从数据集成到AI智能体:行知平台的技术范式演进
一、数据集成的范式转移

企业数据管理正经历从"连接工具"向"认知智能体"的根本性转变。传统数据集成平台的核心任务是解决系统间的数据搬运问题——通过硬编码接口、定时同步任务和人工配置,将分散在ERP、电商平台、财务系统中的数据汇聚到统一仓库。这种模式在系统规模可控时尚能运转,但随着业务系统数量膨胀、数据链路复杂度指数级增长,传统集成架构暴露出三个结构性缺陷:语义断层(系统间数据定义互不兼容)、被动响应(仅能在故障发生后人工排查)、以及高维护成本(每条集成链路都需要独立开发与运维)。
行知平台的架构设计正是针对上述痛点,将平台定位从"数据搬运工"升级为"数据智能体"——不仅完成数据流转,更通过AI本体图谱、自然语言交互和自动化血缘分析,赋予平台对业务语义的理解能力与自主决策能力。
二、传统集成模式的局限性
在传统的技术实现中,数据集成通常呈现以下特征:
点对点硬连接:每新增一个业务系统(如金蝶、用友、某电商平台),都需要独立开发对接接口,缺乏统一的语义层进行数据标准映射。
静态元数据管理:数据表结构、字段定义以文档或孤立元数据库形式存在,与实际数据流脱节,无法反映数据在业务链条中的真实含义。
人工驱动的质量监控:数据质量问题依赖业务人员事后发现,缺乏基于规则的自动化校验与异常预警机制。
固定报表输出:数据消费端以预设报表为主,业务人员获取洞察需要依赖IT部门排期开发,响应周期长。
上述模式本质上是一种"无记忆"的数据管道——数据流过即消失,平台不对业务语义进行沉淀,也无法基于历史链路进行推理。
三、行知平台的智能化重构

行知平台通过五大能力域的重新设计,实现了从被动集成到主动智能的跨越。
3.1 数据资产:从静态定义到语义治理

传统集成平台中的数据标准通常以人工维护的Excel或文档形式存在。行知平台将数据资产治理升级为结构化语义管理:通过模型资产管理模块建立标准字段库、数据类型规范与字段语义标注体系,使不同系统间的"客户编码""订单金额"等字段具备机器可理解的统一语义。同时,数据质量规则模块支持配置完整性、准确性、一致性、时效性等多维度校验规则,实现从人工抽检到自动化监控的转变。数据生命周期管理则覆盖了从采集、存储、使用到归档销毁的全流程合规管控。
3.2 数据血缘:从文档追溯 to 图谱推理
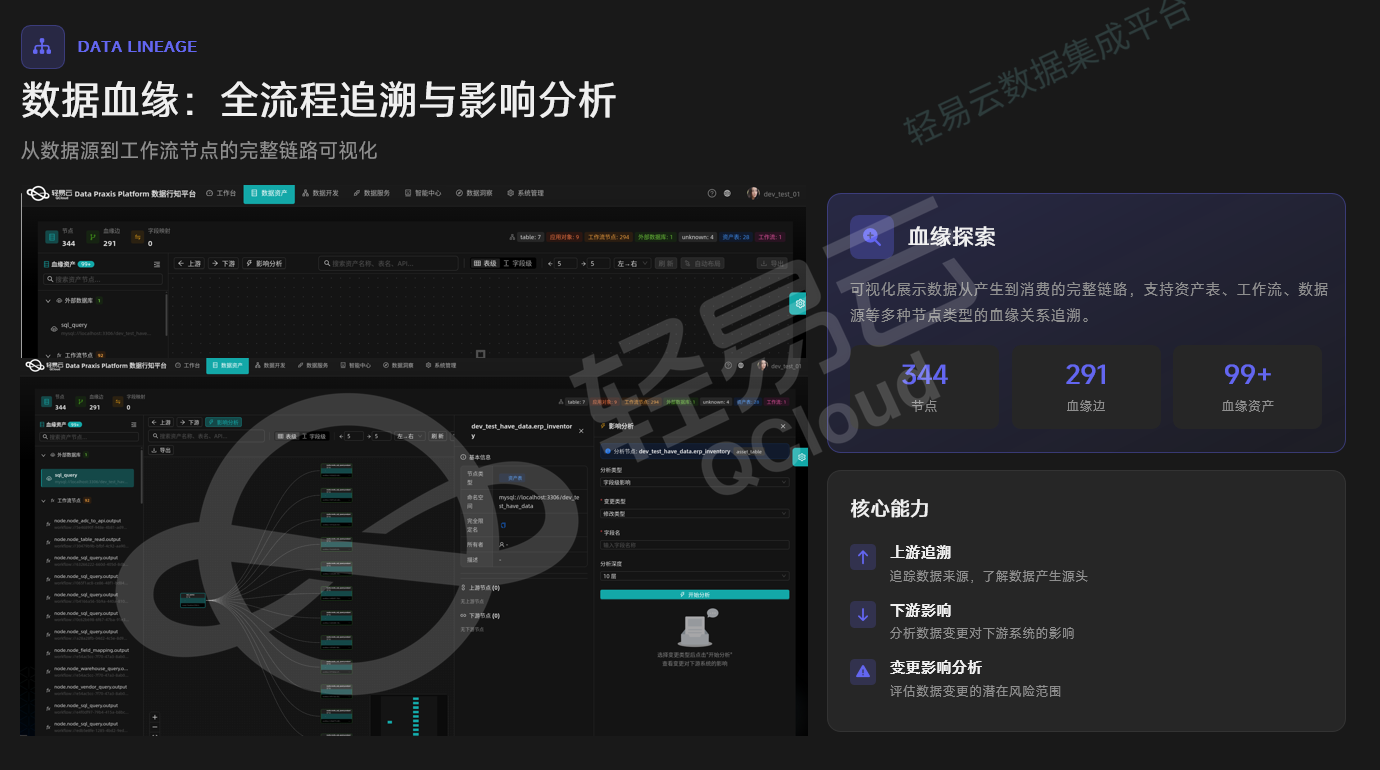
传统数据血缘依赖开发人员手动维护的映射文档,一旦链路复杂化(如电商平台订单数据经清洗、关联、汇总后进入财务系统),文档更新往往滞后于实际代码变更。行知平台的数据血缘模块基于图谱技术构建动态血缘网络,当前已支持344个节点、291条血缘边、99+血缘资产的实时追溯。
核心能力发生质变:上游追溯可定位数据产生的源头系统;下游影响分析能在数据变更前预测对下游报表、API、业务系统的波及范围;变更影响分析则进一步评估潜在风险范围。这种从"事后查阅文档"到"事前推理预判"的转变,是数据平台向智能体演进的关键标志。
3.3 数据服务:从API开发 to 双向智能网关
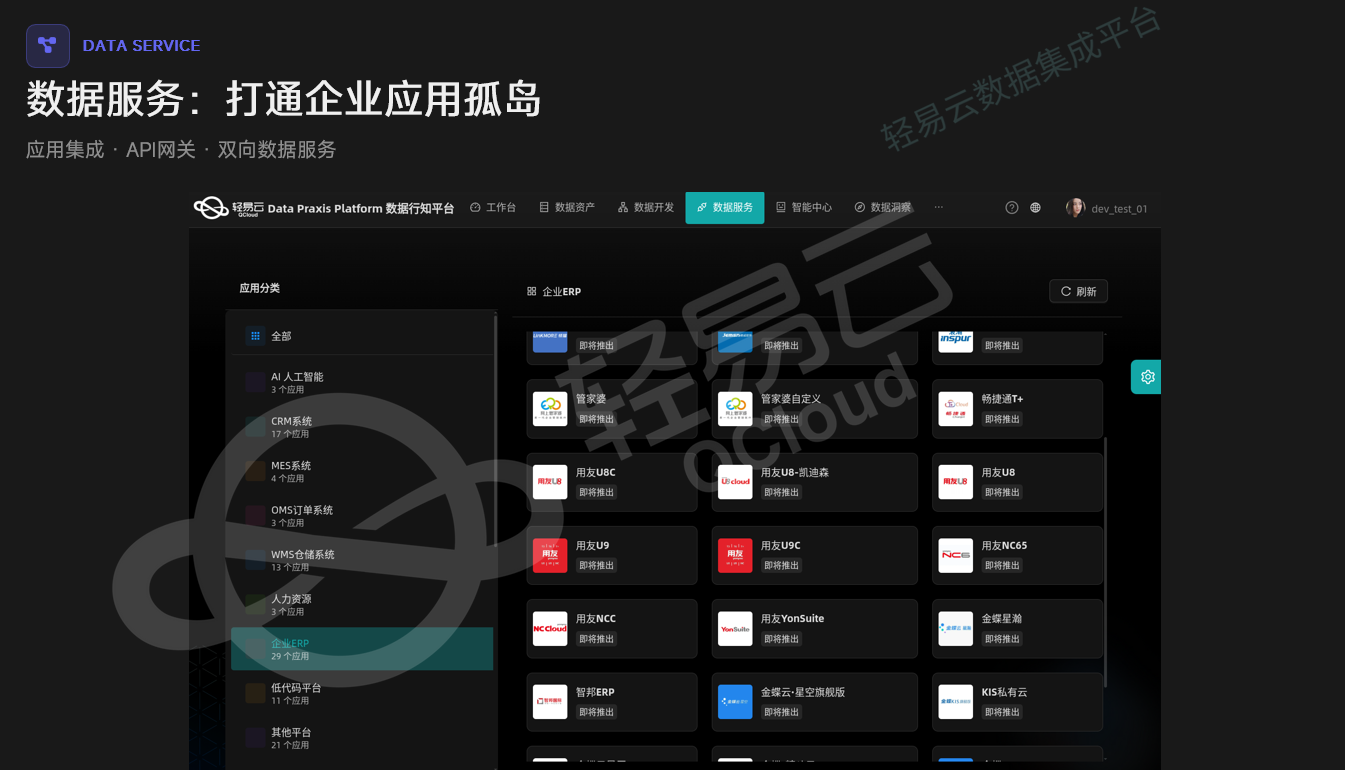
传统集成模式下,每新增一个数据消费方都需要定制化API开发。行知平台的数据服务层采用"向内集成、对外服务"的双向架构:向内通过预置连接器对接金蝶、用友、管家婆、吉客云等主流ERP及淘宝、京东、拼多多等电商平台;对外通过API网关提供标准化的数据服务接口,支持API资产化管理、流量控制与安全认证。这种设计将数据集成从项目制开发转变为平台化配置,显著降低新增系统接入的边际成本。
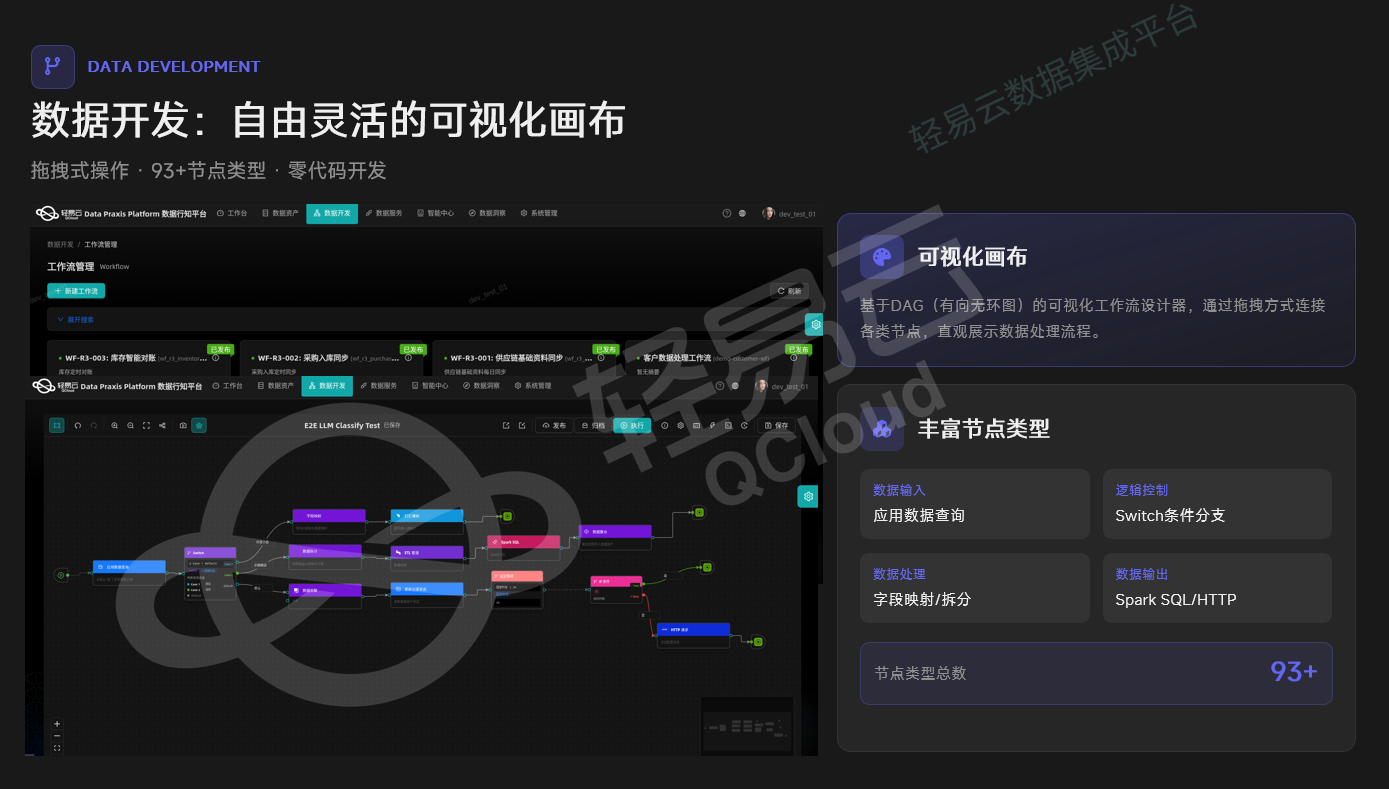
3.4 数据开发:从代码编写 to 可视化编排
数据开发是范式转移最为直观的领域。传统ETL开发依赖工程师编写SQL或脚本代码,行知平台则基于DAG(有向无环图)提供可视化工作流设计器,通过拖拽方式连接各类节点。平台当前支持93+种节点类型,覆盖数据输入(应用数据查询)、逻辑控制(Switch条件分支)、数据处理(字段映射/拆分)、数据输出(Spark SQL/HTTP)等全链路操作。
这种零代码/低代码模式并非简单的"图形化包装",其底层逻辑是将数据处理逻辑抽象为可复用的原子节点,使业务人员能够在不依赖IT排期的情况下自主搭建数据流程,实现从"技术驱动"到"业务自助"的转变。
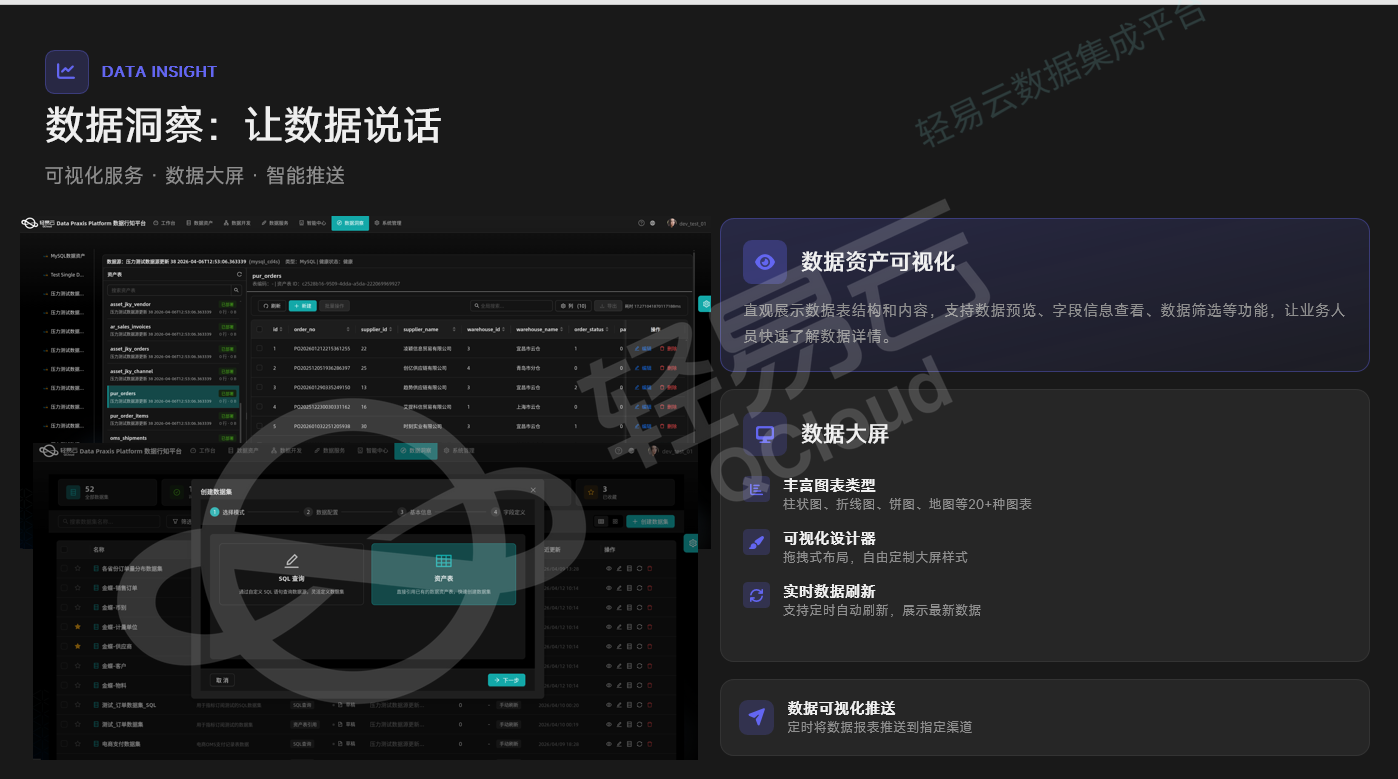
3.5 数据洞察:从固定报表 to 主动推送
传统BI工具以固定报表和数据大屏为主,业务人员被动接收信息。行知平台的数据洞察模块包含三层能力:数据资产可视化支持表结构预览、字段信息查看与数据筛选;数据大屏提供柱状图、折线图、饼图、地图等20+种图表类型,支持拖拽式布局与实时刷新;数据可视化推送则支持定时将报表推送至指定渠道。这种从"人找数据"到"数据找人"的交互逻辑变化,体现了智能体主动服务的特征。
四、数据智能层:平台演进的质变节点
行知平台与传统集成平台的根本分野在于数据智能层的设计。该层由三个组件构成,共同形成平台的"认知中枢":
AI本体图谱(Ontology):构建企业业务世界的知识图谱,将数据资产、业务实体、关系链路以图谱形式组织。这不仅是对元数据的升级,更是使平台具备业务语义理解能力的基础——当用户提及"销售数据"时,平台能够关联到具体的订单表、客户表、产品表及其字段血缘,而非仅返回包含该关键词的表名列表。
OpenClaw龙虾:作为大模型接入层,当前接入MiniMax M2.5模型(4096 tokens上下文),提供智能问答、数据分析与报告生成能力。该模块将通用大模型的语言理解能力与企业私有数据的业务语义相结合,解决了通用AI"懂语言但不懂业务"的痛点。
CHATBI自然语言交互:用户可通过自然语言与数据对话,无需掌握SQL或了解表结构。平台内置三类AI助手角色:本体探索专家帮助理解业务模型与数据关系;表达式助手优化数据转换逻辑;数据质量专员监控数据异常。这种交互模式彻底改变了数据消费的技术门槛,使数据洞察从专业工程师技能转变为普通业务人员的日常工具。
五、业务场景的重构:以电商财务对账为例
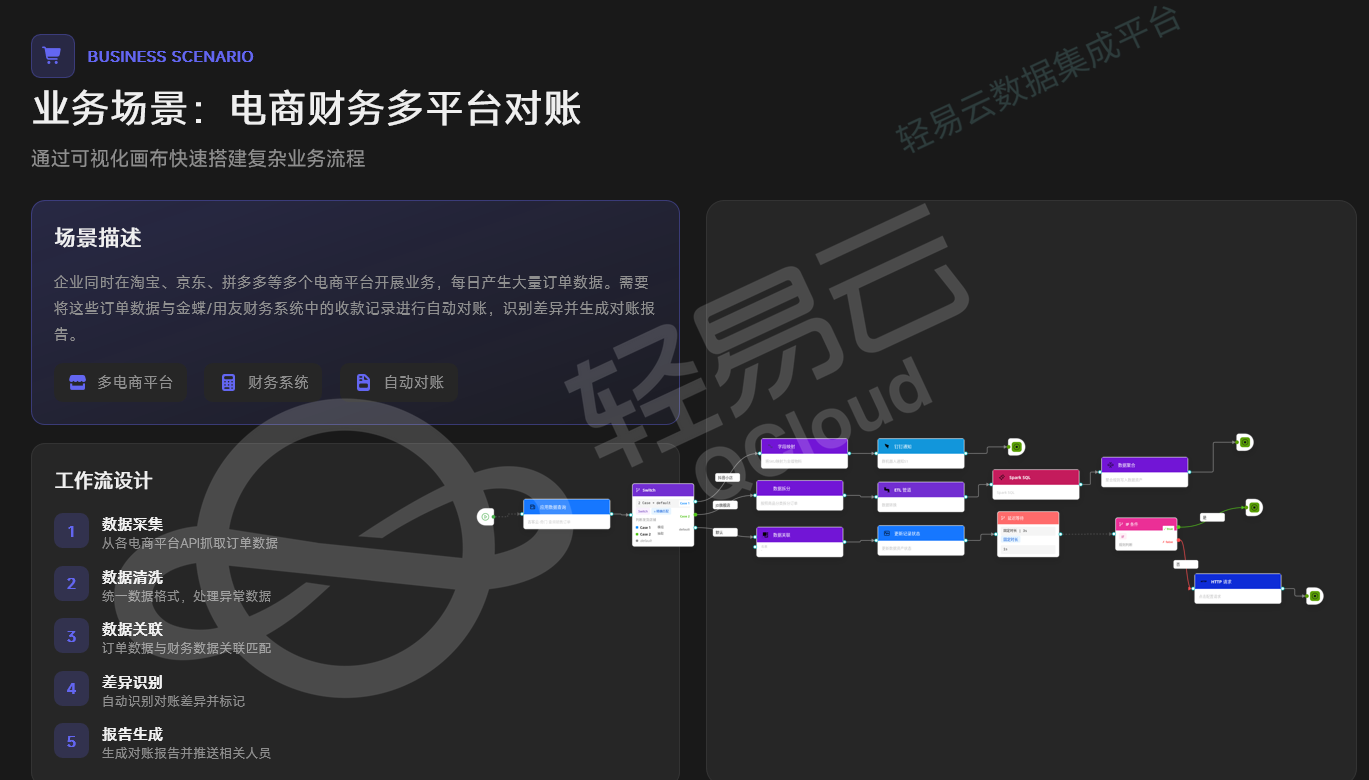
范式转移的价值最终体现在业务场景的重构效率上。以电商财务多平台对账为例,传统模式下需要工程师分别对接淘宝、京东、拼多多API,编写清洗脚本,开发对账算法,再生成固定格式报表。
在行知平台的实现逻辑中,该场景通过可视化画布快速搭建:从各电商平台API抓取订单数据(数据采集节点)→ 统一数据格式并处理异常(数据清洗节点)→ 订单数据与金蝶/用友财务数据关联匹配(数据关联节点)→ 自动识别差异并标记(逻辑判断节点)→ 生成对账报告并推送相关人员(输出+通知节点)。整个流程无需编写底层代码,且因血缘关系的存在,任何上游数据结构的变更都会被自动识别并提示影响范围。
六、结语
行知平台的架构演进揭示了一条清晰的技术路径:数据集成的下一阶段不再是追求更快的传输速度或更多的连接器数量,而是赋予平台对业务语义的理解能力、对数据质量的自主监控能力、以及对用户需求的自然语言响应能力。从数据资产的标准化治理,到数据血缘的图谱化推理,再到CHATBI的自然语言交互,平台正在从被动的数据管道进化为具备业务认知的智能体。这种转变不仅降低了技术门槛,更重要的是将数据管理的重心从"如何搬运数据"转移到了"如何理解业务"——这正是数据智能时代的核心命题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)