Towards Transferable Personality Representation Learning based onTriplet Comparisons and Its Applic
1 论文介绍
人格是心理学中的一个关键概念,它强调个体在思想、情感和行为方面的差异。
随着自然语言处理技术的发展,自动人格识别受到了广泛关注。因为其在心理健康评估、角色扮演以及个性化推荐系统等方面具有广泛应用。
现有方法:
为了在AI模型中表达人格,当前方法主要采用传统的监督学习范式。研究者会收集“语料-人格”数据集来训练预测模型。其中每个样本由多条句子组成,并被组织为一个“文本包(bag)”。人格标签以离散形式由人工进行标注。
这种学习方式带来了几个挑战:
- 数据收集困难:需要同一用户的大量语句,而这往往难以获取;
- 标注困难:在文本包层面进行细粒度标注对人工标注者来说非常困难;
- 应用困难:许多下游任务需要单句表示,这与文本包级方法并不匹配。
这些问题的本质在于:数据结构和学习方法都停留在“文本包级别”。转向单句级别可以显著促进数据规模扩展和任务迁移。
但这种转变面临两个关键障碍:
- 单句通常缺乏完整的人格信息,这使得准确标注变得困难。
- 像 BERT、GPT 这样的通用句子模型并非专门针对人格训练。大语言模型更适用于生成任务,而在检索和推荐任务中的应用仍需进一步研究。
于是本文提出了一种基于“三元组比较”的新任务范式。学习一个连续的人格嵌入空间,该空间能够反映人类的感知方式。
旨在学习一个反映人类感知的连续的人格嵌入空间,然后将其迁移到各种下游任务中。具体而言,当人类感觉两句话在人格特质上比第三句话更相似时,嵌入空间应该通过显示前两句话之间的距离比第三句话更近来反映这一点。
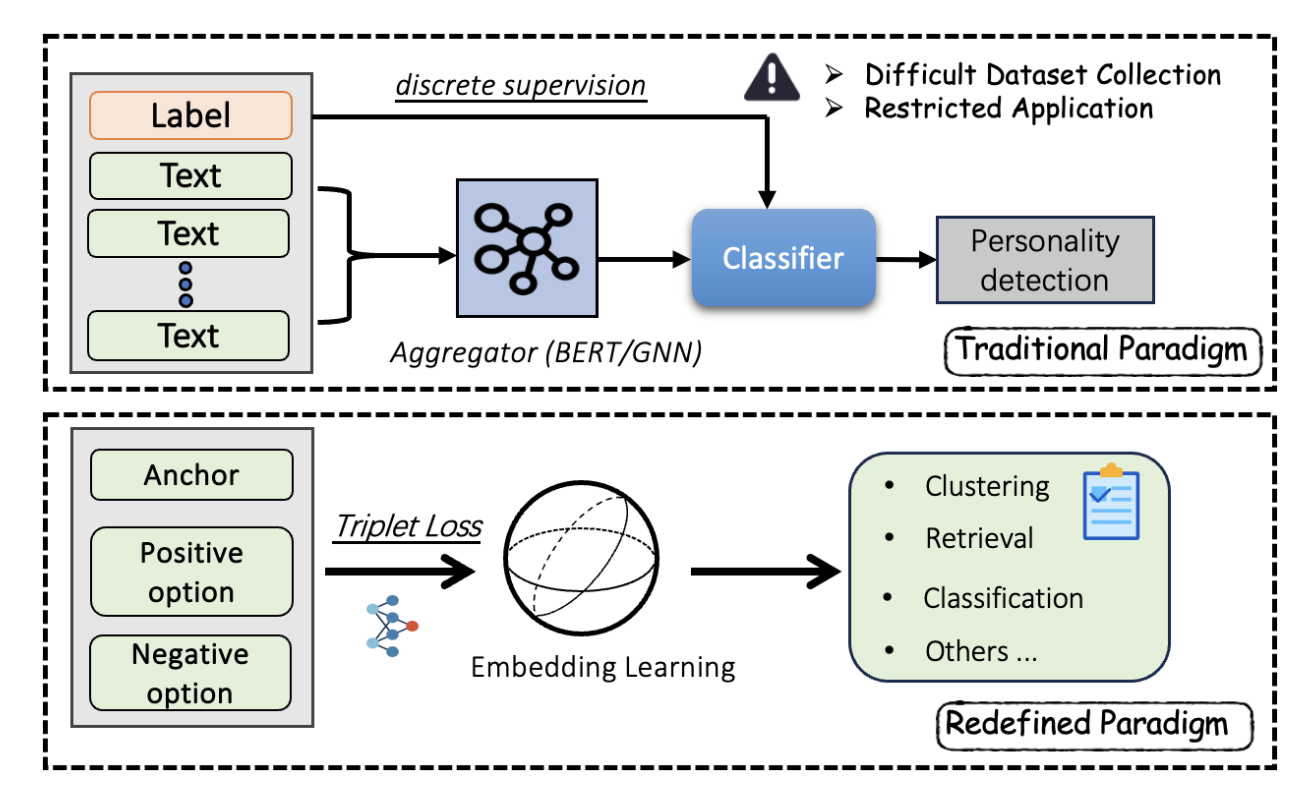
Tradictional Paradigm: 将一个人的所有话语打包成一个单元(
bag level),通过Aggregator (BERT/GNN)聚合特征,由人格标签label进行监督,输入Classifier得出人格分类结果。
Redefind Prardigm: 由
Anchor(锚点句)、Positive option(正样本,即性格相似的话)和Negative option(负样本,即性格不同的话)构成了三元组。通过中间的Triplet Loss(三元组损失函数),强制模型在向量空间中拉近相似性格的距离,推远不同性格的距离。获得了优质的单句向量表征后,就可以即插即用地去做
Clustering(聚类)、Retrieval(检索)和Classification(分类)等各种任务。
2 数据集构建
本文构建了一个多领域、高质量的三元组形式的“人格倾向比较数据集”(PTCD),以解决传统人格嵌入学习范式的局限性。
- 传统方式:收集 M 个人的语料库
,其中每个人 i 包含
句话。
- 本文方式:数据集定义了三元组
,其中锚点句
与正样本
共享上下文相似性,但与负样本
不同。这种范式通过比较性的三元组公式,克服了传统上需要大量单人语料的限制,从而实现了人格数据集的可扩展构建。
数据集的构建步骤
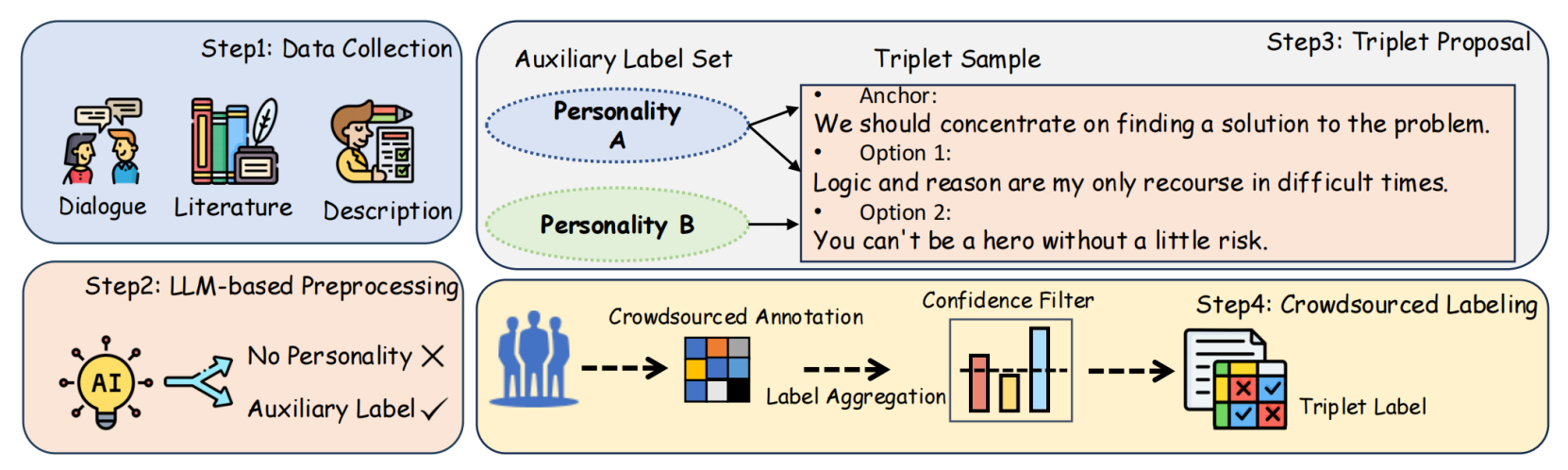
step 1: 数据收集
本文从三个不同领域收集了与人格相关的语料:Dialogue(社交媒体/直播对话)、Literature(文学/动漫游戏角色台词)和 Description(LLM生成的人格描述)
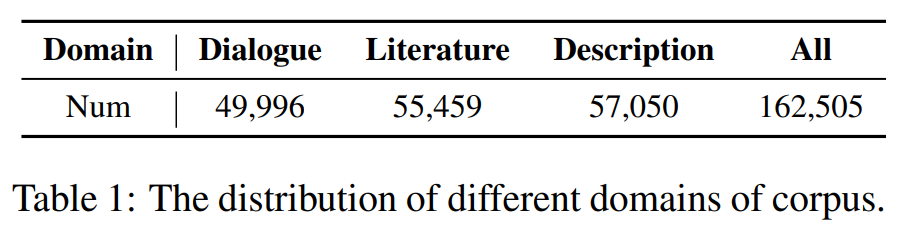
表1 展示了清洗后的基础语料底池大小。对话类 49,996 条,文学类 55,459 条,描述类 57,050 条,总计 162,505 条 (All)。
step 2: LLM 预处理
- 过滤掉缺乏人格相关信息的句子(例如,问候语或客套话)
- 基于 MBTI 体系为句子分配辅助标签(Big Five 同样适用),用于辅助构造triplet
step 3: 三元组生成
对于每个辅助标签 得到了句子集合
,其中辅助标签集合记为
。
- 从辅助标签
中随机选一个句子作为锚点句
- 分别从
(同标签集合)和
(其他所有标签的集合)中采样正样本
为了最大化样本多样性,所有随机选择都采用无放回抽样。此过程总共生成了 40,000 个三元组
从
Personality A集合中抽出两句话(Anchor 锚点 和 Option 1 正样本),它们性格相似;然后从另一个完全不同的集合Personality B中抽出一句话(Option 2 负样本)。
Anchor: 我们应该专注于寻找问题的解决方案。(偏理性/思考)
Option 1 (正样本): 逻辑和理性是我在困难时期的唯一依靠。(同样偏理性)
Option 2 (负样本): 不冒点险是成不了英雄的。(偏冲动/直觉,性格差异大)
step 4: 众包人工标注
- 每个三元组由5位标注者进行标注。
- 采用 Dawid-Skene 算法通过概率推断来解决标签分歧。
- 应用置信度阈值来过滤低质量的标注
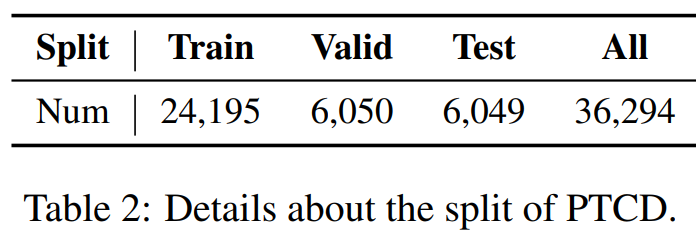
最终获得了 36,294 个具有高标注一致性的三元组,并按照约 8:1:1 的标准比例划分为了训练集 (Train: 24,195)、验证集 (Valid: 6,050) 和测试集 (Test: 6,049)
人格检测数据集 除了造出了创新的“三元组数据集”,他们在收集数据时也整理了一个传统的“包级别(Bag-level)”人物性格数据集(200个角色,每人200句话)。这个副产品由于数据源更丰富,比现有的推特/Reddit社交媒体数据集质量更高,可以作为未来同行研究的一个新 Benchmark(基准)
3 可度量嵌入学习
为了学习具有良好度量属性的单句人格表征,本文在 PTCD 数据集的基础上,使用预训练语言模型 BERT 通过三元组学习来进行“可度量嵌入学习”(MEL)
把“人格”变成一个可计算距离的向量空间
预训练设置
从三元组训练集中提取单句数据作为预训练数据 。论文采用主流方法中常用的掩码语言模型(MLM)进行预训练
把构建好的三元组里的句子全部“拆散”成一个个单句,然后使用经典的 MLM 任务让 BERT 先熟悉这些语料的说话方式,完成领域自适应(Domain Adaptation)
三元组学习
为了学习具有良好度量属性的表征,本文使用来自 PTCD 的带标签三元组进行训练 。对于单句话语 ,使用 BERT 作为编码器来获得相应的归一化特征
模型把输入的文本
转化为高维向量后,做了一步 Normalize(归一化)。这是对比学习中的常规且关键的操作,它将所有句子映射到一个高维单位球面上,排除了句子长度和绝对范数的影响,使得后续计算距离时更加纯粹地比较“方向”
给定一个三元组 ,目标是学习一组表征
,使得
和
之间的距离最小化,同时最大化它们与
的距离
其中 等于
和
之间的距离,
等于
和
之间的距离
由于这里使用的特征经过了归一化,本文直接使用 L2 距离(欧几里得距离)来计算距离 。margin(边界缓冲值)是一个控制损失约束严格程度的超参数 。较大的 margin 会导致更清晰的特征分离,但会使模型收敛变得更加困难 。
通过在三元组数据集上进行可度量嵌入学习得到人格编码器 ,解决了单句人格表征的问题 。利用其可迁移性,可以将其应用于各种下游任务 。
4 下游应用
4.1 人格识别任务
人格识别可以建模为一个多实例、多标签分类问题。
给定来自个体 的
句话的集合
目标是为给定的 预测
维的人格特征
对于 MBTI,人格有4个维度,每个维度是二分类。
[外向/内向, 感觉/直觉, 思考/情感, 判断/知觉]
本文方法中,首先训练一个编码器以获得可度量的人格表征 ,然后学习一个嵌入池化架构来进行分类任务,通过聚合这些向量得到最终人格预测。
。
置换不变池化 (PIP)
人格检测是一个多实例多标签学习任务,受到用户话语非结构化和可变性的挑战。对单句话语嵌入进行有效的池化需要:1. 置换不变性,以避免学习到无意的顺序依赖关系。2. 能够处理可变大小的输入。
如果我们用 RNN 或 LSTM 这种对序列顺序敏感的模型,模型可能会错误地去学习句子出现的先后顺序。因此,池化层必须忽略句子的输入顺序,这就叫“置换不变性”。同时,不同的人说的话数量不同,模型还需要能处理任意长度的句子集合。
受 Set Transformer 的启发,论文使用多头注意力模块(MAB)构建一个排列不变的解码器。
由于MBTI 分类有四个维度,论文设置了四个可学习的种子向量 ,结合多头注意力将特征聚合成四个池化输出。进一步使用 MAB 对这些池化输出进行建模,以确保置换不变性,最后输出4个向量,每个代表一个人格维度
分类层
以 MBTI 分类法为例,它由四个独立的二分类组成
论文设置了四个对应于每个 MBTI 维度的二分类头,每个分类头接收四个池化输出中的一个。将四个分类结果拼接起来,计算二元交叉熵损失(Binary Cross-Entropy Loss, BCE)
其中 是通过拼接四个二分类头的预测结果而获得的一个四维向量。
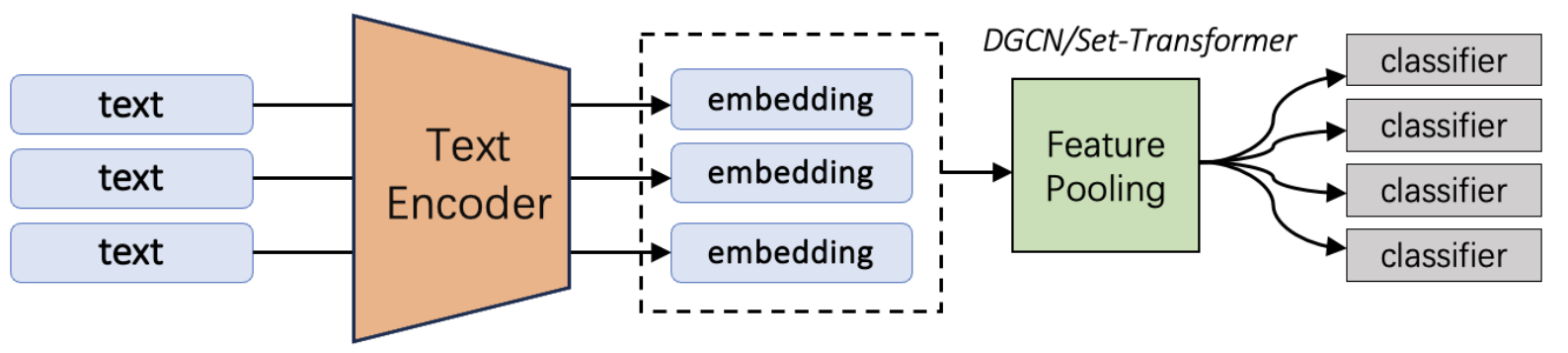
4.2 人格感知检索
人格感知检索是人格嵌入(表征)具有良好度量属性的直接应用 。
给定一个包含 n 句话的知识库 ,将每条语句编码为人格向量
对于查询语句 ,获取其对应的嵌入
计算 与知识库
中每个样本之间的 L2 距离
选取距离最小的 top-k 个样本作为检索结果。
这种检索过程可以应用于多智能体系统(multi-agent systems)的决策制定以及 NPC(非玩家角色)生成领域 。
针对角色扮演代理的基于检索的增强功能
确保角色扮演代理的对话与其预设人格一致是至关重要的
为了评估嵌入模型在角色扮演智能体中的有效性,论文调查了在引入“检索示例”前后智能体回复的变化,评估这些回复与角色人格的一致性 。
作者基于 CharacterEval 构建了一个数据集,该数据集保留了测试数据以及包含人格信息的角色描述 。一部分是角色的文字设定(用于生成 Query),另一部分是大量的候选台词库(用于被检索)。
三种方法对比:
-
Zero-Shot:使用 CharacterEval 的标准提示词直接生成回复,这是最原始的做法,就是直接给大模型发指令:“请扮演张三,你的性格是XXX,现在请回答...”。
-
Few-Shot (MLM+MLL):使用传统BERT模型检索相似对话作为示例。这是一种“平庸的检索”。用没有经过“三元组特训”的普通 BERT 去库里搜几个参考句子,丢给大模型模仿。
-
Few-Shot (Ours):这是本文的方案。用
模型算出性格最匹配的
句话,给大模型当参考。
使用了经典的 RAG(检索增强生成) 架构,使用 GPT-3.5 作为生成模型,GPT-4 作为评估模型。

现在,请扮演一名角色扮演专家。基于以下信息,扮演该角色进行对话,并严格遵守角色的特征。
{角色的背景设定}
以下是具有相似特征的文本样本供您参考:
{刚才通过 M_P 模型算出来最符合该性格的 N 句话}
{历史上下文}
4.3 情感转化预测
对话系统应当能够像人类一样,自动选择合适的情绪来生成回复。个体在情绪表达上的差异与人格特征密切相关。
现有对话系统通常依赖用户问卷或用户画像来获取人格信息。
作者通过将人格嵌入与情感转化模型相整合来解决这个问题,利用实时的人格信息来预测对对话上下文做出反应的情感 。
- 用户和对话系统之间的对话上下文
包含来自双方的 n 句话 。
是在
中表达的情感,
表示我们想要预测的回复情感 。
- 获取预训练的人格嵌入
,并将其纳入情感转化模型
的学习过程中:
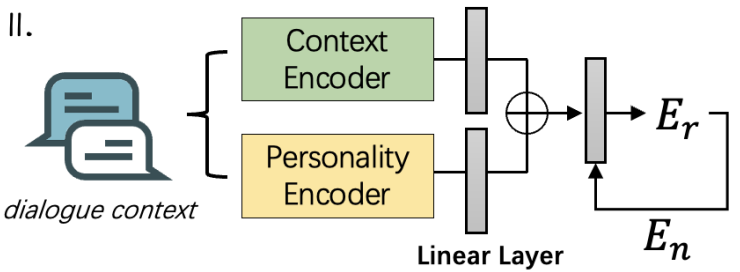
Context Encoder(绿色框):负责编码历史对话上下文

Personality Encoder(黄色框):负责处理公式中的
。使用论文的
Linear Layer(线性融合层):将“上下文情感信息”和“人格特征信息”拼接/相加,对应公式中的条件概率融合。
再拼接
(当前用户最后说的那句话的情感)
最终输出
:公式里的
5 实验
使用来自 (Wolf et al., 2019) 的预训练 bert-base-uncased BERT 模型作为主干模型。
数据集:
- PTCD 数据集
- Kaggle 数据集(MBTI 测试)
- Essays 数据集(大五人格测试)
在人格检测任务中,对各种方法进行了全面的比较。
- 传统的机器学习方法:LIWC+SVM、W2V+CNN。
- 深度学习方法:AttRCNN、DDGCN。
- 基于大型语言模型(LLM)的方法:TAE、PsyCoT。
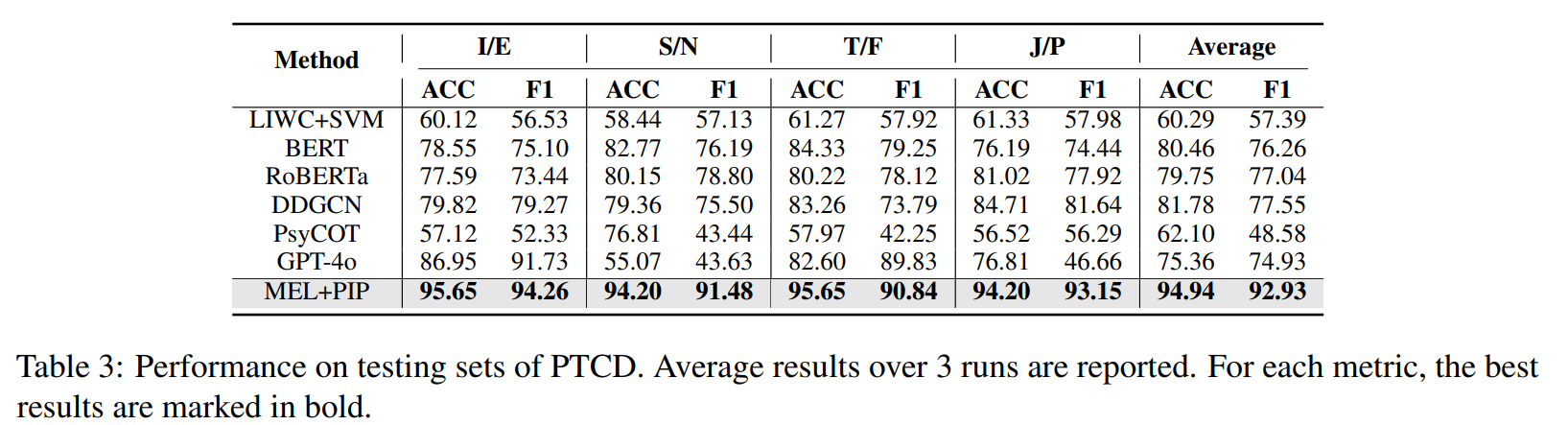
表 3 显示,将可度量嵌入学习与置换不变池化相结合的方法,在所有指标上都以相当大的优势超越了所有竞争方法,相比其他主流方法实现了 12% 的整体性能提升。
迁移到kaggle数据集中
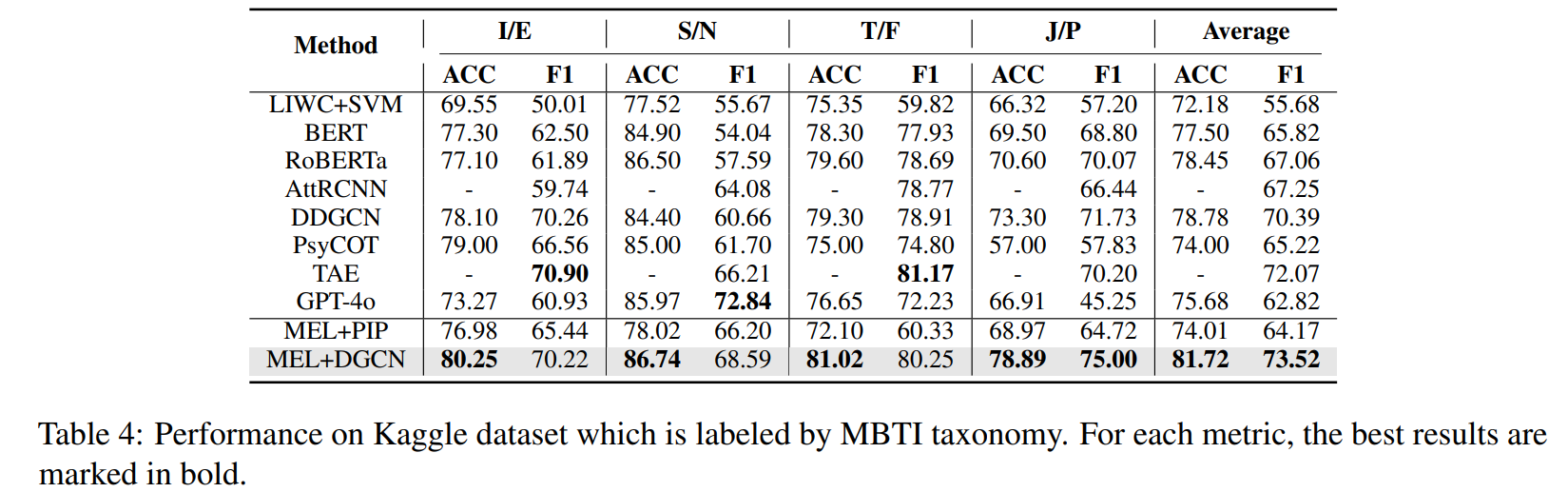
作者的方法(使用了动态图卷积网络聚合的 MEL+DGCN)依然拿下了 81.72 的最高平均准确率 (ACC) 和 73.52 的最高平均 F1 分数。
但可以看到 MEL+PIP 效果不是很好,作者在附录 A.5 中坦言,当面临**领域自适应(Domain Adaptation)**场景(比如将在 PTCD 数据集上训练的模型直接拿到 Kaggle 数据集上去测)时,只有两层的 PIP 架构“太简单了”,无法保持出色的性能。为了更好地捕捉不同语料库之间的复杂信息,作者引入了 DGCN。
基于训练好的人格表征,动态计算邻接图(adjacency graph),并使用 DGCN (Liu et al., 2020) 来完成特征的聚合 。
迁移到Essays数据集中
Essays数据集是基于大五人格(Big 5),与 MBTI 的四个维度不同
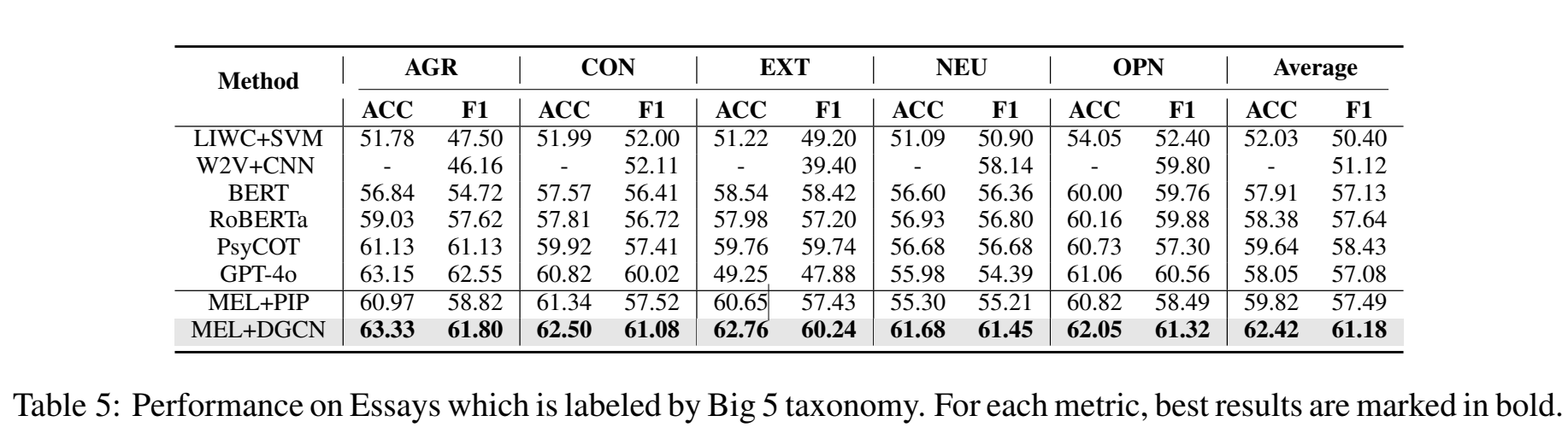
如表所示,MEL+DGCN 全面击败了专门针对问卷和心理学微调的大语言模型架构 PsyCoT以及强大的闭源大模型gpt-4o
情感分类任务
使用 RoBERTa 作为基线模型,使用 PELD (Wen et al., 2021)对话情感数据集,包含 6,510 个带有情感标签的日常对话三元组。
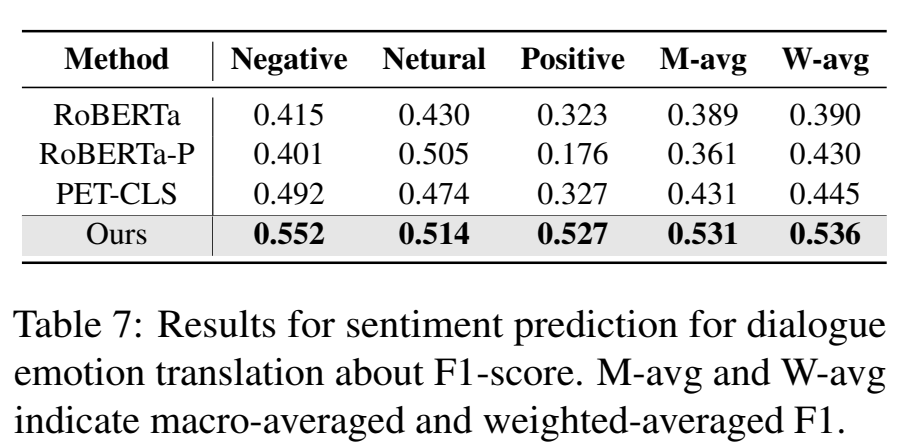
表 7 考察了模型在预测 Negative(负面)、Neutral(中立)、Positive(正面)三种情绪上的 F1 分数,并给出了 M-avg(宏平均 F1,Macro-averaged) 和 W-avg(加权平均 F1,Weighted-averaged) 两个综合指标
如表所示,将之前用 Triplet Loss 训练好的 模型提取出的单句“人格向量”,作为一个额外的特征拼接到原网络后,M-avg 提升到了 0.531,W-avg 提升到了 0.536
基于相似度的人格检索任务
将 PTCD 数据集的测试集拆分为单句,作为知识库。
对于给定的查询(query),我们使用训练好的编码器获取相应的嵌入,并计算与知识库中嵌入的余弦相似度,从而选择出前 N 个最相似的话语。
使用 MLM+MLL(掩码语言模型(MLM)和多标签学习(MLL) )训练的 BERT作为对比
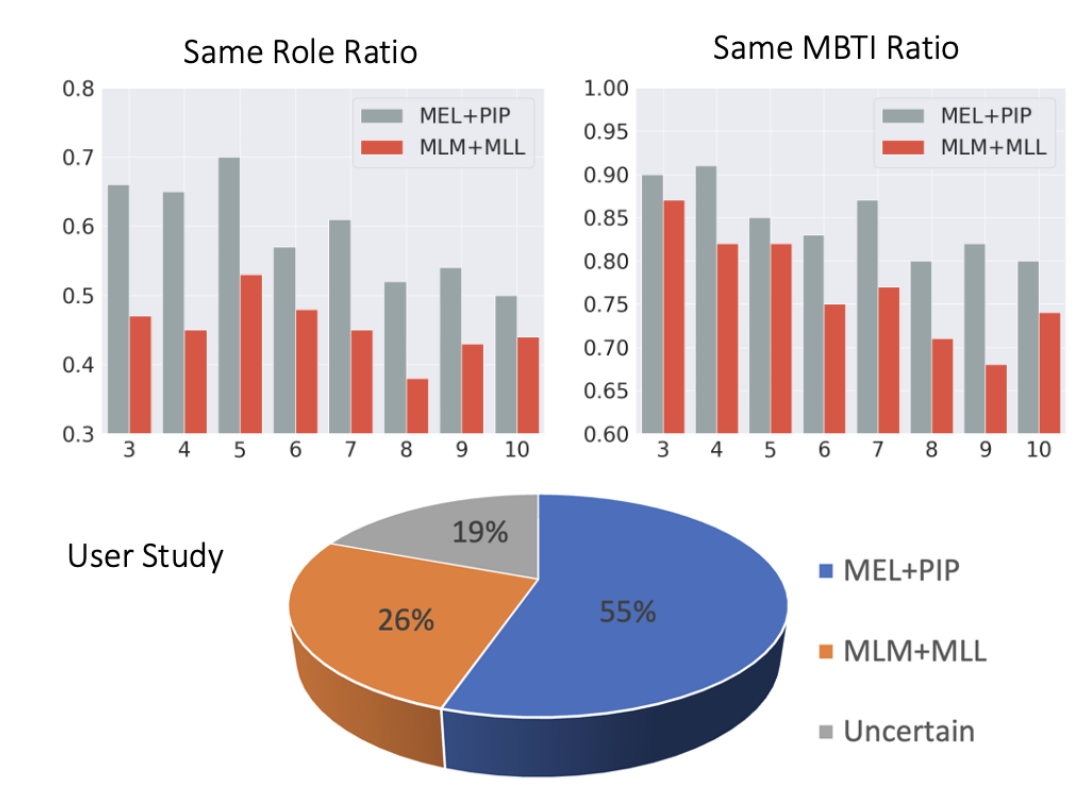
客观评估(Same Role Ratio(同角色比例) 和 Same MBTI Ratio(同 MBTI 比例)):
测试检索结果中属于“相同或相似人格”的比例。
使用知识库中经典角色的话语作为输入,并测试检索出的 个相似话语中属于相同或相似人格的比例。
横坐标是检索出的句子数量,从图中可以看出MEL+PIP的方法再所有数量上都高于MLM+MLL的方法,这证明了该模型找出来的句子,在性格内核上高度一致。
主观指标
作者通过众包平台邀请40名标注者进行评估,判断哪种方法检索的内容更像查询句的人格。
如饼图所示,本文方法 MEL+PIP 有55%的支持率,而传统的 MLM+MLL 只有 26% 的支持率
6 讨论
目前还没有现成可用的人格 embedding 方法。因此作者在下游任务中,将该方法与其他常见的深度学习方法以及文本嵌入大语言模型(text-embedding LLM)的性能进行了比较。
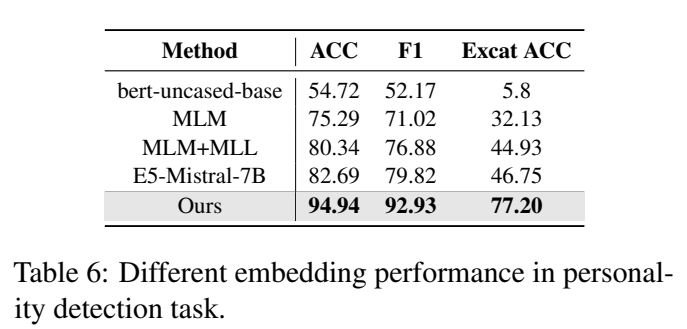
本文提出的方法(基于参数量极小的 BERT 架构)达到了 94.94 的 ACC 和 77.20 的精确匹配率(Exact ACC)。这说明在心理学和人格感知这个极其垂直的领域,“领域专有训练(三元组对比学习)”的收益,远远大于单纯依靠大模型增加参数规模
三元组预测
评估人格表示的“度量性质”,在“三元组选择任务”上比较不同模型。
给模型三元组(anchor, candidate1, candidate2)
选择哪个与 anchor 更相似?
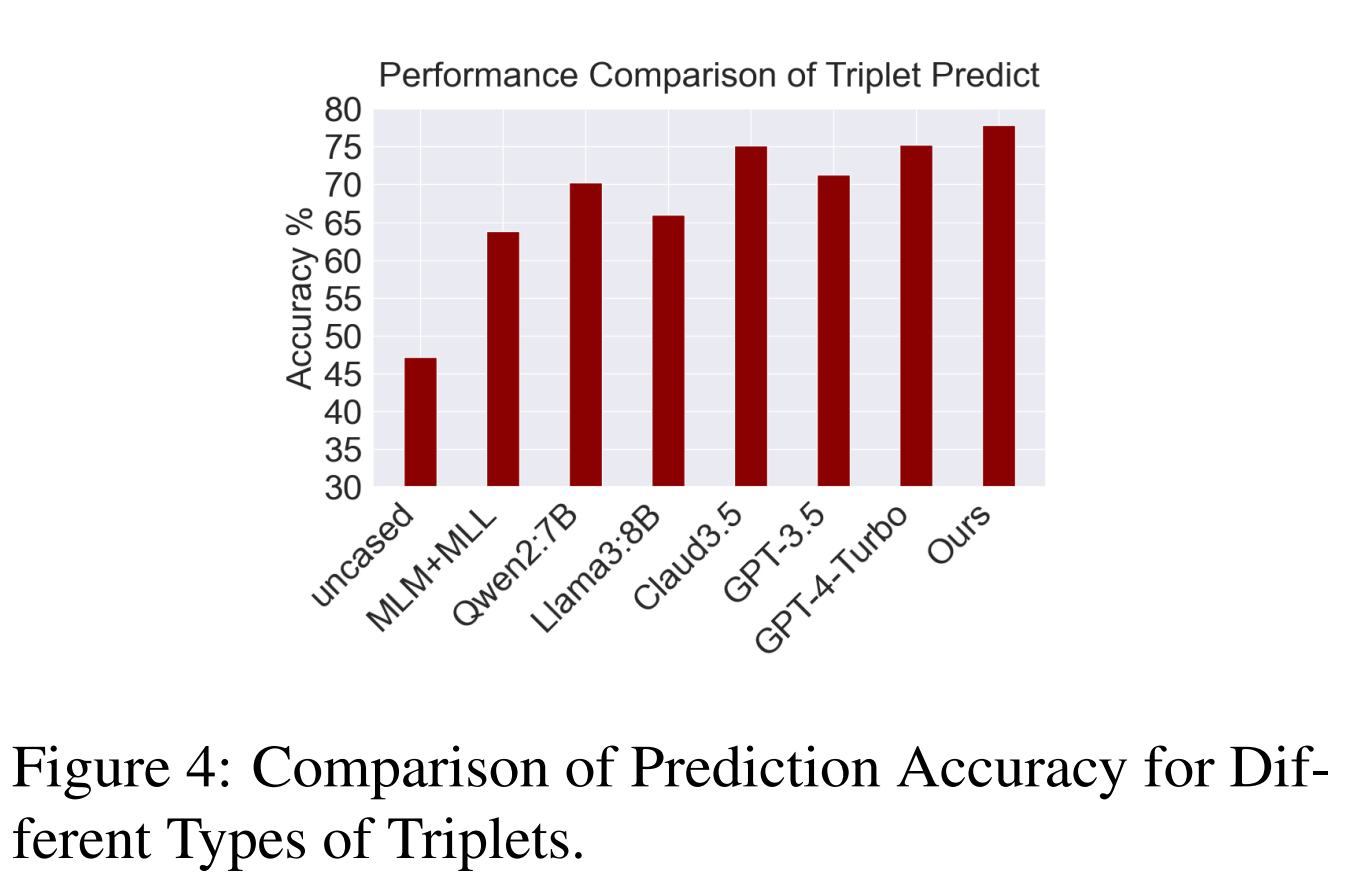
使用了未经过特定微调的 BERT-base-Chinese 模型、使用MLM和多标签学习训练的 BERT 模型、开源大语言模型以及闭源模型来进行比较
从图中可以看到,大模型在该任务上优于传统深度学习方法,而本文的方法超过了所有主流闭源大模型。说明 triplet learning 在人格感知方面效果显著
7 结论
本文提出了一种新的基于文本的人格学习任务范式。
构建了一个三元组人格数据集,用于解决传统“人格-文本”数据集中数据规模与标注质量之间的权衡问题。
基于该数据集,作者通过 triplet learning 学习到具有良好“度量性质”的预训练人格表示。
将人格嵌入整合到各种下游应用中,通过实验证明了三元组学习到的嵌入具有可迁移性。
局限
- 由于地域和平台的限制,构建的三元组数据集仅包含单一语言。在未来,这种方法可以扩展到探索跨语言的人格表征学习。
- 三元组学习的设计相对简单直接,在利用三元组数据学习更好的人格表征方面仍有探索空间。
- 人格表征在推荐领域的应用还有待探索。人格表征在好友推荐和音乐推荐中的耦合效应值得进一步研究。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)