5. 缓存-Redis
文章目录
前言
Redis
Redis 是一个开源的、高性能的内存键值数据库,以速度极快、支持丰富的数据结构而闻名,是现代应用架构中非常流行的组件。
一、 介绍
1. 简介
Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 value 就是指Redis的数据类型,可以是String,也可以是List、Hash、Set、 Zset 的数据类型。Redis通常被用作数据库、缓存、消息中间件和实时数据处理引擎。它以速度极快、支持丰富的数据结构而闻名,是现代应用架构中非常流行的组件。
2. 核心特点
redis为什么这么快
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 采用了非阻塞I/O多路复用机制
- 内存存储 (In-Memory):
- 数据主要存储在内存 (RAM) 中,这是 Redis 速度惊人的根本原因(读写操作通常在微秒级别)。
- 它也提供可选的持久化机制,可以将数据异步或同步保存到磁盘,防止服务器重启后数据丢失。
- 丰富的数据结构 (Data Structures):
不仅仅是简单的 Key-Value 字符串!Redis 支持一共五种数据结构:
- Strings: 最基本类型,可以存储文本、数字、二进制数据(如图片片段)。
- Lists: 有序的元素集合,可在头部或尾部插入/删除,适合实现队列、栈、时间线。
- Sets: 无序的唯一元素集合,支持交集、并集、差集等操作,适合标签、共同好友。
- Sorted Sets (ZSets): 带分数的有序唯一元素集合,元素按分数排序,完美适用于排行榜、优先级队列。
- Hashes: 存储字段-值对的集合,非常适合表示对象(如用户信息:field: name, value: “Alice”; field: age, value: 30)。
- Bitmaps / HyperLogLogs / Geospatial Indexes: 特殊用途的数据结构,用于位操作、基数统计(去重计数)、地理位置计算等。
- 高性能与低延迟:
- 内存访问 + 单线程架构 (核心命令执行是单线程,避免了锁竞争) + 高效的网络 I/O 模型 (epoll/kqueue) 使其拥有极高的吞吐量和极低的延迟。
- 持久化 (Persistence):
- RDB (Redis Database File): 在指定时间间隔生成整个数据集的内存快照。恢复快,文件紧凑。适合备份和灾难恢复。
- AOF (Append-Only File): 记录所有修改数据库状态的命令。更安全(最多丢失一秒数据),文件可读性强,但文件通常更大,恢复可能比 RDB 慢。可以同时开启或选择其一。
- 原子操作与事务:
- 所有单条命令的执行都是原子的。
- 支持简单的事务 (MULTI/EXEC),可以将一组命令打包执行(但不支持回滚 - 命令语法错误会导致整个事务不执行,运行时错误不影响其他命令执行)。
- Lua 脚本: 可以执行复杂的、需要多个命令且保证原子性的操作。
- 还有像发布订阅、集群架构等特性
二、 应用场景
1. 应用场景
-
缓存 (Caching): 最常见的用途。将频繁访问的热点数据(如数据库查询结果、页面片段、会话信息)存储在 Redis 中,显著减轻后端数据库压力,提升应用响应速度。
-
会话存储 (Session Store): 存储用户会话信息,易于在多服务器或微服务架构中实现会话共享。
-
排行榜/计数器 (Leaderboards / Counters): 利用 Sorted Sets 可以非常高效地实现实时排行榜。利用 INCR 等命令实现高并发下的计数器(如点赞数、浏览量)。
-
实时系统 (Real-time Systems):
- 消息队列 (Message Queue): 利用 Lists 或 Streams (一种更强大的持久化消息队列数据结构) 实现简单的消息队列。
- 实时分析: 处理实时事件流(如用户活动跟踪、监控数据)。
-
地理空间应用 (Geospatial): 存储地理位置坐标,执行附近位置查询、距离计算等。
-
速率限制 (Rate Limiting): 限制用户 API 调用频率或操作次数。
-
分布式锁 (Distributed Lock): 利用 Redis 的原子操作实现简单的跨进程/跨机器的互斥锁。
2. 数据类型作用场景
-
String可以用来做缓存、计数器、限流、分布式锁、分布式Session等。
-
Hash可以用来存储复杂对象。List可以用来做消息队列、排行榜、计数器、最近访问记录等。
-
Set可以用来做标签系统、好友关系、共同好友、排名系统、订阅关系等。
-
Zset可以用来做排行榜、最近访问记录、计数器、好友关系等。
-
Geo可以用来做位置服务、物流配送、电商推荐、游戏地图等。
-
HyperLogLog可以用来做用户去重、网站UV统计、广告点击统计、分布式计算等。
-
Bitmaps可以用来做在线用户数统计、黑白名单统计、布隆过滤器等。
三、 性能特性
Redis 可以达到极高的性能(官方测试读速度约 11 万次 / 秒,写速度约 8 万次 / 秒)!
1. 内存
基于内存操作
Redis将所有数据存储在内存中,避免了传统数据库的磁盘I/O瓶颈,内存的读写速度远高于磁盘,这使得Redis能够实现超高的响应速度。
内存的读写速度,和,磁盘读写速度的对比
- 最快情况下, 固态 硬盘 速度,大致是 内存速度的 百分之一,
- 最慢情况下, 机械 硬盘 速度,大致是 内存速度的 万分之一,
内存读写速度可以达到每秒数百GB,在微秒级别,而磁盘(特别机械硬盘) 读写速度通常只有数十MB,在毫秒级别, 是数千倍的差距。
对比与传统的关系型数据库比如说MySQL,需要从磁盘加载数据到内存缓冲区才能操作,Redis不需要这个步骤,就避免了磁盘 I/O 的延迟。
2. 高性能数据结构
高效的数据结构
Redis向我们用户提供了value为string, list, hash, set, zset五种基本数据类型来使用,还有几种高级的数据结构例如geo, bitmap, hyperloglog。本文只讨论基本的数据类型了。
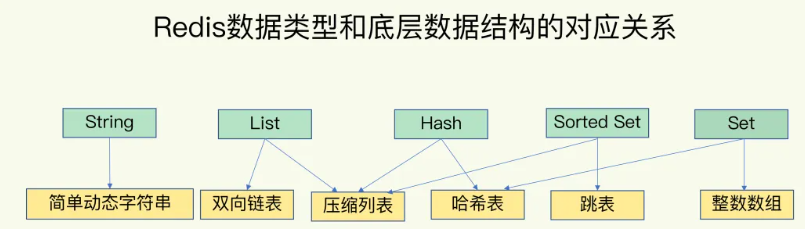
本节分析一下底层实现,这些数据类型底层实现有如下这么些:
-
sds( 简单动态字符串)
-
ziplist(压缩列表)
-
linkedlist(双端链表)
-
hashtable(字典)
-
skiplist(跳表)
这些底层结构能够在内存中高效地存储和操作数据,为Redis的快速性能提供了坚实的基础。
3. 单线程、多路复用
- 单线程
Redis 的单线程设计是其高性能的核心支柱,但它并非字面意义上的“只有一个线程”。Redis 的工作线程(主线程)串行处理所有客户端命令,但存在辅助线程处理异步任务。
为什么坚持核心单线程呢?这可能是一种取舍,如果是多线程的话,需要考虑 共享数据结构需加锁(如 Mutex)、线程上下文切换需要消耗 CPU 周期、线程安全编程难度高一些。
如果采用单线程的话,天然无锁,可以保证操作的原子性;因为是单线程嘛,所以就没有县城上下文切换了;代码就更简单易懂了,也容易维护嘛。
单线程肯定会有不足的:比如说执行了慢命令,(如 KEYS *)会阻塞所有后续请求;单线程无法充分利用多核cpu。
所以可以得出:CPU 并不是Redis的瓶颈 → 避免锁/切换开销 → 单线程更高效
因为Redis使用内存存储数据,所以数据访问非常迅速,不会成为性能瓶颈。此外,Redis的数据操作大多数都是简单的键值对操作,不包含复杂计算和逻辑,因而CPU开销很小。相反,Redis的瓶颈在于内存的容量和网络的带宽,这些问题无法通过增加CPU核心来解决。
Redis 6.x开始引入了多线程, 但是多线程仅仅是在 处理网络IO,Redis 核心命令执行依然是单线程,确保性能和一致性。
- 多路复用
那么,现在说一下Redis 的网络 I/O 处理,采用 事件驱动的 Reactor 模式,结合 I/O 多路复用技术 和 渐进式多线程优化:
Redis 采用 Reactor 模式作为网络模型的基础架构,在这一模式下,Redis 通过一个主事件循环(Event Loop) 持续监听并分发网络事件。
首先,事件分发器:基于 I/O 多路复用技术(如 Linux 的 epoll)实现,负责监控所有客户端连接的 Socket 文件描述符(FD);
然后,事件处理器:为不同事件(如连接、读、写)绑定对应的回调函数。例如:连接事件触发 accept 处理器,创建新客户端连接;读事件触发命令请求处理器,解析并执行 Redis 命令;写事件触发响应回复处理器,将结果返回客户端。
通过 I/O 多路复用,单一线程可同时监听数万个 Socket,仅当 Socket 真正发生读写事件时才触发回调,避免了线程空转和阻塞,这种设计使得 Redis 在单线程下仍能高效处理高并发请求,尤其适合内存操作快速完成的场景
尽管单线程模型简化了数据一致性管理,但网络 I/O 瓶颈在高并发场景下逐渐显现。为此,Redis 从 6.0 版本开始引入渐进式多线程优化:新增的 I/O 线程仅负责网络数据的读取与发送,而命令解析与数据操作仍由主线程单线程执行,这种设计确保了核心数据操作的原子性,避免多线程竞争。
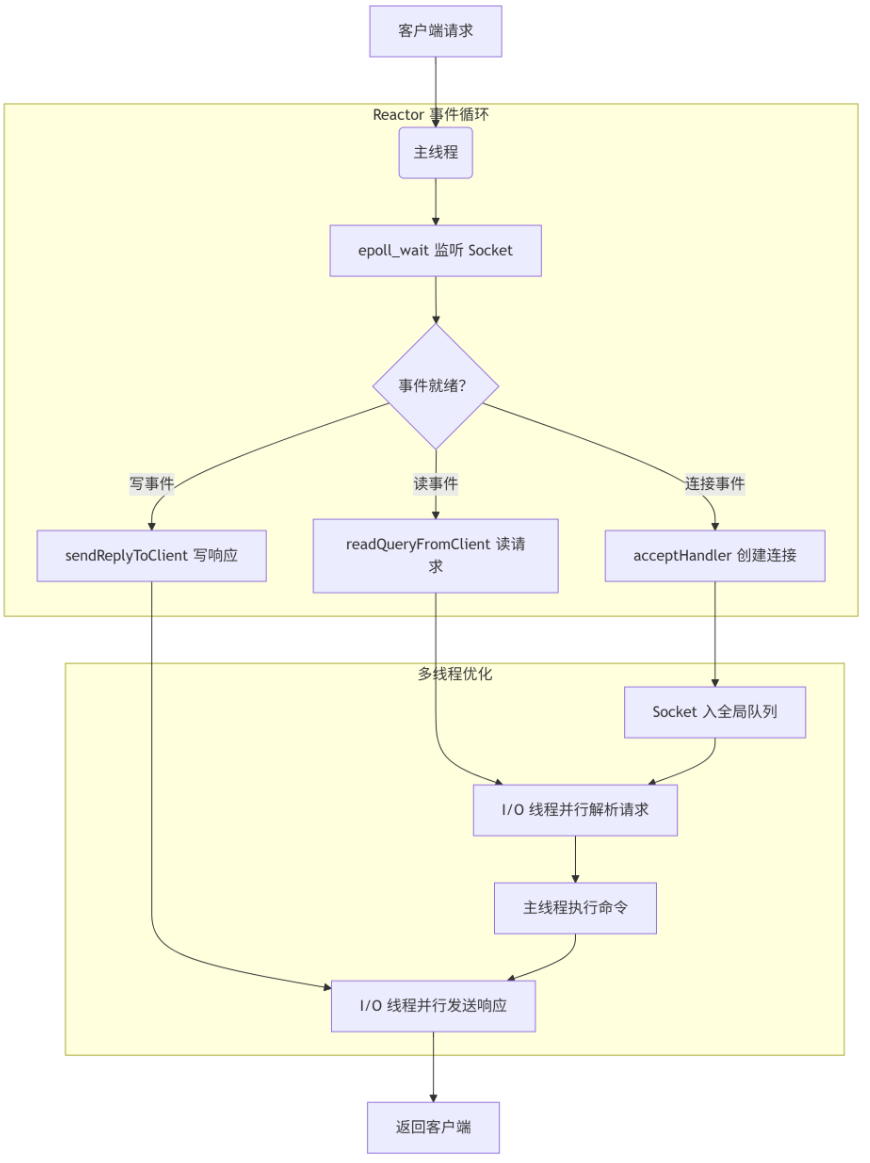
主要流程:
- 主线程接收新连接,将 Socket 分配至全局队列;
- I/O 线程池并行读取请求数据并解析为命令(若启用 io-threads-do-reads),或并行发送响应结果;
- 主线程按顺序执行所有命令,再将结果写入缓冲区供 I/O 线程发送
【用户可通过 io-threads 参数设置线程数(建议为 CPU 核数的 1~1.5 倍),并通过 io-threads-do-reads 控制是否启用读并行化,在高并发网络场景下,此优化可提升吞吐量 40%~50%,同时避免核心逻辑的锁竞争】
四、 异步持久化机制
单机的Redis速度已经独步天下了,倘若遇到系统错误,导致Redis应用程序中断了,由于数据是在内存里面,那不就全部丢失了吗?这就需要 说到Redis的持久化机制了。
Redis的持久化机制包含RDB和AOF两种方式,其核心设计原则是最大化性能,因此持久化操作本质是异步的(主线程非阻塞);
1. RDB(Redis Database)
- 机制
在Redis数据库中RDB持久性以指定的时间间隔执行数据集的时间点快照,就是把某一时刻的数据和状态以RDB文件的形式写到磁盘上。这样一来即使故障宕机,快照文件也不会丢失,当故障恢复时,再将硬盘快照文件直接读到内存,这样数据的可靠性也就得到了保证。
如下图所示:
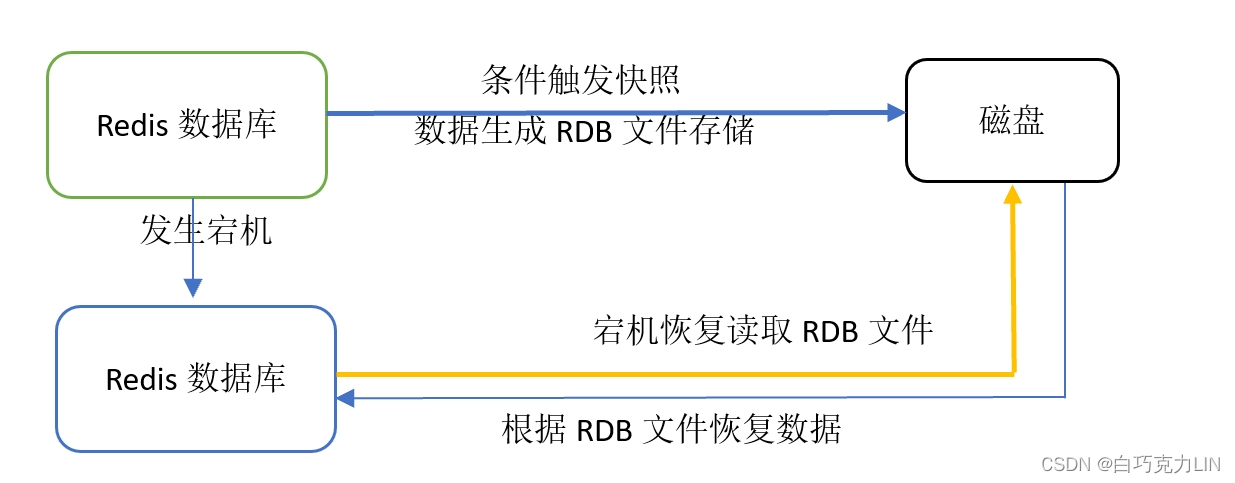
详细来说,它是将内存中的数据以二进制格式生成全量快照(Snapshot),写入 dump.rdb 文件,通过 fork 子进程完成持久化,主进程继续处理请求,仅 fork 操作短暂阻塞(约 1-100ms)。
- 触发
-
自动触发(默认异步),在配置文件里面配置 save m n:如 save 900 1 表示 900 秒内至少 1 次键修改时触发;从节点全量复制时自动触发。
-
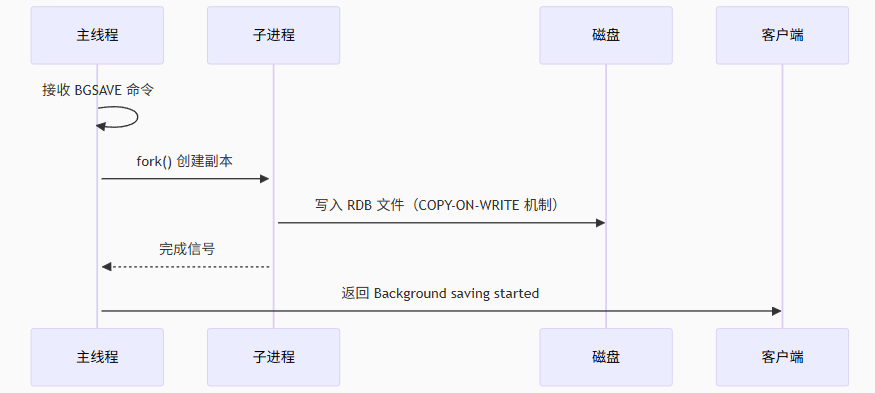
手动触发,就需要命令的形式了,SAVE:同步阻塞主线程,生成快照(不推荐生产环境使用);BGSAVE:异步生成快照,通过子进程完成(默认方式)。
- 影响
这种方式快速生成快照,对性能影响较小,此外呢,文件体积较小,适合备份和灾难恢复。但是,如果是 Redis 服务器在两次快照之间崩溃,可能会丢失部分数据
2. AOF(Append-Only File)
- 机制
AOF持久化是以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录)并以追加的方式写在日志中。
在Redis服务重启时,会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
工作原理如下图所示:
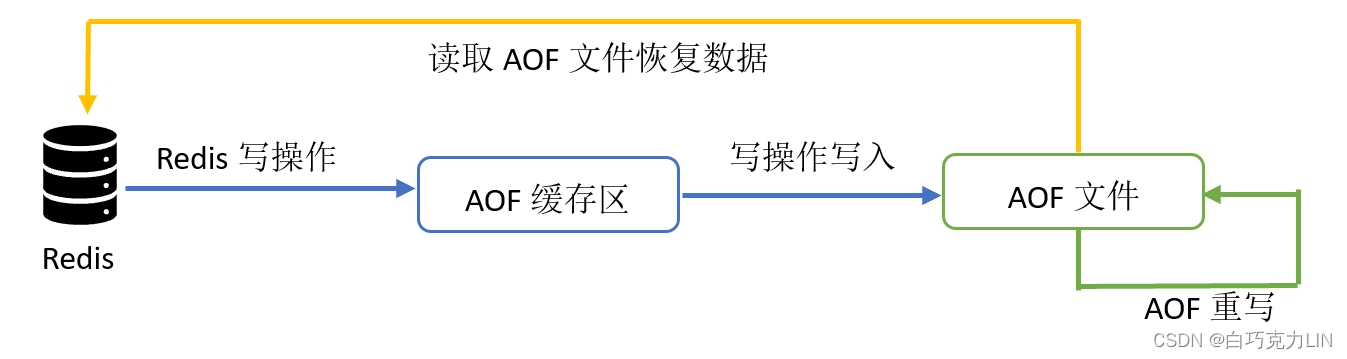
在Redis执行写操作时,不会立刻将写操作写入AOF文件中,而是先将写命令保存在AOF缓存区,根据写入策略将所有写操作保存在AOF文件中。
详细来说,它是将 Redis 执行的所有写命令(如SET、INCR)追加到日志文件(默认名为appendonly.aof),同时在AOF 文件过大时,通过BGREWRITEAOF命令对日志进行瘦身(合并重复命令):创建一个新的AOF文件来替代现有的AOF文件,新旧两个文件所保存的数据库状态是相同的,但 新 AOF文件 去掉 老的 冗余命令,通常体积会较旧AOF文件小很多,达到压缩 AOF 文件体积的目的。
- 触发
随着写入AOF内容的增加,AOF会根据规则进行命令的合并(重写),从而起到AOF文件压缩的目的,避免了文件膨胀。
重写瘦身触发方式:
-
手动:BGREWRITEAOF 命令。
-
自动:满足 auto-aof-rewrite-percentage(默认 100%)和 auto-aof-rewrite-min-size(默认 64MB)条件时触发。
- 影响
这个重写操作是异步的吗?Redis是利用子线程进行复制拷贝,总结来说就是一个拷贝,两处日志。复制过程 不会卡主线程,整个过程是让子进程干活,主线程继续服务用户。
两处日志分别指:
【1】主线程正常处理新操作,把命令记录到 AOF 缓冲区 ,异步刷新到 原来的AOF日志里(比如每秒刷一次磁盘)。
【2】同时,新操作还会被额外记录到 AOF重做缓冲区,等小弟整理完旧日志后,这些新操作会被追加到新的AOF文件里,保证数据不丢失
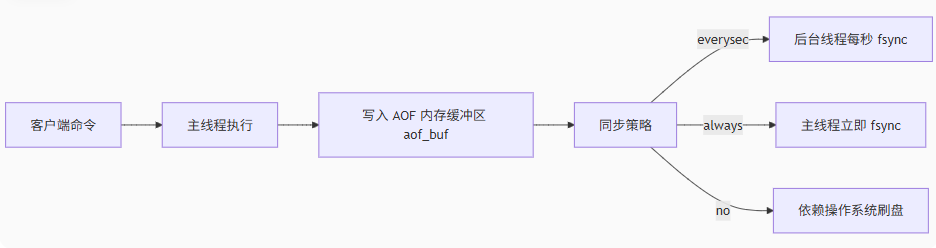
那么AOF这种方式的异步点在哪里呢?
-
写操作:主线程将命令追加到 aof_buf 内存缓冲区(非阻塞)
-
刷盘策略:根据配置异步刷盘
- appendfsync always # 同步写盘(强一致,性能差)
- appendfsync everysec # 每秒异步刷盘(推荐-默认)
- appendfsync no # 依赖操作系统刷盘
这种持久化方式数据安全性高(最多丢失 1 秒数据),支持命令级恢复,但是文件体积大,恢复速度慢,因为是很多命令。
3. 持久化机制
那么Redis是采用哪种方式呢?是同时开启 RDB 和 AOF,利用 RDB 的快速恢复能力和 AOF 的数据安全性,重启时,优先加载RDB恢复数据,再重放AOF增量操作。
- RDB
- 优势:
在使用RDB备份时,Redis父进程实现持久化工作只需要派生一个将完成所有其余工作的子进程即可,这样父进程不需要执行磁盘I/O或类似操作,从而最大限度提高Redis性能。
RDB主要用于大规模的数据恢复、需要定时备份、对数据完整性和一致性要求不高的情况下。
-
劣势:
-
当Redis突然停止工作后,未进行快照备份的数据会导致丢失;
-
内存数据的全量同步,如果数据量太大会导致I/O严重影响服务器性能;
-
RDB依赖于主进程的fork,在更大的数据集中,这可能会导致服务请求的瞬间延迟,fork的时候内存中的数据被克隆一份,导致2倍的膨胀性。
-
- AOF
-
优势:
-
AOF有不同的写入策略,默认是每秒执行写入,其性能也是很好的,而且最多只能丢失一秒的数据;
-
AOF日志是一个仅附加日志,不会出现寻道问题,不会在断电时出现损坏问题,即使有损坏,也可以通过redis-check-aof对AOF文件进行修复;
-
当AOF文件过大,Redis能在后台自动重写AOF,起到AOF文件压缩的目的,避免了文件膨胀;
-
AOF文件内容易于理解,方便我们对其进行修改,从而达到我们想要的效果。
-
-
劣势:
-
AOF文件通常比相同数据集的等效RDB文件大;
-
AOF运行效率要慢于RDB,每秒同步策略效率较好,不同步效率和RDB相同;
-
注意:AOF的优先级高于RDB,当AOF和RDB同时使用时,Redis重启时,只会加载AOF文件,不会加载RDB文件。
五、 部署模式
单一实例的工作模式通常无法保证Redis的可用性和拓展性,Redis提供了三种分布式方案:
- 主从模式
- 哨兵模式
- 集群模式
最初,Redis采用主从模式构建集群。在这种模式下,如果主节点(master)出现故障,需要手动将从节点(slave)转换为主节点。然而,这种模式在故障恢复方面效率不高。
为了提高系统的可用性,Redis引入了哨兵模式。在哨兵模式中,一个哨兵集群负责监控主节点和从节点。如果检测到主节点故障,系统可以自动将从节点晋升为新的主节点。这提高了故障恢复的自动化程度。
尽管如此,哨兵模式仍然面临内存容量和写入性能的限制,因为这种模式的写入能力仍然局限于单个节点。为了解决这一问题,Redis在3.x版本之后推出了Cluster集群模式。Cluster模式通过数据分片和节点的水平扩展,实现了更高效的内存利用和写入性能。
| 特性/配置 | Redis 主从复制 | Redis 哨兵 | Redis 集群 |
|---|---|---|---|
| 主要目的 | 数据备份与读写分离 | 高可用性和故障自动切换 | 高并发和数据分散处理 |
| 架构 | 一个主节点和多个从节点 | 监控主从结构并自动切换 | 多个主节点,数据分片 |
| 数据复制 | 主节点到从节点 | 监控并管理主从复制 | 每个主节点管理自己的数据集 |
| 故障转移机制 | 手动或哨兵自动切换 | 自动故障转移 | 自动处理节点故障 |
| 可伸缩性 | 有限,依赖主节点 | 为主从结构增加高可用性 | 高,因为数据分布式处理 |
| 使用场景 | 数据备份和读扩展 | 关键应用的高可用性 | 大规模应用的高性能需求 |
| 设置复杂度 | 相对简单 | 中等,需配置哨兵 | 复杂,需规划数据分区 |
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
Redis上篇–知识点总结
Redis中篇–应用
Redis教程——持久化(RDB)
Redis教程——持久化(AOF)
再谈Redis三种集群模式:主从模式、哨兵模式和Cluster模式

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)