Gemini实战:用AI写CI/CD脚本——Python 服务自动部署到服务器的 GitLab CI 实操
一、这篇实操版要解决什么问题
前一版更偏经验总结,这一版往前走一步:不给整段冗长 YAML,但给出足够可用的核心片段,帮你把“思路”落成“能改、能跑、能上线”的 GitLab CI。
目标场景很明确:
- 项目是 Python 服务
- 部署目标是一台或多台 Linux 服务器
- 服务器上通过 systemd 管理服务
- GitLab Runner 负责打包、上传、触发切换
- 默认分支自动部署到 staging
- production 只允许手动触发
这类设计在 GitLab 里是顺手的,因为 .gitlab-ci.yml 本来就是用来定义 job、stages、variables 和 workflow 的;部署 job 还能直接挂到 environment 上,形成可追踪的 deployment 记录。
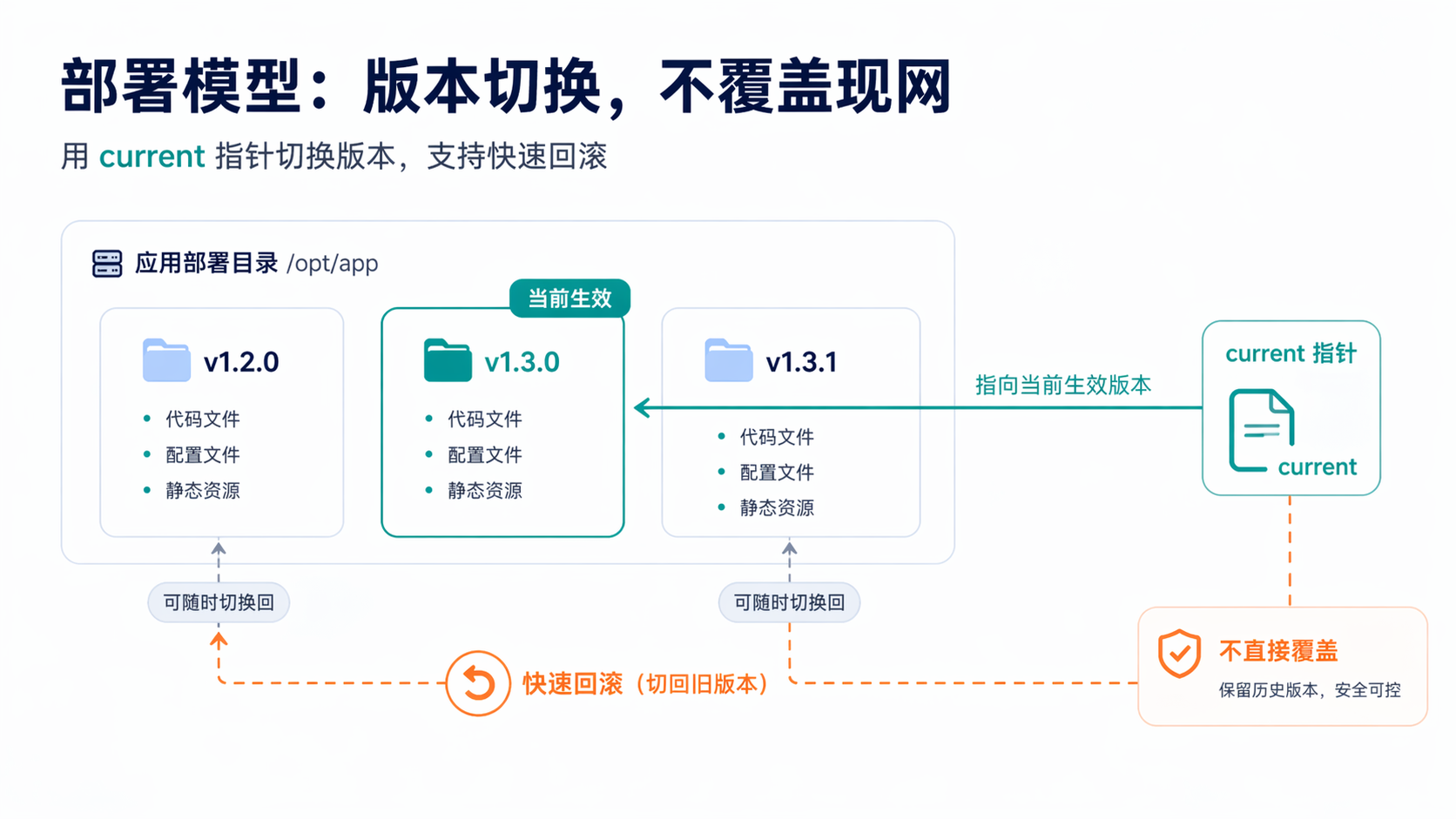
二、先把部署模型定清楚:不要覆盖现网,要做“版本切换”
如果你只记住这篇文章的一句话,我希望是这一句:不要让 CI 直接覆盖线上目录,要让它上传一个新版本,再切换 current。
更稳的服务器目录,一般可以这样设计:
- /srv/myapp/releases/:每次发布一个独立目录
- /srv/myapp/current:当前线上版本的软链接
- /srv/myapp/shared/:日志、上传目录、配置文件等共享内容
- /srv/myapp/venv/:虚拟环境,按团队策略选择复用或每版重建
这样做的好处非常直接:
- 每次发布都有独立版本号
- 健康检查失败时能快速切回上一个 release
- CI 日志、GitLab 环境记录、服务器目录能一一对应
GitLab 的环境和部署页本来就是为了追踪“哪个环境当前部署了哪一次版本”,这种目录结构正好和它的记录模型天然匹配。
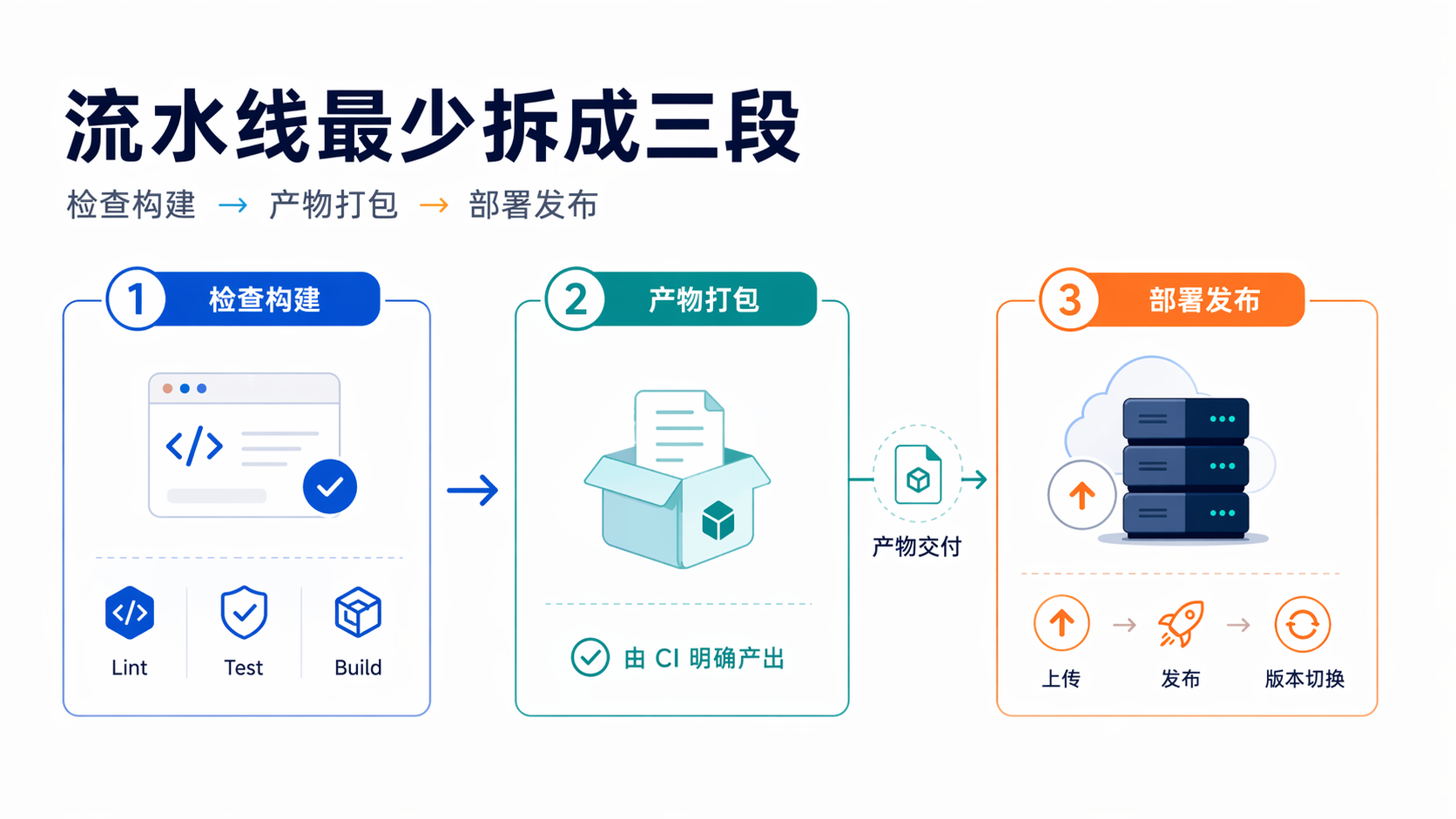
三、流水线不要一把梭,最少拆成这三段
我更建议把 Python 服务自动部署拆成三段:
1)检查阶段——这一段只做代码质量和基础测试,比如:
- black --check
- flake8
- pytest
目的不是追求“测试体系完美”,而是不要让一份明显有问题的提交进入发布阶段。
2)打包阶段——这一段把“可发布内容”做成一个明确产物,比如压缩包。GitLab 的 artifacts 就是干这个的:前一个 job 产出发布包,后一个 job 直接消费。默认情况下,后续 stage 会获取之前 stage 的 artifacts;但如果你改用 needs 或 dependencies,拉取行为会变成更窄的子集,这一点很容易被忽略。
3)部署阶段——这一段做四件事:
- 注入 SSH 密钥
- 上传发布包到服务器
- 在服务器上解压到新 release
- 切换 current 并重启服务,再做健康检查
GitLab 官方关于 SSH key 的建议也很明确:私钥优先作为 file type CI/CD variable 注入,然后在 job 里用 ssh-agent 加载;公钥则放到目标服务器的 authorized_keys。
四、先给一版能直接改的 .gitlab-ci.yml 核心结构
这里不贴完整大文件,只贴最关键的骨架。
- stages 和触发思路
stages:
- verify
- package
- deploy
这三段足够覆盖大多数 Python 服务的自动部署链路:先验证,再产出发布包,最后部署。
如果你只想让默认分支和 tag 进入主流程,可以把触发规则先收紧。GitLab 的 workflow 控制 pipeline 级别的创建,rules 控制具体 job 是否进入流水线。一个够用的思路可以写成:
workflow:
rules:
- if: '$CI_COMMIT_TAG'
- if: '$CI_COMMIT_BRANCH'
- when: never
这不是最复杂的写法,但很适合做第一版骨架。
五、打包阶段:不要把“上传什么”留给部署脚本临场决定
打包阶段的重点不是“压缩一下文件”,而是明确:
- 哪些文件应该进入发布包
- 哪些文件不该被带上服务器
- 发布包怎么命名,能不能和本次提交对应上
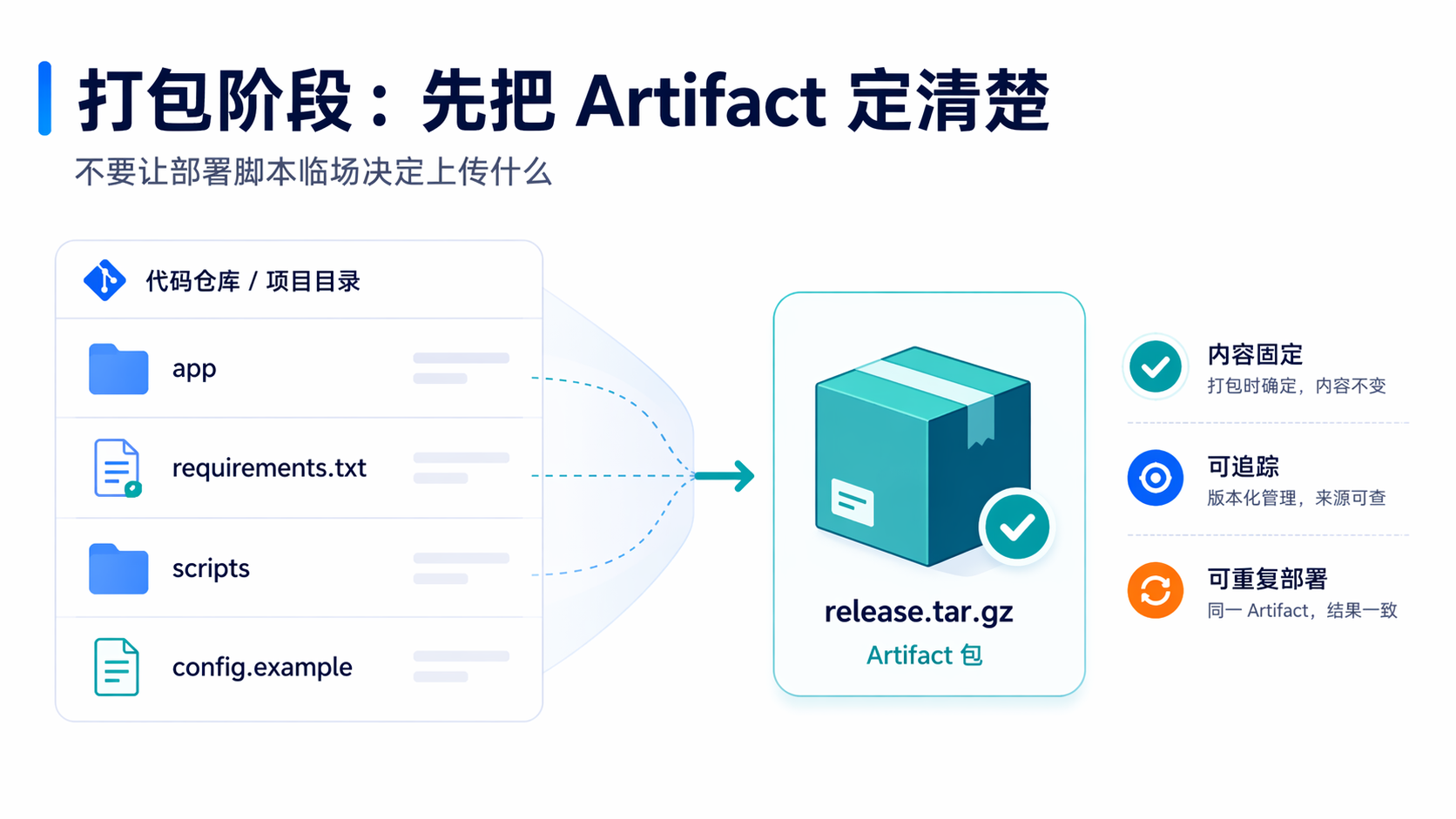
我更推荐把发布包和提交号绑在一起。例如,用 CI_COMMIT_SHORT_SHA 作为 release id,这样 GitLab 流水线、服务器目录和回滚点都能对应起来。CI_COMMIT_SHORT_SHA 本身就是 GitLab 的预定义变量之一。一个足够实用的打包 job,可以长这样:
package_release:
stage: package
image: python:3.12-slim
script:
- mkdir -p build
- tar czf "build/release-${CI_COMMIT_SHORT_SHA}.tar.gz" \
app.py requirements.txt deploy/systemd/myapp.service
artifacts:
paths:
- build/
expire_in: 7 days
rules:
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
- if: '$CI_COMMIT_TAG'
这段的意义有三个:
第一,发布包是明确产物,不再靠部署阶段临时 scp 一堆目录。
第二,文件范围是收口的,不会把测试缓存、临时目录一起发上去。
第三,后面 deploy job 可以稳定消费 build/ 里的内容。GitLab 的 artifacts 就是为这种“前一阶段产出,后一阶段消费”设计的。
六、部署阶段最关键的,不是 SSH,而是“怎么安全地切版本”
1)先把 SSH 准备动作写标准。GitLab 官方推荐的做法,是把私钥作为 file type variable 存进 SSH_PRIVATE_KEY,在 job 中启动 ssh-agent,再把这个文件加进去。
你在 deploy job 里,前置动作通常就是这几步:
before_script:
- 'command -v ssh-agent >/dev/null || ( apt-get update -y && apt-get install -y openssh-client rsync curl bash )'
- eval "$(ssh-agent -s)"
- chmod 400 "$SSH_PRIVATE_KEY"
- ssh-add "$SSH_PRIVATE_KEY"
- mkdir -p ~/.ssh
- chmod 700 ~/.ssh
- ssh-keyscan -H "$DEPLOY_HOST" >> ~/.ssh/known_hosts
这里有两个实战要点:
SSH_PRIVATE_KEY 建议用 file type variable,而不是普通变量,能少掉很多换行和格式问题。known_hosts 最好提前收集,不要用“全局关闭 host key 校验”这种省事但危险的方式。
2)staging 自动发,production 手动发。GitLab 对手动 job 有现成支持,when: manual 可以让 job 变成手动触发;manual_confirmation 则可以增加确认文案,降低误操作。所以我通常会这样分:
Staging
deploy_staging:
stage: deploy
image: python:3.12-slim
environment:
name: staging
url: $STAGING_URL
resource_group: staging
script:
- bash deploy/deploy.sh staging
rules:
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
Production
deploy_production:
stage: deploy
image: python:3.12-slim
environment:
name: production
url: $PROD_URL
resource_group: production
when: manual
manual_confirmation: "确认将当前版本部署到 production?"
script:
- bash deploy/deploy.sh production
rules:
- if: '$CI_COMMIT_TAG =~ /^v\d+\.\d+\.\d+$/'
这几行背后其实体现了三条经验:
- environment 一定要显式写出来,这样 GitLab 才会把它记录成部署环境,并提供环境级预定义变量。
- resource_group 非常适合部署 job,用来限制同一环境一次只跑一个部署,避免多条流水线抢线上。GitLab 官方明确说明,默认 pipeline 是并发的,而 resource_group 就是用来把某类 job 串行化。
- production 最好用手动确认,不要所有 push 都能自动打到线上。
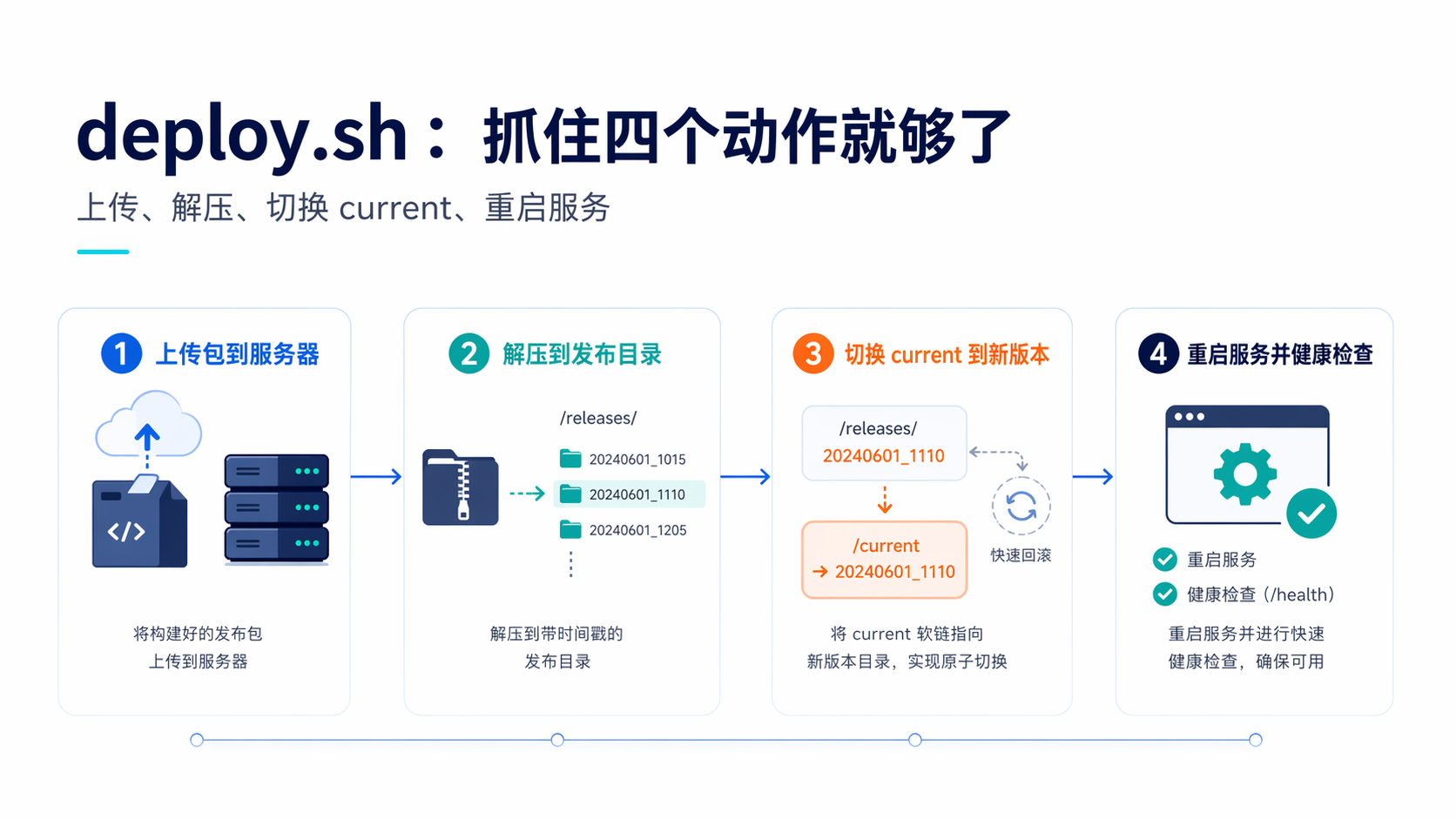
七、deploy.sh 不要写成“大杂烩”,抓住四个动作就够了
真正上服务器的脚本,不需要花哨,但一定要边界清晰。我更建议让它只干四件事:
- 计算本次 release 目录
- 上传并解压发布包
- 切换 current
- 重启服务并做健康检查
下面是一版足够实用的核心片段:
#!/usr/bin/env bash
set -Eeuo pipefail
ENV_NAME="${1:?missing env name}"
RELEASE_ID="${CI_COMMIT_SHORT_SHA:?missing commit sha}"
ARCHIVE="build/release-${RELEASE_ID}.tar.gz"
if [ "$ENV_NAME" = "staging" ]; then
HOST="$STAGING_HOST"
USER="$STAGING_USER"
APP_DIR="$STAGING_APP_DIR"
SERVICE_NAME="$STAGING_SERVICE_NAME"
HEALTH_URL="$STAGING_HEALTH_URL"
else
HOST="$PROD_HOST"
USER="$PROD_USER"
APP_DIR="$PROD_APP_DIR"
SERVICE_NAME="$PROD_SERVICE_NAME"
HEALTH_URL="$PROD_HEALTH_URL"
fi
REMOTE_RELEASE_DIR="${APP_DIR}/releases/${RELEASE_ID}"
ssh "${USER}@${HOST}" "mkdir -p '${REMOTE_RELEASE_DIR}' '${APP_DIR}/shared'"
rsync -az "${ARCHIVE}" "${USER}@${HOST}:${REMOTE_RELEASE_DIR}/"
ssh "${USER}@${HOST}" "cd '${REMOTE_RELEASE_DIR}' && tar xzf 'release-${RELEASE_ID}.tar.gz'"
ssh "${USER}@${HOST}" "
ln -sfn '${REMOTE_RELEASE_DIR}' '${APP_DIR}/current' &&
sudo systemctl restart '${SERVICE_NAME}' &&
sudo systemctl is-active '${SERVICE_NAME}'
"
curl --fail --silent --show-error "${HEALTH_URL}"
这段脚本不长,但已经把关键路径做对了:
- 每次部署一个新 release 目录
- current 用软链接切换
- 服务重启交给 systemd
- 最后用健康检查兜底
如果最后一行健康检查失败,CI 会直接报错,你就不会误以为“脚本执行完了就等于上线成功”。
八、变量别乱放,至少先分成这两层
GitLab 的变量体系很灵活,但越灵活越容易失控。我建议你先做最简单也最有效的一刀切:
1)仓库无关但环境相关的,放 CI/CD variables
例如:
- STAGING_HOST
- STAGING_USER
- STAGING_APP_DIR
- STAGING_SERVICE_NAME
- STAGING_HEALTH_URL
- PROD_HOST
- PROD_USER
- PROD_APP_DIR
- PROD_SERVICE_NAME
- PROD_HEALTH_URL
- SSH_PRIVATE_KEY
GitLab 允许把变量限制到特定 environment scope,这样生产变量不会泄露给 staging job。默认变量作用域是 *,你可以把敏感变量限定到 production 或 staging。
2)GitLab 已经给你的,直接用预定义变量
例如:
- CI_COMMIT_SHORT_SHA
- CI_DEFAULT_BRANCH
- CI_ENVIRONMENT_NAME
- CI_ENVIRONMENT_URL
这些变量已经由 GitLab 注入,不要自己再造一套同义变量,更不要去覆写预定义变量。
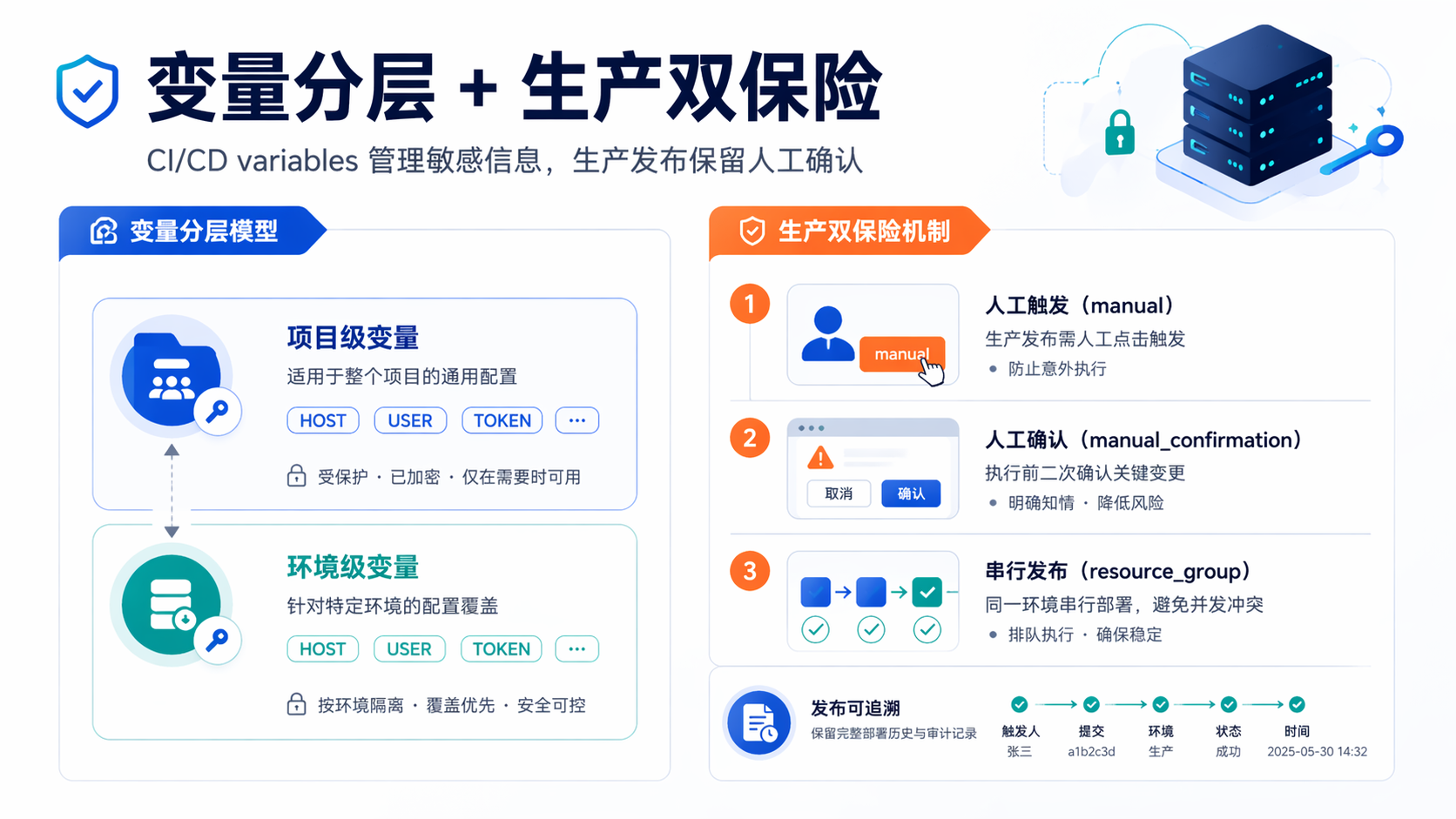
九、把 staging 跑通之后,再考虑生产环境的两道保险
1)保护变量。GitLab 的受保护变量只会暴露给受保护分支或受保护 tag 的 pipeline,这很适合生产环境 secrets。
2)保护环境或审批。如果你的团队流程更严格,可以使用 protected environments,甚至 deployment approvals,让谁能部署到 production 不再只是“谁能点按钮”。GitLab 对受保护环境和部署审批都有原生支持。
这一块的经验很简单:生产安全不要只靠“大家小心点”,最好交给平台规则。
十、让 Gemini 帮你写这类脚本时,提示词要说到这个程度
如果你让 Gemini 写“Python 自动部署到服务器”的 GitLab CI,我建议你至少把这些事实说进去:
你是资深 DevOps 工程师,请为一个 Python 3.12 Web 服务生成 GitLab CI 部署方案。
要求:
1. stages 为 verify、package、deploy
2. 默认分支自动部署 staging
3. 只有 v数字.数字.数字 的 tag 才允许手动部署 production
4. 使用 SSH + rsync 上传发布包
5. 使用 releases/current 目录结构,不允许直接覆盖线上目录
6. 私钥来自 GitLab file type variable: SSH_PRIVATE_KEY
7. deploy job 必须使用 resource_group 串行化
8. 部署完成后必须执行 systemctl restart 和 HTTP 健康检查
9. 输出内容只包含:
- .gitlab-ci.yml 关键片段
- deploy.sh
- 变量清单
- 优先使用 GitLab predefined variables,不要覆写
Google 官方对 Gemini 的建议,本质就是:给角色、给上下文、给约束、给输出范围,而且接受第一次结果需要继续迭代。对 CI/CD 这种强工程边界场景,这种写法明显比“帮我写个部署脚本”靠谱。
十一、最后给三条最容易忽视、但最值得保留的动作
第一条,先用 CI Lint 过配置。GitLab 官方明确支持用 CI Lint 校验 .gitlab-ci.yml。这一步非常值,因为部署类问题很多不是语法错,而是规则和变量边界有坑。
第二条,先让 staging 全链路跑通。生产环境的问题很多来自权限、目录、服务名、端口和健康检查地址,这些都不是 AI 靠猜能猜对的。
第三条,把回滚动作单独写出来。哪怕你今天不自动化回滚,至少也要保证服务器目录结构已经让“切回上一个 release”成为一件简单的事。GitLab 会记录部署历史,但服务器端是否好回退,还是取决于你的目录和脚本设计。
写在结尾(* ̄︶ ̄)
这篇“实操增强版”最想强调的,不是哪几行命令,而是一条更稳的落地顺序:先把发布流程拆开,再把变量收紧,再把部署串行化,最后再把脚本交给 AI 去补。
这样,Gemini 才是在帮你放大工程规则,而不是制造另一份“看起来完整、实际上难维护”的 YAML。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)