AI Coding:什么样的公司不适合把 Token 当作降本增效的手段
一、缘起:一篇博客和一个朋友的微信
写完上一篇 Harness Engineering 之后,本来以为这条线告一段落了。结果两件事把我重新拉回来。
第一件事是 4 月初 Medium 上的一篇 Postmortem,标题挺扎眼:《The Agent That Burned $4,200 in 63 Hours》。一个创业团队的 Agent 周末跑同步任务,没人盯着,循环了 63 小时,烧掉 4,200 美元。原因蠢得令人心碎——Agent 调一个外部 API 拿到 429(限流),它"思考"完之后决定再试一次,然后又被 429 拒绝,再决定再试一次。每一轮"思考"都把上一轮的失败原文喂回上下文里"学习",每一轮的输入 token 都比上一轮长。从第一小时的 $42,到第四小时的 $200,到第十二小时的 $1,000,最后整个周末烧掉了一个工程师两个月的工资。作者那段总结我一直记着:
那个周末没了他的过桥融资。这次事故甚至蠢到不算"事故"——一个最简单的、所有自治系统都会犯的错误。它只是还没轮到所有人罢了。
第二件事更近,就是我们公司的一个朋友周末发微信跟我吐槽,说他们团队 Q1 被裁了三个工程师,公司的逻辑是"反正都用 AI 写了"。结果上个月对账,一个高级开发的 Token 账单比他自己的月薪还高。他原话:“我现在不知道是该庆幸自己留下了,还是应该担心下一个被砍的就是我——因为现在账怎么算都是负的。”
把这两件事放在一起看,我突然意识到一个问题——上一篇文章里我谈 Harness Engineering 的 Cost Envelope,是站在"怎么把 Agent 跑稳"的工程视角。但还有一个更根本的视角我没碰:Token 这个东西,到底适不适合作为一种"替代人力"的成本结构?
这篇文章想试着把这个问题讲清楚。不打算搞经济学论文,就是结合最近读的几个公开案例 + 我们团队这一年的体感,试着回答一个问题:什么样的公司,不适合把 Token 当作降本增效的手段?
二、先把账算清楚:Token 不是"更便宜的人"
2.1 大家都默认了一个等式,但这个等式根本不成立
"用 AI 替代工程师"这套叙事,背后藏着一个等式:
1 个工程师的产出 ≈ 等价 Token 数量 × 模型能力
只要 Token 单价持续下降,模型能力持续上升,这个等式右边迟早会比左边便宜——所以裁人换 AI 是个"时间问题"。
听着很顺,但实操根本不是这样。NVIDIA CEO 黄仁勋在 GTC 2026 上有句更刺激的:
我有一个 50 万美元年薪的工程师,如果他没有花掉 25 万美元在 Token 上,我会感到深度不安。
注意这句话的反向语义——他不是在说"Token 便宜所以可以替代人",他在说"Token 是给你最好的工程师配的弹药,让他更猛,而不是替代他"。一字之差,这两个判断的财务含义南辕北辙。
很多团队是把第二句读成了第一句,然后开始干。
2.2 几组刚出炉的真实数据
光讲概念太虚,把最近几个月看到的几组数字摆上来:
| 来源 | 数字 | 上下文 |
|---|---|---|
| Medium Postmortem | $4,200 / 63h | 单个 Agent 卡在 429 重试循环,无人值守 |
| DEV Community | $47,000 / 11d | 4 个 LangChain Agent 互相 ping-pong,无预算上限 |
| GitHub Copilot 2026.04 公告 | Token 消耗同比 +340% | Agent 自治式工作消耗是预期的 8 倍,被迫暂停企业版新签 |
| Hacker News 调研贴 | 重度 Agent 用户 $500–2000/月 | “10% 的 Claude Code 用户消耗了 90% 的 Token” |
| Morph 报告 | 70% | 一个 FastAPI 项目 42 次 Agent 跑下来,70% 的 Token 是浪费的 |
| Anthropic 官方 | 90% 用户 <$12/天 | 但剩下 10% 把均值拉得很难看 |
数据来源见文末参考资料
这几组数据放一起看,结论很清楚——Token 成本根本不是一条平稳的曲线,它是一条带胖尾巴的指数曲线。 90% 的人用得很省,10% 的人轻松烧掉一个工程师的工资。问题在于,你事前根本不知道你的项目会落在哪一边。
2.3 为什么 Token 成本这么不可预测
这才是问题的核心。我整理了一下近期几个 Postmortem 的复盘内容,跟我们团队自己的体感对比,发现 Token 经济学有四条反直觉的特性——理解这四条之前,谈"用 AI 替代人"基本是耍流氓。

特性 1:上下文累积让单次调用成本是 O(N²)
这是最容易被忽视的一点。Agent 每一轮都会把之前的对话历史 + 工具调用结果原封不动塞回模型。第 5 轮你以为是"5 次 API 调用"——实际上是 5 + 10 + 20 + 40 + 80 这种几何级数。开始时一次调用 5K token,跑到第 20 步可能单次就吃 80K。这就是为什么 staging 环境跑得好好的 Agent,到生产里成本能暴涨一个量级。
特性 2:输出 token 比输入 token 贵 3-5 倍
Anthropic 的 Sonnet 4.5 输入 $3 / 100 万,输出 $15 / 100 万——价差 5 倍。Opus 4.6 也是类似的比例。问题是模型不会自动闭嘴,给它越多模糊的上下文,它越倾向于"边想边说"——“让我看一下这个文件…我注意到这里…我觉得应该这样改…”。Morph 那篇文章里有一组对比特别说明问题:同一个任务,输入精简后总 token 数反而上升了 20%,但总成本下降了 58%——因为输出 token 数从 504 降到 189。换句话说,你给的输入越准,模型的输出越短,钱花得越少。
特性 3:循环是一个最暴利的成本放大器
这就是开头那个 $4,200 周末事故的本质。失败一次的成本是 $0.05,失败 100 次的成本不是 $5,而是接近 $50——因为每次失败的错误信息都会被塞进下一次的上下文里"帮助 Agent 学习"。开头那个 Postmortem 的作者把它总结得很到位:
Agent 既不知道自己累计花了多少钱,也不知道自己已经在同一个操作上失败了 300 次,更不知道下一次大概率还会失败——它每一轮都是从零开始的。
特性 4:长尾分布
Anthropic 自己的数据——90% 的开发者每天花费 < $12,但剩下 10% 在哪个区间?$50? $200? $500? 这个数据他们没公开,但 Hacker News 上有人晒出 $15,000/月的账单。FinOps Foundation 2026 的调研更有意思:受访的 1,192 家公司里,38% 的工程主管已经在为每个开发者付 $101–500/月,21% 已经超过 $500/月。而且这个数字预计到 2026 年底会涨到 AI 工具占工程总 OpEx 的 20-30%。
这四条特性凑在一起,得出一个结论:Token 不是一种"便宜的人力替代品",它是一种"高方差的、依赖工程基建去驯化的、能反咬主人一口的算力。"
三、把"裁员省下的工资"和"AI 烧掉的 Token"放进同一张图
光摆数字还不够,得把这事画成一张能看的图。我做了个简化模型,帮自己想清楚到底什么情况下"裁员换 AI"是赚的、什么情况下是亏的:
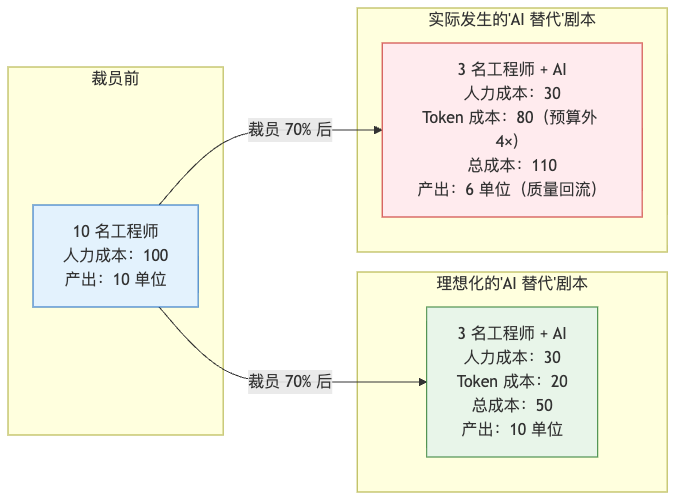
理想剧本和实际剧本,差的不只是数字——差的是几个隐形假设:
| 假设 | 理想剧本 | 实际发生的事 |
|---|---|---|
| Token 成本可预测 | 假设线性 | 实际指数胖尾,10% 任务吃掉 90% 预算 |
| 留下来的工程师能镇住 AI | 假设是"剩下都是高手" | 实际可能被裁的是写 Harness 的那批人 |
| 产出质量不变 | 假设"模型够强" | 实际质量回流(rework),6 单位产出还包含返工 |
| 可观测性已就位 | 假设"出问题能发现" | 实际告警链路根本没搭,事后看账单才知道 |
| 知识传承还在 | 假设"代码在仓库里" | 实际隐性知识跟着裁掉的人一起走了 |
裁员的钱是确定的、立刻到手的;Token 的成本是不确定的、滞后到手的。 这两个时间差让公司财务上看起来很美,但跑两三个月就会反向打脸。
四、先说哪些公司适合——这部分很短
为了不显得我是在唱衰 AI Coding,先说哪些公司确实适合用 Token 替代部分人力。把适合的特征列出来,反过来不适合的就清楚了。
适合的公司大致有几个共同点:
- 业务边界清晰、规则可枚举。比如做 SaaS 的、做模板代码生成的、做数据迁移工具的——任务的输入输出都很结构化,Agent 不容易跑偏。
- 已经有成熟的 CI/CD 和工程基建。Stripe 的 Minions 之所以能跑起来,前面铺垫了多年的内部 Linter、测试框架、CodeReview 流程。
- 有专门的人在做 Harness Engineering。也就是说虽然砍了写代码的人,但养了写规则、写测试、做可观测性的人——团队的总人头数可能没怎么降,结构变了。
- 业务对延迟和成本不敏感。比如做 ToB 长合同、营收稳定,月度多花 $50K 在 Token 上不会动摇 cash flow。
- 代码资产是"长期负债"而非"长期资产"。比如那种内部工具、一次性脚本、营销活动落地页——代码本身没什么长期价值,AI 写得糙也无所谓。
OpenAI 那个"5 个月 100 万行代码、3-7 个工程师"的案例,5 条全占。Stripe 的 Minions,前 4 条全占。他们之所以能跑,不是因为模型变强了,是因为他们花了多年时间把 Harness 搭出来了。
下面要说的,就是不具备这些前提的那些公司。
五、四类不适合走"Token 替代人"路线的公司
下面逐个说。
5.1 第一类:老旧系统多、代码上下文巨复杂的公司
我们公司的系统就有这个特点——一个十年的电商核心 + 一堆收购合并进来的微服务,几十个数据库、上百张表,业务规则散落在 SQL、定时任务、MQ 消费者、配置中心里。
这种代码库对 Token 来说是个噩梦。原因前面讲过:输入 Token 的"准"决定了输出 Token 的"少"。但老系统的"准"几乎不可能——AI 想理解一个改动的影响范围,得读 10 个文件;读完发现还得读上游 5 个;上游里又有 3 个引用了一段历史悠久的 utility…一次"理解上下文"的过程能轻松吃掉 50K input token,而真正生成的修复代码可能就 50 行。
我们做过一个对比测试。同样一个"修一个简单的小 Bug"任务:
| 项目类型 | 平均 Token 消耗 | 平均成本 |
|---|---|---|
| 新启动的 Spring Boot Demo(约 5K 行) | ~12K tokens | ~$0.05 |
| 我们的 calora-ai 模块(约 15 万行) | ~85K tokens | ~$0.40 |
| 我们的 calora-portal 单体(约 80 万行) | ~280K tokens | ~$1.50 |
80 万行的老单体,单次 Bug 修复成本是新项目的 30 倍。 而且这还只是"普通 Bug"。一个跨模块的重构?我们试过一次,单次任务花了 $40+。这种情况下,"用 AI 替代写老系统的工程师"的财务模型根本立不住——你裁的人月薪可能就 1.5-2 万人民币(按国内中等水平),AI 在他原来负责的代码库里跑两次大改造就把工资烧没了。
更糟的是 GitHub Copilot 自己都承认的"200K Token 规则"——一旦输入超过 200K,因为 caching 机制变化,成本会接近翻倍。老系统天然就在这条线附近游走。
判断标准很简单:你的项目代码量超过 50 万行、模块超过 10 个、跨服务调用频繁、技术栈混杂(比如混合 Java + Python + Node)——这种公司千万别想着"裁掉一半人换 AI",先想想怎么把 Harness 搭起来再说。
5.2 第二类:Harness 还没搭、就先动刀子的公司
这是最危险的一类,也是开头那个朋友所在公司的情况。
我上一篇文章把 Harness Engineering 拆成五个组件——Context Engineering、Architectural Constraints、Verification Loops、Cost Envelope、Observability。坦白说,我自己只做到了三个半,剩下两个还没搞利索。但有一点很清楚:Harness 这五件东西,在"裁员换 AI"之前必须先到位。尤其是 Cost Envelope 和 Observability。
为什么?因为人力成本是有自然上限的——再贵的工程师也不会突然某个月薪资涨 10 倍。但 Token 成本没有任何天然上限。没有 Cost Envelope 的 AI 团队,相当于一个不限额度的信用卡放在一个不知道刷卡会扣钱的人手里。
最近那个 $47,000 / 11 天的案例,Postmortem 里给出的原因清单太典型了,几乎可以照着抄成所有失败团队的体检报告:
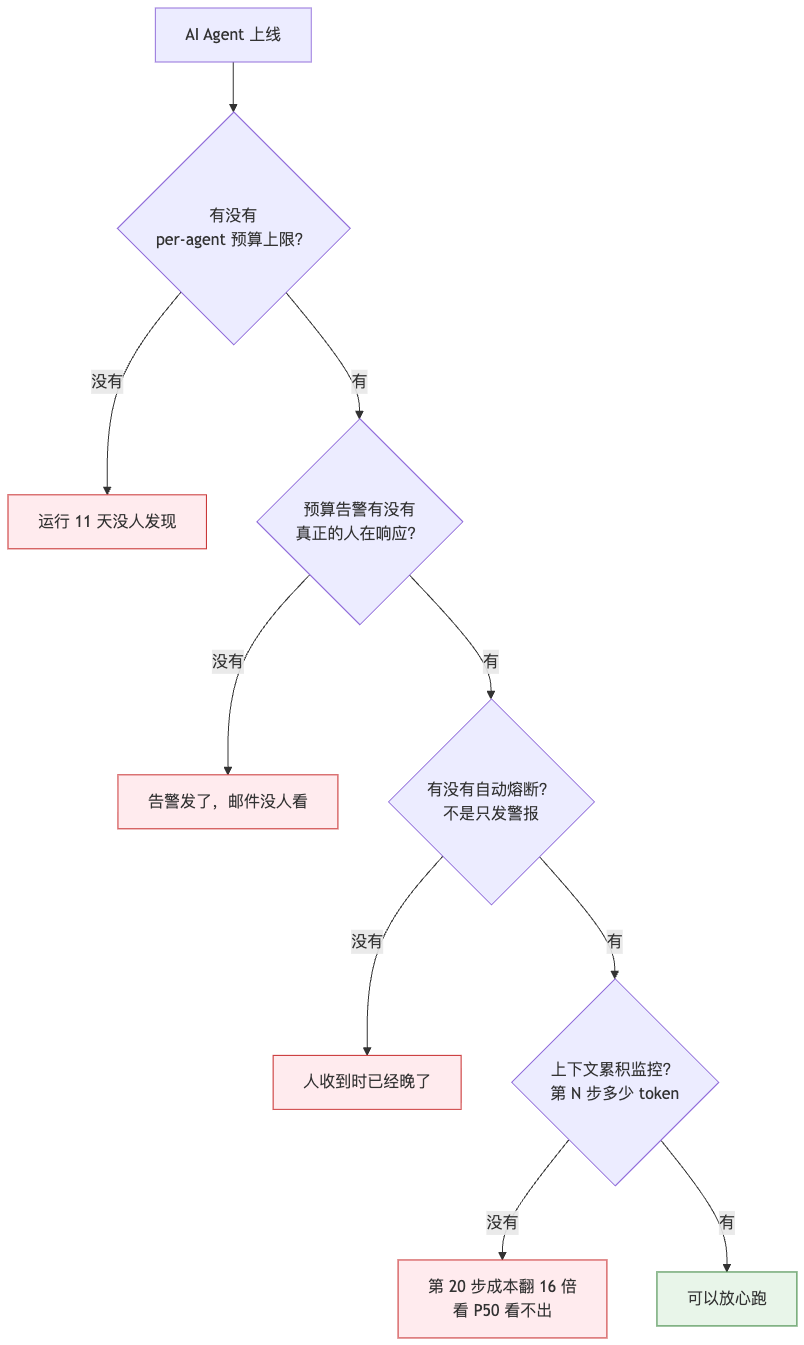
Harness 没搭就裁人换 AI,等同于做了一个"反向杠杆"——你把"成本可控但产出有限"的工程师换成了"产出更高但成本不可控"的 AI,风险结构变了,但你的财务模型和应急预案没变。
我观察到一个很扎心的规律——很多公司裁员的对象,恰恰是那些原本可能去搭 Harness 的人。资深工程师贵啊,先砍。结果留下的初中级工程师虽然便宜,但他们既不知道怎么搭 Cost Envelope,也不知道 Observability 从哪儿下手。AI 跑飞了之后,他们只能等账单出来才发现。
判断标准:问自己三个问题——
- 我们能在每个 Agent 任务上实时看到 token 消耗吗?(不是月底看账单,是实时)
- 我们对单个任务的 token 上限自动熔断了吗?(不是只告警)
- 我们对每个 Agent 的"是否处于循环"有检测吗?(不是凭体感)
三个问题里有一个答"没有"——你不在"用 AI 替代人"的赛道上,你在"给 OpenAI 烧钱"的赛道上。
5.3 第三类:业务波动大、预算敏感的公司
这一类容易被忽视。
很多人以为"用 AI 替代人"的核心问题是技术——其实更现实的问题是财务节奏对不上。
工资是按月固定支出,可预测、可规划、可砍(最多月薪 ×N 的赔偿金)。但 Token 账单是按消耗计算,它有几个特点:
- 滞后性:你这个月烧了多少,下个月才出账单。
- 峰值不可控:一次失败的 Agent 任务可能在几小时内吃掉一周的预算。
- 不可逆性:钱花出去就没了,不像养一个工程师还能慢慢学技能、转岗位。
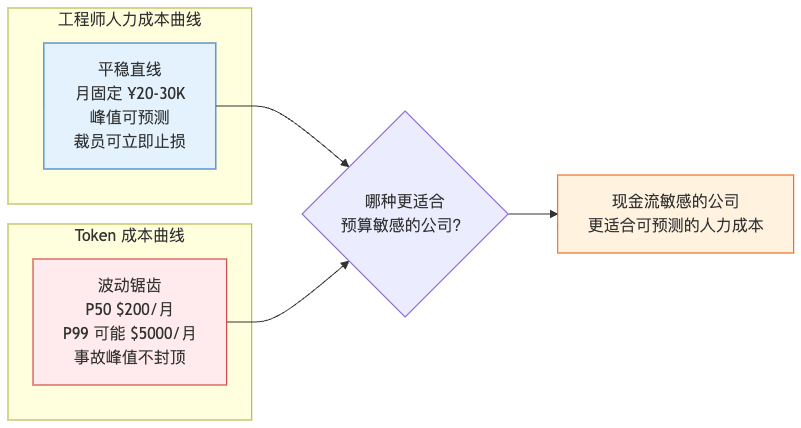
我帮另一个朋友的创业公司算过一次账。他们月营收波动很大,从 30 万到 80 万人民币不等。如果按"裁掉两个开发,月省 4 万"的方案,看起来很好。但他们 AI 用的是 Claude Sonnet,按我估算一个月活跃开发场景下的 Token 消耗,P50 大概 $400/月,P99 可能到 $3000/月——也就是说最坏的月份 Token 账单(约 2 万)会吃掉裁员节省额的一半,加上一次 Agent 跑飞的事故就直接打平甚至倒贴。
而他作为创业公司的 CEO,最怕的不是"成本高",是"成本不可预测"——因为他的现金流压根经不起一次月度账单暴增。
判断标准:
- 公司营收是不是季节性波动 > 30%?
- 现金流储备能不能扛住"某个月成本突然翻倍"?
- 财务系统能不能做到"按 Agent / 按任务"维度的成本归因?
如果你不是 Stripe、OpenAI、Meta 这种"反正预算无限"的公司,Token 这种波动型成本就不应该作为核心成本结构——它适合作为"人力的补充",但不适合作为"人力的替代"。
5.4 第四类:隐性知识浓、合规/安全要求高的公司
这是最容易被低估的一类。
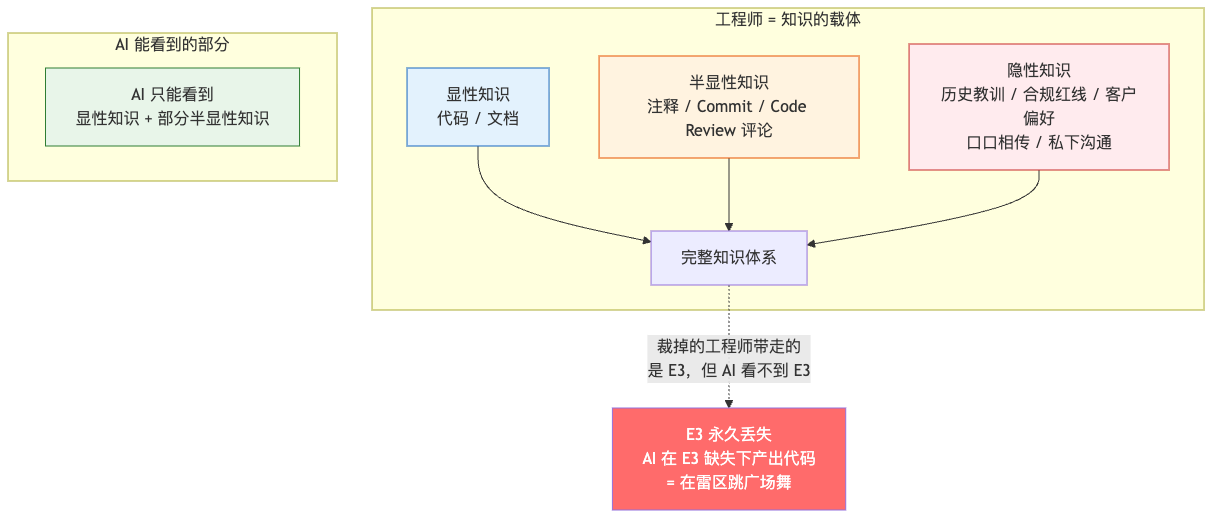
工程师的价值远不止"写代码"——还包括:
- 知道 为什么这段代码不能这样写(哪怕代码上看起来更简洁)
- 知道 哪些是历史包袱不能动(哪怕看起来很丑)
- 知道 业务方真正想要的是什么(哪怕需求文档写的不是这样)
- 知道 某个看似无害的改动会触发哪些合规审查
这些知识有个共同特征——它们不在代码里,也不在文档里,它们在人的脑子里。
我们最近就栽了一个跟头。有一个跟用户隐私相关的接口,AI 想做一个"看起来很合理"的优化——把用户的某个偏好字段从加密存储改成明文(理由是查询性能更好)。这个改动从 PR 看完美无瑕,测试也都过了。如果不是 Code Review 阶段一个老同事看到了拍桌子说"这个字段是 GDPR 合规要求必须加密的",差点就上了线。
这件事让我特别清醒:AI 知道"如何写代码",但不知道"为什么不能写"。后者高度依赖隐性知识——团队的历史、行业的潜规则、监管的红线、客户曾经的投诉、某次未遂事故的教训。
NVIDIA 黄仁勋那套"$500K 工程师配 $250K Token"的逻辑,它默认的前提是——这 $500K 的工程师还在。Token 是给他配的弹药,让他能管 100 个 AI Agent。但如果你把他裁了?这 $250K 的 Token 落在一个不熟悉业务、没踩过坑的新人手里,反而会触发更多的"看起来合理但实际是雷"的代码。
判断标准:
- 公司有没有合规要求(金融、医疗、政府、出海 GDPR、数据安全法)?
- 公司核心业务逻辑里有没有"老人才知道的潜规则"?
- 团队有没有形成的"集体记忆"(某次事故、某次客户投诉)?
只要任何一条命中,裁员换 AI 就是在做一笔风险极不对等的交易——你省下的是月薪 ¥20-30K,可能换来的是一次合规罚款 ¥xxx 万、或者一次业务事故。
六、那这些公司就不能用 AI 了吗?
当然能用,只是不要走"裁员换 AI"那条路。
我自己摸索了大半年的体感是——把 AI 的角色定位从"替代人"改成"放大人",整个财务模型和组织模型都顺了。
| 维度 | "替代人"模式 | "放大人"模式 |
|---|---|---|
| 人员决策 | 裁员、缩编 | 不裁,但提高人均产出标准 |
| Token 预算 | 试图与省下的工资对冲 | 视为工程师的"工具津贴" |
| 失败处理 | 出事了责备 AI / 责备工程师 | 出事了改 Harness |
| 衡量标准 | 人力成本下降 | 单工程师交付量上升 |
| 组织风险 | 高(隐性知识丢失) | 低(人还在) |
NVIDIA 那套"50 万年薪 + 25 万 Token 预算"的逻辑,在这套框架下就立得住——不是因为 Token 替代了人,是因为 Token 让一个人变成了 100 个人。前提是这个人还在。
我把它理解成一个挺直观的物理类比:Token 不是"廉价劳动力",Token 是"放大器"。 放大器能把 1W 信号变成 100W,但如果输入是噪声,输出就是更大的噪声。
放大器接什么样的输入信号最划算?
- 接资深工程师的信号:他们知道要让 AI 干什么、不干什么、怎么验
- 接已经搭好 Harness 的环境:约束清晰、验证自动、成本可控、行为可观测
- 接边界清晰的任务:模板代码、单元测试、文档生成、数据迁移、低风险重构
接错了信号会怎样?开头那个 $4,200 的周末就是答案。
七、给具体公司的 Checklist
如果你是技术负责人,正在考虑"是不是该裁一些人然后让 AI 接手"——下面这个 Checklist 拿去用,过不了就先别动:
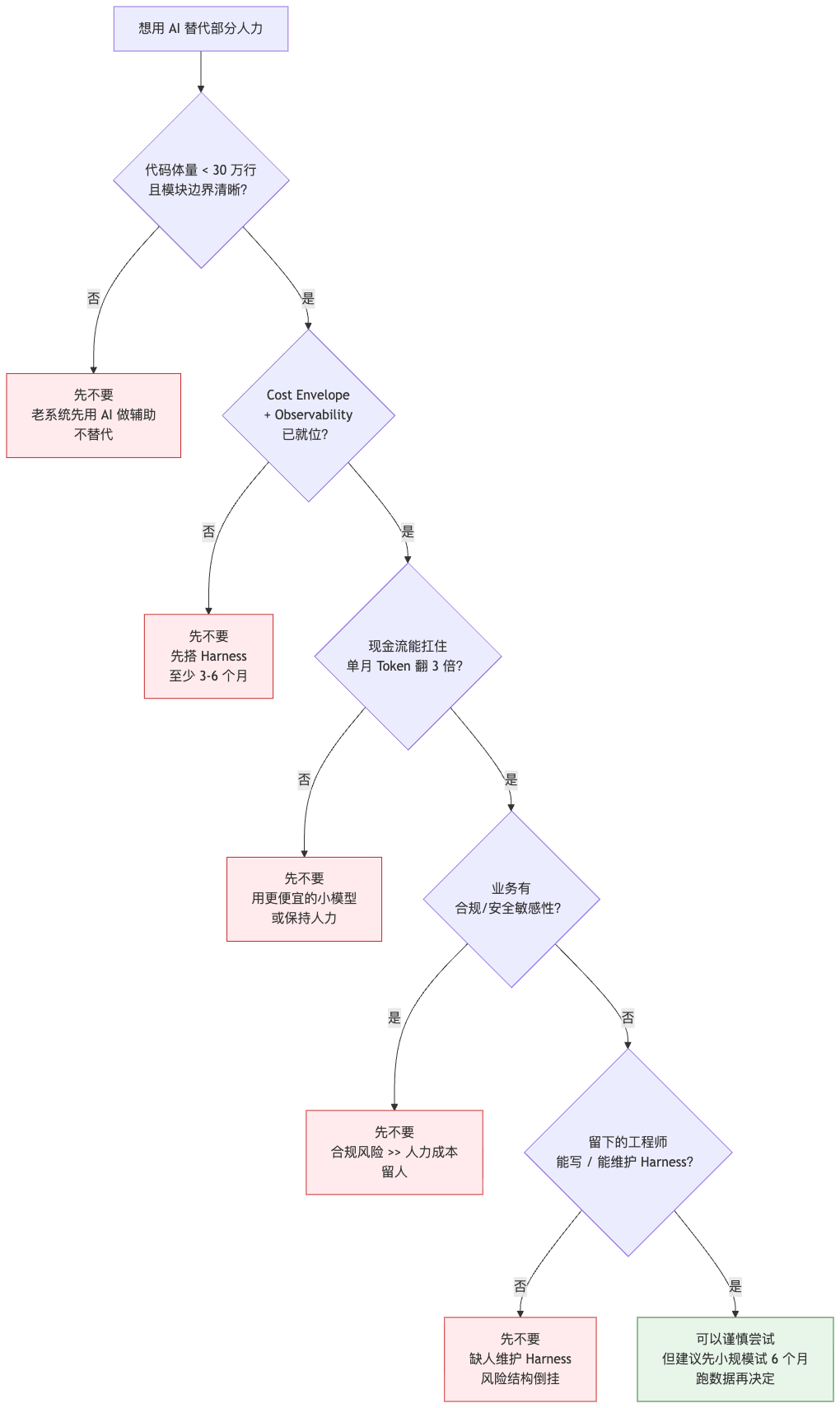
5 个"先不要",1 个"可以"。 这个比例可能会让一些 CTO 不爽——感觉我在唱衰 AI Coding。但我的诚实想法是——这个比例反映了我观察到的现实。真正能跑通"AI 替代人"模型的公司,是少数;大多数公司更适合的姿势是"AI 放大人"。
八、四篇连起来再看一次
写到这里,回头串一下这四篇博客,整个故事其实越来越完整了:

如果说前三篇都在回答"如何让 AI 写出可控、可靠的代码"——这第四篇试图回答的是更前置的一个问题:这家公司,是不是真的应该用 AI 替代人?
工程问题往往是有解的——只要你舍得花时间花钱搭 Harness。但商业问题没有标准答案——它取决于你的现金流、你的代码资产、你的团队结构、你的合规要求。把工程结论直接套到商业决策上,是这一波"AI 裁员潮"踩坑最深的根源。
九、写在最后
Token 经济学这件事,让我想起前几年的两个时刻。
第一个时刻是 2018 年前后,“上云"开始流行。当时很多公司一头扎进去,把自建机房全砍了,结果两年后发现云账单比物理机+人力运维还高,又灰头土脸搞混合云。本质上是没算清楚一个问题——云的成本结构是按用量计算,不是按节省计算。如果你的业务模式天然不适合"按需付费”,那它怎么都不会便宜。
第二个时刻是 2020 年微服务大潮。很多公司觉得"拆了就是先进",把单体砍成 50 个微服务,然后被服务治理、链路追踪、运维复杂度搞死了——又默默合并回去。本质上还是没算清楚——微服务节省的是研发耦合的成本,但增加的是系统复杂度的成本。如果你的团队规模本来就小,研发耦合根本不是瓶颈,拆了纯亏。
现在这一波"AI 替代人",套路一模一样——只算了 AI 节省的人力,没算 Token 增加的成本、没算 Harness 缺失的代价、没算隐性知识丢失的风险。三五年后回头看,大概率会有一批公司复盘说"我们当初不应该砍那么狠"。
第三篇文章末尾我引用了 Mitchell Hashimoto 的那句话——“我是个软件手艺人,做这行就是因为热爱”。今天再加一句我自己的:
Token 是好东西,但 Token 不是人。把 Token 当人用,账早晚要还。
赛车这个比喻,我前几篇用得有点滥。这篇就不用赛车了,换一个——Token 像是给厨房的明火加了个燃气助力器,本来一灶能做一桌菜,现在能做十桌。但你不能因此就把厨子全裁了,让燃气自己烧——那不是降本,那是放火。
参考资料
- The Agent That Burned $4,200 in 63 Hours — Sattyam Jain, Medium, 2026.04
- The $47,000 Agent Loop: Why Token Budget Alerts Aren’t Budget Enforcement — DEV Community
- GitHub Halts New Sign-Ups and Adds Usage Limits Amid Soaring Demand — World Today News, 2026.04
- The Real Cost of AI Coding in 2026: Pricing, Token Waste, and How to Cut It — Morph
- The Real Cost of AI Coding Agents in 2026 — Kumar Gauraw
- Are AI tokens the new signing bonus or just a cost of doing business? — TechCrunch, 2026.03
- How Token-Based AI Coding Tools Impact Engineering Budgets — Exceeds AI Blog
- The Economics of AI-Driven Software Development — Jonathan Fulton, Medium
- More tokens, less cost: why optimizing for token count is wrong — Hacker News 讨论
- Ask HN: How much are you spending on AI coding at work? — Hacker News 讨论
- How to Stop AI Agent Cost Spirals Before They Start — DEV Community
- State of FinOps 2026 — FinOps Foundation 调研

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)