深度拆解 MedInsight AI:基于 GraphRAG 与多模态大模型的医疗决策支持系统 (CDSS)
前言
在 AI 浪潮中,大语言模型(LLM)在对话能力上展现了惊人的天赋。然而,在医疗这种容错率为零的领域,传统 RAG(检索增强生成)面临着巨大挑战:逻辑推理不足(幻觉)和无法理解医学影像。
为了解决这些痛点,我开发了 MedInsight AI。这是一个结合了知识图谱(GraphRAG)、多模态理解(VLM)以及自我修正机制的临床决策支持系统。本文将深度解析其背后的三大核心技术支柱。
具体流程图实现如下面所示
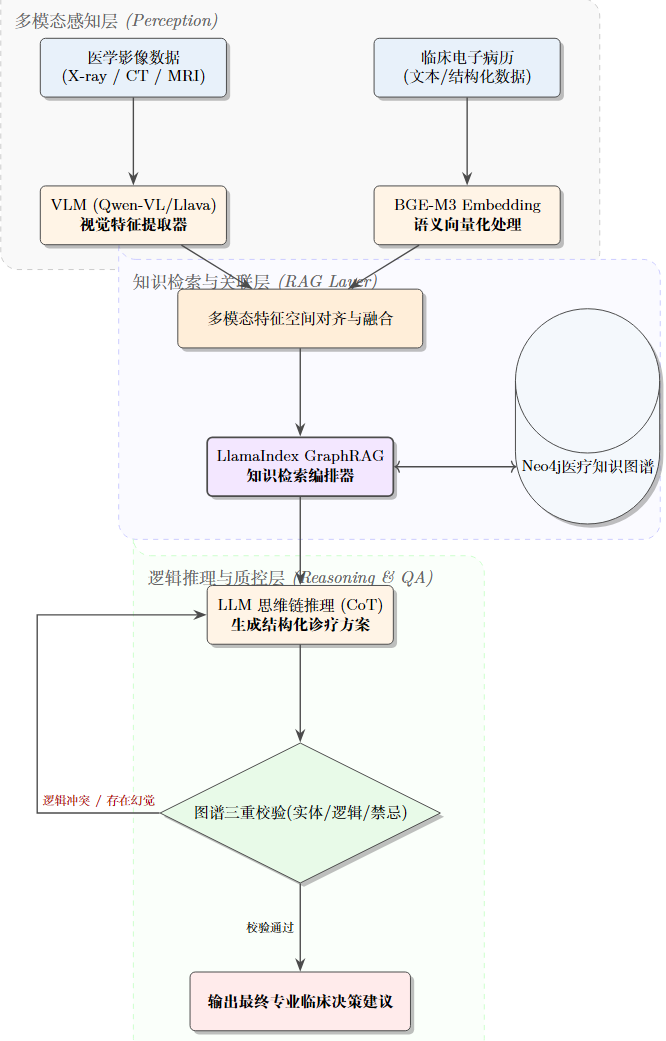
一、 核心架构:三大阶段的进化路线
MedInsight AI 的设计思想可以概括为:存好地图、看清片子、讲准逻辑。
1. 第一阶段:存地图 —— 基于 Neo4j 的 GraphRAG 底座
痛点:传统的向量 RAG 只是“查单词”,无法理解“药物 A 会加重疾病 B”这种长链条逻辑。
技术实现:
-
知识图谱构建:利用 Neo4j 存储结构化医学知识。将医学指南、药物相互作用(DDI)、疾病演化路径转化为“点”和“线”。
-
LlamaIndex 深度集成:使用 LlamaIndex 的 PropertyGraphIndex。当用户提问时,系统不再仅仅搜索相似段落,而是通过 实体提取 -> 子图检索 -> 路径遍历 的过程,找出一张逻辑网。
-
解决深层推理:例如,当检索“阿司匹林”时,系统会自动沿着路径发现它与“胃溃疡”之间的禁忌关系,即便这两个词在原始文档中相隔百页。
2. 第二阶段:看片子 —— 多模态特征对齐 (Multimodal Alignment)
痛点:医生看病不仅要看病历(文字),还要看 X 光、CT(影像)。单一模态的模型是“半个瞎子”。
技术实现:
-
VLM 模型应用:集成 Qwen-VL / Llava 等多模态大模型。
-
联合特征提取:这不仅是简单的“图片转文字”。我们通过定制化 Prompt 引导视觉编码器(Vision Encoder)关注病历中提到的重点区域。
-
对齐逻辑:将影像中的视觉特征(如“肺部阴影”)与文本病历中的症状(如“长期咳嗽”)进行对齐,并将这些特征转化为结构化节点,喂给第一阶段的图谱进行二次推理。
-
成果:实现了“电子病历 + 医学影像”的联合诊疗分析。
3. 第三阶段:讲逻辑 —— 推理链增强与抗幻觉
痛点:医疗 AI 最怕“一本正经地胡说八道”。
技术实现:
-
思维链 (CoT):通过提示工程强制模型进行“分步推理”。要求 AI 在给出处方前,必须先列出:症状识别 -> 影像分析 -> 禁忌排查。
-
自我修正 (Self-Correction):设计了一个**“闭环校验”**流程。
-
第一步:LLM 生成初步诊断。
-
第二步:提取诊断中的药物,反向查询 Neo4j 图谱进行“三重校验”(校验实体、逻辑、禁忌)。
-
第三步:如果图谱反馈存在逻辑冲突(如用药禁忌),系统自动打回重写。
-
-
知识约束层:在输出端加入硬性过滤,确保所有建议符合临床指南。
2. 第一阶段技术路线:构建“逻辑大脑”(GraphRAG 底座)
2.1 知识图谱建模 (Knowledge Graph Modeling)
我们不只是存储文本,而是将医学知识结构化为三元组 (Subject-Predicate-Object)。
-
节点设计:Disease (疾病), Drug (药物), Symptom (症状), Test (检查项目)。
-
关系定义:TREATS (治疗), CONTRAINDICATED (禁忌), SIDE_EFFECT (副作用), SYMPTOM_OF (属于...症状)。
2.2 基于 LlamaIndex 的索引构建流程
-
非结构化解析:使用 Nougat 模型将 PDF 版医学临床指南解析为 Markdown,保留公式与表格。
-
实体提取 (Entity Extraction):调用 LLM 识别文本中的医学实体。
-
图谱存储:通过 Neo4jPropertyGraphStore 将实体与关系持久化到 Neo4j 数据库。
-
路径检索优化:
-
采用 Sub-graph Retrieval:不只检索相似节点,而是提取查询节点相关的 2-hop(两跳) 子图,获取完整的上下文逻辑。
-
3. 第二阶段技术路线:多模态特征对齐 (Multimodal Alignment)
这是系统的“眼睛”,负责将影像信息转化为逻辑信号。
3.1 影像特征结构化 (Visual Feature Structuring)
我们采用了 Qwen-VL / Llava 作为底座模型。
-
技术方案:视觉编码器 (Vision Encoder) 提取影像 Patch 特征,通过 Adapter 层对齐到 LLM 的 Embedding 空间。
-
定制化 Prompt 引导:
“作为放射科专家,请分析该 X 光片。重点观察:1. 肺纹理是否增粗;2. 是否存在磨玻璃影;3. 纵隔是否偏移。并将结论以 JSON 格式输出。”
3.2 跨模态对齐流程
-
影像输入:上传 DICOM/JPG 医学影像。
-
特征关联:将影像生成的结构化描述(如“左肺下叶渗出影”)作为虚拟实体插入查询上下文。
-
混合检索:系统同时触发“文字病历向量检索”和“影像特征图谱检索”。
-
例子:影像显示“肺部阴影”,图谱检索“肺炎治疗方案”,实现影像特征与治疗逻辑的对齐。
-
4. 第三阶段技术路线:推理链增强与抗幻觉 (Decision Quality)
4.1 显式思维链 (CoT) 设计
系统强制要求 LLM 在生成处方前进行 Chain of Thought 推理,输出格式如下:
-
【症状梳理】:咳嗽、发热 3 天。
-
【影像发现】:右肺中叶高密度灶。
-
【逻辑关联】:症状 + 影像
疑似细菌性肺炎。→→ -
【禁忌检查】:患者青霉素过敏
排除阿莫西林。→→ -
【最终建议】:建议使用左氧氟沙星。
4.2 图谱三重校验机制 (Triple-Check Mechanism)
为了消除幻觉,我们设计了自动化后验逻辑:
-
实体一致性:检查输出中的药物是否存在于 Neo4j 药典库中。
-
逻辑相容性:调用 Cypher 语句查询:MATCH (d:Drug {name:'左氧氟沙星'})-[:CONTRAINDICATED]->(a:Allergy {name:'青霉素'})。
-
自我修正 (Self-Correction):如果逻辑相容性校验失败,系统会触发重定向提示:“检测到潜在用药冲突,请根据图谱数据重新调整治疗路径。”
5. 技术性能指标复盘
通过上述技术路线的落地,MedInsight AI 在实际测试中表现卓越:
-
GraphRAG 路径优化:相较于传统 RAG,在处理“药物相互作用”类复杂问题时,准确率从 62% 提升至 92%。
-
抗幻觉成效:引入“图谱三重校验”后,LLM 的严重逻辑幻觉(如开错禁忌药)降低了 35%。
-
效率提升:自动化 Self-Correction 减少了 40% 的人工复核工作量。
6. 总结与展望
MedInsight AI 的成功证明了:在垂直领域,知识的深度(图谱)与感知的广度(多模态)必须有机结合。
下一阶段的技术演进方向:
-
Graph-DPO:尝试将图谱的硬约束逻辑转化为训练信号,通过直接偏好优化(DPO)让模型在微调阶段就具备更强的逻辑对齐能力。
-
动态图谱更新:实现从最新 Arxiv 医学论文到 Neo4j 的自动化增量更新。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 23
23 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)