,元数据2,...]
# Annotated[int,"年龄,范围0-150"]
核心作用:
- 给变量的基础类型附加任意的元数据(额外信息)
- 基础类型是必须遵守的约束,元数据是对这个字段的补充说明
- 元数据可以是任意内容:字符串、数字、函数…
1.6.2 Pydantic
Pydantic 模型提供了丰富的功能集,包括字段验证、描述和嵌套结构。
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
class Animal(BaseModel):
animal: str = Field(description="动物")
emoji: str = Field(description="表情")
class AnimalList(BaseModel):
animals: list[Animal] = Field(description="动物与表情列表")
messages = [{"role": "user", "content": "任意生成三种动物,以及他们的 emoji 表情"}]
llm_with_structured_output = llm.with_structured_output(AnimalList)
resp = llm_with_structured_output.invoke(messages)
print(resp)
# animals=[Animal(animal='猫', emoji='🐱'), Animal(animal='乌龟', emoji='🐢'), Animal(animal='企鹅', emoji='🐧')]
1.6.3 JSON Schema
若需最大程度的控制或互操作性,可以提供一个原始的 JSON Schema。可以将原始响应与解析后的表示一起返回,可在调用 with_structured_output 时设置 include_raw=True 来实现。
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
schema = {
"name": "animal_list",
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"animal": {"type": "string", "description": "动物名称"},
"emoji": {"type": "string", "description": "动物的emoji表情"},
},
"required": ["animal", "emoji"],
},
},
}
messages = [{"role": "user", "content": "任意生成三种动物,以及他们的 emoji 表情"}]
llm_with_structured_output = llm.with_structured_output(
schema, method="json_schema", include_raw=True
)
resp = llm_with_structured_output.invoke(messages)
print(resp)
print(resp["raw"])
print(resp["parsed"])
# [{'animal': '企鹅', 'emoji': '🐧'}, {'animal': '大象', 'emoji': '🐘'}, {'animal': '袋鼠', 'emoji': '🦘'}]
Chains
2.1 Runnable与LCEL
1)Runnable
Runnable 是LangChain 中可以调用、批处理、流式传输、转换和组合的工作单元。
Runnable 接口是使用 LangChain 组件的基础,它在许多组件中实现,例如语言模型、输出解析器、检索器、编译的 LangGraph 图等。
Runnable 接口_强制要求_所有LCEL 组件实现一组标准方法:
| invoke / ainvoke | 将单个输入转换为输出 |
|---|---|
| batch / abatch | 批量将多个输入转换为输出 |
| stream / astream | 从单个输入生成流式输出 |
_Runnable_统一调用方式:
# 分步调用
prompt_text = prompt.invoke({"topic": "猫"}) # 方法1
model_out = model.invoke(prompt_text) # 方法2
result = parser.invoke(model_out) # 方法3
# LCEL管道式
chain = prompt | model | parser # 用管道符组合
result = chain.invoke({"topic": "猫"}) # 所有组件统一用invoke
2)LCEL(语法糖)
LangChain 表达式语言(LCEL,LangChain Expression Language)是一种从现有的Runnable 构建新的Runnable 的声明式方法,用于声明、组合和执行各种组件(模型、提示、工具、函数等)。
我们称使用LCEL 创建的Runnable 为“链”,“链”本身就是Runnable。
LCEL 两个主要的组合原语是RunnableSequence 和 RunnableParallel。许多其他组合原语可以被认为是这两个原语的变体。
2.2 RunnableSequence 可运行序列
RunnableSequence 按顺序“链接”多个可运行对象,其中一个对象的输出作为下一个对象的输入。
LCEL重载了 | 运算符,以便从两个 Runnables 创建 RunnableSequence。
chain = runnable1 | runnable2
# 等同于
chain = RunnableSequence(runnable1, runnable2)
2.3 RunnableParallel 可运行并行
RunnableParallel 同时运行多个可运行对象,并为每个对象提供相同的输入。
对于同步执行,RunnableParallel 使用 ThreadPoolExecutor 来同时运行可运行对象。
对于异步执行,RunnableParallel 使用 asyncio.gather 来同时运行可运行对象。
在 LCEL 表达式中,字典会自动转换为 RunnableParallel。
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableParallel
import dotenv
dotenv.load_dotenv()
llm = ChatOpenAI(
model='qwen-vl-plus'
)
joke_chain=(
PromptTemplate.from_template('讲一个关于{topic}的笑话') | llm | StrOutputParser()
)
poem_chain=(
PromptTemplate.from_template('写一首关于{topic}的情诗') | llm | StrOutputParser()
)
chain=RunnableParallel(joke=joke_chain,poem=poem_chain)
res=chain.invoke({"topic":"菊花"})
print(res)
2.4 RunnableLambda 可运行λ
RunnableLambda 将 Python 可调用函数转换为 Runnable,使得函数可以在同步或异步上下文中使用。
from langchain_core.runnables import RunnableLambda
chain = {
"text1": lambda x: x + " world",
"text2": lambda x: x + ", how are you",
} | RunnableLambda(lambda x: len(x["text1"]) + len(x["text2"]))
result = chain.invoke("hello")
print(result) # 29
2.5 RunnablePassthrough 可运行透传
RunnablePassthrough 接收输入并将其原样输出。RunnablePassthrough 是 LangChain LCEL 体系中的“无操作节点”,用于在流水线中透传输入或保留上下文,也可以用于向输出中添加键。
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
chain = RunnableParallel(
original=RunnablePassthrough(), # 保留中间结果
word_count=lambda x: len(x),
)
result = chain.invoke("hello world")
print(result) # {'original': 'hello world', 'word_count': 11}
2.6 RunnableBranch 可运行分支
RunnableBranch 使用 (条件,Runnable) 对列表和默认分支进行初始化。对输入进行操作时,选择第一个计算结果为 True 的条件,并在输入上运行相应的 Runnable。如果没有条件为 True,则在输入上运行默认分支。
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: isinstance(x, str), lambda x: x.upper()),
(lambda x: isinstance(x, int), lambda x: x + 1),
(lambda x: isinstance(x, float), lambda x: x * 2),
lambda x: "goodbye",
)
result = branch.invoke("hello")
print(result) # HELLO
result = branch.invoke(None)
print(result) # goodbye
2.7 RunnableWithFallbacks 可运行带回退
RunnableWithFallbacks 使得 Runnable 失败后可以回退到其他 Runnable。可以直接在Runnable 上使用with_fallbacks 方法。
from langchain.chat_models import init_chat_model
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
chain = PromptTemplate.from_template("hello") | llm
chain_with_fallback = chain.with_fallbacks([RunnableLambda(lambda x: "sorry")])
result = chain_with_fallback.invoke("1") # 提示词模板中没有需要填充的变量,会报错
print(result) # sorry
Retrieval
3.1RAG
3.1.1 RAG介绍
为了改善大模型在时效性、可靠性与准确性方面的不足,各种针对 LLM 优化的方法应运而生。RAG(Retrieval-Augmented Generation,检索增强生成)就是其中一种被广泛研究和应用的优化架构。
RAG 的基本思想为:将传统的生成式大模型和实时信息检索技术相结合,为大模型补充来自外部的相关数据和上下文,来帮助大模型生成更加准确可靠的内容。这使得大模型在生成内容时可以依赖实时与个性化的数据和知识,而非仅仅依赖训练知识。就相当于在大模型回答时给它一本参考书。
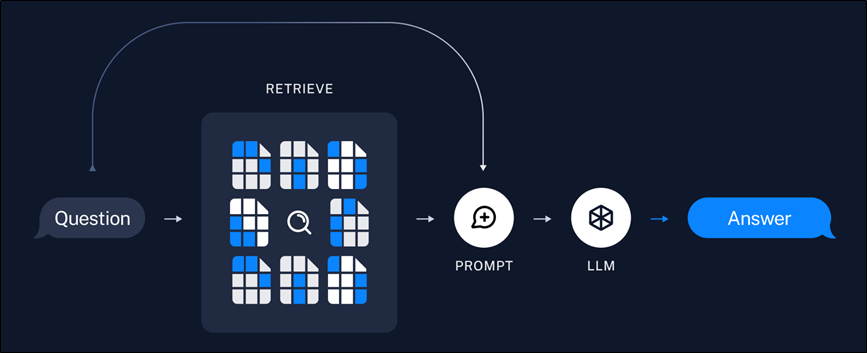
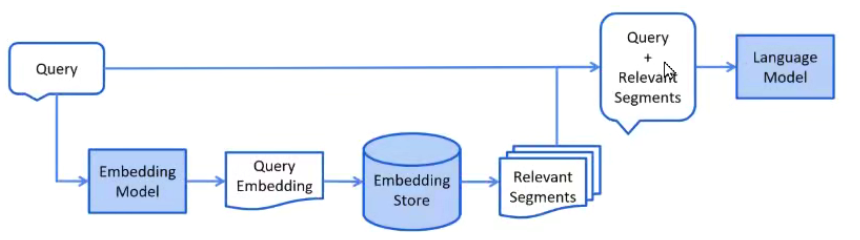
3.1.2 RAG流程
典型的RAG有两个主要流程:
- 索引:从数据源提取数据,构建索引。
- 检索生成:接受用户查询并从索引中检索相关数据,然后将其传递给模型。。
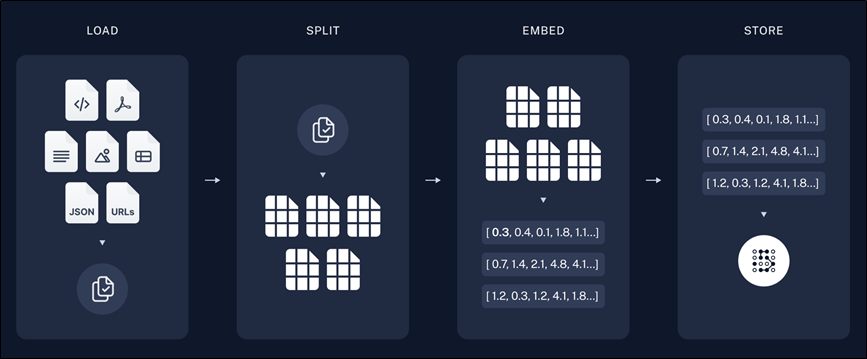
- 索引阶段:
- 从各种数据源加载数据️
- 将文档切分为小块️
- 对文本块进行嵌入️
- 存储嵌入向量。
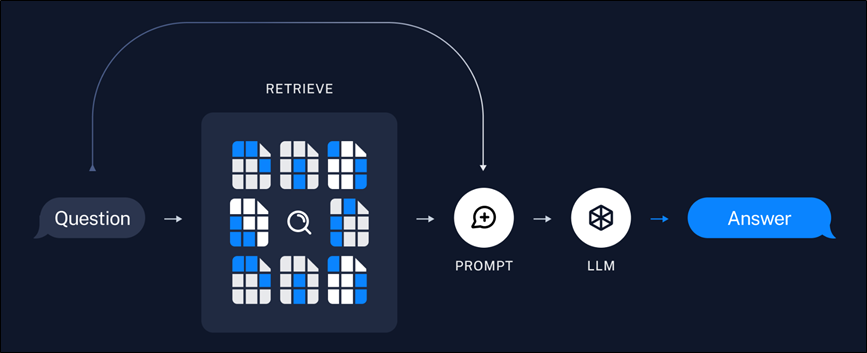
- 检索生成阶段:
- 根据用户输入,使用检索器从存储中检索相关文本块➡️
- 大模型使用包含问题和检索结果的提示生成回答。
3.2 文档加载
数据源可能包含多种格式的文件,如文本文档、Markdown,PDF 等。因此我们首先需要对各种格式的文件进行处理。LangChain 实现和集成了众多文档加载器,方便从不同格式的文件中加载数据。
LangChain 所有文档加载器都实现了 BaseLoader 接口,接口提供了通用的 load(一次加载所有文档)与lazy_load(以延迟方式加载文档)方法,用于从数据源加载数据并处理为 Document 对象。
LangChain 实现了 Document 抽象,用于表示文本单元及其元数据,它包含三个属性:
- page_content:文本内容字符串。
- metadata:包含元数据的字典,如文档的来源等。
- id:可选,文档标识符。
3.2.1 加载TXT
# pip install langchain_community
from langchain_community.document_loaders import TextLoader
docs = TextLoader(
file_path="assets/sample.txt", # 文件路径
encoding="utf-8", # 文件编码方式
).load() # 返回List[Document]
print(docs)
# [Document(metadata={'source': 'asset/sample.txt'}, page_content='...')]
3.2.2 加载CSV
from langchain_community.document_loaders.csv_loader import CSVLoader
# 加载所有列
docs = CSVLoader(
file_path="assets/sample.csv", # 文件路径
).load() # 返回List[Document]
print(docs)
# 加载部分列
docs = CSVLoader(
file_path="assets/sample.csv", # 文件路径
metadata_columns=["title", "author"], # 将指定列作为元数据
content_columns=["content"], # 将指定列作为内容
).load() # 返回List[Document]
print(docs)
3.2.3 加载JSON
LangChain 实现了 JSONLoader,用来将 JSON 和 JSONL 数据转换为 LangChain 文档对象。它使用指定的 jq 模式来解析 JSON 文件,从而将特定字段提取到 LangChain 文档的内容和元数据中。
如果要从 JSON Lines 文件加载文档,需传递 json_lines=True。
from langchain_community.document_loaders import JSONLoader
# 提取所有字段
docs = JSONLoader(
file_path="assets/sample.json", # 文件路径
jq_schema=".", # 提取所有字段
# jq_schema=".data.items[]", # 提取data.items中的数据
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)
3.2.4 加载HTML 网页
import bs4
from langchain_community.document_loaders import WebBaseLoader
docs = WebBaseLoader(
# 网址序列
web_paths=("https://baike.baidu.com/item/%E5%BE%AE%E6%B3%A2%E7%82%89/84186",),
# 传给 BeautifulSoup 的解析参数,parse_only 表示只提取指定标签的元素
bs_kwargs={"parse_only": bs4.SoupStrainer(class_="J-lemma-content")},
).load()
print(docs)
3.2.5 加载Markdown
可以使用Unstructured 文档加载器来加载多种类型的文件。可使用 UnstructuredMarkdownLoader 加载 Markdown 文件,需要unstructured 包。
# pip install langchain_community unstructured[md]
from langchain_community.document_loaders import UnstructuredMarkdownLoader
docs = UnstructuredMarkdownLoader(
# 文件路径
file_path="assets/sample.md",
# 加载模式:
# single 返回单个Document对象
# elements 按标题等元素切分文档
mode="elements",
).load()
print(docs)
3.2.6 加载Doc/Docx
# pip install langchain_community unstructured[docx]
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
docs = UnstructuredWordDocumentLoader(
# 文件路径
file_path="assets/sample.docx",
# 加载模式:
# single 返回单个Document对象
# elements 按标题等元素切分文档
mode="single",
).load()
print(docs)
3.2.7 加载PDF
1)PyPDFLoader
# pip install langchain_community
from langchain_community.document_loaders import PyPDFLoader
docs = PyPDFLoader(
# 文件路径,支持本地文件和在线文件链接,如"https://arxiv.org/pdf/alg-geom/9202012"
file_path="assets/sample.pdf",
# 提取模式:
# plain 提取文本
# layout 按布局提取
extraction_mode="plain",
).load()
print(docs)
2)UnstructuredPDFLoader
UnstructuredPDFLoader是对 unstructured 库的封装。支持布局识别与 OCR 提取文字。使用UnstructuredPDFLoader,需要先下载Poppler和Tesseract OCR。
# pip install unstructured[local-inference]
from langchain_community.document_loaders import UnstructuredPDFLoader
docs = UnstructuredPDFLoader(
file_path="assets/sample.pdf", # 文件路径
# 加载模式:
# single: 返回单个Document对象
# elements: 按标题等元素切分文档
mode="elements",
# 加载策略:
# fast: pdfminer 提取并处理文本
# ocr_only: 转换为图片并进行 OCR
# hi_res: 识别文档布局,将OCR 输出与 pdfminer 输出融合
strategy="hi_res",
# 推断表格结构:仅 hi_res 下起效,如果为 True 则会在表格元素的元数据中添加 text_as_html
infer_table_structure=True,
# OCR 使用的语言: eng 英文,chi_sim 中文简体。语言列表参考 https://github.com/tesseract-ocr/langdata
languages=["eng", "chi_sim"],
# 更多参数详见 https://github.com/Unstructured-IO/unstructured/blob/main/unstructured/partition/pdf.py
).load()
print(docs)
3.3 文档切分
3.3.1 切分策略
- 按照固定字符数或Token 数来切分,但可能会在不适当的位置切断句子。
- 递归使用多个分隔符**切分,**同时尽量保证字符数或 Token 数不超出限制。能保证不切断完整的句子。
- **语义切分:**根据文本的语义内容切分,旨在保持相关信息的集中和完整,适用于需要高度语义保持的场景。但处理速度较慢,且可能出现不同块之间长度极不均衡的情况。具体切分过程为:将相邻的几个句子拼成一个句组。对所有句组进行嵌入,并比较嵌入向量的距离,找到语义变化大的位置,根据阈值确定切分点(比如计算相邻句子嵌入向量的余弦距离,取距离分布的第N 百分位值作为阈值,高于此值则切分)。按照切分点切分出若干个语义段,并合并某些长度很短的语义段。
3.3.2 RecursiveCharacterTextSplitter
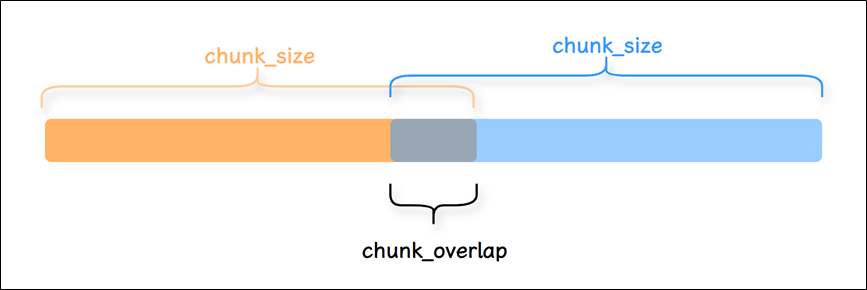
RecursiveCharacterTextSplitte_(递归字符文本切分器)是最常用的切分器_,它由一个字符列表作为参数,默认列表为 [“\n\n”, “\n”, " ", “”],并且会尝试按顺序使用这些字符进行切分,直到块足够小。由此尽可能地将所有段落(然后是句子,最后是词)保持在一起,因为这些段落通常看起来是语义上最相关的文本片段。
同时为了保证段之间语义完整,可以设置每个块之间有一部分重叠。
# pip install langchain-text-splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 加载文档
docs = UnstructuredWordDocumentLoader(
file_path="assets/sample.docx", mode="single"
).load()
# 切分为文本块
chunks = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", "……", ",", ""], # 分隔符列表
chunk_size=400, # 每个块的最大长度
chunk_overlap=50, # 每个块重叠的长度
length_function=len, # 可选:计算文本长度的函数,默认为字符串长度,可自定义函数来实现按 token 数切分
add_start_index=True, # 可选:块的元数据中添加此块起始索引
).split_documents(docs)
print(chunks)
3.4 文档嵌入
使用嵌入模型生成文档的嵌入向量,后续检索时用于与查询的嵌入向量进行相似度计算。
常用嵌入模型:
| 模型 | 机构 | 描述 |
|---|---|---|
| bge-large-zh | 北京智源研究院(BAAI) | 开源,向量维度1024,序列长度512 |
| bge-base-zh | BAAI | 开源,向量维度768,序列长度512 |
| bge-small-zh | BAAI | 开源,向量维度512,序列长度512 |
| bge-m3 | BAAI | 开源,多语言,向量维度1024,序列长度8192 |
| text-embedding-3-small | OpenAI | 多语言,向量维度1536,序列长度8192 |
| text-embedding-3-large | OpenAI | 多语言,向量维度3072,序列长度8192 |
# pip install sentence-transformers langchain_huggingface
import os
from langchain_huggingface import HuggingFaceEmbeddings
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# 单文本嵌入
query = "你好,世界"
print(embed_model.embed_query(query))
# 多文本嵌入
docs = ["你好,世界", "你好,世界"]
print(embed_model.embed_documents(docs))
3.5 向量存储
3.5.1常用的向量数据库
LangChain提供了众多向量存储的集成,包括开源的_本地向量存储_与_云托管_的私有向量存储。并公开了一个标准接口,可以轻松地在向量存储之间进行交换。
| 向量数据库 | 描述 |
|---|---|
| FAISS | 一个用于高效相似性搜索和密集向量聚类的库 |
| Chroma | 开源的轻量级向量数据库,有极简的 API |
| Milvus | 开源的专为向量搜索设计的云原生数据库。性能强悍,功能丰富。覆盖轻量级的原型开发到十亿级向量的大规模生产系统 |
| Pgvector | 开源关系型数据库PostgreSQL 的扩展,为PostgreSQL增加了向量数据类型和相似性搜索功能 |
| Redis | 开源内存数据结构存储,现已原生支持向量相似性搜索功能 |
| Elasticsearch | 开源分布式搜索和分析引擎,提供了一个基于文档的数据库,结构化、非结构化和向量数据通过高效的列式存储统一管理 |
3.5.2 Milvus
Milvus 通过数据库—Collections—实体的结构管理数据。Collections 和实体就类似关系型数据库中的表和记录。具体来说,Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。
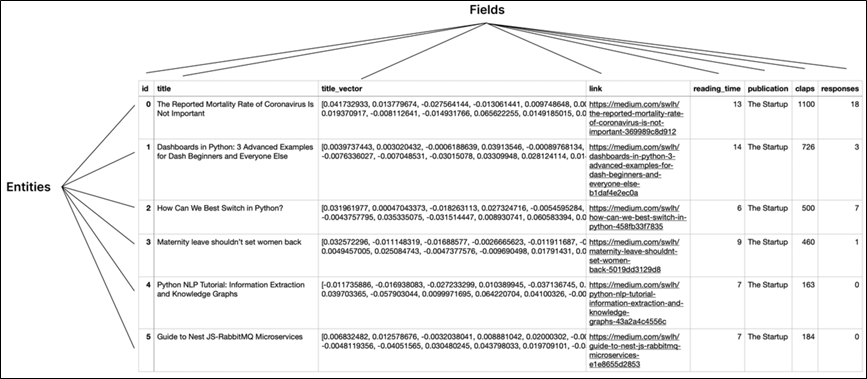
Collection 通过Collection Schema 来定义有哪些字段以及字段的类型、索引等。一个 Collection Schema 有一个主键、最多四个向量字段和若干标量字段。
主键用于唯一标识一个实体,只接受Int64 或VarChar 值。插入实体时,默认情况下应包含主键值。但是,如果在创建 Collections 时启用了AutoId,Milvus 将在插入数据时生成主键值,此时插入的实体中不应包含主键值。
向量字段用于存储文本、图像和音频等非结构化数据类型的嵌入,可以是密集向量、稀疏向量或二进制向量。通常,密集向量用于语义搜索,而稀疏向量则更适合全文或词性匹配。
标量字段通常用来存储一些元数据,并可以在搜索时通过元数据进行过滤,以提高搜索结果的正确性。
| 字段类型 | 字段 | 描述 | |
|---|---|---|---|
| 向量字段 | 密集向量 | FLOAT_VECTOR | 32位浮点数列表 |
| FLOAT16_VECTOR | 16位半精度浮点数列表 | ||
| BFLOAT16_VECTOR | 16位浮点数列表,精度稍低,但指数范围与 Float32 相同 | ||
| INT8_VECTOR | 8位有符号整数向量 | ||
| 稀疏向量 | SPARSE_FLOAT_VECTOR | 非零数字及其序列号列表 | |
| 二进制向量 | BINARY_VECTOR | 一个0和1的列表 | |
| 标量字段 | VARCHAR | 字符串 | |
| BOOL | 存储true或false | ||
| INT | INT8、INT16、INT32、INT64 | ||
| FLOAT | 32位浮点数 | ||
| DOUBLE | 64位双精度浮点数 | ||
| ARRAY | 相同数据类型元素的有序集合 | ||
| JSON | 结构化的键值数据 |
索引是建立在数据之上的附加结构,可以加快搜索速度。不同字段数据类型适用不同的索引类型。比如FLOAT_VECTOR 可使用 HNSW(分层导航小世界)索引,VARCHAR 可使用INVERTED(反转)索引。
3.5.3 创建Collection
# pip install pymilvus[milvus_lite]
from pprint import pprint
from pymilvus import MilvusClient, DataType
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 创建 schema
def build_schema():
return (
MilvusClient.create_schema(
# 自动分配主键
auto_id=True,
# 启用动态字段,未在 Schema 中声明的字段会以键值对的形式存储在这个动态字段
enable_dynamic_field=True,
)
# 添加 id 字段,类型为整数,设置为主键
.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
# 添加 vector 字段,类型为浮点数向量,维度为 768
.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=768)
# 添加 text 字段,类型为字符串,最大长度为 1024
.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1024)
# 添加 metadata 字段,类型为 JSON
.add_field(field_name="metadata", datatype=DataType.JSON)
)
# 创建 index
def build_index():
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="vector", # 建立索引的字段
index_type="AUTOINDEX", # 索引类型
metric_type="L2", # 向量相似度度量方式
)
return index_params
# 创建 collection
if client.has_collection(collection_name="demo_collection"):
# 删除 collection
# 在 Milvus 中删除数据后,存储空间不会立即释放。虽然删除数据会将实体标记为 "逻辑删除",但实际空间可能不会立即释放。
# Milvus 会在后台自动压缩数据。这个过程会将较小的数据段合并为较大的数据段,并删除"逻辑删除"的数据或已超过有效时间的数据。
# 一个名为 Garbage Collection (GC) 的独立进程会定期删除这些 "已删除 "的数据段,从而释放它们占用的存储空间。
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection", # collection 名称
schema=build_schema(), # collection 的 schema
index_params=build_index(), # collection 的 index
)
# 查看 collection
print(client.list_collections())
# 查看 collection 描述
pprint(client.describe_collection(collection_name="demo_collection"))
3.5.4 操作实体
1)插入实体
from pymilvus import MilvusClient
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 加载文档
docs = UnstructuredWordDocumentLoader(
file_path="assets/sample.docx",
mode="single",
).load()
# 文档切分
chunks = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", "……", ",", ""],
chunk_size=400,
chunk_overlap=50,
).split_documents(docs)
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# 计算嵌入向量
embeddings = embed_model.embed_documents([chunk.page_content for chunk in chunks])
# 转换数据格式
data = [
{
"vector": embedding,
"text": chunk.page_content,
"metadata": chunk.metadata,
}
for chunk, embedding in zip(chunks, embeddings)
]
# 插入实体
res = client.insert(collection_name="demo_collection", data=data)
print(res)
2)查询实体
from pymilvus import MilvusClient
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 通过主键查询实体
res = client.get(
collection_name="demo_collection",
ids=[461484610130804912, 461484610130804913],
output_fields=["text", "metadata"],
)
print(res)
# 通过过滤条件(https://milvus.io/docs/zh/boolean.md)查询实体
res = client.query(
collection_name="demo_collection",
filter='metadata["source"] == "assets/sample.docx"', # 使用 metadata["source"] 进行过滤
output_fields=["text", "metadata"],
limit=1,
)
print(res)
3)删除实体
from pymilvus import MilvusClient
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 通过主键删除实体
res = client.delete(
collection_name="demo_collection",
ids=[461484610130804912, 461484610130804913],
)
print(res)
# 通过过滤条件(https://milvus.io/docs/zh/boolean.md)删除实体
res = client.delete(
collection_name="demo_collection",
filter='text LIKE "第%"', # 使用 text 前缀过滤
)
print(res)
3.6 检索与生成
3.6.1 检索
检索阶段:用户输入查询➡️计算嵌入向量➡️在向量存储中检索相似向量➡️返回相似向量对应的内容。
def retrieval(query, embed_model, client):
"""检索并返回上下文"""
query_embedding = embed_model.embed_query(query) # 查询嵌入
context = client.search(
collection_name="demo_collection", # collection 名称
data=[query_embedding], # 搜索的向量
anns_field="vector", # 进行向量搜索的字段
# 度量方式:L2 欧氏距离/IP 内积/COSINE 余弦相似度
search_params={"metric_type": "L2"},
output_fields=["text", "metadata"], # 输出字段
limit=3, # 搜索结果数量
)
return context
context = retrieval("不动产被占有了怎么办?", embed_model, client)
print(context)
3.6.2 生成
# ========== 生成 ==========
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
template = ChatPromptTemplate.from_messages(
[
(
"system",
"# 任务\n\n根据上下文参考,回答用户的问题。\n\n# 上下文参考\n\n{context}",
),
("human", "{query}"),
]
)
rag_chain = (
{
"query": RunnablePassthrough(),
"context": lambda x: retrieval(query=x, embed_model=embed_model, client=client),
}
| RunnableLambda(lambda x: print(x) or x) # 打印中间结果
| template
| llm
| StrOutputParser()
)
res_chunks = rag_chain.stream(input="不动产被占有了怎么办?")
for chunk in res_chunks:
print(chunk, end="", flush=True)
Agent
Agent介绍
通用人工智能(AGI)将是AI 的终极形态,几乎已成为业界共识。同样,构建Agent则是AI 工程应用当下的“终极形态”。
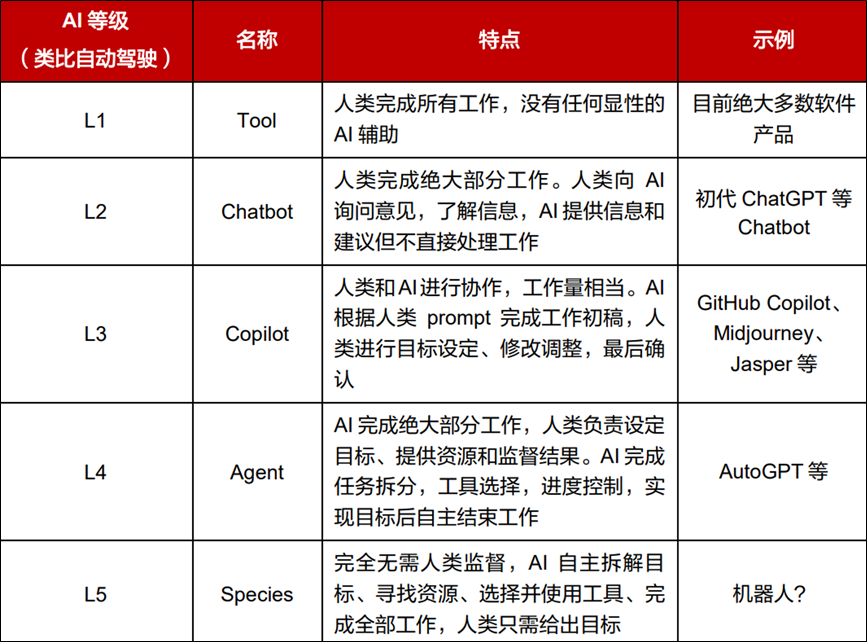
语言模型本身无法采取行动——它们只是输出文本。LangChain 的一个重要功能是创建Agent。Agent 是一种使用 LLM 作为推理引擎的系统,它决定要采取哪些行动以及这些行动的输入应该是什么。这些行动的结果可以反馈给 Agent,由 Agent 决定是否需要采取更多行动,或者是否可以完成。
与传统的固定流程链不同,Agent 具备一定的自主决策能力,更适合处理开放式、多步骤的问题。它可以拆解任务,根据任务动态决定调用哪些工具,并利用中间结果推进任务。
Agent 的核心能力/组件:
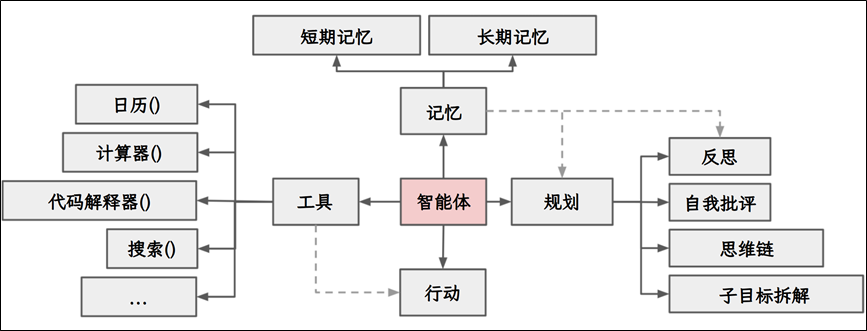
(1)大模型(LLM):作为大脑,提供推理、规划和知识理解能力。
(2)记忆(Memory):具备短期记忆和长期记忆,支持快速知识检索。
(3)工具(Tools):调用外部工具(如API、数据库)的执行单元。
(4)规划(Planning):任务分解、反思与自省框架实现复杂任务处理。
(5)行动(Action):实际执行决策的能力。
(6)协作:通过与其他Agent 交互合作,完成更复杂的任务目标。
Tools
工具封装了一个可调用函数及其输入模式。这些参数可以传递给兼容的聊天模型,从而允许模型决定是否调用工具以及调用哪些参数。在这种情况下,工具调用使模型能够生成符合指定输入模式的请求。
4.2.1.创建工具
一个Tool 通常包括工具名称,工具描述,以及工具参数的类型注解。
可以通过 @tool 装饰器来创建工具。
from langchain.tools import tool
@tool
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b
print(f"{add_number.name=}\n{add_number.description=}\n{add_number.args=}")
# add_number.name='add_number'
# add_number.description='两个整数相加'
# add_number.args={'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
from langchain.tools import tool
from pydantic import BaseModel, Field
class FieldInfo(BaseModel):
a: int = Field(description="第1个参数")
b: int = Field(description="第2个参数")
@tool(
name_or_callable="add_2_number",
description="计算两整数之和",
args_schema=FieldInfo, # 定义参数模式
)
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b
print(f"{add_number.name=}\n{add_number.description=}\n{add_number.args=}")
# add_number.name='add_2_number'
# add_number.description='计算两整数之和'
# add_number.args={'a': {'description': '第1个参数', 'title': 'A', 'type': 'integer'}, 'b': {'description': '第2个参数', 'title': 'B', 'type': 'integer'}}
4.2.2 绑定工具
要想让大模型能够使用工具,首先需要将工具给到大模型。
创建模型实例,并通过bind_tools 方法将工具绑定到大模型。
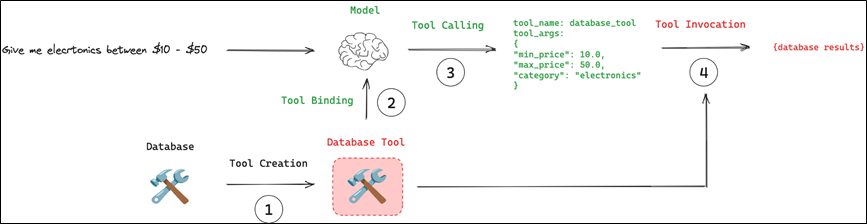
(1)大模型通过分析用户需求,判断是否需要调用工具。
(2)如果需要则在响应的_additional_kwargs_参数中包含工具调用的详细信息。
(3)使用模型提供的参数执行工具。
import os
from langchain.tools import tool
from langchain.chat_models import init_chat_model
@tool
def query_user_info(user_id: int) -> str:
"""查询用户信息"""
return {1001: "Jack", 1002: "Tom", 1003: "Alice"}[user_id]
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 为模型提供工具
tools = [query_user_info]
llm_with_tools = llm.bind_tools(tools)
resp = llm_with_tools.invoke("帮我查下1001用户的信息")
print(resp)
# content='\n\n我来帮您查询1001用户的信息。\n'
# additional_kwargs={'tool_calls': [{'id': '...', 'function': {'arguments': '{"user_id": 1001}', 'name': 'query_user_info'}
# 返回的响应中 additional_kwargs 参数中包括了工具调用的信息,此时还没有调用工具,只是返回了要调用的工具及参数
# 手动执行工具
for tool_call in resp.tool_calls:
tool_name = tool_call["name"] # 获取工具名称
tool_args = tool_call["args"] # 获取工具参数
tool_result = globals()[tool_name].invoke(tool_args) # 执行工具
print(tool_name, tool_args, tool_result)
构建Agent
使用 create_agent 来创建 Agent,create_agent 使用 LangGraph 构建基于图的 Agent运行时。此 Agent 会在一个循环中反复调用模型和工具,直到某次模型输出中不再包含工具调用则结束。
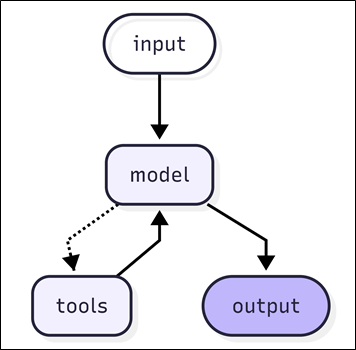
使用 create_agent 创建 Agent 时,需传入模型和工具、可选地也可以传入系统提示词。
这里使用Tavily(搜索引擎)作为工具,需要先获取它的API-Key 并添加到环境变量。
from langchain_tavily import TavilySearch
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
import dotenv
dotenv.load_dotenv()
llm = ChatOpenAI(
model='qwen-vl-plus'
)
search = TavilySearch(max_results=5)
tools=[search]
agent = create_agent(
model=llm,
tools=tools,
system_prompt="你是一名助手,需要调用工具来帮助用户解决问题。"
)
res=agent.invoke({
"messages": [
{"role": "user", "content": "重庆天气怎么样"}
]
})
print(res)
LangSmith
使用 LangChain 构建的许多应用程序都包含多个步骤,需要多次调用LLM。随着这些应用程序变得越来越复杂,能够检查链或 Agent 内部的具体情况变得至关重要。最好的方法是使用LangSmith。
注册LangSmith,在 Settings ➡️ API Keys 下创建 API-Key 并复制。之后在环境变量中添加以开始记录跟踪:
LANGSMITH_TRACING="true"
LANGSMITH_API_KEY="..."
配置好环境变量之后,可在 LangSmith 的Tracing Projects 中查看跟踪记录。
LangSmith默认将跟踪记录到default 项目,可通过LANGSMITH_PROJECT环境变量设置LangSmith跟踪记录保存到哪个项目,如果该项目不存在则会创建。
记忆
为了给代理添加短期记忆(线程级持久化),在创建代理时需要指定一个 checkpointer,并在调用代理时指定线程 ID。这个短期记忆的能力是借助 LangGraph 的状态和检查点实现的。
from langchain_tavily import TavilySearch
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
import dotenv
import datetime
dotenv.load_dotenv()
llm = ChatOpenAI(
model='qwen-vl-plus'
)
search = TavilySearch(max_results=5)
tools=[search]
agent = create_agent(
model=llm,
tools=tools,
checkpointer=InMemorySaver(),
# 需要给大模型提示使用工具
system_prompt="你是一名助手,需要调用工具来帮助用户解决问题。"
)
for chunk in agent.stream(
input={
'messages':[
{'role':'system','content': f"当前时间:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}",},
{'role':'user','content':'今天晚上重庆天气怎么样?'}
]
},
config={'configurable':{'thread_id':'1'}},
):
print(chunk,end='\n\n')
for chunk in agent.stream(
input={
"messages": [
{
"role": "system",
"content": f"当前时间:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}",
},
{"role": "user", "content": "上海呢?"},
]
},
config={"configurable": {"thread_id": "1"}},
):
print(chunk, end="\n\n")
MCP
Model Context Protocol(MCP,模型上下文协议)是一个开源协议,它标准化了大语言模型与外部工具和数据源通信的方式,允许开发者和工具提供商只需集成一次,就能与任何兼容 MCP 的系统交互。MCP 就像 USB-C 标准:不需要为每个设备使用不同的连接器,而是使用一个端口来处理多种类型的连接。
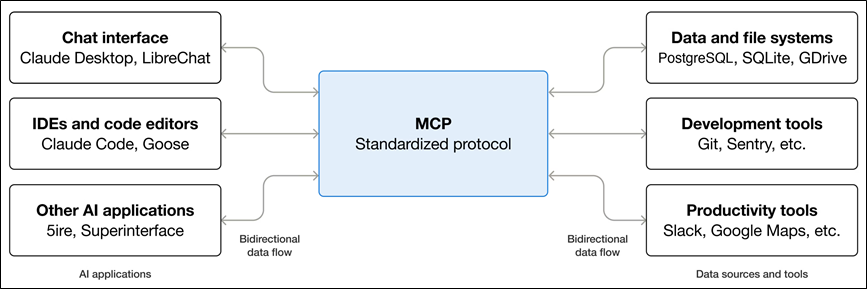
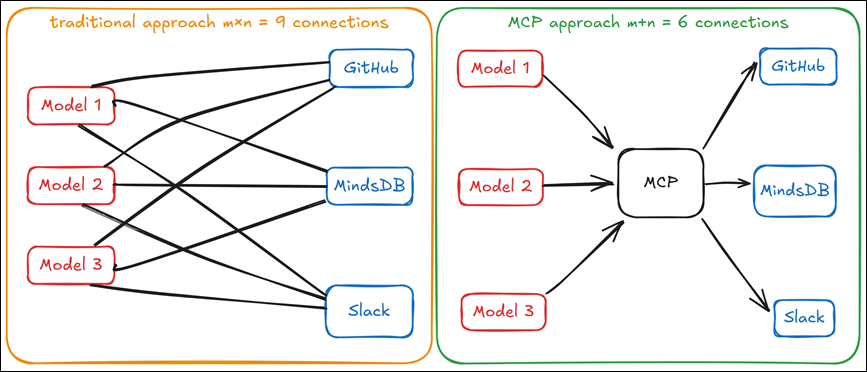
MCP 架构、
| MCP 主机 | 协调和管理一个或多个 MCP 客户端的 AI 应用 |
|---|---|
| MCP 客户端 | 一个保持与 MCP 服务器连接的组件,通过 MCP 定义的消息处理通信,从服务器查找并请求资源和工具,并管理与服务器的连接生命周期 |
| MCP 服务器 | 一个向 MCP 客户端提供服务的程序,通过协议暴露工具、资源和提示模板功能 |
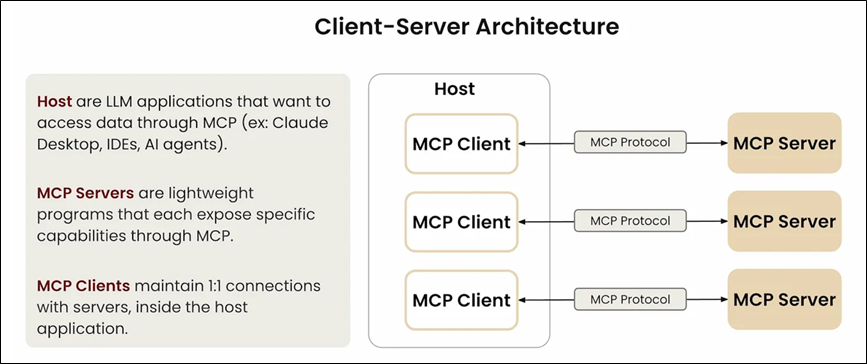
MCP 层级
MCP 分为两个层级:
(1)数据层
数据层实现了一个基于 JSON-RPC 2.0 的交换协议,该协议定义了消息结构和语义。
数据层包括生命周期管理(连接初始化、能力协商、连接终止)、服务器功能(提供工具、资源和提示模板)、客户端功能(调用LLM、获取输入、记录消息)、其他功能(实时更新通知、长时运行操作跟踪)。
(2)传输层
传输层定义了客户端与服务器之间数据交换的通信机制和通道,包括特定传输方式的连接建立、消息帧定界和授权。
MCP 支持多种传输机制,包括Stdio、Streamable HTTP、SSE。
| Stdio | 使用标准输入和输出流,与在终端输入命令并看到响应时使用的机制相同。适用于本地开发 |
|---|---|
| Streamable HTTP | 该传输使用 HTTP POST 和 GET 请求,服务器可以选择使用SSE来流式传输多个服务器消息。支持流式传输和服务器到客户端通知,并支持标准 HTTP 身份验证方法,包括授权令牌、API 密钥和自定义头信息 |
| SSE | 带有 SSE(Server-Sent Events 服务器发送事件)的 HTTP,MCP早期传输机制,现逐渐被 Streamable HTTP 取代 |
MCP 工作流程
(1)初始化
在初始化过程中,AI 应用程序的 MCP 客户端管理器连接到配置的服务器,并将它们的能力存储起来以供后续使用。应用程序使用这些信息来确定哪些服务器可以提供特定类型的功能(工具、资源、提示),以及它们是否支持实时更新。
初始化有几个重要的作用:
| 协议版本协商 | 确保客户端和服务器使用兼容的协议版本,避免因版本不一致导致的通信问题 |
|---|---|
| 能力发现 | 声明各自支持的功能,包括他们能够处理的基元类型(工具、资源、提示)以及是否支持通知等特性 |
| 身份交换 | 交换客户端与服务器的身份及版本信息,便于后续的调试与兼容性管理 |
(2)工具发现
AI 应用程序从所有连接的 MCP 服务器中获取可用工具,并将它们组合成一个语言模型可以访问的统一工具注册表。这使得 LLM 能够理解它可以执行哪些操作,并在对话期间自动生成相应的工具调用。
连接建立之后,客户端可以通过发送 tools/list 请求来发现可用的工具。这个请求是 MCP 工具发现机制的基础—它允许客户端在尝试使用工具之前了解服务器上有哪些可用的工具。响应包含一个 tools 数组,该数组提供了关于每个可用工具的全面元数据。这种基于数组的结构允许服务器同时展示多个工具,同时保持不同功能之间的清晰界限。响应中的每个工具包括几个关键字段:
| name | 工具标识符 |
|---|---|
| title | 工具的易读显示名称 |
| description | 工具描述 |
| inputSchema | 一个定义预期输入参数的 JSON Schema,支持类型验证并提供关于必需和可选参数的清晰文档 |
(3)工具执行
当语言模型在对话中决定使用工具时,AI 应用程序会拦截工具调用,将其路由到合适的 MCP 服务器,执行该工具,并将结果作为对话流程的一部分返回给 LLM。这使 LLM 能够访问实时数据并在外部世界中执行操作。
客户端使用 tools/call 方法执行一个工具。tools/call 请求遵循结构化格式,确保客户端和服务器之间的类型安全和清晰通信。请求结构包括几个重要组件:
| name | 工具标识符 |
|---|---|
| arguments | 包含工具的 inputSchema 定义的输入参数 |
响应返回一个内容对象数组,允许进行丰富、多格式的响应(文本、图片、资源等)。每个内容对象都有一个 type 字段。
(4)实时更新
MCP 支持实时通知,使服务器能够在未经明确请求的情况下通知客户端有关变更。当 AI 应用程序收到关于工具变更的通知时,它会立即刷新其工具注册表并更新 LLM 的可用功能。这确保了正在进行的对话始终能够访问最新的一组工具,并且 LLM 可以随着新功能的可用而动态适应。
MCP SDK
Stdio 服务端与客户端
# pip add mcp
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
mcp = FastMCP("Demo")
# 为 MCP 实例添加工具
@mcp.tool()
def add(a: int, b: int) -> int:
return a + b
# 为 MCP 实例添加资源
@mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
# 为 MCP 实例添加提示词
@mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
if __name__ == "__main__":
mcp.run(transport="stdio")
# pip install mcp
import asyncio
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
async def stdio_run():
server_params = StdioServerParameters(
command="python",
args=["mcp_server_stdio.py"],
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# 初始化连接
await session.initialize()
# 获取可用工具
tools = await session.list_tools()
print(tools)
print()
# 调用工具
call_res = await session.call_tool("add", {"a": 1, "b": 2})
print(call_res)
print()
# 获取可用资源
resources = await session.list_resources()
print(resources)
print()
# 调用资源
read_res = await session.read_resource("greeting://default")
print(read_res)
print()
# 获取可用提示
prompts = await session.list_prompts()
print(prompts)
print()
# 调用提示
get_res = await session.get_prompt("greet_user", {"name": "Jack"})
print(get_res)
print()
asyncio.run(stdio_run())
Streamable HTTP 服务端与客户端
# pip add mcp
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
mcp = FastMCP("Demo")
# 为 MCP 实例添加工具
@mcp.tool()
def add(a: int, b: int) -> int:
return a + b
# 为 MCP 实例添加资源
@mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
# 为 MCP 实例添加提示词
@mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
if __name__ == "__main__":
# mcp.settings.host = "0.0.0.0"
# mcp.settings.port = 8888
mcp.run(transport="streamable-http") # 默认启动在 127.0.0.1:8000
# pip install mcp
import asyncio
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
async def streamablehttp_run():
url = "http://127.0.0.1:8000/mcp"
headers = {"Authorization": "Bearer sk-atguigu"}
async with streamablehttp_client(url, headers) as (read, write, _):
async with ClientSession(read, write) as session:
# 初始化连接
await session.initialize()
# 获取可用工具
tools = await session.list_tools()
print(tools)
print()
# 调用工具
call_res = await session.call_tool("add", {"a": 1, "b": 2})
print(call_res)
print()
# 获取可用资源
resources = await session.list_resources()
print(resources)
print()
# 调用资源
read_res = await session.read_resource("greeting://default")
print(read_res)
print()
# 获取可用提示
prompts = await session.list_prompts()
print(prompts)
print()
# 调用提示
get_res = await session.get_prompt("greet_user", {"name": "Jack"})
print(get_res)
print()
asyncio.run(streamablehttp_run())
将多个 Streamable HTTP 服务器挂载到 ASGI 服务器
ASGI(Asynchronous Server Gateway Interface)是 Python 的异步 Web 服务器接口标准,定义了服务器与应用之间的通信协议,支持异步调用,能够处理高并发和长连接。
可以使用 streamable_http_app 方法将 StreamableHTTP 服务器挂载到现有的 ASGI 服务器。这允许将 StreamableHTTP 服务器与其他 ASGI 应用程序集成。
# pip add mcp fastapi
import uvicorn
import contextlib
from fastapi import FastAPI
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
tool_mcp = FastMCP("tool server")
resource_mcp = FastMCP("resource server")
prompt_mcp = FastMCP("prompt server")
# 为 tool_mcp 实例添加工具
@tool_mcp.tool()
def add(a: int, b: int) -> int:
return a + b
# 为 resource_mcp 实例添加资源
@resource_mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
# 为 prompt_mcp 实例添加提示词
@prompt_mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
# 设置 MCP 的 HTTP 根路径
tool_mcp.settings.streamable_http_path = "/"
resource_mcp.settings.streamable_http_path = "/"
prompt_mcp.settings.streamable_http_path = "/"
# 创建一个组合生命周期来管理会话管理器
@contextlib.asynccontextmanager
async def lifespan(app: FastAPI):
async with contextlib.AsyncExitStack() as stack:
await stack.enter_async_context(tool_mcp.session_manager.run())
await stack.enter_async_context(resource_mcp.session_manager.run())
await stack.enter_async_context(prompt_mcp.session_manager.run())
yield
app = FastAPI(lifespan=lifespan)
# 挂载 MCP 服务器
app.mount("/tool", tool_mcp.streamable_http_app())
app.mount("/resource", resource_mcp.streamable_http_app())
app.mount("/prompt", prompt_mcp.streamable_http_app())
if __name__ == "__main__":
uvicorn.run(app)
客户端代码和之前一致,注意修改 URL 路径。
LangChain 使用 MCP
LangChain Agent 可以通过 langchain-mcp-adapters 包使用 MCP 服务器上定义的工具。
这里使用了如下工具,需要先在相关平台创建 API-Key 并添加到环境变量:
阿里云百炼:https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
Smithery:https://smithery.ai/server/@DeniseLewis200081/rail
import os
import asyncio
from urllib.parse import urlencode
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
import dotenv
dotenv.load_dotenv()
# 配置 MCP 客户端
mcp_client = MultiServerMCPClient(
{
"WebSearch": {
"transport": "streamable_http",
"url": "https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/mcp",
"headers": {"Authorization": f"Bearer {os.getenv('DASHSCOPE_API_KEY')}"},
}, # https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
"RailService": {
"transport": "streamable_http",
"url": f"{'https://server.smithery.ai/@DeniseLewis200081/rail/mcp'}?{urlencode({'api_key': os.getenv('SMITHERY_API_KEY')})}",
}, # https://smithery.ai/server/@DeniseLewis200081/rail
}
)
# 获取工具
tools = asyncio.run(mcp_client.get_tools())
llm=ChatOpenAI(
model='qwen3-vl-plus'
)
agent = create_agent(model=llm,tools=tools)
async def main():
async for chunk in agent.astream(
{
"messages": [
{"role": "system", "content": "你是位助手,需要调用工具来帮助用户。"},
{
"role": "user",
"content": "北京今天天气怎么样,要是还不错的话,帮我看看今天上海到北京的车票",
},
]
}
):
print(chunk, end="\n\n")
asyncio.run(main())
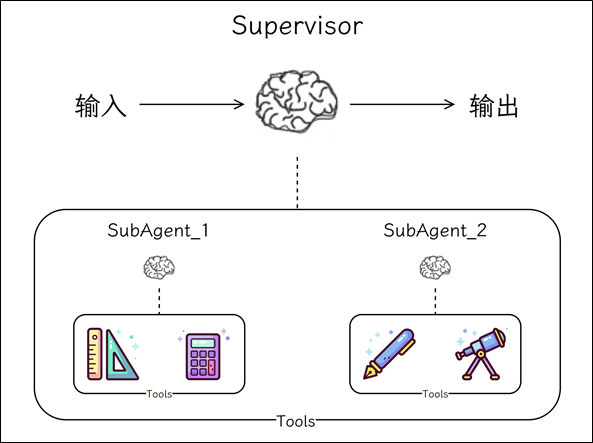
监督者模式多 Agnet 架构
监督者(主管)模式是一种多 Agnet 架构,其中中央主管 Agnet 负责协调各专业工作 Agnet 。当任务需要不同类型的专业知识时,这种方法非常有效。与其构建一个管理跨领域工具选择的 Agnet ,不如创建由了解整体工作流程的主管协调的、专注的专家。
在 LangChain 中可以将 Agent 封装为工具,将工具绑定到主管 Agent 来实现主管多代理模式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)