转载丨一位用了快9年企查查的老用户,接入CLI两周后有了哪些发现
转载自 LiCode.run
CLI 工具,新时代的查企业范式
最近,企查查上线了一个面向 AI 智能体的数据平台,我第一时间接入了自己的工作场景,用了两周。
作为一个用了快九年的老用户,想分享三件事:CLI是什么,我们应该怎么用,效果是否有颠覆?以及由此引发的一些思考。

一、QCC CLI:67 个 API,从api到mcp到cli
大多数人认识其都是一个App——搜索框输入公司名,出来页面,一个模块一个模块翻看,比如要看工商信息,要看专利信息,要看招投标信息,一个企业可能要花好长时间才能完成信息搜集整理。
现在他们把同样的数据能力拆成了 67 个标准化 CLI命令,mcp还需要消耗上下文,但是CLI已经取代了MCP,因为他没有上下文开销:
-
• MCP 协议——让 AI 自己判断该调什么接口,适合需要推理的场景
-
• CLI 命令行——一条命令直接返回结果,不消耗大模型 Token,适合确定性查询

CLI 全景架构
比如我想查企业,在终端里输入:
qcc company get_company_registration_info "企查查科技股份有限公司"几秒钟,返回一段结构化数据:注册资本、成立日期、法定代表人、经营范围、统一社会信用代码,干干净净。
67 个 API 分四大类:企业基础(14 个)、风险扫描(34 个)、知识产权(6 个)、经营动态(13 个)。单条命令单独用也行,但更有意思的是——把这 67 个接口交给 AI 来编排。
二、实际效果:用 AI 查一遍他们
我的工作场景
我的工作场景经常需要对企业做背调,了解企业全方面信息,找到业务切入点。
以前的流程:打开App → 搜索 → 翻页 → 手动摘录 → 再开百度搜补充信息 → 整理成文档。一套下来至少半小时。
集合我vibe coding开发的 TeamClaw(GitHub已开源)搭了一个 AI 智能体管理平台,把 CLI 接了进去。TeamClaw 是管理 OpenClaw 的企业级平台,可以统一管理多个 gateway实例、AI Agent、 SKILLS 能力、企业级RBAC权限,部署在 Docker 开箱即用。
现在客户经理只需要在对话框里说一句"查一下 XX 公司",剩下的事 AI 自己做,它会自己调用相关CLI,而且整合出来的报告远超人类自己能做到的上限。
AI 实际执行的过程
Skills自动跑了以下这些命令:
qcc company get_company_registration_info "企查查科技" → 工商登记
qcc company get_shareholder_info --json "企查查科技" → 股东结构
qcc company get_actual_controller "企查查科技" → 实控人
qcc company get_key_personnel "企查查科技" → 高管团队
qcc company get_external_investments --json "企查查科技" → 对外投资
qcc company get_annual_reports --json "企查查科技" → 年报数据
qcc operation get_financing_records --json "企查查科技" → 融资记录
qcc operation get_news_sentiment --json "企查查科技" → 新闻舆情
qcc risk get_dishonest_info "企查查科技" → 失信记录
qcc risk get_business_exception "企查查科技" → 经营异常
qcc ipr get_internet_service_info "企查查科技" → ICP/APP
qcc operation get_qualifications "企查查科技" → 资质认证十几个 CLI命令,半分钟跑完。然后 AI 自动整合成一份报告,附带三个图表:
-
股权结构饼图——陈德强、万得信息等持股比例清晰呈现
-
融资历程柱状图——从 A 轮到 IPO 申报的完整时间线
-
对外投资矩形树图——旗下子公司的投资版图
有趣的发现
让AI查一遍,确实翻出了一些我平时不会主动去看的信息:
年报里的参保人数变化——从 2021 年到 2024 年的养老保险参保人数,可以侧面反映公司的扩张还是收缩节奏。这个数据藏在年报的社保信息字段里,App 上要自己找、自己算。AI 一条 get_annual_reports 命令就提取出来了。
数字化资产——get_internet_service_info 返回了ICP 备案网站、APP、小程序和算法备案数量。对于我们做 IT 需求分析的场景,这个维度特别实用:一家企业的数字化程度越高,对云服务、CDN、安全产品的需求就越明确。
风险快筛的效率——失信、经营异常、税务异常、行政处罚,四个命令几秒钟全部扫完。以前在 App 上要分别点进去看,现在完全不用自己去查看。
这些不是什么新数据,App 里都有。但差别在于:以前是我自己决定看什么,经常漏掉;现在是 AI 按预设清单全面扫一遍,不会遗漏。
在工作中的实际应用
我们在 SKILL 里预设了一套商机雷达匹配规则。AI 查完企业信息后,会自动做一轮判断:
-
参保人数超过 10 人 → 推荐 团购
-
分支机构 3 家以上 → 推荐组网专线
-
有进出口业务 → 推荐 SD-WAN / 国际专线
-
ICP 备案网站多、有 APP 和小程序 → 推荐 云服务、CDN 和云安全
-
专利和软著数量多 → 研发能力强,推荐天翼云和算力服务
这些规则不复杂,是业务经验的编码。但以前客户经理要自己对着数据想"这家公司适合推什么产品",现在 AI 替他想了。
一个客户经理跟我说,以前走访前紧张的是"我对这家公司了解够不够"。现在的问题反过来了——"报告里的商机太多,不知道先推哪个"。
三、一个老用户的思考
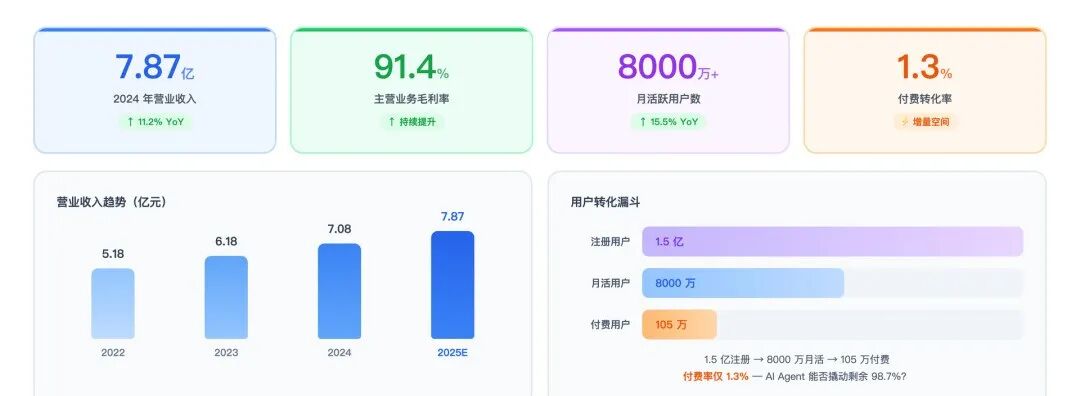
企查查IPO 核心数据
从 App 到API到 CLI,用法变了
用了八年企查查,我对这个产品很熟悉。哪些信息在哪个板块下面,我闭着眼睛都能找到。
但接入 CLI 两周后,我发现自己几乎不打开 App 了。
不是 App 不好用。是消费数据的方式变了——从"我去翻"变成了"AI 去取"。数据还是那些数据,但人和数据之间全部自动化了。
数据本身不是壁垒
在他们的IPO 招股书显示:2024 年营收 7.87 亿元,毛利率 91.4%,注册用户 1.5 亿,月活 8000 万,付费用户 105 万。
91% 的毛利率意味着数据获取成本极低。事实上,企查查的大部分数据来源是公开的——国家企业信用信息公示系统、裁判文书网、知识产权局。天眼查、启信宝拿到的是同一份原料。
真正卖的不是数据,是把散落各处的公开信息清洗、整合、结构化的能力,加上十年建立的品牌认知。
但 AI 时代也在重构护城河:
-
数据清洗的成本在降低。AI 本身就擅长处理非结构化信息,新进入者的门槛比十年前低得多。
-
品牌认知的作用在弱化。当用户通过 AI 间接获取数据,他不太在意底层数据来自哪里——就像你打车的时候不在意司机用的是哪个导航。

AI 时代护城河重构
那什么才是?
我觉得有三个方向是有实质意义的。
第一,从卖事实到卖判断。
企查查现在提供的是事实:"A 公司注册资本 3000 万,有 3 条被执行记录。"
更有价值的是判断:"A 公司信用等级 B+,主要风险在于实控人旗下另外两家公司近期出现经营异常,建议授信额度不超过 500 万。"
事实谁都能查到,判断需要对数据做深度的分析和交叉验证,平台上发布了 17 个行业 SKILL 模板(信用评级、ESG 评估、尽调清单等),这些都是可以给出预判和结论的东西。
但难点也很明显:判断需要持续用真实的业务反馈来校准。一个信用评级模型好不好用,要看它的预测是否准确——这需要时间和大量真实案例的积累。谁先跑起来,谁就先建立起优势。
第二,8000 万月活本身就是护城河。
这一点容易被忽视,他们每月有 8000 万人在搜索企业信息,这些搜索行为本身就是一种极有价值的信号:
-
一家公司突然被大量律师和投资人集中查询——这往往意味着什么事情正在发生,比任何工商变更公示都早。
-
某个行业的搜索量整体上升——可能预示着行业景气度变化。
工商数据是公开的,三家都有。但"谁在查谁"的行为数据是独家的,这种注意力数据如果用好了,比底层的工商数据更有预测价值。类似 Google Trends 预测流感比 CDC 早两周的逻辑。
第三,做企业世界的百科全书。
Karpathy 4 月初提了一个 LLM Wiki 的概念:与其每次都让 AI 从原始数据临时拼装答案,不如先用 AI 把信息编译成一篇结构化的知识页面,后续查询直接读取这个页面,知识持续累积。
他们有 3.65 亿家企业的数据。如果用 AI 为每家企业生成一篇"活的百科页面"——不是字段罗列,而是有上下文的叙述,新数据进来不是覆盖而是修订——那它就不只是一个查询工具,而是一个企业知识库。
Wikipedia 的数据不独家(任何人都可以写百科全书),但它的位置不可替代——因为它最先做到了全面覆盖,所有人都默认引用它。企业信息领域他们就是"默认引用源",只是之前是碎片化引用,现在可以生成完整的企业图谱。
职场社交也是机会
Bloomberg 终端年费 2 万多美元,年收入 120 亿美金。很多人以为它的优势是金融数据,但 Reuters 有几乎一样全的数据。
Bloomberg 真正不可替代的是 35 万交易员在上面建立的工作习惯和社交关系。数据是标准品,但围绕数据形成的使用关系更有价值。
原始数据也是标准品(来自同一组政府公开数据)。但 8000 万用户的搜索行为、各行业 SKILL 的使用积累、未来可能建成的企业知识库——这些围绕数据产生的东西,才是真正难以复制的。
况且现在国内并没有职场社交的APP(领英已经退出中国了),目前这是一个空白。
写在最后
CLI 和Skills 这件事,说明它已经意识到了这个变化。至于能不能从"查数据的工具"变成"AI 时代的企业信息基座",还得看接下来怎么走。
作为他们的老用户,也希望他越走越强,未来空间还是很大,虽然国内很卷,但很多国家根本没有这样的企业信息库,所以长线看仍有很大增长空间。
目前CLI工具公开提供,提供OPC 3个月免费体验,无论你是否付费会员。这点不得不为他们点赞。
引用链接
[1] GitHub: https://github.com/szsip239/teamclaw

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)