学习日记40:Last-VIT
摘要:
Vision Transformer在对大规模数据进行预训练时,为不同的下游任务提供通用的表示。但是在使用Transformer的各种视觉下游任务中发现存在伪影--即VIT模型在识别物体时更多考虑背景而不是前景物体。 文章通过系统实验,得出结论这些伪影源于一种懒惰的聚集行为:VIT使用语义无关的背景patch作为表示全局语义的捷径,受全局注意力和粗粒度语义监督的驱动。 提出将选择token的功能集成到cls中解决上述问题。
介绍:
Vision Transformer(ViT)可以作为通用特征提取器,应用在各种具体的视觉任务中。它们作为在大规模数据上预训练好的固定基础模型,把图像编码成特征表示; 在预训练阶段使用不同的监督方式可以使其产生适合不同下游任务的特性。 比如,监督类方法(例如用分类标签做全监督,或用图文对做文本监督,如 CLIP 模型)能够生成稠密特征,适用于开放词汇任务,同时也能作为大型视觉 - 语言模型(LVLM)的视觉编码器。而自监督方法展现出目标发现与部件发现的能力,这让它们非常适合无监督分割任务。
为了更好的评估伪影,文章设置了两个指标: 1.Patch Score:cls token 与patch features的相似度; 2.Point-in-Box (PiB):具有高Patch Score的patch位于前景区域内的比率;
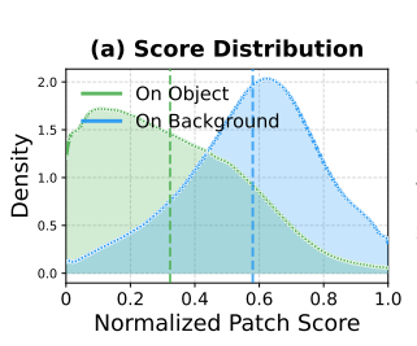
作者研究了在ImageNet-1k(完全监督)上训练的VIT-B/16。将归一化的Patch Score分布可视化。可以看到,Patch Score高的背景占大多数。
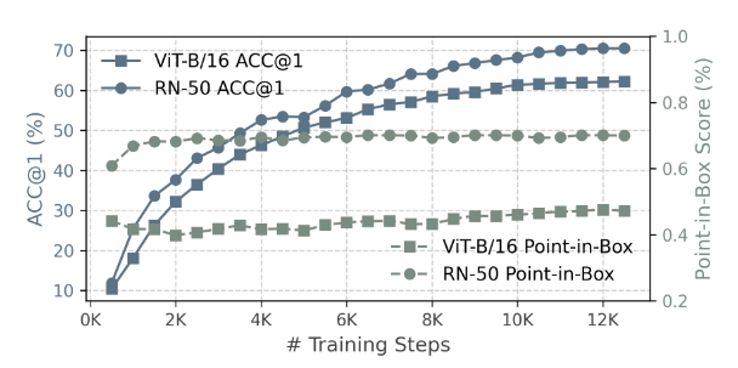
作者使用相同的超参数和批次大小在ImageNet-1k上训练VIT-B/16和ResNet50,并在整个训练过程中跟踪TOP-1精度和Pointin-Box分数。可以得到结论,伪影从VIT模型开始训练就出现,并且不会随着训练消失。
伪影产生的原因:1.粗粒度语义监督:自然图片里本来就有大量和主体物体无关的背景小块。因为只给整张图标类别,没有告诉模型哪里是前景哪里是背景,模型缺少空间指引,所以会偷懒 —— 靠背景信息来表示整张图的意思。把 ViT 里得分最高的 50% 小块删掉,分类准确率几乎没变。2. 全局依赖:让 ViT 学会走捷径:用无关的背景补丁来代表整张图的语义。因为没有逐块标注,ViT 在训练一开始就会偷懒,把前景的一点点信息扩散到背景里。
下面是两个实验来证明上述结论:
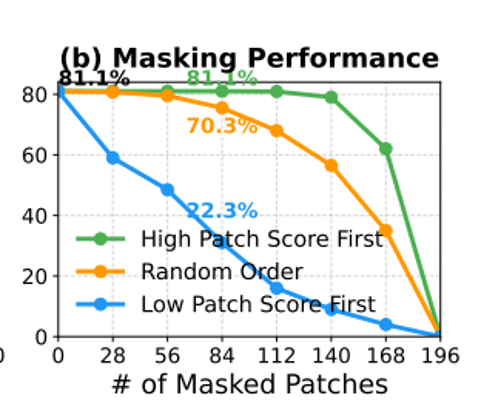
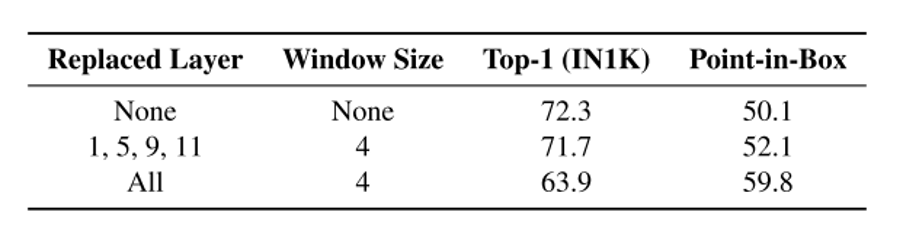
方法:
要解决 ViT 偷懒(懒惰聚合)的问题,就要重新设计 CLS token 的聚合方式:用 “频率感知” 的方法,把前景和背景分开。 自然图片里,前景语义更统一、特征更稳定;背景语义很乱、特征变化很大。所以用通道上的低通滤波 ,选出特征稳定的 patch,让 CLS token 只盯着这些稳定的前景,不看乱的背景。
对每个 patch 的特征,在通道维度做一次 “低通滤波”,把高频噪声过滤掉,留下平稳的信号。 然后,计算稳定性分数S,S越大,说明该patch变化越小,越稳定,更可能是前景;反之,更可能是背景;
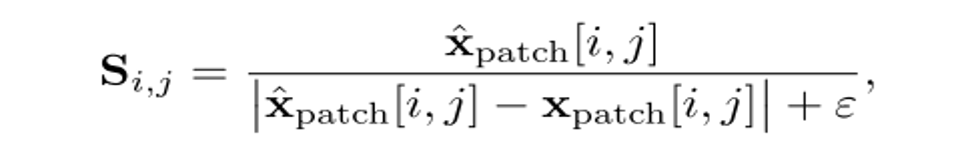
每个通道,挑出最稳定的 K 个 patch,只把它们平均起来生成 CLS,不稳定的背景直接丢掉。
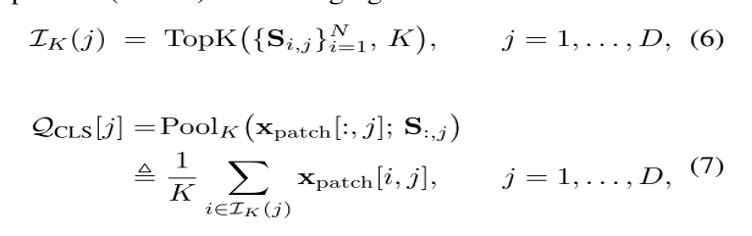
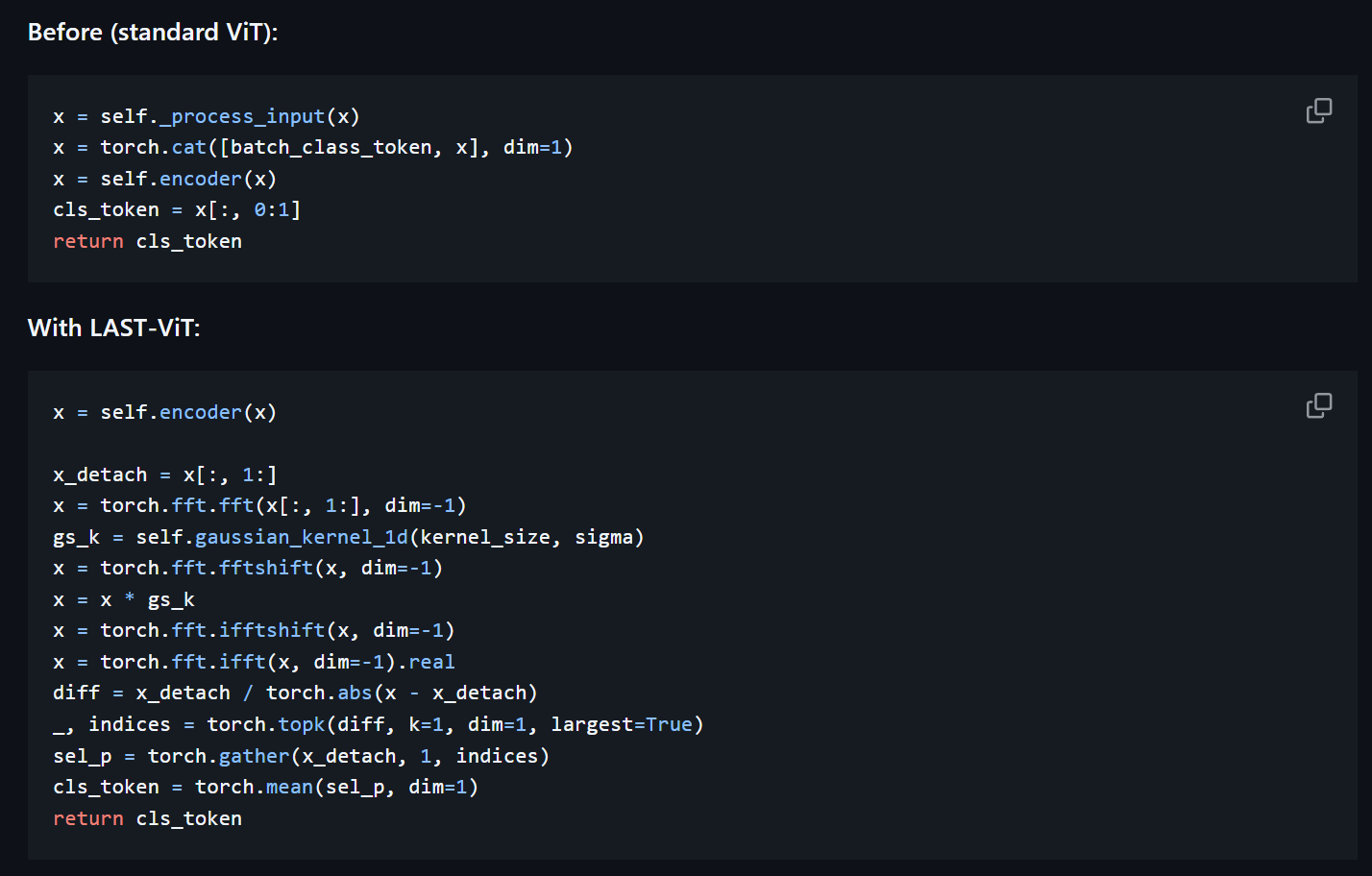
下面是作者提供的github对上述方法的代码演示:
实验:
文本-图像的语义分割和开放域的目标检测实验结果:
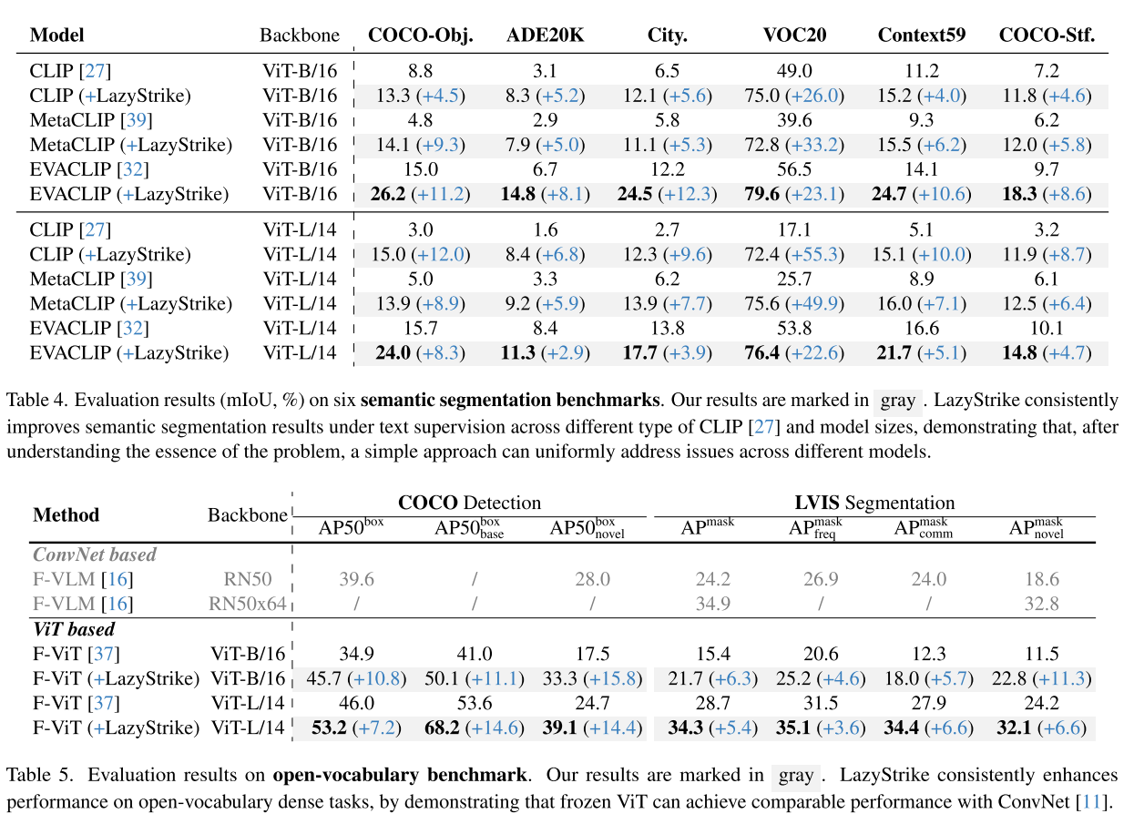
粗语义分割:
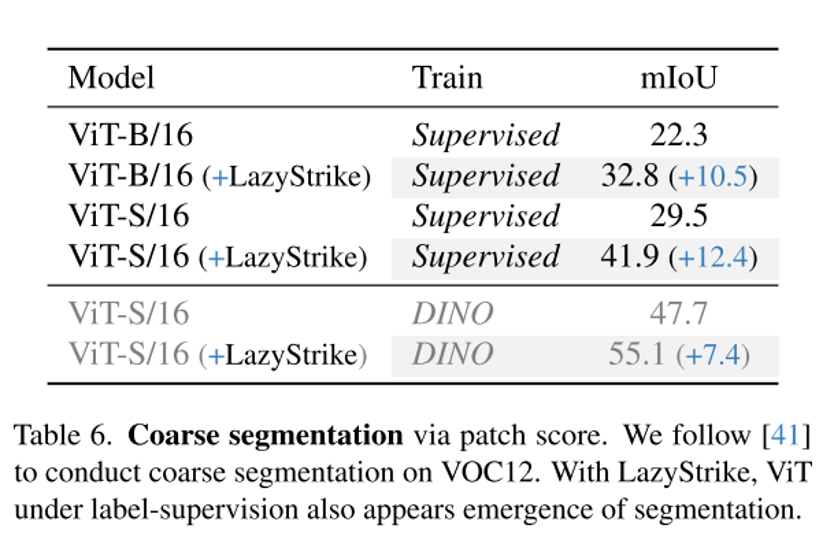
与各种方法的语义分割结果对比:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)