大模型技术入门到实战:小白程序员必备学习路线 & 收藏资源
本文提供从入门到实战的大模型技术学习路线,涵盖基础原理、Prompt工程、RAG技术、AI Agent开发、大模型微调及部署等关键知识点。通过系统化学习,读者可快速掌握大模型核心技术并应用于实际场景。内容详细介绍LLM与Transformer的工作机制、Prompt工程技巧、RAG原理与应用、AI Agent开发流程、高效微调方法及部署策略,为读者提供全面实用技术指导。
大模型技术知识库
从入门到实战|精简高效学习版
推荐学习顺序
- 第一章:大模型基础原理→ 理解LLM和Transformer(1-2天)
- 第二章:Prompt工程 → 掌握与大模型沟通的核心技能(1天)
- 第三章:RAG技术 → 构建私有知识库的关键技术(2-3天)
- 第四章:AI Agent → 从对话到自主任务执行(2-3天)
- 第五章:大模型微调→ LoRA/QLoRA专业化定制(2-3天)
- 第六章:大模型部署→ API调用到生产部署(1-2天)
- 第七章:行业应用→ 各领域落地案例(按需)
第一章:大模型基础原理(LLM & Transformer)
从零理解大语言模型的核心机制
1.1 什么是大语言模型(LLM)
- 定义:基于海量文本训练、参数规模超过百亿的神经网络模型
- 核心能力:文本生成、理解、推理、代码生成、多语言翻译
- 代表模型:GPT-4、Claude、LLaMA、DeepSeek、Qwen、GLM
- 训练规模:参数量从数十亿到数千亿(如GPT-4约1.8T参数)
- 涌现能力:模型在足够大规模后突然涌现出推理、逻辑、情感理解等新能力

1.2 Transformer 架构精要
- 核心机制:自注意力机制(Self-Attention)— 让每个词关注句子中所有其他词
- 注意力公式:Attention(Q,K,V) = softmax(QK^T / √d_k) × V
- 多头注意力:并行多个注意力头,捕捉不同维度的语义关系
- 位置编码:通过sin/cos函数注入位置信息(因Transformer本身无序列感知)
- Encoder-Decoder结构:Encoder理解输入,Decoder生成输出
- 仅Decoder结构:GPT系列采用,适合文本生成任务
- 层归一化(LayerNorm)+ 残差连接:保证深层网络训练稳定性
1.3 LLM 训练流程(三阶段)
- 阶段1 — 预训练(Pre-training):海量无标注文本,学习语言规律,自回归预测下一个token
- 阶段2 — 监督微调(SFT):人工标注的问答对,让模型学会指令跟随
- 阶段3 — RLHF(人类反馈强化学习):人类评分 → 奖励模型 → PPO强化学习优化
- Tokenization:BPE/WordPiece将文字切分为token,中文约1字=1-2token
- Context Window:模型一次能处理的最大token数(如4K/8K/128K)
1.4 核心技术生态图
- LLM(基础能力)→ Prompt工程(使用技巧)→ RAG(外挂知识)→ Agent(自主行动)→ 微调(专业化)
- 向量数据库:将文本转为高维向量,支持语义相似检索
- 知识图谱:结构化知识表示,补充LLM的推理弱点
- Function Calling:LLM调用外部工具/API的标准接口
- AGI方向:通过多模态+多Agent协作趋近通用人工智能
1.5 关键概念速查
- Temperature:控制输出随机性(0=确定,1=创意,>1=混乱)
- Top-P(核采样):从累积概率达P的token中采样,控制多样性
- Hallucination(幻觉):模型编造不存在的事实,主要来源于训练数据偏差
- Grounding:将模型输出与真实数据源关联,减少幻觉
- Embedding:文本的语义向量表示,语义相近的文本向量距离近
- In-context Learning:无需微调,仅通过提示词中的示例让模型学习新任务
第二章:Prompt工程与提示词技巧
用最少的输入,得到最好的输出
2.1 Prompt五大分类体系
- 【直接型】Zero-shot(无示例直接提问)/ Few-shot(给2-5个示例)/ ReAct(推理+行动交替)
- 【链式型】CoT思维链 / ToT思维树 / Self-Consistency自洽 / Reflexion反思
- 【图型】GoT思维图(多路径融合)
- 【生成型】APE自动提示工程 / Automatic CoT
- 【集成型】RAG检索增强 / ART自动推理工具 / PAL程序辅助语言
2.2 必掌握的核心策略(按效果排序)
- ★★★ CoT思维链:‘请一步一步思考…’ — 复杂推理题准确率提升40%+
- ★★★ Few-shot示例:提供2-3个格式示例,强制模型按格式输出
- ★★★ 角色设定:‘你是一位有10年经验的…’ — 激活专业知识域
- ★★☆ Self-Consistency:同一问题生成多个答案,投票选最一致的
- ★★☆ ReAct:让模型先Reason(推理)再Act(执行),适合工具调用
- ★★☆ 结构化输出:‘请以JSON格式输出,包含字段:title/summary/tags’
- ★☆☆ ToT思维树:探索多条推理路径,回溯剪枝,适合复杂规划
2.3 Prompt优化9大方法
- 明确性:用具体数字代替模糊描述(‘300字’ 而非 ‘简短’)
- 结构化:使用XML/Markdown分隔不同部分()
- 约束条件:明确告知不要什么(‘不要使用技术术语’ / ‘不超过500字’)
- 示例驱动:'输入→输出’对照示例比任何描述都有效
- 分步拆解:把大任务拆成子任务,逐步让模型完成
- 系统提示词:在System角色中设定持久行为规则
- 温度控制:创意类任务T=0.7-1.0,精确类任务T=0-0.3
- 迭代优化:记录每次Prompt变化和结果,找规律
- 负面提示:明确告知避免的内容(‘不要提供法律建议’)
2.4 万能提问模板(7步法)
- Step 1 — 角色:你是一位[职业/专家类型]
- Step 2 — 背景:当前情况是[具体上下文]
- Step 3 — 任务:我需要你[具体动作动词+目标]
- Step 4 — 格式:请以[格式:列表/表格/JSON/Markdown]输出
- Step 5 — 约束:要求[字数/语气/禁止内容]
- Step 6 — 示例:参考以下示例:[输入→输出示例]
- Step 7 — 验证:输出后请检查是否符合[验证标准]
2.5 实战Prompt速查表
- 代码生成:‘用Python实现[功能],要求:1)有注释 2)处理异常 3)给出使用示例’
- 文档总结:‘请提取以下文档的核心要点,用5条bullet point输出,每条不超过30字’
- 对比分析:‘请对比[A]和[B]的优缺点,输出Markdown表格,包含:维度/A的表现/B的表现’
- 方案设计:‘请作为[角色],为[场景]设计一个[方案],要包含:背景/目标/方案/风险/评估’
- 调试帮助:‘以下代码报错[错误信息],请分析原因并给出修复方案,标注修改位置’
第三章:RAG技术(检索增强生成)
让大模型能读懂你的私有知识库
3.1 RAG核心原理
- 定义:Retrieval-Augmented Generation — 先检索相关文档,再让LLM基于检索结果生成答案
- 解决的问题:LLM知识截止日期、幻觉问题、私有知识无法访问
- 核心公式:RAG = 向量检索(Retrieval)+ 上下文注入(Augmentation)+ LLM生成(Generation)
- vs 微调:RAG无需训练,实时更新知识;微调需要训练,知识内化模型参数
3.2 RAG标准流程(离线+在线)
- 【离线阶段— 建库】文档加载(Load) → 文本切片(Chunk) → 向量化(Embed) → 存入向量库(Store)
- 【在线阶段— 检索】用户提问 → Query向量化 → 相似度检索 → 取TopK文档
- 【生成阶段】将检索文档 + 用户问题组装成Prompt → 送入LLM → 生成答案
- 切片策略:固定长度(512/1024 tokens) + 重叠(50-100 tokens)防止语义截断
- Embedding模型推荐:BAAI/bge-large-zh(中文)、text-embedding-3-small(OpenAI)
- 向量库选择:Chroma(轻量本地)/ Milvus(生产级)/ Pinecone(云端)/ FAISS(离线)
3.3 高级RAG技术(15种优化)
·【预处理优化】
- ① LLM密度优化:用LLM清洗文档,去除噪声和冗余
- ② 分层索引:先建摘要索引,再建细节索引,两级检索
- ③ HyDE假设文档:先让LLM生成假设答案,用答案向量检索(提升语义匹配)
- ④ QA对生成:从文档自动生成问答对,增强检索多样性
- ⑤ 去重优化:语义去重,消除重复内容干扰
·【检索优化】
- ⑥ 查询改写:LLM将用户问题改写为更适合检索的形式
- ⑦ 多查询检索:同一问题生成多个变体查询,取并集结果
- ⑧ 混合检索:向量检索(语义)+ BM25关键词检索(精确),融合排序
- ⑨ 路由检索:根据问题类型选择不同数据源/索引
·【后处理优化】
- ⑩ Rerank重排序:用交叉编码器对检索结果重新排序,取最相关的
- ⑪ 上下文压缩:只保留检索文档中最相关的句子,减少token消耗
- ⑫ 自反思RAG:让LLM评估检索结果是否够用,不够则再检索
3.4 Rerank模型部署实战
·工具:TEI(Text Embedding Inference)— HuggingFace官方推理框架
·推荐模型:BAAI/bge-reranker-large(中英文,效果好)
·Docker部署命令:
· docker run -p 8080:80 -v /data:/data ghcr.io/huggingface/text-embeddings-inference:cpu-1.2 --model-id BAAI/bge-reranker-large
·LlamaIndex集成:使用 CustomRerank NodePostProcessor
· rerank = CustomRerank(top_n=3, model=‘BAAI/bge-reranker-large’)
·评估指标:MRR(平均倒数排名)、NDCG(归一化折现累积增益)
3.5 RAG vs Agent 选型指南
·选RAG的场景:有固定知识库、问答类任务、需要引用来源、延迟要求低
·选Agent的场景:需要多步推理、调用外部API、动态决策、执行操作
·融合使用:Agent + RAG = 智能体用RAG作为工具之一(最佳实践)
·典型案例:法律咨询(RAG检索法律条文)+ Agent(自动生成合同草稿)

第四章:AI Agent智能体开发
从对话机器人到自主执行任务的智能体
4.1 Agent核心概念
- 定义:Agent = LLM推理(大脑)+ 工具调用(手脚)+ 观察反馈(感知)的自主循环系统
- 核心循环:感知(Perceive) → 思考(Think) → 行动(Act) → 观察(Observe) → 循环
- 与普通LLM区别:LLM是单次问答;Agent是多步自主任务执行
- 自主性:Agent能自行规划步骤、调用工具、处理错误、完成复杂任务
4.2 Agent四大核心组件
- ① 规划模块(Planning):任务分解 + 子任务排序 + 依赖关系分析
- ② 记忆模块(Memory):短期(对话上下文)/ 长期(向量数据库)/ 工具记忆
- ③ 工具模块(Tools):函数调用、API集成、数据库查询、浏览器操作
- ④ 执行模块(Execution):按规划调用工具,处理返回结果,更新状态
4.3 Function Calling(工具调用)
- 原理:LLM输出结构化JSON描述要调用的函数和参数,代码层执行后返回结果
- 标准流程:定义函数Schema → LLM决定调用哪个函数 → 执行函数 → 结果反馈给LLM
- 函数Schema示例(OpenAI格式):
- {“name”: “get_weather”, “parameters”: {“location”: “string”, “date”: “string”}}
- 支持并行调用:新版本支持一次调用多个函数(Parallel Function Calling)
- 常用工具库:LangChain Tools / LlamaIndex Tools / 自定义Python函数
4.4 主流Agent框架对比
- LangChain:最流行,生态最丰富,但代码抽象层过多,调试较复杂
- LangGraph:LangChain的有向图版本,支持条件分支和循环,适合复杂工作流
- AutoGen(微软):多Agent协作,支持代码执行,适合编程类任务
- CrewAI:角色扮演框架,多个专业Agent组成团队协作
- ReAct模式:最基础,推理+行动+观察循环,容易理解和调试
- 推荐入门路径:ReAct → LangChain Agent → LangGraph复杂工作流
4.5 Agent十大趋势(2025-2026)
- ① 解决真实痛点:从Demo转向垂直行业刚需场景
- ② ToB企业部署:私有化部署成为主流,数据安全优先
- ③ 商业模式成熟:SaaS订阅/API调用/效果付费三种模式
- ④ 硬件集成:与机器人/IoT设备结合,走向物理世界
- ⑤ 超越聊天机器人:执行端到端业务流程,而非简单问答
- ⑥ 多平台融合:一个Agent服务多个入口(微信/飞书/浏览器)
- ⑦ 多模型协作:不同专长LLM组合,主模型+专家模型
- ⑧ 企业私有化:数据不出企业,私有知识库+私有部署
- ⑨ PM角色转变:产品经理需懂AI能力边界,成为Agent产品设计师
- ⑩ 评估体系建立:可靠性、可解释性、安全性成为核心指标
4.6 Agent开发实战要点
- 工具设计原则:每个工具职责单一,输入输出定义清晰
- 错误处理:必须有重试机制 + 降级策略 + 超时控制
- Prompt优化:System Prompt中明确Agent的角色、能力边界、输出格式
- 观察反馈:工具执行结果要简洁,避免把大量原始数据传回LLM
- 调试技巧:记录每步的Thought/Action/Observation,用日志追踪执行链
- 成本控制:减少不必要的LLM调用,缓存重复查询结果

第五章:大模型微调技术(PEFT / LoRA)
用最小的成本,让通用模型变成专业模型
5.1 为什么需要微调
- 通用LLM的局限:不懂企业内部术语、无法遵循特定格式、回答风格不符
- 微调的收益:专业领域准确率提升、输出格式标准化、减少幻觉
- 微调 vs RAG:微调改变模型行为,RAG扩展模型知识;实际上经常结合使用
- 全量微调的问题:成本极高(需要80G+ VRAM),容易遗忘原始能力(灾难性遗忘)
- PEFT方案:只训练少量参数(0.1%-1%),效果接近全量微调
5.2 11种高效微调方法速览
·【软提示类】
- ① Prefix Tuning:在每层Transformer前添加可训练的前缀向量
- ② Prompt Tuning:只在输入层添加soft prompt,最轻量
- ③ P-Tuning v2:深层Prompt Tuning,适合NLU任务,效果接近全量微调
·【低秩分解类(主流)】
- ④ LoRA:在注意力矩阵旁添加低秩分解矩阵(A×B),只训练A和B
- 核心:W’ = W + ΔW = W + A×B,其中rank(A×B) << rank(W)
- ⑤ DyLoRA:动态调整LoRA的rank,训练更灵活
- ⑥ AdaLoRA:自适应分配各层的rank,重要层rank大,次要层rank小
- ⑦ QLoRA:量化+LoRA,4bit量化节省显存,在消费级GPU上训练70B模型
- 核心创新:NF4量化 + Double Quantization + Paged Optimizer
- ⑧ QA-LoRA:专为量化感知的LoRA变体
- ⑨ LongLoRA:扩展上下文窗口的LoRA,支持超长文档微调
·【其他】
- ⑩ VeRA:比LoRA参数更少,使用随机固定矩阵
- ⑪ S-LoRA:服务多LoRA适配器的系统,支持动态加载
5.3 LoRA 实战指南
·PEFT库安装:pip install peft transformers datasets accelerate
·关键超参数:r(rank,通常4-64)/ alpha(缩放因子,通常=r或2r)/ dropout
·目标模块:通常是q_proj/v_proj(注意力的Q和V矩阵)
·代码示例(核心部分):
· from peft import LoraConfig, get_peft_model
· config = LoraConfig(r=16, lora_alpha=32, target_modules=[‘q_proj’,‘v_proj’])
· model = get_peft_model(base_model, config)
·训练框架:Hugging Face Trainer / LLaMA-Factory / Axolotl(推荐)
·数据格式:Alpaca格式 {instruction, input, output} 或 ShareGPT格式
5.4 微调实践建议
·数据量:高质量1000条数据 > 低质量10000条数据
·数据质量:确保示例多样性,避免重复和错误标注
·显存要求:7B模型 + QLoRA ≈ 10GB VRAM(单张3090可跑)
·训练时长:1000条数据约1-2小时(单卡A100)
·评估方式:ROUGE/BLEU自动评估 + 人工评估(必须)
·过拟合防范:early stopping,验证集loss不再下降时停止
·模型合并:训练完用merge_and_unload将LoRA权重合并到基础模型
那么如何学习大模型 AI ?
对于刚入门大模型的小白,或是想转型/进阶的程序员来说,最头疼的就是找不到系统、全面的学习资源,要么零散不成体系,要么收费高昂,白白浪费时间走弯路。今天就给大家精心整理了一份全面且免费的AI大模型学习资源包,覆盖从入门到实战、从理论到面试的全流程,所有资料均已整理完毕,免费分享给各位!
核心包含:AI大模型全套系统化学习路线图(小白可直接照做)、精品学习书籍+电子文档、干货视频教程、可直接上手的实战项目+源码、2026大厂面试真题题库,一站式解决你的学习痛点,不用再到处搜集拼凑!
👇👇扫码免费领取全部内容👇👇

1、大模型系统化学习路线
学习大模型,方向比努力更重要!很多小白入门就陷入“盲目看视频、乱刷资料”的误区,最后越学越懵。这里给大家整理的这份学习路线,是结合2026年大模型行业趋势和新手学习规律设计的,最科学、最系统,从零基础到精通,每一步都有明确指引,帮你节省80%的无效学习时间,少走弯路、高效进阶。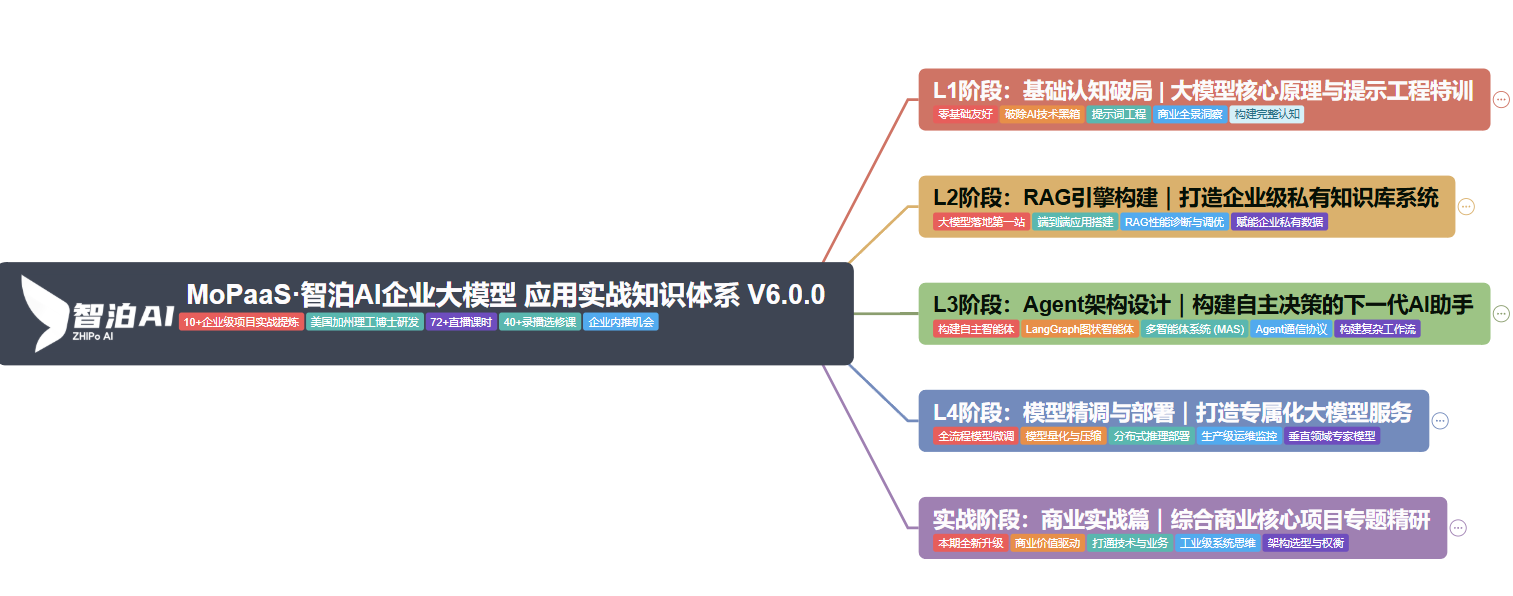
2、大模型学习书籍&文档
理论是实战的根基,尤其是对于程序员来说,想要真正吃透大模型原理,离不开优质的书籍和文档支撑。本次整理的书籍和电子文档,均由大模型领域顶尖专家、大厂技术大咖撰写,涵盖基础入门、核心原理、进阶技巧等内容,语言通俗易懂,既有理论深度,又贴合实战场景,小白能看懂,程序员能进阶,为后续实战和面试打下坚实基础。

3、AI大模型最新行业报告
无论是小白了解行业、规划学习方向,还是程序员转型、拓展业务边界,都需要紧跟行业趋势。本次整理的2026最新大模型行业报告,针对互联网、金融、医疗、工业等多个主流行业,系统调研了大模型的应用现状、发展趋势、现存问题及潜在机会,帮你清晰了解哪些行业更适合大模型落地,哪些技术方向值得重点深耕,避免盲目学习,精准对接行业需求。值得一提的是,报告还包含了多模态、AI Agent等前沿方向的发展分析,助力大家把握技术风口。

4、大模型项目实战&配套源码
对于程序员和想落地能力的小白来说,“光说不练假把式”,只有动手实战,才能真正巩固所学知识,将理论转化为实际能力。本次整理的实战项目,涵盖基础应用、进阶开发、多场景落地等类型,每个项目都附带完整源码和详细教程,从简单的ChatPDF搭建,到复杂的RAG系统开发、大模型部署,难度由浅入深,小白可逐步上手,程序员可直接参考优化,既能练手提升技术,又能丰富简历,为求职和职业发展加分。

5、大模型大厂面试真题
2026年大模型面试已从单纯考察原理,转向侧重技术落地和业务结合的综合考察,很多程序员和新手因为缺乏针对性准备,明明技术不错,却在面试中失利。为此,我精心整理了各大厂最新大模型面试真题题库,涵盖基础原理、Prompt工程、RAG系统、模型微调、部署优化等核心考点,不仅有真题,还附带详细解题思路和行业踩坑经验,帮你精准把握面试重点,提前做好准备,面试时从容应对、游刃有余。

6、四阶段精细化学习规划(附时间节点,可直接照做)
结合上述资源,给大家整理了一份可直接落地的四阶段学习规划,总时长约2个月,小白可循序渐进,程序员可根据自身基础调整节奏,高效掌握大模型核心能力,快速实现从“入门”到“能落地、能面试”的跨越。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献241条内容
已为社区贡献241条内容

所有评论(0)