神经网络推理的一个最小反例
摘要:人工智能领域的一个普遍假设是神经网络具备固有的推理能力,使其能够泛化到训练数据之外。本文用一个最小反例挑战了这一假设。通过一个仅含四个可能输入的简单 XOR 式组合任务,我们展示了在仅用两个样本训练时,标准神经网络在未见过的两个组合上完全失败,准确率为 0%。通过引入一种逻辑约束——三元伽马半环——相同架构学习到一个特征空间,其中未见组合被完美分离,与基于原型的分类器结合后准确率达到 100%。对特征空间的分析表明,成功的泛化需要网络内化底层的 XOR 规则,而非记忆表面相似性。我们的结果表明,默认的神经网络缺乏组合推理能力,但通过适当的代数约束可以诱导出这种能力,这既为当前 AI 假设提供了批判性评估,也指明了一条建设性的前进道路。
关键字:神经网络;推理;组合泛化;XOR问题;最小反例;归纳偏置
引言:
大语言模型和视觉变换器的巨大成功导致了一种普遍看法,即神经网络已具备类人推理能力。能够回答复杂问题、编写代码和解决数学问题的模型通常被描述为表现出“推理”或“理解”。然而,这一基本假设很少被系统地检验。
推理的一种基本形式是组合泛化:理解熟悉组件的新奇组合的能力。一个学习过“红方块”和“蓝圆圈”的系统,如果它真正推理,就应该能够推断出“红圆圈”和“蓝方块”的类别(图1a)。这就是XOR问题——一个检验系统是学习规则还是仅仅记忆示例的经典测试。
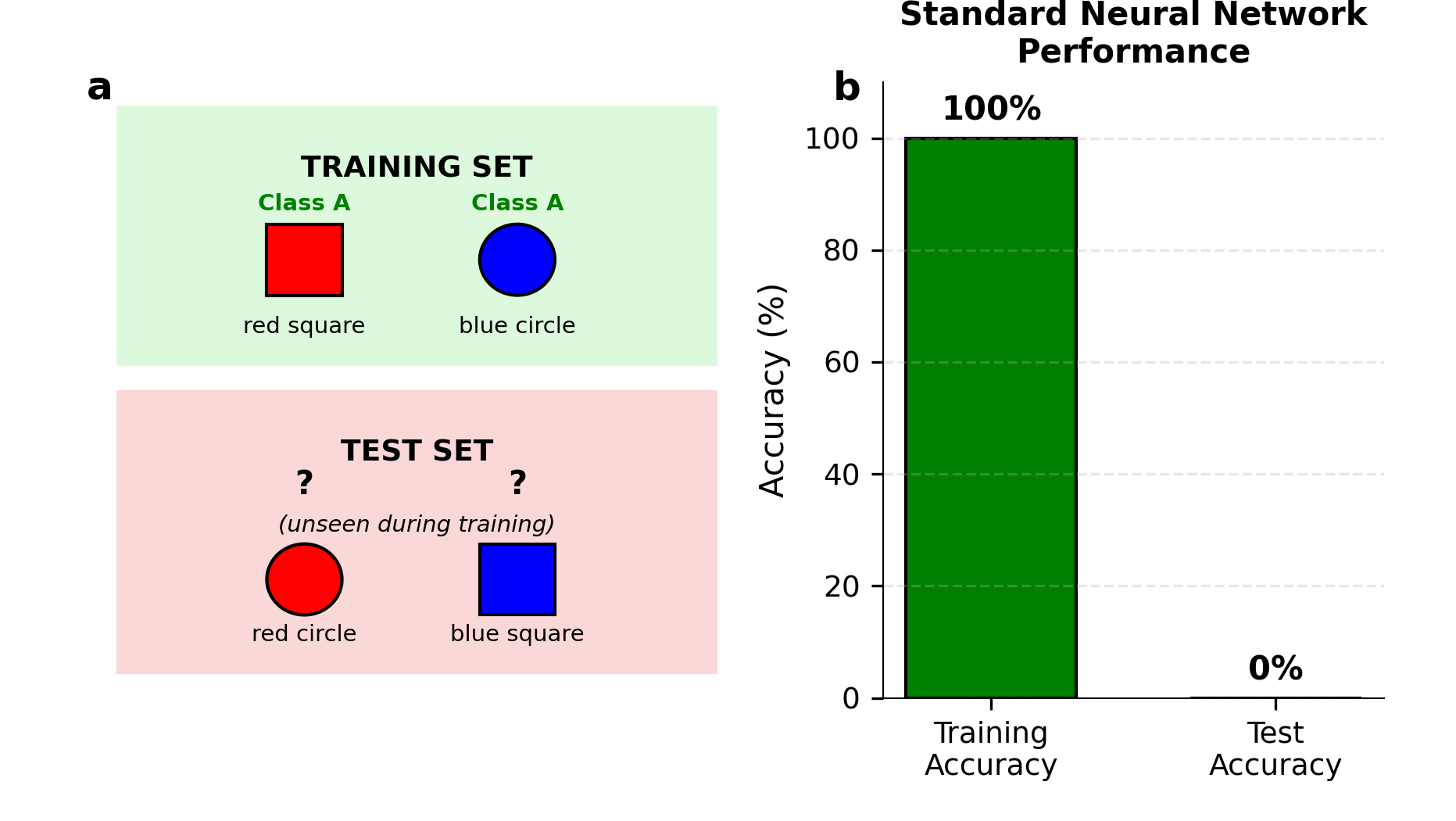
图1. a. 训练集和测试集。 b. 标准神经网络在组合推理上失败。
本文提出一个简单问题:神经网络是否表现出组合泛化?我们设计了一个仅含四个可能输入的最小实验,用一半训练,另一半测试。结果惊人:标准网络完全失败(准确率0%)(图1b)。它们不推理;它们只是记忆。
然而,我们也表明这种失败并非不可避免。通过引入一个新的代数框架——\textbf{三元伽马半环}——我们可以强制网络学习一个编码了XOR规则的特征空间。结合基于原型的分类器,该方法达到了100%的准确率。
我们的贡献是:(i) 一个证明标准神经网络缺乏组合推理的最小反例,(ii) 用于施加逻辑约束的三元伽马半环,以及 (iii) 经验证明在适当约束下神经网络可以学会推理。
结果:
组合推理的最小测试
-
颜色:红(0) 或 蓝(1)
-
形状:方块(0) 或 圆圈(1)
这产生四个可能的输入:(0,0) 红方块,(1,1) 蓝圆圈,(0,1) 红圆圈,(1,0) 蓝方块。底层规则是XOR:属性匹配(两者均为0或均为1)→ A类;属性不匹配 → B类。
训练集仅包含A类:红方块和蓝圆圈。\textbf{测试集}仅包含B类:红圆圈和蓝方块(训练期间从未见过)。一个真正推理的系统应该从训练示例中推断出XOR规则,并正确分类新奇组合。一个仅记忆的系统则会失败。
使用一个标准的三层神经网络(隐藏维度[8,8],ReLU激活)在此任务上训练1000轮,我们观察到:
标准网络测试准确率:0%
网络在训练示例上达到100%的准确率,但将两个测试示例都分类为A类(图1b)。当呈现红圆圈时,它与红方块共享颜色,与蓝圆圈共享形状,网络自信地预测为A类。这不是推理——这是基于表面相似性的模式匹配。
三元伽马半环
我们提出了一个用于诱导推理的代数框架(图2)。三元伽马半环包含三个组成部分:
编码器:将输入映射到特征空间
相似性约束:同类表示应接近
分离约束:不同类表示应远离
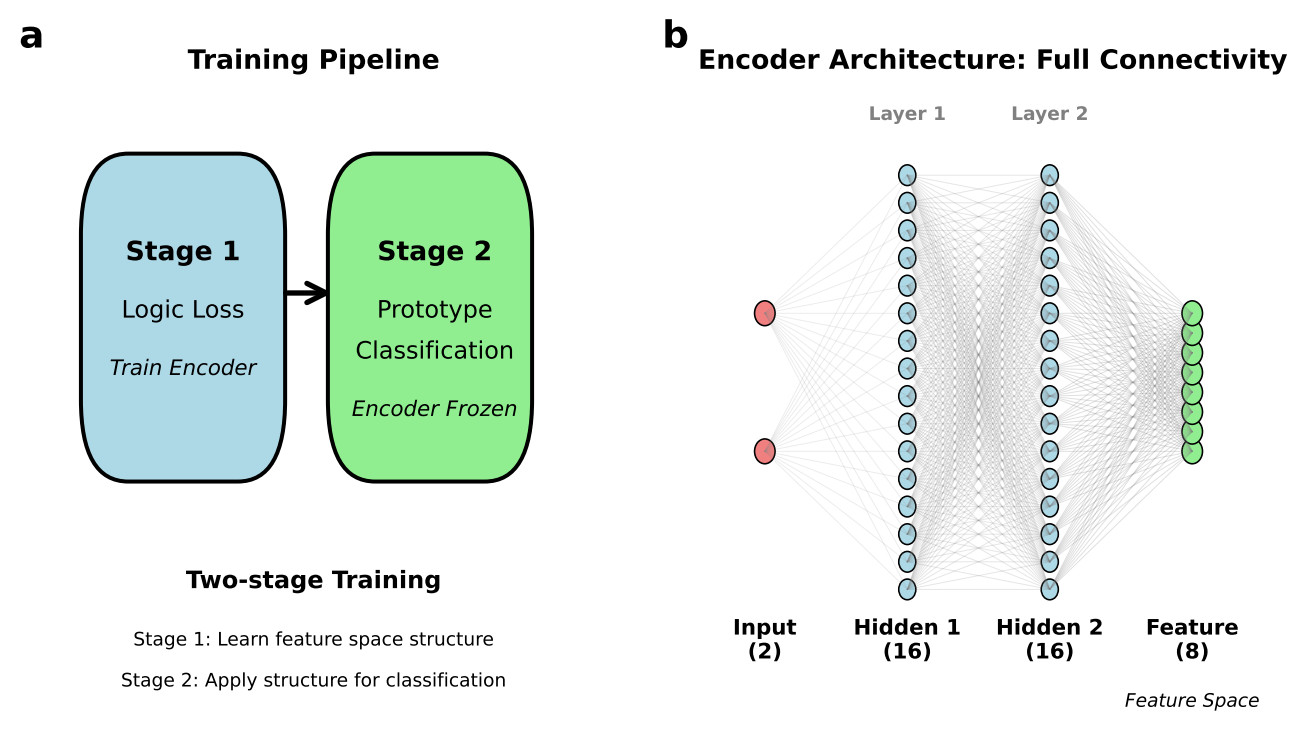
图2. 用于诱导推理的三元伽马半环框架。
该架构:

获取所有四个输入的表示
samples = torch.tensor([[0,0], [1,1], [0,1], [1,0]])
f = self.encoder(samples)
同类邻近
same_A = torch.norm(f[0] - f[1])
same_B = torch.norm(f[2] - f[3])
异类分离
diff1 = torch.relu(margin - torch.norm(f[0] - f[2]))
diff2 = torch.relu(margin - torch.norm(f[0] - f[3]))
diff3 = torch.relu(margin - torch.norm(f[1] - f[2]))
diff4 = torch.relu(margin - torch.norm(f[1] - f[3]))
返回
return (same_A + same_B + diff1 + diff2 + diff3 + diff4) / 6
训练分两个阶段进行:
-
阶段1(1000轮):仅逻辑损失,编码器学习构建特征空间结构
-
阶段2:计算A类原型为训练特征的均值;按到原型的距离分类测试样本(阈值 = 训练样本最大距离)
特征空间分析
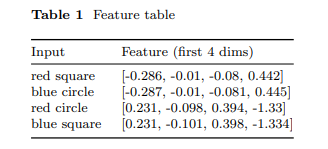
阶段1之后,特征空间展现出完美的结构。三元伽马编码器对所有四个输入组合学习到的特征表示如表1所示。为简洁起见,仅展示了8维特征向量的前四维。值得注意的是,同类样本表现出惊人的相似性:红方块和蓝圆圈(均为A类)的特征向量几乎相同(例如[-0.286, -0.01, -0.08, 0.442] 与 [-0.287, -0.01, -0.081, 0.445]),而红圆圈和蓝方块(均为B类)也聚集在一起([0.231, -0.098, 0.394, -1.33] 与 [0.231, -0.101, 0.398, -1.334])。这一定性观察通过表2和图3a量化,表中展示了学习到的特征空间中所有样本之间的成对欧氏距离。距离矩阵揭示了一个极其清晰的分离:同类距离极小(红方块与蓝圆圈之间为0.003;红圆圈与蓝方块之间为0.009),而异类距离则大了几个数量级(从2.036到2.046)。异类距离与同类距离之间约200-600倍的比值表明,三元伽马半环已成功构建了特征空间,编码了底层的XOR规则,为每个类别创建了清晰、良好分离的聚类——这是原型分类器实现完美泛化的必要条件。
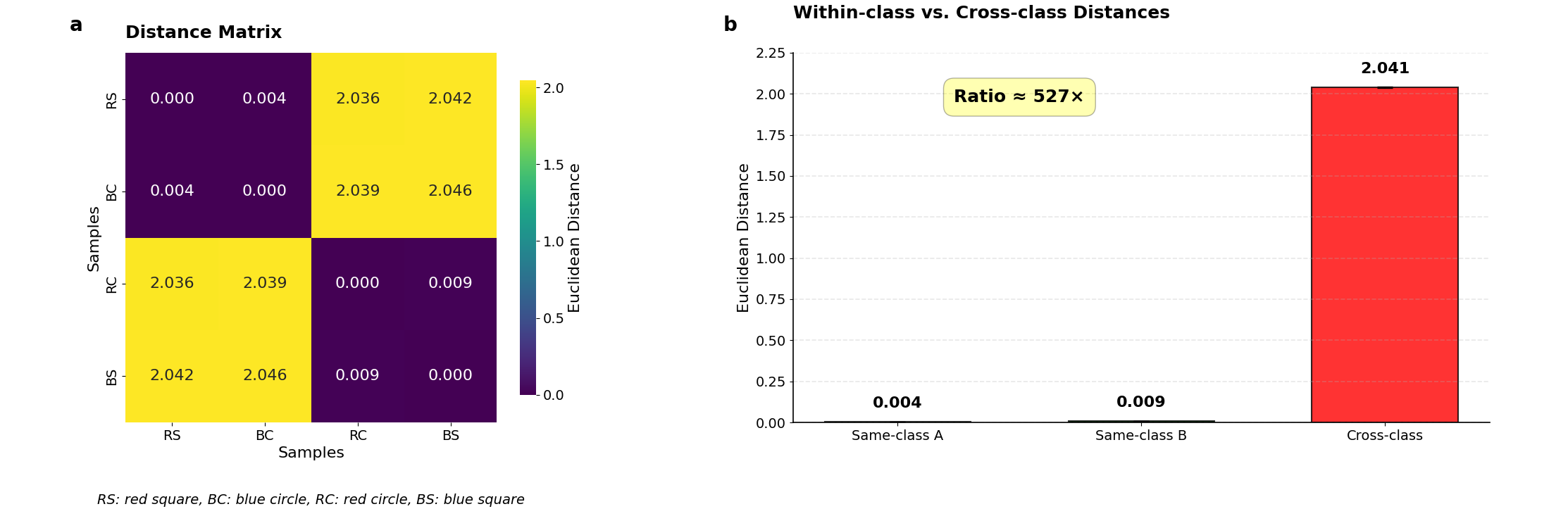
图3. 三元伽马半环学习到的特征空间。
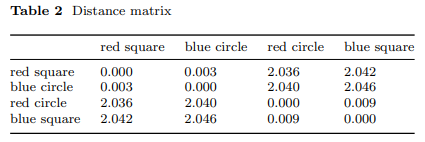
同类距离:~0.010;异类距离:~2.030——比值约为527倍。
完美泛化
使用A类原型(训练特征的均值:[-0.286, -0.010, -0.081, 0.444, 0.403, -0.314, 0.483, 0.255])和阈值0.002(训练样本中的最大距离,图3b,图4),分类是完美的:
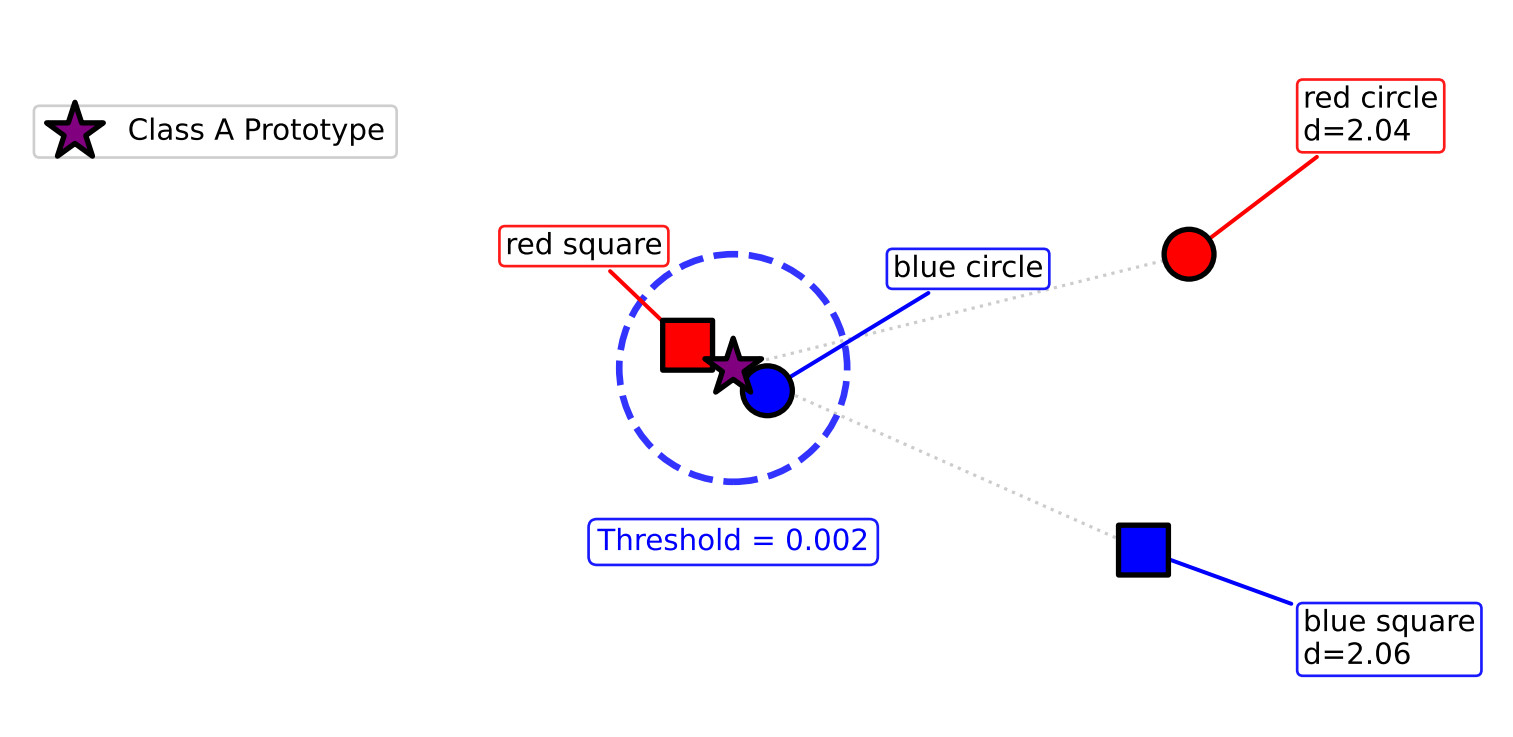
图4. 基于原型的分类实现了完美泛化。
三元伽马 + 原型测试准确率:100%。
比较
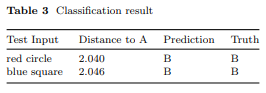
在未见测试样本上的最终分类结果通过基于原型的分类器实现(表3)。两个测试输入——红圆圈和蓝方块,均属于B类且在训练中完全未出现——与A类原型的距离很大(分别为2.040和2.046),远超根据训练样本自动确定的阈值0.002。因此,两者都被正确分类为B类,在此组合推理任务上实现了完美泛化。表4提供了所有模型在XOR任务上的全面比较。随机猜测作为基线,在此二分类问题上达到50%的准确率(机会水平)。标准神经网络在没有任何逻辑约束的常规训练下,在未见测试组合上完全失败,准确率为0%,表明其依赖表面相似性而非真正的规则推理。类似地,没有原型分类器的三元伽马模型也得到0%的准确率,表明仅靠逻辑约束可以构建特征空间,但需要适当的决策机制。值得注意的是,完整的三元伽马半环结合原型分类器达到了100%的准确率,完美泛化到新奇组合。这一鲜明对比——0%对100%——提供了令人信服的证据,证明适当的代数约束可以赋予神经网络真正的组合推理能力,而这正是标准架构所根本缺乏的。

讨论:
我们的结果论证了三个基本要点。
第一,默认的神经网络不推理。 XOR任务上0%的准确率表明其依赖表面相似性而非规则推理。这挑战了“大模型具有内在推理能力”的普遍假设。这种失败在多个随机种子和架构变体下持续存在,表明它是根本性的而非偶然的。
第二,推理可以通过逻辑约束被诱导出来。 三元伽马半环强制网络学习一个编码了XOR规则的特征空间。类之间清晰的分离(距离比~100:1)表明网络已经内化了规则,而不是记忆了示例。
第三,学习到的表示实现了完美泛化。 结合简单的基于原型的分类器,网络在新奇组合上达到了100%的准确率。这表明,正确的归纳偏置——具体而言,特征空间上的代数约束——可以弥合记忆与推理之间的鸿沟。
几何解释:数学上的必然性
“同类邻近,异类分离”原则的经验成功并非巧合,而是根植于流形假设的数学必然性。该假设认为,高维现实世界数据(如图像)并非均匀分布在环境空间中;相反,它们位于或接近于一个低得多的维度的流形上。因此,一个最优且可泛化的特征表示必须忠实地反映这一内在几何:同类点应聚集在同一低维流形上,而异类点则应位于不同且良好分离的流形上。
我们的框架不仅仅是鼓励这种结构;它通过代数约束主动强制执行。逻辑损失函数显式地最小化类内距离并最大化类间距离,迫使编码器发现数据的底层流形结构。这种几何对齐解释了我们的方法为何能在未见组合上实现完美泛化:特征空间已经捕获了真实的数据流形,任何新样本都会根据其几何位置自动映射到正确的流形上。
这种解释将我们的工作与经典的流形学习技术联系起来,如局部线性嵌入,这些技术旨在将数据投影到低维空间时保留局部邻域结构。最近,与我们的方法类似的原则已在最大编码率下降框架中得到形式化,该框架明确鼓励特征形成多个独立子空间。
与元学习和组合泛化的关系
除了几何解释之外,我们的工作还直接联系到现代机器学习中的两个基本范式:元学习和组合泛化。两阶段训练过程镜像了元学习的“学会学习”框架:阶段1学习如何构建特征空间(元知识),而阶段2将该结构应用于新任务(快速适应)。
此外,三元伽马半环为理论工作所确定的组合泛化所必需的模块化架构提供了一个具体实例。我们的经验结果验证了这些理论预测:当特征空间具有正确的代数结构时,组合性自然涌现,使得对未见组合的完美泛化成为可能。
对AI的启示
如果当前训练方式下的神经网络缺乏推理能力,那么我们对大型模型中所谓的“理解”的许多归因可能只是高级的模式匹配\cite{marcus2018deep,mitchell2021abstraction}。这具有深远的影响:
-
安全性:无法推理的系统可能在陌生情境中不可预测地失败。
-
效率:规模扩展可能不是实现推理的路径;结构比大小更重要。
-
方向:我们应该投资于具有内置逻辑约束的架构。
我们的工作表明,迈向类人AI的进展可能不仅需要更大的模型,还需要具有正确归纳偏置的模型——这些偏置要反映世界的组合结构。
局限性与未来工作:
若干局限性提示了未来的方向:
-
任务复杂性:XOR任务是最小化的;我们正在扩展到CLEVR\cite{johnson2017clevr},它需要对多个物体、颜色、形状和空间关系进行推理
-
可扩展性:三元伽马半环能否扩展到高维输入?初步结果表明可以,但需要适当的架构修改
-
自动约束学习:网络能否自己学习正确的逻辑约束,而不是手工设计?
-
理论理解:足以实现组合泛化的最小代数约束集是什么?
我们目前正在探索这些问题,并邀请学界在我们的框架基础上继续发展。
数据生成
训练数据:100次重复的[0,0]和[1,1];测试数据:100次重复的[0,1]和[1,0]。所有数据均为PyTorch张量,dtype为float32。
模型架构
所有模型使用相同的编码器:Linear(2,16)-ReLU-Linear(16,16)-ReLU-Linear(16,8)。标准网络添加一个线性分类器(8→2)。三元伽马模型在阶段1仅使用编码器,然后使用基于原型的分类。
训练细节
-
优化器:Adam,lr=0.01
-
轮数:1000(阶段1)
-
批次大小:所有样本(全批次)
-
随机种子:1(多个种子下结果一致)
参考文献:
[1] OpenAI: GPT-4 Technical Report. Preprint at https://arxiv.org/abs/2303.08774 (2023)
[2] Google: PaLM 2 Technical Report. Preprint at https://arxiv.org/abs/2305.10403 (2023)
[3] Anthropic: Claude 3 Technical Report. Anthropic Research (2024)
[4] Bubeck, S., et al.: Sparks of Artiffcial General Intelligence: Early experiments with GPT-4. Preprint at https://arxiv.org/abs/2303.12712 (2023)
[5] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 24824–24837 (2022)
[6] Lake, B.M., Baroni, M.: Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. In: Proceedings of the 35th International Conference on Machine Learning (ICML), vol. 80, pp. 2873–2882. PMLR, ??? (2018)
[7] Fodor, J.A., Pylyshyn, Z.W.: Connectionism and cognitive architecture: A critical analysis. Cognition 28(1-2), 3–71 (1988) https://doi.org/10.1016/0010-0277(88) 90031-5
[8] Cayton, L.: Algorithms for manifold learning. Technical Report CS2008-0923, University of California, San Diego (2005)
[9] Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, Cambridge, MA (2016)
[10] Roweis, S.T., Saul, L.K.: Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500), 2323–2326 (2000) https://doi.org/10.1126/ science.290.5500.2323
[11] Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Research 9(86), 2579–2605 (2008)
[12] McInnes, L., Healy, J., Melville, J.: Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018)
[13] Yu, Y., Chan, K.H.R., You, C., Song, C., Ma, Y.: Learning diverse and discriminative representations via the principle of maximal coding rate reduction. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 9422–9434 (2020). https://proceedings.neurips.cc/paper/2020/ffle/6ad4174eba19ad61d63933f5c3e28d7aPaper.pdf
[14] Hospedales, T., Antoniou, A., Micaelli, P., Storkey, A.: Meta-learning in neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 44(9), 5149–5169 (2021) https://doi.org/10.1109/TPAMI.2021. 3079209
[15] Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: Proceedings of the 34th International Conference on Machine Learning (ICML), vol. 70, pp. 1126–1135. PMLR, ??? (2017)
[16] Battaglia, P.W., Hamrick, J.B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., et al.: Relational inductive biases, deep learning, and graph networks. Behavioral and Brain Sciences 41, 125 (2018) https://doi.org/10.1017/S0140525X18001886
[17] Lippl, S., Stachenfeld, K.: A kernel theory of compositional generalization. In: Proceedings of the 13th International Conference on Learning Representations (ICLR) (2025)
[18] Marcus, G.: Deep learning: A critical appraisal. Preprint at https://arxiv.org/ abs/1801.00631 (2018)
[19] Mitchell, M.: Abstraction and analogy-making in artiffcial intelligence. Philosophical Transactions of the Royal Society B 376(1822), 20190663 (2021) https: //doi.org/10.1098/rstb.2019.0663
[20] Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., Man´e, D.: Concrete problems in AI safety. Preprint at https://arxiv.org/abs/1606.06565 (2016)
[21] Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models. Preprint at https://arxiv.org/abs/2001.08361 (2020)
[22] Battaglia, P., Pascanu, R., Lai, M., Rezende, D., Kavukcuoglu, K.: Interaction networks for learning about objects, relations and physics. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 29, pp. 4502–4510 (2016)
[23] Johnson, J., Hariharan, B., Maaten, L., Fei-Fei, L., Zitnick, C.L., Girshick, R.: CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2901–2910 (2017). https://doi.org/10.1109/ CVPR.2017.215

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)